
DiffBTS: A Lightweight Diffusion Model for 3D Multimodal Brain Tumor Segmentation


Abstract
1. Introduction
- We propose a 3D multi-head efficient self-attention mechanism embedded between down-sampling and skip connections to form the DiffBTS framework, which enhances the model’s segmentation performance.
- We introduce a novel guidance algorithm, dubbed the Edge-Blurring Guided (EBG) algorithm, that uses the edge information generated during the diffusion model inference process to enhance sample quality without relying on external conditions or additional fine-tuning.
- We conducted a large number of comparative experiments on BraTS2020 and BraTS2021 datasets. The Dice and HD95 scores of the three segmentation targets (WT, TC, and ET) generally outperform those of the state-of-the-art methods.
2. Related Work
2.1. Diffusion-Based Medical Image Segmentation Models
2.2. UNet-Based Medical Image Segmentation Models
2.3. Transformer-Based Medical Image Segmentation Model
3. Methods
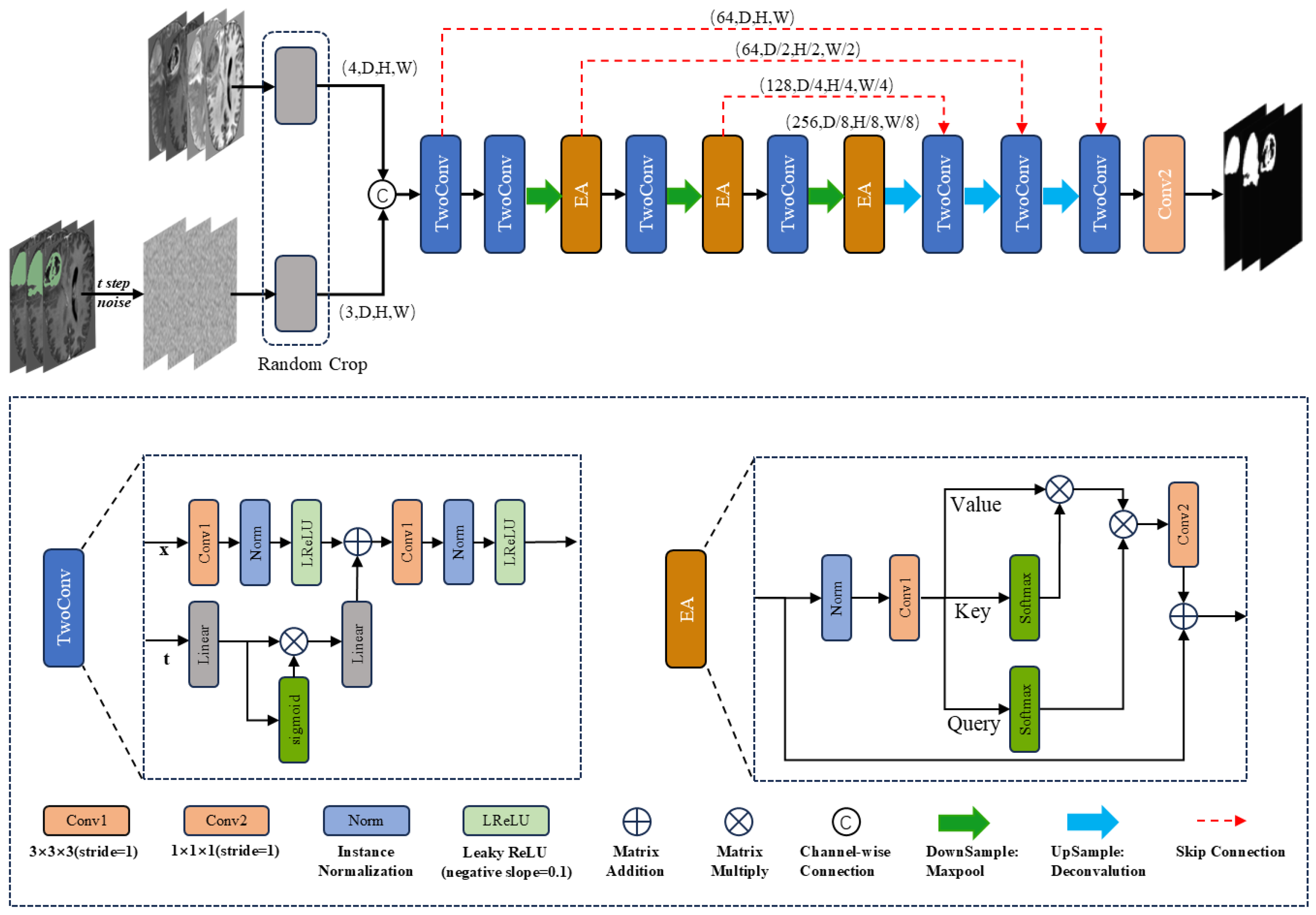
3.1. DiffBTS Overall Framework
3.2. Three-Dimensional Multi-Head Efficient Self-Attention
3.3. Diffusion Model Sampling
3.4. Self-Attention Guidance for Diffusion Models
3.5. Edge-Blurring Guided Algorithm
| Algorithm 1 Edge-Blurring Guided Sampling |
|
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Indicators
4.3. Experimental Details
4.4. Comparison Experiment
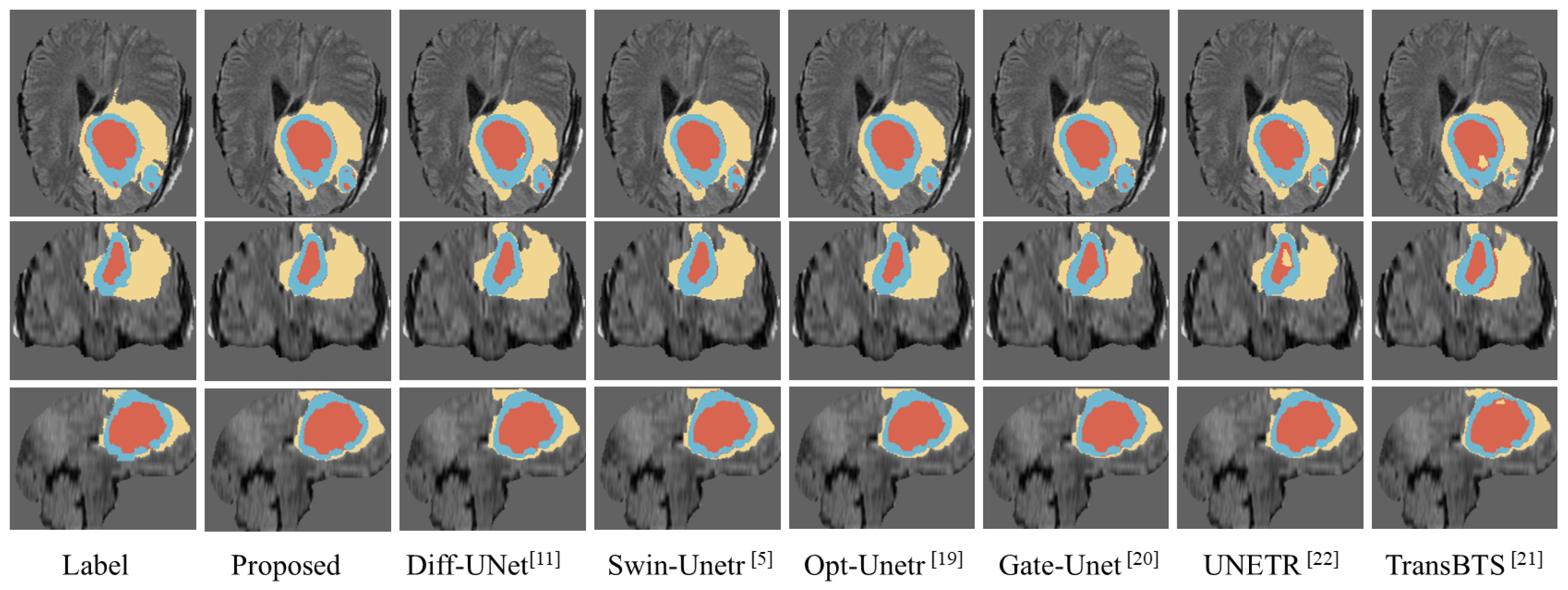
4.5. Visualization Comparison
4.6. Ablation Experiment
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DDPMs | Denoising diffusion probabilistic models |
| EA | Three-dimensional multi-head efficient self-attention module |
| EBG | Edge-Blurring Guided algorithm |
| BraTS | Brain Tumor Segmentation |
| MRI | Magnetic resonance imaging |
| CNN | Convolutional neural networks |
| SAG | Self-Attention Guidance |
| T1 | T1-weighted |
| T1ce | Contrast-enhanced T1-weighted |
| T2 | T2-weighted |
| FLAIR | Fluid-attenuated inversion recovery |
| DSC | Dice similarity coefficient |
| HD95 | 95th percentile Hausdorff distance |
| WT | Whole Tumor |
| TC | Tumor Core |
| ET | Enhancing Tumor |
References
- Dixon, L.; Jandu, G.K.; Sidpra, J.; Mankad, K. Diagnostic accuracy of qualitative MRI in 550 paediatric brain tumours: Evaluating current practice in the computational era. Quant. Imaging Med. Surg. 2022, 12, 131. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.; Xu, D. Swin UNETR: Swin transformers for semantic segmentation of brain tumors in MRI images. In Proceedings of the International MICCAI Brainlesion Workshop, Online, 27 September 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 272–284. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Jiang, Y.; Zhang, Y.; Lin, X.; Dong, J.; Cheng, T.; Liang, J. SwinBTS: A method for 3D multimodal brain tumor segmentation using swin transformer. Brain Sci. 2022, 12, 797. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Wolleb, J.; Sandkühler, R.; Bieder, F.; Valmaggia, P.; Cattin, P.C. Diffusion models for implicit image segmentation ensembles. In Proceedings of the International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; PMLR: Breckenridge, CO, USA, 2022; pp. 1336–1348. [Google Scholar]
- Xing, Z.; Wan, L.; Fu, H.; Yang, G.; Zhu, L. Diff-UNet: A diffusion embedded network for volumetric segmentation. arXiv 2023, arXiv:2303.10326. [Google Scholar]
- Wu, J.; Fu, R.; Fang, H.; Zhang, Y.; Yang, Y.; Xiong, H.; Liu, H.; Xu, Y. MedSegDiff: Medical image segmentation with diffusion probabilistic model. In Proceedings of the Medical Imaging with Deep Learning, Paris, France, 3 July 2024; PMLR: Breckenridge, CO, USA, 2024; pp. 1623–1639. [Google Scholar]
- Wu, J.; Ji, W.; Fu, H.; Xu, M.; Jin, Y.; Xu, Y. MedSegDiff-V2: Diffusion-based medical image segmentation with transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 6030–6038. [Google Scholar]
- Rahman, A.; Valanarasu, J.M.J.; Hacihaliloglu, I.; Patel, V.M. Ambiguous medical image segmentation using diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11536–11546. [Google Scholar]
- Guo, X.; Yang, Y.; Ye, C.; Lu, S.; Xiang, Y.; Ma, T. Accelerating diffusion models via pre-segmentation diffusion sampling for medical image segmentation. In Proceedings of the 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 18–21 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Chen, T.; Wang, C.; Chen, Z.; Lei, Y.; Shang, H. HiDiff: Hybrid diffusion framework for medical image segmentation. arXiv 2024, arXiv:2407.03548. [Google Scholar] [CrossRef] [PubMed]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018; Springer International Publishing: Granada, Spain, 2018; pp. 3–11. [Google Scholar]
- Futrega, M.; Milesi, A.; Marcinkiewicz, M.; Ribalta, P. Optimized U-Net for brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Online, 27 September 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 15–29. [Google Scholar]
- Schwehr, Z.; Achanta, S. Brain tumor segmentation based on deep learning, attention mechanisms, and energy-based uncertainty prediction. arXiv 2023, arXiv:2401.00587. [Google Scholar] [CrossRef]
- Wang, W.; Chen, C.; Ding, M.; Li, J.; Yu, H.; Zha, S. TransBTS: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 109–119. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B. UNETR: Transformers for 3D medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- ZongRen, L.; Silamu, W.; Yuzhen, W.; Zhe, W. DenseTrans: Multimodal brain tumor segmentation using swin transformer. IEEE Access 2023, 11, 42895–42908. [Google Scholar] [CrossRef]
- Wu, Y.; Liao, K.; Chen, J.; Wang, J.; Chen, D.Z.; Gao, H.; Wu, J. D-former: A u-shaped dilated transformer for 3D medical image segmentation. Neural Comput. Appl. 2023, 35, 1931–1944. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Nat. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3531–3539. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv 2022, arXiv:2207.12598. [Google Scholar]
- Hong, S.; Lee, G.; Jang, W.; Kim, S. Improving sample quality of diffusion models using self-attention guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 7462–7471. [Google Scholar]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Bakas, S.; et al. The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Peiris, H.; Chen, Z.; Egan, G.; Harandi, M. Reciprocal adversarial learning for brain tumor segmentation: A solution to BraTS challenge 2021 segmentation task. In Proceedings of the International MICCAI Brainlesion Workshop, Online, 27 September 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 171–181. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Param (M) | Dice↑ | HD95↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | Mean | WT | TC | ET | Mean | ||
| Swin-Unetr [5] | 237.2 | 91.69 | 84.79 | 80.80 | 85.76 | 2.797 | 4.073 | 2.627 | 3.166 |
| Vizviva [32] | 32.5 | 90.74 | 84.43 | 79.36 | 84.84 | 3.566 | 4.351 | 4.006 | 3.974 |
| UNETR [22] | 424.3 | 91.27 | 82.35 | 78.77 | 84.13 | 4.469 | 4.854 | 3.529 | 4.281 |
| Opt-Unet [19] | 178.7 | 92.18 | 85.55 | 80.16 | 85.96 | 1.551 | 2.697 | 3.161 | 2.470 |
| Diff-Unet [11] | 146.3 | 92.02 | 85.06 | 79.87 | 85.65 | 1.787 | 3.408 | 3.415 | 2.870 |
| TransBTS [21] | 125.8 | 90.17 | 82.54 | 76.96 | 83.22 | 4.999 | 4.981 | 5.224 | 5.068 |
| Gate-Unet [20] | 72.1 | 91.43 | 84.49 | 79.09 | 85.00 | 2.683 | 4.289 | 4.377 | 3.783 |
| Proposed | 27.0 | 92.24 | 86.68 | 80.41 | 86.44 | 1.634 | 2.486 | 3.277 | 2.466 |
| Module | Param (M) | Dice↑ | HD95↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | Mean | WT | TC | ET | Mean | ||
| Swin-Unetr * [5] | 237.2 | 92.81 | 90.09 | 84.88 | 89.26 | 1.449 | 1.751 | 1.968 | 1.723 |
| Vizviva [32] | 32.5 | 90.89 | 88.42 | 82.79 | 87.37 | 2.326 | 3.743 | 4.383 | 3.484 |
| UNETR [22] | 424.3 | 91.87 | 87.97 | 84.12 | 87.99 | 2.064 | 2.706 | 3.253 | 2.674 |
| Opt-Unet [19] | 178.7 | 92.81 | 90.27 | 85.20 | 89.42 | 1.501 | 1.677 | 1.960 | 1.712 |
| Diff-Unet [11] | 146.3 | 92.50 | 89.41 | 85.16 | 89.02 | 1.701 | 2.073 | 2.116 | 1.963 |
| TransBTS [21] | 125.8 | 92.18 | 89.55 | 84.12 | 88.62 | 2.108 | 1.905 | 2.549 | 2.186 |
| Gate-Unet [20] | 72.1 | 90.65 | 87.55 | 84.79 | 87.07 | 2.920 | 2.757 | 3.158 | 2.945 |
| Proposed | 27.0 | 92.95 | 90.70 | 86.33 | 89.99 | 2.035 | 1.670 | 2.077 | 1.928 |
| Module | Dice↑ | HD95↓ | Recall↑ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | |
| Baseline | 91.15 | 85.41 | 78.16 | 1.975 | 3.521 | 4.327 | 92.32 | 88.09 | 88.38 |
| Basic | 90.74 | 83.59 | 77.40 | 4.524 | 6.547 | 6.760 | 89.64 | 84.08 | 81.07 |
| Basic (L4) | 91.07 | 84.35 | 78.83 | 2.222 | 4.231 | 3.331 | 89.50 | 83.60 | 81.24 |
| Basic + DA | 91.24 | 84.21 | 77.51 | 3.229 | 5.469 | 5.914 | 91.59 | 85.95 | 80.57 |
| Basic + EBG | 91.47 | 84.28 | 78.48 | 4.228 | 6.520 | 6.927 | 93.52 | 88.18 | 86.61 |
| Basic + EA | 91.63 | 86.06 | 79.51 | 1.830 | 2.652 | 3.333 | 90.72 | 85.40 | 81.58 |
| Basic + EA + EBG | 92.24 | 86.68 | 80.41 | 1.634 | 2.486 | 3.277 | 93.75 | 88.56 | 85.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, Z.; Yang, J.; Li, C.; Wang, Y.; Tang, J. DiffBTS: A Lightweight Diffusion Model for 3D Multimodal Brain Tumor Segmentation. Sensors 2025, 25, 2985. https://doi.org/10.3390/s25102985
Nie Z, Yang J, Li C, Wang Y, Tang J. DiffBTS: A Lightweight Diffusion Model for 3D Multimodal Brain Tumor Segmentation. Sensors. 2025; 25(10):2985. https://doi.org/10.3390/s25102985
Chicago/Turabian StyleNie, Zuxin, Jiahong Yang, Chengxuan Li, Yaqin Wang, and Jun Tang. 2025. "DiffBTS: A Lightweight Diffusion Model for 3D Multimodal Brain Tumor Segmentation" Sensors 25, no. 10: 2985. https://doi.org/10.3390/s25102985
APA StyleNie, Z., Yang, J., Li, C., Wang, Y., & Tang, J. (2025). DiffBTS: A Lightweight Diffusion Model for 3D Multimodal Brain Tumor Segmentation. Sensors, 25(10), 2985. https://doi.org/10.3390/s25102985