Abstract
Precision depth estimation plays a key role in many applications, including 3D scene reconstruction, virtual reality, autonomous driving and human–computer interaction. Through recent advancements in deep learning technologies, monocular depth estimation, with its simplicity, has surpassed the traditional stereo camera systems, bringing new possibilities in 3D sensing. In this paper, by using a single camera, we propose an end-to-end supervised monocular depth estimation autoencoder, which contains an encoder with a structure with a mixed convolution neural network and vision transformers and an effective adaptive fusion decoder to obtain high-precision depth maps. In the encoder, we construct a multi-scale feature extractor by mixing residual configurations of vision transformers to enhance both local and global information. In the adaptive fusion decoder, we introduce adaptive fusion modules to effectively merge the features of the encoder and the decoder together. Lastly, the model is trained using a loss function that aligns with human perception to enable it to focus on the depth values of foreground objects. The experimental results demonstrate the effective prediction of the depth map from a single-view color image by the proposed autoencoder, which increases the first accuracy rate about 28% and reduces the root mean square error about 27% compared to an existing method in the NYU dataset.
1. Introduction
The purpose of depth estimation is to accurately predict the distance between objects and the camera. Depth information finds wide applications across various fields, including household robots [1], autonomous driving [2], 3D movie production [3], etc. Depth information could also be the input data for other computer vision tasks such as face recognition [4], object detection [5] and semantic segmentation [6]. A high-quality depth map is mostly characterized by accurate depth values specified along well-defined object boundaries.
Depth estimation by stereo matching neural networks was first initiated by comparing image patches [7]. To further improve the depth quality, the two-stage network with cascade residual learning [8], the pyramid network [9] and the network with semi-global and mutual information [10] were proposed. Stereo matching neural networks, however, need multiple cameras for depth prediction. If we try to use a single-view image to predict depth, the estimation process becomes a challenging task due to its ill-posed condition. When humans look at a picture and try to understand the spatial relationship of the objects from it, we mostly consider both local cues and global context. Local cues refer to details such as the texture appearance and the perspective of objects, the relative sizes, etc. On the other hand, global context, referring to occlusion issues and global spatial relationships, could be exhibited from the layout of the scene. By assessing these factors, humans and the monocular depth estimation neural networks can make good sense of the geometric configuration from a single image.
For deep learning networks, mainly as the feature extractors, we could employ a series of convolutional neural and down-sampling blocks to gradually extract the detailed and global features layer-by-layer. For instance, VGG [11] achieves this by applying multiple 3 × 3 convolution layers and pooling operations to encode the image into latent features. For better convergence, ResNet [12] utilizes residual blocks with skip connections to learn residual information and extract image features. For both VGG and ResNet, the features in the shallow layers possess more detailed information while those in the deeper layers hold more global information. In recent years, vision transformers [13] have gained a lot of attention because they are with rich global information and can achieve a good performance in computer vision tasks. Many researchers attribute this success to the self-attention mechanism [14], which enables the input features to capture abundant global information and significantly expand their receptive fields. However, the amounts of parameters and calculations of the vision transformers are very large. In addition to the final extracted features, we must efficiently utilize the detailed features from lower layers by the co-called skip connections [15]. How to perfectly fuse the decoded feature and the skip-connected encoder feature is also crucial in the design of the decoder.
2. Related Work
Monocular depth estimation (MDE) [16,17], which is accomplished by using a single color image, can significantly minimize the requirement for multiple cameras and greatly reduce hardware resources. Since monocular depth estimation methods only take a single color image as the input, it is more difficult to estimate the precision depth map than with the stereo matching approaches. Heavily depending on the image to ground truth depth mapping regression, monocular depth estimation methods with deep learning structures can be divided into supervised learning [18], unsupervised learning [19] and semi-supervised learning approaches [20]. Supervised networks apply ground truth depth maps to train a neural network as a regression model. Eigen et al. [18] were the pioneers to approach monocular depth estimation using a deep learning method, where the CNN-based network comprises two stacked deep networks, a coarse depth network and a refinement network. As regards unsupervised monocular depth estimation, Godard et al. [19] introduced a network system that takes a single-view image as the input to generate depth map without ground truth depth. During the training period, however, it needs both the left and right views. The input left and right view images with the estimated depth maps by the MDE networks are warped to the other synthesized view images. The reconstruction loss subsequently utilizes the closeness of the synthesized and the input images to facilitate unsupervised learning. The semi-supervised learning approach [20] simultaneously apply supervised and unsupervised loss terms; however, the possible synthesizing of paired images should be performed. Considering consecutive multiple single-view frames, Yang et al. [21] suggested video-based depth estimation autoencoder to further improve the depth performances.
2.1. Vision Transformer
Dosovitskiy et al. [13] are the pioneers of developing a structure related to a transformer in an image classification task. The vision transformer (ViT) [13], which is a new type of neural network for computer vision, extends the success of transformers originally developed for natural language processing [14]. To extract more global features, the ViT and its variations have gained significant attention and achieved state-of-the-art results in various computer vision tasks such as image classification [22], semantic segmentation [23] and depth estimation [24] but with higher computation. Unlike traditional convolutional neural networks (CNNs) that rely on spatial convolutions and pooling layers, the vision transformers utilize the multi-head self-attention mechanism to calculate global dependencies and long-range relationships within an image.
In vision transformers, the input image is segmented into patches, which are then flattened to vectors. Linear projection or 1 × 1 convolution is used for adjusting the length of the flattened vectors as “patch embeddings” or “tokens”. These tokens are then passed through the transformer blocks to capture global information. The basic architecture of a vision transformer block is shown in Figure 1, where the ViT is used to detect the class (bird, car, ball, or ….) of the image. The vision transformer consists of layer normalization (LN), multi-head self-attention (MSA), channel MLP and the residual connections.
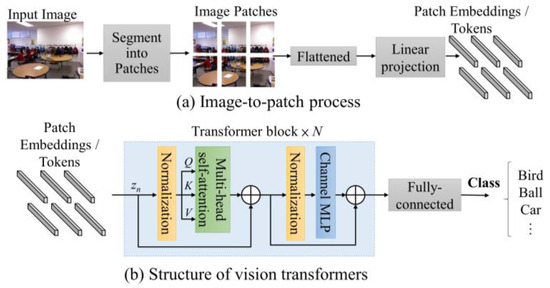
Figure 1.
The structure of the vision transformer.
Many studies have proposed using a vision transformer to increase global information [25,26,27] for monocular depth estimation. With a Transbins module, Depthformer [26] employs the attention-based architecture to attain the advantage of a global reception field. To explore local details and global dependency, PCTNet [27] adopts CNN and vision transformer branches by using bidirectional feature and cross-feature multi-scale fusion modules to obtain good results for single structured light image depth estimation. GlobalFuse-Depth [28] also suggests CNN and vision transformer branches to capture the features of paired images and fuse them together to achieve better depth estimation. The network needs paired, i.e., night and daytime, images with a pretrained CycleGAN. It is noted that PCTNet uses self-supervised training and tests with structured light databases. Generally, the vision transformers will introduce huge computation in their networks.
2.2. Atrous Spatial Pyramid Pooling
To expand the receptive field for convolutional neural networks, a common solution is to increase the kernel size of standard convolutions. However, the computation will become larger while using a bigger convolutional kernel size. Dilated convolution is similar to standard convolution by introducing gaps between each kernel pixel based on the specific dilation rate. The dilated convolution allows the kernel receptive field to be expanded without increasing computations. For instance, in a standard 3 × 3 convolution with dilation rate of two, its receptive field is expanded to achieve the same receptive field as a standard 5 × 5 standard convolution kernel. The 3 × 3 convolution with a dilation rate of two utilizes only nine kernel parameters.
Chen et al. [29] introduced the Atrous spatial pyramid pooling (ASPP) module, as shown in Figure 2. The ASPP module learns a comprehensive feature by combining the features obtained from a pooling layer and multiple convolution layers with different dilation rates. The BTS network [30] is composed of a dense feature extractor, ASPP as the contextual information extractor, local planar guidance layers and their dense connection for depth estimation. The ASPP captures the large-scale variations in features by applying sparse convolutions with various dilation rates. The BTS network presents a supervised monocular depth estimation network to achieve state-of-the-art results.
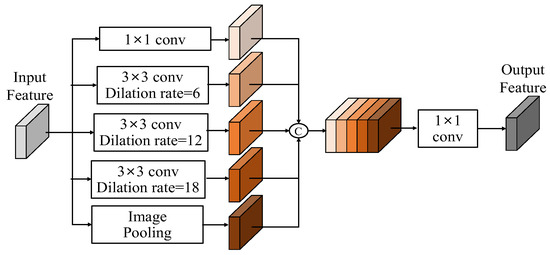
Figure 2.
Architecture of Atrous spatial pyramid pooling.
2.3. Selective Feature Fusion
To effectively fuse the skip connection features, GLPDepth [17] utilizes a selective feature fusion (SFF) module to achieve high-quality depth, as shown in Figure 3. Instead of element-wise summation of skip-connected encoder and decoder features, the SFF module offers improved fusion capabilities. It is noted that the skip connection feature Fc and the decoder feature Fd have the size of C × H × W. They are first concatenated along the channel dimension and then passed through two layers of 3 × 3 convolution, batch normalization, and ReLU and finally through a 3 × 3 convolution layer to reduce the number of channels to two, and undergo sigmoid activation function to obtain two separate attention maps, Ac and Ad. By performing element-wise multiplications of Fc to Ac and Fd to Ad, these weighted features after the element-wise summation construct the final fused feature Ff.
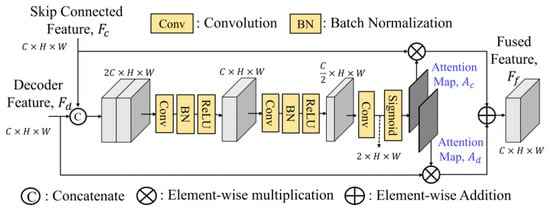
Figure 3.
Structure of selective feature fusion (SFF) module.
3. Proposed Methods
For monocular depth estimation, effectively combining the local information and the global features is an important challenge for the networks to estimate the depth map with exceptional quality. As shown in Figure 4, the basic framework of the proposed residual vision transformer and adaptive fusion (RVTAF) depth estimation network consists of a CNN-ViT encoder and an adaptive fusion decoder. The CNN-ViT encoder is further composed of a CNN feature extractor mixed with several ViT modules in residual configurations to extract local and global features, while the multiple-level features are skip-connected to fuse the feature of the decoder to achieve high-quality depth estimation. In the RVTAF depth estimation network, we need to identify a better residual configuration of vision transformers to successfully expand the receptive field of the bottleneck feature. We also need to design an effective adaptive fusion module to further enhance the precision of the estimation. A detailed explanation of the CNN-ViT encoder and adaptive fusion decoder is present in the following two subsections.
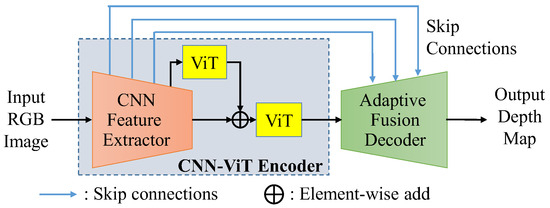
Figure 4.
Basic framework of the proposed RVTAF depth estimation network.
3.1. CNN¬-ViT Encoder
The detailed structure of the final CNN_ViT encoder, which is shown in Figure 5, mainly contains subsampled residual blocks (SRBs) and residual blocks (RBs) to extract 3 intermediate features, F1, F2, F3, and the final bottleneck feature Fo with a size of 512 × H/16 × W/16. Through experiments, the proposed CNN-ViT encoder incorporates vision transformers (ViTs), which are marked in yellow color, and will be further discussed in the subsequent sections. Inspired by ResNet50 [12], the backbone is constructed by two different building blocks to become the CNN feature extractor. In a formulation, the CNN-ViT encoder with the input of the image, I, and outputs of F1, F2, F3 can be expressed as follows:
where the front CNN part of the encoder can be mainly expressed by several subsampled residual blocks (SRBs) and residual blocks (RBs). Thus, the computation of intermediate skip features can be further given as follows:
and the final output with ViT stages is given as follows:
where the numbers behind the RB and ViT functions denote the repeated number of the modules. The detailed structures of the subsampled residual block (SRB) and residual block (RB), and the vision transformer (ViT) are shown in the following three subsections.
{F1, F2, F2, Fo} = CNN-ViT(I)
F1 = RB2(SRB(I)), F2 = RB3(SRB(F1)), F3 = RB5(SRB(F2))
F0 = ViT3(SRB(F4)) with F4 = RB2(SRB(F3)) + ViT2(SRB(F3))
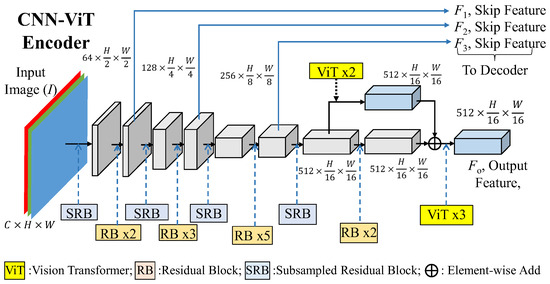
Figure 5.
Detailed structure of the final CNN-ViT encoder.
3.1.1. Subsampled Residual Block
As shown in Figure 6, the subsampled residual block (SRB) has two branches, where the lower branch first projects the input feature to a lower dimension space by 1 × 1 convolution (Conv1) to reduce the number of channels by half. Then, the spatial information is further down-sampled through a 3 × 3 convolution with stride 2, i.e., Conv3_s2, and finally the features are projected to twice dimension of the input feature with 1 × 1 convolution. The upper branch first uses a max-pooling operation to downsize the spatial information by half, followed by a 1 × 1 convolution (Conv1) to double the channel number. Finally, the features from these two branches are combined through element-wise summation to obtain the output SRB feature. The height and width of the input feature (C × H × W) are reduced to half while the channel number is increased twice for the output feature (2C × H/2 × W/2). In formulation expression, the SBR module with the input feature fi and the output feature fi+1 can be expressed as follows:
where the upper and bottom parts of SRB module are, respectively given as follows:
and
fi+1 = SRB(Fi)) = ReLU{SRBU(fi) + SRBB(fi)}
SRBU(fi) = Conv1(Maxpool(fi))
SRBB(fi) = BN(Conv1(ReLU(BN(Conv3_s2(Relu(BN(Conv1(fi))))))
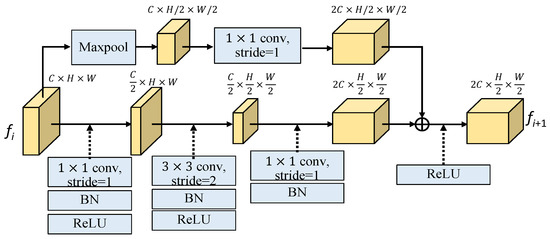
Figure 6.
The structure of the subsampled residual block (SRB).
3.1.2. Residual Block
As shown in Figure 7, the residual block (RB) employs a 1 × 1 convolution to reduce the dimension of the input feature by half. Once the feature is projected into the low-dimensional space, we utilize a 3 × 3 convolution with a stride of 1, i.e., Conv3, to capture spatial information. Following that, a 1 × 1 convolution (Conv1) is used to adjust the dimension to match that of the input feature. Finally, we combine the learned feature with the input feature through element-wise summation. The output feature of the residual block (RB) maintains the same feature size as the input feature. In formulation expression, the RB module with input feature fi and output feature fi+1 can be expressed as follows:
fi+1 = fi + BN(Conv1(ReLU(BN(Conv3(ReLU(BN(Conv1(fi))))))))
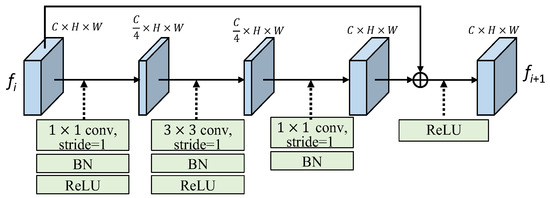
Figure 7.
The structure of the residual block (RB).
3.1.3. Vision Transformers in CNN-ViT
The flow chart of the realized vision transformer is shown in Figure 8. The input feature map, f, is segmented into patches with a size of p × p, where we set p = 5, to obtain N = HW/p patches. These patches are flattened into vectors, followed by a 1 × 1 convolution to adjust the length of vectors from C to Cvit. We call the ith adjusted vector “the ith token”, ti, which has the size of Cvit × 1 × 1. After the preparation of the inputs for vision transformer, these tokens are sent into the vision transformer, which is shown in Figure 1b, to learn global information. The vision transformer first maps the ith token ti into query (qi), key (ki) and values (vi) as follows
where Wq, Wk and Wv, respectively, denote the linear transformations for queries, keys and values. Let the initial patch matrix as z0 = [t1, t2, …., tN]; the jth iteration of multi-head self-attention (MSA) is shown as follows:
where Q = {q1, q2, …, qN}, K = {k1, k2, …, kN} and V = {v1, v2, …, vN}. As shown in Figure 6, the n-iteration vision transformer can be expressed as follows:
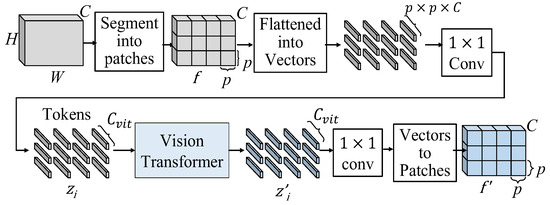
Figure 8.
Flow chart of the realized vision transformer.
In (2), the ViT2 and ViT3 functions perform n = 2 and n = 3 iterations of the vision transformer process defined in (9)–(11), respectively.
After the vision transformer, the patch embeddings, which have the size of Mvit × 1 × 1, learn a lot of global information. We deploy a 1 × 1 convolution to adjust the lengths of the learned patch embeddings from Cvit to p × p × C. Then, as the flattened procedure, we reverse the process and restore the learned patch embeddings back to their original C × H × W size.
There are many ways to insert the vision transformers (ViTs) into the CNN encoder. Initially, we attempted to insert vision transformers into the feature extraction pipeline in sequential manners; however, we found that the series configurations cannot improve the quality of depth estimation. To mitigate the impact of computation, we should not put the vision transformers in the shallow layers. Thus, we proposed a general residual layout of the vision transformers into the CNN feature extractor as shown in Figure 9, where we mark five positions (Position 1, Position 2, …., Position 5) for adding (n1, n2…., n5) ViTs, respectively. With the limitation of 5 ViTs, i.e., n1 + n2 + n3 + n4 + n5 = 5 for the consideration of reasonable computation complexity, we determine a better configuration of these five residual ViTs in the CNN network through the experiments detailed in Section 4.
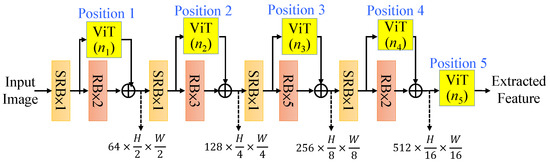
Figure 9.
The depicted positions for inserting the residual vision transformers.
3.2. Adaptive Fusion Decoder
To achieve a good decoder, we believe that feature fusion of skip connections will be the crucial design to achieve an effective autoencoder. The decoder layer could refer to the detailed information of the encoder, which progressively extracts layer features with a global scope. Consequently, effectively integrating the skip connection feature extracted from the encoder with the decoded feature returned by the decoder becomes an indispensable concern. The structure of the adaptive fusion decoder as shown in Figure 10 is composed of up-conversion (Upconv) blocks, fusion modules (FMs) and a Deep ASSP module. In formulation expressions, the adaptive fusion decoder, whose inputs are the connected features F1, F2, F2 and the encoder output features, Fo, finally estimates the estimation depth as follows:
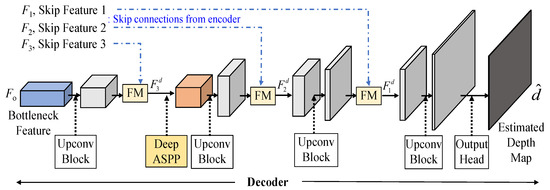
Figure 10.
The structure of the proposed adaptive fusion decoder in the proposed RVTAF depth estimation network.
To fuse the connected features one-by-one, the above AFdecoder process can be further decomposed into the following processes as follows:
The detailed descriptions of fusion modules (FMs), up-conversion (Upconv) block, and Deep ASSP module will be explained in the following subsections.
3.2.1. Fusion Modules
There are many ways to fuse two features together. To improve the SFF module [16], we suggest three variants of the fusion module (FM), namely, separate enhancement addition fusion module (SEAFM), separate enhancement concatenation fusion module (SECFM) and adaptive fusion module (AFM). We believe that the connected feature Fc and the decoded feature Fd have their distinct feature characteristics, which implies that their attention maps Ac and Ad cannot be generated using the same set of weights and need to be extracted separately. The fusion module (FM) performs the fusion process as follows:
where denotes the element-by-element multiply operator. To find the attention maps, the detailed explanations of these three fusion modules are presented as follows.
- A.
- Separate Enhancement Addition Fusion Module
As shown in Figure 11, the separate enhancement addition fusion module (SEAFM) independently enhances the two input features. Comparing to Figure 3, the skip connection feature branch and the decoded feature branch undergo two sequential 3 × 3 convolution-batch normalization-ReLU layers to reduce the number of channels to one-fourth of the original.
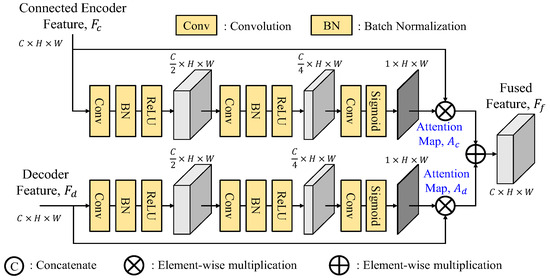
Figure 11.
Structure of separate enhancement addition fusion module (SEAFM).
- B.
- Separate Enhancement Concatenation Fusion Module
As shown in Figure 12, the separate enhancement concatenation fusion module (SECFM) is a modified version of the SEAFM by replacing the addition operation of the SEAFM with the concatenation operation of two weighted features, which are then further processed by a 3 × 3 convolution, batch normalization and ReLU operations. As expected, the element-wise summation in the SEAFM is slightly more efficient and requires fewer parameters than the concatenation in the SECFM.
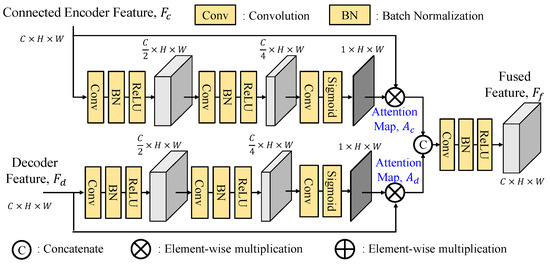
Figure 12.
Architecture of separate enhancement concatenation fusion module (SECFM).
- C.
- Adaptive Fusion Module
As shown in Figure 13, the adaptive fusion module (AFM) first concatenates the skip connection feature and the decoded feature before being split into two branches for attention map generations. This approach ensures that both branches access the information from two features, thereby enhancing the generation process with more comprehensive and integrated information. By incorporating this strategy, the attention maps Ac and Ad can effectively prioritize crucial information from both features, leading to a better improved performance. It is noted that the SEAFM, which independently generates two attention maps, lacks the knowledge of the information present in the input features. The adaptive fusion module with a better reference of them through the first concatenation can adaptively generate better attention maps.
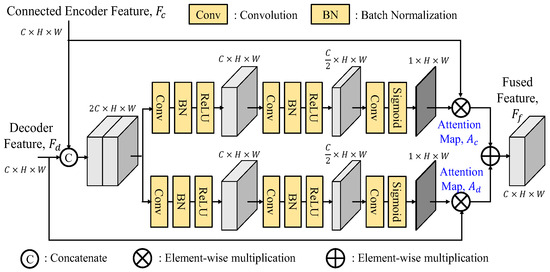
Figure 13.
Architecture of adaptive fusion module (AFM).
3.2.2. Up-Convolution Module
We deploy up-convolution (Upconv) blocks to increase the width and height of the decoded feature and fused features while reducing the number of channels. This step ensures that the feature not only matches the input size of the subsequent AFM but also enhances the precision of spatial information in the up-sampled feature. The architecture of the up-convolution block is shown in Figure 14. The input feature of the up-convolution block will first up-sample to double its width and height, and then pass through a layer of 3 × 3 convolution-batch normalization-ReLU for enhancing the spatial information. In (13–15), the Upconv function is given as follows:
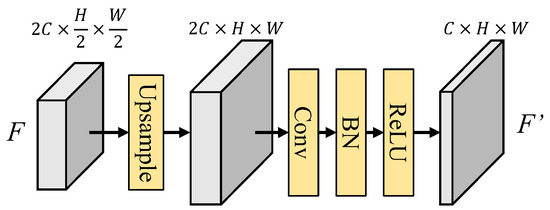
Figure 14.
Architecture of up-convolution block.
3.2.3. Deep ASPP Module
When the dilation rate exceeds the width and height of the feature, dilated convolution behaves similarly to a 1 × 1 convolution. Consequently, the output of certain branches in the ASPP module cannot extend the receptive field. To improve Atrous spatial pyramid pooling (ASPP) [29,30], we deploy the Deep ASPP [31], which was used for the segmentation task, to help the model to expand its receptive field of the feature. Unlike the original ASPP, the Deep ASPP possesses a wider receptive field, and prevents the degradation of Atrous convolution kernels with high dilated rates into 1 × 1 convolution. We use the Deep ASPP module after the first fusion module (FM), as shown in Figure 10. The architecture of the Deep ASPP module is shown in Figure 15; thus, the DeepASPP function in (14), based on Figure 15, can be expressed as follows:
where
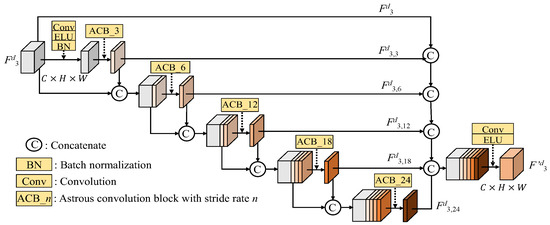
Figure 15.
The architecture of the Deep ASPP.
3.3. Training Loss Function
In order to calculate the distance between the predicted depth map and the ground truth depth map D, we use a scale-invariant log loss [18] to train the proposed network. The training loss function is given as follows:
with yi measuring the loss of the ith log depth as follows:
where and represent the ground truth depth and predicted depth of the ith pixel, respectively. In (1), the loss function is calculated with square-mean minus mean-square, known as the variance when α = 1. When α = 0, the loss function becomes an L2 loss. Here, we set α = 0.5 to train our network, as suggested in [18].
During the network training process, we normalize the ground truth depth values to a range between 0 and 1. This normalization allows the network to predict depth values within the same range during regression. By applying the logarithm function as shown in Figure 15 to the difference between two values ranging from 0 to 1, the error is effectively amplified, especially for low values. This amplification has a stronger impact on smaller ground truth depth values. As a result, our predicted depth map prioritizes the accurate prediction of foreground depth values. This amplification helps in improving the accuracy of our predicted depth values. It is important to highlight that during the training process with the KITTI dataset, we exclusively consider pixels where and for calculating the loss function. This approach is adopted because logarithms of depth values cannot be defined when the depth is 0. By focusing on non-zero depth values, we prevent difficulties that may arise during training.
4. Experimental Results
The proposed RVTAF depth estimation network is implemented by using Python 3.6 with Pytorch [32] 1.10.2. For hardware systems, we used a personal computer with Intel Core i7-7700K CPU (Santa Clara, CA, USA) and NVIDIA GeForce RTX 3070Ti 8G GPU (Santa Clara, CA, USA). To validate the effectiveness of our approach, we present several experimental results on challenging benchmarks that encompass diverse settings. Specifically, we provide experimental results on two famous benchmarks, which encompass both indoor and outdoor environments.
The NYU Depth V2 dataset [33] consists of 120 K image-depth pairs obtained from video sequences captured using a Microsoft Kinect (Redmond, WA, USA). The images have a size of 480 × 640 and are collected from 464 indoor scenes. For training our network, we utilize approximately 50 K training pairs obtained from random crops of size 416 × 544. We evaluate the performance of our approach on 654 testing pairs at full resolution. The depth maps have an upper bound of 10 m. The two selected image-depth pairs in the NYU Depth V2 dataset are shown in Figure 16.

Figure 16.
Two selected RGB color images and their corresponding depth maps in the NYU Depth V2 dataset.
Speaking of an outdoor scene, the KITTI dataset [34] is widely recognized in the field of depth estimation. The KITTI dataset comprises 61 scenes from various categories such as “city”, “residential”, “road”, and “campus”. To ensure fair comparisons with existing methods, we adopt the split proposed by Eigen et al. [18] for training and testing. Therefore, we evaluate our approach on a subset of 652 images across 29 scenes, while the remaining 32 scenes consisting of 23,488 images are used for training purposes. The RGB images have a resolution of approximately 376 × 1241, whereas the corresponding depth maps exhibit low density and contain numerous missing data points. Therefore, we calculate the loss function only for those of the depth map that have valid values. Two selected image–depth pairs in the KITTI dataset are shown in Figure 17. The images are uniformly cropped to a fixed size of 352 × 1216 at a specific position. Afterwards, we train our network using a random crop of size 352 × 704. During evaluation, we utilize the full resolution with the size of 352 × 1216.

Figure 17.
Two selected RGB color images and their corresponding depth maps in the KITTI dataset.
For performance evaluation, in this paper, we use three inlier metrics and root mean square error and absolute related error matrices, where are used by previous work:
The inlier matrices, denoting by δ1, δ2, and δ3, are defined as follows:
The root mean square error (RMSE) is defined as:
The absolute relative error (AbsRel) is defined as:
where T denotes a collection of pixels that the ground truth values are available in and and represent the ground truth depth and predicted depth of the ith pixel, respectively.
To prevent overfitting during network training, we employ several data augmentation techniques. For both the KITTI dataset and the NYU Depth v2 dataset, we utilize random cropping. For the NYU Depth v2 dataset, we crop the images to a size of 416 × 544 during training and perform inference with the full-size images, which are 480 × 640. For the KITTI dataset, we crop the images to a size of 352 × 704 and perform inference with a size of 352 × 1216. Additionally, each image has a 50% chance of being horizontally flipped. We also apply random adjustments to the brightness, saturation, and hue of each image. These data augmentation methods introduce variability into the training set, effectively reducing the risk of overfitting.
For training, we utilize the Adam optimizer [35] with cosine decay. We adopt the one-cycle learning rate policy. The learning rate increases by applying linear warm-up from 1 × 10−5 to 1 × 10−4 for the first 10% of iterations followed by cosine decay to 3 × 10−5. The total number of epochs is set to 150, with a batch size of 6, except for the ablation study, which is trained for approximately 70 epochs.
4.1. CNN-ViT Encoder with Various ViT Configurations
First, we conducted intensive experiments to determine a better positioning of vision transformers (ViTs) combined into the CNN encoder shown in Figure 9; the most reasonable configurations are listed in Table 1. Hereafter for all tables, it is noted that the bold results mean the best achieved ones in each metric. To reduce the computation, we only test the patterns with more ViTs for the deeper-level features, which could achieve better results and less computation. Each configuration is denoted by five digits, n1 n2 n3 n4 n5, which represent the specific numbers of ViTs used in Positions 1, 2, 3, 4, 5, respectively, as illustrated in Figure 9. For the “00000” case, it is noted that no ViT modules are used; thus, the computation becomes the smallest. For “00131”, it is indicated that there are no ViTs in Positions 1 and 2, one ViT in Position 3, three ViTs in Position 4, and one ViT in Position 5. The simulation results show that, of the position indices, “01121” has the best estimation performance. However, we prefer to choose the position index “00023”, which achieves a quality near that of “01121” and has lower computation complexity. Thus, as shown in Figure 5, the proposed CNN-ViT encoder is used with the two residual ViTs in Position 4 and three ViTs in Position 5 to complete the RVTAF autoencoder for depth estimation.

Table 1.
Experiments of arrangements of ViTs evaluated on NYU V2 dataset Test 1449.
4.2. Adaptive Fusion Decoder with Various Fusion Modules
In the previous section, we provided a detailed introduction of the baseline method SFF [16] and three proposed fusion modules. Now, we conduct the comparative analyses of these fusion modules as the subsequent ablation study. To ensure a fair comparison of their performance, we utilized the same model architecture for all four fusion modules, only replacing the specific fusion component. The results in Table 2 clearly demonstrate that adaptive fusion module (AFM), which concatenates the skip connection feature and the decoded feature and generates attention maps through two separate branches, consistently outperforming the other fusion modules across all evaluation metrics. As expected, the AFM with concatenated data and separate branches requires a higher number of parameters. The AFM decoder is designed in the RVTAF autoencoder for depth estimation.
Table 2.
Experimental results with variations in fusion modules on NYU V2 testset 654.
4.3. Comparisons on NYU Depth V2 Dataset
In this experiment, we utilized the NYU Depth V2 test set, specifically 654 samples, to evaluate the performance of the three models. Table 3 clearly demonstrates that our proposed RVTAF depth estimation network outperforms the other two methods across all evaluation metrics. Figure 18 shows two test images and their ground truth depth maps. These two images contain particular glass windows and long-range targets. Figure 19 shows the visualization comparisons of depth estimation results comparing with the existing approaches. The proposed RVTAF depth estimation network in all figures achieves better depth results than the BTS [30] and GLPDepth [17] methods in the NYU Depth V2 dataset. The proposed RVTAF method shows the δ1 accuracy metric with an improvement of about 28% and the RMSE with a reduction of about 27% compared to the GLPDepth method.
Table 3.
Comparison with existing approaches on NYU Depth V2 test set 654.

Figure 18.
Two selected images and their corresponding ground truth depth maps on the NYU Depth V2 dataset.

Figure 19.
Visualizations of depth estimation results obtained with the proposed RVTAF network and the existing approaches.
4.4. Comparisons on KITTI Dataset
In this experiment, we utilized the KITTI dataset Eigen split, which contains 652 testing images. In Table 4, it is evident that our proposed RVTAF network surpasses GLPDepth in all metrics, particularly in the δ1 metric, where the proposed RVTAF network demonstrates similar performance, with a slight edge over the BTS.
Table 4.
Comparisons the proposed RVTAF depth network and the existing approaches on KITTI dataset Eigen split.
Figure 20 shows visualization comparisons of the depth estimation results achieved by the proposed and the existing approaches in the KITTI dataset. The proposed RVTAF network in the figures also exhibits better depth results than the BTS and GLPDepth methods.

Figure 20.
Visualization comparisons of the depth estimation achieved by the proposed RVTAF depth estimation network and the existing approaches on the KITTI dataset.
5. Conclusions
In this paper, we proposed a residual vision transformer and adaptive fusion (RVTAF) depth estimation network that is based on an autoencoder with skip connection architecture. In the proposed encoder, we suggest residual configurations of vision transformers (ViTS) to the CNN-based feature extractor achieve better performance. As for the proposed decoder, we introduce the adaptive fusion module (AFM) to effectively fuse the skip connected features from the encoder with the decoded feature, where the AFM generates two separate attention maps, allowing each feature to concentrate on specific spatial information. Additionally, we enhanced the decoder by incorporating a deep ASPP module to expand the effective receptive field of deep features. Ultimately, the proposed RVTAF depth estimation network is capable of accurately predicting depth maps from a single image. We conducted ablation studies to determine the best ViT configuration that uses less parameters and maintains the best performance for depth estimation and to evaluate the effectiveness of the proposed AFM. Subsequently, we compared our final network with the existing methods for both indoor scenes on the NYU Depth V2 dataset and outdoor scenes on the KITTI dataset Eigen split. In the case of indoor scenes, our method achieves sharper boundaries and more accurate depth values. Additionally, our network successfully captures depth information from traffic signs and vehicles in the KITTI dataset. Overall, the experimental results demonstrate that our method is competitive with the current methods. With the introduction of ViTs, the computation of the proposed method is slightly increased for depth estimation. The simplified ViT could be considered to promote real applications in the future.
Author Contributions
Conceptualization, W.-J.Y., C.-C.W. and J.-F.Y.; methodology, W.-J.Y.; software, C.-C.W.; validation, W.-J.Y., C.-C.W. and J.-F.Y.; formal analysis, W.-J.Y.; investigation, W.-J.Y.; resources, W.-J.Y.; data curation, W.-J.Y. and C.-C.W.; writing—original draft preparation, C.-C.W. and W.-J.Y.; writing—review and editing, W.-J.Y. and J.-F.Y.; visualization, W.-J.Y.; supervision, W.-J.Y.; project administration, W.-J.Y.; funding acquisition, W.-J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science and Technology Council, Taiwan under Grant: NSTC 113-2221-E-006-158.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The authors use KITTI dataset in [28] and the NYU Depth v2 dataset in [24] for all simulations.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Fabrizio, F.; De Luca, A. Real-time computation of distance to dynamic obstacles with multiple depth sensors. IEEE Robot. Autom. Lett. 2017, 2, 56–63. [Google Scholar] [CrossRef]
- Natan, O.; Miura, J. End-to-end autonomous driving with semantic depth cloud mapping and multi-agent. IEEE Trans. Intell. Veh. 2023, 8, 557–571. [Google Scholar] [CrossRef]
- Kauff, P.; Atzpadin, N.; Fehn, C.; Müller, M.; Schreer, O.; Smolic, A.; Tanger, R. Depth map creation and image-based rendering for advanced 3DTV services providing interoperability and scalability. Signal Process. Image Commun. 2007, 22, 217–234. [Google Scholar] [CrossRef]
- Gordon, G.G. Face recognition based on depth maps and surface curvature. In Proceedings of the SPIE 1570, Geometric Methods in Computer Vision, San Diego, CA, USA, 1 September 1991. [Google Scholar] [CrossRef]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning depth-guided convolutions for monocular 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 1000–1001. [Google Scholar]
- Zhang, C.; Wang, L.; Yang, R. Semantic segmentation of urban scenes using dense depth maps, ECCV 2010. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314. [Google Scholar] [CrossRef]
- Žbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Pang, J.; Sun, W.; Ren, J.; Yang, C.; Yang, Q.; Yan, Q. Cascade residual learning: A two-stage convolutional neural network for stereo matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 878–886. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular Depth Estimation Using Deep Learning: A Review. Sensors 2021, 22, 5353. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Ka, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-local path networks for monocular depth estimation with vertical cutdepth. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semi-supervised deep learning for monocular depth map prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar]
- Yang, W.-J.; Tsung, W.-N.; Chung, P.-C. Video-based depth estimation autoencoder with weighted temporal feature and spatial edge guided modules. IEEE Trans. Artif. Intell. 2024, 5, 613–623. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Al Dayil, R.; Al Ajlan, N. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Yang, J.; An, L.; Dixit, A.; Koo, J.; Park, S.I. Depth estimation with simplified transformer. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; Available online: https://arxiv.org/abs/2204.13791v3 (accessed on 28 May 2024).
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Agarwal, A.; Arora, C. Depthformer: Multiscale Vision Transformer for Monocular Depth Estimation with Global Local Information Fusion. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3873–3877. [Google Scholar]
- Zhu, X.; Han, Z.; Zhang, Z.; Song, L.; Wang, H.; Guo, Q. PCTNet: Depth estimation from single structured light image with a parallel CNN-transformer network. Meas. Sci. Technol. 2023, 34, 085402. [Google Scholar] [CrossRef]
- Zhang, Z.; Chan, R.K.; Wong, K.K. GlocalFuse-Depth: Fusing transformers and CNNs for all-day self-supervised monocular depth estimation. Neurocomputing 2024, 569, 127122. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2021, arXiv:1907.10326v5. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 14 December 2019; Volume 32. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Kingma, D.P. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).