

Cockpit-Llama: Driver Intent Prediction in Intelligent Cockpit via Large Language Model

 , , , , and
, , , , and
Abstract
1. Introduction
2. Related Works
2.1. Intelligent Cockpit Intent Prediction
2.2. Large Language Models
3. Methodology
3.1. Multi-Attribute Cockpit Dataset Construction
3.1.1. Sensor Data Pre-Processing
3.1.2. Data Augmentation
- State Attribute to Behavior Attribute Transformation. The existing behavior attributes mainly reflect the driver’s usage of cockpit infotainment systems, such as radio, music, calls, navigation, and functional settings, lacking the capture of behaviors like air conditioning adjustment, door operations, window adjustment, and seat adjustment. To capture these behaviors, we construct a state-to-behavior attribute transformation algorithm, . The specific process of transforming seat status into behavior is detailed in Algorithm 1. First, the algorithm initializes the sensor data at the current time and the sensor data at the previous time (line 1). Then it traverses all state data and uses the state-to-behavior function from the toolkit to extract the corresponding seat heating states and from the sensor data at present time and the sensor data at previous time (lines 2 to 3). The value of can be 0, 1, 2, or 3, representing seat heating off, level one, level two, and level three heating, respectively. Then, further judge and , when and are different, return the corresponding behavior value (lines 4 to 20). By analyzing the transformation of various state information within the cockpit through this algorithm, driver behaviors can be inferred, enriching the behavior data.
- Behavior Attribute to State Attribute Transformation. Similar to the transformation from state attributes to behavior attributes, the existing state attributes are mainly limited to vehicle driving states and vehicle body states, lacking descriptions of the in-cabin device states, which can be inferred from behavior attributes. For instance, behaviors such as starting music playback indicate that the music state is on, while pausing music playback or ending the driving journey represents the music state being off. Therefore, when capturing the driver’s behavior of starting music playback, it can be transformed into the action of turning on the music player. Similarly, when capturing the driver’s behavior of stopping music playback, other common state attributes that can be inferred include radio, phone, and navigation driving scenes. The specific construction method is detailed in Algorithm 2. First, initialize the detected driver behavior H (line 1), then traverse all the behavior data H to extract multimedia-related behaviors (lines 2 to 3). Next, judge the corresponding value of and return the state corresponding to (lines 4 to 16). Algorithm 2 can convert cockpit behavior attributes into state attributes. By analyzing driver behavior data, the usage status of these devices can be inferred, enriching the state attributes.
| Algorithm 1 Seat heating state to action algorithm |
| Input: present sensor data , previous sensor data Output: The Action
|
| Algorithm 2 Action to state algorithm |
| Input: Action data H Output: State
|
3.1.3. Dataset Text Generation
- Multimedia states include music playback status, radio playback status, and navigation status:
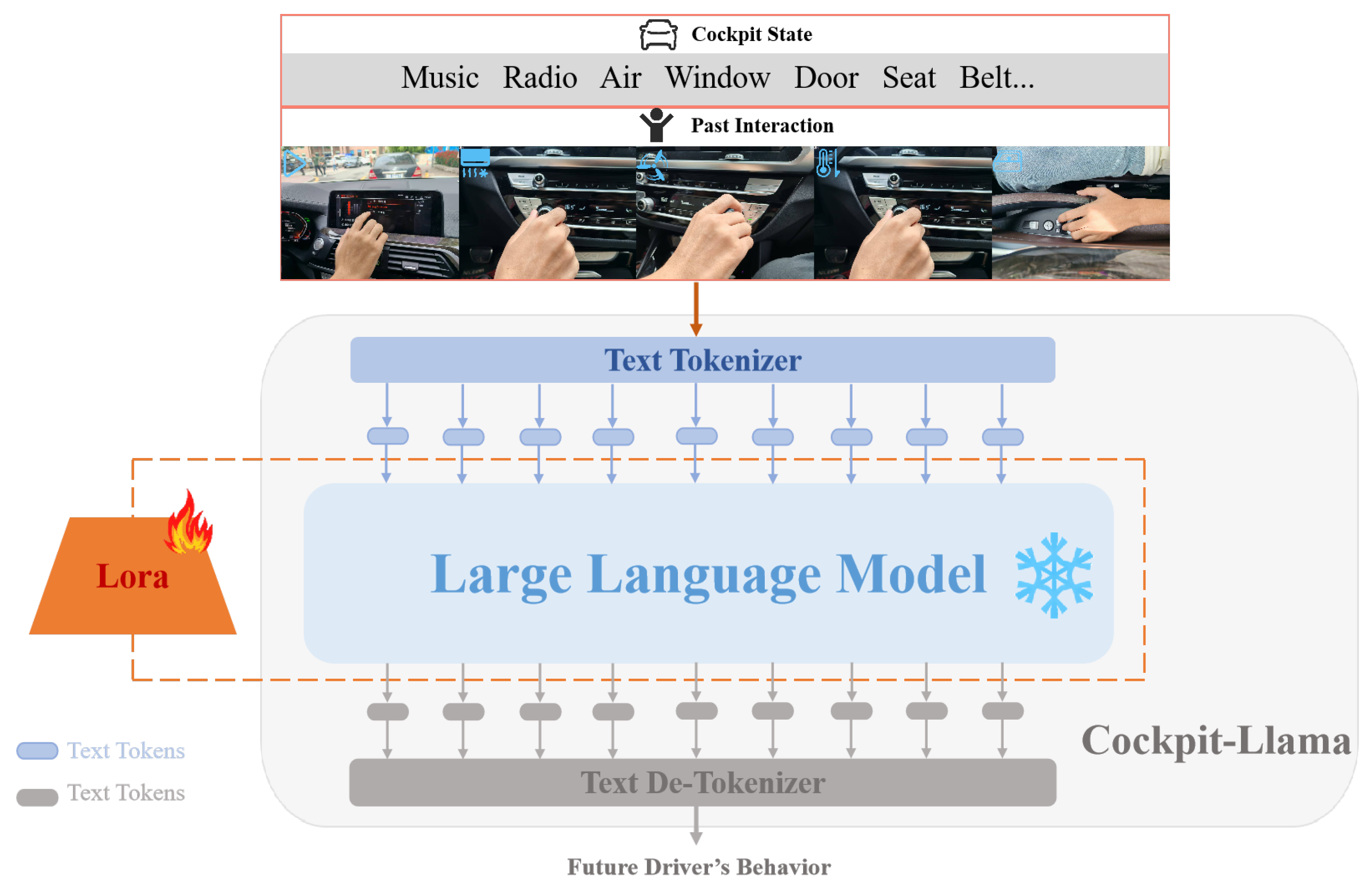
3.2. Cockpit-Llama Model Architecture Design
3.2.1. Modal Text Data Encoding
3.2.2. Lightweight Fine-Tuning of LLM Backbone Using Adapters
3.2.3. Driver Behavior Intent Decoding
3.3. Model Fine-Tuning Strategy
4. Experiment
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Evaluation Metrics
4.2. Comparison with Baseline Methods
4.3. In-Context Learning and Freeze vs. Cockpit-Llama (LoRA)
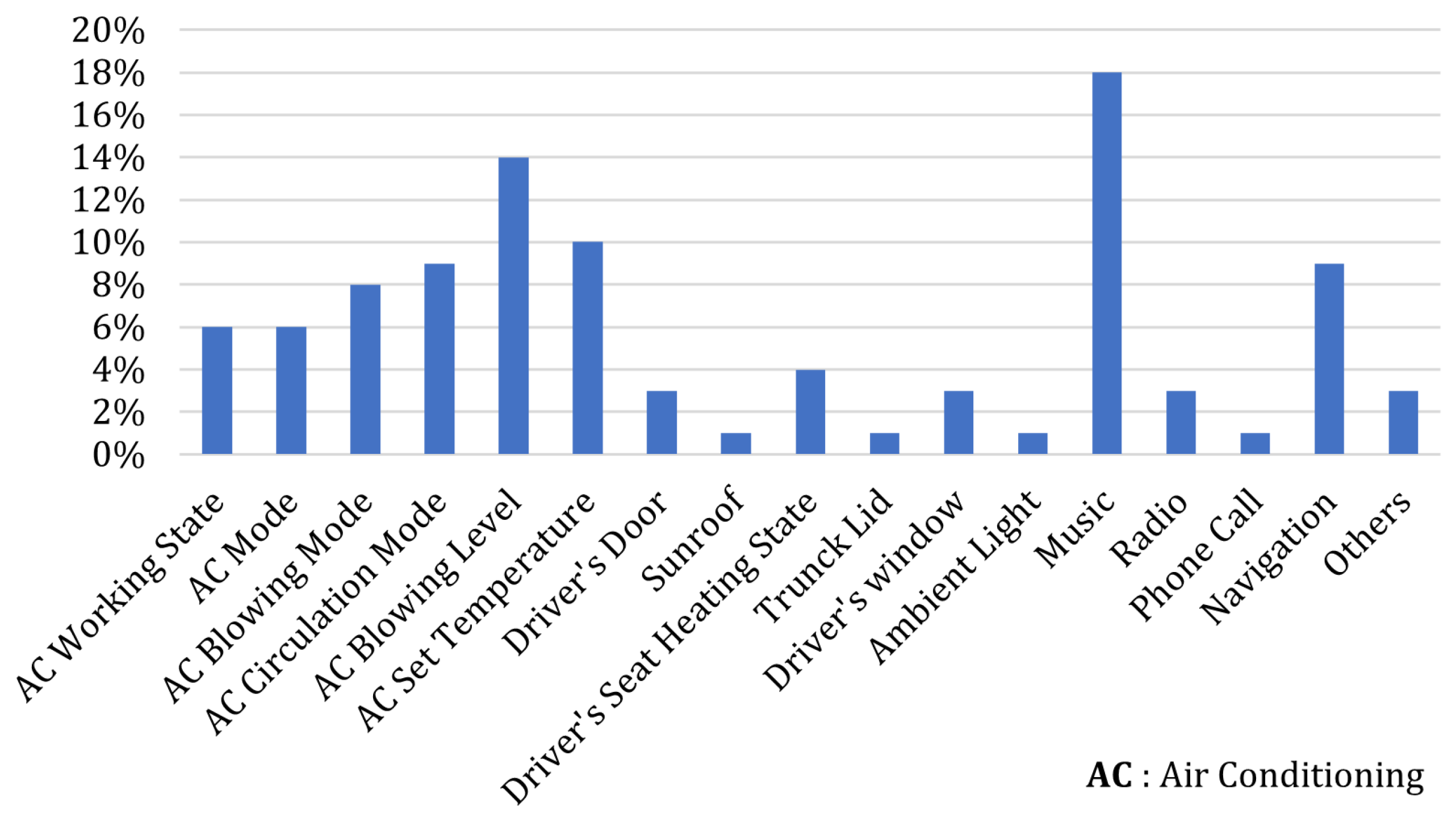
4.4. Dataset Analysis and Visualization
5. Conclusions
- Limitations and Future Work: Due to the limited size of the dataset, only about 60,000 samples were used to fine-tune Cockpit-Llama, and the inference time is relatively long due to the constraints of parameter size, making it challenging to meet the real-time requirements of commercial driving applications. Additionally, the current model may not fully capture the complexity of driver behavior and the various influencing factors. Future work should focus on constructing larger-scale datasets aiming to provide prior knowledge for the model. It should also explore using large language models to guide smaller ones to optimize inference time. Furthermore, integrating real-time data and additional contextual variables could further enhance the model’s predictive accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, W.; Cao, D.; Tan, R.; Shi, T.; Gao, Z.; Ma, J.; Guo, G.; Hu, H.; Feng, J.; Wang, L. Intelligent cockpit for intelligent connected vehicles: Definition, taxonomy, technology and evaluation. IEEE Trans. Intell. Veh. 2023, 9, 3140–3153. [Google Scholar] [CrossRef]
- Sun, X.; Chen, H.; Shi, J.; Guo, W.; Li, J. From hmi to hri: Human-vehicle interaction design for smart cockpit. In Proceedings of the Human-Computer Interaction. Interaction in Context: 20th International Conference, HCI International 2018, Las Vegas, NV, USA, 15–20 July 2018; Proceedings, Part II 20. Springer: Cham, Switzerland, 2018; pp. 440–454. [Google Scholar]
- Son, Y.S.; Kim, W.; Lee, S.H.; Chung, C.C. Robust multirate control scheme with predictive virtual lanes for lane-keeping system of autonomous highway driving. IEEE Trans. Veh. Technol. 2014, 64, 3378–3391. [Google Scholar] [CrossRef]
- Rosekind, M.R.; Gander, P.H.; Gregory, K.B.; Smith, R.M.; Miller, D.L.; Oyung, R.; Webbon, L.L.; Johnson, J.M. Managing fatigue in operational settings 1: Physiological considerations and counter-measures. Hosp. Top. 1997, 75, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Large, D.R.; Burnett, G.; Antrobus, V.; Skrypchuk, L. Driven to discussion: Engaging drivers in conversation with a digital assistant as a countermeasure to passive task-related fatigue. IET Intell. Transp. Syst. 2018, 12, 420–426. [Google Scholar] [CrossRef]
- Wong, P.N.; Brumby, D.P.; Babu, H.V.R.; Kobayashi, K. Voices in self-driving cars should be assertive to more quickly grab a distracted driver’s attention. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Utrecht, The Netherlands, 21–25 September 2019; pp. 165–176. [Google Scholar]
- Politis, I.; Langdon, P.; Adebayo, D.; Bradley, M.; Clarkson, P.J.; Skrypchuk, L.; Mouzakitis, A.; Eriksson, A.; Brown, J.W.; Revell, K.; et al. An evaluation of inclusive dialogue-based interfaces for the takeover of control in autonomous cars. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 601–606. [Google Scholar]
- Kaboli, M.; Long, A.; Cheng, G. Humanoids learn touch modalities identification via multi-modal robotic skin and robust tactile descriptors. Adv. Robot. 2015, 29, 1411–1425. [Google Scholar] [CrossRef]
- Kaboli, M.; Mittendorfer, P.; Hügel, V.; Cheng, G. Humanoids learn object properties from robust tactile feature descriptors via multi-modal artificial skin. In Proceedings of the 2014 IEEE-RAS International Conference on Humanoid Robots, Madrid, Spain, 18–20 November 2014; pp. 187–192. [Google Scholar]
- Kaboli, M.; Walker, R.; Cheng, G. In-hand object recognition via texture properties with robotic hands, artificial skin, and novel tactile descriptors. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Republic of Korea, 3–5 November 2015; pp. 1155–1160. [Google Scholar]
- Braun, A.; Neumann, S.; Schmidt, S.; Wichert, R.; Kuijper, A. Towards interactive car interiors: The active armrest. In Proceedings of the 8th Nordic Conference on Human-Computer Interaction: Fun, Fast, Foundational, Helsinki, Finland, 26–30 October 2014; pp. 911–914. [Google Scholar]
- Endres, C.; Schwartz, T.; Müller, C.A. Geremin 2D microgestures for drivers based on electric field sensing. In Proceedings of the 16th International Conference on Intelligent User Interfaces, Palo Alto, CA, USA, 13–16 February 2011; pp. 327–330. [Google Scholar]
- Pfleging, B.; Schneegass, S.; Schmidt, A. Multimodal interaction in the car: Combining speech and gestures on the steering wheel. In Proceedings of the 4th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Portsmouth, UK, 17–19 October 2012; pp. 155–162. [Google Scholar]
- Lee, S.H.; Yoon, S.O. User interface for in-vehicle systems with on-wheel finger spreading gestures and head-up displays. J. Comput. Des. Eng. 2020, 7, 700–721. [Google Scholar] [CrossRef]
- Li, B.; Cao, D.; Tang, S.; Zhang, T.; Dong, H.; Wang, Y.; Wang, F.Y. Sharing traffic priorities via cyber–physical–social intelligence: A lane-free autonomous intersection management method in metaverse. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 2025–2036. [Google Scholar] [CrossRef]
- Ma, Y.; Cao, Y.; Sun, J.; Pavone, M.; Xiao, C. Dolphins: Multimodal language model for driving. arXiv 2023, arXiv:2312.00438. [Google Scholar]
- Xu, Z.; Zhang, Y.; Xie, E.; Zhao, Z.; Guo, Y.; Wong, K.Y.K.; Li, Z.; Zhao, H. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robot. Autom. Lett. 2024, 9, 8186–8193. [Google Scholar] [CrossRef]
- Yuan, J.; Sun, S.; Omeiza, D.; Zhao, B.; Newman, P.; Kunze, L.; Gadd, M. Rag-driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model. arXiv 2024, arXiv:2402.10828. [Google Scholar]
- Zhang, W.; Zhang, H. Research on distracted driving identification of truck drivers based on simulated driving experiment. IOP Conf. Ser. Earth Environ. Sci. 2021, 638, 012039. [Google Scholar] [CrossRef]
- Tran, D.; Manh Do, H.; Sheng, W.; Bai, H.; Chowdhary, G. Real-time detection of distracted driving based on deep learning. IET Intell. Transp. Syst. 2018, 12, 1210–1219. [Google Scholar] [CrossRef]
- Fasanmade, A.; He, Y.; Al-Bayatti, A.H.; Morden, J.N.; Aliyu, S.O.; Alfakeeh, A.S.; Alsayed, A.O. A fuzzy-logic approach to dynamic bayesian severity level classification of driver distraction using image recognition. IEEE Access 2020, 8, 95197–95207. [Google Scholar] [CrossRef]
- Riaz, F.; Khadim, S.; Rauf, R.; Ahmad, M.; Jabbar, S.; Chaudhry, J. A validated fuzzy logic inspired driver distraction evaluation system for road safety using artificial human driver emotion. Comput. Netw. 2018, 143, 62–73. [Google Scholar] [CrossRef]
- Teyeb, I.; Snoun, A.; Jemai, O.; Zaied, M. Fuzzy logic decision support system for hypovigilance detection based on CNN feature extractor and WN classifier. J. Comput. Sci. 2018, 14, 1546–1564. [Google Scholar] [CrossRef]
- Xiao, H.; Li, W.; Zeng, G.; Wu, Y.; Xue, J.; Zhang, J.; Li, C.; Guo, G. On-road driver emotion recognition using facial expression. Appl. Sci. 2022, 12, 807. [Google Scholar] [CrossRef]
- Li, W.; Xue, J.; Tan, R.; Wang, C.; Deng, Z.; Li, S.; Guo, G.; Cao, D. Global-local-feature-fused driver speech emotion detection for intelligent cockpit in automated driving. IEEE Trans. Intell. Veh. 2023, 8, 2684–2697. [Google Scholar] [CrossRef]
- Oehl, M.; Siebert, F.W.; Tews, T.K.; Höger, R.; Pfister, H.R. Improving human-machine interaction–a non invasive approach to detect emotions in car drivers. In Proceedings of the Human-Computer Interaction. Towards Mobile and Intelligent Interaction Environments: 14th International Conference, HCI International 2011, Orlando, FL, USA, 9–14 July 2011; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2011; pp. 577–585. [Google Scholar]
- Hu, J.; Yang, B.; Song, H. Data-driven Prediction of Vehicle Air Conditioner Set Temperature. Mech. Sci. Technol. Aerosp. Eng. 2022, 41, 134–142. [Google Scholar] [CrossRef]
- Ferenc, G.; Timotijević, D.; Tanasijević, I.; Simić, D. Towards Enhanced Autonomous Driving Takeovers: Fuzzy Logic Perspective for Predicting Situational Awareness. Appl. Sci. 2024, 14, 5697. [Google Scholar] [CrossRef]
- Li, Y.; Metzner, M.; Schwieger, V. Driving environment inference from POI of navigation map: Fuzzy logic and machine learning approaches. Sensors 2023, 23, 9156. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; pp. 325–334. [Google Scholar]
- Mukhopadhyay, S.; Kumar, A.; Parashar, D.; Singh, M. Enhanced Music Recommendation Systems: A Comparative Study of Content-Based Filtering and K-Means Clustering Approaches. Rev. D’Intelligence Artif. 2024, 38, 365–376. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Leoni Aleman, F.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al.; OpenAI GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 11324–11436. [Google Scholar]
- Zheng, L.; Chiang, W.L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Adv. Neural Inf. Process. Syst. 2023, 36, 46595–46623. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Zhang, J.; Pu, J.; Xue, J.; Yang, M.; Xu, X.; Wang, X.; Wang, F.Y. HiVeGPT: Human-machine-augmented intelligent vehicles with generative pre-trained transformer. IEEE Trans. Intell. Veh. 2023, 8, 2027–2033. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Rojas, D.; Feng, G.; Zhao, H.; Lai, H.; Yu, H.; et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Evaluation | |||
|---|---|---|---|---|---|
| Bleu-4 | Rouge-1 | Rouge-2 | Rouge-L | ||
| ChatGPT-4 [33] | LLM | 37.08 | 28.21 | 39.32 | 27.03 |
| ChatGLM-3 [41] | LLM | 30.33 | 25.69 | 13.74 | 27.47 |
| Cockpit-Llama | LLM | 71.32 | 80.01 | 76.89 | 81.42 |
| Method | Evaluation | |||
|---|---|---|---|---|
| Bleu-4 | Rouge-1 | Rouge-2 | Rouge-L | |
| In-Context | 39.54 | 36.24 | 44.02 | 42.29 |
| Freeze | 46.88 | 49.45 | 54.32 | 50.80 |
| Cockpit (Lora) | 71.32 | 80.01 | 76.89 | 81.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, C.; Yuan, Q.; Li, J.; Fan, Y.; Ge, X.; Li, Y.; Gao, F.; Zhao, R. Cockpit-Llama: Driver Intent Prediction in Intelligent Cockpit via Large Language Model. Sensors 2025, 25, 64. https://doi.org/10.3390/s25010064
Chen Y, Li C, Yuan Q, Li J, Fan Y, Ge X, Li Y, Gao F, Zhao R. Cockpit-Llama: Driver Intent Prediction in Intelligent Cockpit via Large Language Model. Sensors. 2025; 25(1):64. https://doi.org/10.3390/s25010064
Chicago/Turabian StyleChen, Yi, Chengzhe Li, Qirui Yuan, Jinyu Li, Yuze Fan, Xiaojun Ge, Yun Li, Fei Gao, and Rui Zhao. 2025. "Cockpit-Llama: Driver Intent Prediction in Intelligent Cockpit via Large Language Model" Sensors 25, no. 1: 64. https://doi.org/10.3390/s25010064
APA StyleChen, Y., Li, C., Yuan, Q., Li, J., Fan, Y., Ge, X., Li, Y., Gao, F., & Zhao, R. (2025). Cockpit-Llama: Driver Intent Prediction in Intelligent Cockpit via Large Language Model. Sensors, 25(1), 64. https://doi.org/10.3390/s25010064