

A Comparison Study of Person Identification Using IR Array Sensors and LiDAR




Abstract
1. Introduction
1.1. Background
1.2. Motivations
1.3. Contribution
2. Related Work
3. Prelimiaries
3.1. IR Array Sensors
3.2. LiDAR
3.3. Deep Learning for Computer Vision
3.3.1. ViT
3.3.2. ResNet34
3.3.3. Attention Rollout
3.3.4. GradCAM
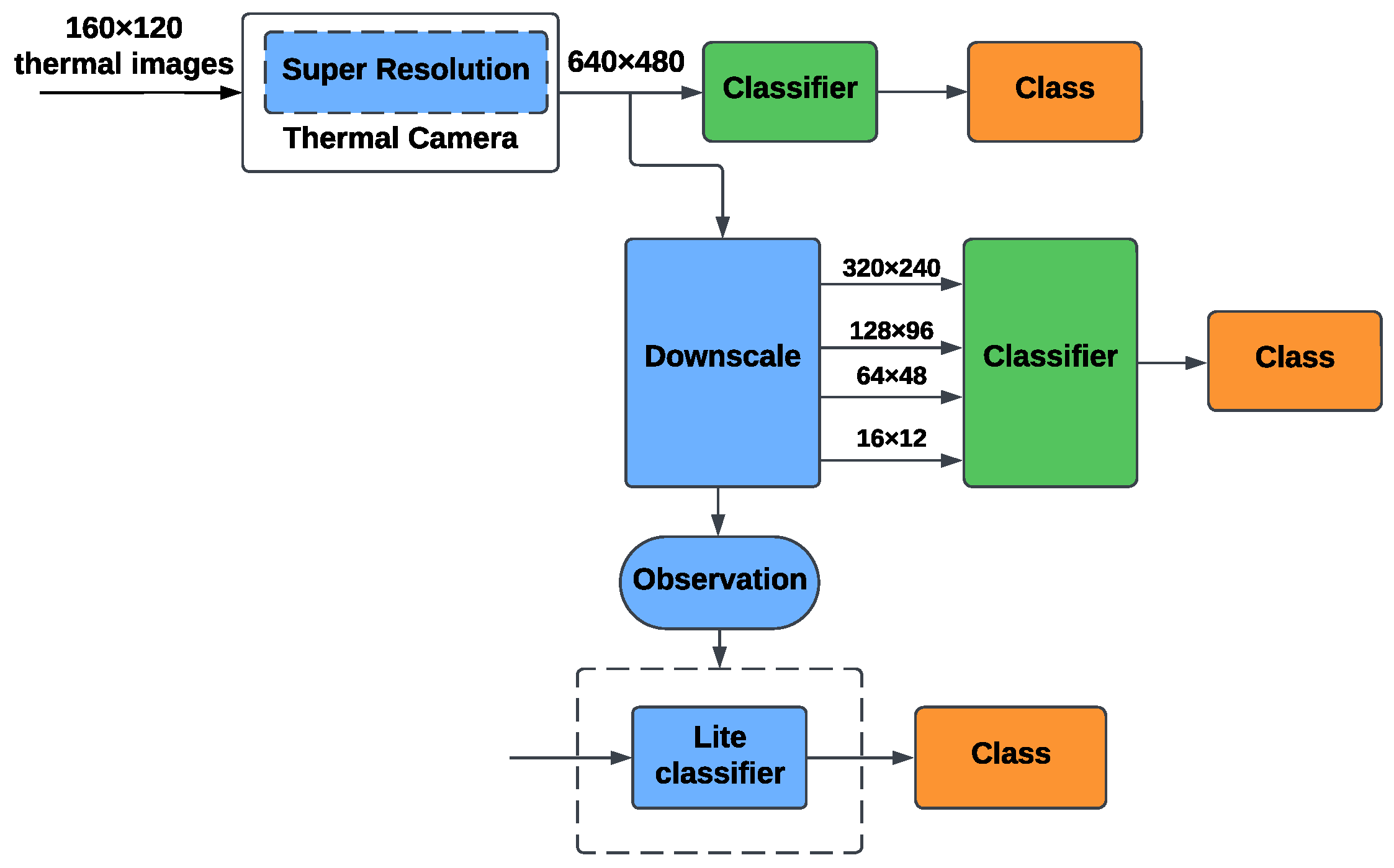
4. System Description and Setup
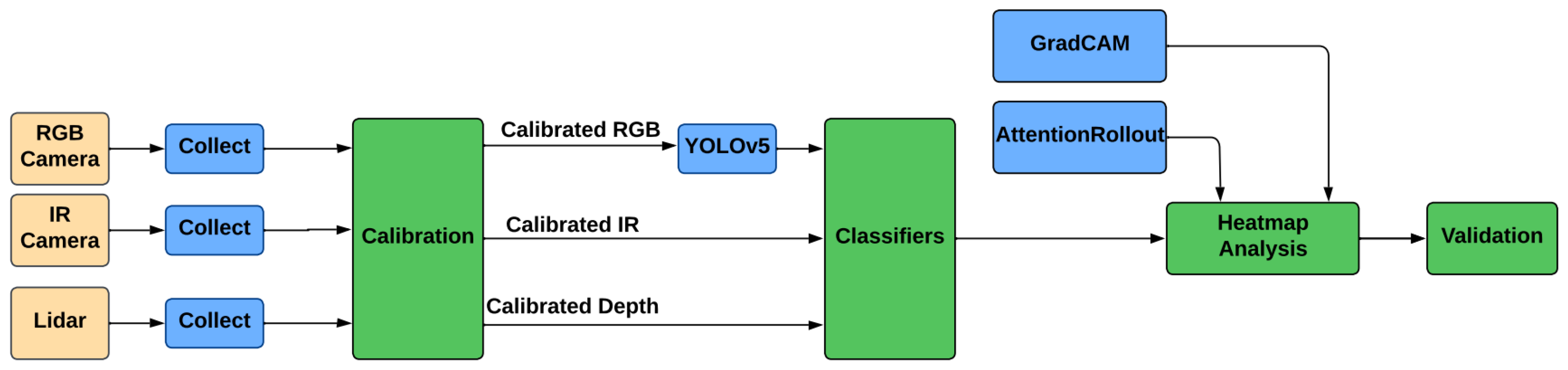
4.1. System Description
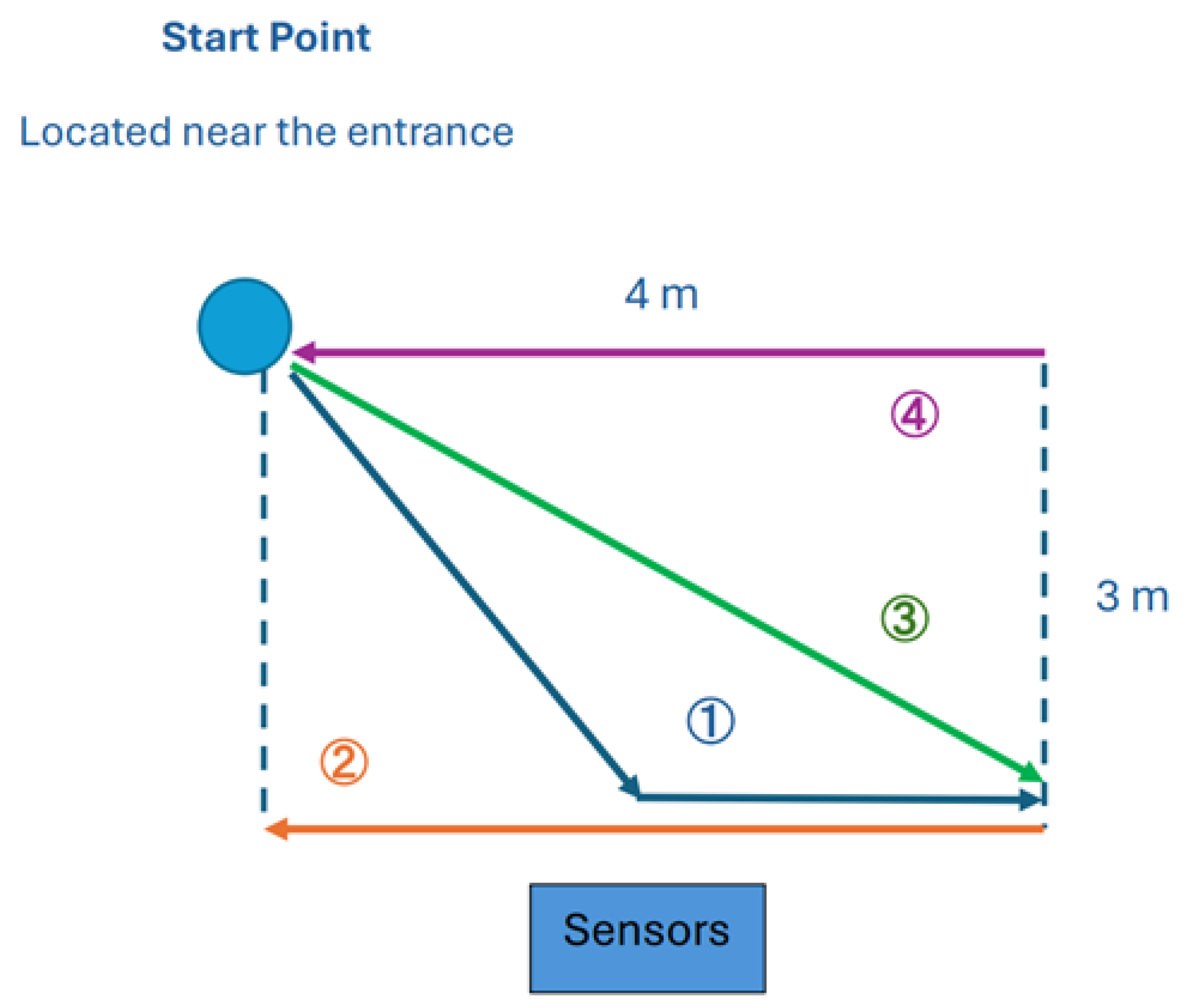
4.2. Setup
5. Proposed Method
5.1. Proposed Method Details
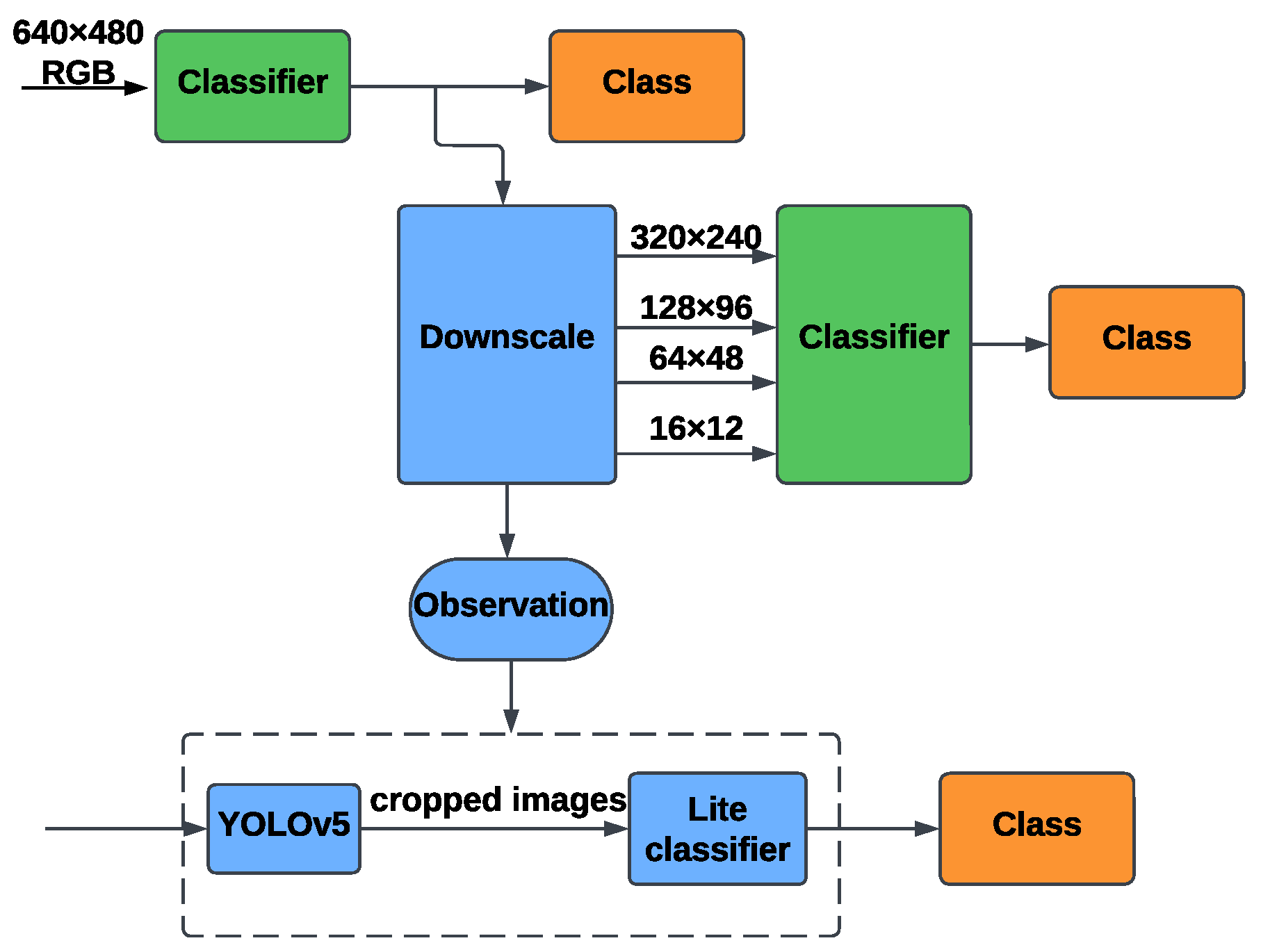
5.1.1. RGB-Based Identification
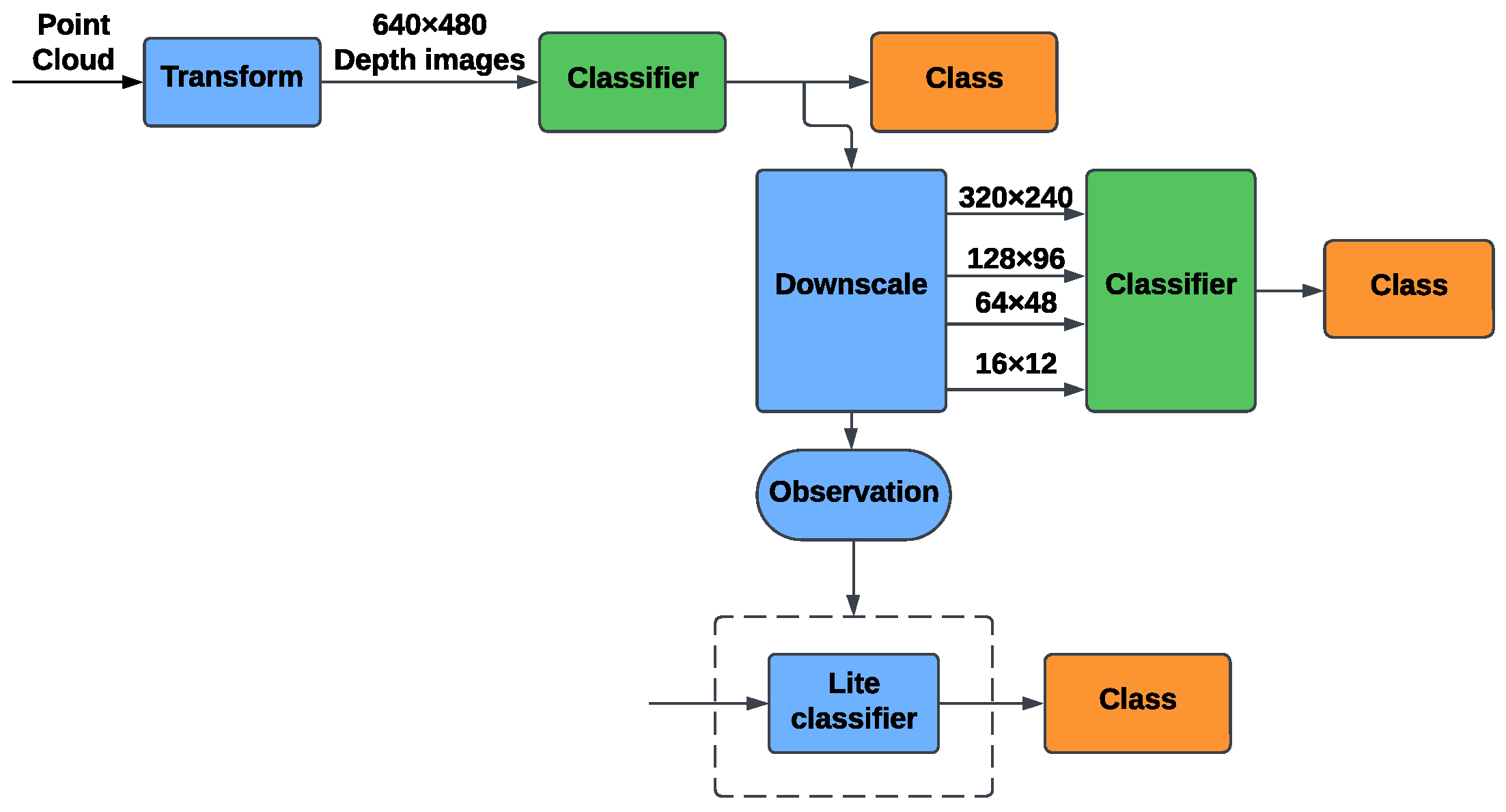
5.1.2. Depth-Based Identification
5.1.3. Thermal-Based Identification
5.2. Network Details
6. Experimental Results
6.1. Experimental Settings
6.1.1. Parameters
6.1.2. Data Set
6.1.3. Evaluation Metrics
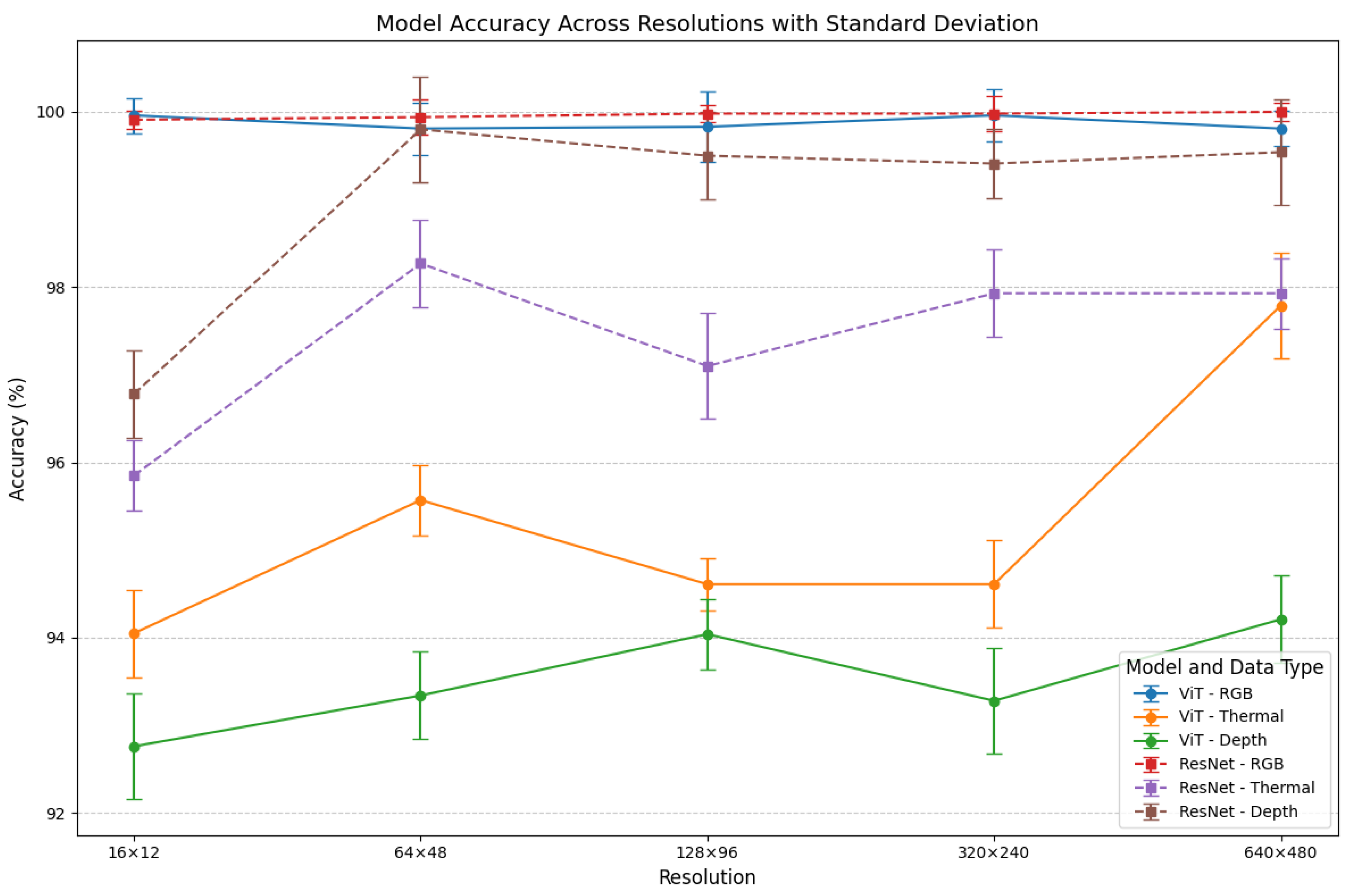
6.2. Experimental Results and Analysis
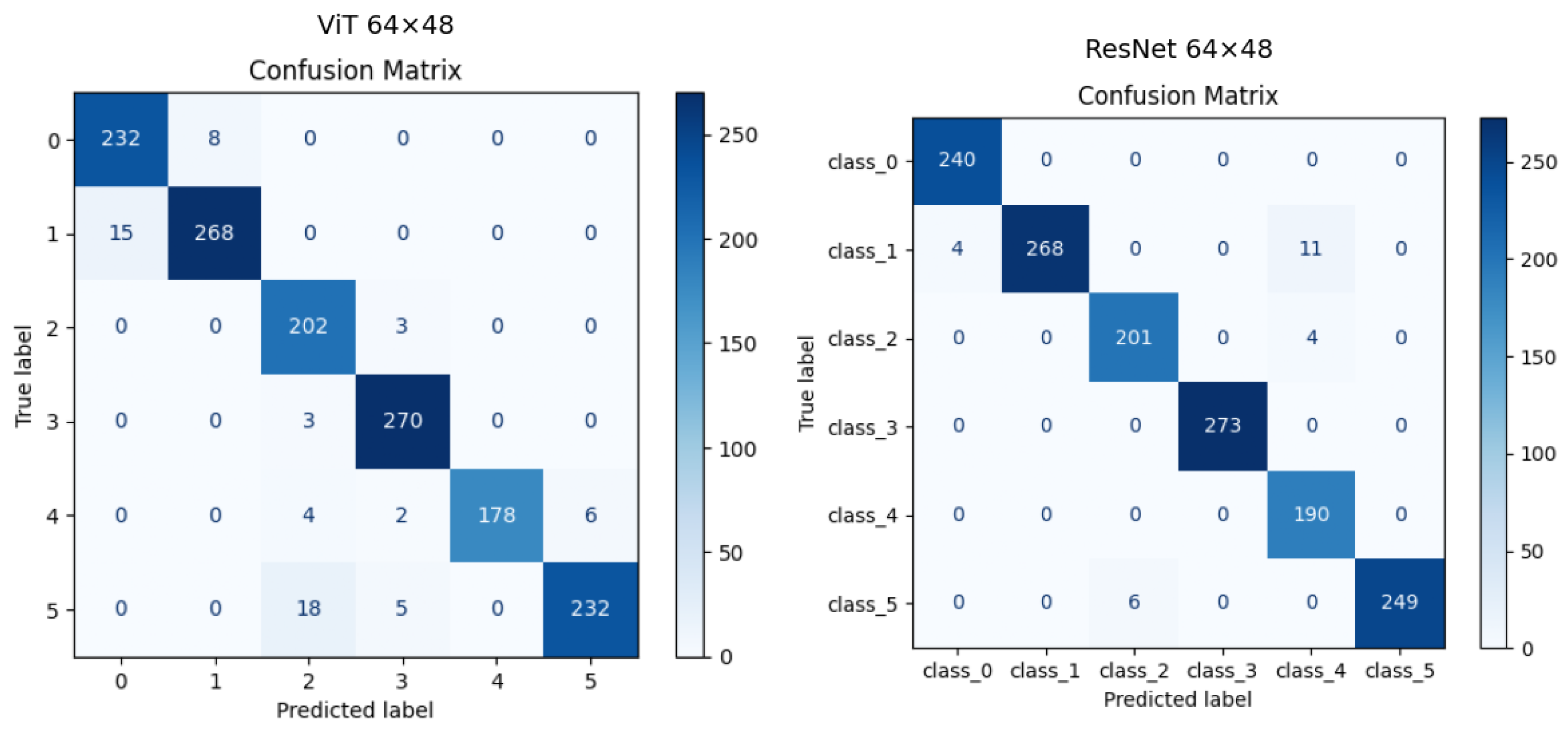
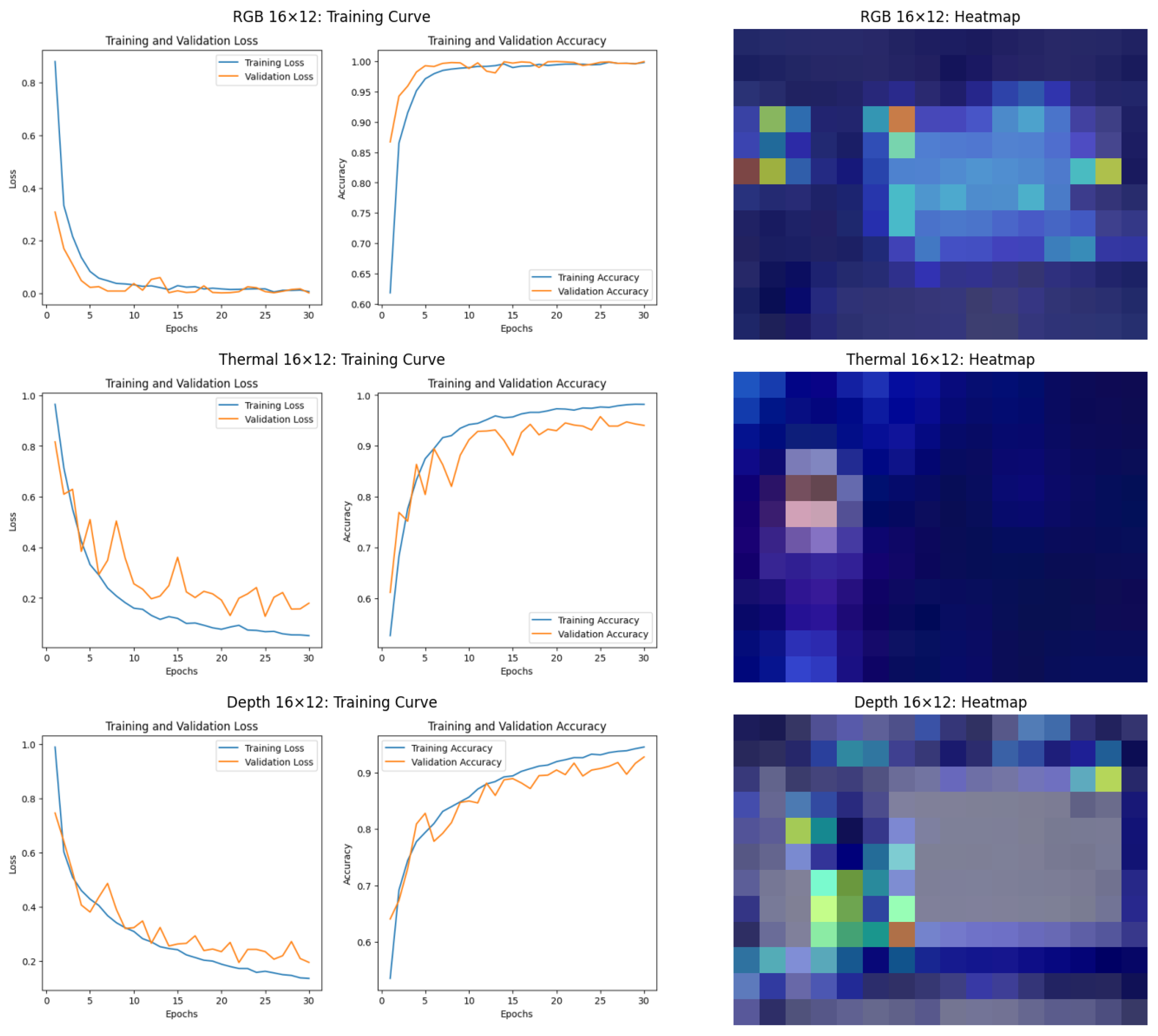
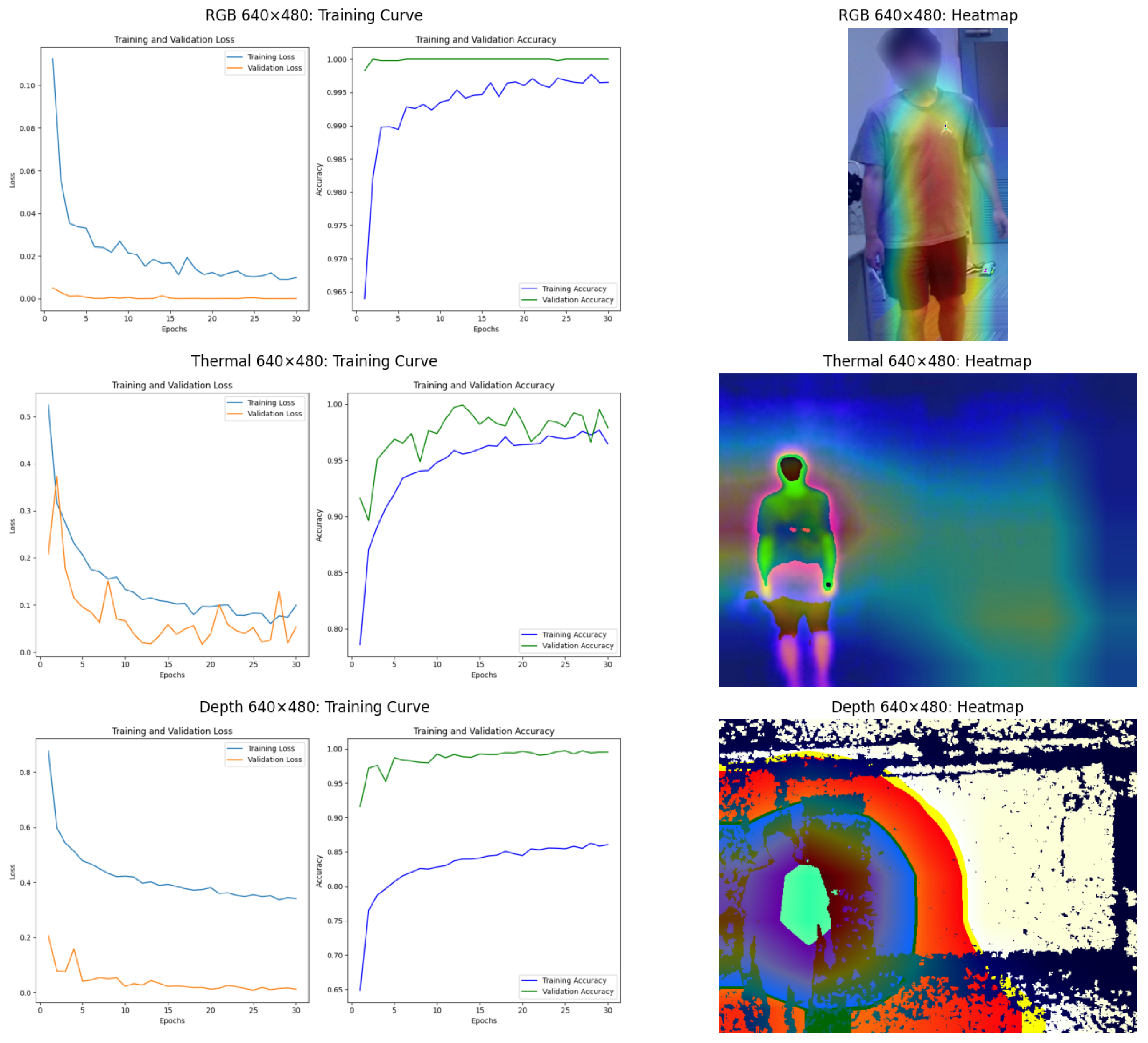
6.2.1. Experimental Results
6.2.2. Performance Analysis of ViT Model
6.2.3. Performance Analysis of ResNet34 Model
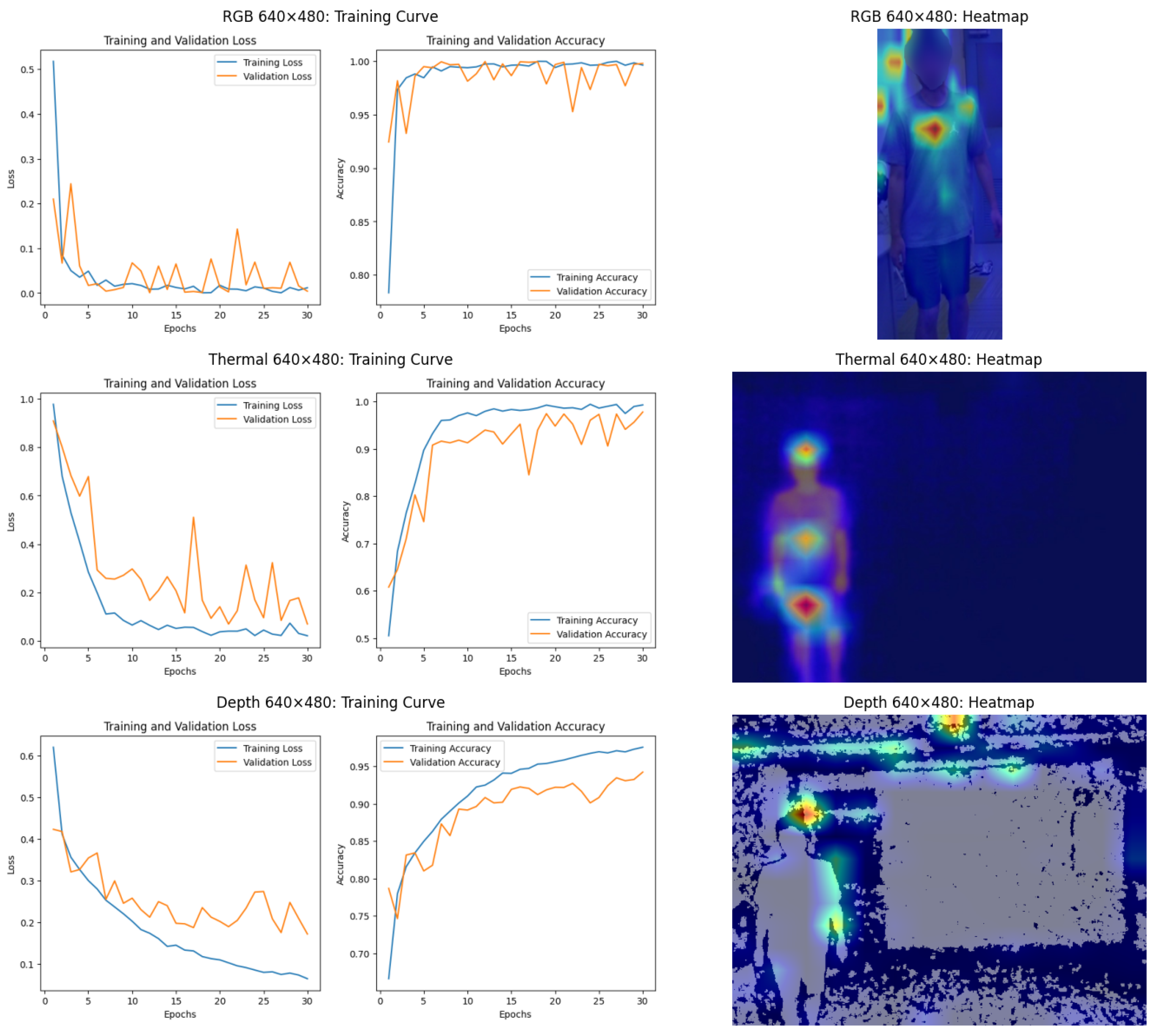
6.3. Discussion
6.3.1. RGB Data: Challenges with Background Dependency
6.3.2. Thermal Data: A Robust Modality
6.3.3. Depth Data: Sensitivity to Resolution
6.3.4. Heatmap Analysis: GradCAM and Attention Rollout
6.3.5. Multi-Modal Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Brunelli, R.; Falavigna, D. Person identification using multiple cues. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 955–966. [Google Scholar] [CrossRef]
- Xing, Z.; Bouazizi, M.; Ohtsuki, T. Person Identification under Noisy Conditions using Radar-extracted Heart Signal. IEICE Tech. Rep. 2024, 123, 64–69. [Google Scholar]
- Xing, Z.; Bouazizi, M.; Ohtsuki, T. Deep Learning-based Person Identification using Vital Signs Extracted from Radar Signal. In Proceedings of the 2022 International Conference on Emerging Technologies for Communications (ICETC), Tokyo, Japan, 29 November–1 December 2022; Volume 72. [Google Scholar]
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. Artif. Intell. Rev. 2023, 56, 8647–8695. [Google Scholar] [CrossRef]
- Ebrahimian, Z.; Mirsharji, S.A.; Toosi, R.; Akhaee, M.A. Automated person identification from hand images using hierarchical vision transformer network. In Proceedings of the 2022 IEEE 12th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 17–18 November 2022; pp. 398–403. [Google Scholar]
- Ni, Z.; Huang, B. Gait-based person identification and intruder detection using mm-wave sensing in multi-person scenario. IEEE Sensors J. 2022, 22, 9713–9723. [Google Scholar] [CrossRef]
- Qiu, J.; Tian, Z.; Du, C.; Zuo, Q.; Su, S.; Fang, B. A survey on access control in the age of internet of things. IEEE Internet Things J. 2020, 7, 4682–4696. [Google Scholar] [CrossRef]
- Guo, D.; Chen, H.; Wu, R.; Wang, Y. AIGC challenges and opportunities related to public safety: A case study of ChatGPT. J. Saf. Sci. Resil. 2023, 4, 329–339. [Google Scholar] [CrossRef]
- Gu, X.; Chang, H.; Ma, B.; Bai, S.; Shan, S.; Chen, X. Clothes-changing person re-identification with rgb modality only. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 1060–1069. [Google Scholar]
- Ozcan, A.; Cetin, O. A novel fusion method with thermal and RGB-D sensor data for human detection. IEEE Access 2022, 10, 66831–66843. [Google Scholar] [CrossRef]
- Uddin, M.K.; Bhuiyan, A.; Bappee, F.K.; Islam, M.M.; Hasan, M. Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey. Sensors 2023, 23, 1504. [Google Scholar] [CrossRef]
- Wan, L.; Jing, Q.; Sun, Z.; Zhang, C.; Li, Z.; Chen, Y. Self-supervised modality-aware multiple granularity pre-training for RGB-infrared person re-identification. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3044–3057. [Google Scholar] [CrossRef]
- Patruno, C.; Renò, V.; Cicirelli, G.; D’Orazio, T. Multimodal People Re-identification using 3D Skeleton, Depth and Color Information. IEEE Access 2024, 12, 174689–174704. [Google Scholar] [CrossRef]
- Shao, W.; Bouazizi, M.; Meng, X.; Otsuki, T. People Identification in Private Car Using 3D LiDAR With Generative Image Inpainting and YOLOv5. IEEE Access 2024, 12, 38258–38274. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Bergmann, J.H. Non-contact infrared thermometers and thermal scanners for human body temperature monitoring: A systematic review. Sensors 2023, 23, 7439. [Google Scholar] [CrossRef]
- Hafner, F.M.; Bhuyian, A.; Kooij, J.F.; Granger, E. Cross-modal distillation for RGB-depth person re-identification. Comput. Vis. Image Underst. 2022, 216, 103352. [Google Scholar] [CrossRef]
- Shopovska, I.; Jovanov, L.; Philips, W. Deep visible and thermal image fusion for enhanced pedestrian visibility. Sensors 2019, 19, 3727. [Google Scholar] [CrossRef]
- Rodrigo, M.; Cuevas, C.; García, N. Comprehensive comparison between vision transformers and convolutional neural networks for face recognition tasks. Sci. Rep. 2024, 14, 21392. [Google Scholar] [CrossRef]
- Kowalski, M.; Grudzień, A.; Mierzejewski, K. Thermal–visible face recognition based on cnn features and triple triplet configuration for on-the-move identity verification. Sensors 2022, 22, 5012. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X.s. Attribute-driven feature disentangling and temporal aggregation for video person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4913–4922. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, Y.; Wang, K.; Ye, H.; Tao, L.; Tie, Z. Person Re-Identification in Special Scenes Based on Deep Learning: A Comprehensive Survey. Mathematics 2024, 12, 2495. [Google Scholar] [CrossRef]
- Ivasic-Kos, M.; Kristo, M.; Pobar, M. Person Detection in thermal videos using YOLO. In Proceedings of the 2019 Intelligent Systems Conference (IntelliSys), London, UK, 5–6 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 254–267. [Google Scholar]
- Wang, G.A.; Zhang, T.; Yang, Y.; Cheng, J.; Chang, J.; Liang, X.; Hou, Z.G. Cross-modality paired-images generation for RGB-infrared person re-identification. In Proceedings of the 2020 AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12144–12151. [Google Scholar]
- Speth, S.; Goncalves, A.; Rigault, B.; Suzuki, S.; Bouazizi, M.; Matsuo, Y.; Prendinger, H. Deep learning with RGB and thermal images onboard a drone for monitoring operations. J. Field Robot. 2022, 39, 840–868. [Google Scholar] [CrossRef]
- Palmero, C.; Clapés, A.; Bahnsen, C.; Møgelmose, A.; Moeslund, T.B.; Escalera, S. Multi-modal rgb–depth–thermal human body segmentation. Int. J. Comput. Vis. 2016, 118, 217–239. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wilson, A.; Gupta, K.A.; Koduru, B.H.; Kumar, A.; Jha, A.; Cenkeramaddi, L.R. Recent advances in thermal imaging and its applications using machine learning: A review. IEEE Sensors J. 2023, 23, 3395–3407. [Google Scholar] [CrossRef]
- Giacomini, E.; Brizi, L.; Di Giammarino, L.; Salem, O.; Perugini, P.; Grisetti, G. Ca2Lib: Simple and Accurate LiDAR-RGB Calibration Using Small Common Markers. Sensors 2024, 24, 956. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. (NeurIPS) 2017, 30, 5998–6008. [Google Scholar]
- Borawar, L.; Kaur, R. ResNet: Solving vanishing gradient in deep networks. In Proceedings of the International Conference on Recent Trends in Computing (ICRTC), Ghaziabad, Delhi, India, 3–4 June 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 235–247. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Advantages | Disadvantages |
|---|---|---|
| Millimeter Wave Radar |
|
|
| RGB |
|
|
| Thermal |
|
|
| Depth |
|
|
| Modality | Theoretical Effective Distance Range | Experimental Effective Distance Range | Factors Influencing Effectiveness |
|---|---|---|---|
| RGB Imaging | 10 to 50 m (up to 100 m with high-resolution cameras in well-lit conditions) | Up to 3 m | Performance degrades in low-light conditions without auxiliary lighting. |
| Thermal Imaging (FLIR C5) | 5 to 30 m | Up to 3 m | Environmental factors such as temperature variations and atmospheric interference. |
| Depth Imaging (Intel RealSense L515) | 1 to 4 m (optimal); up to 9 m (general depth data collection) | Up to 3 m | Reduced accuracy beyond 4 m; noise increases with distance. |
| Parameter | FLIR C5 (Thermal Camera) | Intel RealSense LiDAR L515 |
|---|---|---|
| Resolution | 160 × 120 pixels | RGB: 640 × 480 pixels; Depth: 640 × 480 pixels |
| Frame Rate | 15 FPS | RGB: 30 FPS; Depth: 30 FPS |
| Sensor Type | Infrared Array Sensor | LiDAR with RGB and Depth Sensors |
| Data Output | Thermal Videos | RGB and Depth Images |
| Mounting Height | 2 m | 2 m |
| Field of View (FOV) | 54° × 42° | RGB: 70° × 43°; Depth: 70° × 55° |
| Resolution | RGB (%) | Thermal (%) | Depth (%) |
|---|---|---|---|
| 16 × 12 | 0.00 | 0.00 | 0.00 |
| 64 × 48 | 49.75 | 5.07 | 3.50 |
| 128 × 96 | 98.76 | 15.18 | 0.41 |
| 320 × 240 | 99.46 | 20.62 | 0.07 |
| 640 × 480 | 99.51 | 5.94 | 0.01 |
| Resolution | ViT RGB | ViT Thermal | ViT Depth | ResNet RGB | ResNet Thermal | ResNet Depth |
|---|---|---|---|---|---|---|
| 16 × 12 | 99.96 | 94.05 | 92.76 | 99.91 | 95.85 | 96.78 |
| 64 × 48 | 99.81 | 95.57 | 93.34 | 99.94 | 98.27 | 99.80 |
| 128 × 96 | 99.83 | 94.61 | 94.04 | 99.98 | 97.10 | 99.50 |
| 320 × 240 | 99.96 | 94.61 | 93.28 | 99.98 | 97.93 | 99.41 |
| 640 × 480 | 99.81 | 97.79 | 94.21 | 100.0 | 97.93 | 99.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; Bouazizi, M.; Xing, Z.; Ohtsuki, T. A Comparison Study of Person Identification Using IR Array Sensors and LiDAR. Sensors 2025, 25, 271. https://doi.org/10.3390/s25010271
Liu K, Bouazizi M, Xing Z, Ohtsuki T. A Comparison Study of Person Identification Using IR Array Sensors and LiDAR. Sensors. 2025; 25(1):271. https://doi.org/10.3390/s25010271
Chicago/Turabian StyleLiu, Kai, Mondher Bouazizi, Zelin Xing, and Tomoaki Ohtsuki. 2025. "A Comparison Study of Person Identification Using IR Array Sensors and LiDAR" Sensors 25, no. 1: 271. https://doi.org/10.3390/s25010271
APA StyleLiu, K., Bouazizi, M., Xing, Z., & Ohtsuki, T. (2025). A Comparison Study of Person Identification Using IR Array Sensors and LiDAR. Sensors, 25(1), 271. https://doi.org/10.3390/s25010271