
Robust Multi-Subtype Identification of Breast Cancer Pathological Images Based on a Dual-Branch Frequency Domain Fusion Network


Abstract
1. Introduction
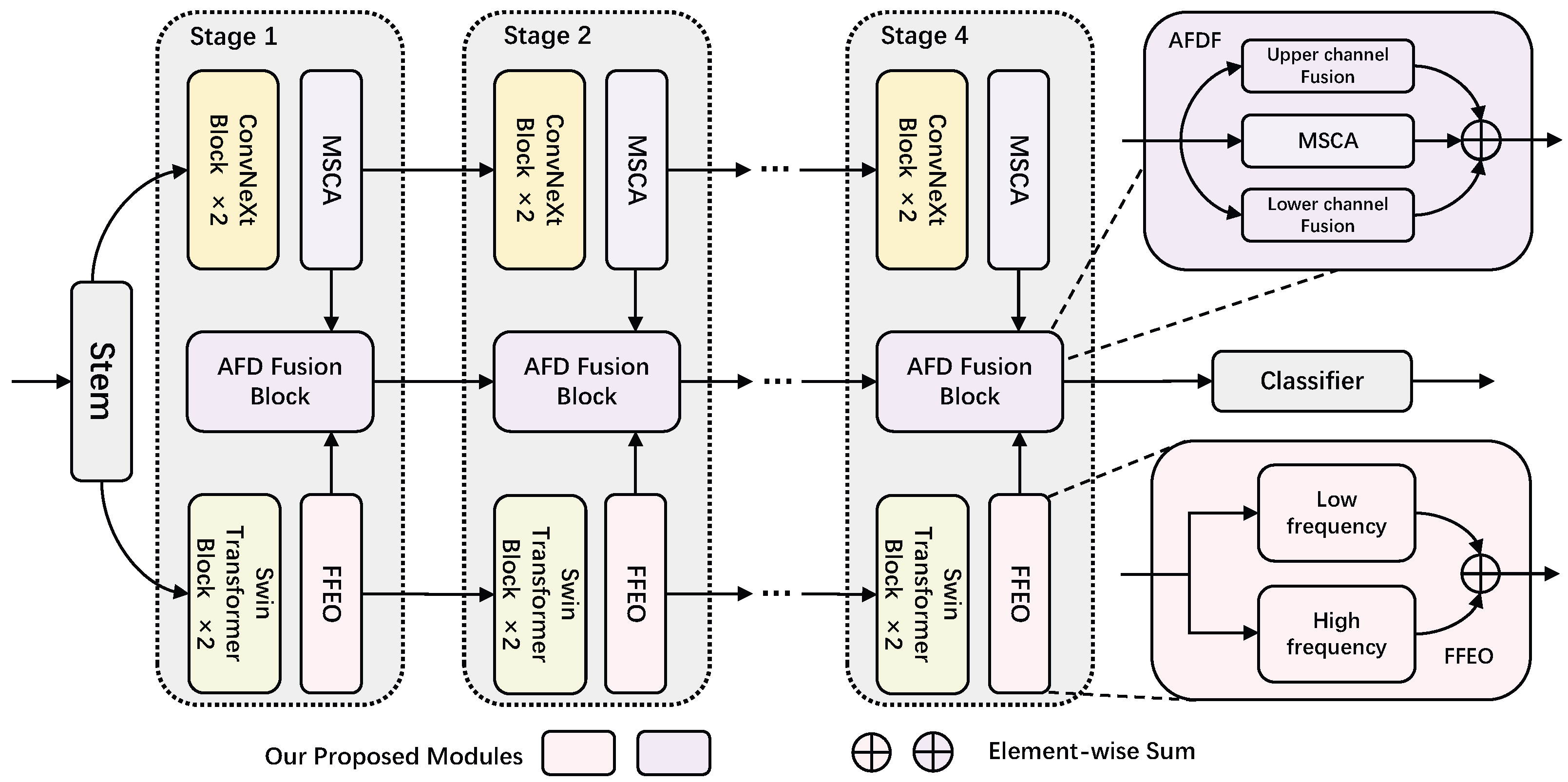
- We propose a dual-branch framework, AFFNet, designed to simultaneously capture fine-grained local details and global structural information in images.
- The characteristics and attention mechanisms of BC histopathological images are analyzed from the perspective of the frequency domain. MSCA is employed to effectively extract the local high-saliency features of pathological images. Meanwhile, FFEO is utilized to enhance high-frequency information while preserving the low-frequency features of images. These frequency domain features are then transformed into spatial domain feature maps, thus increasing the number of feature maps and enabling the network to focus on contour and texture information simultaneously.
- A novel frequency-domain-adaptive feature fusion strategy is proposed to adaptively model multi-scale contextual information. This enables the model to efficiently integrate multi-source information at different resolutions, thus enhancing its representational capacity.
- AFFNet outperforms other state-of-the-art models in the experiments based on two publicly accessible BC histopathological image datasets. Furthermore, the effectiveness and superiority of the proposed method are validated by a T-SNE-based visualization.
2. Related Work
3. Proposed Method
3.1. Stem
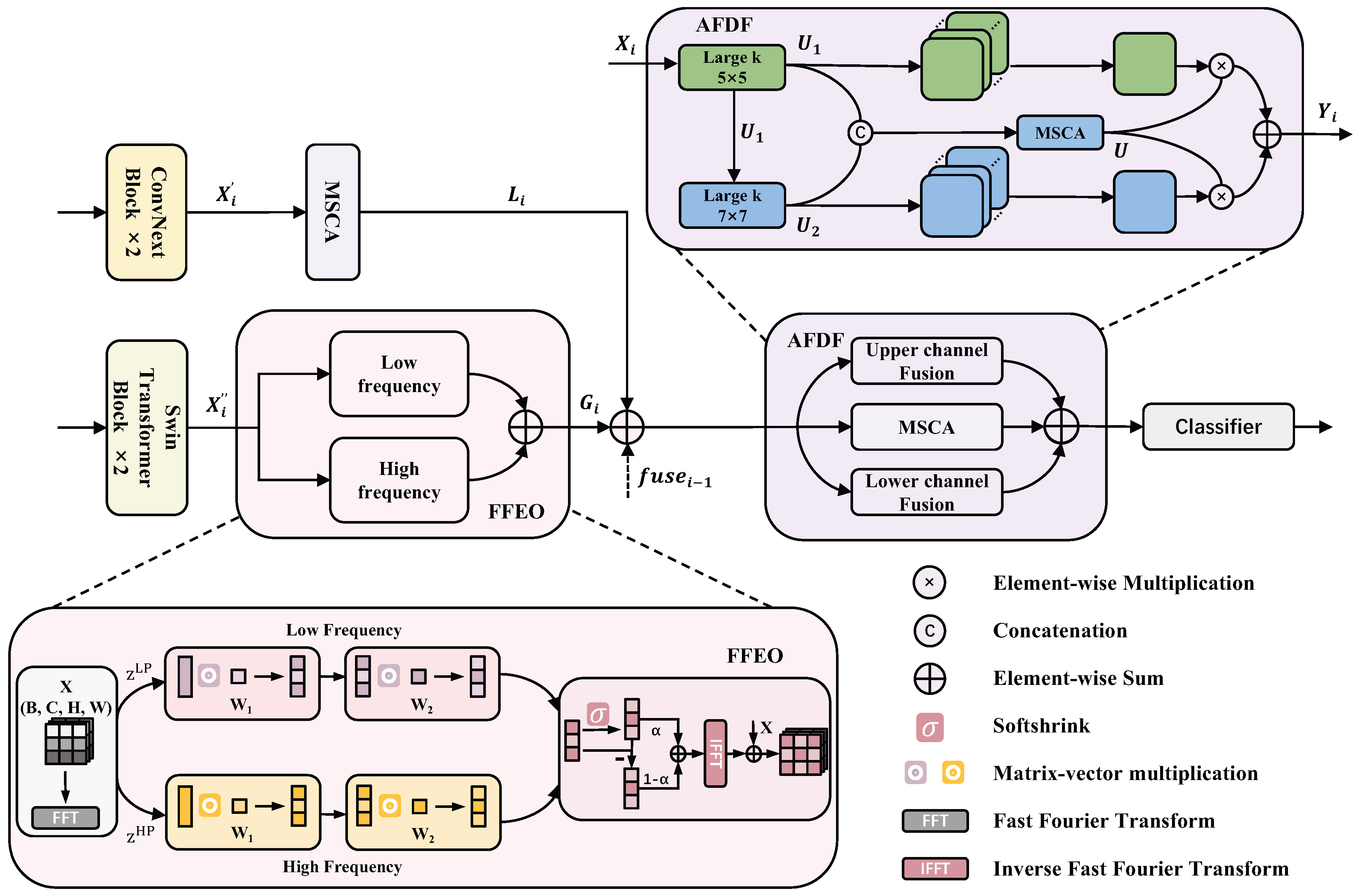
3.2. Frequency Domain Operator
3.2.1. Multi-Spectral Channel Attention
3.2.2. Fourier Filtering Enhancement Operator
| Algorithm 1: Fourier Filtering Enhancement Operator |
Input: Output:
|
3.2.3. Structure
3.3. Adaptive Frequency Domain Fusion
4. Experiments and Results
4.1. Dataset
4.2. Experimental Setup
4.3. Results
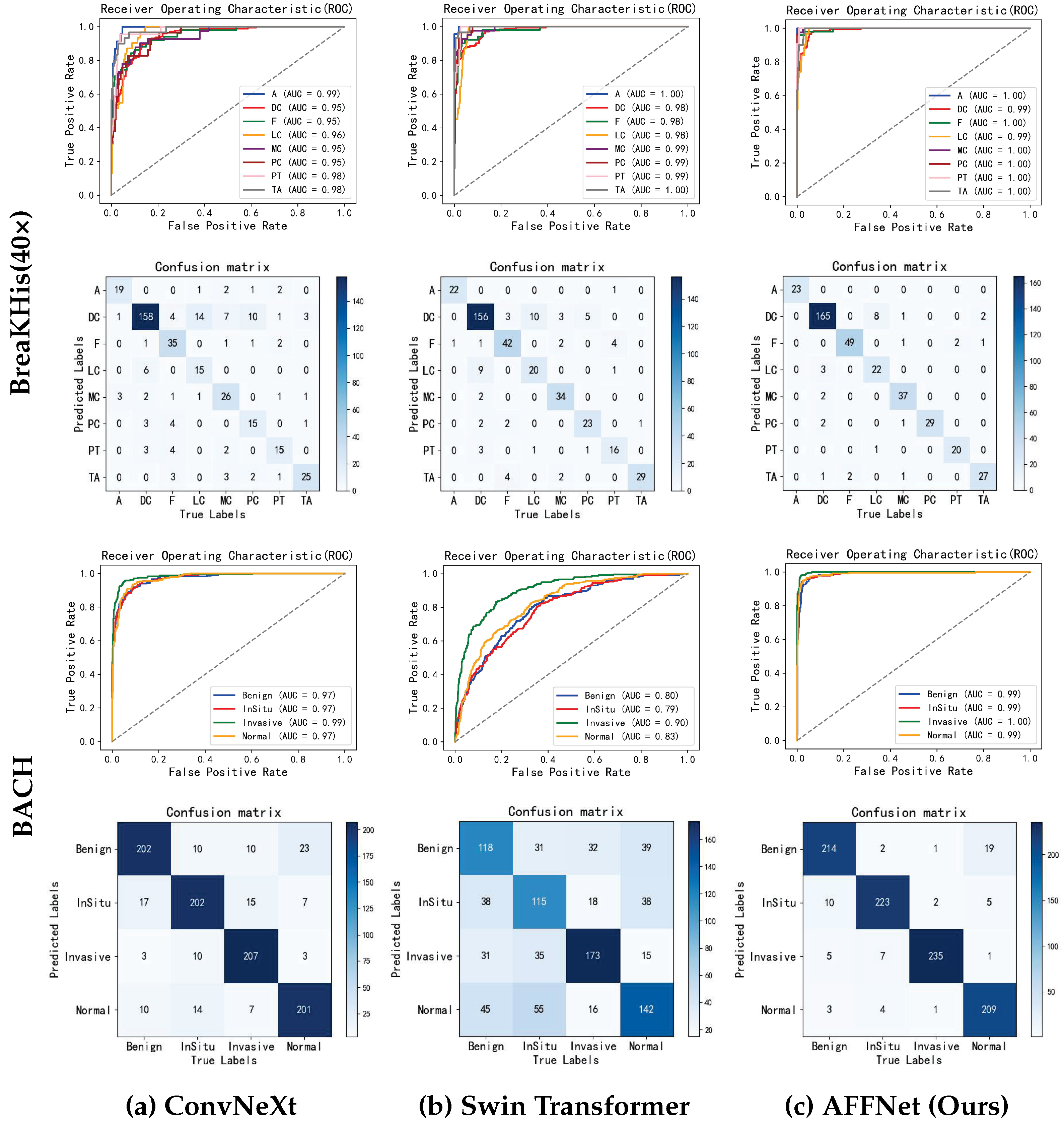
4.3.1. Results Based on the BreaKHis Dataset
4.3.2. Results on Based the BACH Dataset
4.3.3. Result Analysis
4.4. Ablation Study
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bray, F.; Laversanne, M.; Sung, H.; Ferlay, J.; Siegel, R.L.; Soerjomataram, I.; Jemal, A. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2024, 74, 229–263. [Google Scholar] [CrossRef]
- Din, N.M.U.; Dar, R.A.; Rasool, M.; Assad, A. Breast cancer detection using deep learning: Datasets, methods, and challenges ahead. Comput. Biol. Med. 2022, 149, 106073. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Ju, J.; Guo, L.; Ji, B.; Shi, S.; Yang, Z.; Gao, S.; Yuan, X.; Tian, G.; Liang, Y.; et al. Prediction of HER2-positive breast cancer recurrence and metastasis risk from histopathological images and clinical information via multimodal deep learning. Comput. Struct. Biotechnol. J. 2022, 20, 333–342. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Lu, Y.; Lan, R.; Liu, Z.; Qin, Z.; Wang, H.; Liu, Z. Mitosis detection techniques in H&E stained breast cancer pathological images: A comprehensive review. Comput. Electr. Eng. 2021, 91, 107038. [Google Scholar]
- Abhisheka, B.; Biswas, S.K.; Purkayastha, B. A Comprehensive Review on Breast Cancer Detection, Classification and Segmentation Using Deep Learning. Arch. Comput. Methods Eng. 2023, 30, 5023–5052. [Google Scholar] [CrossRef]
- Batool, A.; Byun, Y.-C. Toward Improving Breast Cancer Classification Using an Adaptive Voting Ensemble Learning Algorithm. IEEE Access 2024, 12, 12869–12882. [Google Scholar] [CrossRef]
- Gonzalez, R.; Nejat, P.; Saha, A.; Campbell, C.J.V.; Norgan, A.P.; Lokker, C. Performance of externally validated machine learning models based on histopathology images for the diagnosis, classification, prognosis, or treatment outcome prediction in female breast cancer: A systematic review. J. Pathol. Inform. 2024, 15, 100348. [Google Scholar] [CrossRef] [PubMed]
- Maurya, R.; Pandey, N.N.; Dutta, M.K.; Karnati, M. FCCS-Net: Breast cancer classification using Multi-Level fully Convolutional-Channel and spatial attention-based transfer learning approach. Biomed. Signal Process. Control 2024, 94, 106258. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. Breast cancer histopathological image classification using convolutional neural networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2560–2567. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Jiang, Z.; Dong, Z.; Fan, J.; Yu, Y.; Xian, Y.; Wang, Z. Breast TransFG Plus: Transformer-based fine-grained classification model for breast cancer grading in Hematoxylin-Eosin stained pathological images. Biomed. Signal Process. Control 2023, 86, 105284. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Su, Y.; Bai, Y.; Zhang, B.; Zhang, Z.; Wang, W. HAT-Net: A Hierarchical Transformer Graph Neural Network for Grading of Colorectal Cancer Histology Images. In Proceedings of the British Machine Vision Conference (BMVC2021), Virtual, UK, 22–25 November 2021; p. 412. [Google Scholar]
- Ju, W.; Fang, Z.; Gu, Y.; Liu, Z.; Long, Q.; Qiao, Z.; Qin, Y.; Shen, J.; Sun, F.; Xiao, Z.; et al. A Comprehensive Survey on Deep Graph Representation Learning. Neural Netw. 2024, 173, 106207. [Google Scholar] [CrossRef]
- Awan, R.; Sirinukunwattana, K.; Epstein, D.; Jefferyes, S.; Qidwai, U.; Aftab, Z.; Mujeeb, I.; Snead, D.; Rajpoot, N. Glandular Morphometrics for Objective Grading of Colorectal Adenocarcinoma Histology Images. Sci. Rep. 2017, 7, 16852. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Mu, D.; Guo, L. Random Time Delay Effect on Out-of-Sequence Measurements. IEEE Access 2016, 4, 7509–7518. [Google Scholar] [CrossRef]
- Al-Haddad, L.; Jaber, A.; Neranon, P.; Al-Haddad, S. Investigation of Frequency-Domain-Based Vibration Signal Analysis for UAV Unbalance Fault Classification. Eng. Technol. J. 2013, 41, 915–923. [Google Scholar] [CrossRef]
- Kong, L.; Dong, J.; Ge, J.; Li, M.; Pan, J. Efficient frequency domain-based transformers for high-quality image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5886–5895. [Google Scholar]
- Yi, K.; Zhang, Q.; Fan, W.; Wang, S.; Wang, P.; He, H.; An, N.; Lian, D.; Cao, L.; Niu, Z. Frequency-domain MLPs are more effective learners in time series forecasting. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Attallah, O. Cervical Cancer Diagnosis Based on Multi-Domain Features Using Deep Learning Enhanced by Handcrafted Descriptors. Appl. Sci. 2023, 13, 1916. [Google Scholar] [CrossRef]
- Liu, X.; Gu, Z.; Ding, H.; Zhang, M.; Wang, L. Underwater Image Super-Resolution Using Frequency-Domain Enhanced Attention Network. IEEE Access 2024, 12, 6136–6147. [Google Scholar] [CrossRef]
- Sharma, R.; Mahanti, G.K.; Panda, G.; Rath, A.; Dash, S.; Mallik, S.; Hu, R. A Framework for Detecting Thyroid Cancer from Ultrasound and Histopathological Images Using Deep Learning, Meta-Heuristics, and MCDM Algorithms. J. Imaging 2023, 9, 173. [Google Scholar] [CrossRef] [PubMed]
- Vo, X.-T.; Nguyen, D.-L.; Priadana, A.; Jo, K.-H. Dynamic Circular Convolution for Image Classification. In Proceedings of the International Workshop on Frontiers of Computer Vision, Yeosu, Republic of Korea, 20–22 February 2023; pp. 43–55. [Google Scholar]
- Patro, B.N.; Namboodiri, V.P.; Agneeswaran, V.S. SpectFormer: Frequency and Attention is what you need in a Vision Transformer. arXiv 2023, arXiv:2304.06446. [Google Scholar]
- Shen, H.; Wang, C.; Deng, L.; He, L.; Lu, X.; Shao, M.; Meng, D. FDDN: Frequency-guided network for single image dehazing. Neural Comput. Appl. 2023, 35, 18309–18324. [Google Scholar] [CrossRef]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Wang, C.; Feng, J. Improving Convolutional Networks With Self-Calibrated Convolutions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Wang, K.N.; Zhuang, S.; Ran, Q.Y.; Zhou, P.; Hua, J.; Zhou, G.Q.; He, X. DLGNet: A dual-branch lesion-aware network with the supervised Gaussian Mixture model for colon lesions classification in colonoscopy images. Med. Image Anal. 2023, 87, 102832. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Zhi, L.; Zhang, S.; Zhou, T. A Dual-Branch Framework With Prior Knowledge for Precise Segmentation of Lung Nodules in Challenging CT Scans. IEEE J. Biomed. Health Inf. 2024, 28, 1540–1551. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Guibas, J.; Mardani, M.; Li, Z.; Tao, A.; Anandkumar, A.; Catanzaro, B. Adaptive fourier neural operators: Efficient token mixers for transformers. arXiv 2021, arXiv:2111.13587. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2016, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Aresta, G.; Araújo, T.; Kwok, S.; Chennamsetty, S.S.; Safwan, M.; Alex, V.; Marami, B.; Prastawa, M.; Chan, M.; Donovan, M. Bach: Grand challenge on breast cancer histology images. Med. Image Anal. 2019, 56, 122–139. [Google Scholar] [CrossRef]
- Golatkar, A.; Anand, D.; Sethi, A. Classification of breast cancer histology using deep learning. In Proceedings of the 15th International Conference on Image Analysis and Recognition ICIAR 2018, Póvoa de Varzim, Portugal, 27–29 June 2018; pp. 837–844. [Google Scholar]
- Tatsunami, Y.; Taki, M. Fft-based dynamic token mixer for vision. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 15328–15336. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 17773–17783. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer Is Actually What You Need for Vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Fu, B.; Zhang, M.; He, J.; Cao, Y.; Guo, Y.; Wang, R. StoHisNet: A hybrid multi-classification model with CNN and Transformer for gastric pathology images. Comput. Methods Programs Biomed. 2022, 221, 106924. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Li, L.; Zhou, Y.; Liu, W.; Qian, C.; Ji, X. CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications. arXiv 2024, arXiv:2408.03703. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Params (M) | Folps (G) | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| ConvNeXt-B | 87.57 | 15.35 | 77.00 | 73.78 | 69.70 | 71.05 |
| Swin Transformer-B | 86.75 | 15.16 | 85.50 | 83.76 | 83.04 | 83.27 |
| ViT | 85.80 | 16.86 | 51.75 | 24.23 | 26.77 | 24.22 |
| DFFormer-B36 | 111.94 | 22.10 | 79.75 | 76.99 | 74.49 | 75.51 |
| TransNeXt-base | 88.96 | 17.82 | 85.00 | 83.08 | 83.07 | 82.71 |
| CSwin-B | 76.62 | 14.37 | 83.50 | 81.51 | 79.64 | 80.19 |
| PoolFormer-M36 | 55.41 | 8.76 | 81.75 | 80.14 | 80.73 | 80.12 |
| BiFormer-B | 56.04 | 9.36 | 90.25 | 89.67 | 89.62 | 89.44 |
| StoHisNet | 31.13 | 7.81 | 91.00 | 91.55 | 86.61 | 88.70 |
| CAS-ViT | 2.76 | 0.55 | 82.25 | 81.24 | 74.88 | 76.68 |
| AFFNet (Ours) | 68.45 | 9.24 | 93.00 | 92.75 | 91.69 | 92.06 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| ConvNeXt-B | 79.56 | 76.16 | 74.08 | 74.79 |
| Swin Transformer-B | 85.81 | 84.59 | 82.13 | 83.09 |
| ViT | 56.97 | 43.21 | 33.26 | 32.25 |
| DFFormer-B36 | 81.97 | 78.22 | 78.14 | 77.93 |
| TransNeXt-base | 87.98 | 85.63 | 86.01 | 85.78 |
| CSwin-B | 80.52 | 78.27 | 73.67 | 75.65 |
| PoolFormer-M36 | 82.21 | 79.03 | 76.75 | 77.56 |
| BiFormer-B | 83.89 | 80.13 | 81.66 | 80.40 |
| StoHisNet | 88.70 | 87.32 | 85.60 | 86.34 |
| CAS-ViT | 83.65 | 81.21 | 77.88 | 79.34 |
| AFFNet (Ours) | 90.62 | 90.82 | 87.29 | 88.74 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| ConvNeXt-B | 80.64 | 77.75 | 76.96 | 77.24 |
| Swin Transformer-B | 83.37 | 79.33 | 80.27 | 79.41 |
| ViT | 60.54 | 51.06 | 36.56 | 35.88 |
| DFFormer-B36 | 83.37 | 80.15 | 80.12 | 79.82 |
| TransNeXt-base | 86.84 | 84.95 | 84.92 | 84.83 |
| CSwin-B | 83.37 | 78.51 | 76.49 | 77.18 |
| PoolFormer-M36 | 82.38 | 82.20 | 77.00 | 79.05 |
| BiFormer-B | 87.84 | 86.85 | 88.34 | 87.26 |
| StoHisNet | 87.09 | 86.23 | 85.59 | 85.71 |
| CAS-ViT | 81.88 | 80.04 | 75.07 | 76.86 |
| AFFNet (Ours) | 90.32 | 88.89 | 89.44 | 89.09 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| ConvNeXt-B | 84.89 | 84.20 | 81.77 | 82.28 |
| Swin Transformer-B | 88.73 | 86.29 | 84.91 | 85.33 |
| ViT | 60.71 | 58.08 | 39.81 | 41.06 |
| DFFormer-B36 | 82.96 | 78.93 | 80.49 | 79.49 |
| TransNeXt-base | 89.01 | 87.29 | 87.05 | 86.98 |
| CSwin-B | 74.17 | 71.57 | 65.84 | 68.00 |
| PoolFormer-M36 | 84.06 | 81.66 | 80.93 | 80.67 |
| BiFormer-B | 87.91 | 84.80 | 86.94 | 85.56 |
| StoHisNet | 85.71 | 82.84 | 83.33 | 82.89 |
| CAS-ViT | 83.51 | 81.43 | 77.58 | 78.90 |
| AFFNet (Ours) | 90.65 | 90.39 | 88.16 | 88.76 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| ConvNeXt-B | 86.29 | 86.43 | 86.29 | 86.31 |
| Swin Transformer-B | 58.23 | 57.95 | 58.16 | 57.95 |
| ViT | 42.61 | 45.38 | 42.43 | 40.56 |
| DFFormer-B36 | 85.54 | 85.55 | 85.51 | 85.50 |
| TransNeXt-base | 91.17 | 91.17 | 91.15 | 91.16 |
| CSwin-B | 48.88 | 51.17 | 48.88 | 49.18 |
| PoolFormer-M36 | 83.84 | 83.95 | 83.83 | 83.83 |
| BiFormer-B | 84.48 | 84.45 | 84.45 | 84.44 |
| StoHisNet | 86.07 | 86.24 | 86.07 | 86.11 |
| CAS-ViT | 83.52 | 83.59 | 83.51 | 83.49 |
| AFFNet (Ours) | 93.62 | 93.66 | 93.59 | 93.58 |
| Baseline 1 | Baseline 2 | MSCA | FFEO | AFDF | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|---|
| ✓ | × | × | × | × | 77.00 | 73.78 | 69.70 | 71.05 |
| × | ✓ | × | × | × | 85.75 | 83.34 | 84.85 | 83.88 |
| ✓ | ✓ | × | × | × | 88.50 | 86.28 | 88.38 | 87.09 |
| ✓ | × | ✓ | × | × | 89.75 | 88.41 | 86.96 | 87.31 |
| × | ✓ | × | ✓ | × | 91.00 | 90.22 | 89.35 | 89.58 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 93.00 | 92.75 | 91.69 | 92.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wang, K.; Jiang, X. Robust Multi-Subtype Identification of Breast Cancer Pathological Images Based on a Dual-Branch Frequency Domain Fusion Network. Sensors 2025, 25, 240. https://doi.org/10.3390/s25010240
Li J, Wang K, Jiang X. Robust Multi-Subtype Identification of Breast Cancer Pathological Images Based on a Dual-Branch Frequency Domain Fusion Network. Sensors. 2025; 25(1):240. https://doi.org/10.3390/s25010240
Chicago/Turabian StyleLi, Jianjun, Kaiyue Wang, and Xiaozhe Jiang. 2025. "Robust Multi-Subtype Identification of Breast Cancer Pathological Images Based on a Dual-Branch Frequency Domain Fusion Network" Sensors 25, no. 1: 240. https://doi.org/10.3390/s25010240
APA StyleLi, J., Wang, K., & Jiang, X. (2025). Robust Multi-Subtype Identification of Breast Cancer Pathological Images Based on a Dual-Branch Frequency Domain Fusion Network. Sensors, 25(1), 240. https://doi.org/10.3390/s25010240