
Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11

Abstract
1. Introduction
- (1).
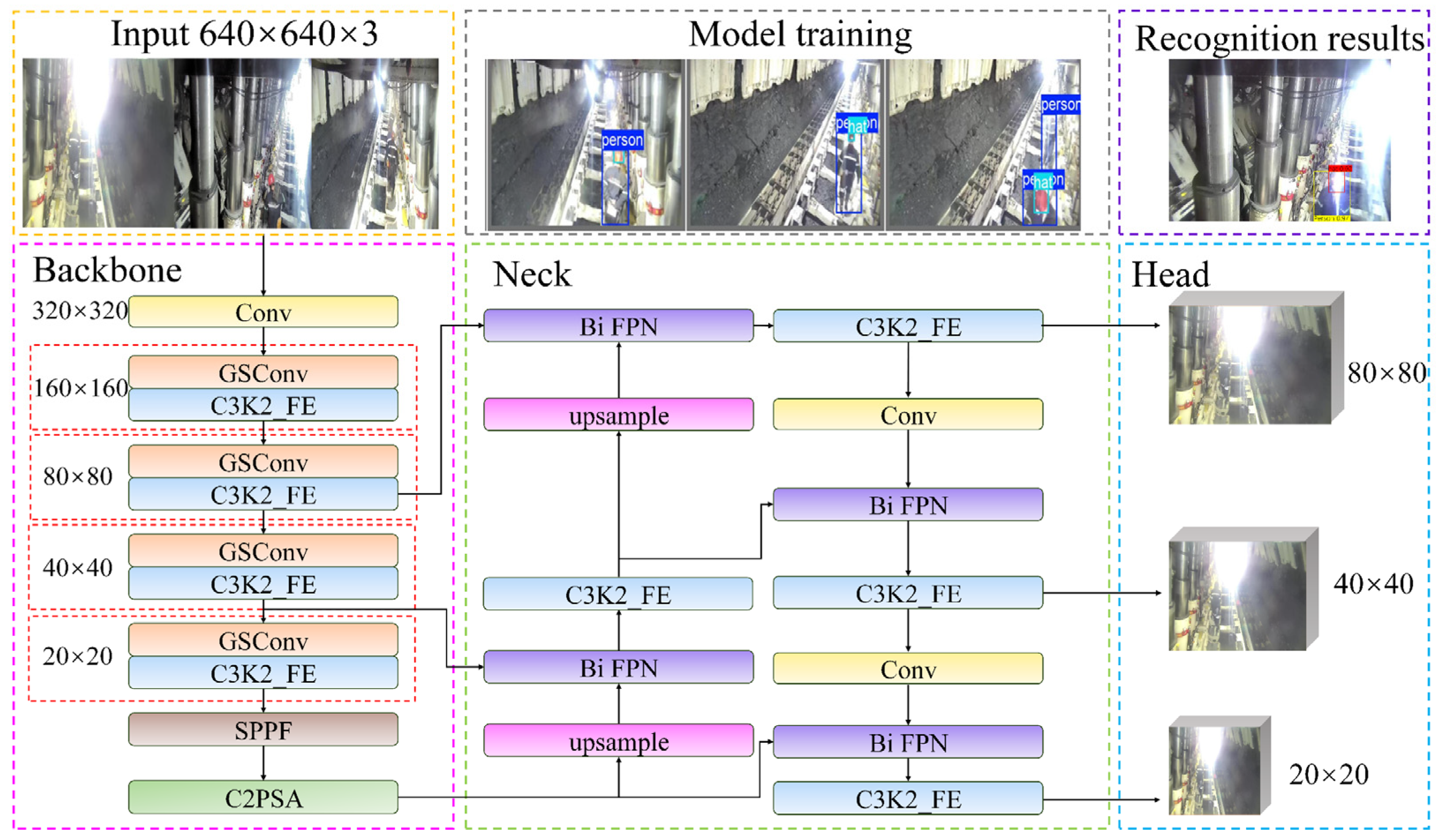
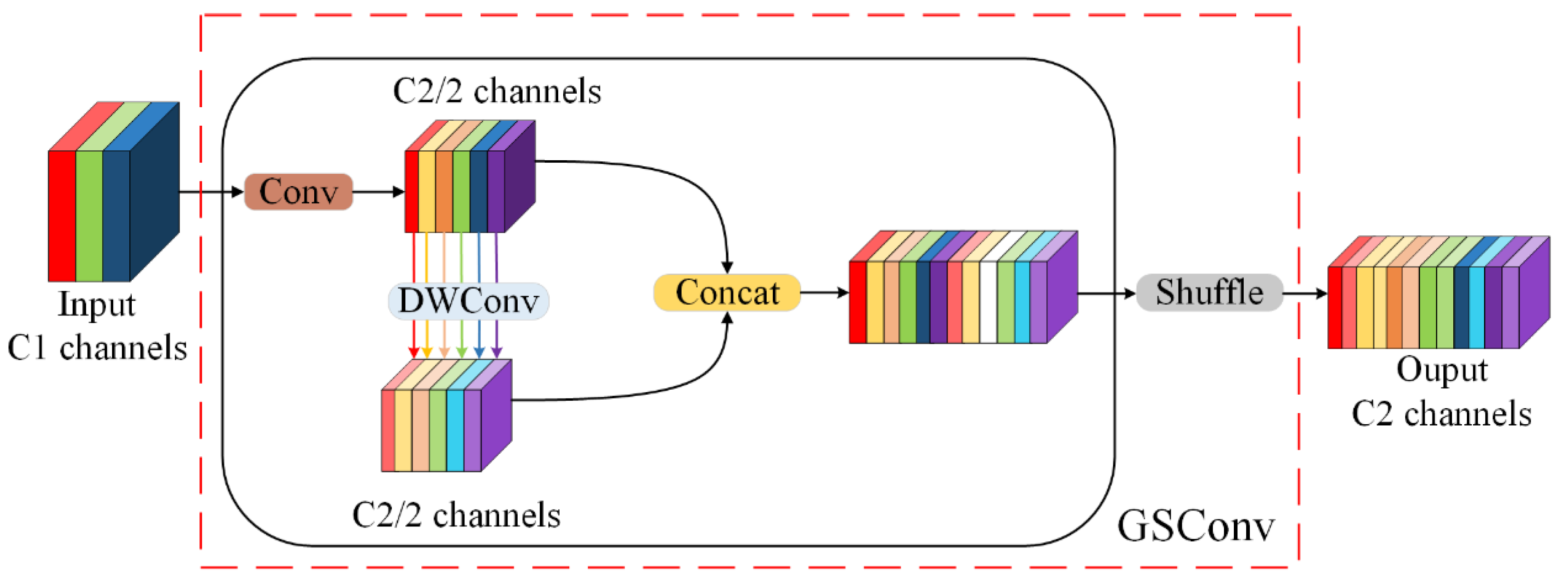
- The standard convolution method is susceptible to generating redundant feature information during the extraction of features related to downhole personnel and safety helmets. This redundancy can result in issues such as an increased number of parameters and elevated floating-point computations. To address these challenges, we employed Group Shuffle Convolution (GSConv) as a replacement for the standard convolution within the backbone network. This method aims to optimize feature extraction efficiency, enhance detection accuracy, and reduce the computational cost of the model.
- (2).
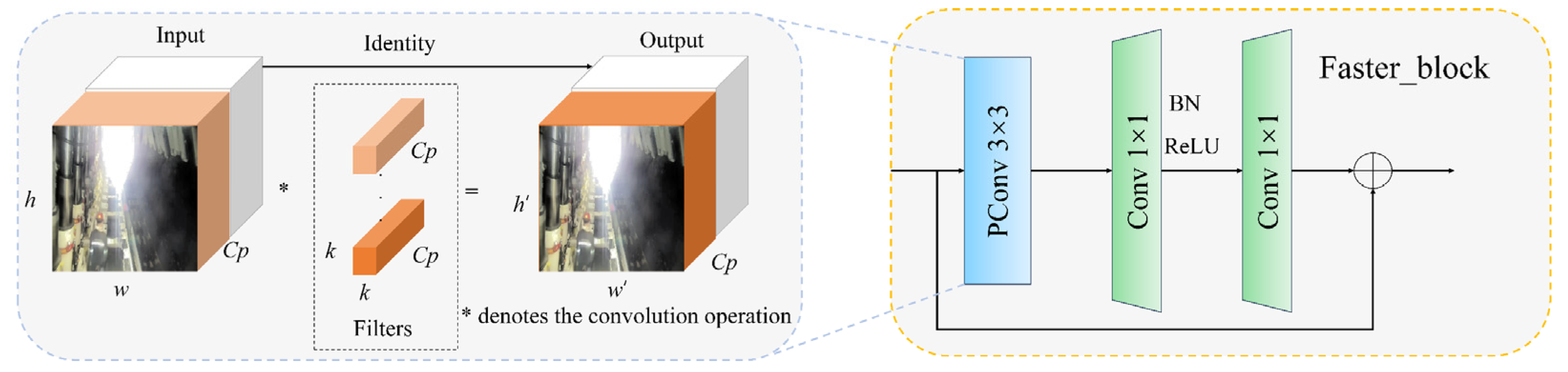
- As the depth of the network increases, the feature maps processed by C3K2 tend to contain a significant amount of irrelevant information, such as background elements. These extraneous data adversely impact both the accuracy and real-time detection capabilities of the model. To address this issue, we have redesigned the C3K2 module and introduced a novel C3K2_FE module. This new design enhances the model’s focus on key objects, specifically personnel and safety helmets, by integrating Faster_block and ECA attention mechanisms.
- (3).
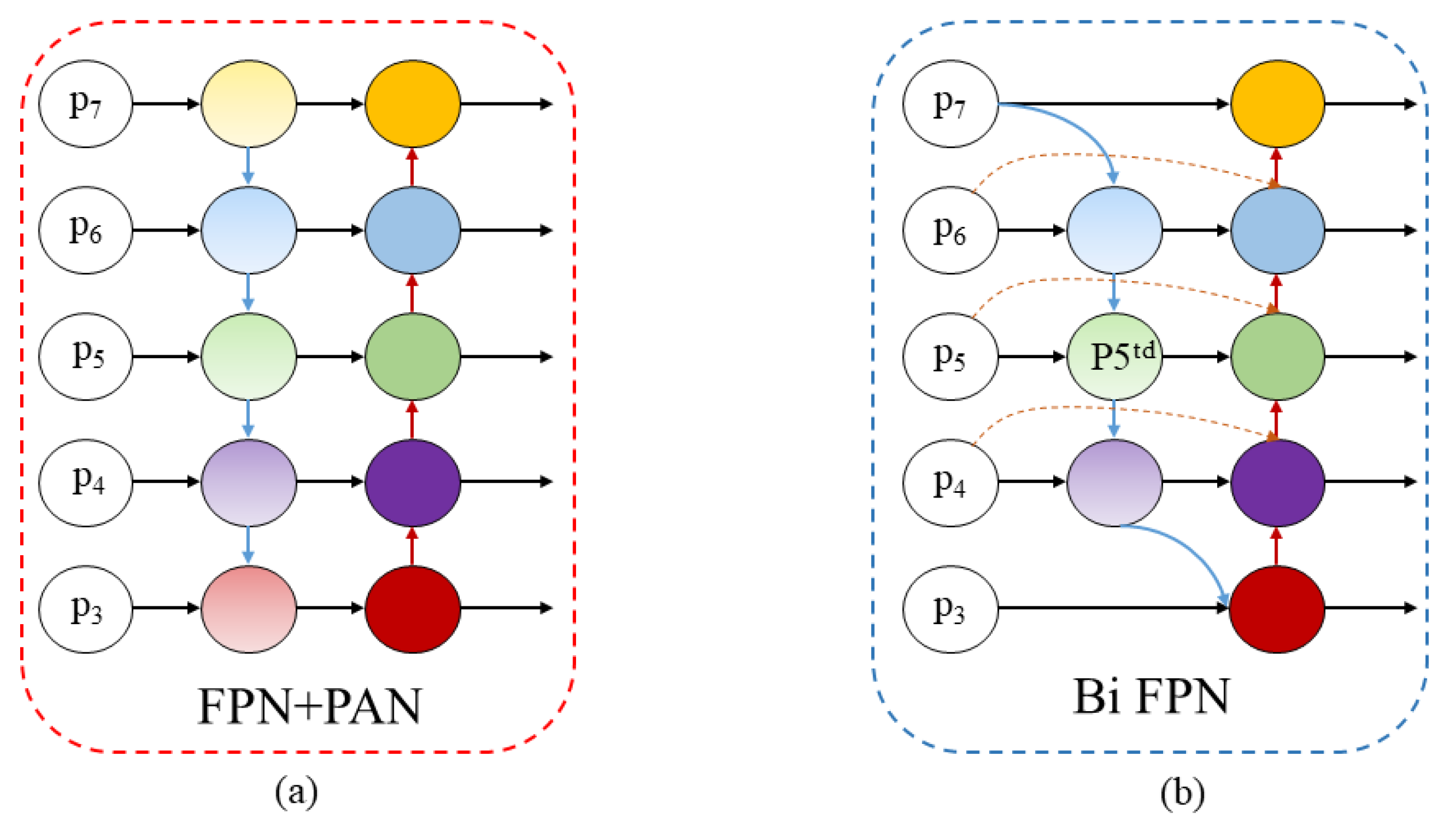
- To enhance the efficiency of feature fusion for two object types across varying scales, we implemented a bidirectional feature pyramid network (Bi FPN) mechanism at the neck [17]. This method improves multi-scale feature-fusion capabilities through skip connections, effectively addressing issues related to feature loss in complex environments and enhancing fusion efficiency under such conditions.
2. Method and Principle
2.1. YOLOv11 Model
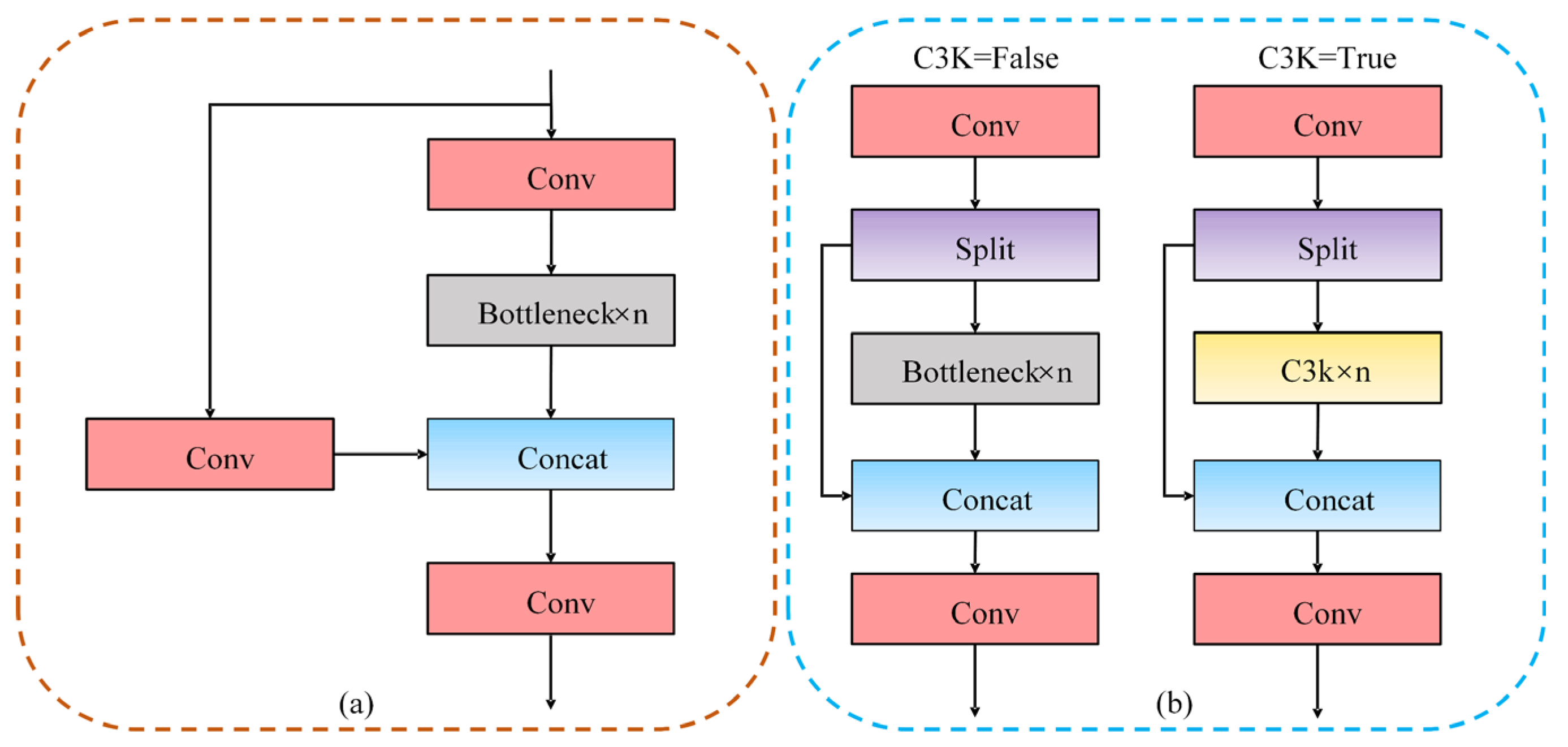
2.1.1. C3 Module and C3K2 Module
2.1.2. C2PSA Module
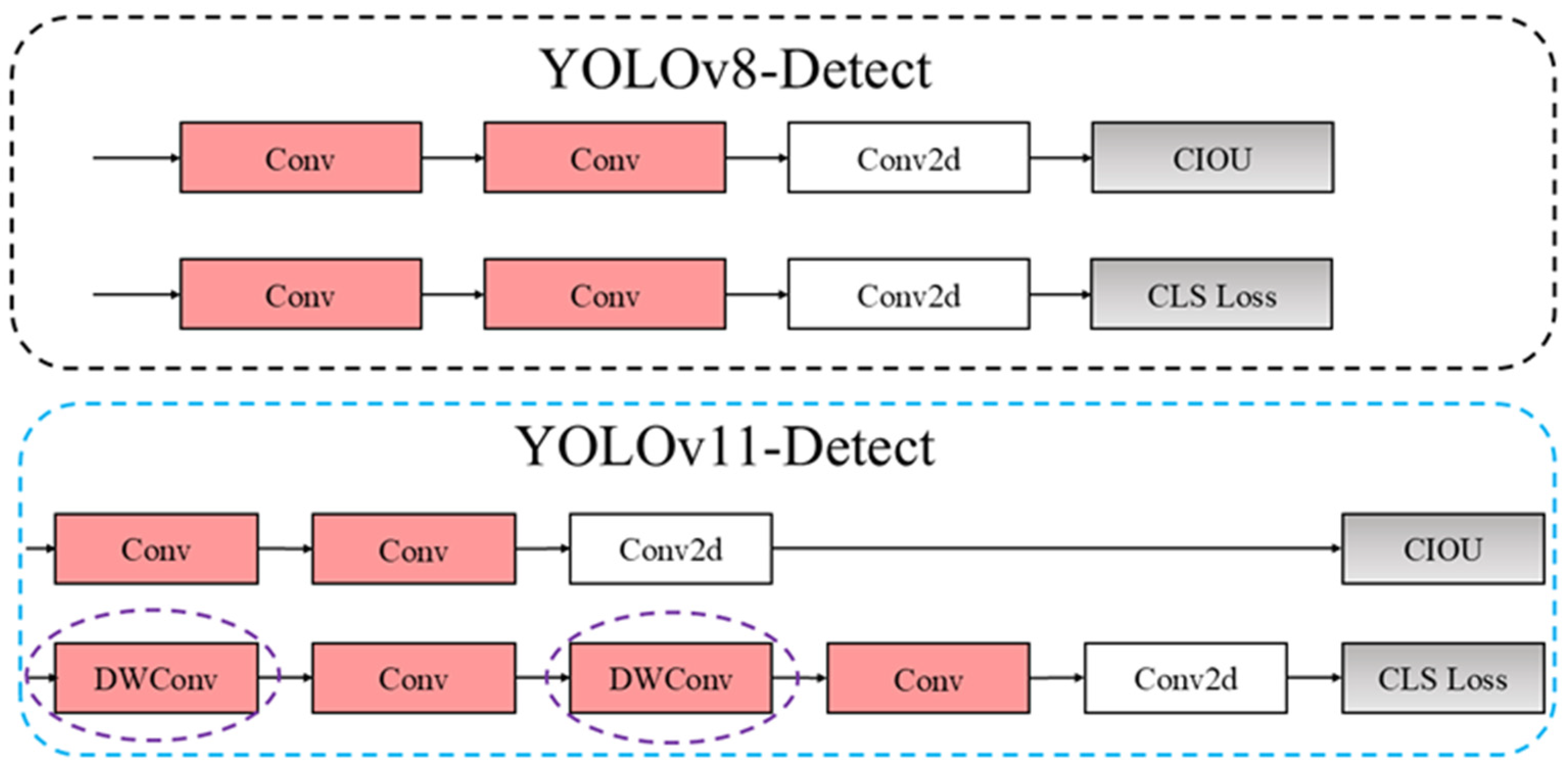
2.1.3. Sort Detection Head
2.2. GCB-YOLOv11 Network Structure
2.2.1. GSConv Module
2.2.2. C3K2_FE Module
2.2.3. Bi FPN Mechanism
3. Experiment and Analysis
3.1. Experimental Environment Configuration
3.2. Experimental Dataset
3.3. Model Evaluation Indicators
3.4. Experimental Results
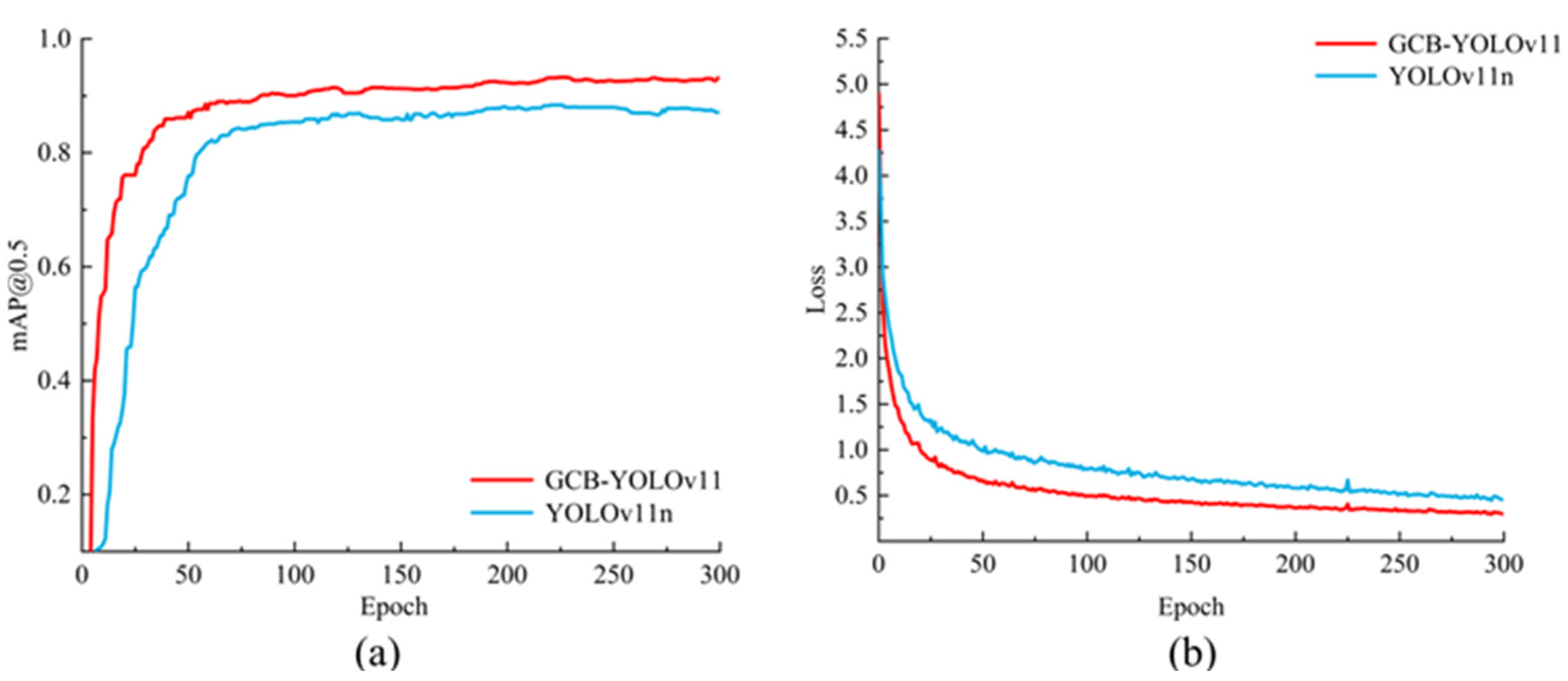
3.4.1. Model Training Analysis
3.4.2. Ablation Experiment
3.4.3. Contrast Experiment
- (1).
- In terms of detection accuracy, the model proposed in this article demonstrates a significant advantage, with a mAP@0.5 of 93.6%. This performance surpasses that of YOLOv3 Tiny, YOLOv5s, YOLOv8s, YOLOv11n, Fast R-CNN, RT-DETR, EfficientDet, HRHD-YOLOv8, and BLP-YOLOv10 by margins of 4.9%, 3.5%, 3.6%, 3.0%, 3.7%, 2.1%, 8.1%, and 4.3% respectively. These results indicate that the GCB-YOLOv11 model exhibits superior detection accuracy compared to other models and performs effectively in mining environments.
- (2).
- Regarding model complexity, the GCB-YOLOv11 model proposed in this paper exhibits a parameter count of 1.6 million and a floating-point computation requirement of 4.5 billion. These metrics demonstrate superior performance compared to nine other classes of models, particularly when contrasted with the two larger categories: Fast R-CNN and RT-DETR. Furthermore, the relatively lower model complexity associated with Fast R-CNN suggests that the GCB-YOLOv11 model is well-suited for deployment in underground coal mine environments.
- (3).
- In terms of real-time detection, the models YOLOv3-Tiny, YOLOv5s, YOLOv8s, EfficientDet, BLP-YOLOv10, and GCB-YOLOv11 demonstrate commendable performance. Notably, the FPS of GCB-YOLOv11 surpasses that of YOLOv3-Tiny, YOLOv5s, and YOLOv11n. Although models such as Fast R-CNN and RT-DETR exhibit slightly lower FPS compared to YOLOv8s, they still achieve an impressive FPS of 90.3 f·s−1, thereby satisfying the requirements for real-time processing.
3.4.4. Visualization Experiment
4. Discussion
- (1).
- This study adopts YOLOv11 as the benchmark model for enhancement. Additionally, there are several high-performance deep-learning networks that can be utilized to develop models for detecting underground personnel and safety helmets. Further research is necessary to explore the integration and analysis of various methods in the future.
- (2).
- The real-time detection performance of GCB-YOLOv11 could potentially be further improved by incorporating lightweight network concepts into the model. However, finding the right balance between detection accuracy and real-time performance is a critical consideration for future research.
- (3).
- Although the Bi FPN mechanism has been introduced to enhance multi-scale feature fusion, GCB-YOLOv11 may still experience issues related to leakage or false detection when identifying very small or highly overlapping objects. This is primarily due to the small size and dense distribution of personnel and helmets in the mining environment.
- (4).
- The environment at the mine working face is complex and dynamic, often characterized by disruptive factors such as dust and smoke. While GCB-YOLOv11 demonstrates commendable performance on the current dataset, its detection efficacy may be compromised in various mining contexts or under extreme environmental conditions. Therefore, further validation and optimization are essential to enhance its adaptability to diverse environments.
5. Conclusions
- (1).
- The GCB-YOLOv11 model, designed for detecting underground personnel and safety helmets in coal mines, is proposed. This model integrates three significant modules, GSConv, C3K2-FE, and Bi FPN, which are based on the baseline model. GSConv allows the model to group and shuffle features, thereby reducing complexity while maintaining detection accuracy. The C3K2_FE module, developed from the C3K2 structure, is applied throughout the entire network. This module not only improves the model’s real-time performance but also achieves high detection accuracy. Additionally, the Bi FPN mechanism effectively enhances the fusion efficiency of features at different scales through cross-layer operations.
- (2).
- Based on my self-constructed dataset of mine personnel and safety helmets, the GCB-YOLOv11 model was evaluated. The experimental results demonstrated that the average accuracy of the GCB-YOLOv11 model reached 93.6%, while its real-time detection performance achieved 90.3 f·s⁻¹. Additionally, the occurrence of missed detections was significantly reduced, effectively fulfilling the detection requirements for mine personnel and safety helmets. This provides a technical solution to enhance the safety of coal mine workers.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, G.F.; Zhao, G.R.; Ren, H. Analysis on key technologies of intelligent coal mine and intelligent mining. J. China Coal Soc. 2019, 44, 34–41. [Google Scholar]
- Li, S.; Xue, G.; Fang, X.; Yang, Q.; He, C.; Han, S.; Kang, Y. Coal mine intelligent safety system and key technologies. J. China Coal Soc. 2020, 45, 2320–2330. [Google Scholar]
- Wang, G.F.; Zhao, G.R.; Hu, Y. Application Prospect of 5G technology in coal mine intelligence. J. China Coal Soc. 2019, 45, 16–23. [Google Scholar]
- Liu, F.; Cao, W.; Zhang, J.; Cao, G.; Guo, L. Progress of scientific and technological innovation in China’s coal industry and the development direction of the 14th Five-Year Plan. J. China Coal Soc. 2021, 46, 1–15. [Google Scholar]
- Jin, Z.X.; Wang, H.W.; Fu, X. Development path of new generation intelligent coal mine under HCPS theory system. J. Mine Autom. 2022, 48, 1–12. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; pp. 886–893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–24 June 2014; pp. 580–587. [Google Scholar]
- Chen, H.; Zendehdel, N.; Leu, M.C.; Yin, Z. Fine-grained activity classification in assembly based on multi-visual modalities. J. Intell. Manuf. 2024, 35, 2215–2233. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Li, Z.H.; Zhang, L. Safety helmet wearing detection method of improved YOLOv3. Foreign Electron. Meas. Technol. 2022, 41, 148–155. [Google Scholar]
- Xie, G.; Tang, J.; Lin, Z.; Zheng, X.; Fang, M. Improved YOLOv4 Helmet Detection Algorithm Under Complex Scenarios. Laser Optoelectron. Prog. 2023, 60, 139–147. [Google Scholar]
- Yang, Y.B.; Li, D. Lightweight helmet wearing detection algorithm of improved YOLOv5. Comput. Eng. Appl. 2022, 58, 201–207. [Google Scholar]
- Zhang, J.; Feng, Y.Y.; Li, H.; Du, S.; Mo, J. Safety helmet recognition algorithm in spray dust removal scenario of coal mine working face. Min. Saf. Environ. Prot. 2024, 51, 9–16. [Google Scholar]
- Di, J.Y.; Yang, C.Y. Underground personnel detection based on improved transformer. Sci. Technol. Eng. 2024, 24, 11188–11194. [Google Scholar]
- Shao, X.; Li, X.; Yang, Y.; Yuan, Z.; Yang, T. Mine personnel detection algorithm based on improved YOLOv7. J. Univ. Electron. Sci. Technol. China 2024, 53, 414–423. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement[EB/OL]. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection [EB/OL]. arXiv 2023, arXiv:2004.10934. [Google Scholar]
- Song, Q.S.; Li, S.B.; Bai, Q.; Yang, J.; Zhang, X.; Li, Z.; Duan, Z. Object detection method for grasping robot based on improved YOLOv5. Micromachines 2021, 12, 1273. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Zeng, G.M.; Yu, W.N.; Wang, R.J.; Lin, A.H. Research on mosaic image data enhancement and detection method for overlapping ship targets. Control. Theory Appl. 2022, 39, 1139–1148. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetv2: Inverted residuals and inear- bottenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recoanition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.Y.; Lin, M.X.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Cui, Z.; Wang, N.; Su, Y.Z.; Zhang, W.; Lan, Y.; Li, A. ECANet: Enhanced context aggregation network for single image dehazing. Signal Image Video Process. 2023, 17, 471–479. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Cheng, L. A Highly Robust Helmet Detection Algorithm Based on YOLO V8 and Transformer. IEEE Access 2024, 12, 130693–130705. [Google Scholar] [CrossRef]
- Du, Q.; Zhang, S.; Yang, S. BLP-YOLOv10: Efficient safety helmet detection for low-light mining. J. Real-Time Image Proc. 2025, 22, 10. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Set Value |
|---|---|
| Image size | 640 × 640 |
| Training frequency | 300 |
| Batch | 32 |
| Training optimizer | SGD |
| Lr0 | 0.01 |
| Weight attenuation coefficient | 0.0005 |
| Model | GSConv | C3K2_FE | Bi FPN | mAP@0.5/% | Params/M | FLOPs/G | FPS/f·s−1 |
|---|---|---|---|---|---|---|---|
| Baseline | — | — | — | 90.3 | 2.6 | 6.5 | 82.5 |
| A | √ | — | — | 90.9 | 2.3 | 5.8 | 79.2 |
| B | — | √ | — | 91.1 | 2.1 | 4.9 | 87.7 |
| C | — | — | √ | 90.5 | 1.9 | 6.3 | 75.2 |
| D | √ | √ | — | 91.5 | 1.8 | 4.4 | 82.6 |
| E(our) | √ | √ | √ | 93.6 | 1.6 | 4.5 | 90.3 |
| Model | mAP@0.5/% | Params/M | FLOPs/G | FPS/f·s−1 |
|---|---|---|---|---|
| YOLOv3-Tiny | 88.7 | 9.5 | 14.3 | 83.3 |
| YOLOv5s | 90.1 | 5.4 | 13.9 | 82.0 |
| YOLOv8s | 90.0 | 9.8 | 23.3 | 90.4 |
| YOLOv11n | 90.3 | 2.6 | 6.5 | 82.5 |
| Fast R-CNN | 89.9 | 40.0 | 207.1 | 54.2 |
| RT-DETR | 91.5 | 42.8 | 130.5 | 59.7 |
| EfficientDet | 90.0 | 6.8 | 6.1 | 88.6 |
| HRHD-YOLOv8 | 90.2 | 12.5 | 27.4 | 68.3 |
| BLP-YOLOv10 | 89.6 | 3.28 | 9.8 | 80.0 |
| GCB-YOLOv11 | 93.6 | 1.6 | 4.5 | 90.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Sun, Z.; Tao, H.; Wang, M.; Yi, W. Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11. Sensors 2025, 25, 170. https://doi.org/10.3390/s25010170
Zhang L, Sun Z, Tao H, Wang M, Yi W. Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11. Sensors. 2025; 25(1):170. https://doi.org/10.3390/s25010170
Chicago/Turabian StyleZhang, Lei, Zhipeng Sun, Hongjing Tao, Meng Wang, and Weixun Yi. 2025. "Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11" Sensors 25, no. 1: 170. https://doi.org/10.3390/s25010170
APA StyleZhang, L., Sun, Z., Tao, H., Wang, M., & Yi, W. (2025). Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11. Sensors, 25(1), 170. https://doi.org/10.3390/s25010170