
Real-Time Multi-Person Video Synthesis with Controllable Prior-Guided Matting



Abstract
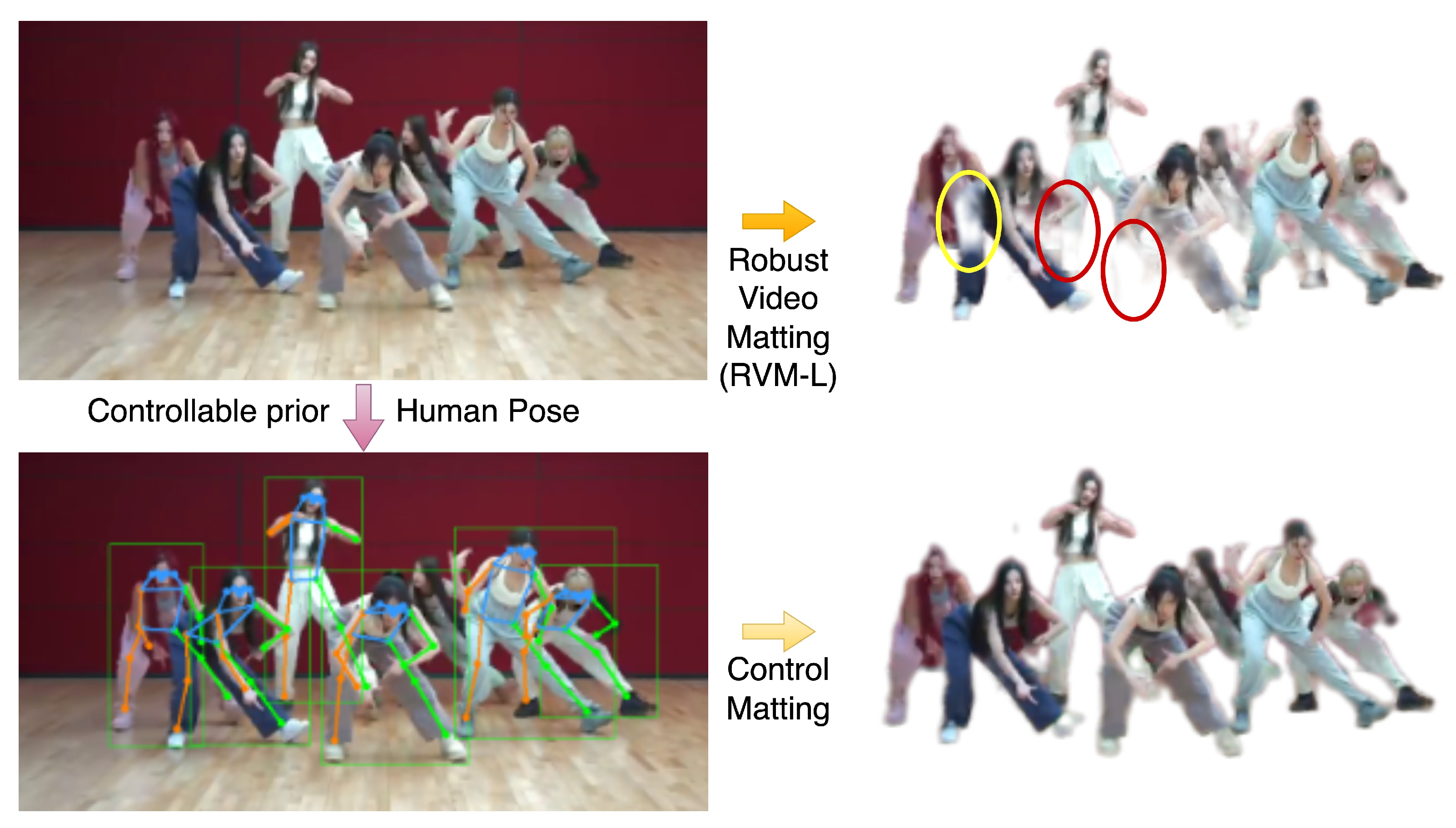
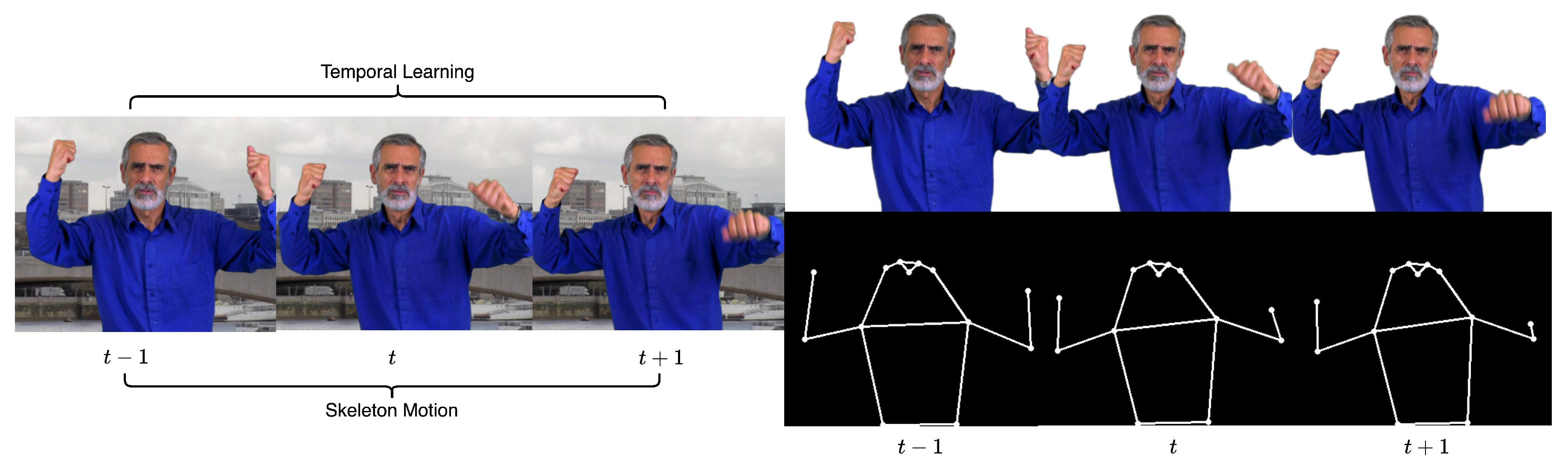
1. Introduction

- We design a controllable encoder to build the recurrent matting model with generative architecture. Controllable human body prior information can obviously preserve the quality of alphas in complex, dynamic, multi-person videos.
- We propose a learnable and mask-guided image filter algorithm to augment the edge detail of each human alpha, which can effectively improve the video matting quality.
- We evaluate our ControlMatting model on the VM and AIM datasets, and experimental results prove that ControlMatting can achieve the state of the art on all metrics. Compared with the frame-by-frame-based matting model, we consistently obtain significant improvements.
2. Related Work
2.1. Classical and Trimap-Based Matting
2.2. Auxiliary-Free Video Matting
2.3. Instance Segmentation and VSOD
2.4. Generative Model
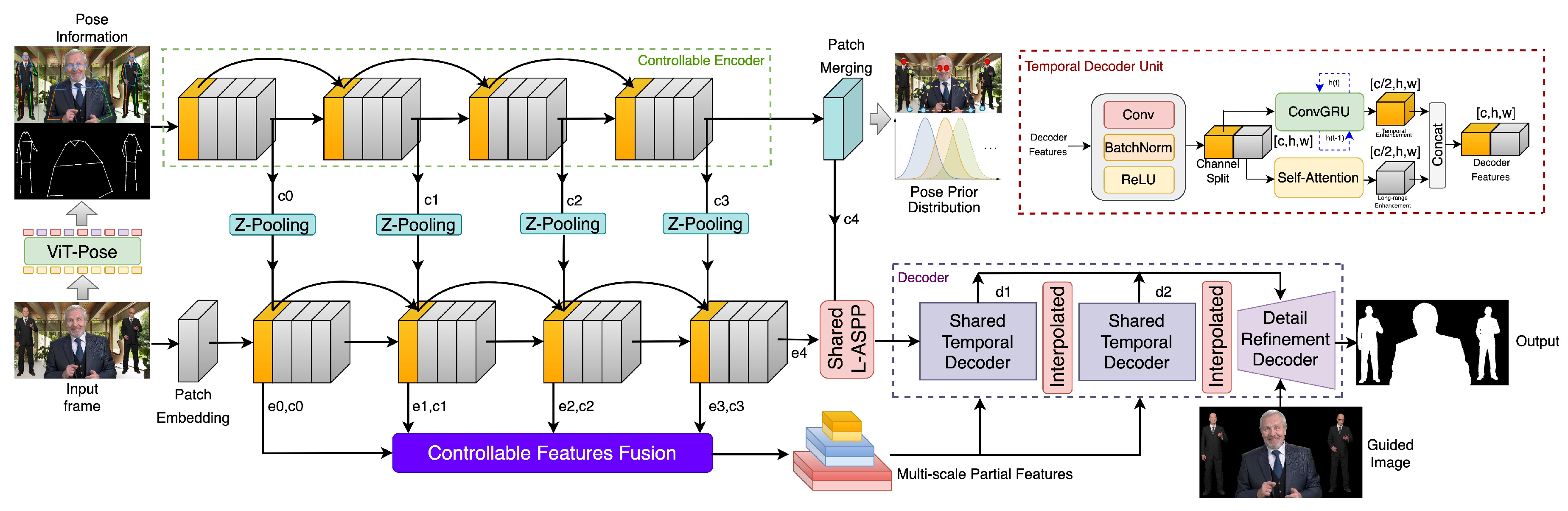
3. Methods
3.1. Network Architecture
3.2. Controllable Encoder
3.3. Progressive Refined Filter
4. Experimental Results
4.1. Experimental Setting
4.1.1. Dataset Information
4.1.2. Training Strategy
- Stage 1: We train the base encoder, L-ASPP layer, and the shared decoder for 20 epochs. The dataset is used for matting training, and the semantic segmentation dataset is inserted intermittently in every epoch iteration. Our machine can afford 25 frames of training at the same time, so we set the sequence length as 25. The base encoder backbone is initialized by FasterNet*, and the learning rate is 1 × . Other blocks adopt 2 × as the learning rate.
- Stage 2: Before Stage 2 training, we copy the parameters in the base encoder into a controllable encoder to save on training time. The base encoder is still trained with a small learning rate, 1 × , and the controllable encoder with a large learning rate, 1 × . Our two encoders use a unified L-ASPP middle layer and a shared decoder, with the same learning rate in Stage 1, and are trained for 5 more epochs. The semantic segmentation dataset is no longer needed.
- Stage 3: We train high-resolution videos and images here, and the VM and AIM datasets are used to create composite training frames, which need a detailed refinement decoder to recover the edge information. We train the whole model for 5 more epochs and set the base encoder learning rate as 1 × , the controllable encoder as 2 × , the detailed refiner decoder as 2 × , and the others as 1 × .
4.1.3. Loss Functions
4.2. Evaluation on HD/SD Datasets
4.3. Ablation Studies



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | L-ASPP | Detailed Refiner | CE | Size | MAD (1 × 103) | MSE (1 × 103) | Grad | Conn | dtSSD (1 × 102) |
|---|---|---|---|---|---|---|---|---|---|
| MobileNet-v3 | - | - | - | 512 × 288 | 6.08 | 1.47 | 0.88 | 0.41 | 1.36 |
| ResNet-50 | - | - | - | 512 × 288 | 5.66 | 0.92 | 0.75 | 0.37 | 1.32 |
| ResNet-101 | - | - | - | 512 × 288 | 5.62 | 0.91 | 0.72 | 0.34 | 1.29 |
| FasterNet | - | - | - | 512 × 288 | 28.81 | 17.16 | 5.35 | 3.53 | 2.24 |
| FasterNet* | - | - | - | 512 × 288 | 5.40 | 0.88 | 0.71 | 0.29 | 1.19 |
| FasterNet* | ✓ | - | - | 512 × 288 | 5.39 | 0.88 | 0.69 | 0.28 | 1.17 |
| FasterNet* | ✓ | - | ✓ | 512 × 288 | 5.31 | 0.79 | 0.65 | 0.26 | 1.08 |
| FasterNet* | ✓ | - | - | 1920 × 1080 | 5.54 | 0.91 | 9.32 | - | 1.82 |
| FasterNet* | ✓ | ✓ | - | 1920 × 1080 | 5.51 | 0.91 | 9.25 | - | 1.68 |
| FasterNet* | ✓ | ✓ | ✓ | 1920 × 1080 | 5.46 | 0.87 | 9.20 | - | 1.62 |
4.4. Speed Comparison
| Model | Parameters | Size | GMACs | FPS |
|---|---|---|---|---|
| DeepLabV3 + FBA | 95.68 M | 233.3 M | 205.77 | 5.3 |
| BGMv2 | 5.01 M | 19.4 M | 8.46 | 48.5 |
| MODNet | 6.49 M | 25.0 M | 8.80 | 178.5 |
| RVM | 3.75 M | 14.5 M | 4.57 | 145.7 |
| RVM-Large | 26.89 M | 102.9 M | 98.68 | 86.8 |
| Our Model | 17.54 M | 67.08 M | 29.95 | 93.8 |
| Our Model + CE | 32.78 M | 125.4 M | 52.58 | 61.5 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, S.; Ryabtsev, A.; Sengupta, S.; Curless, B.L.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Real-time high-resolution background matting. In Proceedings of theIEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8762–8771. [Google Scholar]
- Ke, Z.; Sun, J.; Li, K.; Yan, Q.; Lau, R.W. Modnet: Real-time trimap-free portrait matting via objective decomposition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 1140–1147. [Google Scholar]
- Lin, S.; Yang, L.; Saleemi, I.; Sengupta, S. Robust high-resolution video matting with temporal guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 238–247. [Google Scholar]
- Sengupta, S.; Jayaram, V.; Curless, B.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Background matting: The world is your green screen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2291–2300. [Google Scholar]
- Gu, Z.; Chen, H.; Xu, Z.; Lan, J.; Meng, C.; Wang, W. Diffusioninst: Diffusion model for instance segmentation. arXiv 2022, arXiv:2212.02773. [Google Scholar]
- Zhang, M.; Liu, J.; Wang, Y.; Piao, Y.; Yao, S.; Ji, W.; Li, J.; Lu, H.; Luo, Z. Dynamic context-sensitive filtering network for video salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1553–1563. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X.; et al. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.N. ECFFNet: Effective and consistent feature fusion network for RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1224–1235. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Chen, T.; Fang, C.; Shen, X.; Zhu, Y.; Chen, Z.; Luo, J. Anatomy-aware 3d human pose estimation with bone-based pose decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 198–209. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action recognition with spatio–temporal visual attention on skeleton image sequences. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2405–2415. [Google Scholar] [CrossRef]
- Lin, K.; Wang, L.; Luo, K.; Chen, Y.; Liu, Z.; Sun, M.T. Cross-domain complementary learning using pose for multi-person part segmentation. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1066–1078. [Google Scholar] [CrossRef]
- Yi, P.; Wang, Z.; Jiang, K.; Shao, Z.; Ma, J. Multi-temporal ultra dense memory network for video super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2503–2516. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, K.; Ren, S.; Hu, B.; Hu, M.; Fang, H. Lightweight image super-resolution with expectation-maximization attention mechanism. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1273–1284. [Google Scholar] [CrossRef]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3911–3927. [Google Scholar] [CrossRef]
- Ning, X.; Gong, K.; Li, W.; Zhang, L.; Bai, X.; Tian, S. Feature refinement and filter network for person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3391–3402. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, T.; Shi, J. Deep image blending. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 231–240. [Google Scholar]
- Kang, Z.; Li, Z.; Liu, Q.; Zhu, Y.; Zhou, H.; Zhang, S. Lightweight Image Matting via Efficient Non-Local Guidance. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 2884–2900. [Google Scholar]
- Yu, H.; Xu, N.; Huang, Z.; Zhou, Y.; Shi, H. High-resolution deep image matting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3217–3224. [Google Scholar]
- Ding, H.; Zhang, H.; Liu, C.; Jiang, X. Deep interactive image matting with feature propagation. IEEE Trans. Image Process. 2022, 31, 2421–2432. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Liu, B.; Quan, Y.; Ji, H. Unsupervised deep background matting using deep matte prior. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4324–4337. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Cui, M.; Ren, P.; Xie, X.; Hua, X.S.; Bao, H.; Huang, Q.; Xu, W. Attention-guided temporally coherent video object matting. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5128–5137. [Google Scholar]
- Liu, C.; Ding, H.; Jiang, X. Towards enhancing fine-grained details for image matting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 385–393. [Google Scholar]
- Sun, Y.; Wang, G.; Gu, Q.; Tang, C.K.; Tai, Y.W. Deep video matting via spatio-temporal alignment and aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6975–6984. [Google Scholar]
- Li, J.; Zhang, J.; Maybank, S.J.; Tao, D. Bridging composite and real: Towards end-to-end deep image matting. Int. J. Comput. Vis. 2022, 130, 246–266. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, J.; Shi, X.; Qiao, Y.; Huang, Y.; Tang, Y.; Yang, X. Tripartite information mining and integration for image matting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7555–7564. [Google Scholar]
- Cai, H.; Xue, F.; Xu, L.; Guo, L. Transmatting: Enhancing transparent objects matting with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 253–269. [Google Scholar]
- Park, G.; Son, S.; Yoo, J.; Kim, S.; Kwak, N. Matteformer: Transformer-based image matting via prior-tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11696–11706. [Google Scholar]
- Wang, T.; Liu, S.; Tian, Y.; Li, K.; Yang, M.H. Video matting via consistency-regularized graph neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4902–4911. [Google Scholar]
- Sun, Y.; Tang, C.K.; Tai, Y.W. Human instance matting via mutual guidance and multi-instance refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2647–2656. [Google Scholar]
- Seong, H.; Oh, S.W.; Price, B.; Kim, E.; Lee, J.Y. One-trimap video matting. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 430–448. [Google Scholar]
- Yu, Q.; Zhang, J.; Zhang, H.; Wang, Y.; Lin, Z.; Xu, N.; Bai, Y.; Yuille, A. Mask guided matting via progressive refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1154–1163. [Google Scholar]
- Chen, G.; Liu, Y.; Wang, J.; Peng, J.; Hao, Y.; Chu, L.; Tang, S.; Wu, Z.; Chen, Z.; Yu, Z.; et al. PP-matting: High-accuracy natural image matting. arXiv 2022, arXiv:2204.09433. [Google Scholar]
- Li, J.; Ohanyan, M.; Goel, V.; Navasardyan, S.; Wei, Y.; Shi, H. VideoMatt: A Simple Baseline for Accessible Real-Time Video Matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2176–2185. [Google Scholar]
- Lin, C.C.; Wang, J.; Luo, K.; Lin, K.; Li, L.; Wang, L.; Liu, Z. Adaptive Human Matting for Dynamic Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10229–10238. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1838–1847. [Google Scholar]
- Sun, Y.; Tang, C.K.; Tai, Y.W. Semantic image matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11120–11129. [Google Scholar]
- Cong, R.; Song, W.; Lei, J.; Yue, G.; Zhao, Y.; Kwong, S. PSNet: Parallel symmetric network for video salient object detection. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 402–414. [Google Scholar] [CrossRef]
- Cong, R.; Lei, J.; Fu, H.; Cheng, M.M.; Lin, W.; Huang, Q. Review of visual saliency detection with comprehensive information. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2941–2959. [Google Scholar] [CrossRef]
- Su, Y.; Deng, J.; Sun, R.; Lin, G.; Su, H.; Wu, Q. A unified transformer framework for group-based segmentation: Co-segmentation, co-saliency detection and video salient object detection. IEEE Trans. Multimed. 2023, 26, 313–325. [Google Scholar] [CrossRef]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Chen, C.; Song, J.; Peng, C.; Wang, G.; Fang, Y. A novel video salient object detection method via semisupervised motion quality perception. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2732–2745. [Google Scholar] [CrossRef]
- Zheng, Q.; Li, Y.; Zheng, L.; Shen, Q. Progressively real-time video salient object detection via cascaded fully convolutional networks with motion attention. Neurocomputing 2022, 467, 465–475. [Google Scholar] [CrossRef]
- Huang, K.; Tian, C.; Su, J.; Lin, J.C.W. Transformer-based cross reference network for video salient object detection. Pattern Recognit. Lett. 2022, 160, 122–127. [Google Scholar] [CrossRef]
- Ren, X.; Liu, Y.; Song, C. A generative adversarial framework for optimizing image matting and harmonization simultaneously. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1354–1358. [Google Scholar]
- Li, Y.; Zhang, J.; Zhao, W.; Jiang, W.; Lu, H. Inductive Guided Filter: Real-Time Deep Matting with Weakly Annotated Masks on Mobile Devices. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Cun, X.; Pun, C.M.; Shi, C. Towards ghost-free shadow removal via dual hierarchical aggregation network and shadow matting gan. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10680–10687. [Google Scholar]
- Lu, E.; Cole, F.; Dekel, T.; Zisserman, A.; Freeman, W.T.; Rubinstein, M. Omnimatte: Associating objects and their effects in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4507–4515. [Google Scholar]
- Gu, Z.; Xian, W.; Snavely, N.; Davis, A. Factormatte: Redefining video matting for re-composition tasks. ACM Trans. Graph. (TOG) 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. arXiv 2022, arXiv:2211.09788. [Google Scholar]
- Zhang, L.; Agrawala, M. Adding conditional control to text-to-image diffusion models. arXiv 2023, arXiv:2302.05543. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2970–2979. [Google Scholar]
- Yang, L.; Fan, Y.; Xu, N. Video instance segmentation. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5188–5197. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Niklaus, S.; Liu, F. Context-aware synthesis for video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1701–1710. [Google Scholar]

| Model | MAD (1 × 103) | MSE (1 × 103) | Grad | Conn | dtSSD (1 × 102) |
|---|---|---|---|---|---|
| DeepLabV3 | 14.47 | 9.67 | 8.55 | 1.69 | 5.18 |
| FBA | 8.36 | 3.37 | 2.09 | 0.75 | 2.09 |
| BGMv2 | 25.19 | 19.63 | 2.28 | 3.26 | 2.74 |
| MODNet | 9.41 | 4.30 | 1.89 | 0.81 | 2.23 |
| VideoMatte | 6.06 | 1.27 | 1.09 | 0.42 | 1.60 |
| RVM | 6.08 | 1.47 | 0.88 | 0.41 | 1.36 |
| RVM-Large | 5.66 | 0.92 | 0.75 | 0.37 | 1.32 |
| Our Model | 5.39 | 0.88 | 0.69 | 0.28 | 1.17 |
| Our Model + CE | 5.31 | 0.79 | 0.65 | 0.26 | 1.08 |
| Model | MAD (1 × 103) | MSE (1 × 103) | Grad | Conn | dtSSD | Fgr (1 × 103) |
|---|---|---|---|---|---|---|
| DeepLabV3 | 29.64 | 23.78 | 20.17 | 7.71 | 432 | - |
| FBA | 23.45 | 17.66 | 9.05 | 6.05 | 229 | 6.32 |
| BGMv2 | 44.61 | 39.08 | 5.54 | 11.60 | 269 | 3.31 |
| MODNet | 21.66 | 14.27 | 5.37 | 5.23 | 176 | 9.51 |
| RVM | 14.84 | 8.93 | 4.35 | 3.83 | 101 | 5.01 |
| RVM-Large | 13.48 | 4.58 | 3.95 | 3.38 | 98 | 4.79 |
| Our Model | 11.86 | 4.28 | 3.73 | 3.25 | 94 | 4.55 |
| Ours + CE | 11.32 | 4.19 | 3.68 | 3.09 | 90 | 4.33 |
| Model | MAD (1 × 103) | MSE (1 × 103) | Grad | dtSSD (1 × 102) |
|---|---|---|---|---|
| MODNet | 11.13 | 5.54 | 15.30 | 3.08 |
| RVM | 6.57 | 1.93 | 10.55 | 1.90 |
| RVM-Large | 5.81 | 0.97 | 9.65 | 1.78 |
| Our Model | 5.51 | 0.91 | 9.25 | 1.68 |
| Ours + CE | 5.46 | 0.87 | 9.20 | 1.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.; Huang, H.; Zhu, Y.; Xue, J. Real-Time Multi-Person Video Synthesis with Controllable Prior-Guided Matting. Sensors 2024, 24, 2795. https://doi.org/10.3390/s24092795
Chen A, Huang H, Zhu Y, Xue J. Real-Time Multi-Person Video Synthesis with Controllable Prior-Guided Matting. Sensors. 2024; 24(9):2795. https://doi.org/10.3390/s24092795
Chicago/Turabian StyleChen, Aoran, Hai Huang, Yueyan Zhu, and Junsheng Xue. 2024. "Real-Time Multi-Person Video Synthesis with Controllable Prior-Guided Matting" Sensors 24, no. 9: 2795. https://doi.org/10.3390/s24092795
APA StyleChen, A., Huang, H., Zhu, Y., & Xue, J. (2024). Real-Time Multi-Person Video Synthesis with Controllable Prior-Guided Matting. Sensors, 24(9), 2795. https://doi.org/10.3390/s24092795