This section presents the related works in the literature and introduces the theoretical principles, such as the feature extraction technique and the architecture of the ML model.
2.1. Related Works
In the literature, there are a variety of strategies that perform load recognition. In Qaisar and Alsharif [
14], the authors use active power. Active power performs work in an electrical system and refers to the energy consumed by the appliance to operate. However, the study uses different procedures to classify each device category. The paper uses devices from the Appliance Consumption Signature-Fribourg 2 (ACS-F2) database and the accuracy metric to evaluate the performance of the SVM and kNN models at the devices’ classification stage. In Cabral et al. [
7], the authors exclusively use the active power profile of the household appliances in the REDD and REFIT datasets. In this reference, the
k-NN, Decision Tree (DT), Random Forest (RF), and SVM models can perform load recognition with a balance between short training time and high performance for the accuracy metrics, weighted average F1 score, and Kappa index.
Nonetheless, approaches do not necessarily only exploit the active power of a household appliance. The study reported by Mian Qaisar and Alsharif [
8] uses active and reactive power. Reactive power in an alternating current system does not perform effective work, being stored and returned to the electrical system due to the presence of reactive elements, such as capacitors and inductors. In this case, the authors also apply accuracy to evaluate the performance of the ANN and
k-NN models. In Matindife et al. [
11], the researchers use a private dataset involving active power, current, and power factor. Here, by employing the Gramian Angular Difference Field (GADF) for feature extraction; the researchers convert the data into images. In the sequence, the CNN recognizes the appliances and the authors test the robustness of their proposal using the recall, precision, and accuracy metrics.
On the other hand, alternative studies utilize different types of data, as demonstrated in Borin et al. [
19], which employs instant current measurements. The study applies Vector Projection Classification (VPC) in pattern recognition of loads. In this reference, the authors assess the performance of the proposed approach through the percentage of identified devices. Some methods utilize a combination of these other variables, such as voltage and current, for instance. In Zhiren et al. [
16], the study uses a private dataset. The authors evaluate the proposed solution through accuracy metric, where the models tested are ELM, Adaboost-ELM, and SVM. In Faustine and Pereira [
10], the scientists employ the Plug Load Appliance Identification Dataset (PLAID) dataset and the F
1 example-based (F
1-eb) and F
1 macro-average (F
1-macro) metrics in their analysis. The methodology proposed in this reference focuses on the Fryze power theory, which decomposes the current characteristics into components. As a result, the current becomes an image-like representation and a CNN recognizes the loads.
Unlike the utilization of voltage and current profiles, certain studies consider alternative attributes. Heo et al. [
13] use Amplitude–Phase–Frequency (APF). The researchers employ accuracy and the F
1-Score as metrics to evaluate the overall performance of the proposed system and the following databases: Building-Level fully labeled Electricity Disaggregation (BLUED), PLAID, and a private database. As reported in the study, the use of HT-LSTM improves the recognition of devices with differences in the transient time and transient form of the load signal. Furthermore, the proposed scheme includes an event detection stage. Event detection is not always present in the strategies published in the literature but it is a tool that allows the system to identify when the appliance has turned on and off. The references Cabral et al. [
7], Anderson et al. [
20], Norford and Leeb [
21], and Le and Kim [
22] contain event detection strategies. It is relevant to mention that event detection is not the focus of our proposed work. Nevertheless, we use Wavelet transform to detect the ON/OFF status of the appliances according to references Lemes et al. [
6] and Cabral et al. [
7]. The selection of the Wavelet transform is justified due to its ability to detect appliance activity simply through the analysis of the level 1 detail coefficient. According to Lemes et al. [
6], level 1 already contains enough information to detect ON/OFF activity. Hence, detecting the ON/OFF activity of the appliance can be performed without needing to decompose the signal into higher levels.
Another significant factor is the volume of data involved in the proposed approaches; more attributes to consider mean a more computationally complex and invasive system. In Huang et al. [
12], the authors consider the steady-state power, the amplitude of the fundamental wave of the transient current, the transient voltage, and the harmonics of the transient current. In this case, the work adopts the REDD dataset and F
1-Score in the tests. The methodology combines LSTM layers with Back Propagation (BP) layers, resulting in the following architecture: the Long Short-Time Memory Back Propagation (LSTM-BP) network. The method described by Soe and Belleudy [
15] uses characteristics from the active power of the equipment present in the Appliance Consumption Signature-Fribourg 1 (ACS-F1). Such features are the maximum power, average power, standard deviation, number of signal processing, operating states, and activity number of the appliances. The article evaluates the performance of the SVM,
k-NN, CART, LDA, Logistic Regression (LR), and Naive Bayes (NB) models in terms of accuracy. It is worth emphasizing that as the diversity of electrical signals and parameters demanded from home appliances increases, the load recognition method becomes more intrusive and computationally expensive. For this reason, creating a strategy that has an optimal balance between high performance, reliability, and short training time based on a single type of electrical signal represents a key challenge in the load recognition field.
Finally, it is essential to mention some shortcomings in the methods proposed in the literature. Few studies use only one type of electrical signal in their approaches. The greater the number of electrical signals involved, the more invasive and computationally costly the method becomes. For example, the works of Mian Qaisar and Alsharif [
8], Qaisar and Alsharif [
14], and Zhiren et al. [
16] use many parameters excessively. On the other hand, the majority of existing studies do not include a stage for detecting the ON/OFF status of the equipment, for example, the works of Mian Qaisar and Alsharif [
8], Soe and Belleudy [
15], and Zhiren et al. [
16]. This condition limits the practical use of these methods. Most studies in the literature do not consider applying procedures to optimize their approaches, such as the hyperparameter search, for example, Faustine and Pereira [
10], Qaisar and Alsharif [
14], and Soe and Belleudy [
15]. Adopting this procedure supports the definition of classifier structural parameters and can provide additional performance gains. Other papers are not concerned with evaluating the reliability of the system.
2.2. Feature Extraction
Feature extraction concerns the process of transforming relevant characteristics from raw data to create more compact and informative representations. The extracted features describe distinctive properties of the data and practitioners widely apply this approach across several areas, such as image processing, according to Nixon and Aguado [
23] and Chowdhary and Acharjya [
24], signal processing, in line with Gupta et al. [
25] and Turhan-Sayan [
26], and ML according to Musleh et al. [
27] and Kumar and Martin [
28]. One of the advantages of some feature extraction techniques is the reduction in data dimensionality, thereby decreasing computational complexity.
Several techniques exist for feature extraction. The approach choice depends on the nature of the data, the task concerned, and the computational cost involved. Some studies, according to Veeramsetty et al. [
29] and Laakom et al. [
30], employ autoencoders for compact data representations. However, this kind of architecture can make methods computationally expensive. Alternative investigations use computational techniques that are less resource-intensive, such as in Reddy et al. [
31] with LDA, Fang et al. [
32] with Independent Component Analysis (ICA), and Bharadiya [
33] and Kabir et al. [
34] with PCA.
Currently, more modern methods employ NCA to eliminate redundant information to reduce computational cost, according to Ma et al. [
35]. NCA is a technique focusing on learning a distance metric in the feature space, optimizing the similarity between points without necessarily decreasing the dimensionality of the data. As per Goldberger et al. [
36], the NCA technique is based on
k-NN and stands out for optimizing a distance metric to enhance the quality of features, especially in classification tasks where the distinction between classes is crucial.
According to Singh-Miller et al. [
37], the NCA algorithm uses the training set as the input, i.e.,
with
∈
, and
with the set of labels
. The algorithm needs to learn a projection matrix
of dimension
, which it uses to project the training vectors
into a low-dimensional representation of dimension
q. To obtain low-dimensional projection, NCA requires learning a quadratic distance metric
, that optimize the performance of
k-NN. The distance
between two points,
and
, is
where
is the Frobenius norm and
is a linear transformation matrix. In the NCA technique, each point
i chooses another point
j as its neighbor from among
k points with a probability
and assumes the class label of the selected point. According to Goldberger et al. [
36], through
,
, and the optimization of the objective function
, NCA calculates a vector representation in a low-dimensional space (
). The vector in low-dimensionality can be represented by
It is possible to produce a matrix in low-dimensional space, depending on the implementation. This scenario is subject to the input data and the number of components required for the application. Detailed information regarding the NCA algorithm is available at Goldberger et al. [
36].
2.3. Extreme Learning Machine (ELM)
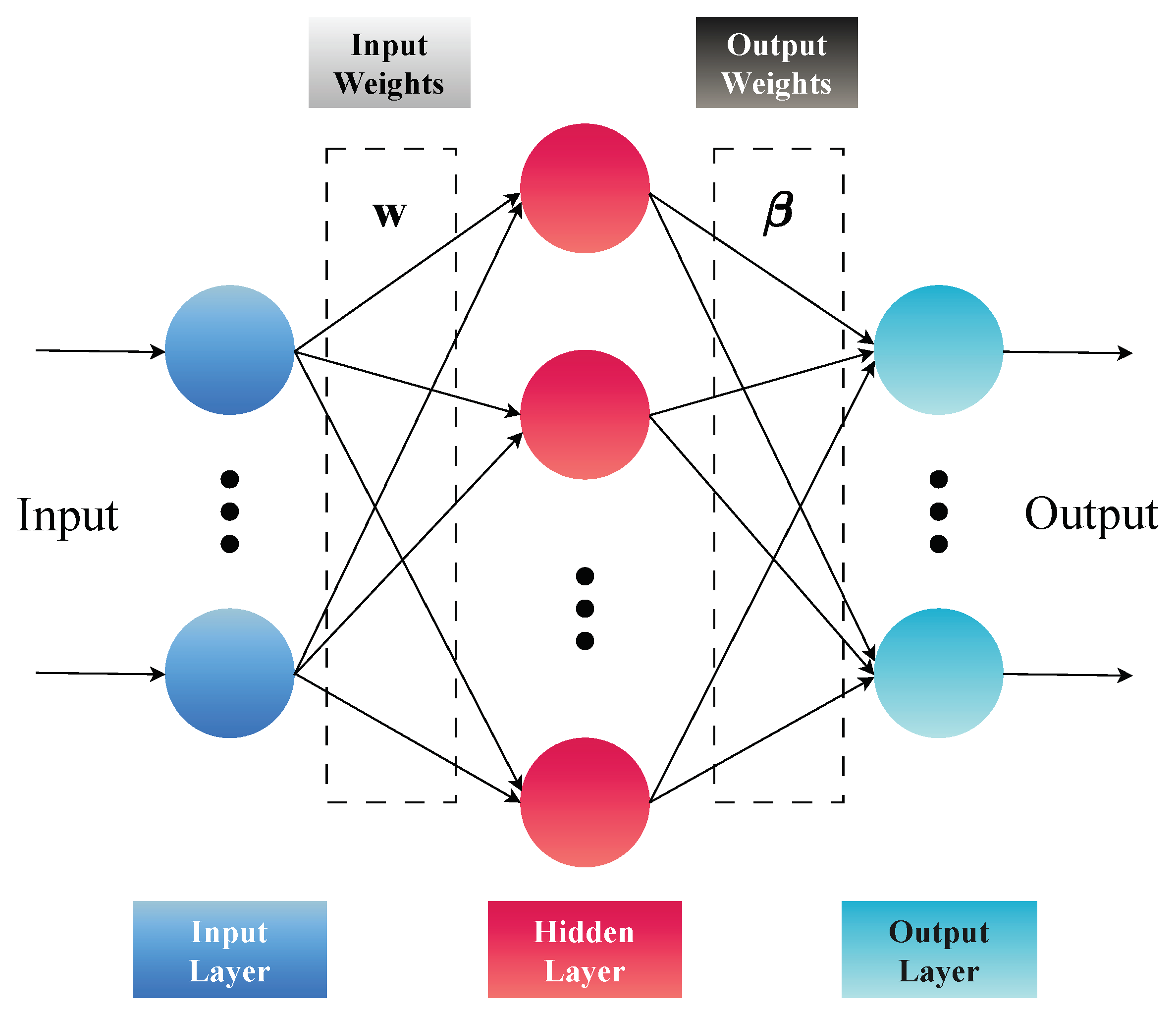
The ELM presents a visionary structure in the ML field, standing out for its computational efficiency and conceptual simplicity. In contrast to many conventional neural networks, where all parameters need adjustment during training, ELMs adopt a unique strategy by randomly fixing the weights of the hidden layer and focusing solely on learning the weights of the output layer. This methodology enables a short training time. Furthermore, the simplified architecture of ELMs facilitates implementation, making them an appealing choice for applications requiring computational efficiency and robust performance in supervised learning tasks.
As per the formal description of ELM in accordance with Huang et al. [
38], for different samples
, where
and
, the output of an ELM is
in which
is the input weight vector connecting the
ith hidden neuron,
is the output weight vector connecting the
ith hidden neuron,
is the bias,
L is the number of hidden neurons,
is the activation function, and
is the inner product. Nevertheless, the Equation (
3) can be written in the matrix form as
is the output matrix of the hidden layer of the neural network and can be expressed as follows:
where
However, we can solve the system described in (
4) through the Moore–Penrose pseudo-inverse of the
, depicted as
, where
. Consequently, we can determine the output weights by
Figure 1 illustrates the standard ELM, one of the ML models of the proposed system. Later in the manuscript, our approach includes modifications to the standard ELM to achieve enhanced results.

 ,
, 

{kind=link}
{kind=link}