
GBDT-IL: Incremental Learning of Gradient Boosting Decision Trees to Detect Botnets in Internet of Things

Abstract
1. Introduction
- 1
- We propose an improved feature selection method with Fisher Score, which filters out the best features based on the score and eliminates most irrelevant features. While ensuring high accuracy of the model, it further reduces the system resources required for model training, making the detection model applicable to resource-poor IoT devices.
- 2
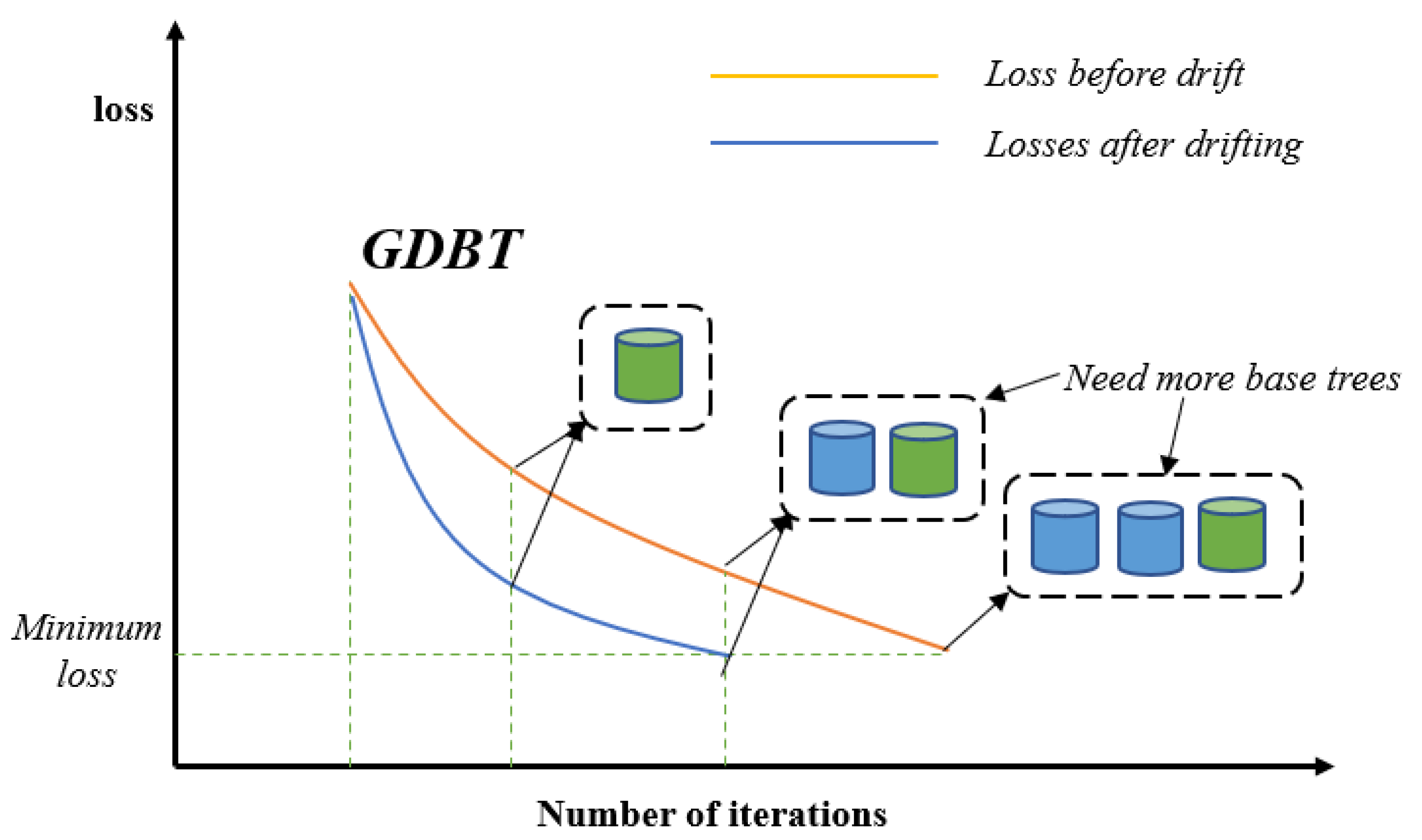
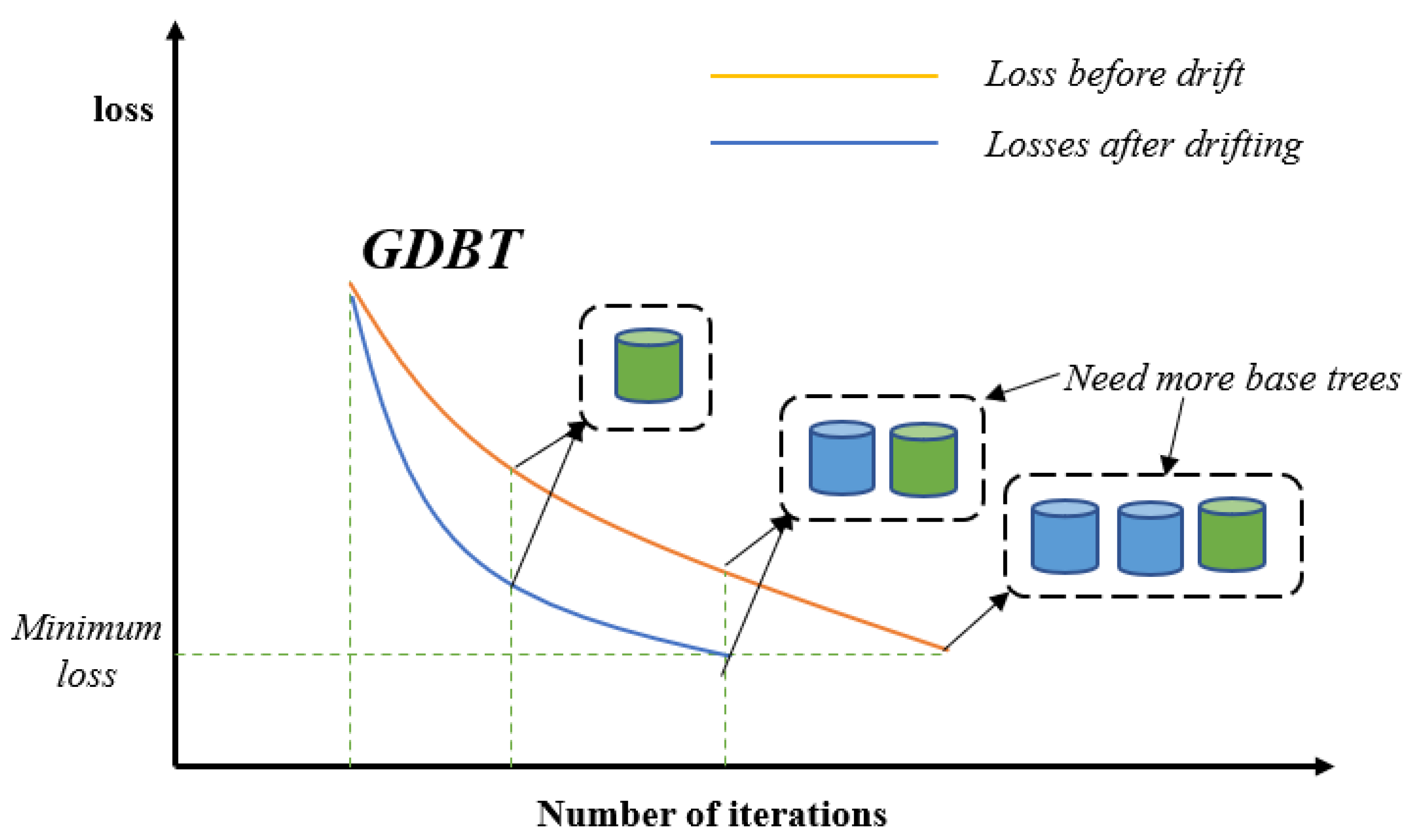
- We propose a gradient boosting decision-tree-improvement-based anti-conceptual drift algorithm, GBDT-IL (Gradient Boosting Decision Tree-incremental learning), which adapts to emerging data samples in the data stream by the incremental learning method. Also considering the overfitting due to the redundancy of the incremental learning process, the tree-pruning process is added to improve the model performance.
- 3
- We validate our method on four commonly used IoT datasets as well as their constructed drift datasets. The experimental results show that the improved feature selection method with Fisher Score outperforms and significantly reduces the training time of the model compared to existing feature selection methods. In addition, GBDT-IL is able to improve the model accuracy by more than 20% compared to traditional machine learning algorithms, and it also performs better than existing concept drift-resistant algorithms.
2. Related Works
2.1. Botnet Detection Methods
2.2. Concept Drift Detection
3. Proposed Method
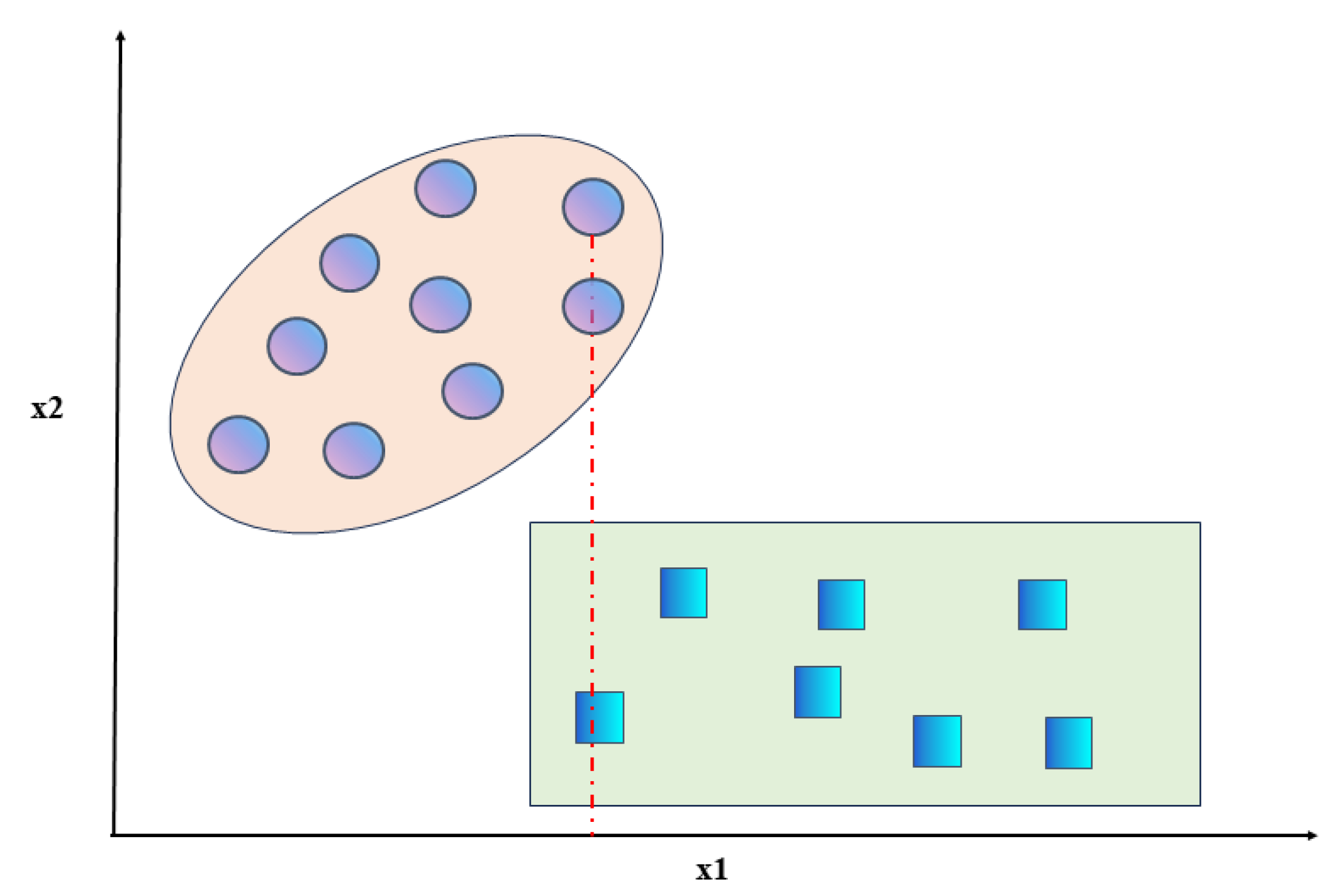
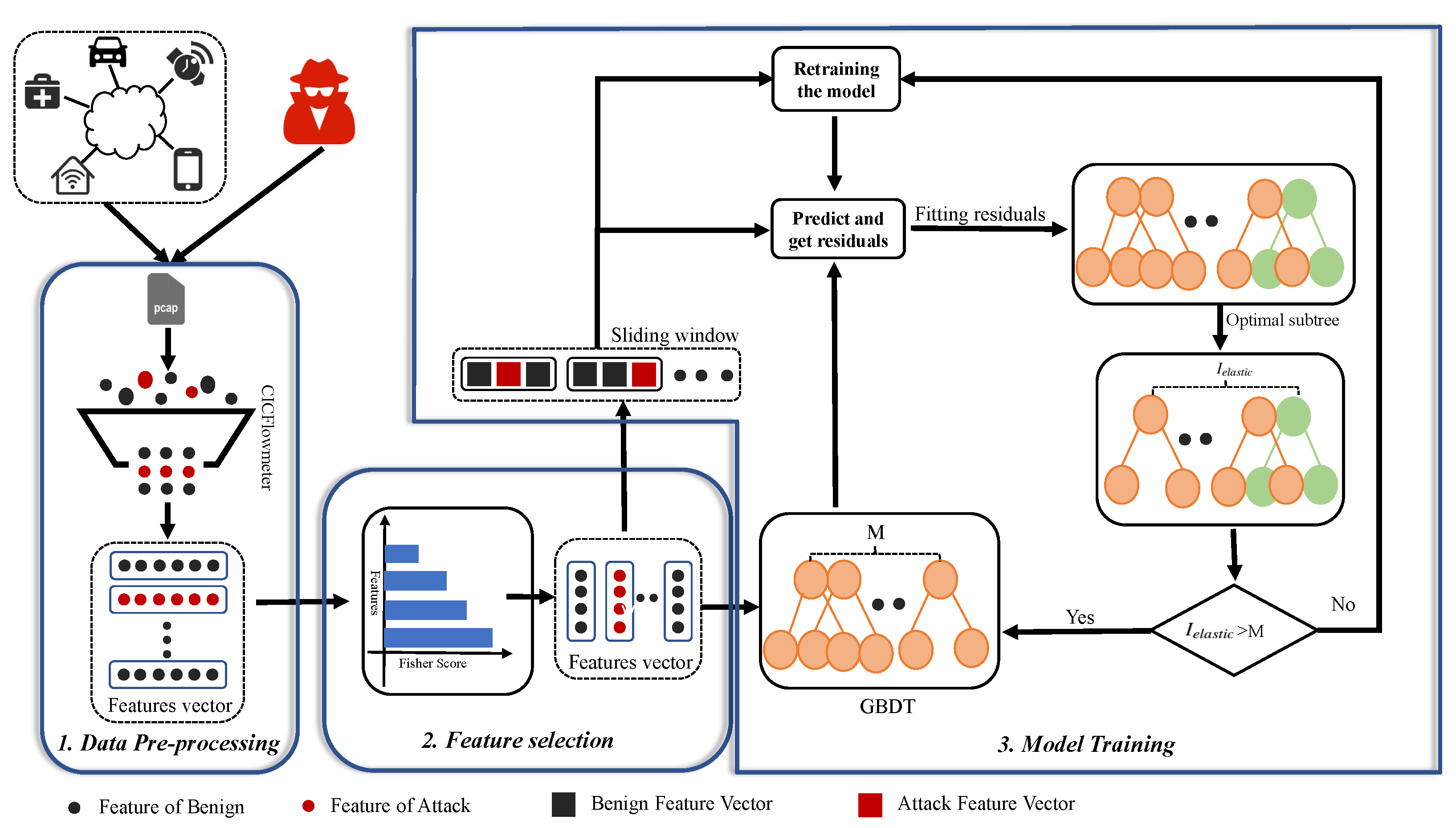
3.1. Data Pre-Processing
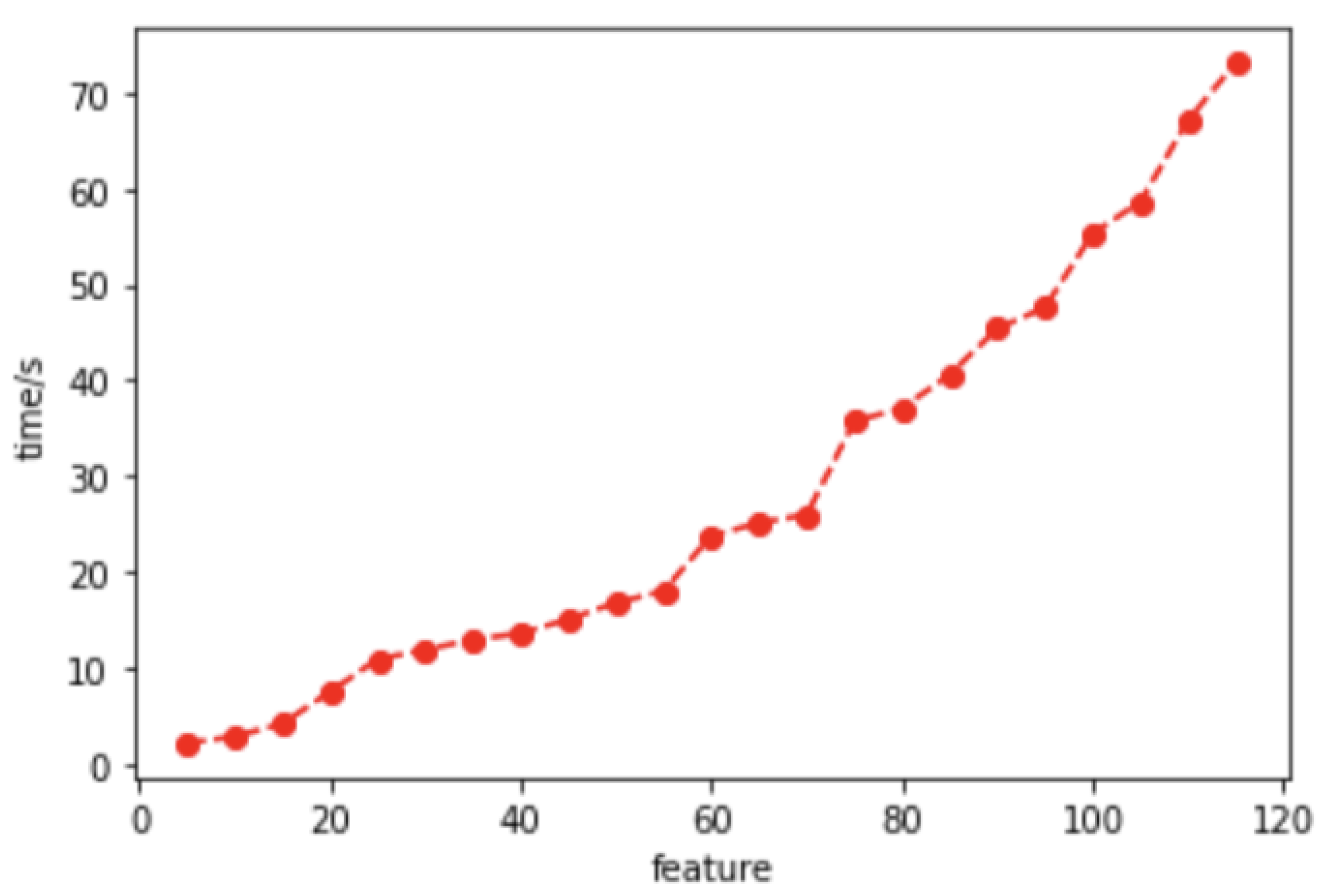
3.2. Feature Selection
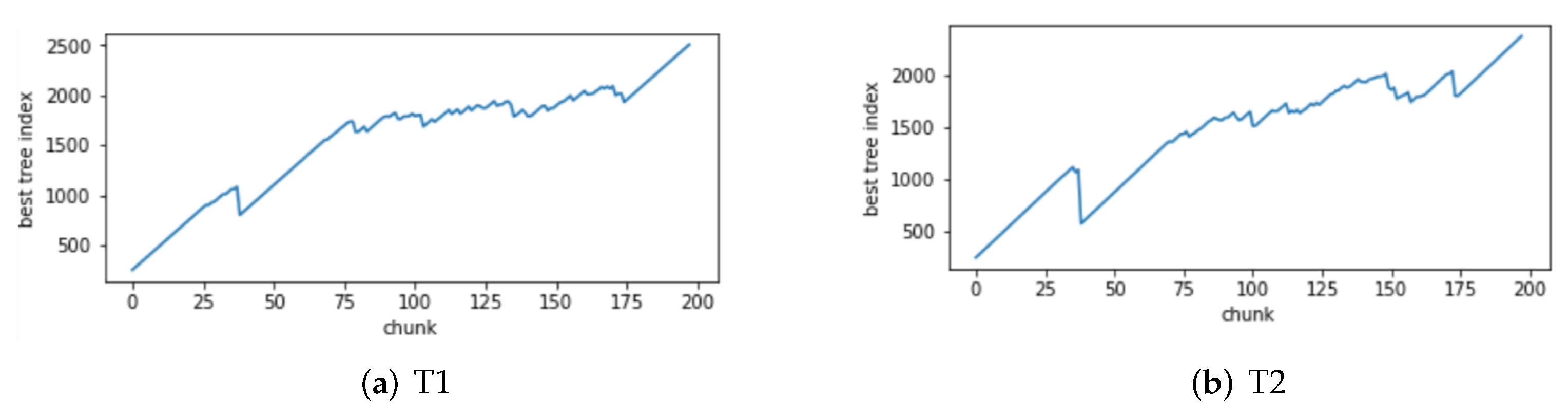
3.3. Model Training
| Algorithm 1 initial GBDT-IL |
| Input: Initial training window , Sliding window Output: Incremental GBDT model 1: Initialization 2: Train a GBDT model in the initial training block M 3: for to L do 4: Calculate the pseudo-residuals in a new slider using Equations (2)–(5) 5: Fitting the data in the new slider to generate a new regression tree 6: Update the model by Equations (3)–(5) 7: end for 8: return |
| Algorithm 2 GBDT-IL |
| Input: Trained GBDT model , Slider size Output: GBDT model after pruning, 1: Testing the GBDT model in a slider 2: Calculate each tree residual value based on the model output 3: Find the tree that minimizes the average absolute value of the residuals, and the number of trees is denoted as 4: if then 5: Retrain the GBDT model on a sliding block 6: Return the model after retraining 7: else 8: Pruning of the model 9: Return the model after pruning 10: end if |
4. Experimental Evaluation and Results
4.1. Experimental Environment
4.2. Dataset Description
4.3. Evaluation Criteria
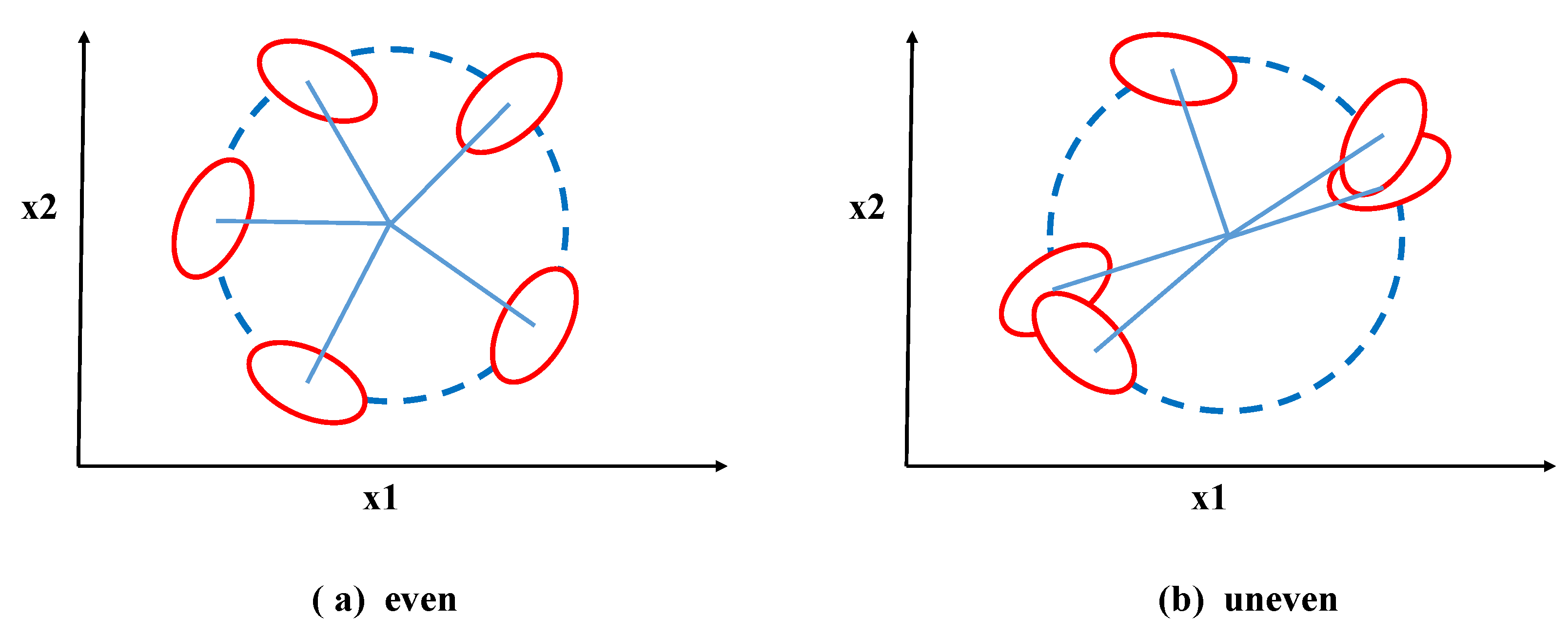
4.4. Concept Drift Design
4.5. Parameter Setting
4.6. Baseline Setting
4.7. Results and Analysis
4.7.1. Feature Dimensionality Reduction
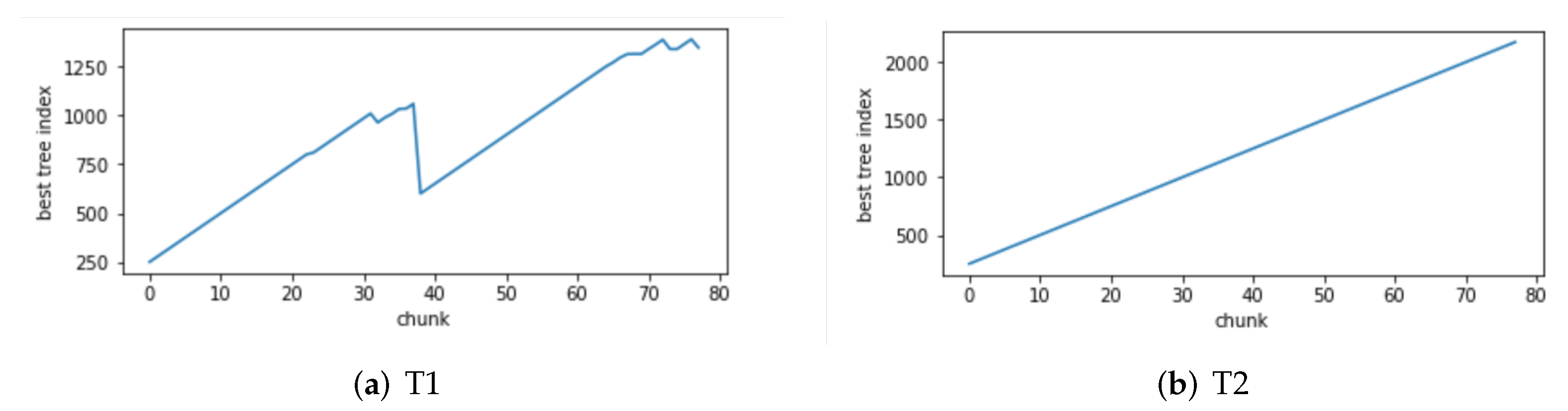
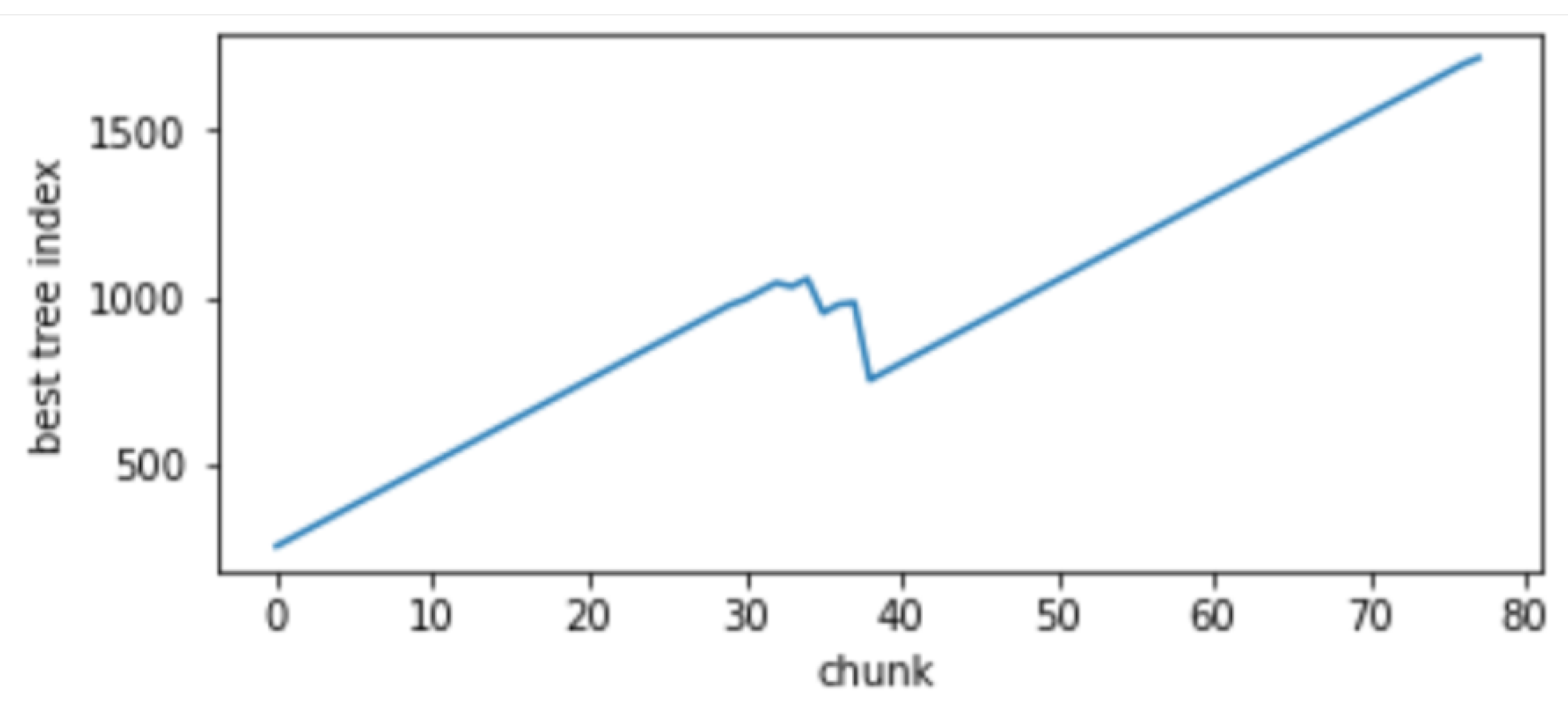
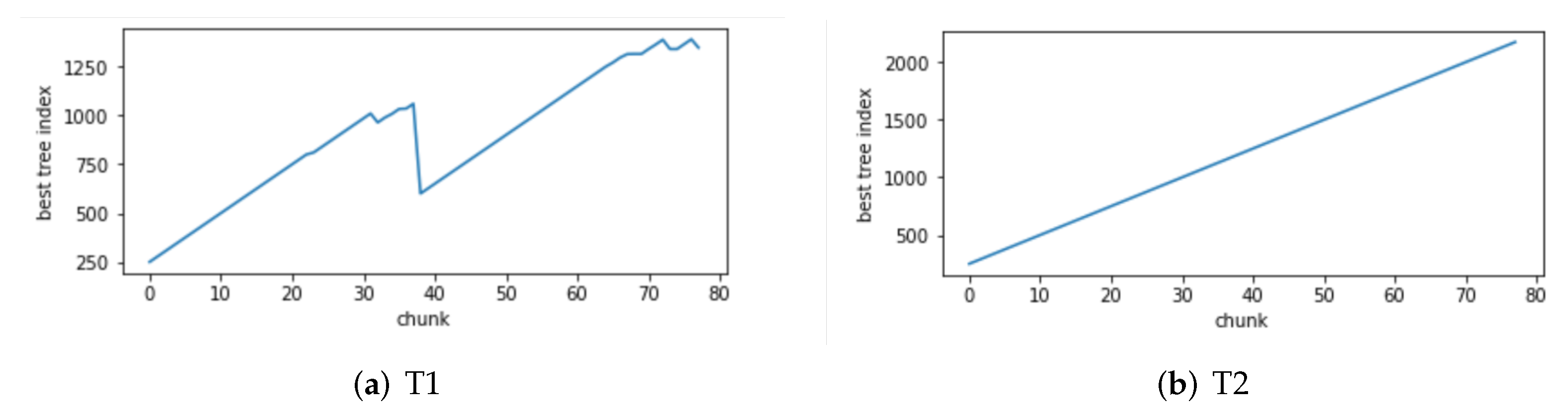
4.7.2. Concept Drift Detection
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ray, S.; Jin, Y.; Raychowdhury, A. The Changing Computing Paradigm With Internet of Things: A Tutorial Introduction. IEEE Des. Test 2016, 33, 76–96. [Google Scholar] [CrossRef]
- Khan, R.; Khan, S.U.; Zaheer, R.; Khan, S. Future Internet: The Internet of Things Architecture, Possible Applications and Key Challenges. In Proceedings of the International Conference on Frontiers of Information Technology, Islamabad, Pakistan, 17–19 December 2012. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and Other Botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, X.; Yan, Q.; Li, B.; Shao, M.; Peng, H. Multi-attributed heterogeneous graph convolutional network for bot detection. Inf. Sci. 2020, 537, 380–393. [Google Scholar] [CrossRef]
- Zahoor, S.; Mir, R.N. Resource management in pervasive Internet of Things: A survey. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 921–935. [Google Scholar] [CrossRef]
- Din, S.U.; Shao, J. Exploiting evolving micro-clusters for data stream classification with emerging class detection. Inf. Sci. 2020, 507, 404–420. [Google Scholar] [CrossRef]
- Bilge, L.; Balzarotti, D.; Robertson, W.; Kirda, E.; Kruegel, C. Disclosure: Detecting botnet command and control servers through large-scale NetFlow analysis. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3 December 2012. [Google Scholar]
- Chen, R.; Niu, W.; Zhang, X.; Zhuo, Z.; Lv, F. An Effective Conversation-Based Botnet Detection Method. Math. Probl. Eng. 2017, 2017, 4934082. [Google Scholar] [CrossRef]
- Moustafa, N.; Turnbull, B.; Choo, K.K.R. An Ensemble Intrusion Detection Technique based on proposed Statistical Flow Features for Protecting Network Traffic of Internet of Things. IEEE Internet Things J. 2018, 6, 4815–4830. [Google Scholar] [CrossRef]
- Homayoun, S.; Ahmadzadeh, M.; Hashemi, S.; Dehghantanha, A.; Khayami, R. Hybrid Deep Learning for Botnet Attack Detection in the Internet of Things Networks. IEEE Internet Things J. 2020, 8, 4944–4956. [Google Scholar]
- Popoola, S.I.; Adebisi, B.; Hammoudeh, M.; Gui, G.; Gacanin, H. BoTShark: A deep learning approach for botnet traffic detection. Cyber Threat Intell. J. 2018, 70, 137–153. [Google Scholar]
- Ashraf, J.; Keshk, M.; Moustafa, N.; Abdel-Basset, M.; Mostafa, R.R. IoTBoT-IDS: A Novel Statistical Learning-enabled Botnet Detection Framework for Protecting Networks of Smart Cities. Sustain. Cities Soc. 2021, 72, 103041. [Google Scholar] [CrossRef]
- Ditzler, G.; Polikar, R. Incremental Learning of Concept Drift from Streaming Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2013, 25, 2283–2301. [Google Scholar] [CrossRef]
- Brzezinski, D.; Stefanowski, J. Accuracy Updated Ensemble for Data Streams with Concept Drift. In International Conference on Hybrid Artificial Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 155–163. [Google Scholar]
- Frias-Blanco, I.; Campo-Avila, J.D.; Ramos-Jimenez, G.; Morales-Bueno, R.; Ortiz-Diaz, A.; Caballero-Mota, Y. Online and Non-Parametric Drift Detection Methods Based on Hoeffding’s Bounds. IEEE Trans. Knowl. Data Eng. 2015, 27, 810–823. [Google Scholar] [CrossRef]
- Qiao, H.; Novikov, B.; Blech, J.O. Concept Drift Analysis by Dynamic Residual Projection for effectively Detecting Botnet Cyber-attacks in IoT scenarios. IEEE Trans. Ind. Inform. 2021, 18, 3692–3701. [Google Scholar] [CrossRef]
- Wahab, O.A. Intrusion detection in the iot under data and concept drifts: Online deep learning approach. IEEE Internet Things J. 2022, 9, 19706–19716. [Google Scholar] [CrossRef]
- Amin, M.; Al-Obeidat, F.; Tubaishat, A.; Shah, B.; Anwar, S.; Tanveer, T.A. Cyber security and beyond: Detecting malware and concept drift in AI-based sensor data streams using statistical techniques. Comput. Electr. Eng. 2023, 108, 108702. [Google Scholar] [CrossRef]
- Abusitta, A.; de Carvalho, G.H.; Wahab, O.A.; Halabi, T.; Fung, B.C.; Al Mamoori, S. Deep learning-enabled anomaly detection for IoT systems. Internet Things 2023, 21, 100656. [Google Scholar] [CrossRef]
- Shi, W.C.; Sun, H.M. DeepBot: A time-based botnet detection with deep learning. Soft Comput. 2020, 24, 16605–16616. [Google Scholar] [CrossRef]
- Lingam, G.; Rout, R.R.; Somayajulu, D.V.; Das, S.K. Social botnet community detection: A novel approach based on behavioral similarity in twitter network using deep learning. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020. [Google Scholar]
- Hasan, N.; Chen, Z.; Zhao, C.; Zhu, Y.; Liu, C. IoT Botnet Detection framework from Network Behavior based on Extreme Learning Machine. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022. [Google Scholar]
- Veluchamy, S.; Kathavarayan, R.S. Deep reinforcement learning for building honeypots against runtime DoS attack. Int. J. Intell. Syst. 2022, 37, 3981–4007. [Google Scholar] [CrossRef]
- Garre, J.T.M.; Pérez, M.G.; Ruiz-Martínez, A. A novel Machine Learning-based approach for the detection of SSH botnet infection. Future Gener. Comput. Syst. 2021, 115, 387–396. [Google Scholar] [CrossRef]
- Memos, V.A.; Psannis, K.E. AI-powered honeypots for enhanced IoT botnet detection. In Proceedings of the 2020 3rd World Symposium on Communication Engineering (WSCE), Thessaloniki, Greece, 9–11 October 2020. [Google Scholar]
- Singh, M.; Singh, M.; Kaur, S. Issues and challenges in DNS based botnet detection: A survey. Comput. Secur. 2019, 86, 28–52. [Google Scholar] [CrossRef]
- Alani, M.M. BotStop: Packet-based efficient and explainable IoT botnet detection using machine learning. Comput. Commun. 2022, 193, 53–62. [Google Scholar] [CrossRef]
- Liaqat, S.; Akhunzada, A.; Shaikh, F.S.; Giannetsos, A.; Jan, M.A. SDN orchestration to combat evolving cyber threats in Internet of Medical Things (IoMT). Comput. Commun. 2020, 160, 697–705. [Google Scholar] [CrossRef]
- Jiang, M.; Zhao, B.; Luo, S.; Wang, Q.; Chu, Y.; Chen, T.; Mao, X.; Liu, Y.; Wang, Y.; Jiang, X.; et al. NeuroPpred-Fuse: An interpretable stacking model for prediction of neuropeptides by fusing sequence information and feature selection methods. Briefings Bioinform. 2021, 22, bbab310. [Google Scholar] [CrossRef] [PubMed]
- Cooke, E.; Jahanian, F.; Mcpherson, D. The Zombie Roundup: Understanding, Detecting, and Disrupting Botnets. USENIX Assoc. 2005, 5, 6. [Google Scholar]
- Herwig, S.; Harvey, K.; Hughey, G.; Roberts, R.; Levin, D. Measurement and Analysis of Hajime, a Peer-to-peer IoT Botnet. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Proceedings of the Advances in Artificial Intelligence—SBIA 2004:17th Brazilian Symposium on Artificial Intelligence, Sao Luis, Maranhao, Brazil, 29 September–1 October 2004. [Google Scholar]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- Gomes, H.M.; Barddal, J.P.; Enembreck, F.; Bifet, A. A survey on ensemble learning for data stream classification. ACM Comput. Surv. (CSUR) 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E. Forensics and Deep Learning Mechanisms for Botnets in Internet of Things: A Survey of Challenges and Solutions. IEEE Access 2019, 7, 61764–61785. [Google Scholar] [CrossRef]
- Ghafir, I.; Hammoudeh, M.; Prenosil, V.; Han, L.; Hegarty, R.; Rabie, K.; Aparicio-Navarro, F.J. Detection of Advanced Persistent Threat Using Machine-Learning Correlation Analysis. Future Gener. Comput. Syst. 2018, 89, 349–359. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-BaIoT: Network-based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef]
- Guo, H.; Li, H.; Ren, Q.; Wang, W. Concept drift type identification based on multi-sliding windows. Inf. Sci. 2022, 585, 1–23. [Google Scholar] [CrossRef]
- Yang, L.; Guo, W.; Hao, Q.; Ciptadi, A.; Ahmadzadeh, A.; Xing, X.; Wang, G. {CADE}: Detecting and explaining concept drift samples for security applications. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021. [Google Scholar]
- Zhao, P.; Cai, L.W.; Zhou, Z.H. Handling concept drift via model reuse. Mach. Learn. 2020, 109, 533–568. [Google Scholar] [CrossRef]
- Juanying, X.; Shunxia, W.; Shuai, J.; Yan, Z. Feature selection method combing improved F-score and support vector machine. J. Comput. Appl. 2010, 30, 993–996. [Google Scholar]
- Zhao, H.; Gao, F.; Zhang, C. A method for face gender recognition based on blocking-LBP and SVM. In Proceedings of the 2012 2nd International Conference on Consumer Electronics, Communications and Networks (CECNet), Yichang, China, 21–23 April 2012. [Google Scholar]
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset, a New Dataset for Machine Learning Techniques on MQTT. Sensors 2020, 20, 6578. [Google Scholar] [CrossRef] [PubMed]
- Guerra-Manzanares, A.; Medina-Galindo, J.; Bahsi, H.; Nmm, S. MedBIoT: Generation of an IoT Botnet Dataset in a Medium-sized IoT Network. In Proceedings of the 6th International Conference on Information Systems Security and Privacy(ICISSP 2020), Valletta, Malta, 25–27 February 2020. [Google Scholar]
- Ghazanfar, S.; Hussain, F.; Rehman, A.U.; Fayyaz, U.U.; Shah, G.A. IoT-Flock: An Open-source Framework for IoT Traffic Generation. In Proceedings of the 2020 International Conference on Emerging Trends in Smart Technologies (ICETST), Karachi, Pakistan, 26–27 March 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Botnet | Real/Virtual Device | Time | Description |
|---|---|---|---|---|
| N-BaIoT | Mirai&BashLite | real | 2018 | More relevant to real IoT environments |
| BoT-IoT | Virtual | Virtual | 2018 | Multiple protocol types and attack traffic samples |
| MedBIoT | Mirai&BashLite | real + Virtual | 2020 | Simulated medium-sized IoT network |
| MQTTSet | Virtual | Virtual | 2020 | Focused on the MQTT protocol |
| Dataset | Samples | Types | Data Set Features | Model Training Features |
|---|---|---|---|---|
| N-BaIoT | 7,062,606 | 10 | 115 | 115 |
| BoT-IoT | 73,370,443 | 7 | 46 | 28 |
| MedBIoT | 17,845,567 | 4 | 100 | 100 |
| MQTTSet | 156,261 | 6 | 34 | 27 |
| Dataset | Composition |
|---|---|
| IoT botnet traffic | BoT-IoT-Malware-TCP_Dos |
| BoT-IoT-Malware-TCP_DDos | |
| BoT-IoT-Malware-Theft | |
| Dos attack traffic generated by IoT-Flock | |
| N_BaIoT_Mirai | |
| N_BaIoT_gafgyt | |
| Normal Traffic | N_BaIoT_Benign |
| Virtual traffic based on MQTT protocol |
| Concept Type | Flow Type (Number) | |
|---|---|---|
| The same type of attack for different botnet families | ||
| C1 | Benign (10,000) | Mirai_Scan (10,000) |
| C2 | Benign (10,000) | gafgyt_Scan (10,000) |
| Same attack pattern over time | ||
| C1 | Benign (10,000) | BoT-IoT_Dos (10,000) |
| C2 | Benign (10,000) | IoT-Flock_Dos (10,000) |
| Concept Type | Flow Type (Number) | |
|---|---|---|
| C1 | Benign (10,000) | Mirai_Scan (10,000) |
| C2 | Benign (10,000) | Mirai_Ack (10,000) |
| Concept Type | Flow Type (Number) | |||
|---|---|---|---|---|
| Type I | ||||
| C1 | Benign (10,000) | Mirai_Scan (10,000) | Mirai_Ack (0) | Mirai_Syn (0) |
| C2 | Benign (10,000) | Mirai_Scan (10,000) | Mirai_Ack (10,000) | Mirai_Syn (2000) |
| C3 | Benign (10,000) | Mirai_Scan (2000) | Mirai_Ack (2000) | Mirai_Syn (10,000) |
| C4 | Benign (0) | Mirai_Scan (4000) | Mirai_Ack (4000) | Mirai_Syn (4000) |
| C5 | Benign (0) | gafgyt_Scan (4000) | Mirai_Ack (4000) | Mirai_Syn (4000) |
| Type II | ||||
| C1 | Benign (10,000) | Bot-IoT_Dos (10,000) | Bot-IoT_DDos (0) | Bot-IoT_Scan (0) |
| C2 | Benign (10,000) | Bot-IoT_Dos (10,000) | Bot-IoT_DDos (10,000) | Bot-IoT_Scan (2000) |
| C3 | Benign (10,000) | Bot-IoT_Dos (2000) | Bot-IoT_DDos (2000) | Bot-IoT_Scan (10,000) |
| C4 | Benign (0) | Bot-IoT_Dos (4000) | Bot-IoT_DDos (4000) | Bot-IoT_Scan (4000) |
| C5 | Benign (0) | IoT-Flock_Dos (4000) | Bot-IoT_DDos (4000) | Bot-IoT_Scan (4000) |
| GBDT | GBDT-IL | ||
|---|---|---|---|
| Parameter | Value | Parameter | Value |
| max_iter | 250 | ini_train_size | 1000 |
| sample_rate | 0.8 | win_size | 500 |
| learn_rate | 0.01 | max_tree | 10,000 |
| max_depth | 10 | num_inc_tree | 25 |
| min_sample_leaf | 5 | ||
| Dataset | Original | FS | DFS | WFS | NFS | |
|---|---|---|---|---|---|---|
| N_BaIoT | accuracy feature | 0.999911 115 | 0.999916 30 | 0.999940 110 | 0.999923 35 | 0.999953 55 |
| BoT-IoT | accuracy feature | 0.999867 28 | 0.999871 14 | 0.999876 12 | 0.999870 16 | 0.999876 12 |
| MedBIoT | accuracy feature | 0.998813 100 | 0.998835 80 | 0.998906 90 | 0.999870 95 | 0.998915 90 |
| MQTTSet | accuracy feature | 0.997173 27 | 0.997056 26 | 0.997078 12 | 0.997098 16 | 0.997178 20 |
| GBDT | iGBDT-IL | GBDT-IL | Learn++ | OnlineAUE | HDDM-W | HDDM-A | |
|---|---|---|---|---|---|---|---|
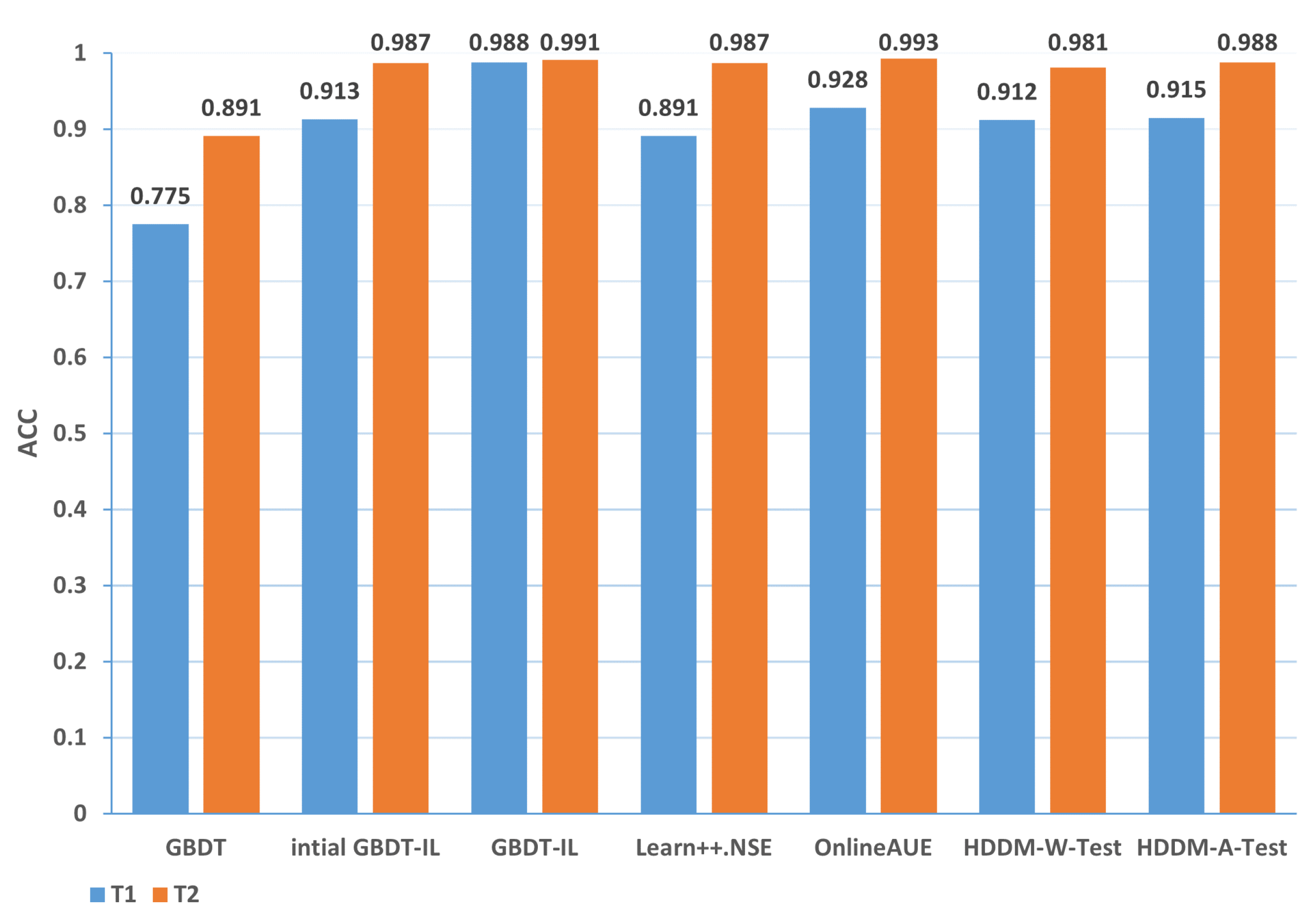
| 1-T1 | 0.775 | 0.913 | 0.988 | 0.891 | 0.928 | 0.912 | 0.915 |
| 1-T2 | 0.891 | 0.987 | 0.991 | 0.978 | 0.993 | 0.981 | 0.988 |
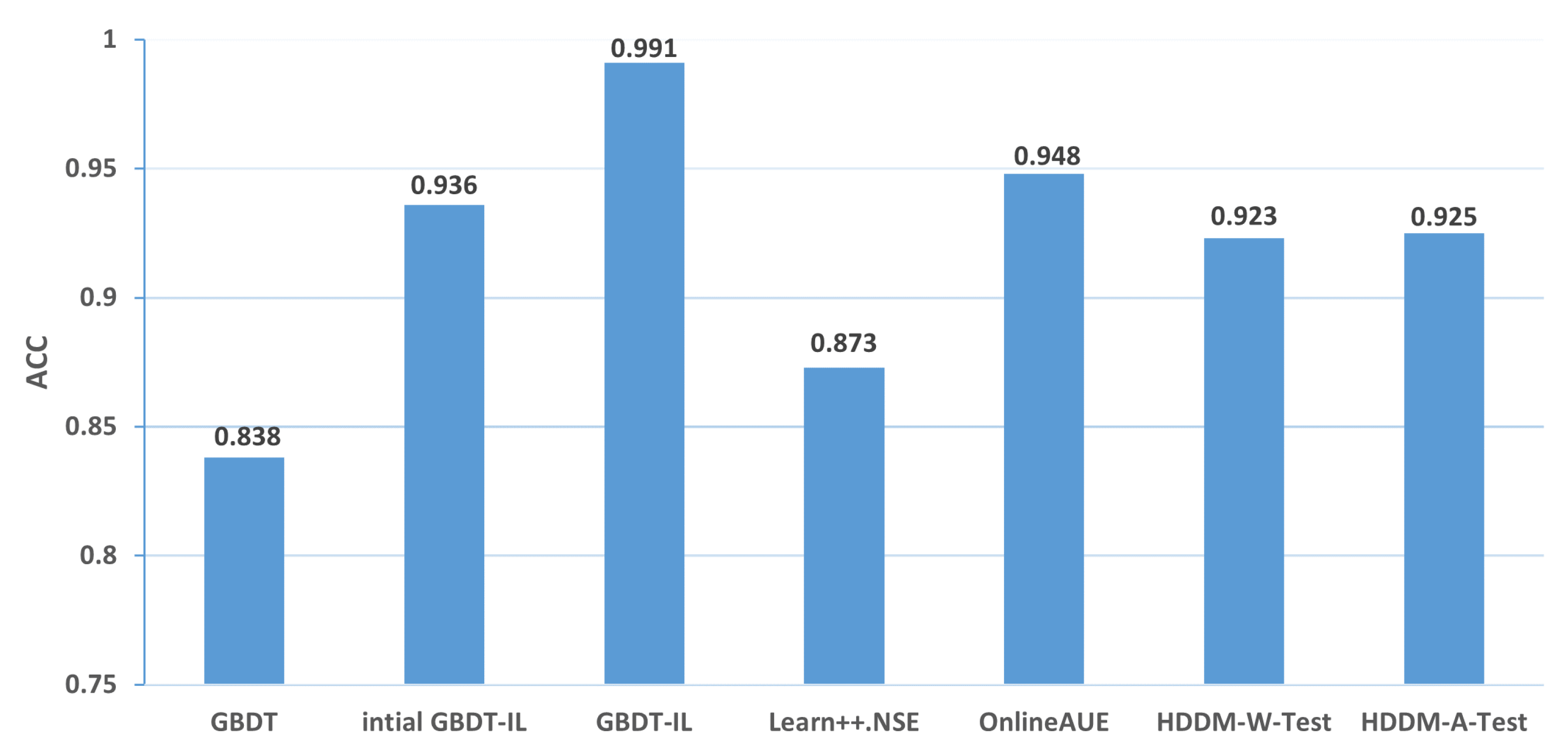
| 2 | 0.838 | 0.936 | 0.991 | 0.873 | 0.948 | 0.923 | 0.925 |
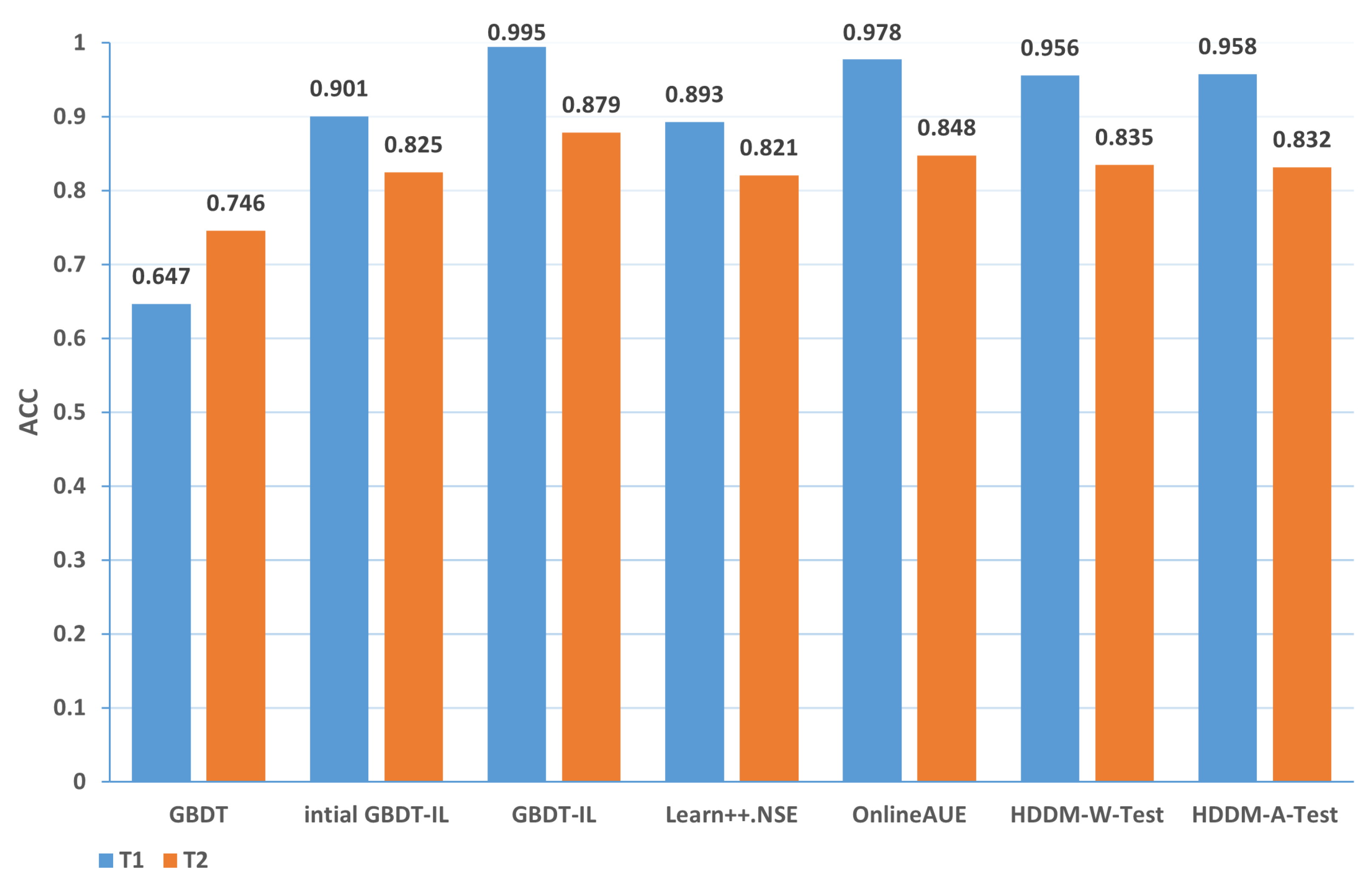
| 3-T1 | 0.647 | 0.901 | 0.995 | 0.893 | 0.978 | 0.956 | 0.958 |
| 3-T2 | 0.746 | 0.825 | 0.879 | 0.821 | 0.848 | 0.835 | 0.832 |
| GBDT | iGBDT-IL | GBDT-IL | Learn++ | OnlineAUE | HDDM-W | HDDM-A | |
|---|---|---|---|---|---|---|---|
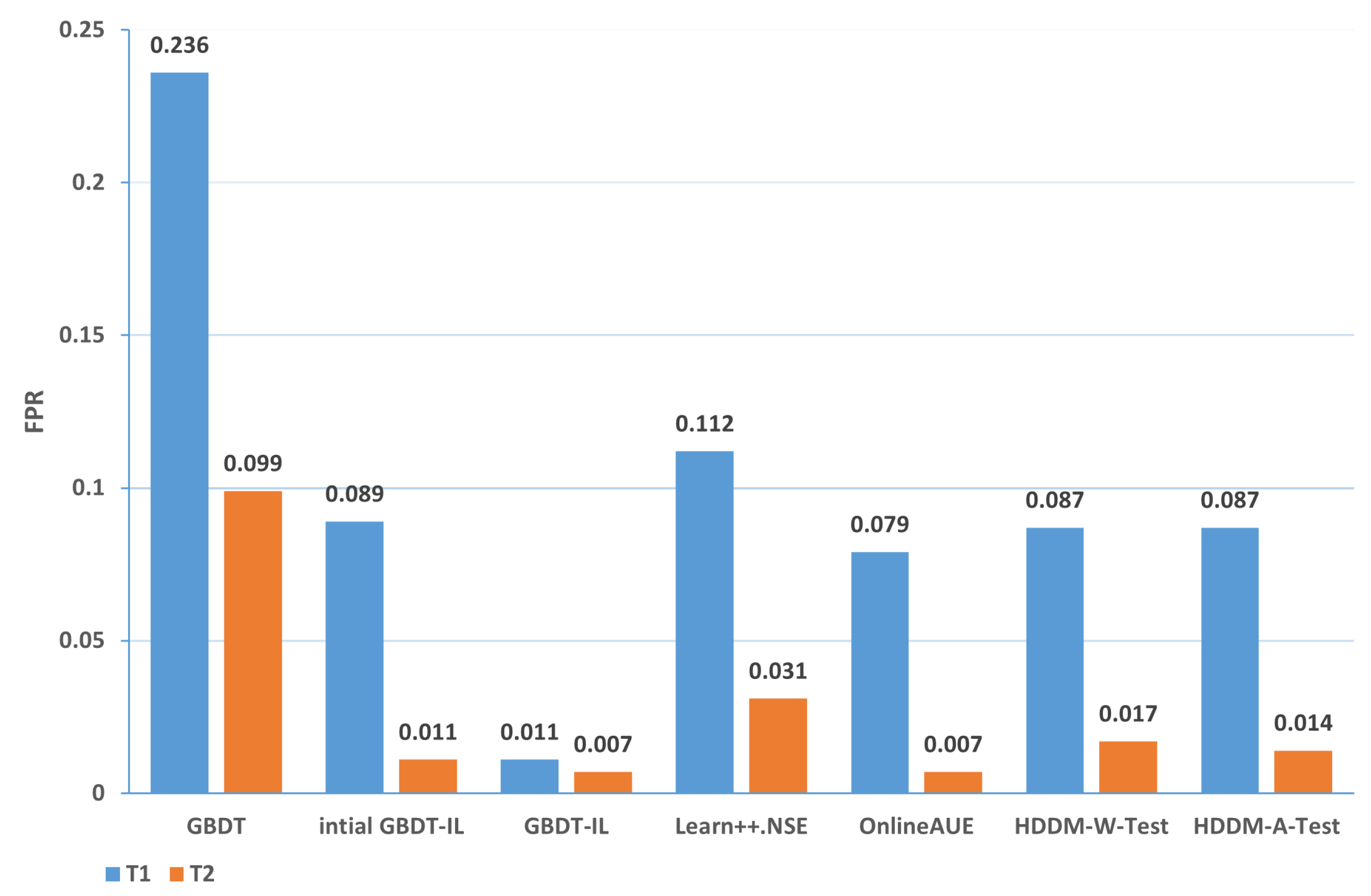
| 1-T1 | 0.236 | 0.089 | 0.011 | 0.112 | 0.079 | 0.087 | 0.087 |
| 1-T2 | 0.099 | 0.011 | 0.007 | 0.032 | 0.007 | 0.017 | 0.014 |
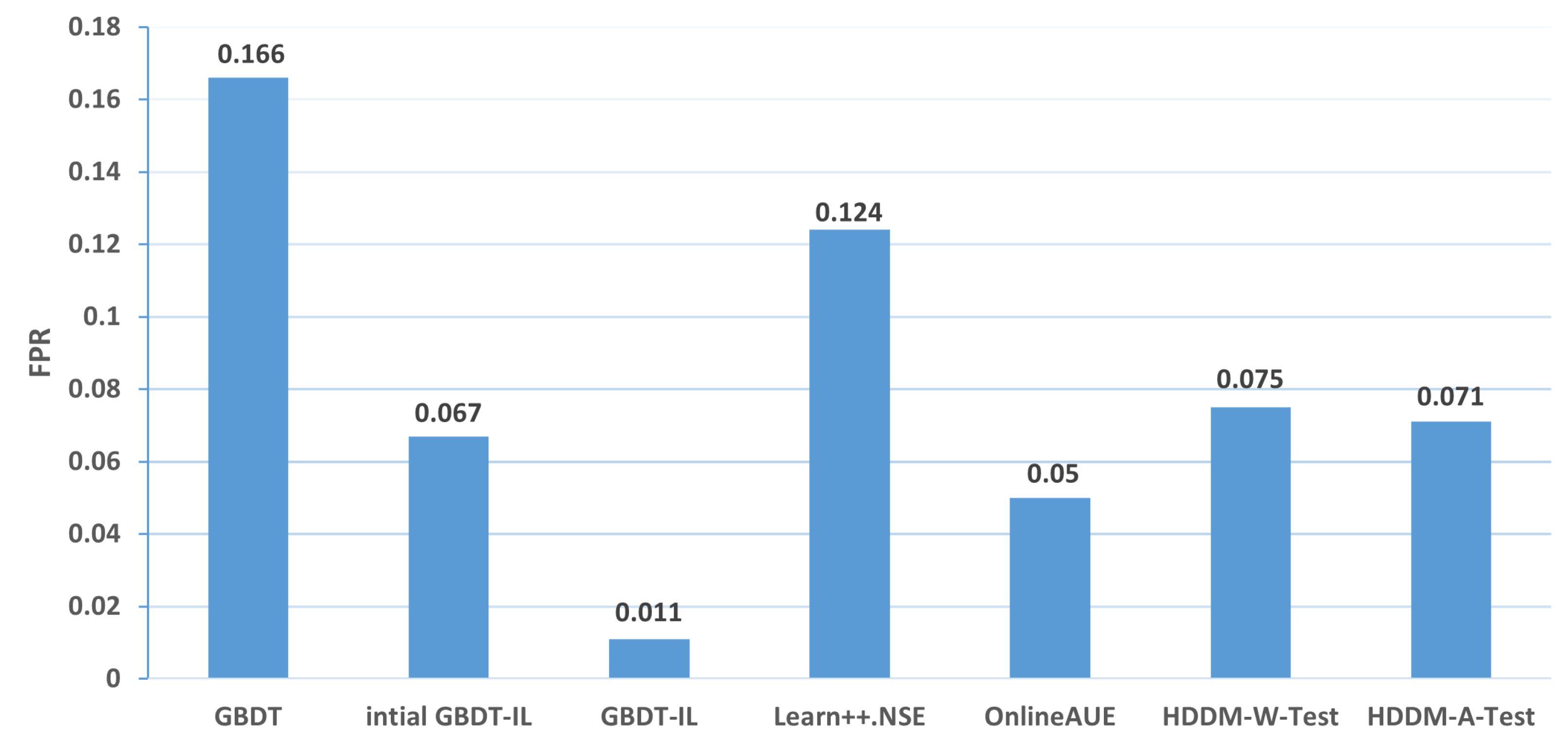
| 2 | 0.166 | 0.067 | 0.011 | 0.124 | 0.05 | 0.075 | 0.071 |
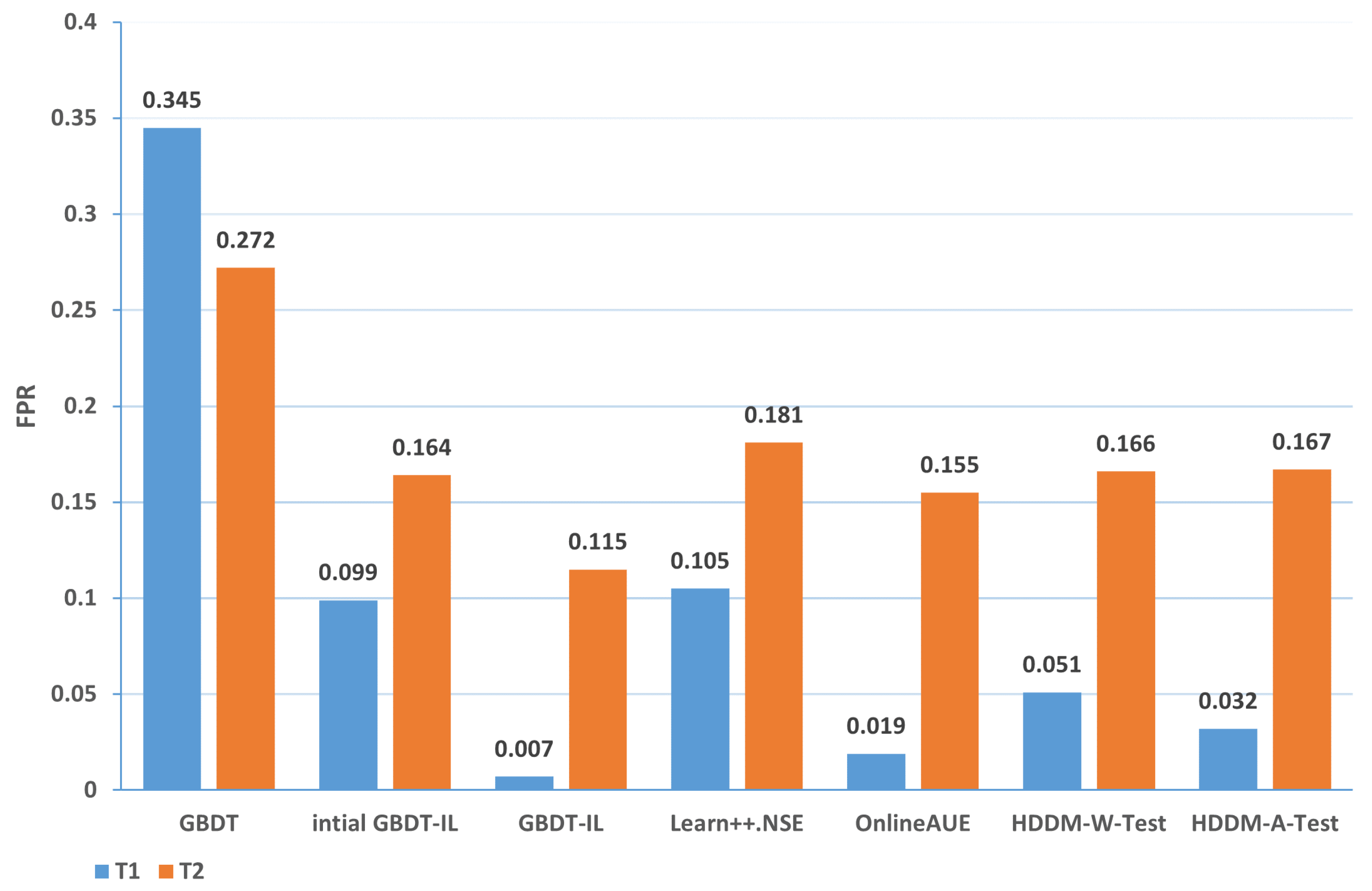
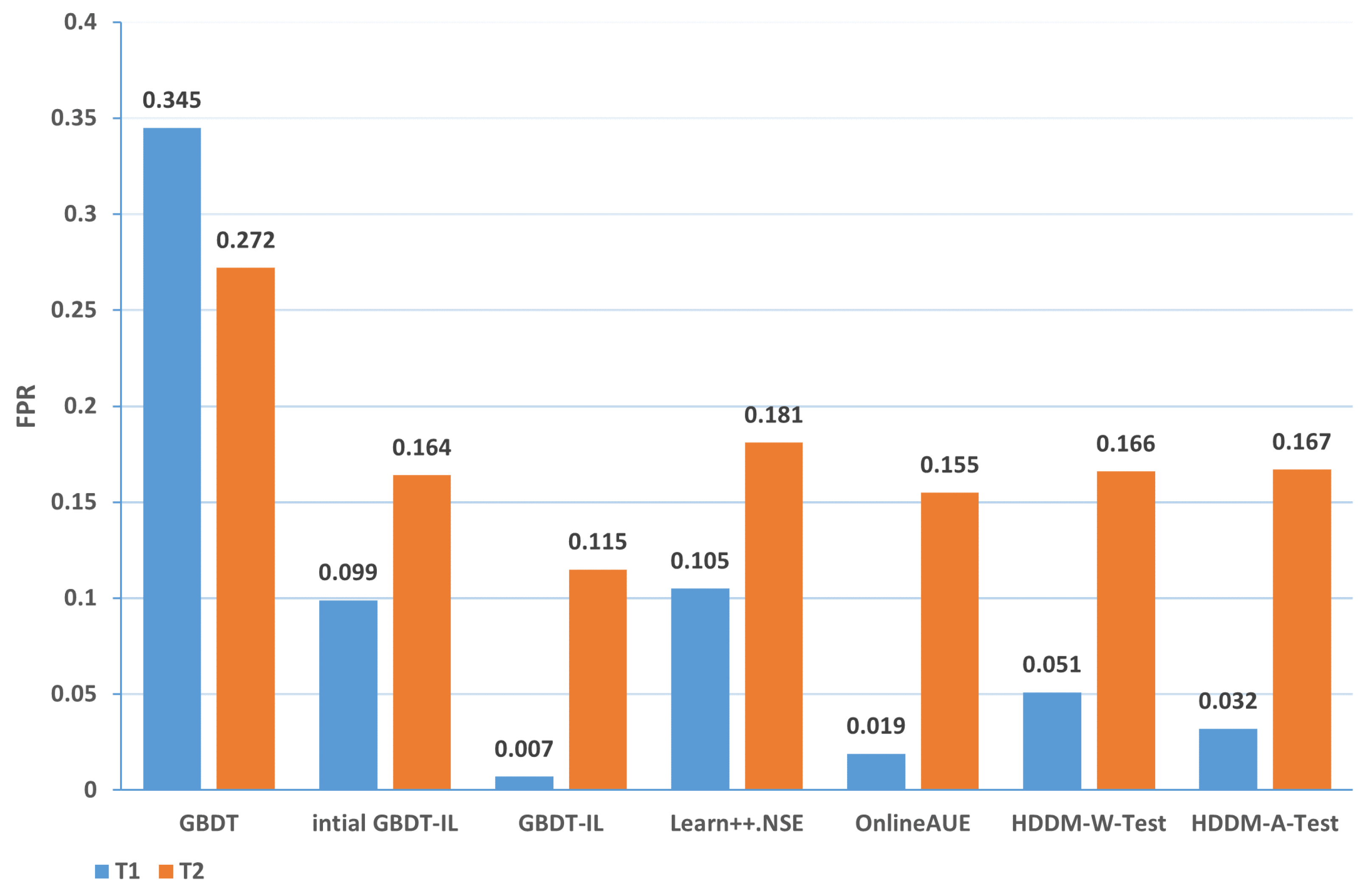
| 3-T1 | 0.345 | 0.099 | 0.007 | 0.105 | 0.019 | 0.051 | 0.032 |
| 3-T2 | 0.272 | 0.164 | 0.115 | 0.181 | 0.155 | 0.166 | 0.167 |
| Ranking | 7 | 3.8 | 1 | 6 | 1.8 | 4.2 | 3.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Dai, T.; Zhang, Y.; Zhu, Y.; Liu, X.; Zhao, E. GBDT-IL: Incremental Learning of Gradient Boosting Decision Trees to Detect Botnets in Internet of Things. Sensors 2024, 24, 2083. https://doi.org/10.3390/s24072083
Chen R, Dai T, Zhang Y, Zhu Y, Liu X, Zhao E. GBDT-IL: Incremental Learning of Gradient Boosting Decision Trees to Detect Botnets in Internet of Things. Sensors. 2024; 24(7):2083. https://doi.org/10.3390/s24072083
Chicago/Turabian StyleChen, Ruidong, Tianci Dai, Yanfeng Zhang, Yukun Zhu, Xin Liu, and Erfan Zhao. 2024. "GBDT-IL: Incremental Learning of Gradient Boosting Decision Trees to Detect Botnets in Internet of Things" Sensors 24, no. 7: 2083. https://doi.org/10.3390/s24072083
APA StyleChen, R., Dai, T., Zhang, Y., Zhu, Y., Liu, X., & Zhao, E. (2024). GBDT-IL: Incremental Learning of Gradient Boosting Decision Trees to Detect Botnets in Internet of Things. Sensors, 24(7), 2083. https://doi.org/10.3390/s24072083