1. Introduction
The application of electrical impedance spectroscopy (EIS) as an analytical method is widespread. Examples include material characterization, monitoring and diagnosis of battery or accumulator systems, medical applications, or food monitoring [
1]. The advantages of the measurement method include its non-invasive nature, the flexibility of the measurement duration and the volume under investigation, and the high information content due to the simultaneous determination of the real and imaginary parts of an impedance at various frequencies [
1]. Impedance is an integral measure that contains information about larger volumes rather than local characteristics, which do not have to be statistically representative. Finally, the measurement is harmless to health compared to other methods such as X-rays [
2]. For all these reasons, EIS is interesting for the in-situ monitoring of industrial processes. However, in order to be able to use EIS in an industrial environment, appropriate measuring devices are required, as laboratory equipment usually does not meet field requirements (it tends to be too expensive, too bulky, or too general-purpose). Various approaches to replacing laboratory equipment with application-specific developments can be found in the literature. These developments consist of a control unit, such as a field-programmable gate array [
3], an Arduino DUE [
4,
5], or a Red Pitaya Board [
6]. Conventional setups are extended and improved by, e.g., an impedance-to-digital converter [
7], a logarithmic amplifier [
4], or a digital auto-balancing bridge [
8]. The operating frequencies range from 0.1 MHz [
7] to 10 MHz [
8], and the impedance magnitudes range from 100 Ω [
8] to 10 GΩ [
5]. The relative measurement deviations achievable with these application-specific developments are in the low single-digit percentage range [
3,
5,
6,
7,
8]. Measurement times compatible with real-time requirements (between a few milliseconds and a few minutes) are achieved if the operating frequencies are restricted to sufficiently high values [
8,
9]. The devices developed in this way offer advantages since they can be adapted to the respective problem, such as battery technology [
9], corrosion monitoring [
5], and bioimpedance [
3,
6,
8], and can also be inexpensive and compact compared to laboratory equipment [
3,
5]. Other research areas that are coming into the focus of EIS include environmental technology (microplastics detection [
10], nitrate detection [
11]), biotechnology or medical technology, especially sensor technology for minimally invasive surgical techniques, and cell monitoring [
12,
13,
14]. In the medical field, the suitability of EIS for tomographic examinations is also being investigated [
14,
15].
The number of developments of suitable EIS devices for a wide range of applications demonstrates the interest and performance of EIS as a measurement technology in the field of online monitoring. An example of such an application is the process of used-sand regeneration in the foundry industry, in which used sand from casting production is processed so that the product obtained can be reused as a new-sand substitute for mold or core production [
16] (pp. 311–313). The goal of regeneration is to reduce the raw material input of new quartz sand and the landfilling of used sand as a waste product. Such processes are currently controlled based on the empirical values of each foundry and with offline sand quality analysis. Process optimization in terms of energy consumption and product yield is highly desirable, but it is not at all clear how the continuous process state monitoring required for such a closed-loop system could be realized in the field and at a reasonable cost. We have investigated the merits of EIS as a measuring tool to identify the process moment at which regeneration is complete, and the processed former waste sand is available for reuse [
17].
The EIS is intended to collect information on the used sand during the regeneration process. The composition of this sand varies depending on the casting process and the cast product. Typical main components can be quartz sand, chromite sand, and inorganic binder components such as bentonite [
16] (pp. 19–65). Since these components are natural products, they vary in their properties, such as composition or particle size distribution. Some of the influence quantities affecting the measurement result have been characterized impedimetrically in the literature. For example, the influence of the water content of different types of bentonites on the dielectric properties was investigated in [
18]. In addition to moisture, Szypłowska et al. [
19,
20] analyzed salinity and were able to extract a relationship between conductivity and permittivity via the salinity index model. The influence of the particle size distribution on the electrical impedance has also been analyzed in the literature. For example, Robinson et al. [
21] mention its effect on the permittivity of the measured substance. In our previous EIS analyses of different sand types and mixtures, we were also able to show that the impedance spectra are characteristic of each mixture at the given particle size distribution of the mixtures [
17,
22,
23].
The question that now arises is whether the characteristics or impedance features are suitable for distinguishing the two process states—“used sand to be regenerated” and “used sand regenerated sufficiently to serve as new-sand substitute”—from each other. This corresponds to a binary classification. An analytical solution to this task is difficult because of the large number of possible used-sand compositions and process parameters. For this reason, we have undertaken to solve the classification problem by machine learning (ML) in the form of support vector machines (SVM). An SVM has the potential to provide a generalized solution even though training data are available in limited quantities. Analytical problem-solving is no longer necessary. It outperforms numerical solution methods in computational speed [
24]. The overfitting risk is low due to the robust mathematical design. The required computational power is also small due to efficient algorithms [
25,
26]. Extremely complex nonlinear input-output relationships can be handled with relative ease, and unique solutions can be found even with large data sets [
26]. In addition, the risk of misclassification is minimized by maximizing the margin as outliers can be detected. The empirical training error is minimized [
24,
26].
The SVM methodology is the subject of ongoing research and development. The main focus is on efficiency improvements during training by avoiding numerical iteration procedures, a reduced memory requirement due to a smaller number of support vectors, and an optimized method for selecting the width of the kernel function by avoiding the grid search for determining the hyperparameters [
27,
28]. Approaches include the fast support vector classification or the semiproximal support vector machine [
27,
29]. Weakening the condition of a hard-margin to a soft-margin loss is also mentioned as a possible performance improvement [
30]. Other approaches aim at improved algorithms that specifically reduce the input data to those that contain the most important pieces of information, leading to a higher training speed [
31]. Typical SVM applications are in the field of image processing, i.e., surface, face, and object recognition or the analysis of handwriting and text classification [
24,
32]. Examples of more specific applications in medical technology include the analysis of ECG signals [
33] and tumor detection [
2,
34]. More recent SVM applications are material classification tasks such as moisture determination in wood chips [
35] or classification of various coals and rocks [
36].
Our research follows on from material investigations, with the raw data being generated using EIS. Here, the input data for the SVM, denoted as features, are analyzed and selected both manually and automatically. The obtained results are then presented and compared within the context of this study. Importantly, employing effective feature selection techniques yields SVM models that demonstrate reduced complexity and a smaller risk of overfitting.
Based on the positive experiences described in the literature when investigating materials with EIS and the subsequent data analysis with SVM and based on the further investigation of the capabilities of SVM, we measured typical molding material mixtures from foundries impedimetrically and used the features extracted from the EIS output data for classification with SVM.
2. Materials and Methods
The molding materials investigated by us are listed in
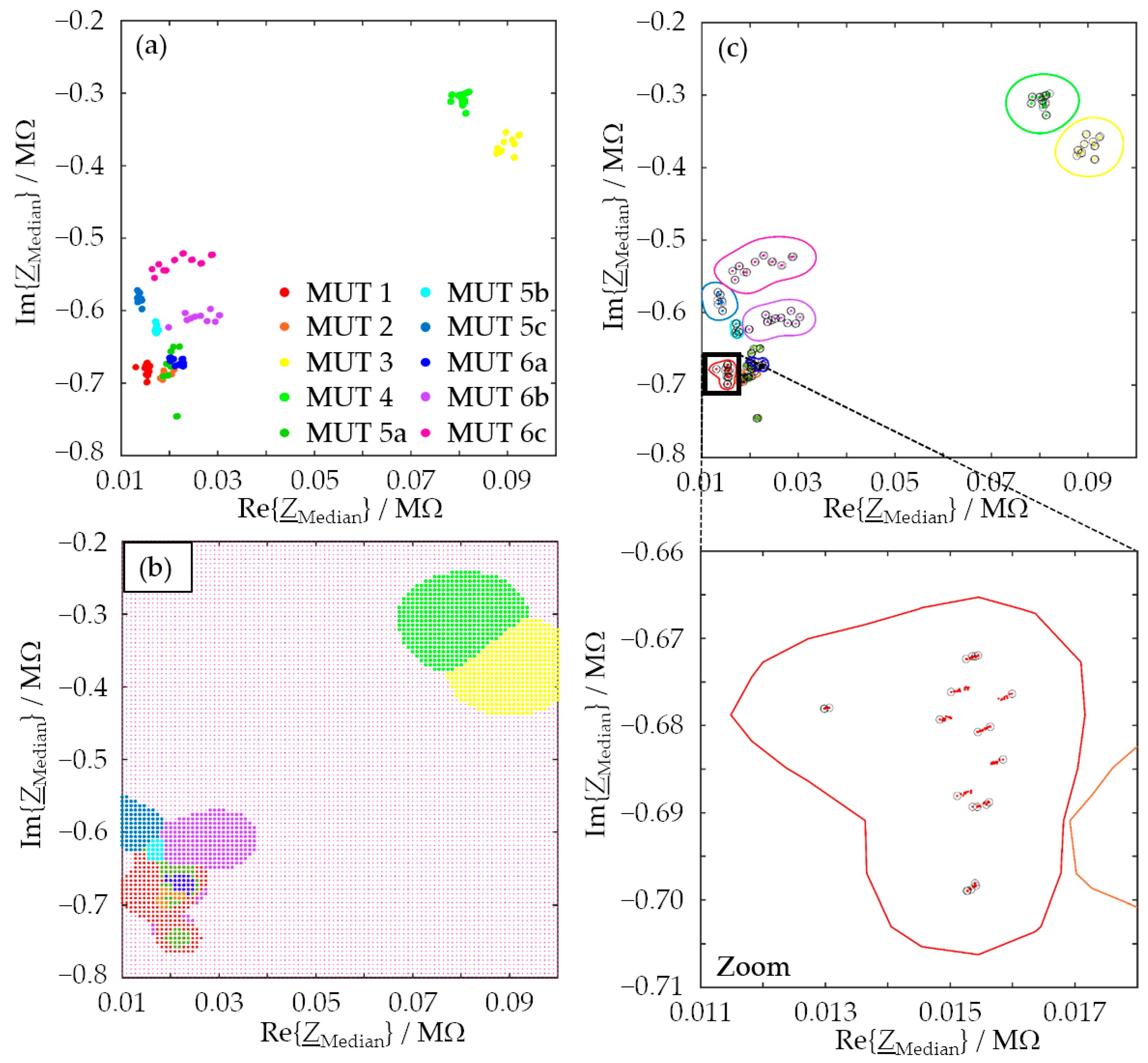
Table 1. They are typical materials for foundries. Quartz sand (MUT 1 and 2) or, in special applications, chromite sand (MUT 4) is used as the mold base material. To ensure that the mold has the necessary stability, various binder systems are used. Here, two inorganic systems based on bentonite were selected, which were added to the mold base material in different concentrations (MUT 5 and 6, both a–c). The two substances differed in terms of composition since the system of MUT 5 contained, in addition to the binder bentonite, further additives preset by the manufacturer. The binder system of MUT 6, on the other hand, was pure bentonite. MUT 3 is also quartz sand. Due to its lower quartz content, it does not meet the requirements of foundries, but it allowed us to test whether the proposed method can also distinguish quartz sands with varying quartz contents.
The molding compounds listed in
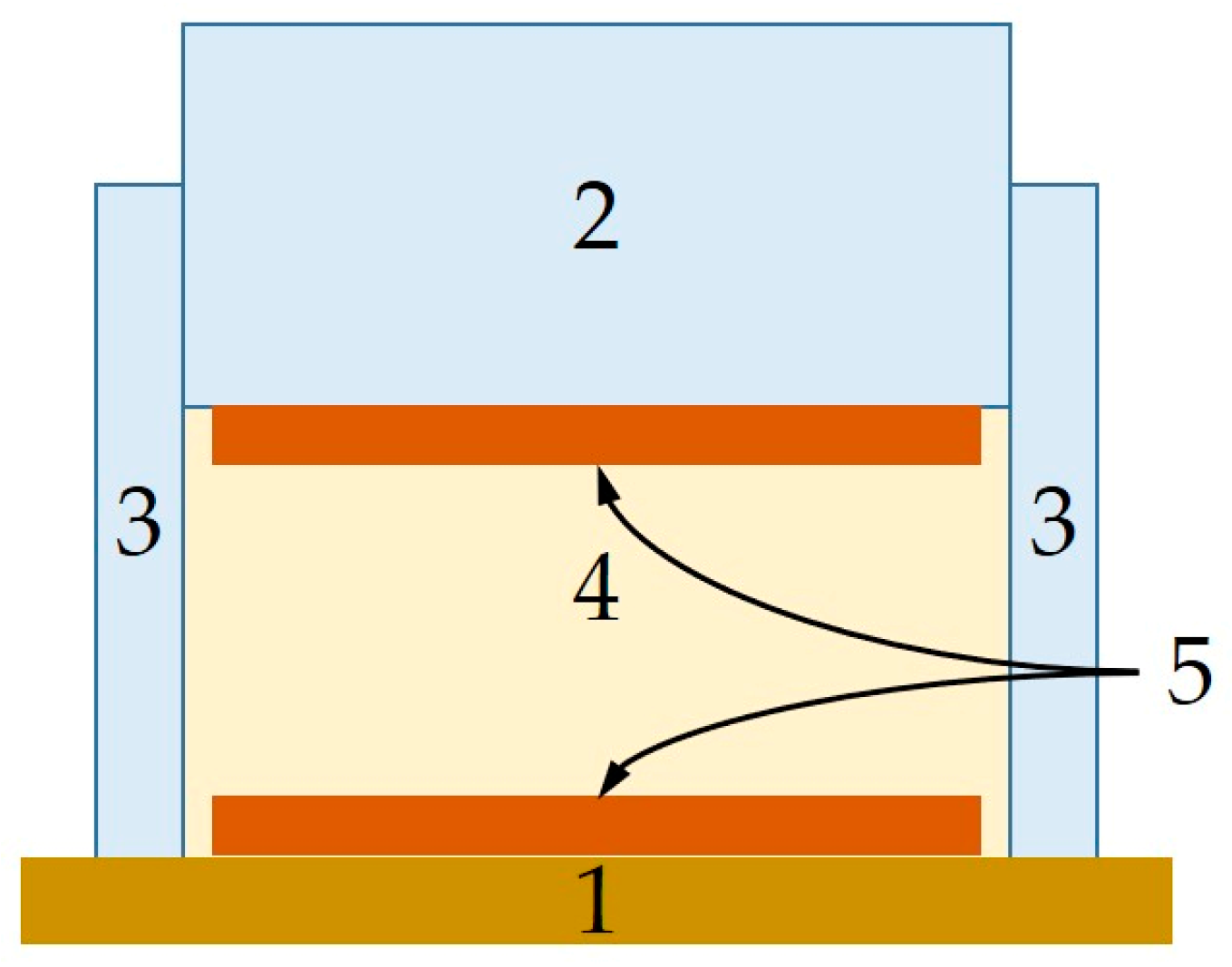
Table 1 were each filled into a cylindrical plate-capacitor measuring cell (
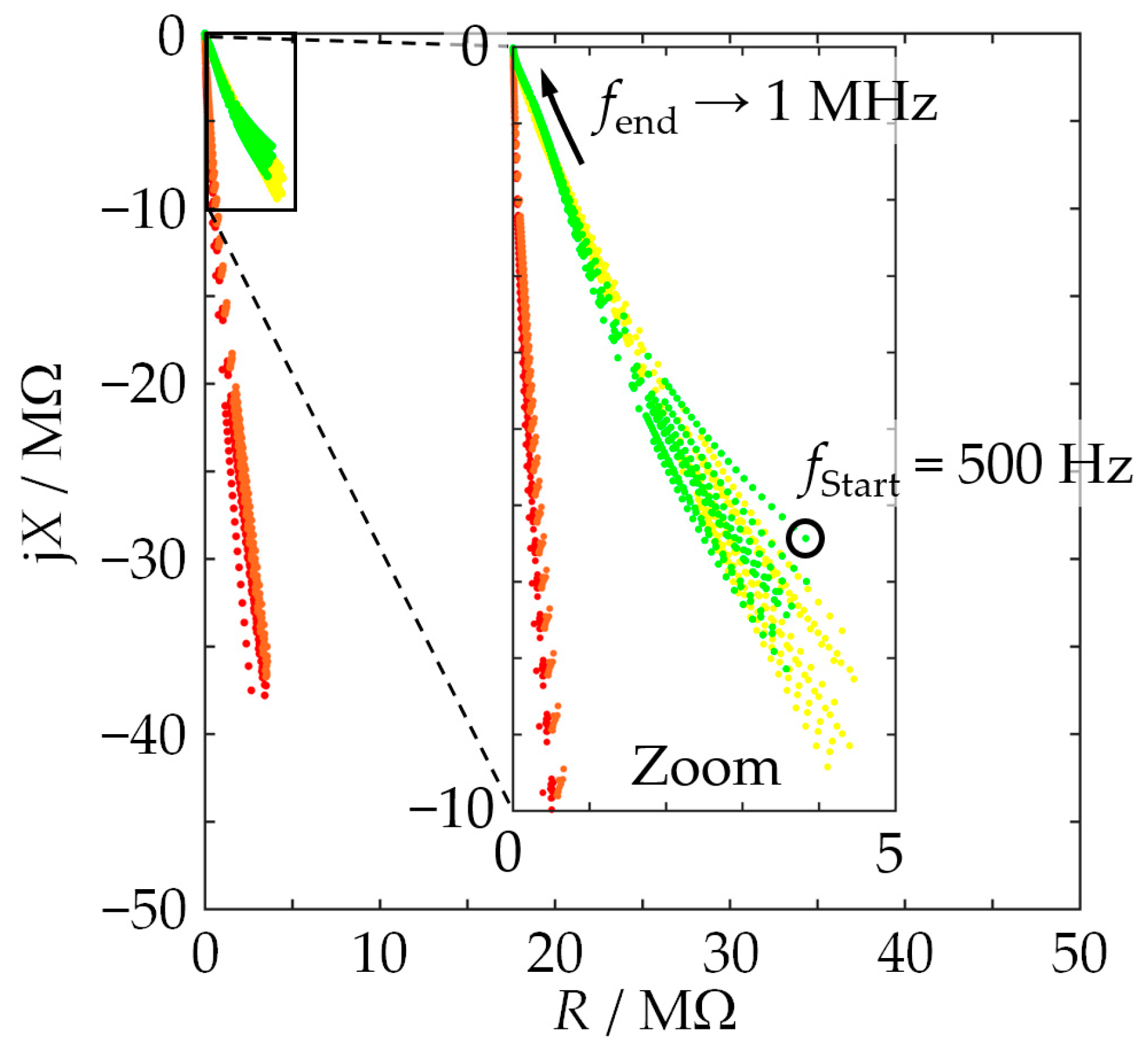
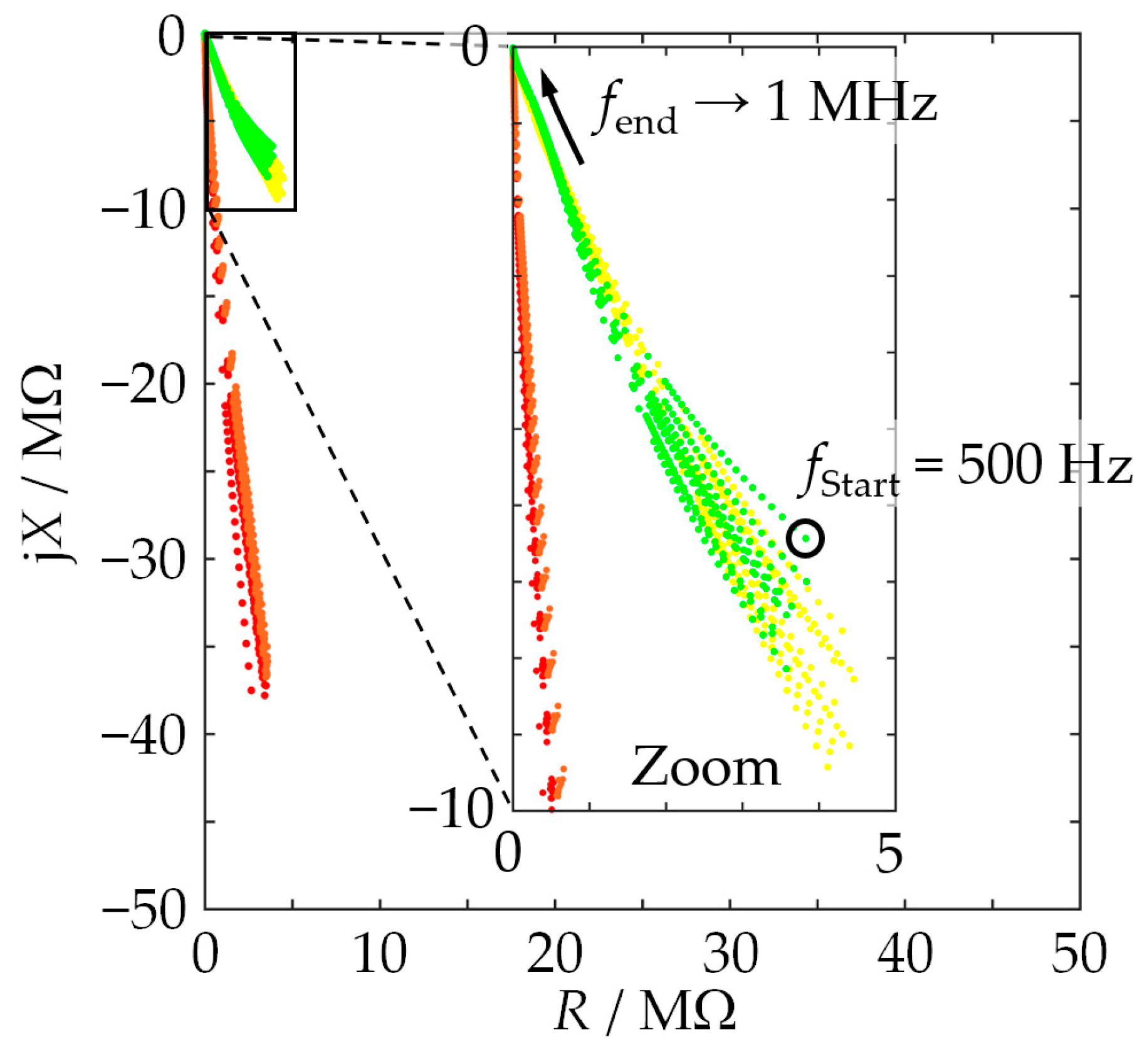
Figure 1), characterized, removed, filled in again, etc., and the whole cycle was repeated until ten fillings were characterized. The measurement of each individual filling involved a total of 20 repeated frequency sweeps so that at the end of the measurement series, a database of 10 × 20 frequency sweeps per MUT was available. The frequency range investigated included 145 frequency points between 0.5 kHz and 1 MHz. One sweep took approximately 1 min.
These settings were chosen with field applications in mind. The laboratory application of EIS usually involves lower frequencies, sometimes in the MHz range, and often frequencies higher than 1 MHz. Measuring low-frequency sinusoids, however, requires long measurement times, which is incompatible with the dynamics of an industrial process such as used-sand regeneration. In addition, higher-frequency signals are sensitive to disturbances in the field. In addition, they do not provide significant information in the current context.
Impedances were measured by an Agilent E4980A LCR meter. The measuring cell was connected to the instrument via two coaxial cables, and their shielding was connected to the ground LCR meter. Measurements were then performed at room temperature (between 21 °C and 26 °C). A broader temperature range is not necessary because the regeneration in the foundry is performed at temperatures between 20 °C and 40 °C. Impedimetric investigations of the MUTs in this temperature window did not reveal any significant influence of the temperature on the data.
4. Conclusions
This contribution is concerned with the real-time assessment of molding-compound quality in field environments of the foundry industry. The task involves (a) the generation of measurement data, (b) the interpretation of the measurement data, and (c) some measure for the overall soundness of the interpretation. Task (a) was solved by EIS. This then means that entire impedance spectra (or, put differently, complex-valued frequency series) form the basis of step (b).
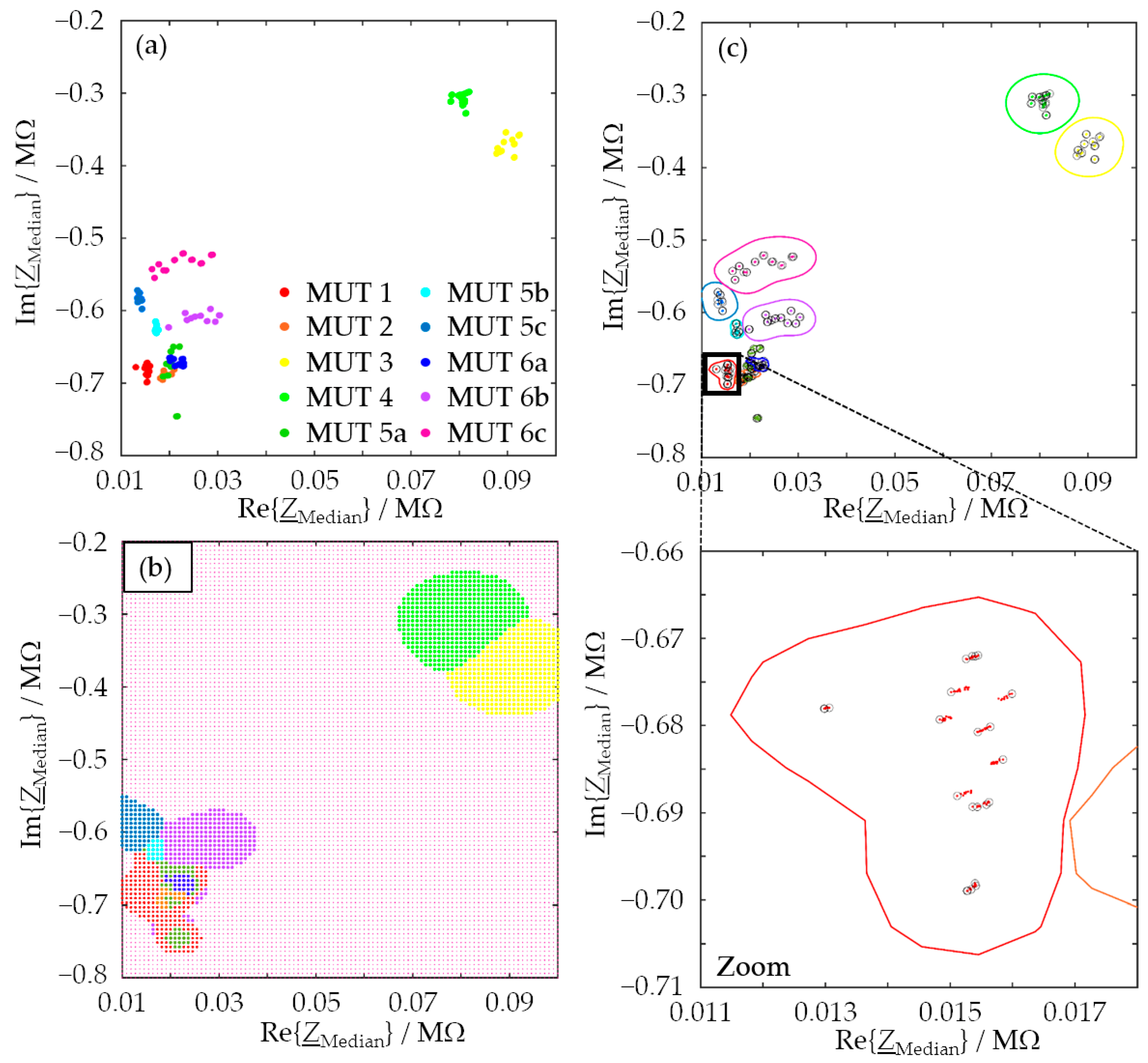
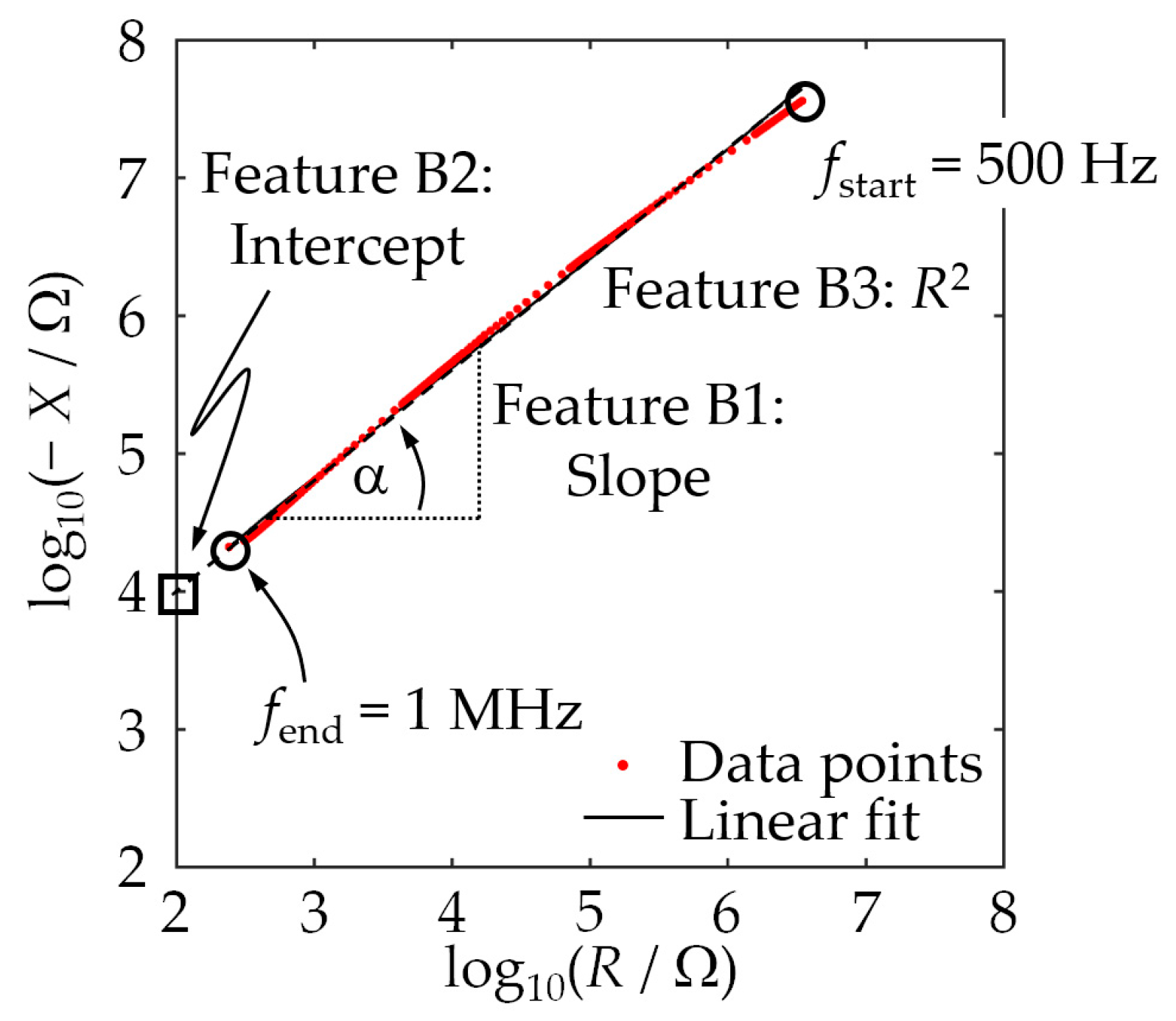
Step (b) was tackled by machine learning in general and by SVM in particular. In principle, SVM can be expected to be suitable for sand classification based on EIS spectra, but we have actually demonstrated it and have now investigated the key points that need to be considered. Feature candidates to be used for classification by the SVM were the median resistance, the mean resistance, the median reactance, and the mean reactance of an entire impedance spectrum (feature class A), as well as the fit parameters slope, intercept, and coefficient of determination of a linear fit of the logarithmized measurement data (feature class B). Convincing assignment results (>83%) were achieved even with single features, with the median resistance performing particularly well (>90%). Misclassifications could be explained by similar compositions of two or more molding materials.
To achieve even better assignment results, two features were combined, and a new SVM was generated for each case. As a result, the overall assignment correctness could be increased for all feature combinations examined so that values of over 99% were achieved. As we can show, by combining the features with the highest information density determined by an SFS, viz., the intercept of the regression line and the median reactance, one can achieve an assignment correctness of 100%.
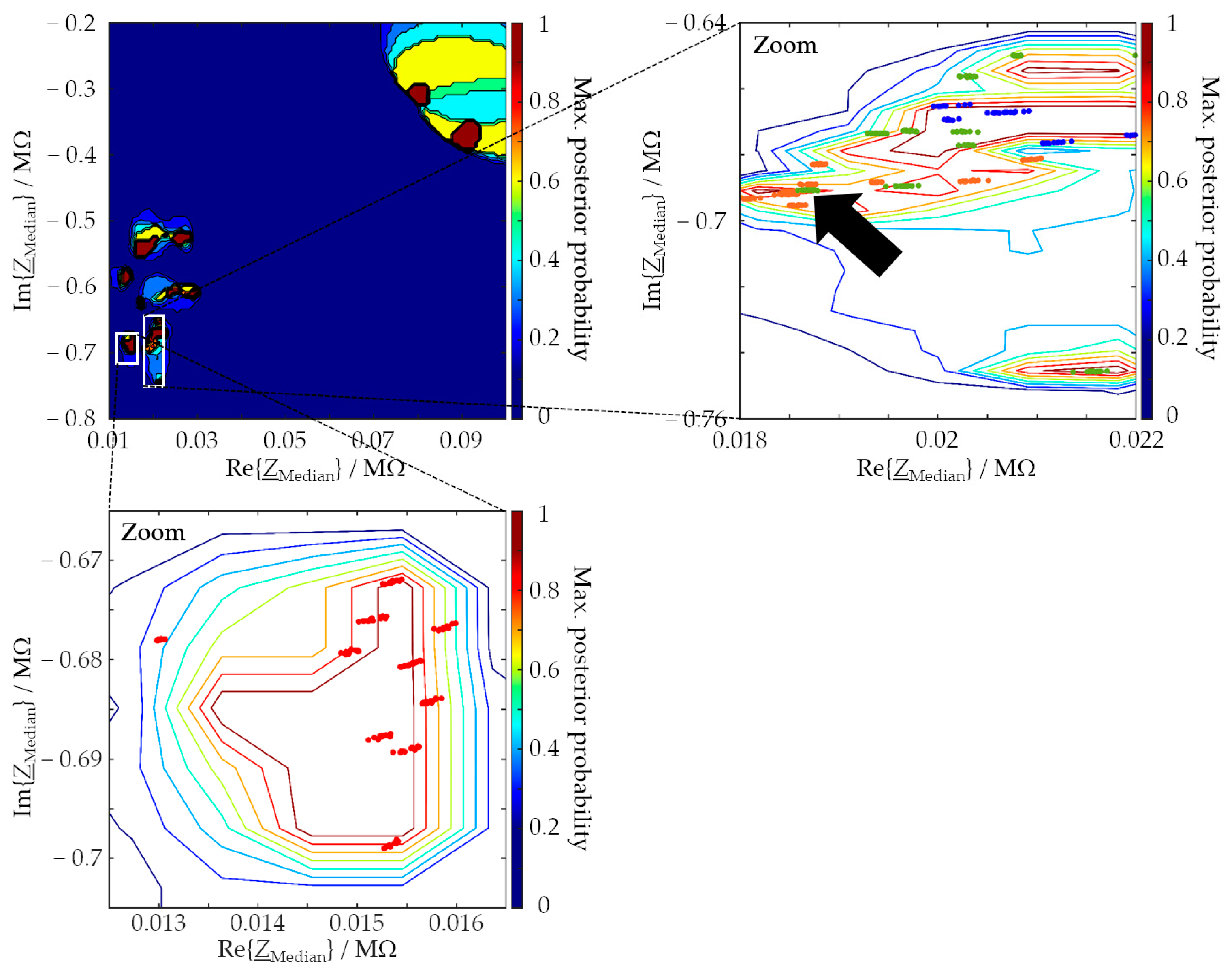
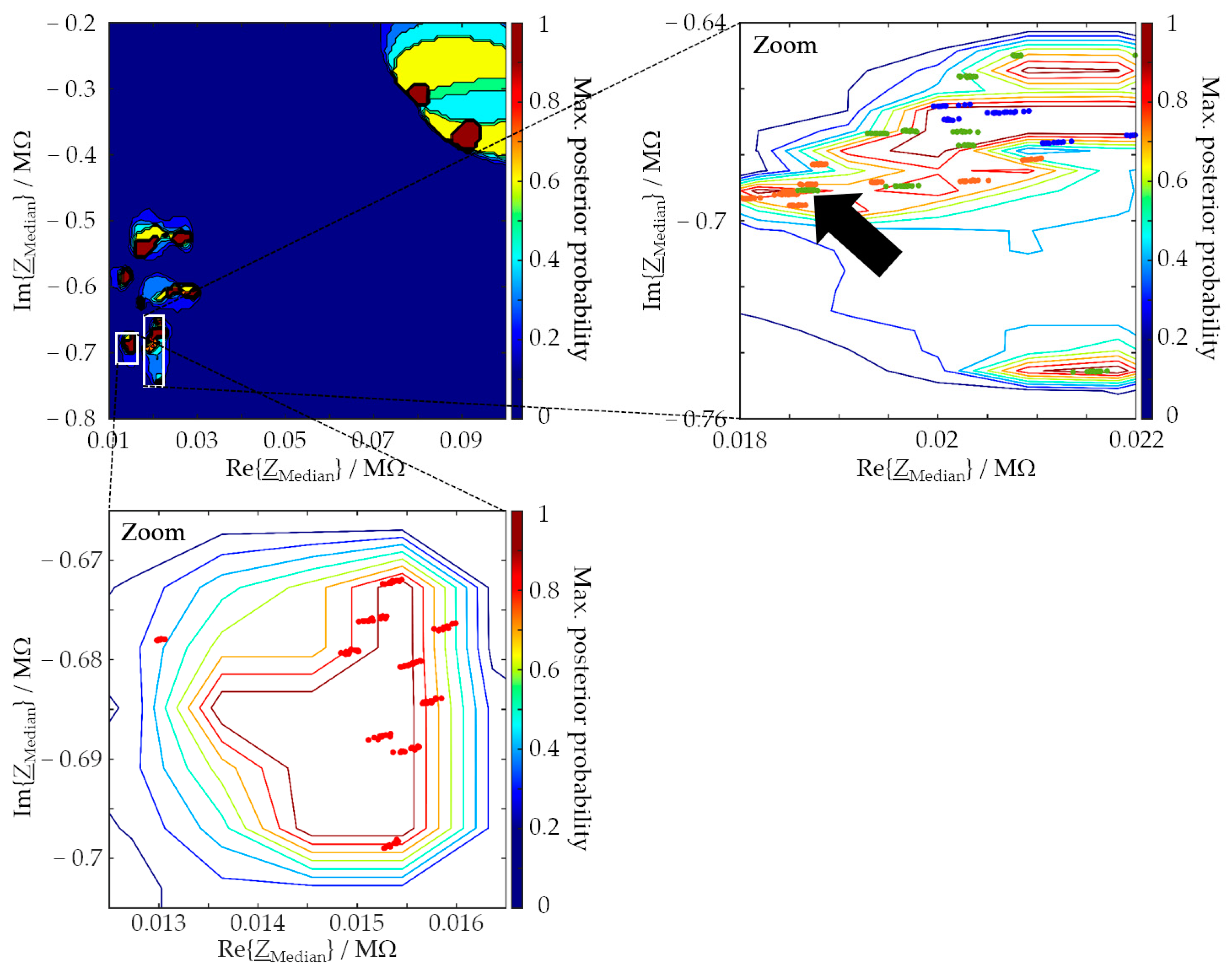
Regarding task (c) from above, variance analysis of the SVM results has shown that the uncertainty can be a valuable quality criterion for an SVM result in addition to the assignment correctness. The assignment correctness can be high overall, although the uncertainty of any one class assignment is also high. It is our understanding that measurement results involving some form of machine learning cannot be trusted (in the sense that led to the GUM methodology) unless a variance analysis or an equivalent approach is performed. At least for the material systems studied by us to date, we believe that we can state the following: EIS spectra are suitable input data to SVM classifiers, which are able to classify molding compounds reliably and with a small enough uncertainty to be useful for foundry applications.
In further steps, the SVM will be optimized, i.e., an optimal hyperparameter selection will be performed. With the results generated in this process and the classification findings, the aim will then be to refine the classes in order to be able to make concentration statements about how much bentonite is present in the measured mold material via a regression SVM. This aspect is highly relevant in the field of molding material preparation in foundry applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}