


A Deep Learning Model for Markerless Pose Estimation Based on Keypoint Augmentation: What Factors Influence Errors in Biomechanical Applications?

 , , , , and
, , , , and
Abstract
1. Introduction
2. Materials and Methods
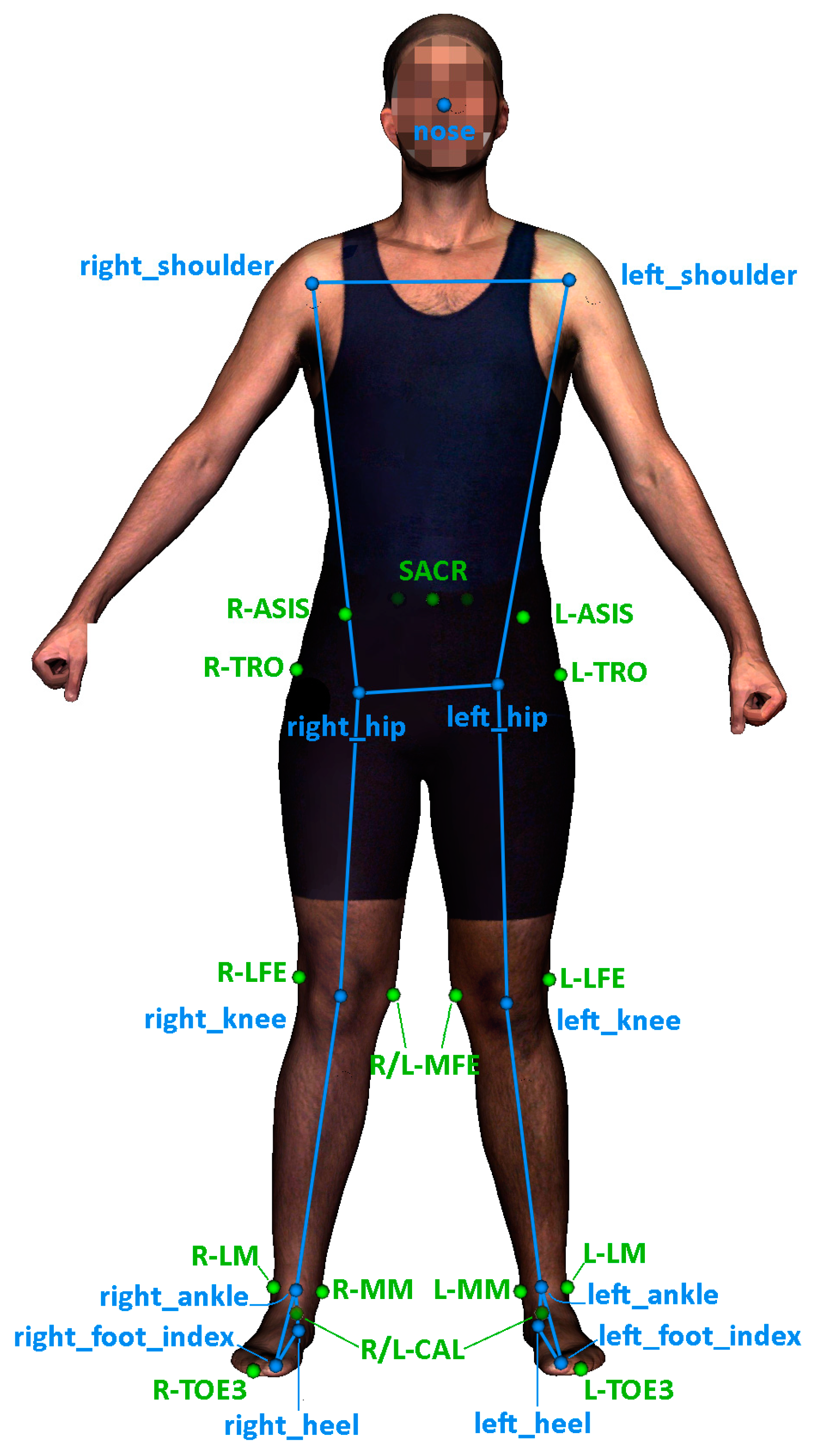
2.1. Dataset
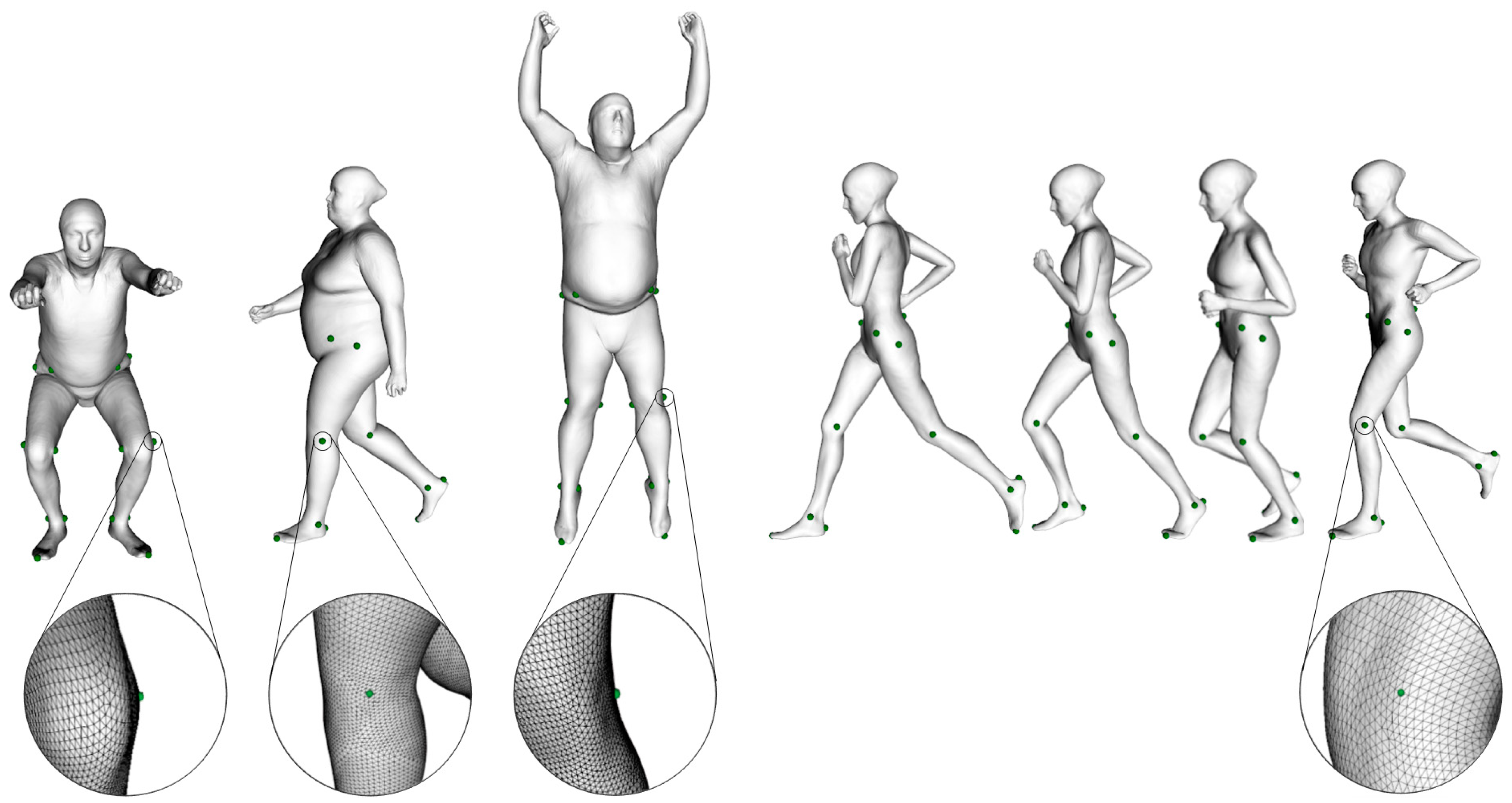
2.1.1. Dataset Generation Overview
2.1.2. Description of the Data Used in Training and Validation
2.2. Data Pre-Processing
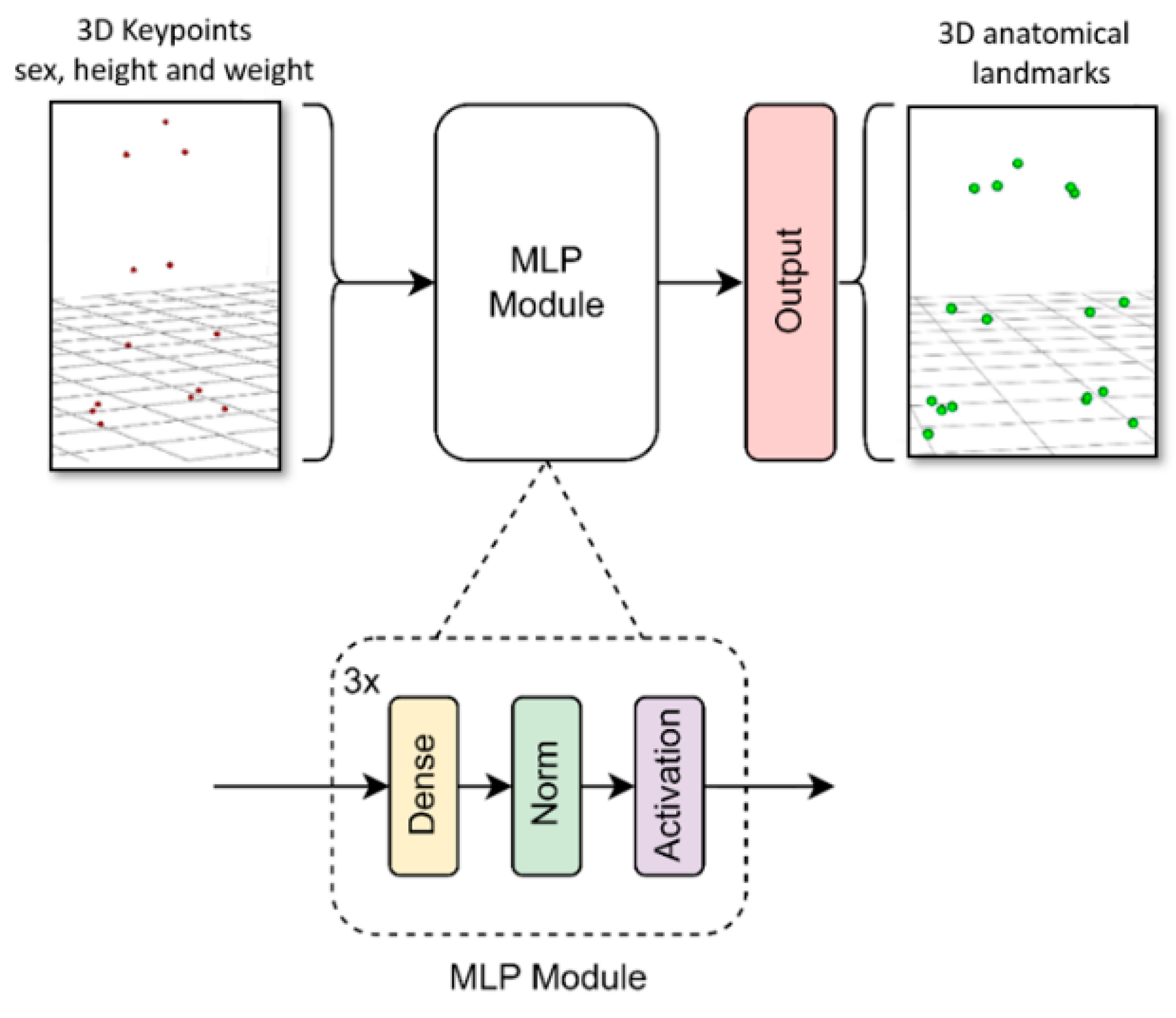
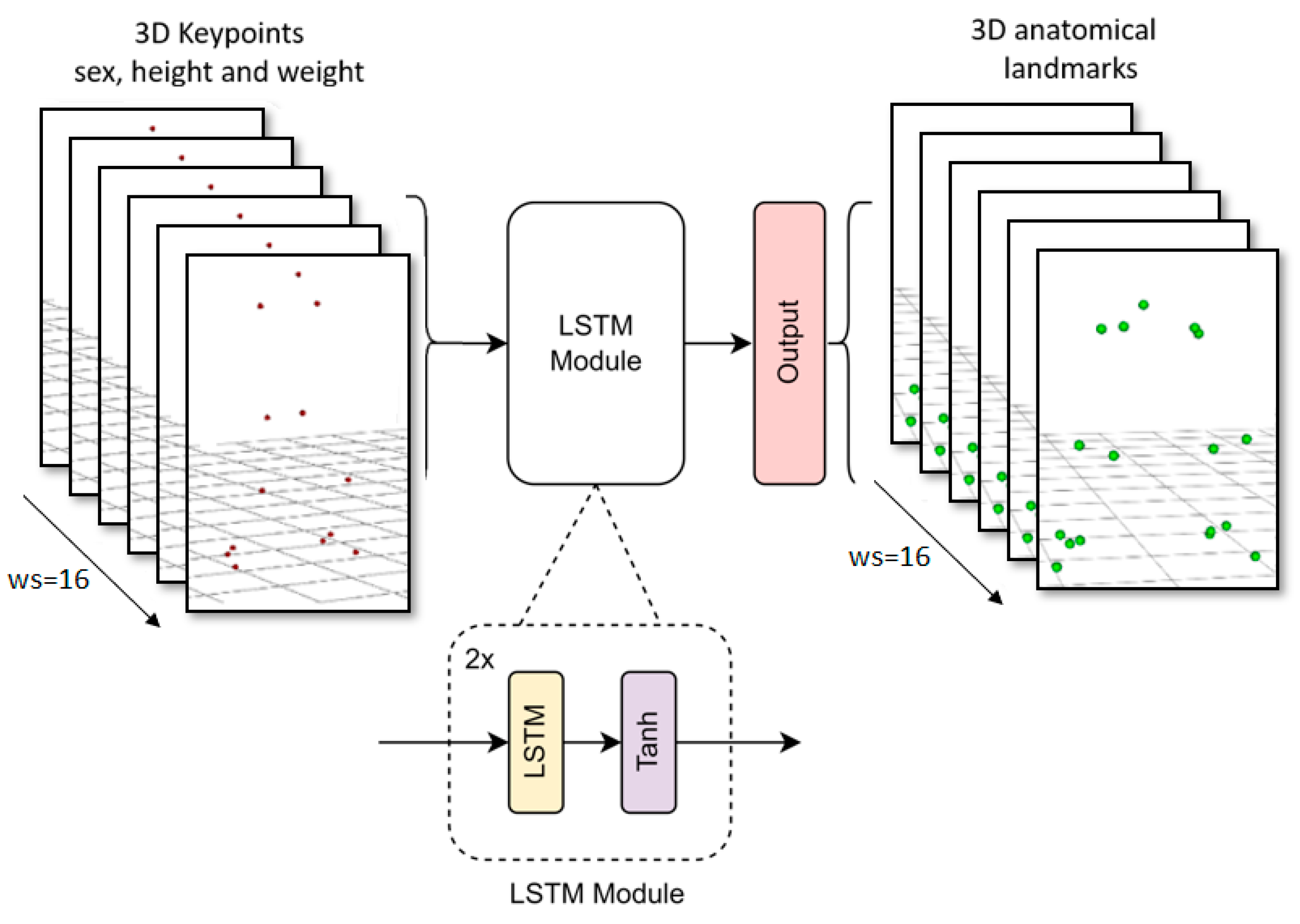
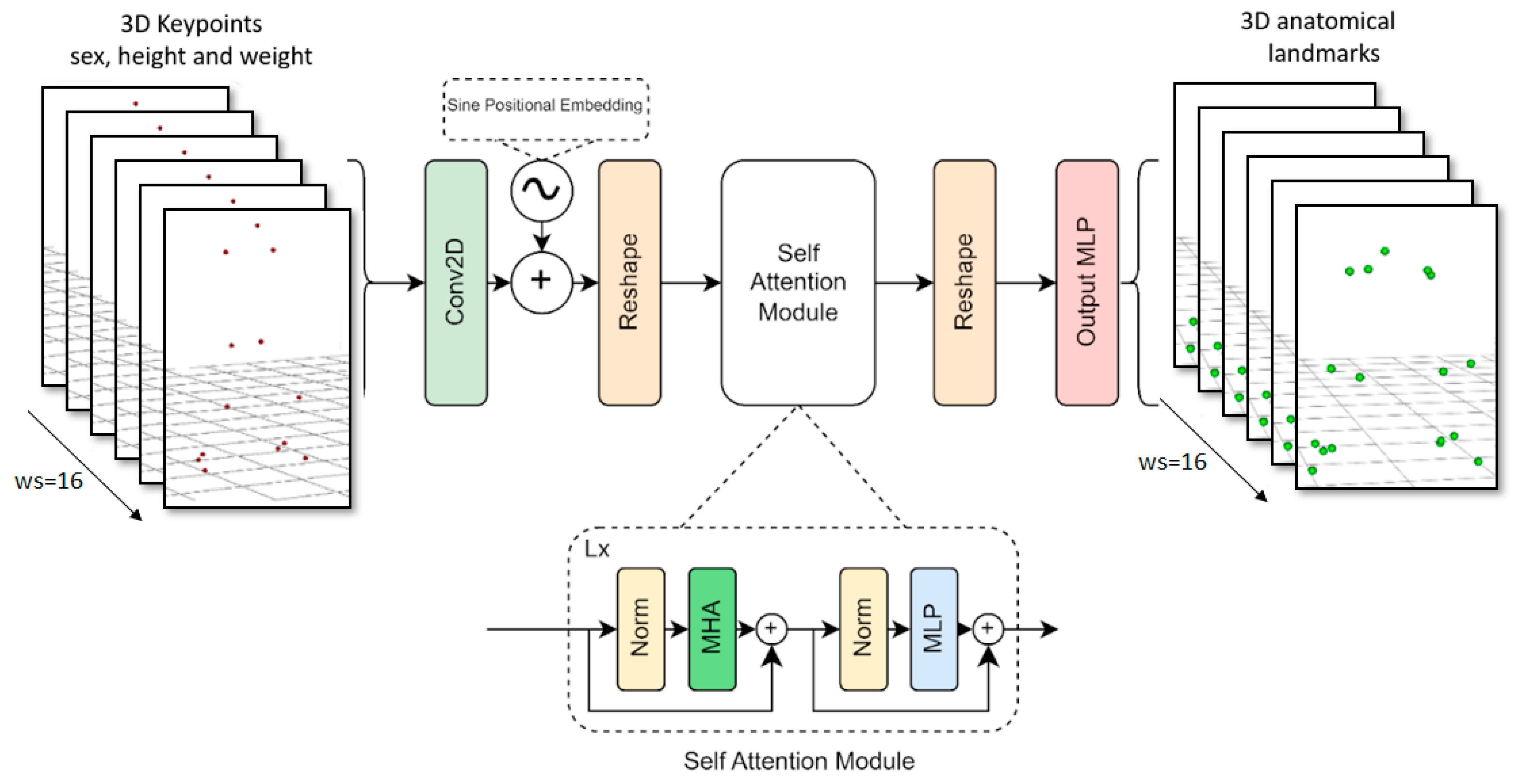
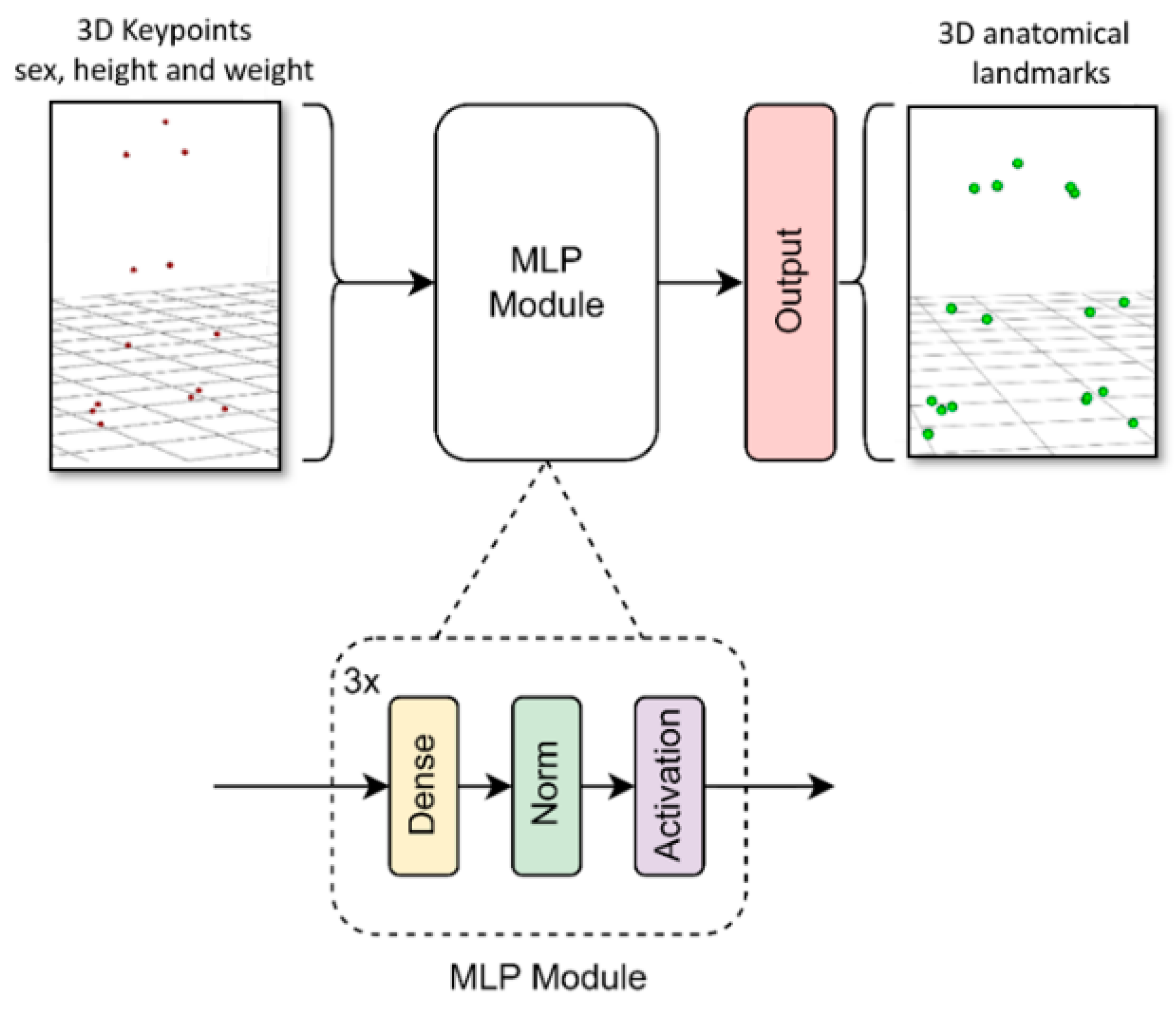
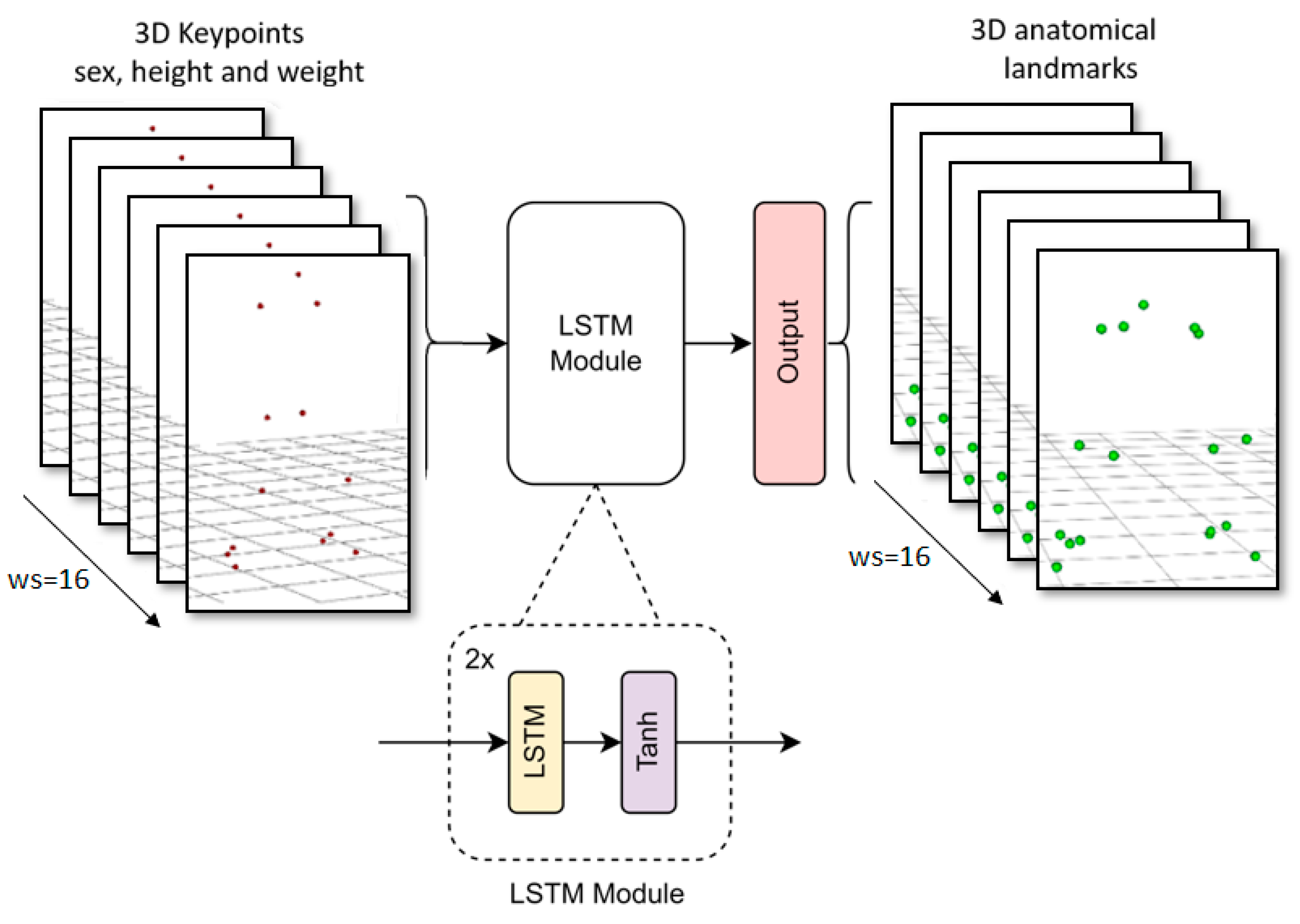
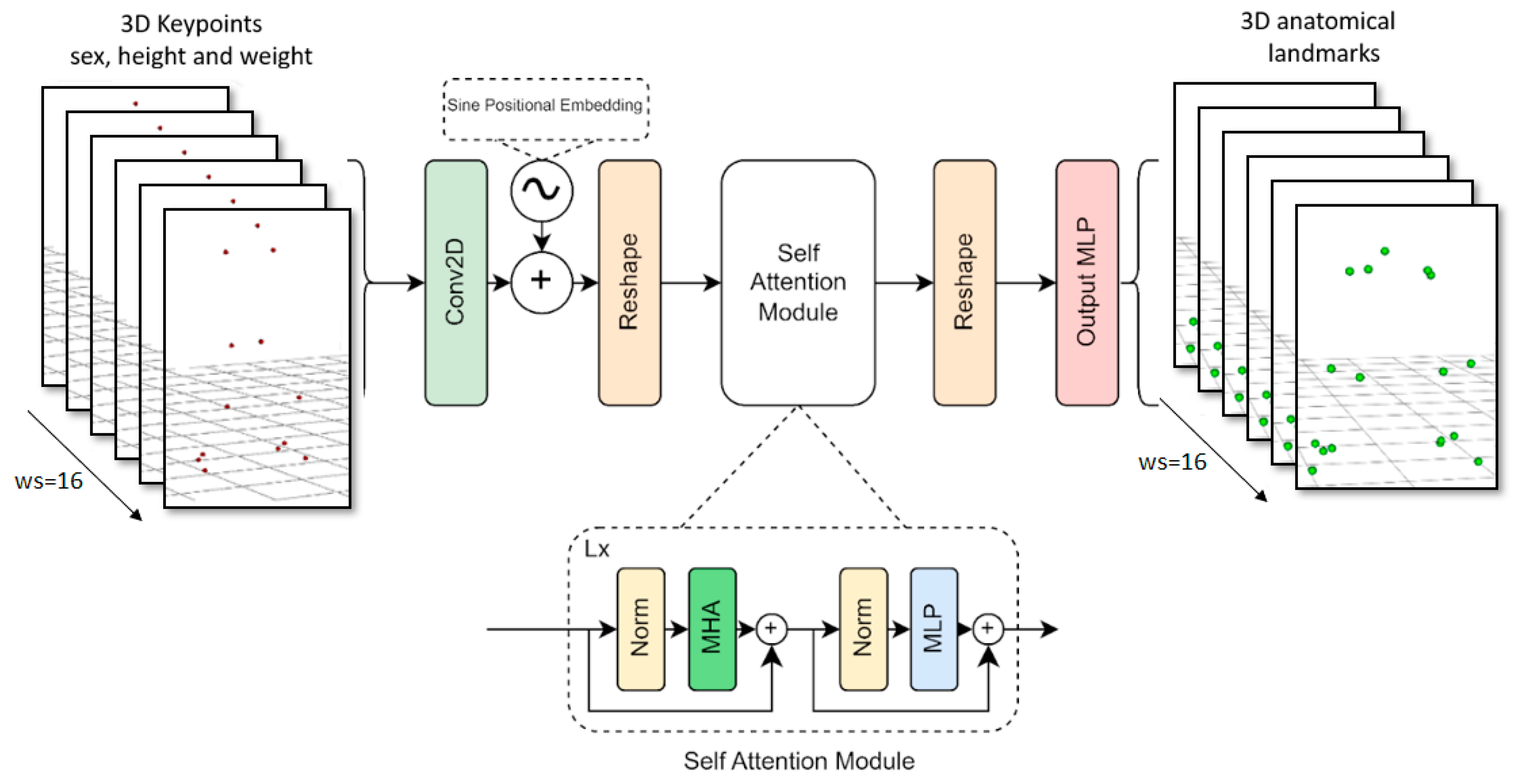
2.3. Marker Augmentation Models
- MLP: a multilayer perceptron with a rectified linear unit activation function (ReLU). This model is less accurate but very lightweight, allowing its implementation on devices with low resources such as mobile phones or other low-cost devices.
- LSTM: an adaptation of the long-short term memory neural network used in OpenCap for the full body [25]. It uses temporal but not spatial information.
- Transformer [44]: designed for a comprehensive understanding of the problem, capturing long-range dependences in the global context. This model improves upon the previous one by incorporating spatial information. Transformers have recently been used successfully in different problems. It is more resource intensive but more accurate.
2.3.1. MLP Model
2.3.2. LSTM Model
2.3.3. Transformer Model
2.4. Metrics
2.5. Error Analysis
- Prediction model, movement, and anatomical landmarks for the prediction of anatomical landmark locations;
- Prediction model, side of the body joint, and rotation axis for the calculation of joint angles.
3. Results
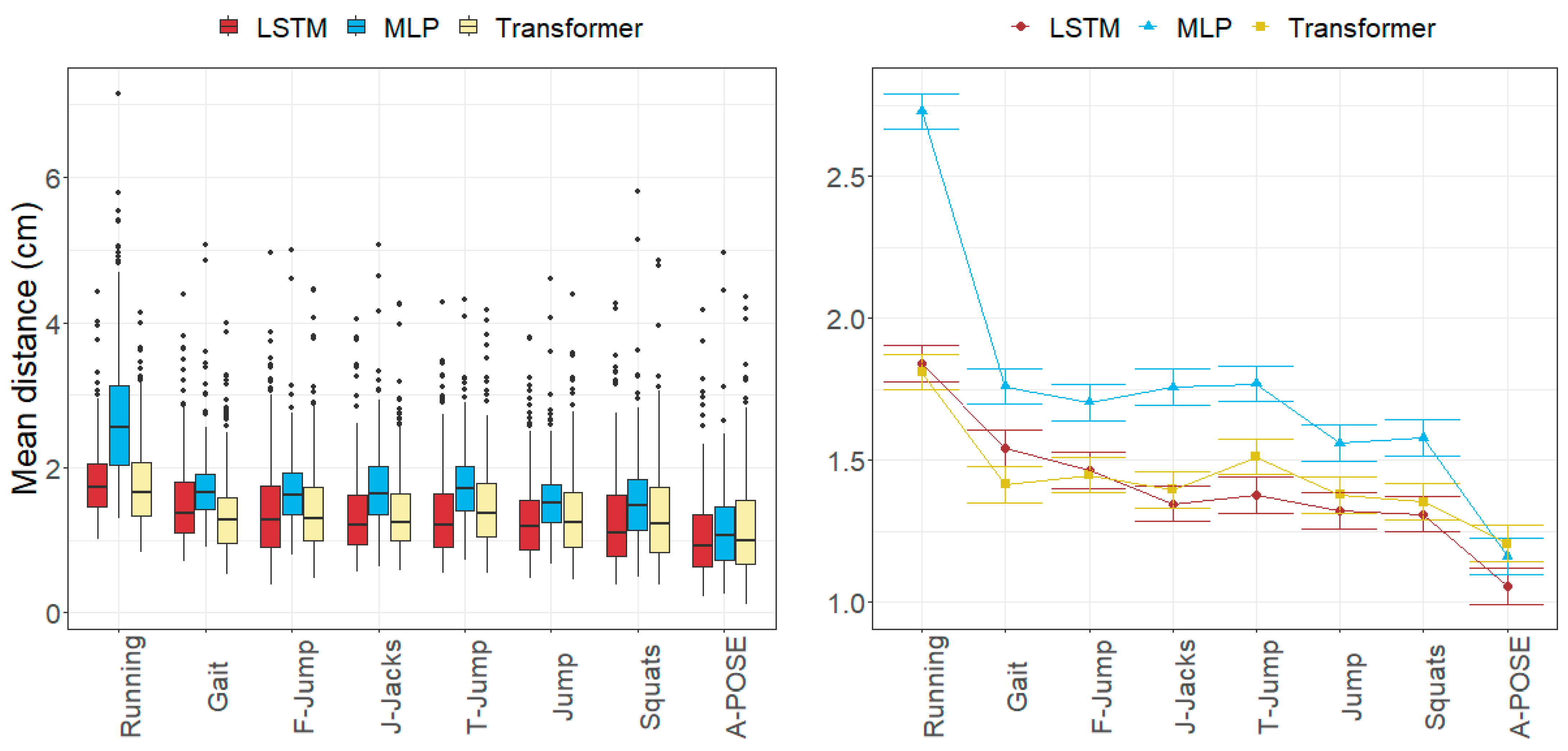
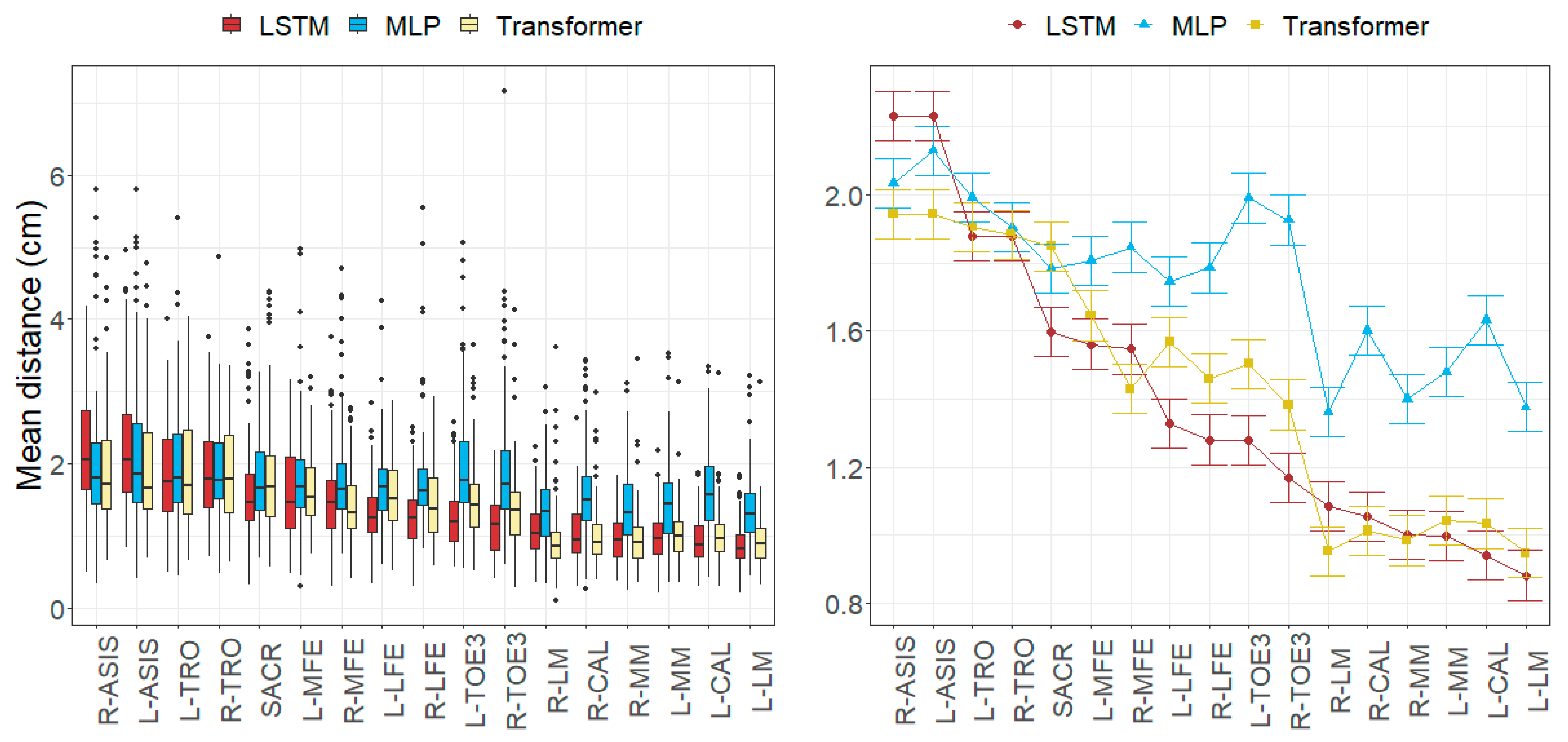
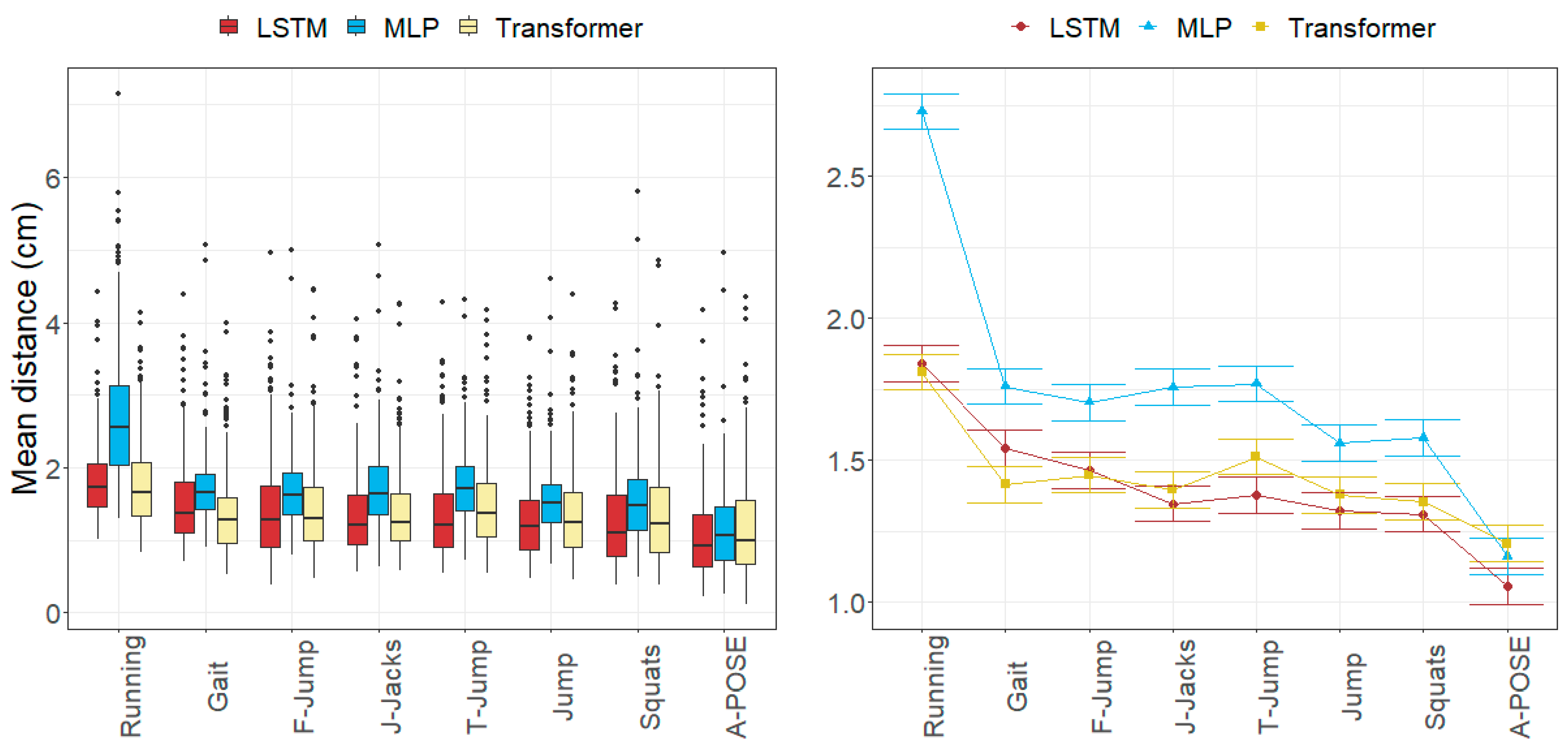
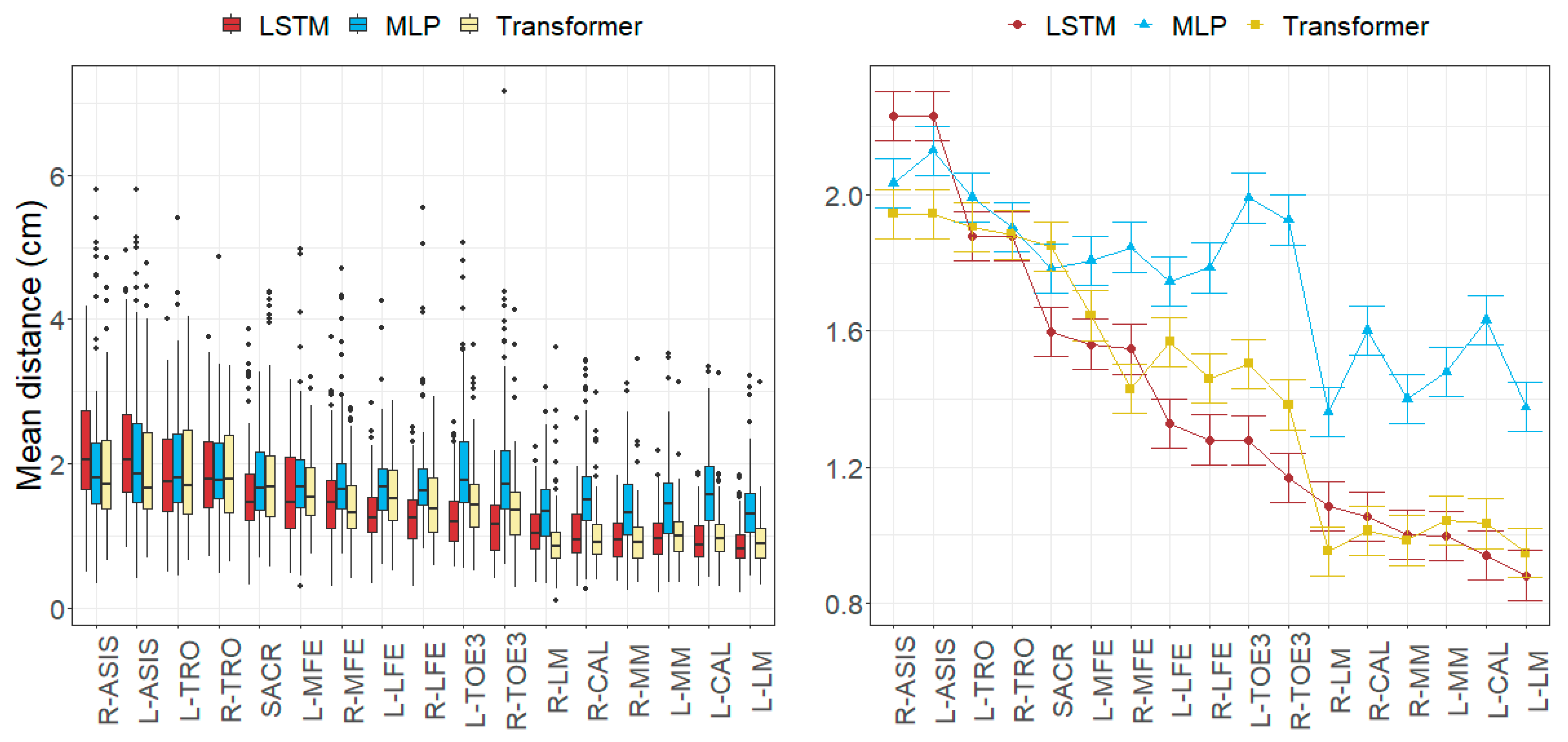
3.1. Anatomical Landmark Position Errors
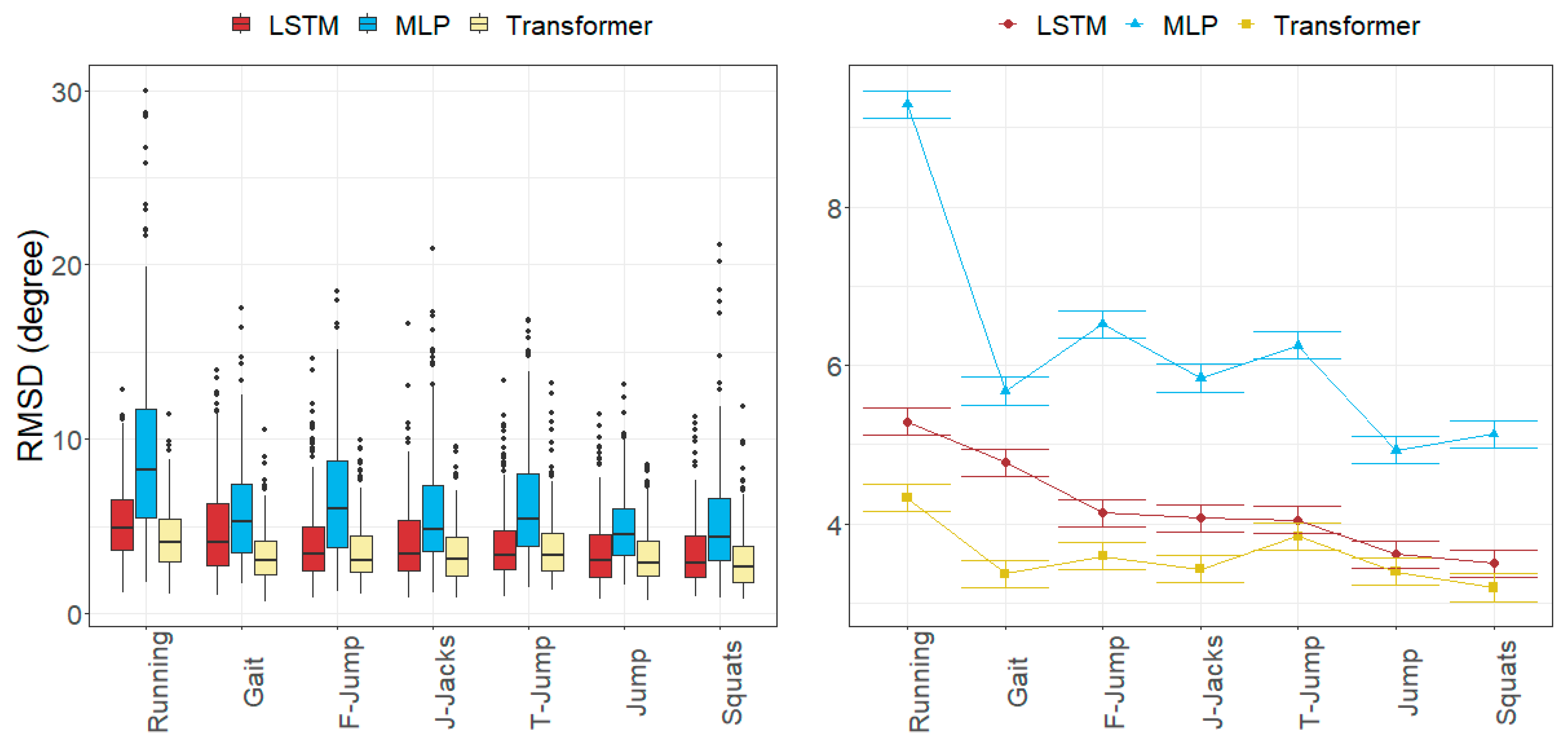
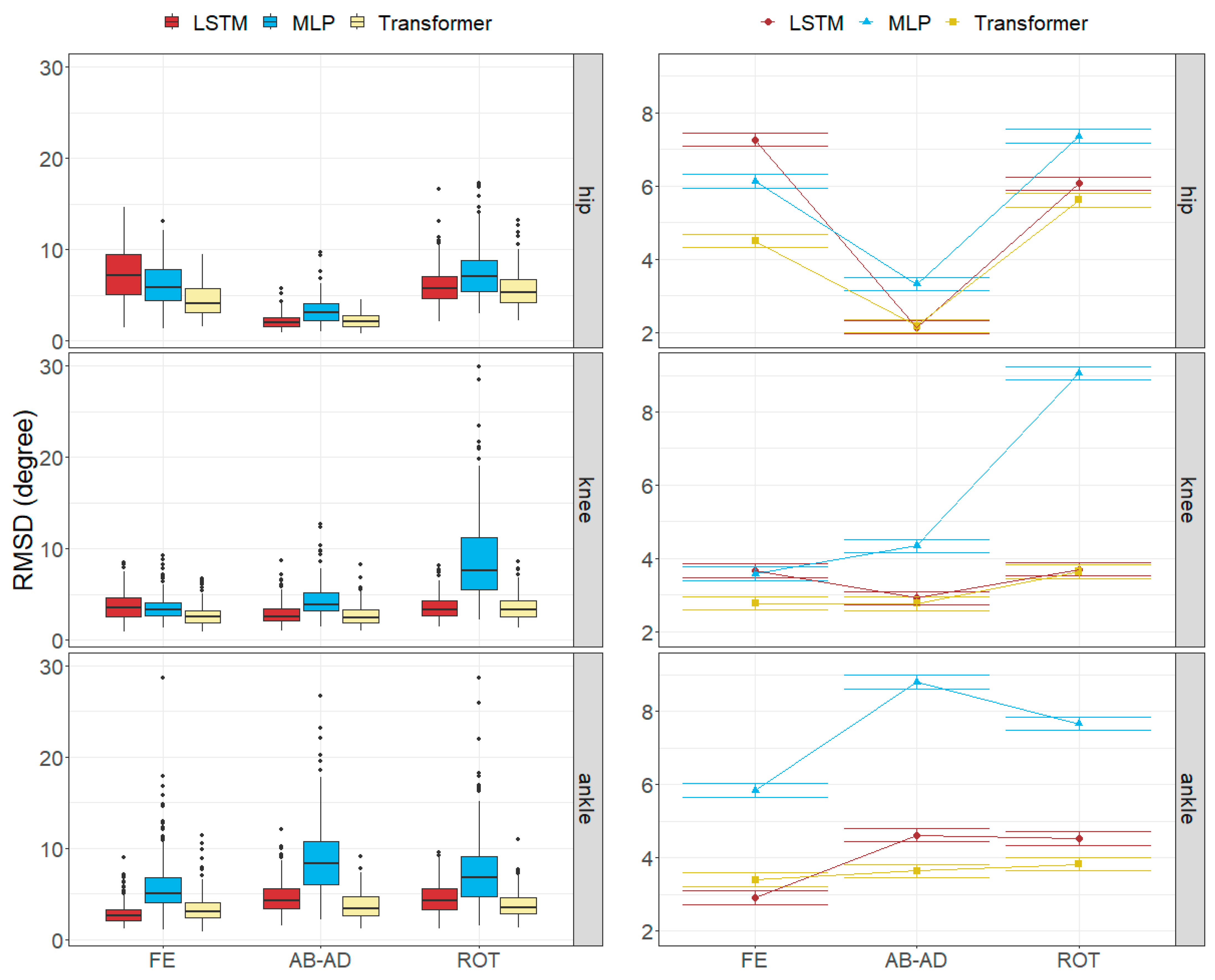
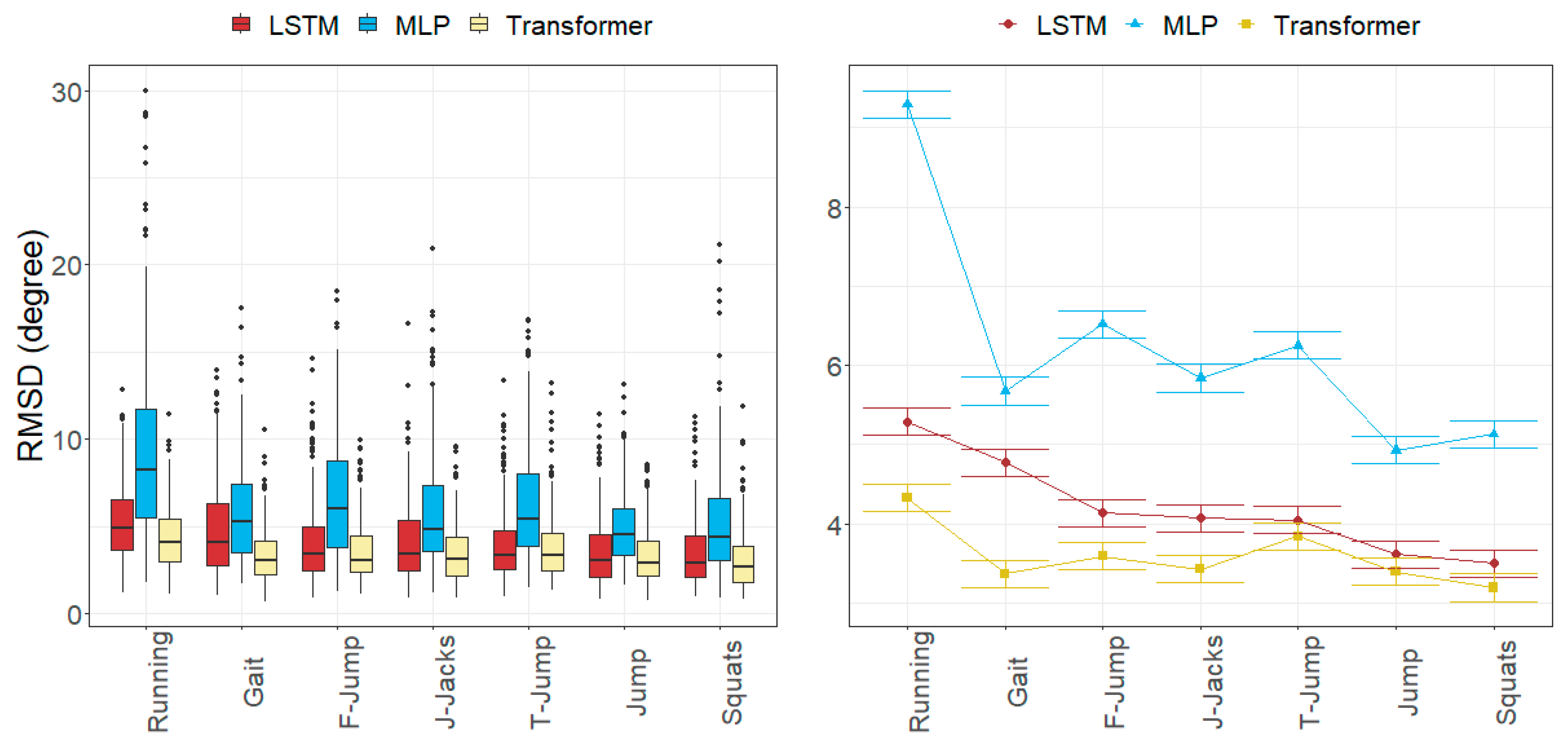
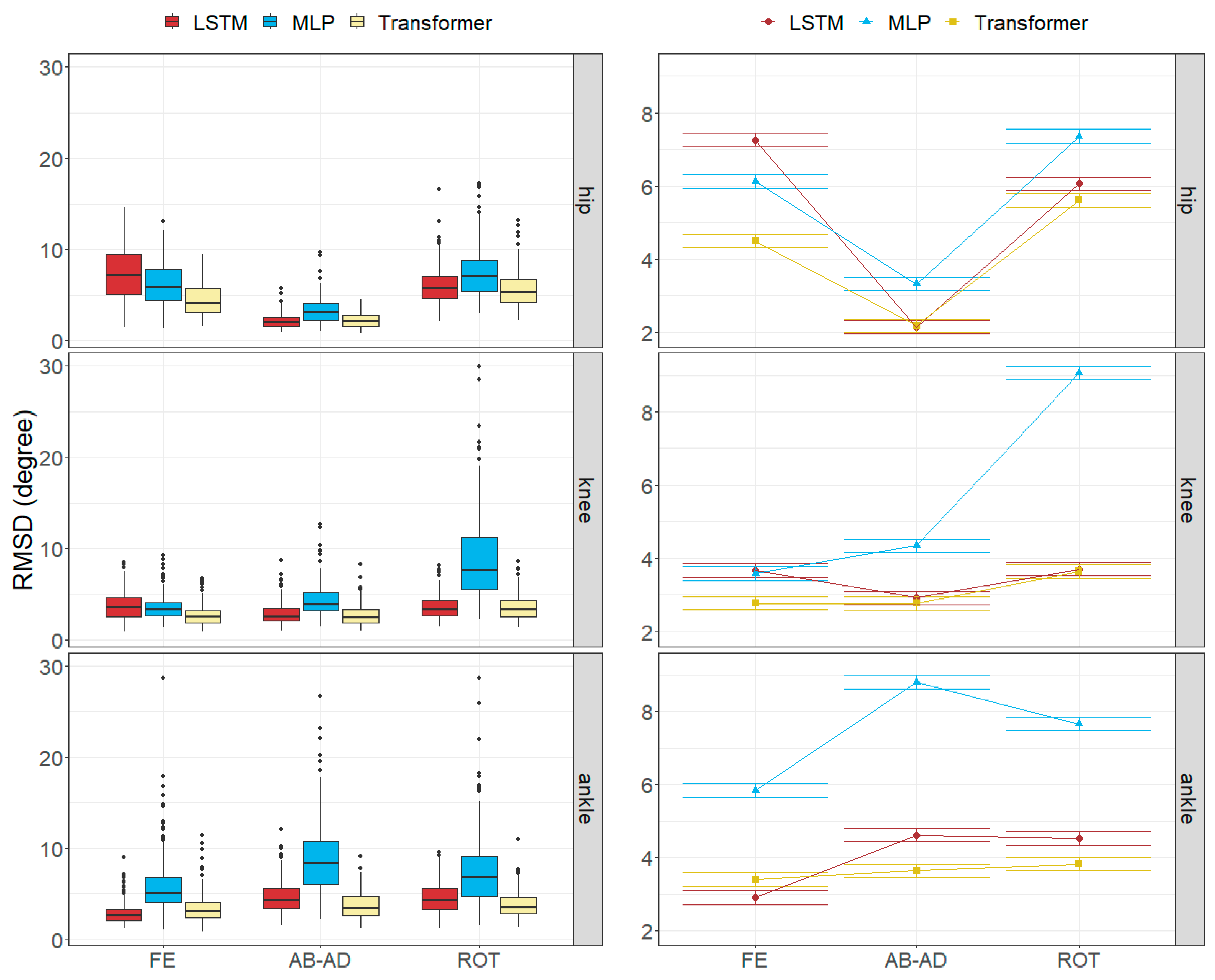
3.2. Joint Angle Errors
3.3. Factors Influencing the Errors
4. Discussion
4.1. Size of the Joint Angle and Landmark Position Errors
4.2. Factors Influencing the Errors
4.3. Other Considerations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Anatomical Landmarks | Name in Dataset |
| L-ASIS | Lt ASIS |
| L-CAL | Lt Calcaneous Post |
| L-LFE | Lt Femoral Lateral Epicn |
| L-LM | Lt Lateral Malleolus |
| L-MFE | Lt Femoral Medial Epicn |
| L-MM | Lt Medial Malleolus |
| L-TRO | Lt Trochanterion |
| L-TOE3 | Lt Digit II |
| R-ASIS | Rt ASIS |
| R-CAL | Rt Calcaneous Post |
| R-LFE | Rt Femoral Lateral Epicn |
| R-LM | Rt Lateral Malleolus |
| R-MFE | Rt Femoral Medial Epicn |
| R-MM | Rt Medial Malleolus |
| R- TRO | Rt Trochanterion |
| R-TOE3 | Rt Digit II |
| SACR | This point is midpoint between Lt PSIS and Rt PSIS |
References
- Marras, W.S.; Ferguson, S.A.; Gupta, P.; Bose, S.; Parnianpour, M.; Kim, J.Y.; Crowell, R.R. The Quantification of Low Back Disorder Using Motion Measures. Methodology and Validation. Spine 1999, 24, 2091–2100. [Google Scholar] [CrossRef]
- Ferrario, V.F.; Sforza, C.; Poggio, C.E.; Schmitz, J.H.; Tartaglia, G. A Three-dimensional Non-invasive Study of Head Flexion and Extension in Young Non-patient Subjects. J. Oral Rehabil. 1997, 24, 361–368. [Google Scholar] [CrossRef]
- Bulgheroni, M.V.; Antonaci, F.; Sandrini, G.; Ghirmai, S.; Nappi, G.; Pedotti, A. A 3D Kinematic Method to Evaluate Cervical Spine Voluntary Movements in Humans. Funct. Neurol. 1998, 3, 239–245. [Google Scholar]
- Lu, T.-W.; Chang, C.-F. Biomechanics of Human Movement and Its Clinical Applications. Kaohsiung J. Med. Sci. 2012, 28, S13–S25. [Google Scholar] [CrossRef]
- Whittle, M.W. Clinical Gait Analysis: A Review. Hum. Mov. Sci. 1996, 15, 369–387. [Google Scholar] [CrossRef]
- Best, R.; Begg, R. Overview of Movement Analysis and Gait Features. In Computational Intelligence for Movement Sciences: Neural Networks and Other Emerging Techniques; IGI Global: Hershey, PA, USA, 2006; pp. 1–69. [Google Scholar]
- Wu, G.; Siegler, S.; Allard, P.; Kirtley, C.; Leardini, A.; Rosenbaum, D.; Whittle, M.; D’Lima, D.D.; Cristofolini, L.; Witte, H.; et al. ISB Recommendation on Definitions of Joint Coordinate System of Various Joints for the Reporting of Human Joint Motion—Part I: Ankle, Hip, and Spine. J. Biomech. 2002, 35, 543–548. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; van der Helm, F.C.T.; Veeger, H.E.J.; Makhsous, M.; Van Roy, P.; Anglin, C.; Nagels, J.; Karduna, A.R.; McQuade, K.; Wang, X.; et al. ISB Recommendation on Definitions of Joint Coordinate Systems of Various Joints for the Reporting of Human Joint Motion—Part II: Shoulder, Elbow, Wrist and Hand. J. Biomech. 2005, 38, 981–992. [Google Scholar] [CrossRef]
- Della Croce, U.; Leardini, A.; Chiari, L.; Cappozzo, A. Human Movement Analysis Using Stereophotogrammetry: Part 4: Assessment of Anatomical Landmark Misplacement and Its Effects on Joint Kinematics. Gait Posture 2005, 21, 226–237. [Google Scholar] [CrossRef] [PubMed]
- Chiari, L.; Croce, U.D.; Leardini, A.; Cappozzo, A. Human Movement Analysis Using Stereophotogrammetry: Part 2: Instrumental Errors. Gait Posture 2005, 21, 197–211. [Google Scholar] [CrossRef]
- Cappozzo, A.; Della Croce, U.; Leardini, A.; Chiari, L. Human Movement Analysis Using Stereophotogrammetry: Part 1: Theoretical Background. Gait Posture 2005, 21, 186–196. [Google Scholar]
- Kanko, R.M.; Laende, E.K.; Davis, E.M.; Selbie, W.S.; Deluzio, K.J. Concurrent Assessment of Gait Kinematics Using Marker-Based and Markerless Motion Capture. J. Biomech. 2021, 127, 110665. [Google Scholar] [CrossRef]
- Captury—Markerless Motion Capture Technology. Available online: https://captury.com/ (accessed on 18 January 2024).
- Theia Markerless—Markerless Motion Capture Redefined. Available online: https://www.theiamarkerless.ca/ (accessed on 18 January 2024).
- Iosa, M.; Picerno, P.; Paolucci, S.; Morone, G. Wearable Inertial Sensors for Human Movement Analysis. Expert Rev. Med. Devices 2016, 13, 641–659. [Google Scholar] [CrossRef]
- Picerno, P.; Iosa, M.; D’Souza, C.; Benedetti, M.G.; Paolucci, S.; Morone, G. Wearable Inertial Sensors for Human Movement Analysis: A Five-Year Update. Expert Rev. Med. Devices 2021, 18, 79–94. [Google Scholar] [CrossRef]
- RajKumar, A.; Vulpi, F.; Bethi, S.R.; Wazir, H.K.; Raghavan, P.; Kapila, V. Wearable Inertial Sensors for Range of Motion Assessment. IEEE Sens. J. 2020, 20, 3777–3787. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A Convolutional Network for Real-Time 6-Dof Camera Relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 34–50. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 472–487. [Google Scholar]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless Pose Estimation of User-Defined Body Parts with Deep Learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef] [PubMed]
- Martınez Hidalgo, G. OpenPose: Whole-Body Pose Estimation; Carnegie Mellon University: Pittsburgh, PA, USA, 2019. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- He, Y.; Yan, R.; Fragkiadaki, K.; Yu, S.-I. Epipolar Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7776–7785. [Google Scholar]
- Uhlrich, S.D.; Falisse, A.; Kidziński, Ł.; Muccini, J.; Ko, M.; Chaudhari, A.S.; Hicks, J.L.; Delp, S.L. OpenCap: Human Movement Dynamics from Smartphone Videos. PLoS Comput. Biol. 2023, 19, e1011462. [Google Scholar] [CrossRef] [PubMed]
- Wade, L.; Needham, L.; McGuigan, P.; Bilzon, J. Applications and Limitations of Current Markerless Motion Capture Methods for Clinical Gait Biomechanics. PeerJ 2022, 10, e12995. [Google Scholar] [CrossRef] [PubMed]
- Sigal, L.; Balan, A.O.; Black, M.J. HumanEva: Synchronized Video and Motion Capture Dataset and Baseline Algorithm for Evaluation of Articulated Human Motion. Int. J. Comput. Vis. 2010, 87, 4–27. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef]
- Carnegie Mellon University—CMU Graphics Lab—Motion Capture Library. Available online: http://mocap.cs.cmu.edu/ (accessed on 15 February 2024).
- Kwolek, B.; Michalczuk, A.; Krzeszowski, T.; Switonski, A.; Josinski, H.; Wojciechowski, K. Calibrated and Synchronized Multi-View Video and Motion Capture Dataset for Evaluation of Gait Recognition. Multimed. Tools Appl. 2019, 78, 32437–32465. [Google Scholar] [CrossRef]
- Rosskamp, J.; Weller, R.; Zachmann, G. Effects of Markers in Training Datasets on the Accuracy of 6D Pose Estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2024; pp. 4457–4466. [Google Scholar]
- Kanko, R.M.; Outerleys, J.B.; Laende, E.K.; Selbie, W.S.; Deluzio, K.J. Comparison of Concurrent and Asynchronous Running Kinematics and Kinetics from Marker-Based Motion Capture and Markerless Motion Capture under Two Clothing Conditions. bioRxiv 2023. [Google Scholar] [CrossRef]
- Kanko, R.M.; Laende, E.K.; Strutzenberger, G.; Brown, M.; Selbie, W.S.; DePaul, V.; Scott, S.H.; Deluzio, K.J. Assessment of Spatiotemporal Gait Parameters Using a Deep Learning Algorithm-Based Markerless Motion Capture System. J. Biomech. 2021, 122, 110414. [Google Scholar] [CrossRef] [PubMed]
- Kanko, R.M.; Laende, E.; Selbie, W.S.; Deluzio, K.J. Inter-Session Repeatability of Markerless Motion Capture Gait Kinematics. J. Biomech. 2021, 121, 110422. [Google Scholar] [CrossRef] [PubMed]
- Vafadar, S.; Skalli, W.; Bonnet-Lebrun, A.; Khalifé, M.; Renaudin, M.; Hamza, A.; Gajny, L. A Novel Dataset and Deep Learning-Based Approach for Marker-Less Motion Capture during Gait. Gait Posture 2021, 86, 70–76. [Google Scholar] [CrossRef] [PubMed]
- Vafadar, S.; Skalli, W.; Bonnet-Lebrun, A.; Assi, A.; Gajny, L. Assessment of a Novel Deep Learning-Based Marker-Less Motion Capture System for Gait Study. Gait Posture 2022, 94, 138–143. [Google Scholar] [CrossRef] [PubMed]
- Needham, L.; Evans, M.; Wade, L.; Cosker, D.P.; McGuigan, M.P.; Bilzon, J.L.; Colyer, S.L. The Development and Evaluation of a Fully Automated Markerless Motion Capture Workflow. J. Biomech. 2022, 144, 111338. [Google Scholar] [CrossRef]
- Delp, S.L.; Anderson, F.C.; Arnold, A.S.; Loan, P.; Habib, A.; John, C.T.; Guendelman, E.; Thelen, D.G. OpenSim: Open-Source Software to Create and Analyze Dynamic Simulations of Movement. IEEE Trans. Biomed. Eng. 2007, 54, 1940–1950. [Google Scholar] [CrossRef]
- Ruescas Nicolau, A.V.; Medina-Ripoll, E.; Parrilla Bernabé, E.; De Rosario Martínez, H. Human Tracking Dataset of 3D Anatomical Landmarks and Pose Keypoints. 2024. Available online: https://doi.org/10.17632/493s6f753v.2 (accessed on 1 January 2024).
- Parrilla, E.; Ballester, A.; Parra, P.; Ruescas, A.; Uriel, J.; Garrido, D.; Alemany, S. MOVE 4D: Accurate High-Speed 3D Body Models in Motion. In Proceedings of the 3DBODY.TECH 2019, Lugano, Switzerland, 22–23 October 2019; pp. 30–32. [Google Scholar]
- Ruescas Nicolau, A.V.; De Rosario, H.; Della-Vedova, F.B.; Bernabé, E.P.; Juan, M.-C.; López-Pascual, J. Accuracy of a 3D Temporal Scanning System for Gait Analysis: Comparative With a Marker-Based Photogrammetry System. Gait Posture 2022, 97, 28–34. [Google Scholar] [CrossRef]
- Ruescas-Nicolau, A.V.; De Rosario, H.; Bernabé, E.P.; Juan, M.-C. Positioning Errors of Anatomical Landmarks Identified by Fixed Vertices in Homologous Meshes. Gait Posture 2024, 108, 215–221. [Google Scholar] [CrossRef]
- Ruescas Nicolau, A.V.; Medina Ripoll, E.J.; Parrilla Bernabé, E.; De Rosario, H. Multimodal Human Motion Dataset of 3d Anatomical Landmarks and Pose Keypoints. Data Brief 2024, 53, 110157. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Chollet, F. Others Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 1 January 2024).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. Others KerasTuner. 2019. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. TransPose: Keypoint Localization via Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 11802–11812. [Google Scholar]
- Song, K.; Hullfish, T.J.; Scattone Silva, R.; Silbernagel, K.G.; Baxter, J.R. Markerless Motion Capture Estimates of Lower Extremity Kinematics and Kinetics Are Comparable to Marker-Based across 8 Movements. J. Biomech. 2023, 157, 111751. [Google Scholar] [CrossRef]
- Horsak, B.; Eichmann, A.; Lauer, K.; Prock, K.; Krondorfer, P.; Siragy, T.; Dumphart, B. Concurrent Validity of Smartphone-Based Markerless Motion Capturing to Quantify Lower-Limb Joint Kinematics in Healthy and Pathological Gait. J. Biomech. 2023, 159, 111801. [Google Scholar] [CrossRef] [PubMed]
- Grood, E.S.; Suntay, W.J. A Joint Coordinate System for the Clinical Description of Three-Dimensional Motions: Application to the Knee. J. Biomech. Eng. 1983, 105, 136–144. [Google Scholar] [CrossRef] [PubMed]
- Harrington, M.E.; Zavatsky, A.B.; Lawson, S.E.M.; Yuan, Z.; Theologis, T.N. Prediction of the Hip Joint Centre in Adults, Children, and Patients with Cerebral Palsy Based on Magnetic Resonance Imaging. J. Biomech. 2007, 40, 595–602. [Google Scholar] [CrossRef]
- Team, R.D.C. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2010. [Google Scholar]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest Package: Tests in Linear Mixed Effects Models. J. Stat. Softw. 2017, 82, 1–26. [Google Scholar] [CrossRef]
- Lüdecke, D.; Ben-Shachar, M.S.; Patil, I.; Waggoner, P.; Makowski, D. Performance: An R Package for Assessment, Comparison and Testing of Statistical Models. J. Open Source Softw. 2021, 6, 3139. [Google Scholar] [CrossRef]
- De Rosario, H. “Phia: Post-Hoc Interaction Analysis”. R Package Version 0.3-1. 2024. Available online: https://CRAN.R-project.org/package=phia (accessed on 13 February 2024).
- Nakagawa, S.; Schielzeth, H. A General and Simple Method for Obtaining R2 from Generalized Linear Mixed-effects Models. Methods Ecol. Evol. 2013, 4, 133–142. [Google Scholar] [CrossRef]
- Della Croce, U.; Cappozzo, A.; Kerrigan, D.C. Pelvis and Lower Limb Anatomical Landmark Calibration Precision and Its Propagation to Bone Geometry and Joint Angles. Med. Biol. Eng. Comput. 1999, 37, 155–161. [Google Scholar] [CrossRef]
- Ripic, Z.; Nienhuis, M.; Signorile, J.F.; Best, T.M.; Jacobs, K.A.; Eltoukhy, M. A Comparison of Three-Dimensional Kinematics between Markerless and Marker-Based Motion Capture in Overground Gait. J. Biomech. 2023, 159, 111793. [Google Scholar] [CrossRef] [PubMed]
- Kanko, R.M.; Outerleys, J.B.; Laende, E.K.; Selbie, W.S.; Deluzio, K.J. Comparison of Concurrent and Asynchronous Running Kinematics and Kinetics From Marker-Based and Markerless Motion Capture Under Varying Clothing Conditions. J. Appl. Biomech. 2024, 1, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wren, T.A.L.; Isakov, P.; Rethlefsen, S.A. Comparison of Kinematics between Theia Markerless and Conventional Marker-Based Gait Analysis in Clinical Patients. Gait Posture 2023, 104, 9–14. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset | Sex (Size) | Height (m) Mean (std) | Weight (kg) Mean (std) | Age (years) Mean (std) |
|---|---|---|---|---|
| Training | Female (N = 29) | 1.64 (0.08) | 70.89 (18.19) | 38.21 (13.27) |
| Male (N = 28) | 1.78 (0.11) | 79.77 (17.83) | 37.04 (11.27) | |
| Total (N = 57) | 1.71 (0.12) | 75.25 (18.41) | 37.63 (12.23) | |
| Test | Female (N = 7) | 1.58 (0.08) | 55.57 (11.40) | 34.86 (11.36) |
| Male (N = 7) | 1.75 (0.08) | 78.54 (11.49) | 31.14 (9.41) | |
| Total (N = 14) | 1.67 (0.12) | 67.06 (16.22) | 33.00 (10.21) | |
| Dataset | Total (N = 71) | 1.70 (0.12) | 73.64 (18.18) | 36.72 (11.94) |
| Anatomical Landmark (AL) | A-Pose | Gait | F-Jump | J-Jacks | Jump | Running | Squats | T-Jump | Across Movement |
|---|---|---|---|---|---|---|---|---|---|
| L-ASIS | 1.49 | 2.18 | 2.18 | 1.96 | 1.97 | 2.96 | 2.09 | 2.21 | 2.13 |
| L-CAL | 0.98 | 1.84 | 1.37 | 1.91 | 1.36 | 2.65 | 1.39 | 1.55 | 1.63 |
| L-LFE | 1.37 | 1.58 | 1.60 | 1.85 | 1.50 | 2.53 | 1.81 | 1.72 | 1.75 |
| L-LM | 0.82 | 1.39 | 1.27 | 1.60 | 1.24 | 2.21 | 1.08 | 1.42 | 1.38 |
| L-MFE | 0.99 | 1.85 | 1.70 | 1.91 | 1.59 | 2.93 | 1.80 | 1.69 | 1.81 |
| L-MM | 0.82 | 1.60 | 1.45 | 1.68 | 1.33 | 2.42 | 1.18 | 1.35 | 1.48 |
| L-TRO | 1.37 | 1.78 | 1.91 | 1.95 | 1.97 | 2.82 | 1.93 | 2.20 | 1.99 |
| L-TOE3 | 1.19 | 2.05 | 1.90 | 1.96 | 1.65 | 3.44 | 1.51 | 2.22 | 1.99 |
| R-ASIS | 1.43 | 2.30 | 2.27 | 1.80 | 1.96 | 2.56 | 1.99 | 1.97 | 2.03 |
| R-CAL | 1.04 | 1.57 | 1.52 | 1.82 | 1.37 | 2.53 | 1.22 | 1.75 | 1.60 |
| R-LFE | 1.30 | 1.66 | 1.62 | 1.80 | 1.53 | 3.12 | 1.61 | 1.64 | 1.79 |
| R-LM | 0.77 | 1.40 | 1.51 | 1.43 | 1.11 | 2.09 | 1.15 | 1.44 | 1.36 |
| R-MFE | 1.37 | 1.96 | 1.64 | 1.68 | 1.55 | 3.27 | 1.56 | 1.74 | 1.85 |
| R-MM | 1.00 | 1.31 | 1.47 | 1.41 | 1.24 | 2.18 | 1.18 | 1.41 | 1.40 |
| R-TRO | 1.30 | 1.86 | 1.91 | 1.77 | 1.76 | 2.62 | 2.01 | 1.99 | 1.90 |
| R-TOE3 | 1.26 | 2.07 | 1.64 | 1.63 | 1.53 | 3.75 | 1.47 | 2.05 | 1.93 |
| SACR | 1.27 | 1.53 | 2.03 | 1.71 | 1.88 | 2.28 | 1.86 | 1.72 | 1.78 |
| Across AL | 1.16 | 1.76 | 1.70 | 1.76 | 1.56 | 2.73 | 1.58 | 1.77 | 1.75 |
| Anatomical Landmark (AL) | A-Pose | Gait | F-Jump | J-Jacks | Jump | Running | Squats | T-Jump | Across Movement |
|---|---|---|---|---|---|---|---|---|---|
| L-ASIS | 1.68 | 2.38 | 2.74 | 1.91 | 2.23 | 2.21 | 2.39 | 2.31 | 2.23 |
| L-CAL | 0.64 | 1.00 | 0.92 | 1.20 | 0.83 | 1.34 | 0.69 | 0.92 | 0.94 |
| L-LFE | 1.00 | 1.42 | 1.46 | 1.18 | 1.27 | 1.72 | 1.30 | 1.26 | 1.33 |
| L-LM | 0.63 | 0.90 | 0.82 | 0.78 | 0.80 | 1.43 | 0.86 | 0.84 | 0.88 |
| L-MFE | 0.95 | 2.06 | 1.64 | 1.43 | 1.26 | 2.41 | 1.33 | 1.39 | 1.56 |
| L-MM | 0.65 | 1.13 | 0.97 | 1.06 | 0.88 | 1.63 | 0.80 | 0.86 | 1.00 |
| L-TRO | 1.32 | 1.85 | 2.24 | 1.69 | 1.93 | 1.96 | 2.06 | 1.97 | 1.88 |
| L-TOE3 | 1.03 | 1.48 | 1.37 | 1.31 | 1.03 | 1.90 | 0.91 | 1.19 | 1.28 |
| R-ASIS | 1.84 | 2.42 | 2.63 | 2.05 | 2.26 | 2.12 | 2.26 | 2.29 | 2.23 |
| R-CAL | 0.93 | 0.96 | 1.01 | 0.99 | 1.03 | 1.52 | 0.97 | 1.04 | 1.05 |
| R-LFE | 0.82 | 1.50 | 1.13 | 1.12 | 1.23 | 1.98 | 1.23 | 1.24 | 1.28 |
| R-LM | 0.88 | 1.19 | 0.90 | 0.98 | 1.01 | 1.78 | 0.96 | 0.98 | 1.08 |
| R-MFE | 1.10 | 1.94 | 1.40 | 1.59 | 1.24 | 2.57 | 1.18 | 1.37 | 1.55 |
| R-MM | 0.76 | 1.17 | 0.88 | 1.05 | 0.85 | 1.63 | 0.78 | 0.90 | 1.00 |
| R-TRO | 1.62 | 1.79 | 2.10 | 1.74 | 1.94 | 1.67 | 2.10 | 2.06 | 1.88 |
| R-TOE3 | 0.84 | 1.41 | 0.99 | 1.26 | 1.03 | 1.79 | 0.82 | 1.20 | 1.17 |
| SACR | 1.29 | 1.60 | 1.75 | 1.55 | 1.66 | 1.66 | 1.62 | 1.63 | 1.60 |
| Across AL | 1.06 | 1.54 | 1.47 | 1.35 | 1.32 | 1.84 | 1.31 | 1.38 | 1.41 |
| Anatomical Landmark (AL) | A-Pose | Gait | F-Jump | J-Jacks | Jump | Running | Squats | T-Jump | Across Movement |
|---|---|---|---|---|---|---|---|---|---|
| L-ASIS | 1.76 | 1.80 | 2.01 | 1.70 | 2.02 | 2.11 | 2.03 | 2.13 | 1.94 |
| L-CAL | 0.86 | 1.05 | 0.99 | 1.00 | 0.96 | 1.53 | 0.90 | 0.99 | 1.03 |
| L-LFE | 1.47 | 1.63 | 1.51 | 1.58 | 1.58 | 1.63 | 1.50 | 1.64 | 1.57 |
| L-LM | 0.74 | 0.85 | 0.85 | 0.97 | 0.92 | 1.43 | 0.89 | 0.95 | 0.95 |
| L-MFE | 1.56 | 1.73 | 1.66 | 1.72 | 1.61 | 1.69 | 1.54 | 1.66 | 1.65 |
| L-MM | 0.77 | 1.04 | 1.00 | 1.16 | 0.94 | 1.46 | 0.98 | 1.00 | 1.04 |
| L-TRO | 1.76 | 1.73 | 1.90 | 1.63 | 2.03 | 2.00 | 2.08 | 2.13 | 1.91 |
| L-TOE3 | 1.13 | 1.52 | 1.59 | 1.51 | 1.25 | 2.22 | 1.16 | 1.65 | 1.50 |
| R-ASIS | 1.73 | 1.83 | 2.02 | 1.80 | 2.07 | 1.93 | 1.97 | 2.19 | 1.94 |
| R-CAL | 0.67 | 0.96 | 0.93 | 1.06 | 0.83 | 1.75 | 0.87 | 1.04 | 1.01 |
| R-LFE | 1.20 | 1.42 | 1.58 | 1.39 | 1.33 | 1.89 | 1.40 | 1.46 | 1.46 |
| R-LM | 0.55 | 0.98 | 0.91 | 0.93 | 0.73 | 1.84 | 0.78 | 0.91 | 0.95 |
| R-MFE | 1.30 | 1.44 | 1.51 | 1.44 | 1.33 | 1.61 | 1.38 | 1.43 | 1.43 |
| R-MM | 0.72 | 0.95 | 0.95 | 1.00 | 0.83 | 1.60 | 0.86 | 0.96 | 0.98 |
| R-TRO | 1.72 | 1.81 | 1.90 | 1.68 | 1.95 | 1.94 | 1.97 | 2.09 | 1.88 |
| R-TOE3 | 0.81 | 1.55 | 1.41 | 1.42 | 1.16 | 2.31 | 0.93 | 1.48 | 1.38 |
| SACR | 1.78 | 1.77 | 1.92 | 1.76 | 1.92 | 1.84 | 1.78 | 2.02 | 1.85 |
| Across AL | 1.21 | 1.42 | 1.45 | 1.40 | 1.38 | 1.81 | 1.35 | 1.51 | 1.44 |
| Movement | Hip | Knee | Ankle | Across Joint and Axis | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FE | AB-AD | ROT | FE | AB-AD | ROT | FE | AB-AD | ROT | ||
| Running | 7.39 | 5.21 | 9.04 | 4.67 | 6.59 | 15.35 | 10.1 | 12.86 | 12.44 | 9.29 |
| Gait | 5.13 | 3.13 | 6.71 | 3.55 | 3.64 | 8.08 | 5.33 | 8.73 | 6.77 | 5.68 |
| F-Jump | 7.62 | 2.97 | 6.24 | 3.49 | 3.94 | 10.58 | 5.82 | 9.01 | 8.99 | 6.52 |
| J-Jacks | 5.25 | 2.52 | 7.96 | 3.89 | 3.77 | 7.73 | 7.06 | 7.74 | 6.63 | 5.84 |
| T-Jump | 5.01 | 3.48 | 9.51 | 3.07 | 4.7 | 8.68 | 5.31 | 9.02 | 7.45 | 6.25 |
| Jump | 6.08 | 2.8 | 6.06 | 3.06 | 3.85 | 5.93 | 4.17 | 6.92 | 5.48 | 4.93 |
| Squats | 6.4 | 3.1 | 6 | 3.37 | 3.9 | 7.09 | 3.09 | 7.3 | 5.89 | 5.13 |
| Across movement | 6.12 | 3.32 | 7.36 | 3.59 | 4.34 | 9.06 | 5.84 | 8.8 | 7.66 | 6.23 |
| Movement | Hip | Knee | Ankle | Across Joint and Axis | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FE | AB-AD | ROT | FE | AB-AD | ROT | FE | AB-AD | ROT | ||
| Running | 7.62 | 2.9 | 6.52 | 4.54 | 4.12 | 5.52 | 4.3 | 5.63 | 6.44 | 5.29 |
| Gait | 9.32 | 2.04 | 6.53 | 4.29 | 2.96 | 3.73 | 2.93 | 5.64 | 5.48 | 4.77 |
| F-Jump | 8.63 | 1.96 | 5.5 | 3.53 | 2.99 | 3.89 | 2.2 | 4.68 | 3.84 | 4.14 |
| J-Jacks | 5.13 | 2.1 | 7.24 | 2.82 | 2.69 | 3.2 | 3.79 | 4.76 | 4.93 | 4.07 |
| T-Jump | 7.15 | 2.31 | 6.65 | 3.24 | 2.67 | 3.37 | 2.92 | 4 | 4.08 | 4.04 |
| Jump | 6.82 | 1.78 | 5.2 | 3.4 | 2.42 | 3.19 | 2.29 | 3.94 | 3.5 | 3.61 |
| Squats | 6.17 | 1.86 | 4.78 | 3.88 | 2.6 | 3.03 | 1.99 | 3.68 | 3.47 | 3.5 |
| Across movement | 7.26 | 2.13 | 6.06 | 3.67 | 2.92 | 3.7 | 2.92 | 4.62 | 4.53 | 4.2 |
| Movement | Hip | Knee | Ankle | Across Joint and Axis | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FE | AB-AD | ROT | FE | AB-AD | ROT | FE | AB-AD | ROT | ||
| Running | 4.94 | 2.63 | 5.34 | 3.47 | 3.23 | 4.31 | 5.7 | 4.98 | 4.33 | 4.32 |
| Gait | 3.99 | 1.91 | 4.78 | 2.92 | 2.2 | 3.33 | 3.49 | 4.17 | 3.52 | 3.37 |
| F-Jump | 5.26 | 2.16 | 5.66 | 2.72 | 2.74 | 3.8 | 3.06 | 3.27 | 3.64 | 3.59 |
| J-Jacks | 3.52 | 2.03 | 5.6 | 2.21 | 2.41 | 3.57 | 3.73 | 3.97 | 3.84 | 3.43 |
| T-Jump | 4.91 | 2.43 | 7.13 | 2.76 | 2.98 | 3.84 | 3.2 | 3.31 | 4.02 | 3.84 |
| Jump | 4.78 | 1.95 | 5.67 | 2.6 | 2.83 | 3.34 | 2.63 | 3.16 | 3.55 | 3.39 |
| Squats | 4.07 | 2.07 | 5.09 | 2.74 | 2.99 | 3.3 | 1.99 | 2.63 | 3.85 | 3.19 |
| Across movement | 4.49 | 2.17 | 5.61 | 2.78 | 2.77 | 3.64 | 3.4 | 3.64 | 3.82 | 3.59 |
| SS | MS | DoF | |
|---|---|---|---|
| Model | 137.88 | 68.94 | 2 |
| Movement | 381.41 | 54.49 | 7 |
| Anatomical landmark | 617.89 | 38.62 | 16 |
| Model:Movement | 78.22 | 5.59 | 14 |
| Model:Anatomical landmark | 88.55 | 2.77 | 32 |
| SS | MS | DoF | |
|---|---|---|---|
| Model | 6745.12 | 3372.56 | 2 |
| Movement | 2828.23 | 471.37 | 6 |
| Joint | 1032.79 | 516.40 | 2 |
| Axis | 3186.66 | 1593.33 | 2 |
| Side | 67.53 | 67.53 | 1 |
| Model:Movement | 1233.55 | 102.80 | 4 |
| Model:Joint | 1454.16 | 363.54 | 12 |
| Model:Axis | 1195.82 | 298.95 | 4 |
| Joint:Axis | 4614.30 | 1153.58 | 4 |
| Model:Joint:Axis | 1593.14 | 199.14 | 8 |
| MLP | LSTM | Transformer | |
|---|---|---|---|
| Anatomical landmark distance (cm) | 1.75 | 1.41 | 1.44 |
| RMSD (degrees) | 6.23 | 4.20 | 3.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruescas-Nicolau, A.V.; Medina-Ripoll, E.; de Rosario, H.; Sanchiz Navarro, J.; Parrilla, E.; Juan Lizandra, M.C. A Deep Learning Model for Markerless Pose Estimation Based on Keypoint Augmentation: What Factors Influence Errors in Biomechanical Applications? Sensors 2024, 24, 1923. https://doi.org/10.3390/s24061923
Ruescas-Nicolau AV, Medina-Ripoll E, de Rosario H, Sanchiz Navarro J, Parrilla E, Juan Lizandra MC. A Deep Learning Model for Markerless Pose Estimation Based on Keypoint Augmentation: What Factors Influence Errors in Biomechanical Applications? Sensors. 2024; 24(6):1923. https://doi.org/10.3390/s24061923
Chicago/Turabian StyleRuescas-Nicolau, Ana V., Enrique Medina-Ripoll, Helios de Rosario, Joaquín Sanchiz Navarro, Eduardo Parrilla, and María Carmen Juan Lizandra. 2024. "A Deep Learning Model for Markerless Pose Estimation Based on Keypoint Augmentation: What Factors Influence Errors in Biomechanical Applications?" Sensors 24, no. 6: 1923. https://doi.org/10.3390/s24061923
APA StyleRuescas-Nicolau, A. V., Medina-Ripoll, E., de Rosario, H., Sanchiz Navarro, J., Parrilla, E., & Juan Lizandra, M. C. (2024). A Deep Learning Model for Markerless Pose Estimation Based on Keypoint Augmentation: What Factors Influence Errors in Biomechanical Applications? Sensors, 24(6), 1923. https://doi.org/10.3390/s24061923