
UAV Detection Using Reinforcement Learning


Abstract
1. Introduction
Article Contribution
2. Literature Review
2.1. Radio Frequency Detection Techniques Based on Machine Learning
2.2. Detection Techniques Based on Reinforcement Learning
2.2.1. Detection Based on Acoustic and Visual Cues
2.2.2. Detection Based on Source Radiation
2.2.3. Detection Based on Radio Frequency Signals
3. Methodology
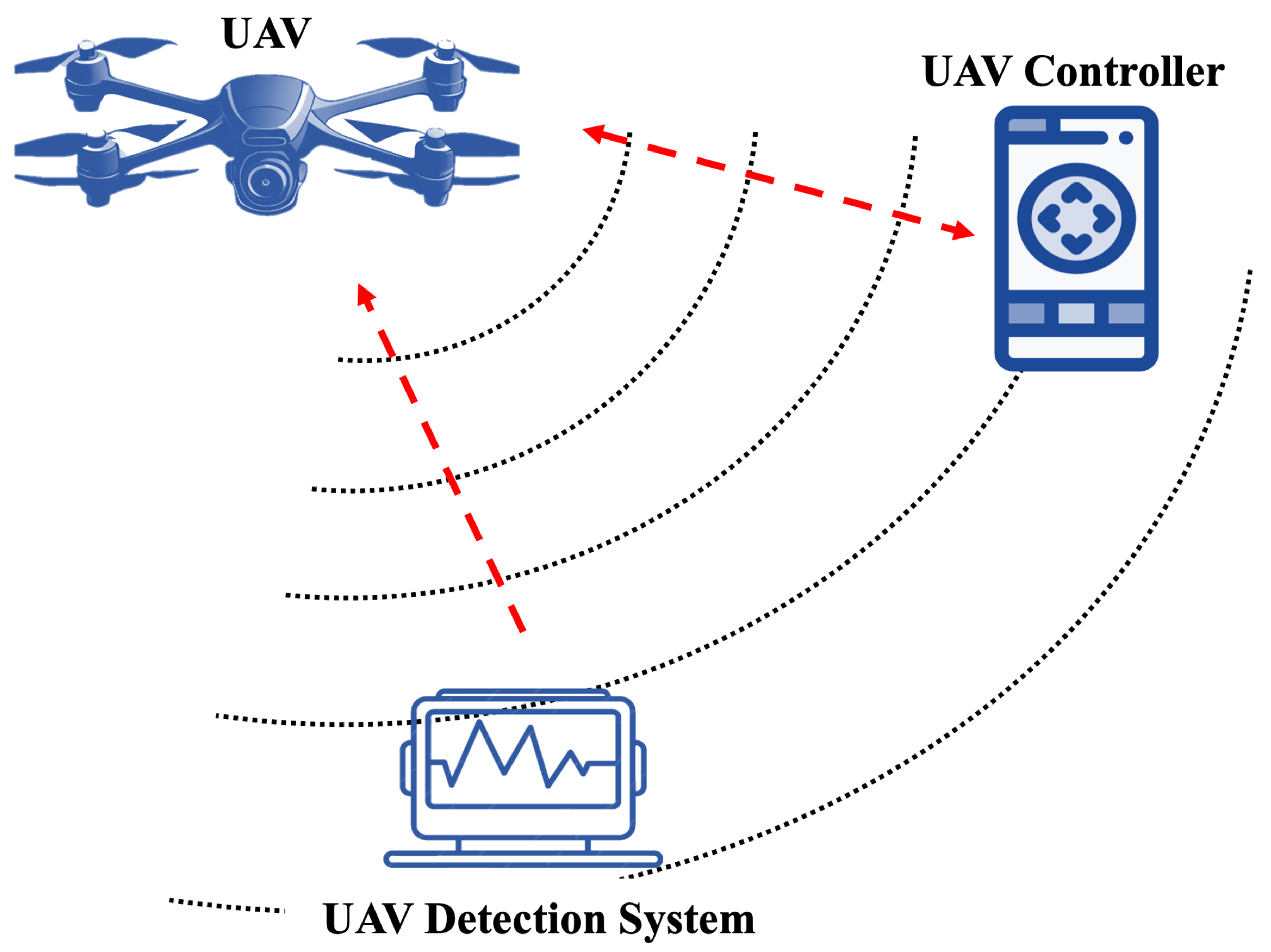
3.1. System Model
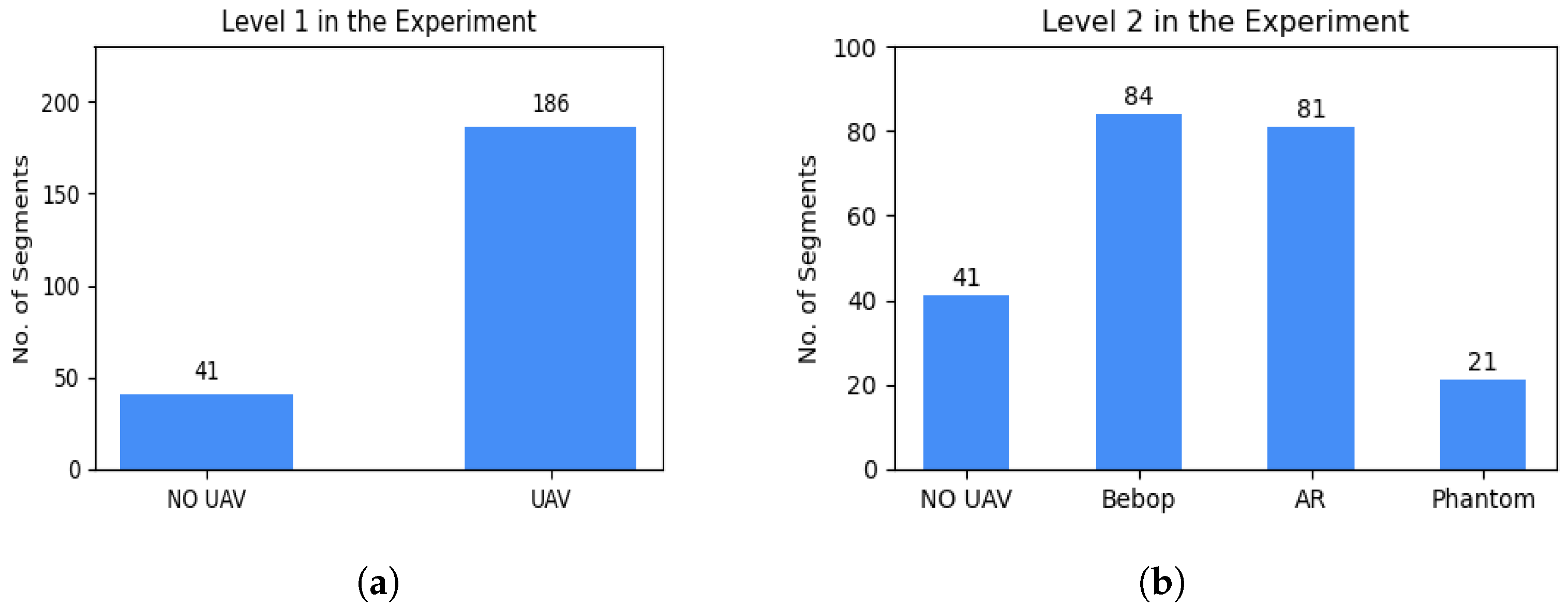
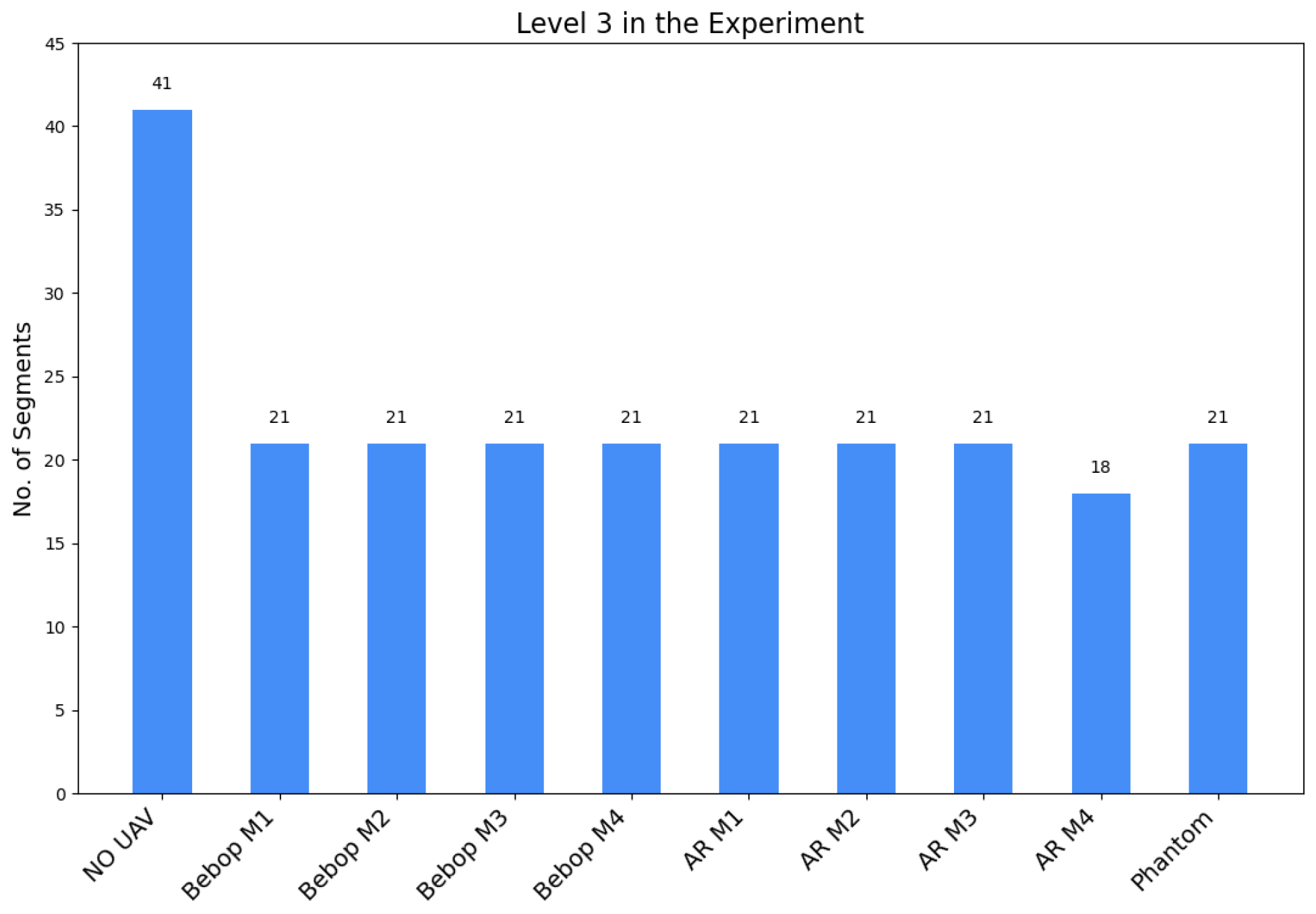
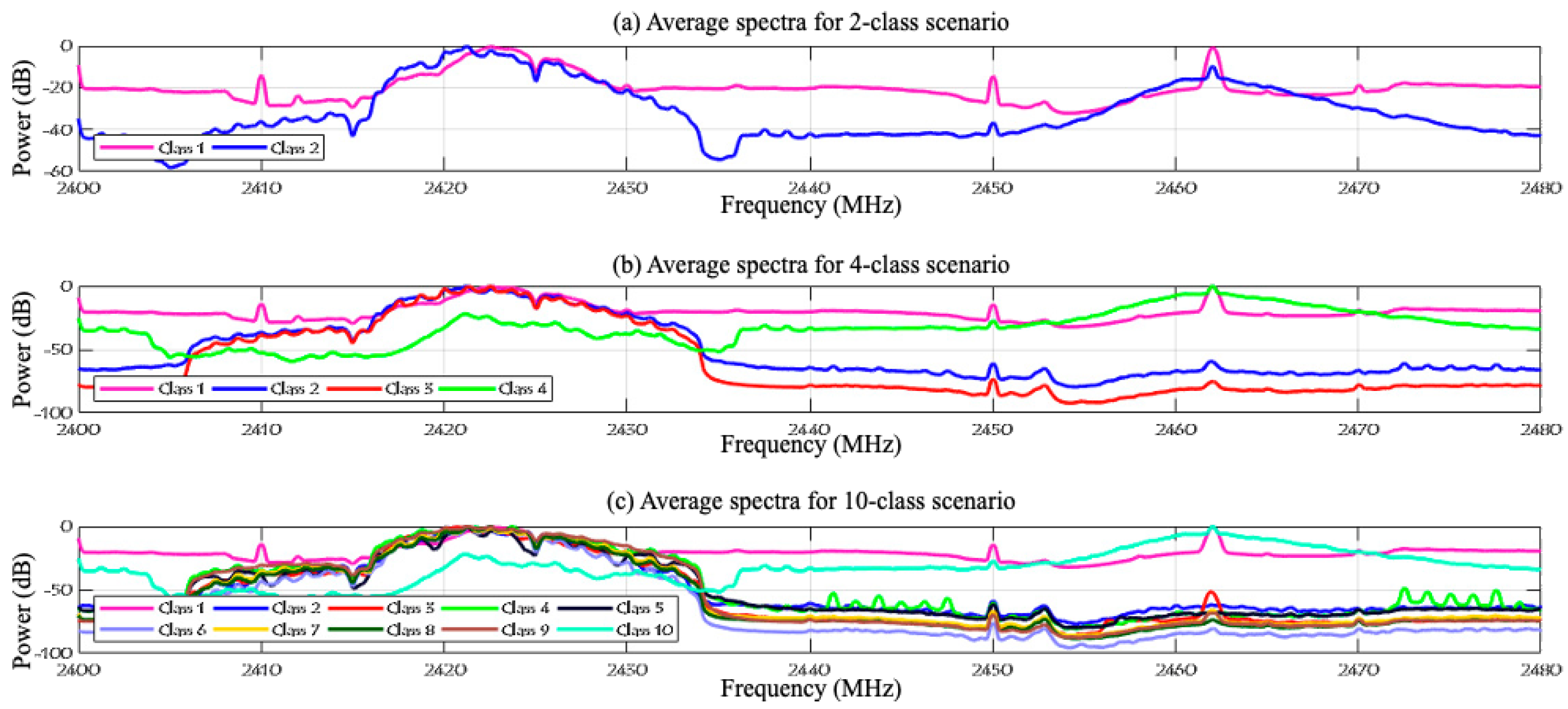
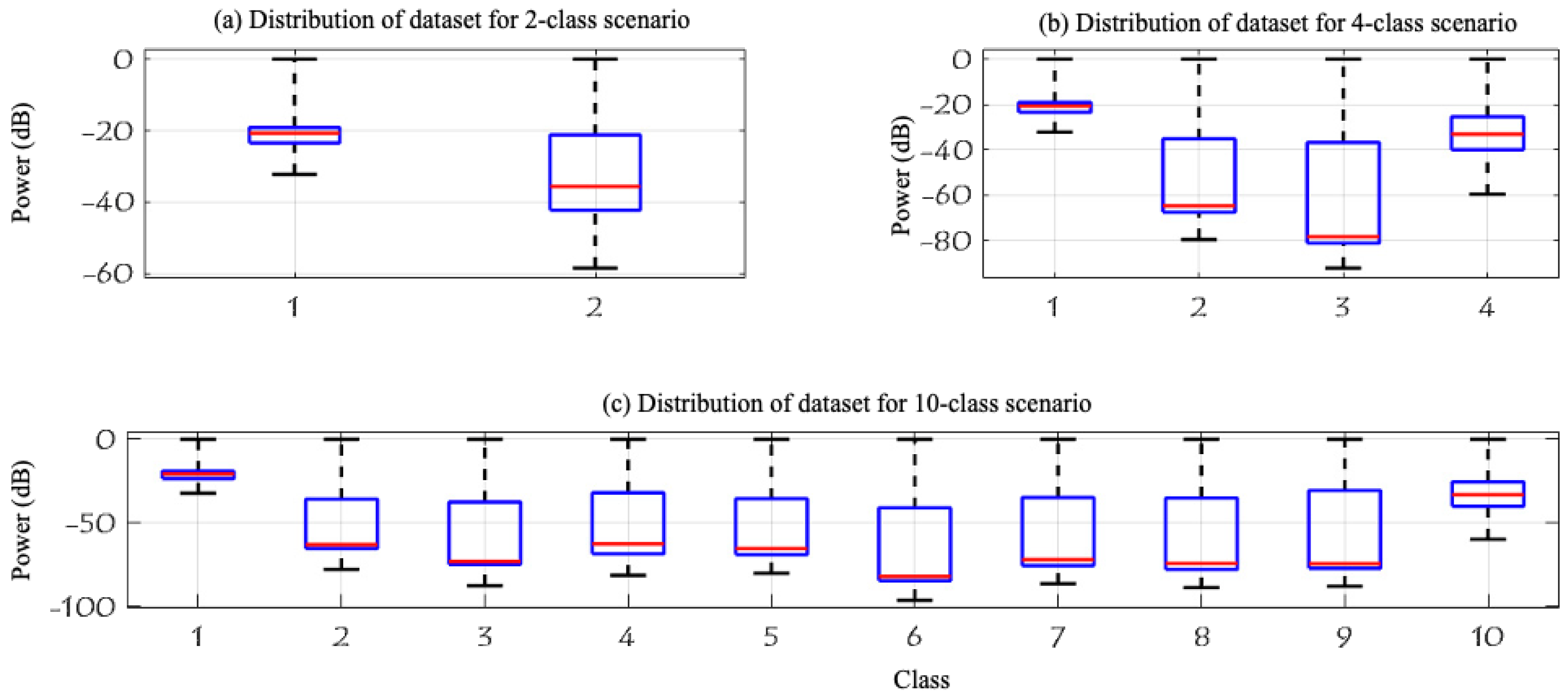
3.2. Dataset
- Level 1: This level determines if a UAV is present in the environment or not, resulting in two classes:
- -
- Class one: No UAV;
- -
- Class two: UAV.
- Level 2: This level identifies the making model of the UAV that is detected in the first level. We categorize them into three classes, named after their models:
- -
- Class one: Parrot Bebop;
- -
- Class two: Parrot AR;
- -
- Class three: Phantom 3.
- Level 3: This level determines the flying mode of the detected UAV identified in Level 2. Parrot AR and Parrot Bebop have four flying modes resulting in four classes for each model:
- -
- Class one: ON (mode 1);
- -
- Class two: Hovering (mode 2);
- -
- Class three: Flying (mode 3);
- -
- Class four: Recording video (mode 4).
4. Proposed Solution
4.1. Data Pre-Processing
4.2. Hierarchical Reinforcement Learning Approach
4.2.1. Environment and Elements
4.2.2. REINFORCE Algorithm
| Algorithm 1 REINFORCE |
|
4.2.3. Hierarchy Design
- Classifier 1 (binary classification): Determines the UAV presence in the environment, (UAV or NO UAV).
- Classifier 2 (multi-class classification): Contains three classes (Parrot Bebop, Parrot AR, Phantom). Determines the model of UAV after detecting its existence through the first classifier.
- Classifier 3 (multi-class classification): Contains four classes (ON, hovering, flying, flying and recording videos). Determines the flight mode of the Parrot Bebop model after passing through the first and second classifiers.
- Classifier 4 (multi-class classification): Contains four classes (ON, hovering, flying, flying and recording videos). Determines the flight mode of the Parrot AR model after passing through the first and second classifiers.
4.2.4. Hierarchical Reinforcement Learning (HRL) Approach Algorithm
| Algorithm 2 Hierarchical Reinforcement Learning (HRL) |
|
5. Results and Discussion
5.1. Performance Metrics
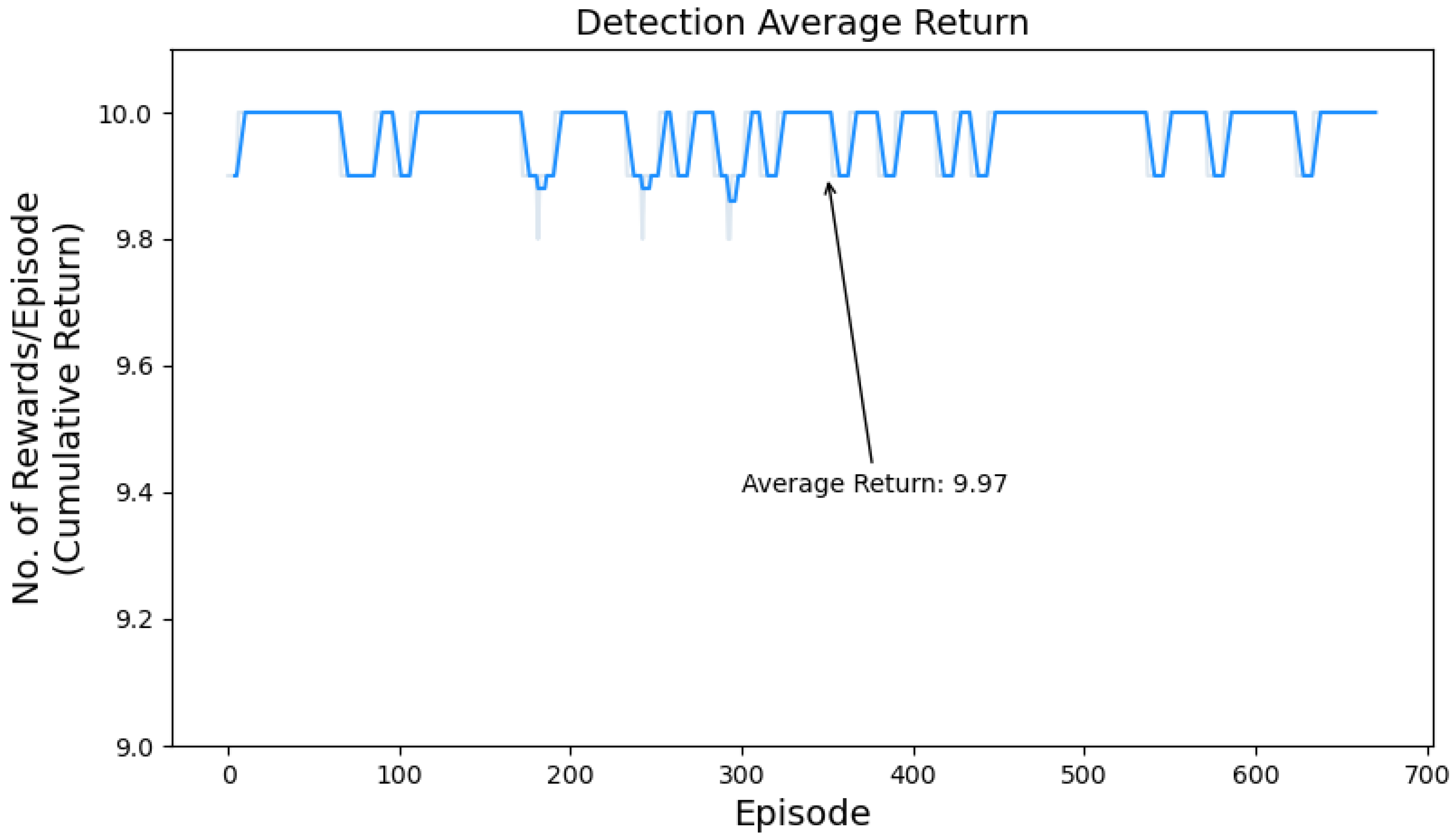
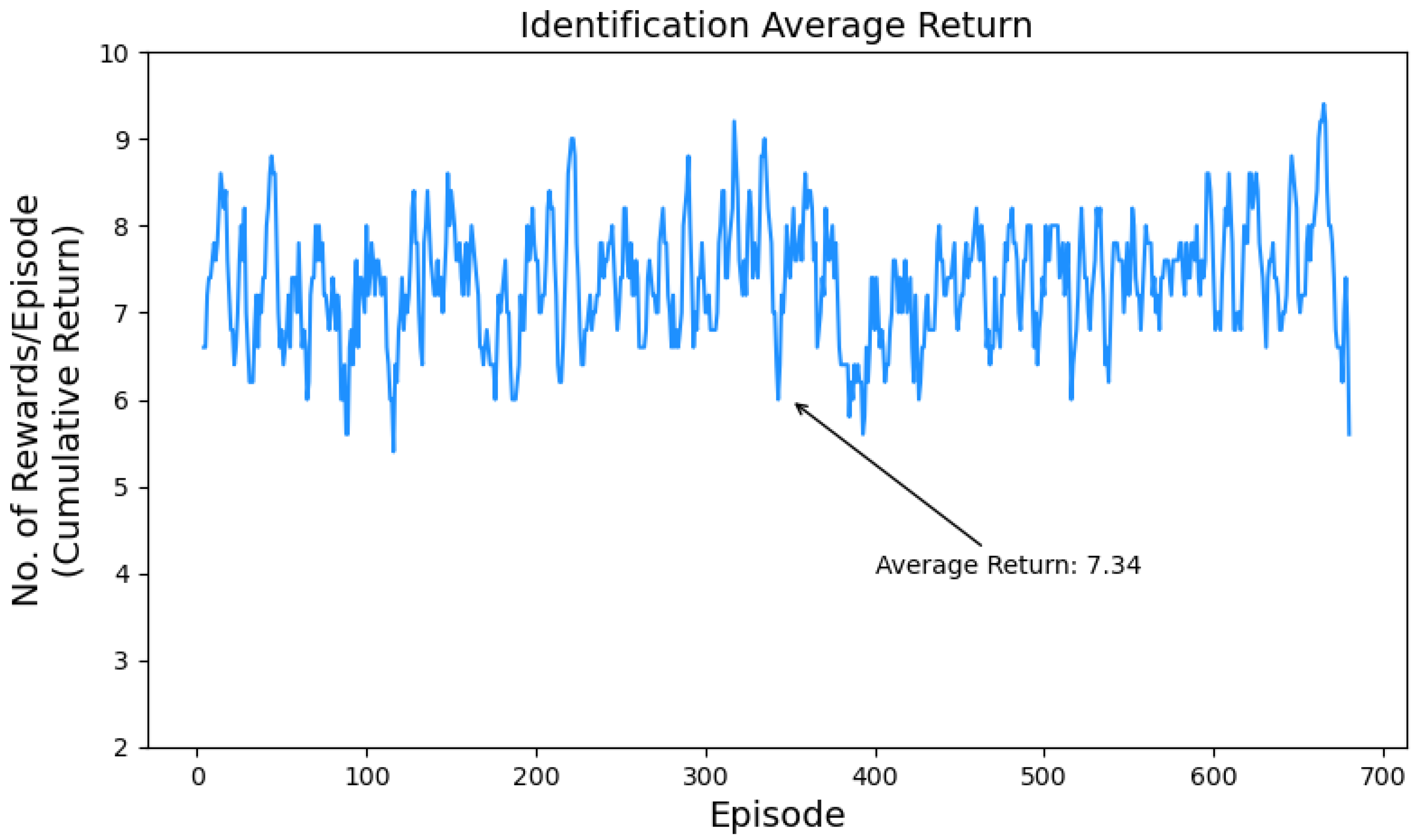
- Cumulative Return: The sum of all rewards the agent received over a single episode by interacting with the environment. It indicates the agent’s overall performance and success in maximizing long-term rewards by measuring the decision-making capabilities of the trained policy. The quality of the policy improves as the agent earns a higher number of rewards in future episodes.
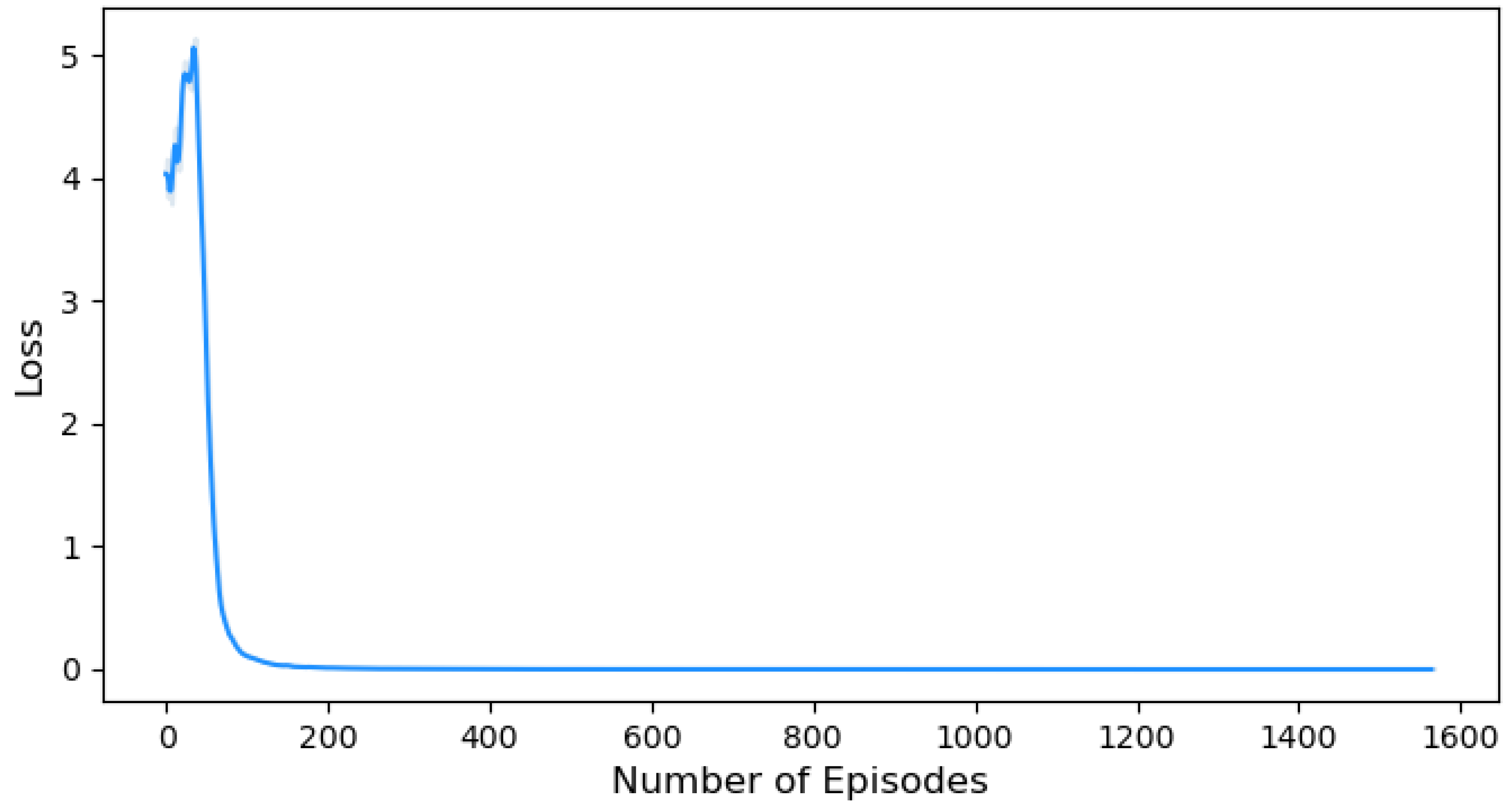
- Policy Loss: The loss function in our solution is designed to guide the training process of the agent. It assigns greater weights to the actions that resulted in positive rewards while decreasing the weights of the other actions. Hence, the weights are updated iteratively to enhance the generated actions of the agent. By optimizing the loss function, we aim to converge towards an optimal policy that maximizes the cumulative reward over time [61].
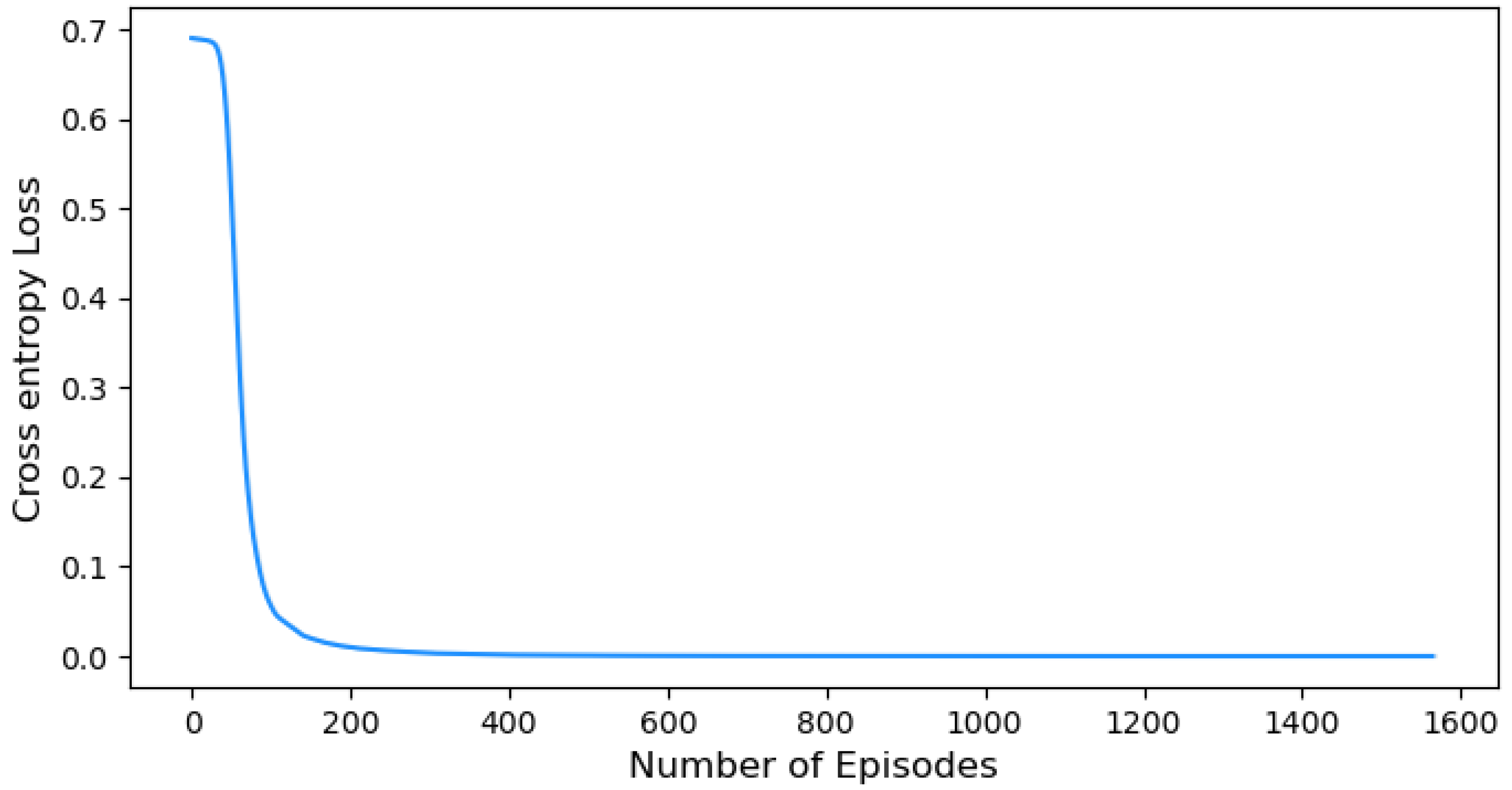
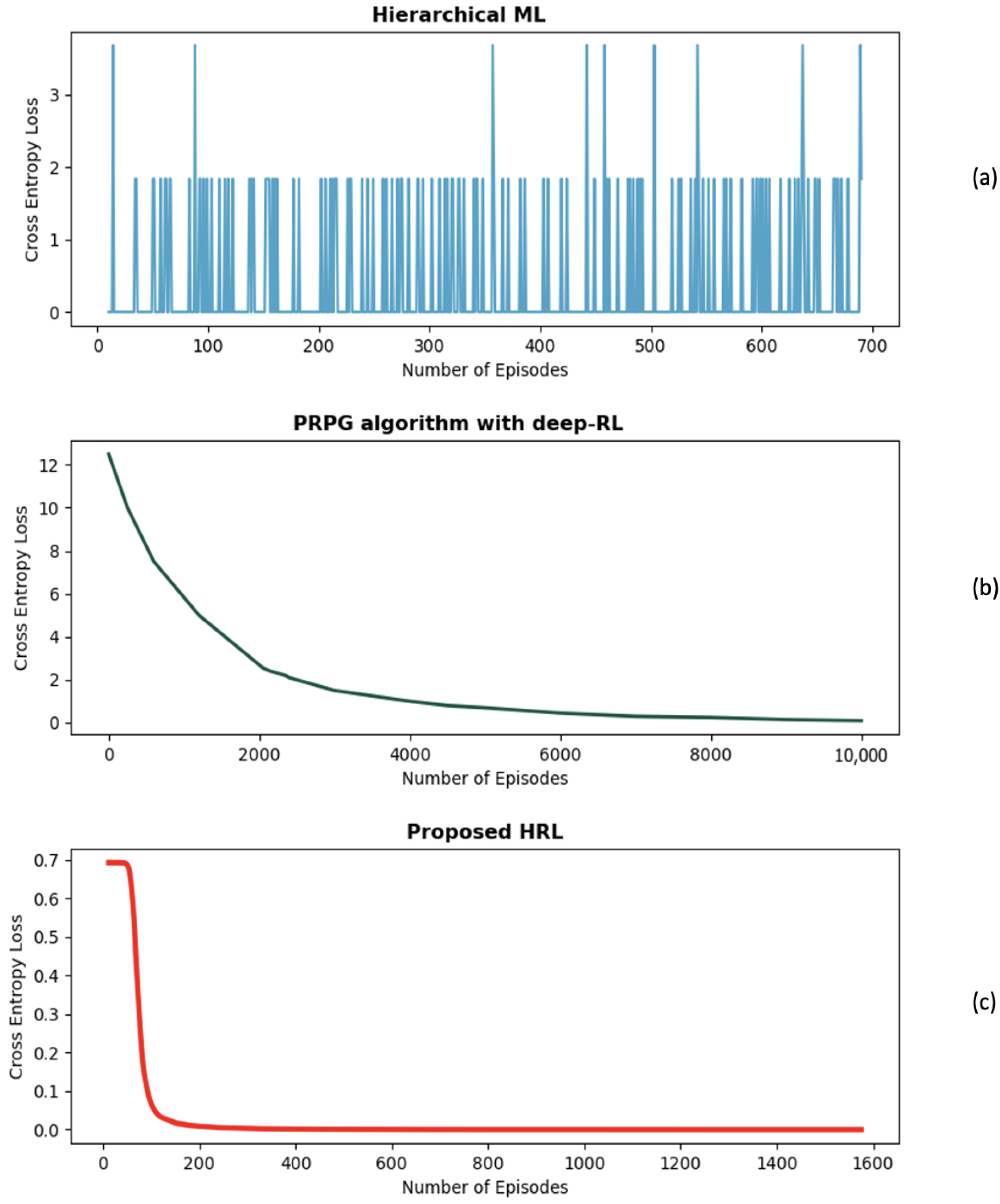
- Entropy Loss: Measure the difference between the agent’s predicted probability distribution and the target distribution. Minimizing the cross-entropy loss is key to the learning process as it improves the accuracy of the action probabilities. The cross-entropy loss plays an essential role in refining the decision-making capabilities of the agent. This iterative improvement ultimately leads to an enhanced overall performance of the agent.
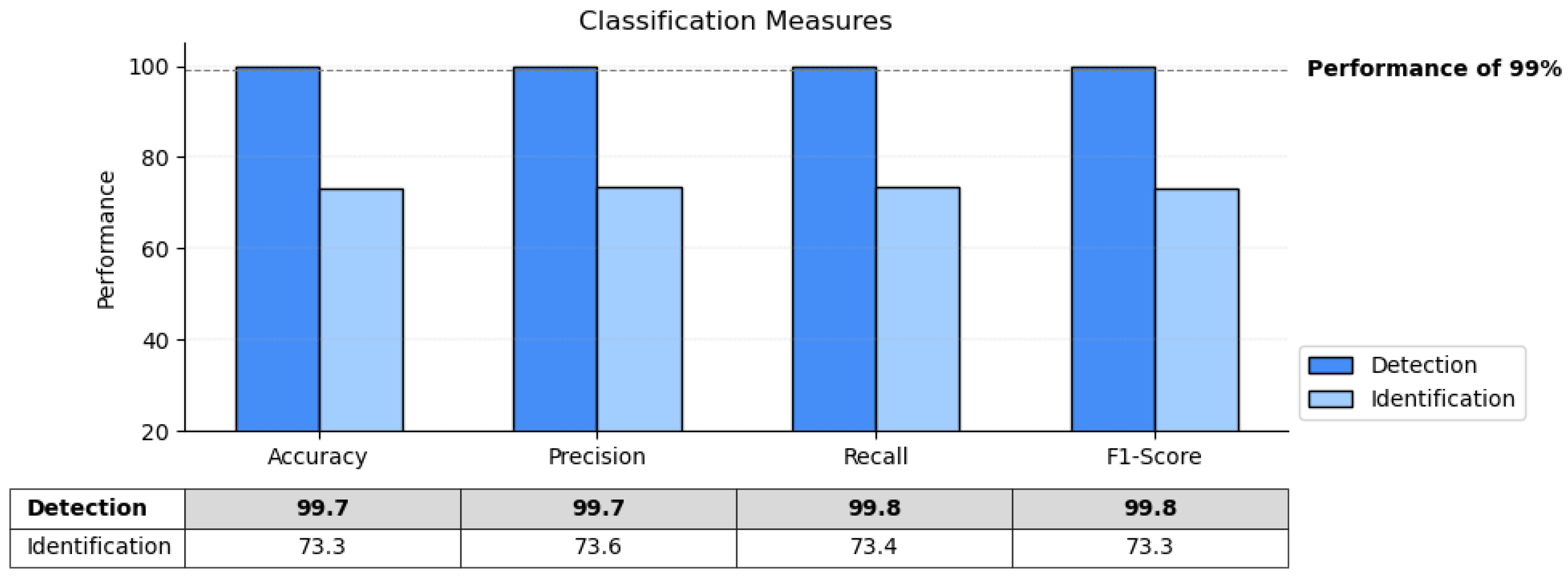
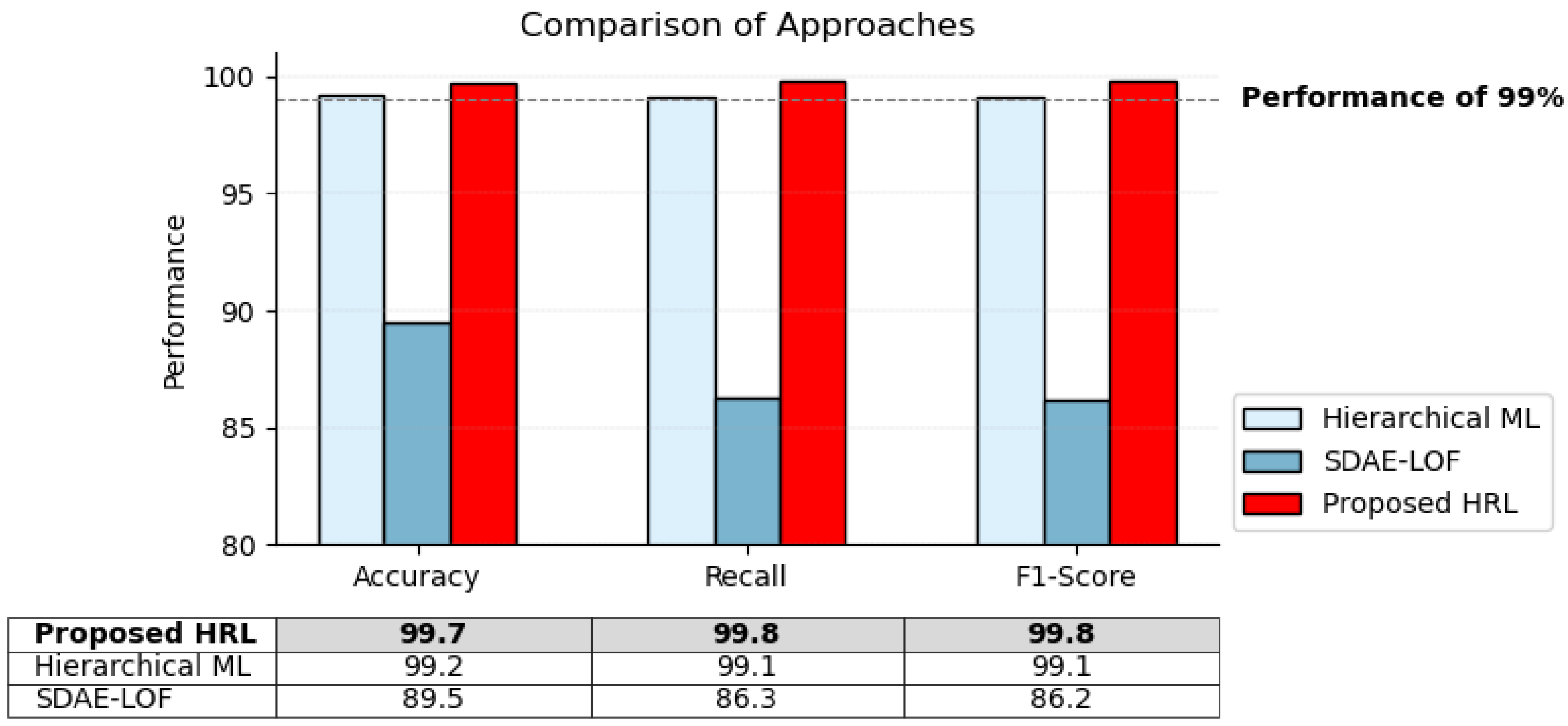
- Accuracy: The ratio of correctly classified samples to the total number of samples.
- Precision: The ratio of correctly classified positive samples to the total number of samples predicted as positive. Precision is important when the cost of false positives is high.
- Recall: The ratio of correctly classified positive samples to the total number of actual positive samples. Recall is also known as sensitivity or true positive rate. It is an important measure especially in detection systems where the cost of false negatives is high. In the detection systems, we want to minimize the rate of missed positive instances.
- F1-Score: The harmonic mean of precision and recall. It integrates the precision and recall into a single metric to gain a good understanding of the model’s performance in terms of both positive predictions and missed positive instances.
5.2. Training Performance Evaluation
5.3. Testing Performance Evaluation
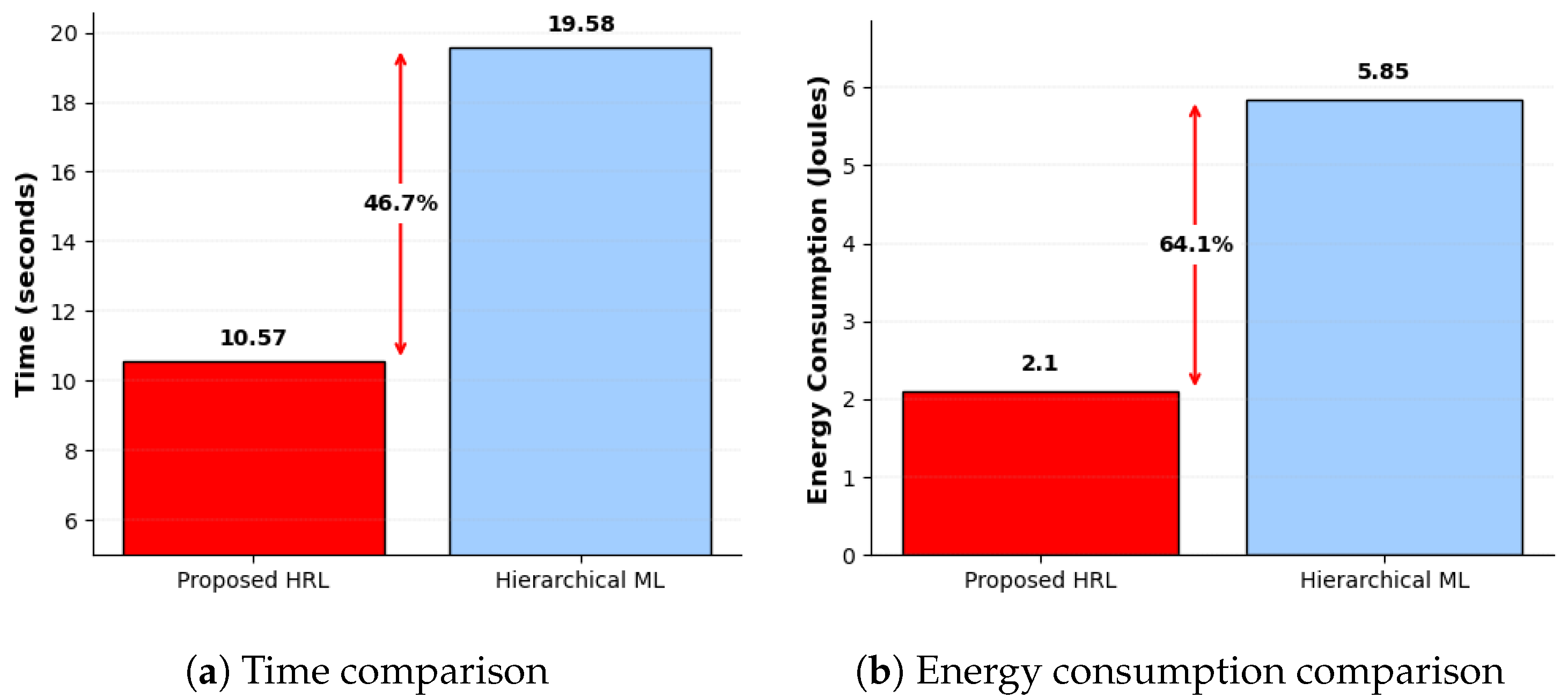
5.4. Comparative Analysis: Previous Research and Proposed Approach
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 2D | Two Dimensional |
| 3D | Three Dimensional |
| A2C | Actor–Critic Framework |
| ANN | Artificial Neural Networks |
| BLE | Bluetooth Low Energy |
| CNN | Convolutional Neural Networks |
| DNN | Deep Neural Networks |
| DA | Discriminant Analysis |
| dB | Decibel |
| DRN | Dynamic Radar Network |
| DQN | Deep Q Network |
| DDQN | Double Deep Q Network |
| GPS | Global Positioning System |
| HC | Hierarchical Control |
| HRL | Hierarchical Reinforcement Learning |
| HOC | Higher Order Cumulant |
| ISM | Industrial, Scientific, and Medical |
| kNN | K-Nearest Neighbor |
| MAE | Mean Absolute Error |
| MCTS | Monte Carlo Tree Search |
| MDP | Markov Decision Process |
| ML | Machine Learning |
| MVODM | Military Vehicle Object Detection Method |
| MUAV | Micro Unmanned Aerial Vehicles |
| NCA | Neighborhood Component Analysis |
| NN | Neural Networks |
| PFGRU | Particle Filter Gated Recurrent Unit |
| PRPG | Progressing Reward Policy Gradient |
| PODMP | Partially Observable Markov Decision Process |
| RF | Radio Frequency |
| R-FCN | Region-Based Fully Convolutional Network |
| RID-FIM | Rényi Information Divergence-Fisher Information Matrix |
| RL | Reinforcement Learning |
| RMHPL | Reinforced Mobile Hidden Passive Localization |
| RSS | Received Signal Strength |
| SAR | Search and Rescue |
| SNR | Signal-to-Noise Ratio |
| SSD | Single-Shot Detector |
| STD | Standard Deviation |
| SVM | Support Vector Machine |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machine |
| UASN | Underwater Acoustic Sensor Networks |
| UAV | Unmanned Aerial Vehicles |
| YOLOv3 | You Only Look Once version 3 |
| YOLOv5 | You Only Look Once version 5 |
References
- Santos, N.P.; Rodrigues, V.B.; Pinto, A.B.; Damas, B. Automatic Detection of Civilian and Military Personnel in Reconnaissance Missions using a UAV. In Proceedings of the 2023 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Tomar, Portugal, 26–27 April 2023; pp. 157–162. [Google Scholar]
- Hernandez, J.A. Integrating Unmanned Ariel Vehicles into SWAT Operations; Law Enforcement Management Institute of Texas (LEMIT): Huntsville, TX, USA, 2023. [Google Scholar]
- Li, X.; Tupayachi, J.; Sharmin, A.; Ferguson, M.M. Drone-Aided Delivery Methods, Challenge, and the Future: A Methodological Review. Drones 2023, 7, 191. [Google Scholar] [CrossRef]
- Eskandaripour, H.; Boldsaikhan, E. Last-Mile Drone Delivery: Past, Present, and Future. Drones 2023, 7, 77. [Google Scholar] [CrossRef]
- Ateş, S.S.; Uzgor, M.; Yuksek, K. UAV tracking module proposal based on a regulative comparison between manned and unmanned aviation. J. Airl. Airpt. Manag. 2022, 12, 29. [Google Scholar] [CrossRef]
- Rocco, P.; Carmela, G.; Adriana, G. Towards an urban planners’ perspective on Smart City. J. Land Use Mobil. Environ. 2013, 6, 5–17. [Google Scholar]
- Zhang, S.; Shi, S.; Feng, T.; Gu, X. Trajectory planning in UAV emergency networks with potential underlaying D2D communication based on K-means. Eurasip J. Wirel. Commun. Netw. 2021, 2021, 107. [Google Scholar] [CrossRef]
- Alhindi, A.; Alyami, D.; Alsubki, A.; Almousa, R.; Al Nabhan, N.; Al Islam, A.B.M.A.; Kurdi, H. Emergency planning for uav-controlled crowd evacuations. Appl. Sci. 2021, 11, 9009. [Google Scholar] [CrossRef]
- Beg, A.; Qureshi, A.R.; Sheltami, T.; Yasar, A. UAV-enabled intelligent traffic policing and emergency response handling system for the smart city. Pers. Ubiquitous Comput. 2021, 25, 33–50. [Google Scholar] [CrossRef]
- Jin, Y.; Qian, Z.; Yang, W. UAV cluster-based video surveillance system optimization in heterogeneous communication of smart cities. IEEE Access 2020, 8, 55654–55664. [Google Scholar] [CrossRef]
- Yun, W.J.; Park, S.; Kim, J.; Shin, M.; Jung, S.; Mohaisen, D.A.; Kim, J.H. Cooperative Multi-Agent Deep Reinforcement Learning for Reliable Surveillance via Autonomous Multi-UAV Control. IEEE Trans. Ind. Inform. 2022, 18, 7086–7096. [Google Scholar] [CrossRef]
- Innocenti, E.; Agostini, G.; Giuliano, R. UAVs for Medicine Delivery in a Smart City Using Fiducial Markers. Information 2022, 13, 501. [Google Scholar] [CrossRef]
- Munawar, H.S.; Inam, H.; Ullah, F.; Qayyum, S.; Kouzani, A.Z.; Mahmud, M.A.P. Towards smart healthcare: Uav-based optimized path planning for delivering covid-19 self-testing kits using cutting edge technologies. Sustainability 2021, 13, 10426. [Google Scholar] [CrossRef]
- Kitonsa, H.; Kruglikov, S.V. Significance of drone technology for achievement of the United Nations sustainable development goals. R-economy 2018, 4, 115–120. [Google Scholar] [CrossRef]
- Du, Y. Multi-UAV Search and Rescue with Enhanced A Algorithm Path Planning in 3D Environment. Int. J. Aerosp. Eng. 2023, 2023, 8614117. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, W.; Liu, J.; Sun, C. Cooperative USV–UAV marine search and rescue with visual navigation and reinforcement learning-based control. ISA Trans. 2023, 137, 222–235. [Google Scholar] [CrossRef]
- Yanmaz, E. Joint or decoupled optimization: Multi-UAV path planning for search and rescue. Ad Hoc Netw. 2023, 138, 103018. [Google Scholar] [CrossRef]
- Lyu, M.; Zhao, Y.; Huang, C.; Huang, H. Unmanned Aerial Vehicles for Search and Rescue: A Survey. Remote Sens. 2023, 15, 3266. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Yang, Y.; Yang, F.; Sun, L.; Xiang, T.; Lv, P. Echoformer: Transformer Architecture Based on Radar Echo Characteristics for UAV Detection. IEEE Sens. J. 2023, 23, 8639–8653. [Google Scholar] [CrossRef]
- Guerra, A.; Guidi, F.; Dardari, D.; Djuric, P.M. Reinforcement Learning for Joint Detection and Mapping using Dynamic UAV Networks. IEEE Trans. Aerosp. Electron. Syst. 2023, 1–16. [Google Scholar] [CrossRef]
- Caicedo, J.C.; Lazebnik, S. Active Object Localization with Deep Reinforcement Learning. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Ouyang, Y.; Wang, X.; Hu, R.; Xu, H.; Shao, F. Military Vehicle Object Detection Based on Hierarchical Feature Representation and Refined Localization. IEEE Access 2022, 10, 99897–99908. [Google Scholar] [CrossRef]
- Nemer, I.; Sheltami, T.; Ahmad, I.; Yasar, A.U.H.; Abdeen, M.A.R. Rf-based UAV detection and identification using hierarchical learning approach. Sensors 2021, 21, 1947. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Zhang, H.; Bian, K.; Renzo, M.D.; Han, Z.; Song, L. MetaSensing: Intelligent Metasurface Assisted RF 3D Sensing by Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2021, 39, 2182–2197. [Google Scholar] [CrossRef]
- Shorten, D.; Williamson, A.; Srivastava, S.; Murray, J.C. Localisation of Drone Controllers from RF Signals using a Deep Learning Approach. In Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence, Union, NJ, USA, 15–17 August 2018; pp. 89–97. [Google Scholar]
- Liu, H.; Wei, Z.; Chen, Y.; Pan, J.; Lin, L.; Ren, Y. Drone detection based on an audio-assisted camera array. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017. [Google Scholar]
- Zmyslowski, D.; Skokowski, P.; Kelner, J. Anti-drone Sensors, Effectors, and Systems—A Concise Overview. TransNav Int. J. Mar. Navig. Saf. Sea Transp. 2023, 17, 455–461. [Google Scholar] [CrossRef]
- Ganti, S.R.; Kim, Y. Implementation of detection and tracking mechanism for small UAS. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VI, USA, 7–10 June 2016. [Google Scholar]
- Al-Sa’d, M.F.; Al-Ali, A.; Mohamed, A.; Khattab, T.; Erbad, A. RF-based drone detection and identification using deep learning approaches: An initiative towards a large open source drone database. Future Gener. Comput. Syst. 2019, 100, 86–97. [Google Scholar] [CrossRef]
- Azari, M.M.; Sallouha, H.; Chiumento, A.; Rajendran, S.; Vinogradov, E.; Pollin, S. Key Technologies and System Trade-offs for Detection and Localization of Amateur Drones. IEEE Commun. Mag. 2018, 56, 51–57. [Google Scholar] [CrossRef]
- Allahham, M.S.; Al-Sa’d, M.F.; Al-Ali, A.; Mohamed, A.; Khattab, T.; Erbad, A. DroneRF dataset: A dataset of drones for RF-based detection, classification and identification. Data Brief 2019, 26, 104313. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, Y.; Gulliver, T.A. An improved sensing method using radio frequency detection. Phys. Commun. 2019, 36, 10076. [Google Scholar] [CrossRef]
- Ezuma, M.; Erden, F.; Anjinappa, C.K.; Ozdemir, O.; Guvenc, I. Detection and classification of UAVs using RF Fingerprints in the Presence of Wi-Fi and bluetooth interference. IEEE Open J. Commun. Soc. 2020, 1, 60–76. [Google Scholar] [CrossRef]
- Ezuma, M.; Erden, F.; Anjinappa, C.K.; Ozdemir, O.; Guvenc, I. Micro-UAV Detection and Classification from RF Fingerprints Using Machine Learning Techniques. In Proceedings of the 2019 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2019; pp. 1–13. [Google Scholar]
- Salman, S.; Mir, J.; Farooq, M.T.; Malik, A.N.; Haleemdeen, R. Machine Learning Inspired Efficient Audio Drone Detection using Acoustic Features. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 335–339. [Google Scholar]
- Henderson, A.; Yakopcic, C.; Harbour, S.; Taha, T.M. Detection and Classification of Drones Through Acoustic Features Using a Spike-Based Reservoir Computer for Low Power Applications. In Proceedings of the IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022; pp. 1–7. [Google Scholar]
- Al-Emadi, S.; Al-Ali, A.; Mohammad, A.; Al-Ali, A. Audio Based Drone Detection and Identification using Deep Learning. In Proceedings of the 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 459–464. [Google Scholar]
- Kurilová, V.; Goga, J.; Oravec, M.; Pavlovičová, J.; Kajan, S. Support vector machine and deep-learning object detection for localisation of hard exudates. Sci. Rep. 2021, 11, 16045. [Google Scholar] [CrossRef] [PubMed]
- Yavariabdi, A.; Kusetogullari, H.; Celik, T.; Cicek, H. FastUAV-NET: A multi-UAV detection algorithm for embedded platforms. Electronics 2021, 10, 724. [Google Scholar] [CrossRef]
- Elhoseny, M. Multi-object Detection and Tracking (MODT) Machine Learning Model for Real-Time Video Surveillance Systems. Circuits Syst. Signal Process. 2020, 39, 611–630. [Google Scholar] [CrossRef]
- Xu, Y.; Dai, S.; Wu, S.; Chen, J.; Fang, G. Vital Sign Detection Method Based on Multiple Higher Order Cumulant for Ultrawideband Radar. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1254–1265. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, S.; Chen, C.; Chen, J.; Fang, G. A Novel Method for Automatic Detection of Trapped Victims by Ultrawideband Radar. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3132–3142. [Google Scholar] [CrossRef]
- Medaiyese, O.; Ezuma, M.; Lauf, A.P.; Adeniran, A.A. Hierarchical Learning Framework for UAV Detection and Identification. IEEE J. Radio Freq. Identif. 2021, 6, 176–188. [Google Scholar] [CrossRef]
- Medaiyese, O.; Ezuma, M.; Lauf, A.; Adeniran, A. Cardinal RF (CardRF): An Outdoor UAV/UAS/Drone RF Signals with Bluetooth and WiFi Signals Dataset. IEEE Dataport. 2022. Available online: https://ieee-dataport.org/documents/cardinal-rf-cardrf-outdoor-uavuasdrone-rf-signals-bluetooth-and-wifi-signals-dataset (accessed on 26 February 2024).
- Kainth, S.; Sahoo, S.; Pal, R.; Jha, S.S. Chasing the Intruder: A Reinforcement Learning Approach for Tracking Intruder Drones. In Proceedings of the 6th International Conference on Advances in Robotics, IIT Ropar, India, 5 July 2023; pp. 1–6. [Google Scholar]
- Cetin, E.; Barrado, C.; Pastor, E. Counter a Drone and the Performance Analysis of Deep Reinforcement Learning Method and Human Pilot. In Proceedings of the IEEE/AIAA 40th Digital Avionics Systems Conference (DASC), San Antonio, TX, USA, 3–7 October 2021; pp. 1–7. [Google Scholar]
- Liao, R.; You, X.; Su, W.; Chen, K.; Xiao, L.; Cheng, E. Reinforcement Learning Based Energy Efficient Underwater Passive Localization of Hidden Mobile Node. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Virtual Conference, 17–19 August 2021; pp. 1–6. [Google Scholar]
- Liu, Z.; Abbaszadeh, S. Double Q-Learning for radiation source detection. Sensors 2019, 19, 960. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Wang, J.; Chen, A.; Liu, Y. An autonomous radiation source detection policy based on deep reinforcement learning with generalized ability in unknown environments. Nucl. Eng. Technol. 2023, 55, 285–294. [Google Scholar] [CrossRef]
- Proctor, P.; Teuscher, C.; Hecht, A.; Osiński, M. Proximal Policy Optimization for Radiation Source Search. J. Nucl. Eng. 2021, 2, 368–397. [Google Scholar] [CrossRef]
- Hammel, S.E.; Liu, I.P.T.; Hilliard, E.J.; Gong, K.F. Optimal Observer Motion for Localization with Bearing Measurements. Comput. Math. Appl. 1989, 18, 171–180. [Google Scholar] [CrossRef]
- Kreucher, C.; Kastella, K.; Hero, A.O. Sensor management using an active sensing approach. Signal Process. 2005, 85, 607–624. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Mu, X.; Hou, T.; Xu, J.; Di Renzo, M.; Al-Dhahir, N. Reconfigurable Intelligent Surfaces: Principles and Opportunities. IEEE Commun. Surv. Tutor. 2021, 23, 1546–1577. [Google Scholar] [CrossRef]
- Kulkarni, S.; Chaphekar, V.; Uddin Chowdhury, M.M.; Erden, F.; Guvenc, I. UAV Aided Search and Rescue Operation Using Reinforcement Learning. In Proceedings of the 2020 SoutheastCon, Raleigh, NC, USA, 28–29 March 2020; Volume 2, pp. 1–8. [Google Scholar] [CrossRef]
- Tindall, L.; Hampel-Arias, Z.; Goldfrank, J.; Mair, E.; Nguven, T.Q. Localizing Radio Frequency Targets Using Reinforcement Learning. In Proceedings of the 2021 IEEE International Symposium on Robotic and Sensors Environments (ROSE), Online, 28–29 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Billah, M.F.R.M.; Saoda, N.; Gao, J.; Campbell, B. BLE Can See: A Reinforcement Learning Approach for RF-Based Indoor Occupancy Detection. In Proceedings of the 20th International Conference on Information Processing in Sensor Networks (Co-Located with CPS-IoT Week 2021), New York, NY, USA, 18–21 May 2021; pp. 132–147. [Google Scholar] [CrossRef]
- Instruments, N. USRP-2943 Specifications. Available online: https://www.ni.com/docs/en-US/bundle/usrp-2943-specs/page/specs.html (accessed on 26 February 2024).
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1352–1361. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the Advances in Neural Information Processing Systems; Solla, S., Leen, T., Müller, K., Eds.; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. Eur. Conf. Inf. Retr. 2005, 3408, 345–359. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Dataset | Training Model | Measure | Percentage |
|---|---|---|---|---|
| [33] | Signals collected using a receiver and stored in the computer | ANN | Accuracy STD | >80% |
| [34] | 5000K samples for every controller that contains 100 RF signals | kNN, SVM, DA, and NN | Accuracy False Alarm | 99.8% 2.8% |
| [35] | 100 RF signals database. 80% for training. 20% for testing | kNN, SVM, DA, and NN | Accuracy | 96.2% |
| [26] | Windows of dimension | CNN | MAE | |
| [30] | 227 segments where each segment is samples | Three DNN | Accuracy | 2 classes→ 99.7% 4 classes → 84.5% 10 classes → 46.8% |
| [24] | 227 segments where each segment is samples | Ensemble Learning | Accuracy | 99% |
| [44] | Mix of UAVs, Wi-Fi, and Bluetooth signals | SDAE-LOF and XGBoost | Accuracy | 89.5% |
| Ref. | Feature | 2D/3D | Training Model | Measure | Percentage |
|---|---|---|---|---|---|
| [46] | Images | 2D | The UAV’s alignment and chasing pace to track the intruding UAV | Closest to the target and keep sight of the target | Total reward Absolute value error |
| [47] | Images | 2D | Minimize response time while maximizing the performance | Detect and catch intruding UAVs | Response time Success rate |
| [23] | Images | 2D | The best refined target localization while maximizing the performance | Shortest path distance | Average precision |
| [22] | Images | 2D | Minimize searching time | Target coverage | Average precision |
| [48] | Acoustic | 3D | Enhance localization accuracy and minimize energy consumption | Better localization and lower energy usage | Localization RMSE Energy consumption |
| Ref. | Objectives | Reward | Measure |
|---|---|---|---|
| [49] | Minimize searching time | Closest to the target | Average searching time Failure rate |
| [50] | Maximize the information gain and reduce the searching time | Obstacle avoidance and shortest path distance | Running time Success rate |
| [51] | Shortest path to the source | Shortest path distance | Median Completion rate |
| Ref. | Objectives | Reward | Measure |
|---|---|---|---|
| [21] | Faster target detection and mapping | Closest to the target | Time Success rate |
| [25] | Maximize accuracy and minimize cross entropy | The negative cross entropy loss | Speed Cross entropy loss |
| [55] | Faster performance and avoiding obstacles | Speed | |
| [56] | Maximize the accuracy of localization | Belief dependent reward | Inference speed Localization error |
| [57] | Occupancy detection in indoor areas | Classifying occupied room | F1-score |
| UAV | Parrot Bebop | Parrot AR | DJI Phantom 3 |
|---|---|---|---|
| Dimensions (cm) | |||
| Weight (kg) | 0.4 | 0.420 | 1.216 |
| Battery capacity (mAh) | 1200 | 1000 | 4480 |
| Maximum Range (m) | 250 | 50 | 1000 |
| Connectivity | WiFi (2.4 & 5 GHz) | WiFi (2.4 GHz) | WiFi ([2.4–2.483] GHz) RF ([5.725–5.825] GHz) |
| Specifications | Values |
|---|---|
| Number of channels | 2 |
| Frequency Range | [1.2–6] GHz |
| Frequency step | <1 KHz |
| Gain range | [0–37.5] dB |
| Max instantaneous bandwidth | 40 MHz |
| Max I/Q sample rate | 200 MS/s |
| ADC resolution | 14 bits |
| Noise Figure | 5 dB to 7 dB |
| sFDR | 88 dB |
| Elements | Description |
|---|---|
| Environment | 10 conceptual RF analysis channels |
| State | Single channel holding a single data sample |
| Agent | Single agent for each classifier of the hierarchy |
| Action | Class number determined by probability distribution |
| Reward | Positive reward for correct classifications, 0 otherwise |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlKhonaini, A.; Sheltami, T.; Mahmoud, A.; Imam, M. UAV Detection Using Reinforcement Learning. Sensors 2024, 24, 1870. https://doi.org/10.3390/s24061870
AlKhonaini A, Sheltami T, Mahmoud A, Imam M. UAV Detection Using Reinforcement Learning. Sensors. 2024; 24(6):1870. https://doi.org/10.3390/s24061870
Chicago/Turabian StyleAlKhonaini, Arwa, Tarek Sheltami, Ashraf Mahmoud, and Muhammad Imam. 2024. "UAV Detection Using Reinforcement Learning" Sensors 24, no. 6: 1870. https://doi.org/10.3390/s24061870
APA StyleAlKhonaini, A., Sheltami, T., Mahmoud, A., & Imam, M. (2024). UAV Detection Using Reinforcement Learning. Sensors, 24(6), 1870. https://doi.org/10.3390/s24061870