1. Introduction
Turbine blades serve as critical components of aero-engines, constantly operating under high temperature, high pressure, and corrosion conditions [
1]. Under such circumstances, the various components of aero-engines are prone to degradation, including cracks, ablations, and pits, thereby affecting flight safety. Therefore, detecting defects in turbine blade casting before aero-engine assembly plays a crucial role in improving aircraft performance. This not only significantly extends the service life of aero-engines but also helps avoid secondary damage to the blades in harsh environments [
2].
Due to the complex structure of turbine blades, it is inevitable that casting defects, such as slag inclusions, cracks, gas cavity, and cold shuts, will be developed during the casting process [
3]. For the aforementioned defects, Non-Destructive Testing (NDT) is generally used for defect detection since it does not damage the physical structure of the turbine blade. This includes ultrasonic testing [
4], eddy current testing [
5], radiographic testing [
6], infrared thermography [
7], and magnetic particle testing [
8].
For instance, Yang et al. [
9] applied ultrasonic infrared thermography to detect the impact damage of a Carbon Fiber-Reinforced Plastic (CFRP) specimen for Unmanned Aerial Vehicles (UAVs), proposing defect-merging algorithms incorporating both time- and space-domain methods with a few thermal images. Moreover, Yin et al. [
10] analyzed the trajectory of the Lissajous Curve (LC) of impedance data during eddy current testing presented on the complex plane, proposing a new LC analytical model to effectively extract features of the LC graph, enabling automatic defect identification. In addition, Jamison et al. [
11] employed full-field infrared thermography imaging technology to monitor AlSi10Mg samples during SLM production, successfully applying it for statistical analysis of system processes during SLM production errors. In addition, Li et al. [
12] proposed frequency-band-selecting pulsed eddy current testing, based on a frequency selection strategy. This technique improved the sensitivity of traditional pulsed eddy current testing for local wall thinning defect detection. Moreover, Balyts’ kyi et al. [
13] proposed estimating the untightness of the cylinder of an internal combustion engine, dependent on the wear of the sealing ring of a piston, according to the value of its gap, volume, and rate of gas scavenging to the crankshaft box. Furthermore, Hossam et al. [
14] applied laser-generated ultrasonic waves to realize the remote localization and detection of two-dimensional defects. The experiments proved that the proposed system combined the advantages of photons and ultrasonic waves, thus achieving two-dimensional visualization of defects.
To address the issue of fake magnetic particle indicator point noise in magnetic particle testing results, Chen et al. [
15] introduced Hough transform to automatically identify the dominant features of magnetic particle indicators, effectively identifying scratches on hub bearings. Although the above traditional NDT methods have proven useful for defect detection, they still rely on specialized equipment and prior knowledge, greatly limiting the development of automation for defect detection technology.
Currently, object detection, as a branch of deep learning, is widely used in defect detection in industrial fields [
16]. Existing object detection models based on Convolutional Neural Network (CNN) architecture can be divided into two categories: two-stage methods (Fast R-CNN [
17] and Faster R-CNN [
18]) and one-stage methods (YOLO [
19,
20,
21,
22,
23,
24,
25] and SSD [
26]). Two-stage methods are characterized by their small object detection tasks with high precision requirements. For instance, Hu et al. [
27] applied ResNet50 to replace the original backbone network of Faster R-CNN for efficient feature extraction and incorporated the residual unit of ShuffleNetV2 to improve detection speed and accuracy. Moreover, Cheng et al. [
28] proposed a DS-Cascade RCNN with deformable convolution to detect hub defects, allowing adaptive adjustments of the position and size of the convolution kernel considering the defect shape; however, this process will increase the computational complexity of the model and it is not conducive to training. Furthermore, Gong et al. [
29] introduced a transfer learning object detection model based on domain-adaptive Faster R-CNN. The proposed system achieved accurate detection of small-size void and inclusion defects in X-ray images of spacecraft composite structures. Yet, due to the constraints of a multi-stage process and redundant computation, two-stage models have some distinct disadvantages regarding detection speed. In contrast, one-stage methods can effectively address the issue of the speed of detection. For example, Liu et al. [
30] proposed a weather domain-integrated network aimed at the task of multi-domain insulator defect detection and classification. This technique extracts cross-modal discriminant information, thereby improving the accuracy of detecting small targets. Moreover, Liu et al. [
31] enhanced YOLOv7, integrated a new convolution operator into the backbone network, and extended the sensitivity field; thus, they reduced the parameters by 18.03% and computed the load of the defect detection model that was equal to 20.53%. In addition, Zhu et al. [
32] proposed a variety of SSD-based modules to detect concrete cracks, where the feature fusion-enhanced module can effectively fuse the feature channel information to enhance object detection precision. In addition, Zhao et al. [
33] proposed an entire RDD-YOLO network based on the improvement of the backbone network and the design of a dual-feature pyramid network. This process enhanced the representation richness and ensured low-dimensional feature utilization. Moreover, Yang et al. [
34] proposed the combination of an Electrode-Grounded Droplet-based Electricity Generator (EG-DEG) and a Graphene Sheet-Embedded Carbon (GSEC) electrode to monitor droplet velocities on different triboelectric surfaces. In addition, Li et al. [
35] proposed a model consisting of the combination of an SSD meta-structure and the lightweight network MobileNet. As a result, it optimized the structure of the SSD without sacrificing detection precision. Concerning Xu et al. [
36], they proposed an improved YOLOv5 model with a CA attention mechanism, SIOU loss function, and FReLU activation function. This new combination improved the ability to capture low-sensitivity spatial information. To sum up, these CNN-based models can efficiently extract image features and automatically learn feature representations, excelling in handling spatial information in images. However, all listed methods face challenges in capturing multi-scale object information due to their limited receptive fields and complex anchor box generation strategies. As a result, CNN-based models frequently exhibit unsatisfactory multi-scale object detection capability in real industrial scenarios.
Compared to traditional CNN-based methods, the transformer-based method has apparent advantages in global perception, long-distance dependency modeling, and multi-scale detection; thus, it benefits from the introduction of innovative self-attention mechanisms. DETR [
37], being the most representative work of transformer-based models, simplifies the object detection process and effectively removes some hand-designed components. As a result, this technique achieves real end-to-end object detection with the global modeling capability of transformers. For instance, Dang et al. [
38] proposed an efficient and robust sewer defect localization system based on DETR, applying the transformer’s self-attention mechanism to analyze sewer defect level and scope. Although object detection-based models have achieved higher detection precision and efficiency while reducing manual experience dependence due to the limitations of industrial complex environments, three crucial problems still reside in defect detection:
- (1)
Due to the limited quantity of casting defects and the extremely imbalanced distribution of sample categories, it becomes challenging to collect sufficient data for model training to mitigate the risk of overfitting;
- (2)
The complexity and variability in the size of casting defects pose significant challenges for the multi-scale object detection capabilities of existing object detection models. However, most current methods struggle with extracting multi-scale features, leading to a deficiency in mining deep semantic information and accurately locating objects;
- (3)
Traditional defect detection methods rely on hand-designed components to improve detection precision, often based on extensive prior knowledge. However, this approach imposes significant limitations on their application across diverse industrial scenarios.
To address the aforementioned challenges, a novel DETR technique with a multi-scale fusion attention mechanism for aero-engine turbine blade defect detection is proposed. This method considers comprehensive features, enabling multi-scale defect detection even with imbalanced datasets. A JDA method is introduced, combining Mix-Mos, Mixup, and Mosaic techniques to effectively enhance the quantity and diversity of the dataset. Additionally, an attention-based channel-adaptive weighting (ACAW) module is constructed to fully use the complementary information across feature channels, leading to the elimination of redundant feature information. Then, an MFF module is introduced to optimize the interaction between feature mappings. Finally, the R-Focal loss is developed in the MFF attention-based DETR, applying a random hyper-parameter search strategy to accelerate the model’s convergence. An ATBDX image dataset is used to validate the proposed method. The comparative results demonstrate that the proposed method can efficiently integrate multi-scale image features and improve multi-scale defect detection precision when considering imbalanced dataset conditions. Therefore, the novelties of this work are summarized as follows:
A novel JDA method is proposed based on the combination of Mix-Mos, Mixup, and Mosaic techniques. This method effectively enhances the quantity and diversity of the dataset. Compared to traditional random data augmentation methods, the proposed method can solve imbalanced dataset problems and avoid the overfitting issue during model training. Therefore, this will improve model prediction, precision, and generalization;
The ACAW feature enhancement module is introduced for mining the dependencies among different feature channels. This module ensures focusing on necessary features while removing redundant ones, leading to further refining feature representations;
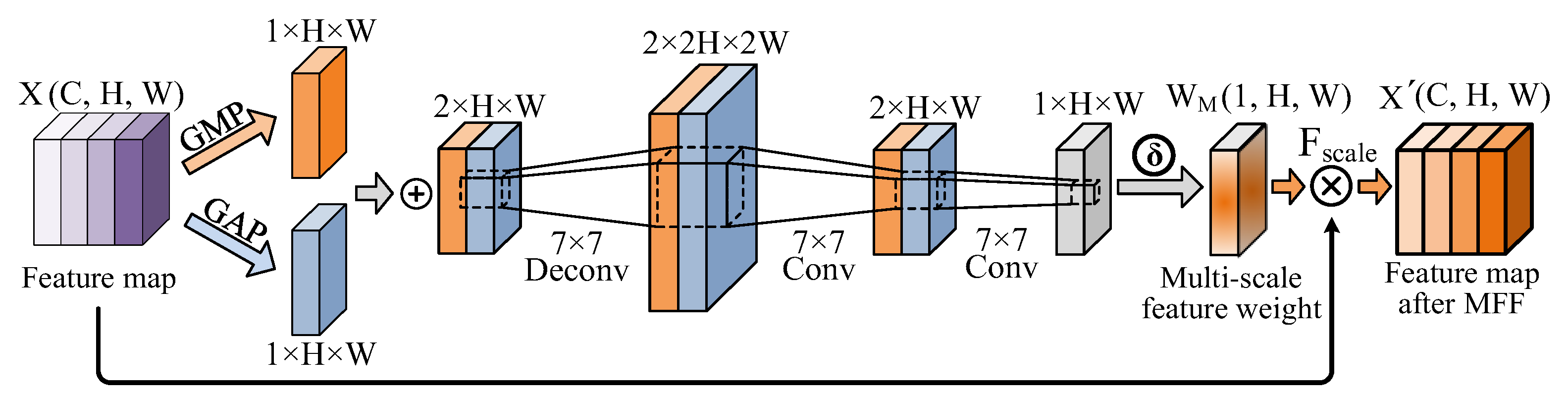
A novel MFF module is proposed to integrate high-dimensional semantic information with low-level representation features in response to various defect sizes. In contrast to simply concatenating high-dimensional and low-dimensional feature map methods, the proposed module achieves effective MFF due to the optimization of the interaction between feature mappings, significantly enhancing the precision of multi-scale defect detection;
An R-Focal loss is developed in the MFF attention-based DETR by applying a random hyper-parameter search strategy to accelerate the convergence of the model. Moreover, the training weights of the positive and negative samples, in addition to the easy and hard classification samples, are adaptively adjusted to further address the challenge of imbalanced datasets;
To validate the proposed method, an ATBDX dataset is used for defect detection. The strengths of the proposed framework are demonstrated by comparing it to other methods in terms of diverse evaluation indicators. The comparison results highlight the better detection performance of the proposed method with respect to other traditional methods. This proves that this method not only alleviates the defect detection missing issue caused by data imbalance but also effectively enhances the multi-scale defect detection precision under imbalanced dataset conditions.
To sum up, the remainder of this paper is structured as follows:
Section 2 introduces the relevant basic theories of the DETR model and the attention mechanism.
Section 3 details the proposed defect detection method.
Section 4 provides the implementation and showcases the ablation experiments results. Finally, the conclusions are drawn in
Section 5.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}