

Enhancing Infrared Optical Flow Network Computation through RGB-IR Cross-Modal Image Generation


Abstract
1. Introduction
- (1)
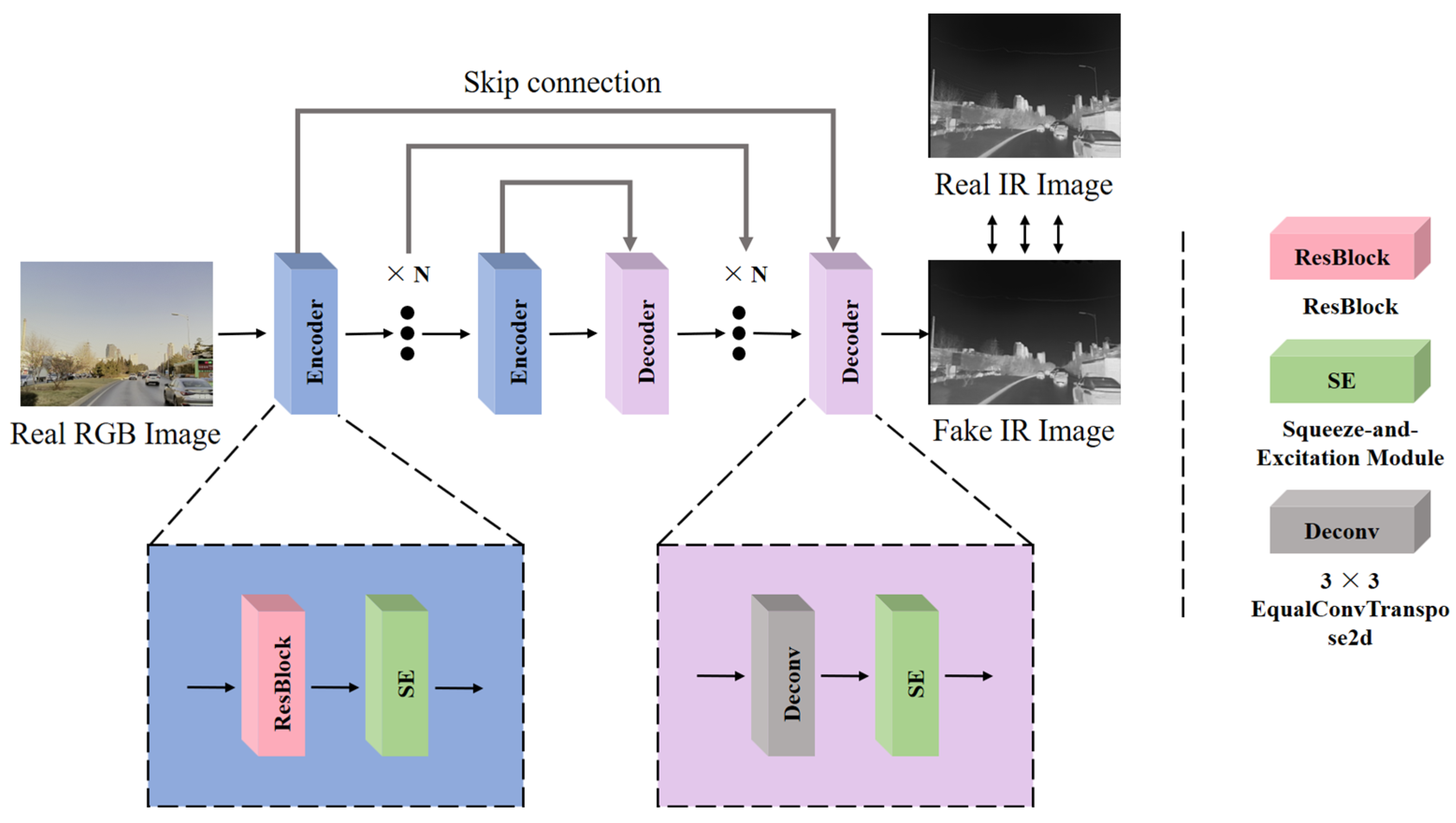
- Achieving cross-modal image transformation between RGB and IR. Drawing upon research on style transfer and image-to-image networks, this paper proposes a redesigned RGB-IR cross-modal image transformation network.
- (2)
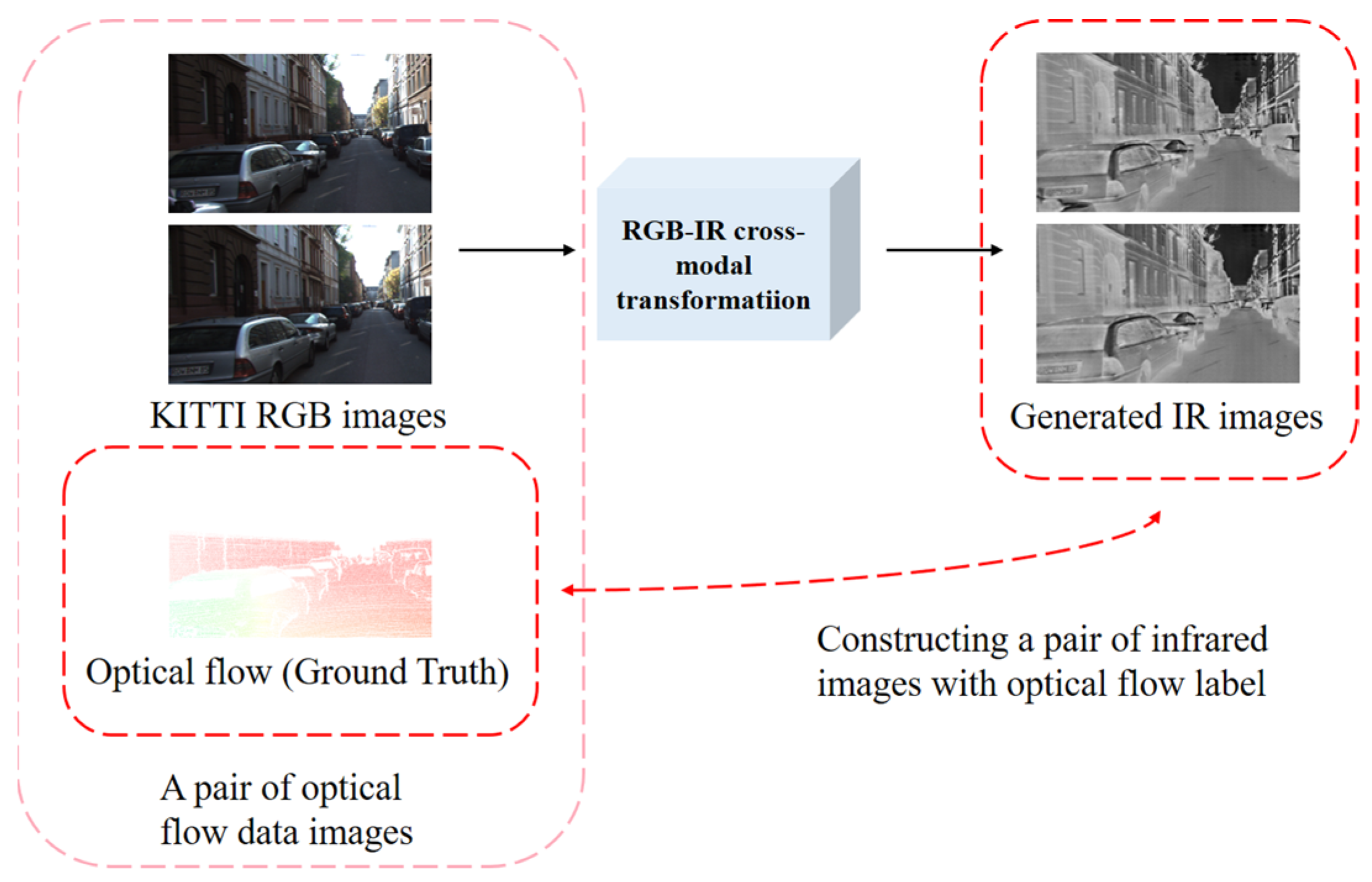
- Realization of optical flow computational networks for fine-tuning in IR scenes. In this paper, all the RGB images in the KITTI optical flow dataset are converted to IR images. Subsequently, the converted IR images are employed to train the optical flow computation network, thereby enhancing its performance, specifically for IR scenes.
2. Related Work
3. Proposed Method
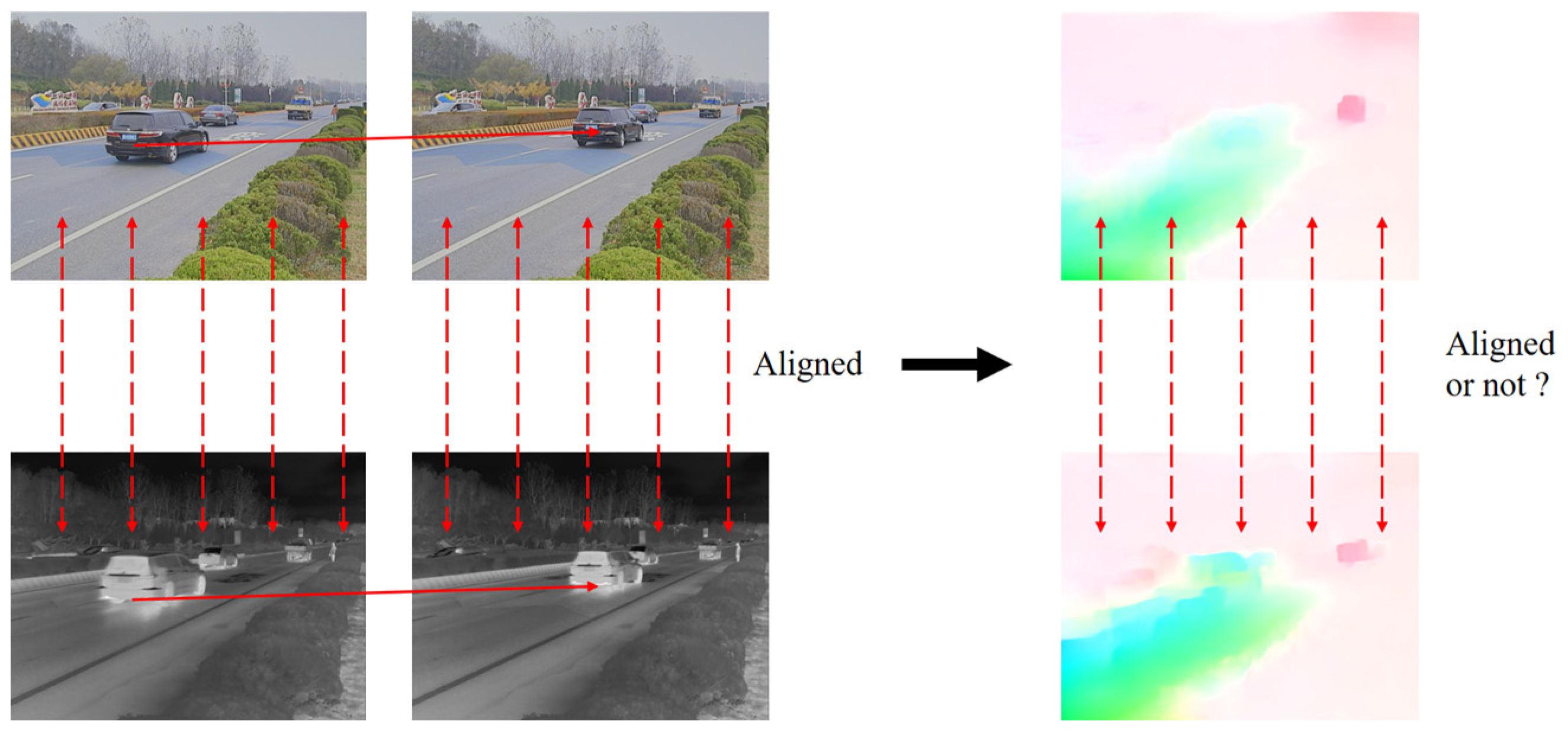
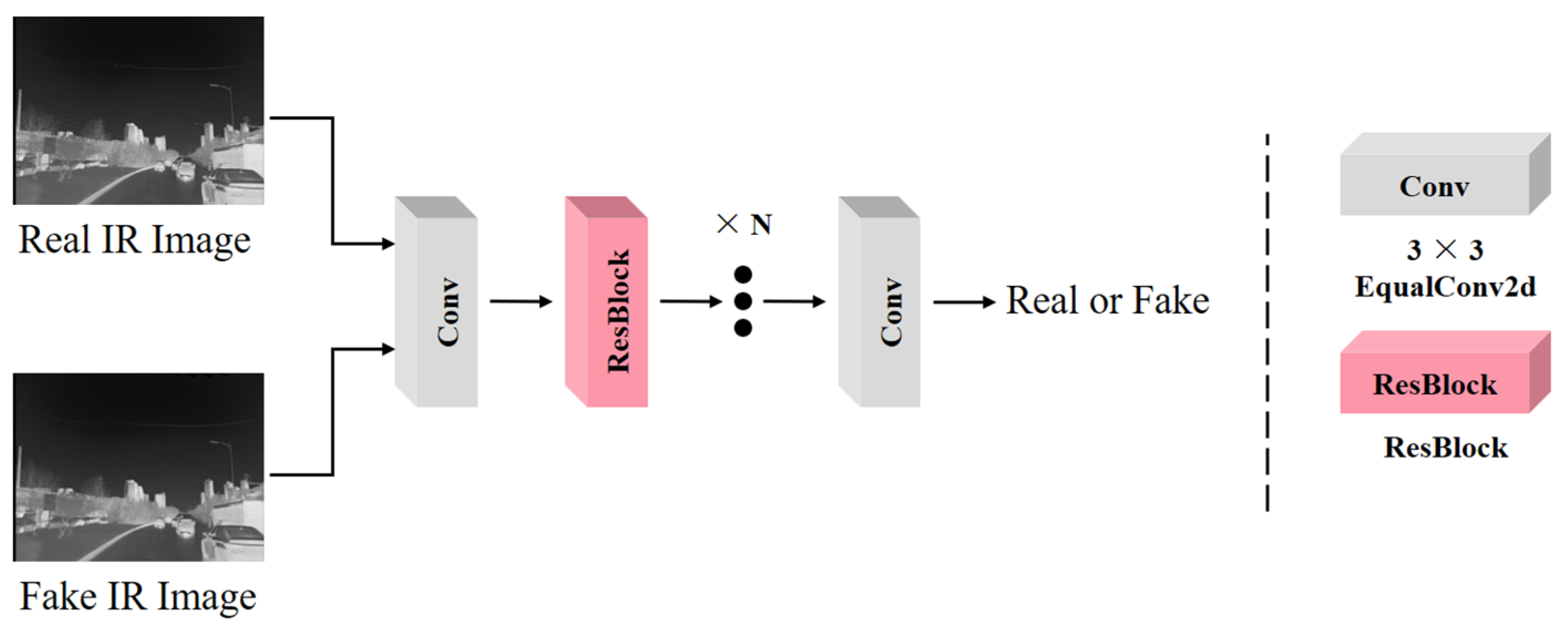
3.1. RGB-IR Cross-Modal Transformation
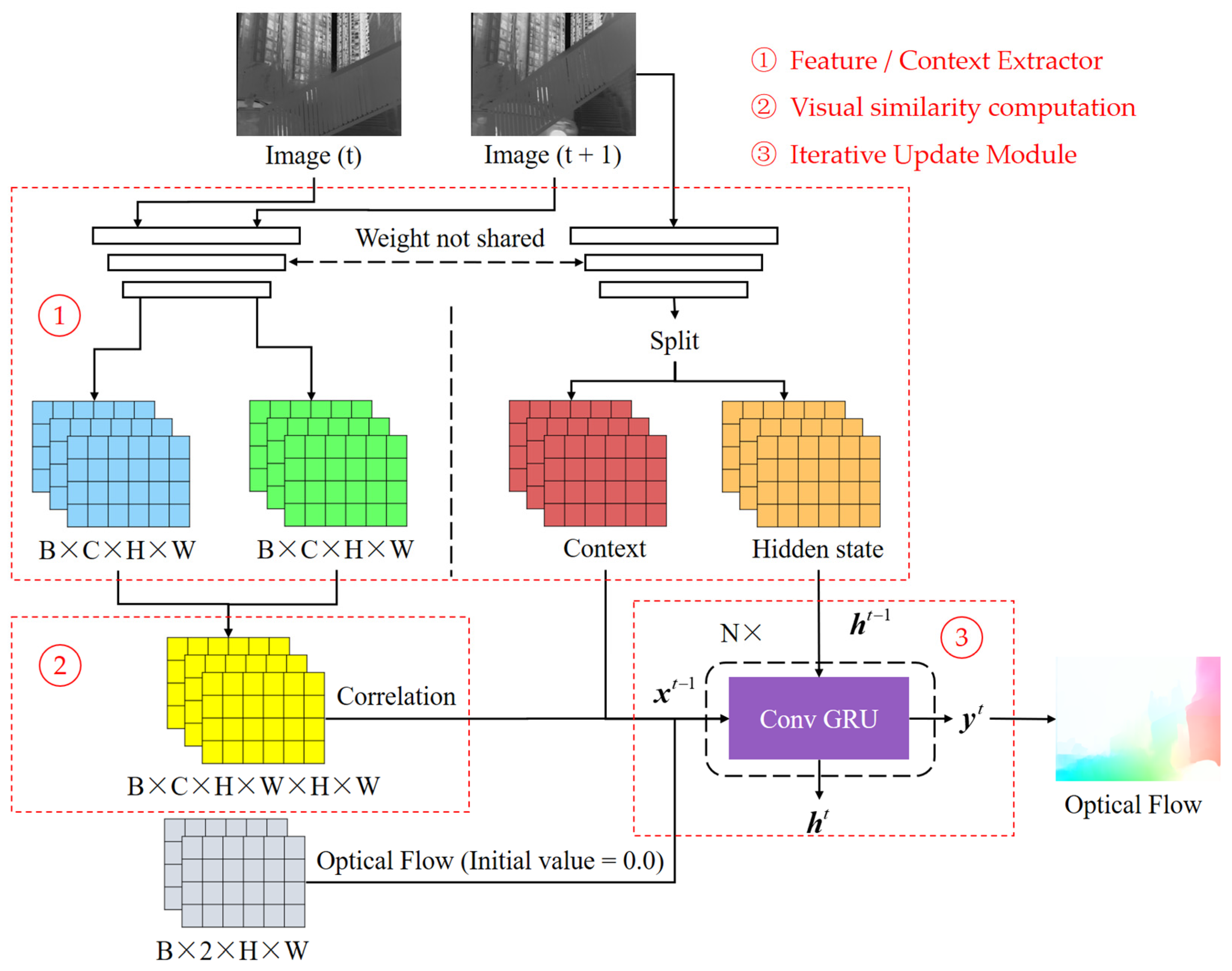
3.2. Optical Flow Computation
3.2.1. RAFT
3.2.2. FastFlowNet
4. Experimental Results
4.1. Experimental Results of RGB-IR Cross-Modal Transition
4.2. Experimental Results of Optical Flow Computation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fortun, D.; Bouthemy, P.; Kervrann, C. Optical flow modeling and computation: A survey. Comput. Vis. Image Underst. 2015, 134, 1–21. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, M.; Lu, F. Optical flow in the dark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6749–6757. [Google Scholar]
- Kastberger, G.; Stachl, R. Infrared imaging technology and biological applications. Behav. Res. Methods Instrum. Comput. 2003, 35, 429–439. [Google Scholar] [CrossRef] [PubMed]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Horn, B.K.; Schunck, B. Determining Optical Flow (Artificial Intelligence Laboratory); Massachusetts Institute of Technology: Cambridge, MA, USA, 1981; Volume 17, pp. 185–203. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.-Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- Yang, G.; Ramanan, D. Volumetric correspondence networks for optical flow. In Proceedings of the NIPS’19: 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 794–805. [Google Scholar]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Cham, Switzerland, 2020; pp. 402–419. [Google Scholar]
- Zhai, M.; Xiang, X.; Lv, N.; Kong, X. Optical flow and scene flow estimation: A survey. Pattern Recognit. 2021, 114, 107861. [Google Scholar] [CrossRef]
- Shah, S.T.H.; Xiang, X. Traditional and modern strategies for optical flow: An investigation. SN Appl. Sci. 2021, 3, 289. [Google Scholar] [CrossRef]
- Xin, J.; Cao, X.; Xiao, H.; Liu, T.; Liu, R.; Xin, Y. Infrared Small Target Detection Based on Multiscale Kurtosis Map Fusion and Optical Flow Method. Sensors 2023, 23, 1660. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Pinto, J.; Torres-Torriti, M. Optical Flow and Driver’s Kinematics Analysis for State of Alert Sensing. Sensors 2013, 13, 4225–4257. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Li, W.; Chu, H.; Chang, Z.; Zhang, X.; Zhan, H. A multitask cascading cnn with multiscale infrared optical flow feature fusion-based abnormal crowd behavior monitoring uav. Sensors 2020, 20, 5550. [Google Scholar] [CrossRef]
- Guerrero-Rodriguez, J.-M.; Cifredo-Chacon, M.-A.; Cobos Sánchez, C.; Perez-Peña, F. Exploiting the PIR Sensor Analog Behavior as Thermoreceptor: Movement Direction Classification Based on Spiking Neurons. Sensors 2023, 23, 5816. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 3061–3070. [Google Scholar]
- Yin, X.-L.; Liang, D.-X.; Wang, L.; Xu, J.; Han, D.; Li, K.; Yang, Z.-Y.; Xing, J.-H.; Dong, J.-Z.; Ma, Z.-Y. Optical flow estimation of coronary angiography sequences based on semi-supervised learning. Comput. Biol. Med. 2022, 146, 105663. [Google Scholar] [CrossRef] [PubMed]
- Jonschkowski, R.; Stone, A.; Barron, J.T.; Gordon, A.; Konolige, K.; Angelova, A. What matters in unsupervised optical flow. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Cham, Switzerland, 2020; pp. 557–572. [Google Scholar]
- Wang, G.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. RGB-infrared cross-modality person re-identification via joint pixel and feature alignmen. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3623–3632. [Google Scholar]
- Wu, A.; Zheng, W.-S.; Yu, H.-X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1125–1134. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- He, B.; Gao, F.; Ma, D.; Shi, B.; Duan, L.-Y. Chipgan: A generative adversarial network for chinese ink wash painting style transfer. In Proceedings of the 26th ACM International Conference on Multimedia, Torino, Italy, 22–26 October 2018; pp. 1172–1180. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Kong, L.; Shen, C.; Yang, J. Fastflownet: A lightweight network for fast optical flow estimation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 10310–10316. [Google Scholar]
- Eldesokey, A.; Felsberg, M. Normalized convolution upsampling for refined optical flow estimation. arXiv 2021, arXiv:2102.06979. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Cai, M.; Zhang, H.; Huang, H.; Geng, Q.; Li, Y.; Huang, G. Frequency domain image translation: More photo-realistic, better identity-preserving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 13930–13940. [Google Scholar]
- Wang, G.-A.; Zhang, T.; Yang, Y.; Cheng, J.; Chang, J.; Liang, X.; Hou, Z.-G. Cross-modality paired-images generation for RGB-infrared person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12144–12151. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | RMSE | PSNR | SSIM | RMSE | |
| Pix2Pix | 38.6729 | 0.9772 | 0.0118 | 21.6372 | 0.7048 | 0.1003 |
| FDIT | 9.0525 | 0.3992 | 0.3658 | 9.5175 | 0.4217 | 0.3495 |
| AlignGAN2 | 16.9659 | 0.6568 | 0.1457 | 14.5287 | 0.6030 | 0.1918 |
| Ours | 40.0976 | 0.9797 | 0.0102 | 20.9572 | 0.6915 | 0.1057 |
| RAFT | FastFlowNet | |
|---|---|---|
| RGB Network (without IR KITTI) | 64.8766 | 8.6948 |
| IR Network (with IR KITTI) | 49.3069 | 7.5395 |
| Percentage increase | 24% | 13.29% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, F.; Huang, W.; Wu, X. Enhancing Infrared Optical Flow Network Computation through RGB-IR Cross-Modal Image Generation. Sensors 2024, 24, 1615. https://doi.org/10.3390/s24051615
Huang F, Huang W, Wu X. Enhancing Infrared Optical Flow Network Computation through RGB-IR Cross-Modal Image Generation. Sensors. 2024; 24(5):1615. https://doi.org/10.3390/s24051615
Chicago/Turabian StyleHuang, Feng, Wei Huang, and Xianyu Wu. 2024. "Enhancing Infrared Optical Flow Network Computation through RGB-IR Cross-Modal Image Generation" Sensors 24, no. 5: 1615. https://doi.org/10.3390/s24051615
APA StyleHuang, F., Huang, W., & Wu, X. (2024). Enhancing Infrared Optical Flow Network Computation through RGB-IR Cross-Modal Image Generation. Sensors, 24(5), 1615. https://doi.org/10.3390/s24051615