Assessing Sensor Integrity for Nuclear Waste Monitoring Using Graph Neural Networks




Abstract
1. Introduction
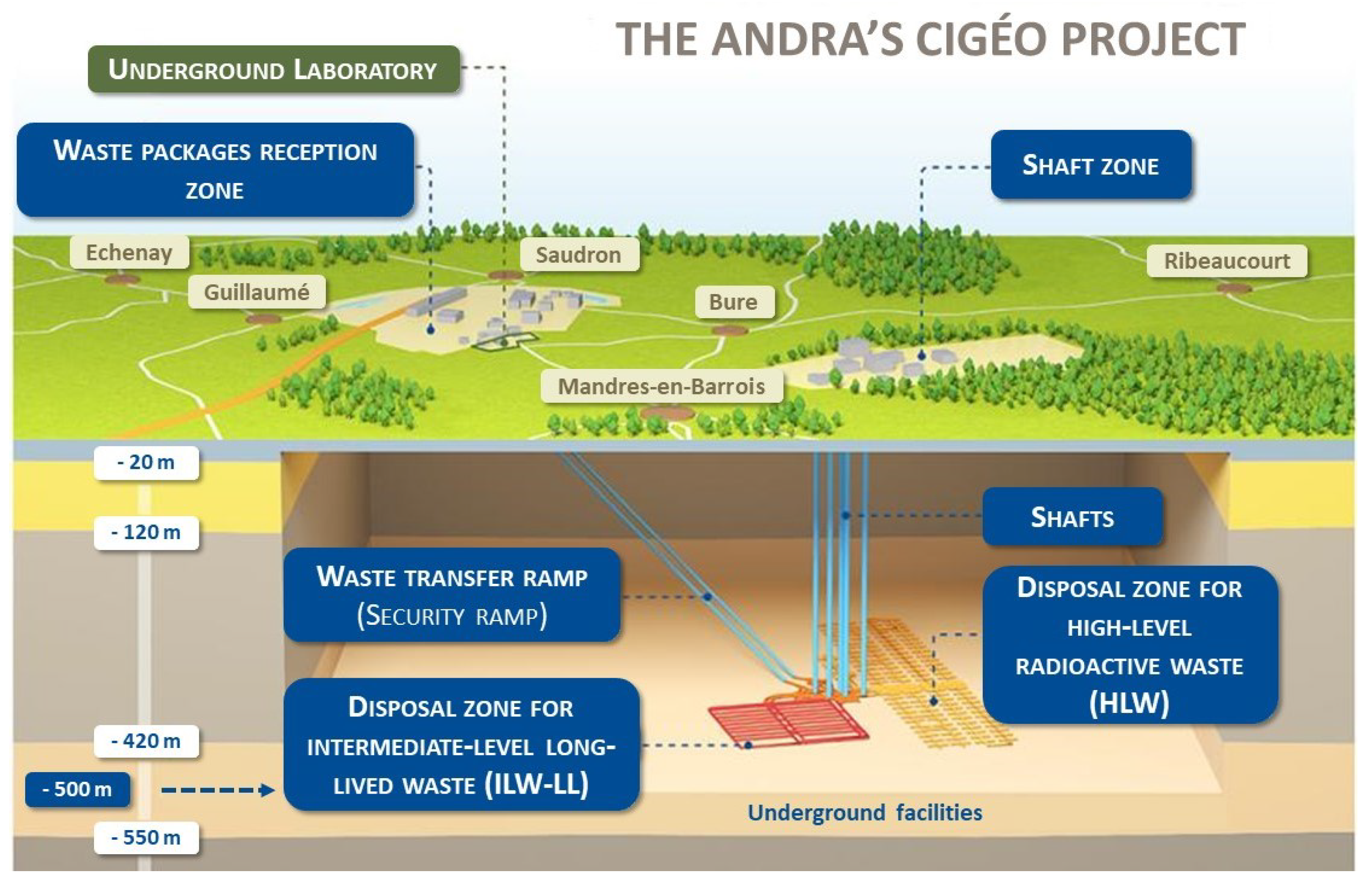
1.1. Andra’s Cigéo Project
1.2. The High-Level Waste (HLW) Demonstrator Cell
1.3. Graph Neural Networks and Message Passing
- At the graph level, for instance, one could give a molecule (as an input graph) and try to find out whether the molecule is toxic.
- At the edge level, typical operations are friend recommendations on a social network graph.
- At the node level, classification tasks can be performed, as was the case in this work, where the state (healthy or faulty) of each sensor (i.e., each node) was derived from the graph of the sensor network.
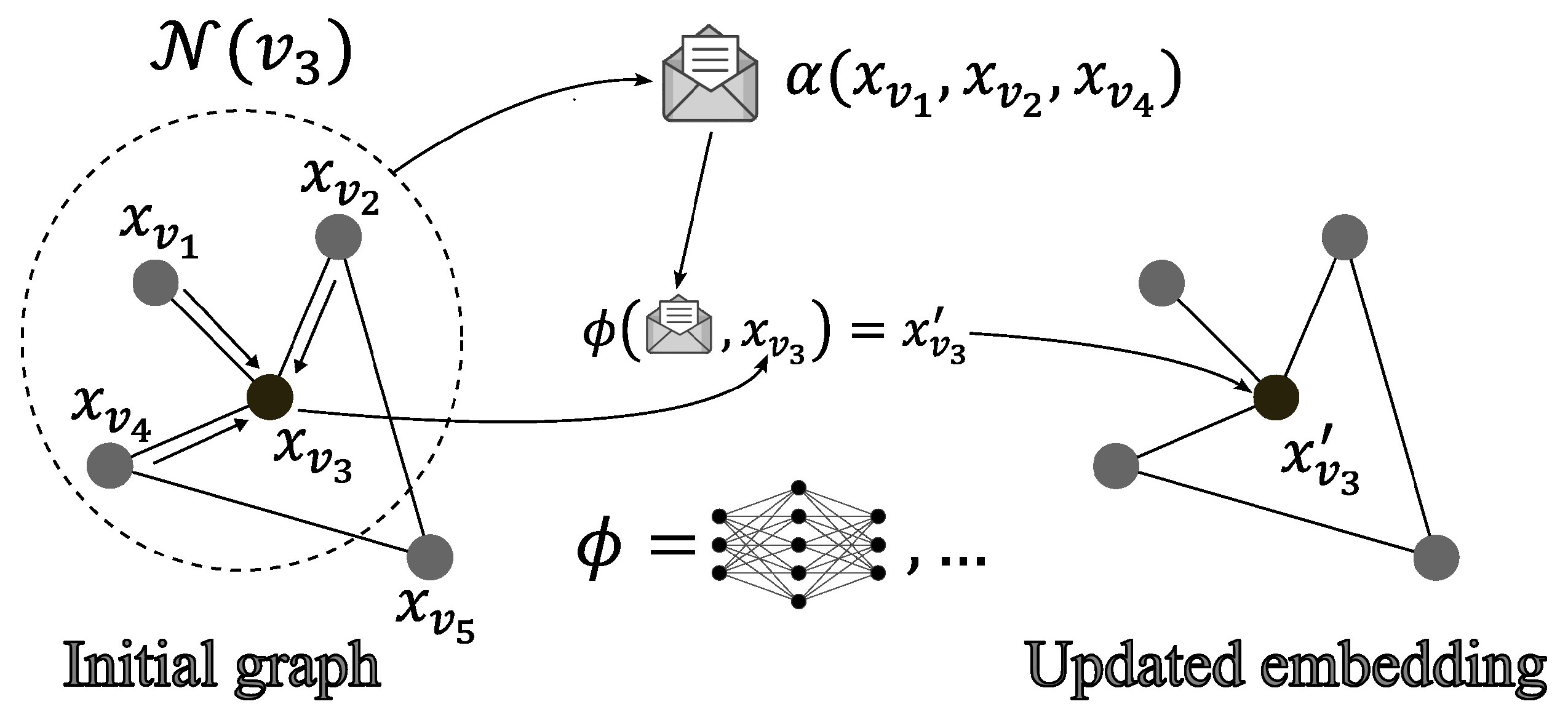
- Select a node v.
- Collect information (the messages) from the neighboring nodes (and edges).
- Concatenate the messages using a node-order equivariant function .
- Update the embedding of the node using an update function (which can be discovered by a neural network). This update function takes the concatenated messages and the selected node’s embedding as the inputs and outputs the updated node’s embedding .
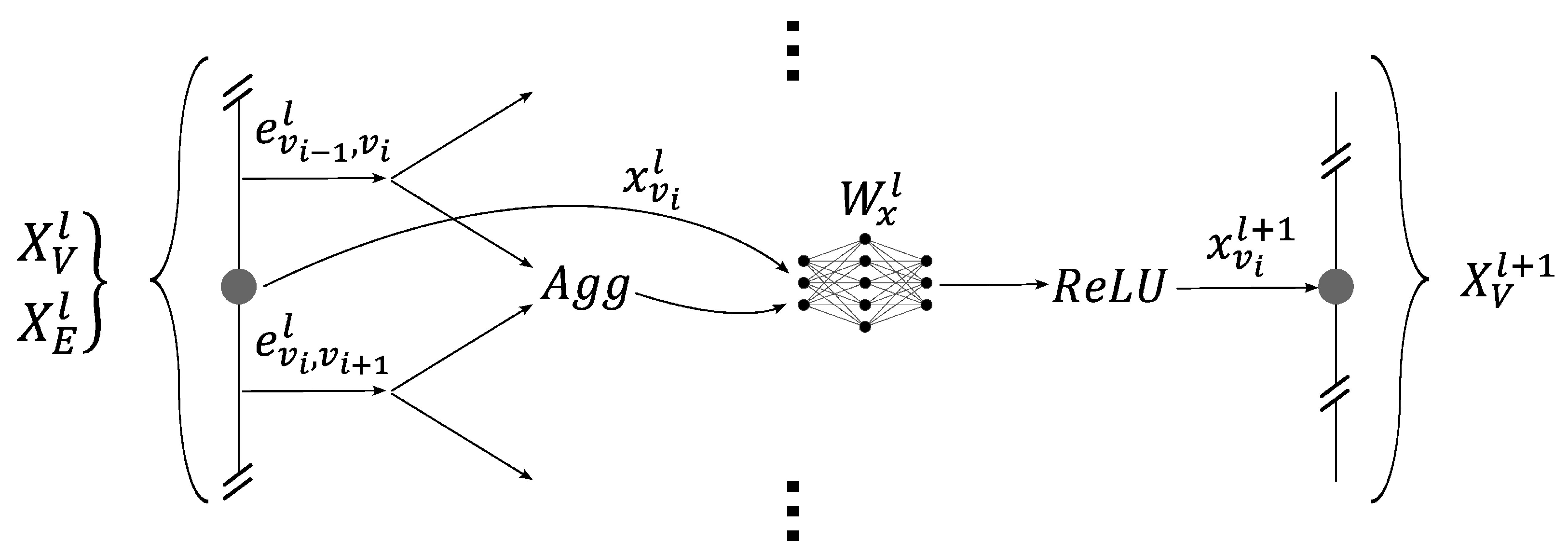
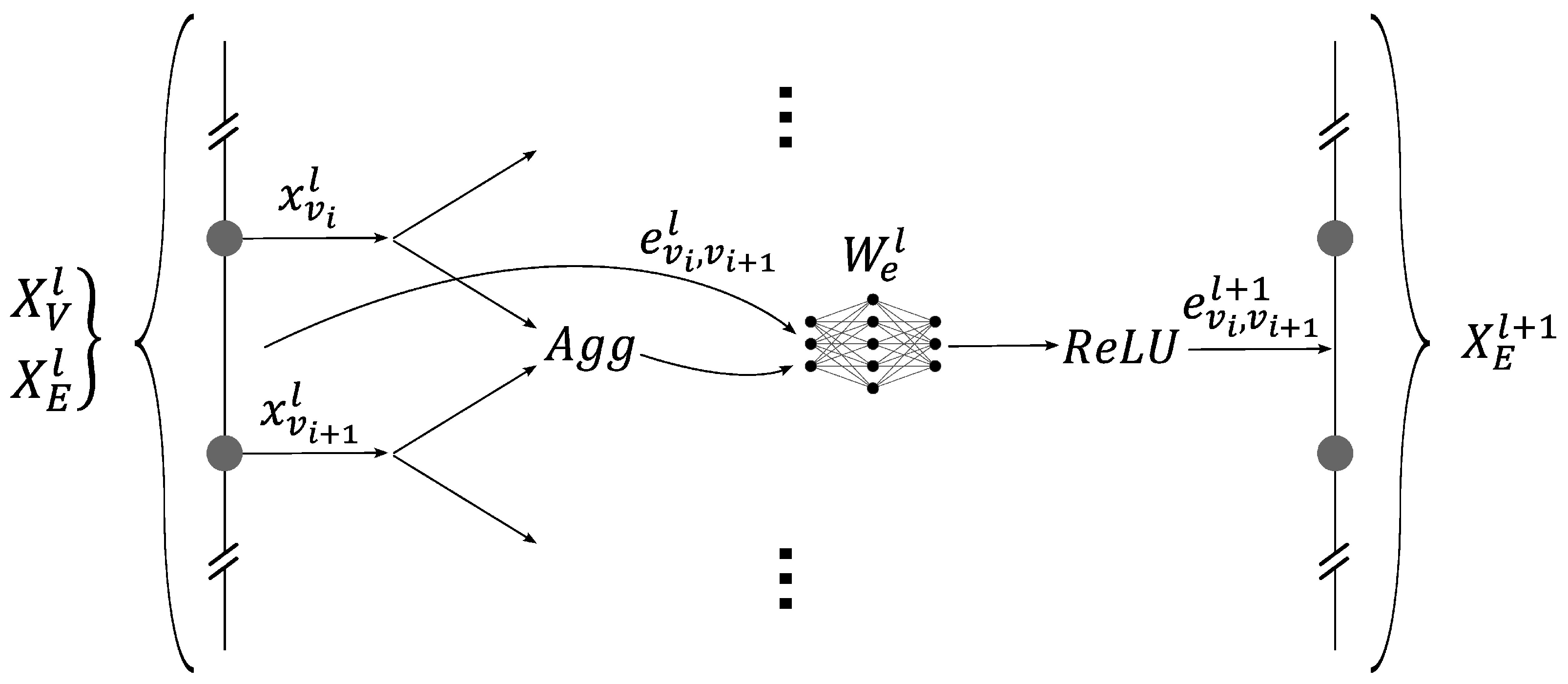
- The core of a GNN aims at transforming the input graph’s embeddings into embeddings that are easier to interpret by the second part of the model. This is achieved by stacking multiple layers of the GNN, each of which is based on message passing. The connectivity of the graph is not modified during this step. At the bottom of Figure 5, the embeddings are transformed into embeddings by the repeated application of message passing.
- The specific network takes the updated graph as the input and performs the desired prediction task (in the example, it is node classification). This network’s architecture depends on the related task (pooling layers are used for graph classification, softmax or sigmoid activation functions for classification, etc.). Then, a loss function is applied to the model in order to train it.
1.4. Graph Neural Network Models
1.5. Related Works
- Anomaly detection.
- Node classification.
- Sensor network monitoring.
2. Materials and Methods
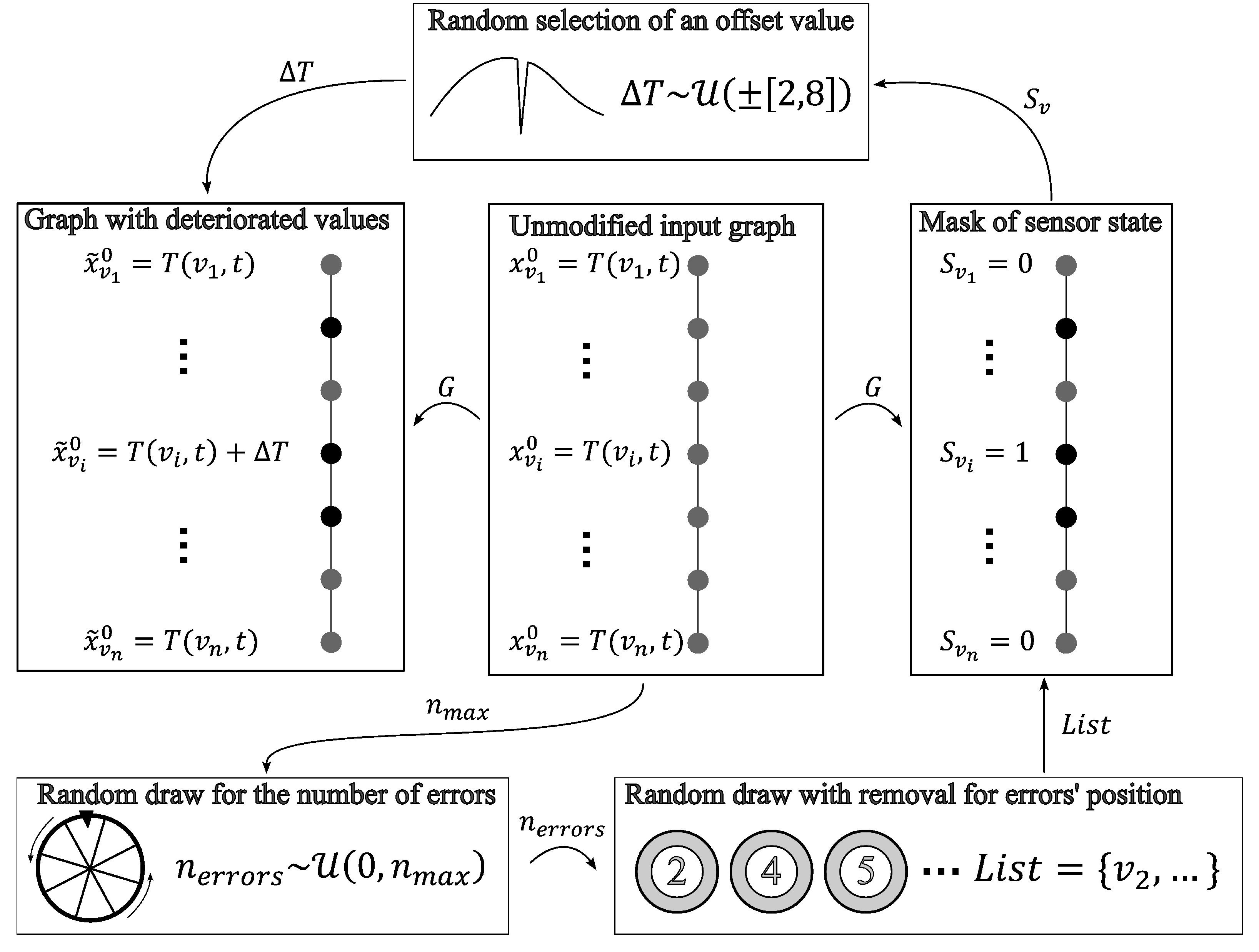
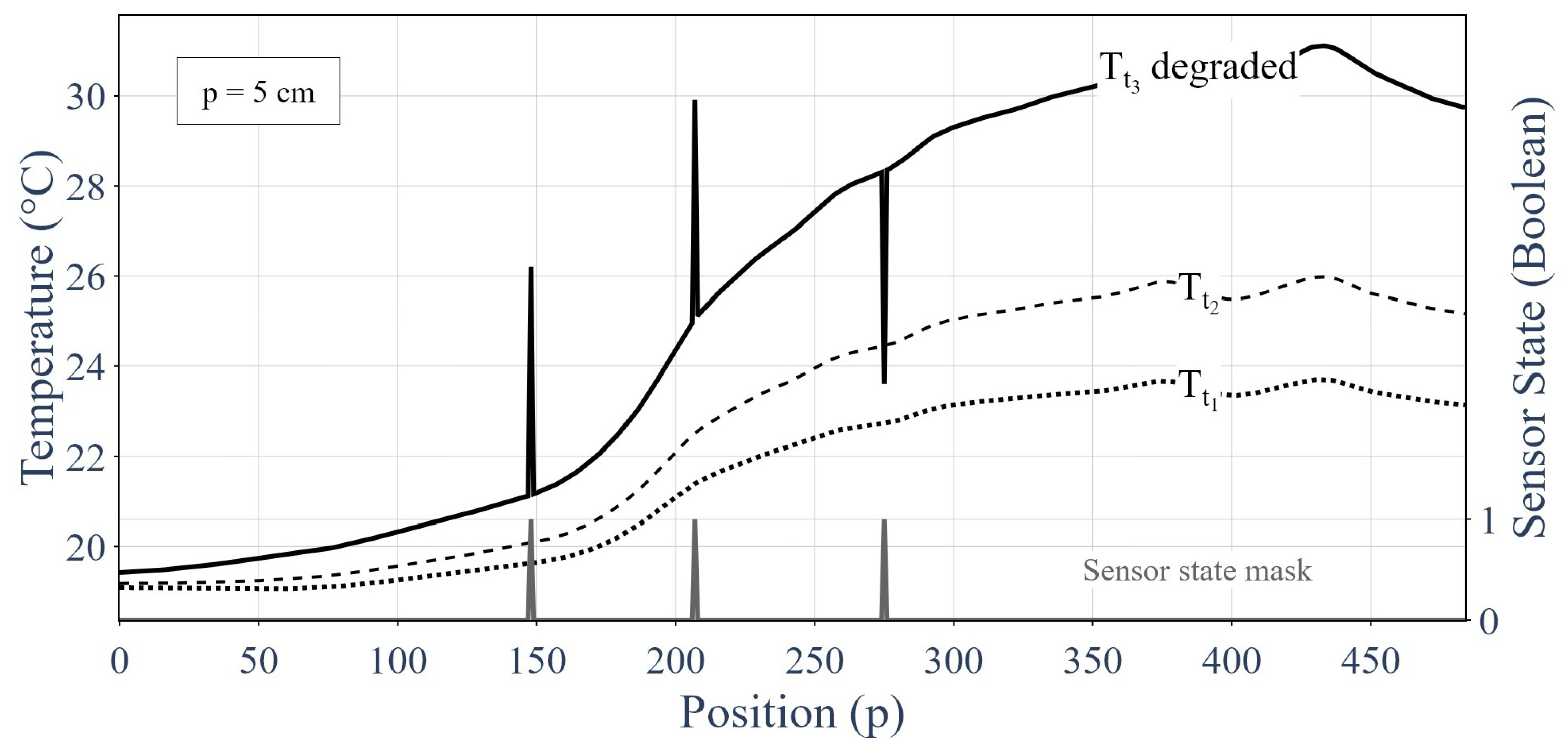
2.1. Generating a Training Dataset
- Bias.
- Drifting.
- Precision degradation.
- Gain.
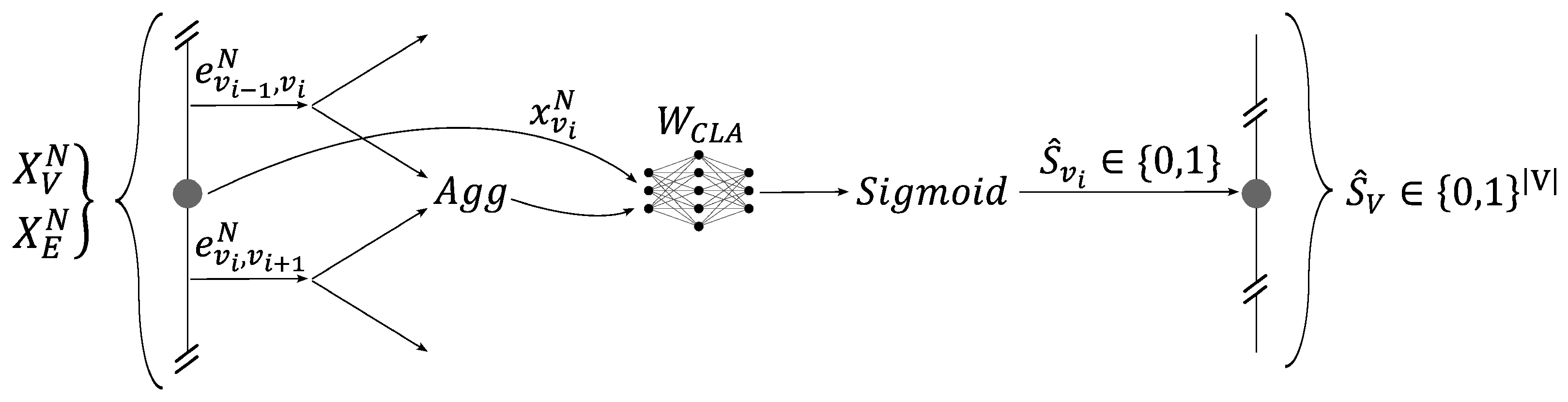
2.2. The Graph Neural Network Architecture
- The creation of the input graph.
- The updating of the graph’s embeddings, i.e., the core of the GNN, using message-passing layers based on the GraphSAGE model.
- The classification of each independent node.
- The size of the various MLPs in terms of the number of neurons.
- The aggregation functions used for the message-passing layers and the classifier.
- The number of message-passing layers.
- The weight w used in the loss function.
- The used optimizer was the Adam stochastic gradient descent algorithm [61].
- A total of 50 training epochs.
- A batch size of 20 per iteration of the gradient descent algorithm.
- A validation split of 15% (same split for all the networks).
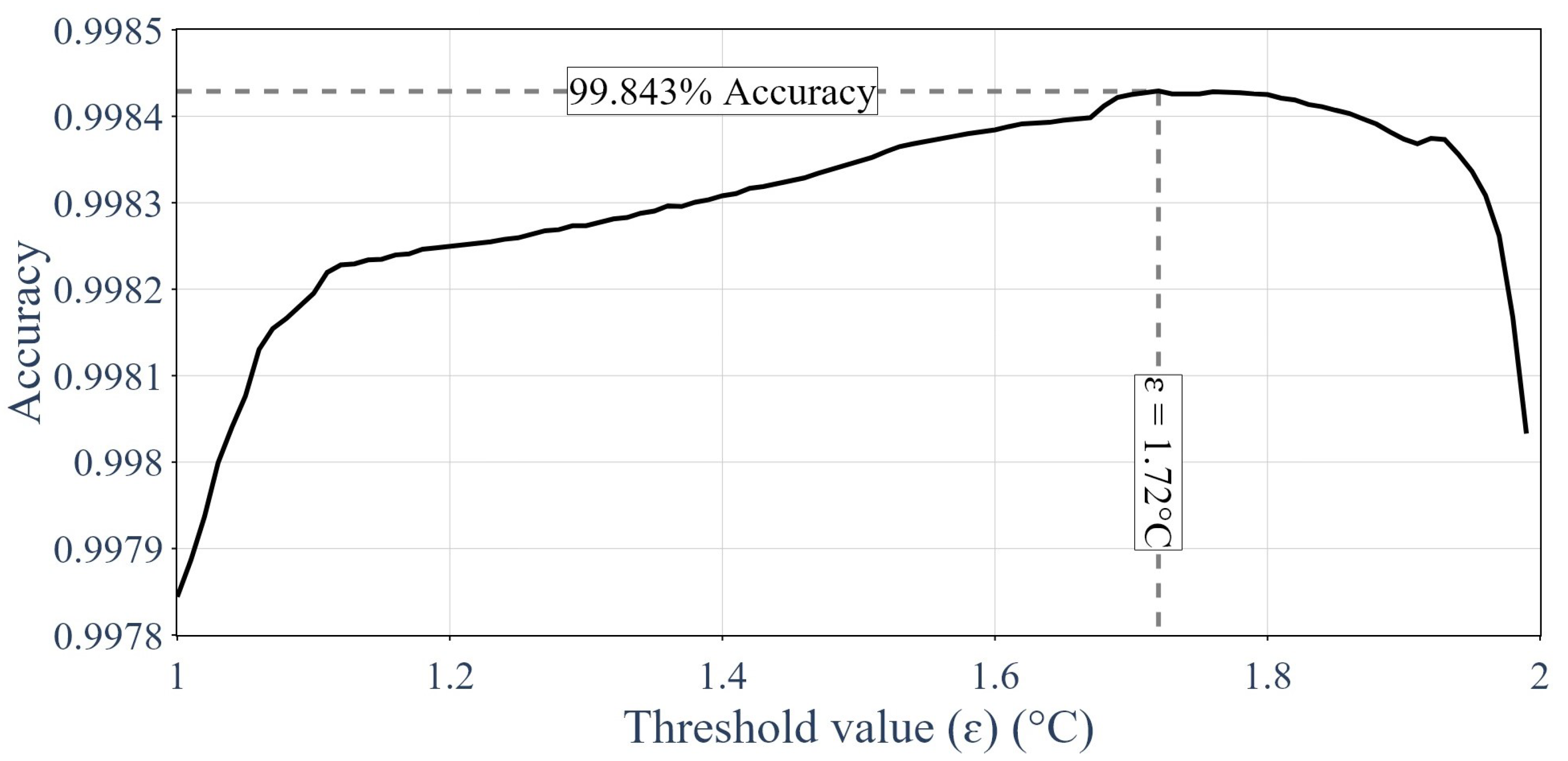
2.3. The Thresholding Classification Method
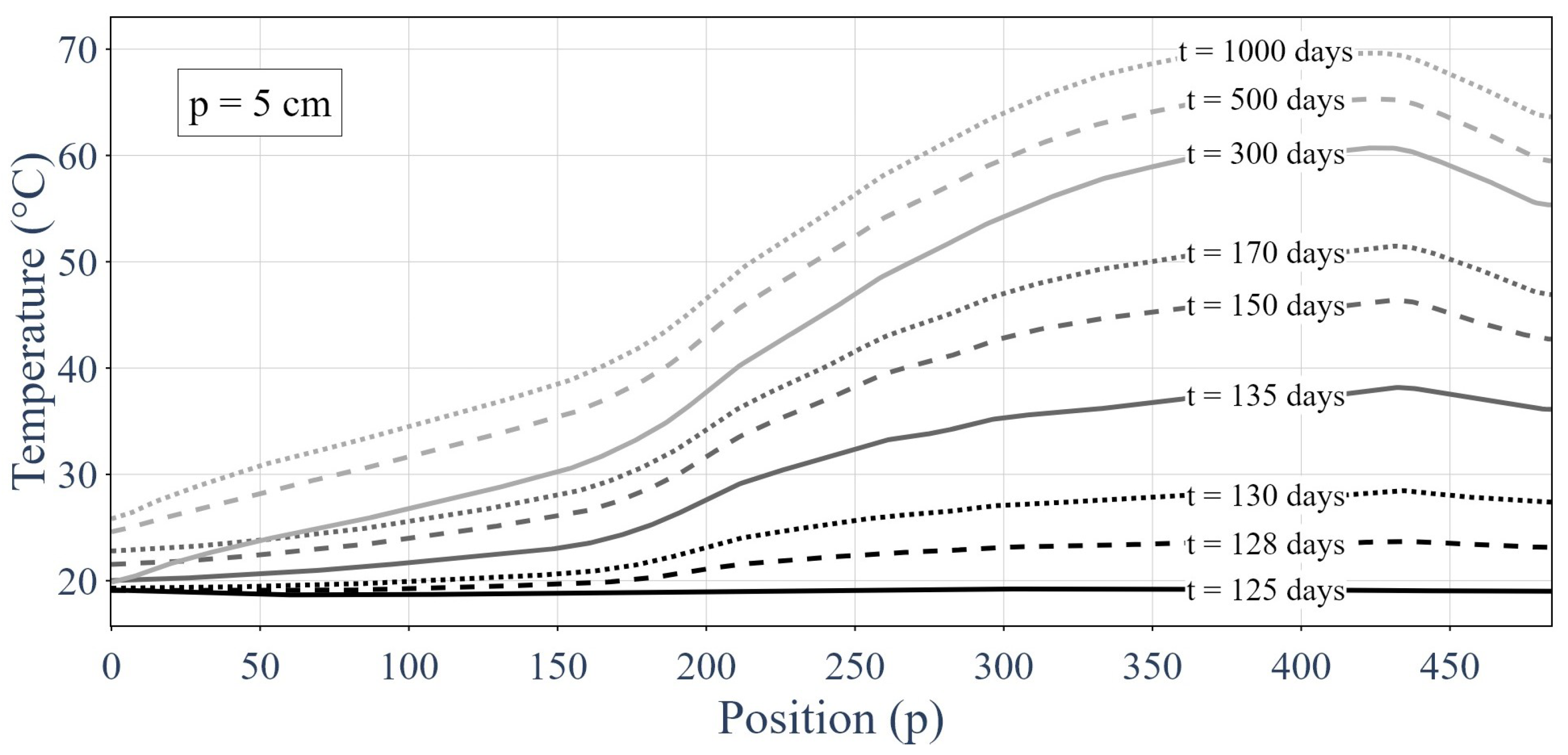
- The prediction of the temperature distribution at the third time step without errors was derived from the distributions at the two first time steps. For this purpose, a linear extrapolation method in time was used. Equation (17) presents how to obtain a prediction of the temperature at the third time step.
- The prediction of the temperature distribution was compared against the deteriorated response (at the third time step) by determining a threshold under which the sensor was supposedly healthy and over which the sensor was supposedly faulty. Equation (18) shows how the threshold value was used to assess the sensor integrity.
- Multiple thresholds were tested and the one with the best results was used.
2.4. The Multi-Layer-Perceptron-Based Classifier
- Layer 1 was composed of 15 neurons and used ReLU as its activation function.
- Layer 2 was composed of five neurons and used ReLU as its activation function.
- Layer 3 was composed of one neuron and used sigmoid as its activation function.
- The optimizer used was the Adam stochastic gradient descent algorithm [61].
- A total of 200 training epochs.
- A batch size of 200 per iteration of the gradient descent algorithm.
- A validation split of 15%.
2.5. The Decision Tree Classification Method
3. Results
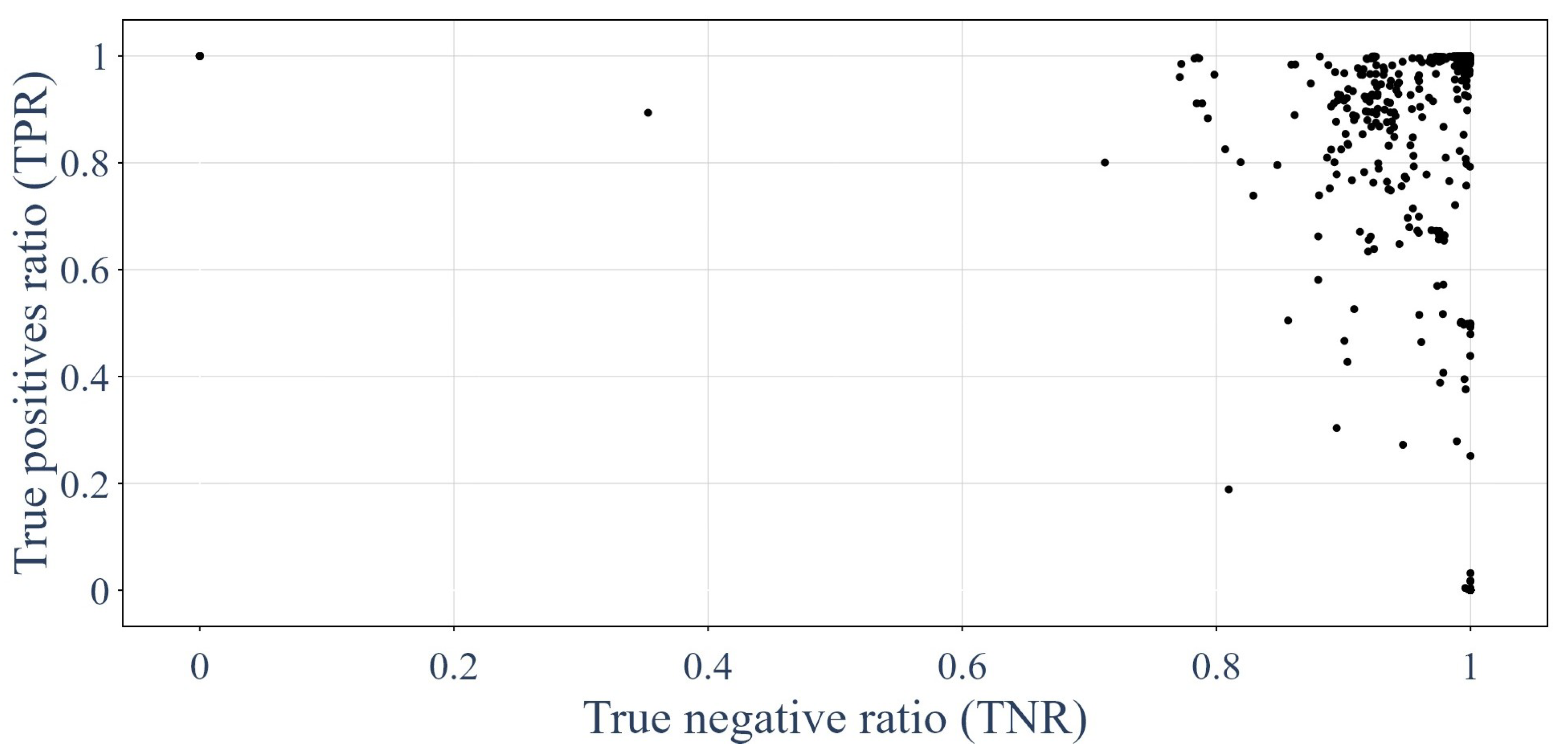
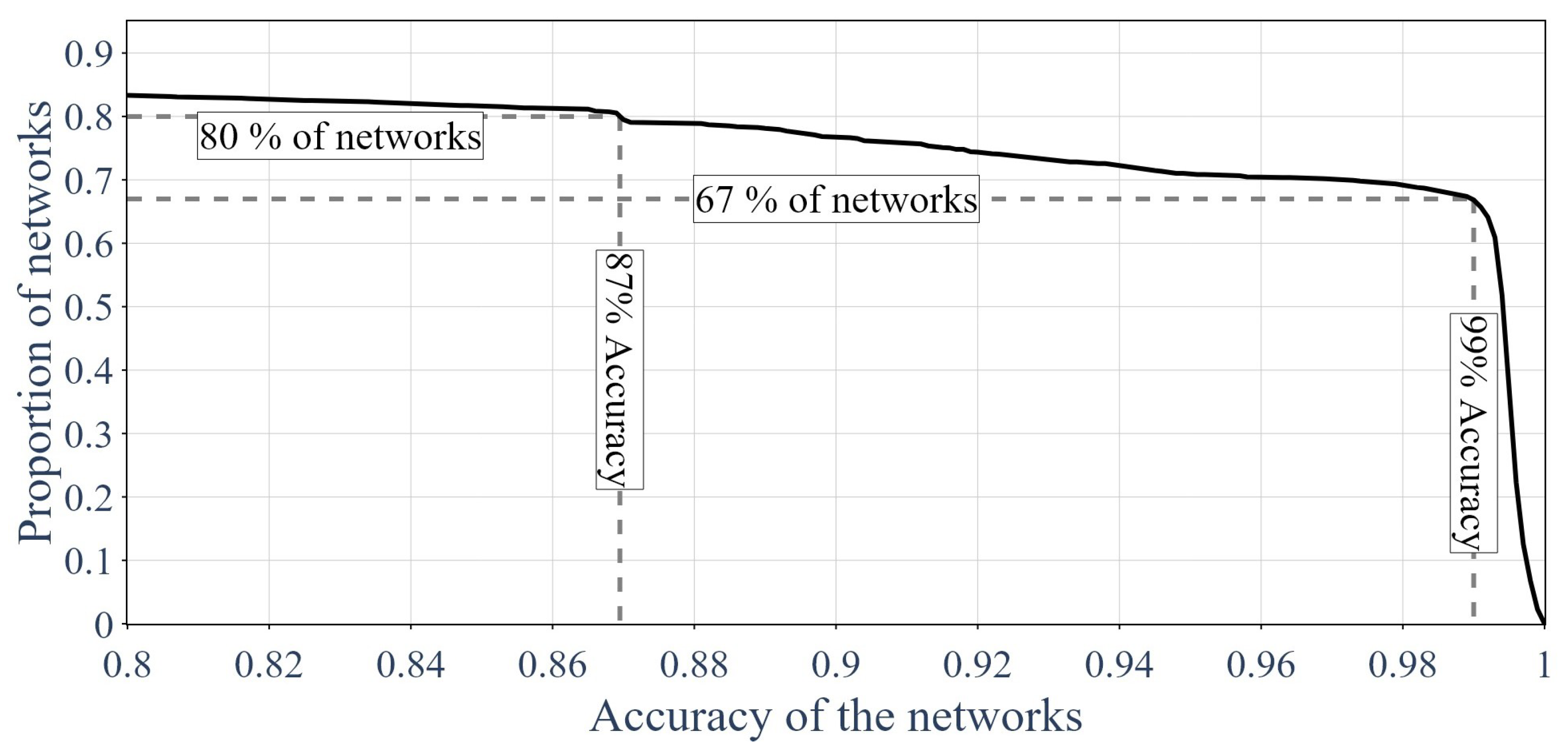
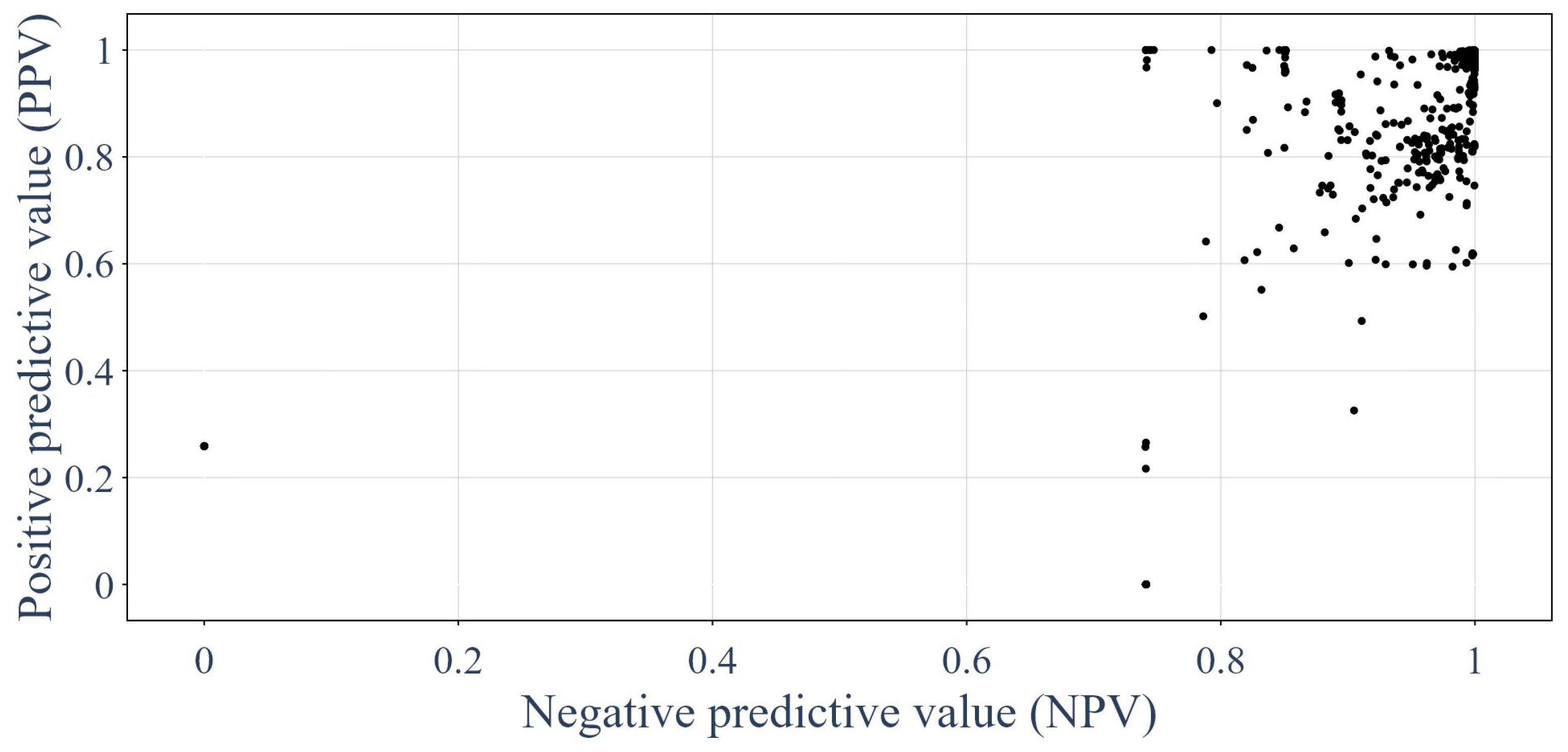
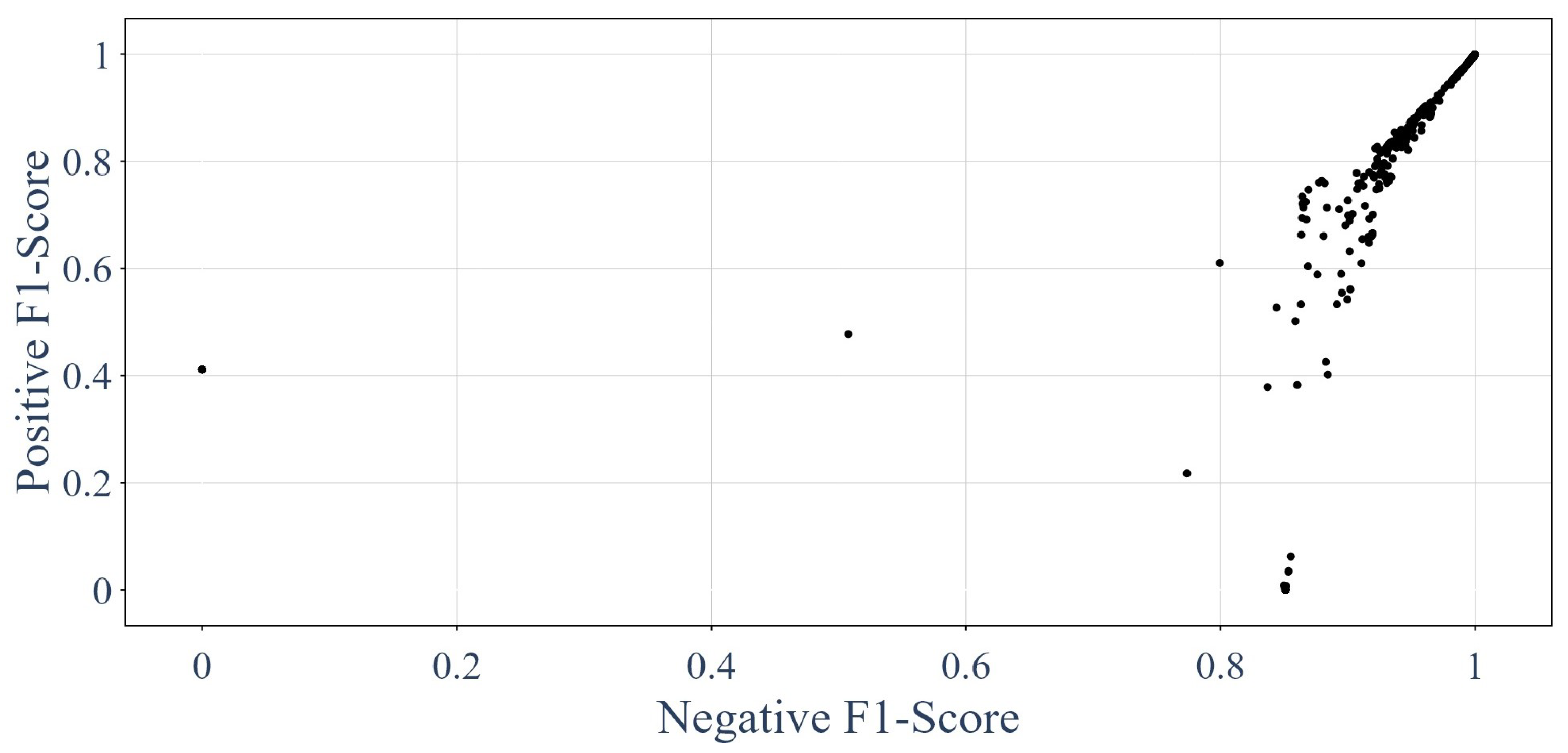
3.1. Results of the GNNs
3.2. Results of the Thresholding
3.3. Results of the Multi-Layer-Perceptron-Based Classifier
3.4. Results of the Multi-Layer-Perceptron-Based Classifier
3.5. Trained GNNs Compared against the Other Classification Methods
4. Discussion
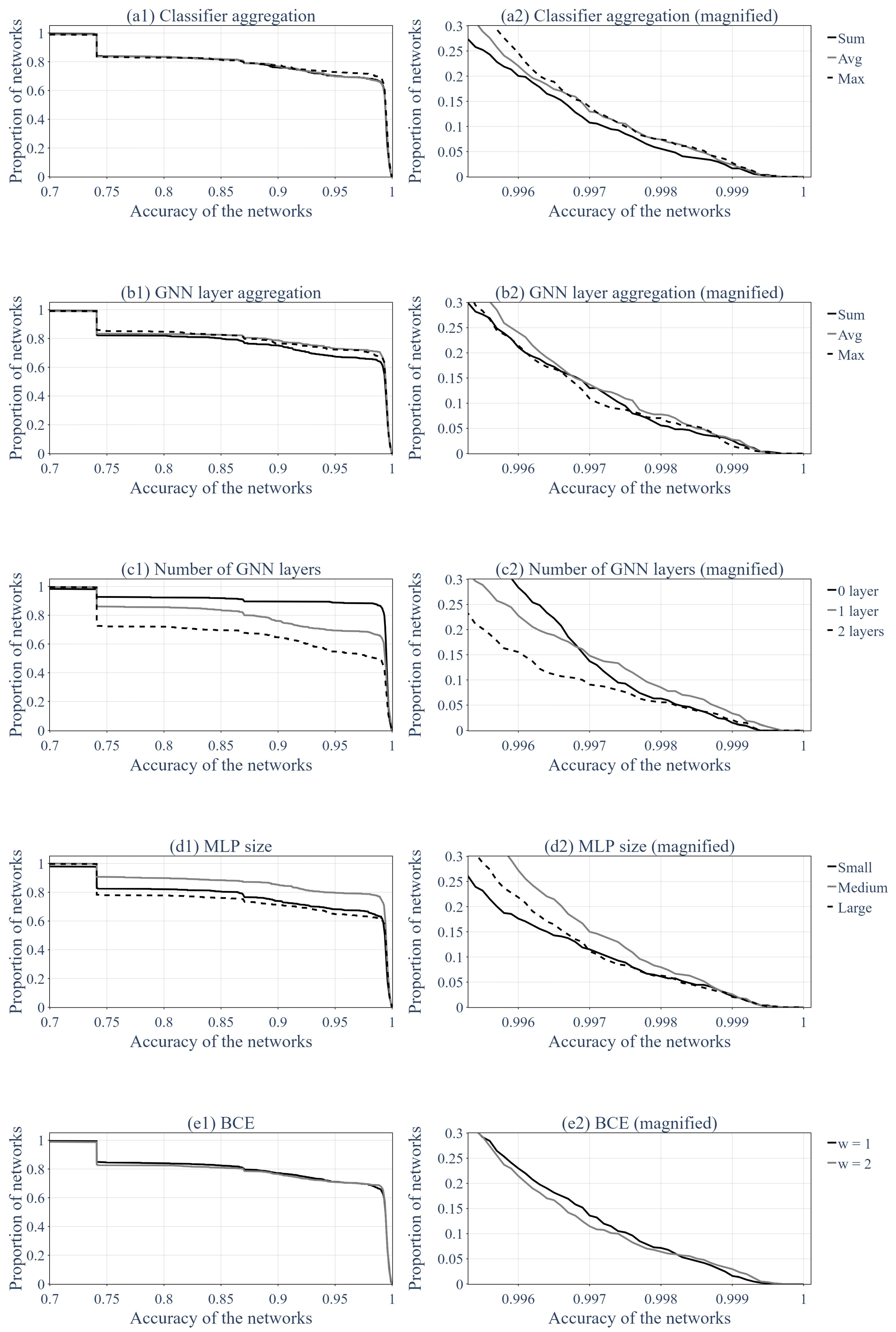
4.1. The Impacts of Different Hyperparameters
- To have a set of hyperparameters that performs well on average.
- To train only a few GNNs and have decent results.
- To have a set of hyperparameters that performs the best but many trained GNNs might have relatively bad precision.
- To train a lot of GNNs and pick out the top performers.
4.2. Efficiency of GNNs for Sensors’ Integrity Assessment
4.3. Upscaling the Model to Complex Networks
4.4. Limitations of the Used Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Notations | |
| Variable | Definition |
| G | Graph |
| V | Set of a graph’s nodes |
| n | Number of nodes in the graph () |
| E | Set of a graph’s edges |
| R | Set of the graph’s relations (edge type) |
| Individual nodes | |
| Individual edge adjacent to nodes u and v | |
| r | Individual relation |
| Neighborhood of node v (subset of V) | |
| Neighborhood of node v given a relation r (subset of ) | |
| l | Individual graph neural network layer |
| N | Graph neural network’s final layer |
| General update function | |
| W | Weight matrix of a neural network |
| Non-linear activation function | |
| Rectified linear unit function | |
| Sigmoid function | |
| Concatenation function | |
| Node-order equivariant aggregation function | |
| A | Attention function |
| Loss function | |
| Embedding of node v at layer l | |
| Embedding of edge at layer l | |
| Set of the nodes’ embeddings at layer l | |
| Set of the edges’ embeddings at layer l | |
| Set of the graph’s embeddings at layer l | |
| Real sensor state at node v | |
| Predicted sensor state at node v | |
| Set of the sensor state’s real value | |
| Set of the sensor state’s predicted value | |
| T | Temperature in degrees Celsius |
| Predicted temperature in degrees Celsius | |
| t | Time in days |
| p | Sensor’s position |
| P | Probability |
| Discrete uniform distribution | |
| Continuous uniform distribution | |
| Threshold value in degrees Celsius | |
| log | Natural logarithm function |
| Abbreviations | |
| GNN | Graph neural network |
| RecGNN | Recurrent graph neural network |
| GCN | Graph convolutional network |
| R-GCN | Relational graph convolutional network |
| GAT | Graph attention network |
| MLP | Multi-layer perceptron |
| URL | Underground Research Laboratory (of Andra) |
| HLW | High-level radioactive waste |
| ILW | Intermediate-level radioactive waste |
| ILW-LL | Intermediate-level long-lived radioactive waste |
| LLW | Low-level radioactive waste |
| HAW | High-activity waste |
| Agg | Aggregation |
| BCE | Binary cross-entropy |
| P | Real positive |
| N | Real negative |
| PP | Predicted positive |
| PN | Predicted negative |
| TN | True negative |
| TP | True positive |
| FN | False negative |
| FP | False positive |
| TNR | True negative ratio |
| TPR | True positive ratio |
| NPV | Negative predictive value |
| PPV | Positive predictive value |
References
- Sanchez-Lengeling, B.; Reif, E.; Pearce, A.; Wiltschko, A.B. A Gentle Introduction to Graph Neural Networks. Distill 2021, 6, e33. [Google Scholar] [CrossRef]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 32, 4–24. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. arXiv 2020, arXiv:1812.04202. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Hoang, V.T.; Jeon, H.J.; You, E.S.; Yoon, Y.; Jung, S.; Lee, O.J. Graph Representation Learning and Its Applications: A Survey. Sensors 2023, 23, 4168. [Google Scholar] [CrossRef]
- Nguyen, H.X.; Zhu, S.; Liu, M. A Survey on Graph Neural Networks for Microservice-Based Cloud Applications. Sensors 2022, 22, 9492. [Google Scholar] [CrossRef] [PubMed]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. arXiv 2017, arXiv:1704.01212. [Google Scholar] [CrossRef]
- Daigavane, A.; Ravindran, B.; Aggarwal, G. Understanding Convolutions on Graphs. Distill 2021, 6, e32. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. arXiv 2017, arXiv:1606.09375. [Google Scholar] [CrossRef]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. arXiv 2019, arXiv:1902.07153. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2018, arXiv:1706.02216. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? arXiv 2019, arXiv:1810.00826. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, F.; Zhang, L.; Ji, T.; Fu, K.; Zhao, L.; Chen, F.; Wu, L.; Aggarwal, C.; Lu, C.T. Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks. arXiv 2021, arXiv:2002.11867. [Google Scholar] [CrossRef]
- Weisfeiler, B.Y.; Leman, A.A. The Reduction of a Graph to Canonical Form and the Algebra which appears therein. nti Ser. 1968, 2, 12–16. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Sperduti, A.; Starita, A. Supervised neural networks for the classification of structures. IEEE Trans. Neural Netw. 1997, 8, 714–735. [Google Scholar] [CrossRef]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with Local and Global Consistency. Adv. Neural Inf. Process. Syst. 2003, 16. Available online: https://proceedings.neurips.cc/paper_files/paper/2003/file/87682805257e619d49b8e0dfdc14affa-Paper.pdf (accessed on 18 December 2023).
- Micheli, A. Neural network for graphs: A contextual constructive approach. IEEE Trans. Neural Netw. 2009, 20, 498–511. [Google Scholar] [CrossRef] [PubMed]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. arXiv 2014, arXiv:1312.6203. [Google Scholar] [CrossRef]
- He, M.; Wei, Z.; Wen, J.R. Convolutional Neural Networks on Graphs with Chebyshev Approximation, Revisited. arXiv 2022, arXiv:2202.03580. [Google Scholar] [CrossRef]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. arXiv 2016, arXiv:1605.05273. [Google Scholar] [CrossRef]
- Dehmamy, N.; Barabási, A.L.; Yu, R. Understanding the Representation Power of Graph Neural Networks in Learning Graph Topology. arXiv 2019, arXiv:1907.05008. [Google Scholar] [CrossRef]
- Atwood, J.; Towsley, D. Diffusion-Convolutional Neural Networks. arXiv 2016, arXiv:1511.02136. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. arXiv 2019, arXiv:1801.07829. [Google Scholar] [CrossRef]
- Levie, R.; Isufi, E.; Kutyniok, G. On the Transferability of Spectral Graph Filters. arXiv 2019, arXiv:1901.10524. [Google Scholar] [CrossRef]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on Graphs via Spectral Graph Theory. arXiv 2009, arXiv:0912.3848. [Google Scholar] [CrossRef]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. arXiv 2017, arXiv:1703.06103. [Google Scholar] [CrossRef]
- Beaini, D.; Passaro, S.; Létourneau, V.; Hamilton, W.L.; Corso, G.; Liò, P. Directional Graph Networks. arXiv 2021, arXiv:2010.02863. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903. [Google Scholar] [CrossRef]
- Knyazev, B.; Taylor, G.W.; Amer, M.R. Understanding Attention and Generalization in Graph Neural Networks. arXiv 2019, arXiv:1905.02850. [Google Scholar] [CrossRef]
- Zheng, X.; Liu, Y.; Pan, S.; Zhang, M.; Jin, D.; Yu, P.S. Graph Neural Networks for Graphs with Heterophily: A Survey. arXiv 2022, arXiv:2202.07082. [Google Scholar] [CrossRef]
- He, Z.; Chen, P.; Li, X.; Wang, Y.; Yu, G.; Chen, C.; Li, X.; Zheng, Z. A Spatiotemporal Deep Learning Approach for Unsupervised Anomaly Detection in Cloud Systems. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 1705–1719. [Google Scholar] [CrossRef] [PubMed]
- Jacob, S.; Qiao, Y.; Ye, Y.; Lee, B. Anomalous distributed traffic: Detecting cyber security attacks amongst microservices using graph convolutional networks. Comput. Secur. 2022, 118, 102728. [Google Scholar] [CrossRef]
- Somashekar, G.; Dutt, A.; Vaddavalli, R.; Varanasi, S.B.; Gandhi, A. B-MEG: Bottlenecked-Microservices Extraction Using Graph Neural Networks. In Proceedings of the Companion of the 2022 ACM/SPEC International Conference on Performance Engineering, Bejing, China, 9–13 April 2022; ICPE ’22. Association for Computing Machinery: New York, NY, USA, 2022; pp. 7–11. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Chen, H. Informer: Irregular traffic detection for containerized microservices RPC in the real world. High-Confid. Comput. 2022, 2, 100050. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, X.; Sha, C.; Zhang, K.; Fu, Z.; Wu, X.; Lin, Q.; Zhang, D. DeepTraLog: Trace-log combined microservice anomaly detection through graph-based deep learning. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022; ICSE ’22. Association for Computing Machinery: New York, NY, USA, 2022; pp. 623–634. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4027–4035. [Google Scholar] [CrossRef]
- Wu, Y.; Dai, H.N.; Tang, H. Graph Neural Networks for Anomaly Detection in Industrial Internet of Things. IEEE Internet Things J. 2022, 9, 9214–9231. [Google Scholar] [CrossRef]
- Skarding, J.; Gabrys, B.; Musial, K. Foundations and modelling of dynamic networks using Dynamic Graph Neural Networks: A survey. IEEE Access 2021, 9, 79143–79168. [Google Scholar] [CrossRef]
- Maekawa, S.; Noda, K.; Sasaki, Y.; Onizuka, M. Beyond Real-world Benchmark Datasets: An Empirical Study of Node Classification with GNNs. arXiv 2022, arXiv:2206.09144. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, Z.; Zhong, S.; Zhou, K.; Li, L.; Chen, R.; Choi, S.H.; Hu, X. Editable Graph Neural Network for Node Classifications. arXiv 2023, arXiv:2305.15529. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, S.; Dai, Y.; Guo, W. Graph neural networks in node classification: Survey and evaluation. Mach. Vis. Appl. 2021, 33, 4. [Google Scholar] [CrossRef]
- Maurya, S.K.; Liu, X.; Murata, T. Simplifying approach to Node Classification in Graph Neural Networks. arXiv 2021, arXiv:2111.06748. [Google Scholar] [CrossRef]
- Protogerou, A.; Papadopoulos, S.; Drosou, A.; Tzovaras, D.; Refanidis, I. A graph neural network method for distributed anomaly detection in IoT. Evol. Syst. 2021, 12, 19–36. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Z.; Li, X.; Shao, H.; Han, T.; Xie, M. Attention-aware temporal–spatial graph neural network with multi-sensor information fusion for fault diagnosis. Knowl.-Based Syst. 2023, 278, 110891. [Google Scholar] [CrossRef]
- Dong, G.; Tang, M.; Wang, Z.; Gao, J.; Guo, S.; Cai, L.; Gutierrez, R.; Campbel, B.; Barnes, L.E.; Boukhechba, M. Graph Neural Networks in IoT: A Survey. ACM Trans. Sens. Netw. 2023, 19, 47:1–47:50. [Google Scholar] [CrossRef]
- Li, H.; Zhang, S.; Su, L.; Huang, H.; Jin, D.; Li, X. GraphSANet: A Graph Neural Network and Self Attention Based Approach for Spatial Temporal Prediction in Sensor Network. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5756–5758. [Google Scholar] [CrossRef]
- Chen, D.; Liu, R.; Hu, Q.; Ding, S.X. Interaction-Aware Graph Neural Networks for Fault Diagnosis of Complex Industrial Processes. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 6015–6028. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Xu, L.; Zhou, J.; Liu, Y.; Gu, M.; Liu, X.; Yang, S. Modeling IoT Equipment with Graph Neural Networks. IEEE Access 2019, 7, 32754–32764. [Google Scholar] [CrossRef]
- Owerko, D.; Gama, F.; Ribeiro, A. Predicting Power Outages Using Graph Neural Networks. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; pp. 743–747. [Google Scholar] [CrossRef]
- Casas, S.; Gulino, C.; Liao, R.; Urtasun, R. SpAGNN: Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9491–9497. [Google Scholar] [CrossRef]
- Jiang, D.; Luo, X. Sensor self-diagnosis method based on a graph neural network. Meas. Sci. Technol. 2023, 35, 035109. [Google Scholar] [CrossRef]
- Kullaa, J. Detection, identification, and quantification of sensor fault in a sensor network. Mech. Syst. Signal Process. 2013, 40, 208–221. [Google Scholar] [CrossRef]
- Jäger, G.; Zug, S.; Casimiro, A. Generic Sensor Failure Modeling for Cooperative Systems. Sensors 2018, 18, 925. [Google Scholar] [CrossRef]
- Zou, X.; Liu, W.; Huo, Z.; Wang, S.; Chen, Z.; Xin, C.; Bai, Y.; Liang, Z.; Gong, Y.; Qian, Y.; et al. Current Status and Prospects of Research on Sensor Fault Diagnosis of Agricultural Internet of Things. Sensors 2023, 23, 2528. [Google Scholar] [CrossRef] [PubMed]
- ElHady, N.E.; Provost, J. A Systematic Survey on Sensor Failure Detection and Fault-Tolerance in Ambient Assisted Living. Sensors 2018, 18, 1991. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Xu, Q.; Chen, J.; Li, J.; Wang, M. A New Framework for Isolating Sensor Failures and Structural Damage in Noisy Environments Based on Stacked Gated Recurrent Unit Neural Networks. Buildings 2022, 12, 1286. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- van Rijsbergen, C.K. Information Retrieval. 1979. Available online: https://openlib.org/home/krichel/courses/lis618/readings/rijsbergen79_infor_retriev.pdf (accessed on 18 December 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Kozak, J.; Probierz, B.; Kania, K.; Juszczuk, P. Preference-Driven Classification Measure. Entropy 2022, 24, 531. [Google Scholar] [CrossRef]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Mittal, M.; Alenezi, M.; Alazab, M. The Use of Ensemble Models for Multiple Class and Binary Class Classification for Improving Intrusion Detection Systems. Sensors 2020, 20, 2559. [Google Scholar] [CrossRef]
- Zha, B.; Yilmaz, A. Subgraph Learning for Topological Geolocalization with Graph Neural Networks. Sensors 2023, 23, 5098. [Google Scholar] [CrossRef] [PubMed]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Keras: Deep Learning for Humans. 2015. Available online: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=VfYhf2wAAAAJ&citation_for_view=VfYhf2wAAAAJ:9pM33mqn1YgC (accessed on 18 December 2023).
- Plotly Technologies Inc. Plotly: Collaborative Data Science. 2015. Available online: https://plotly.com/chart-studio-help/citations/ (accessed on 18 December 2023).



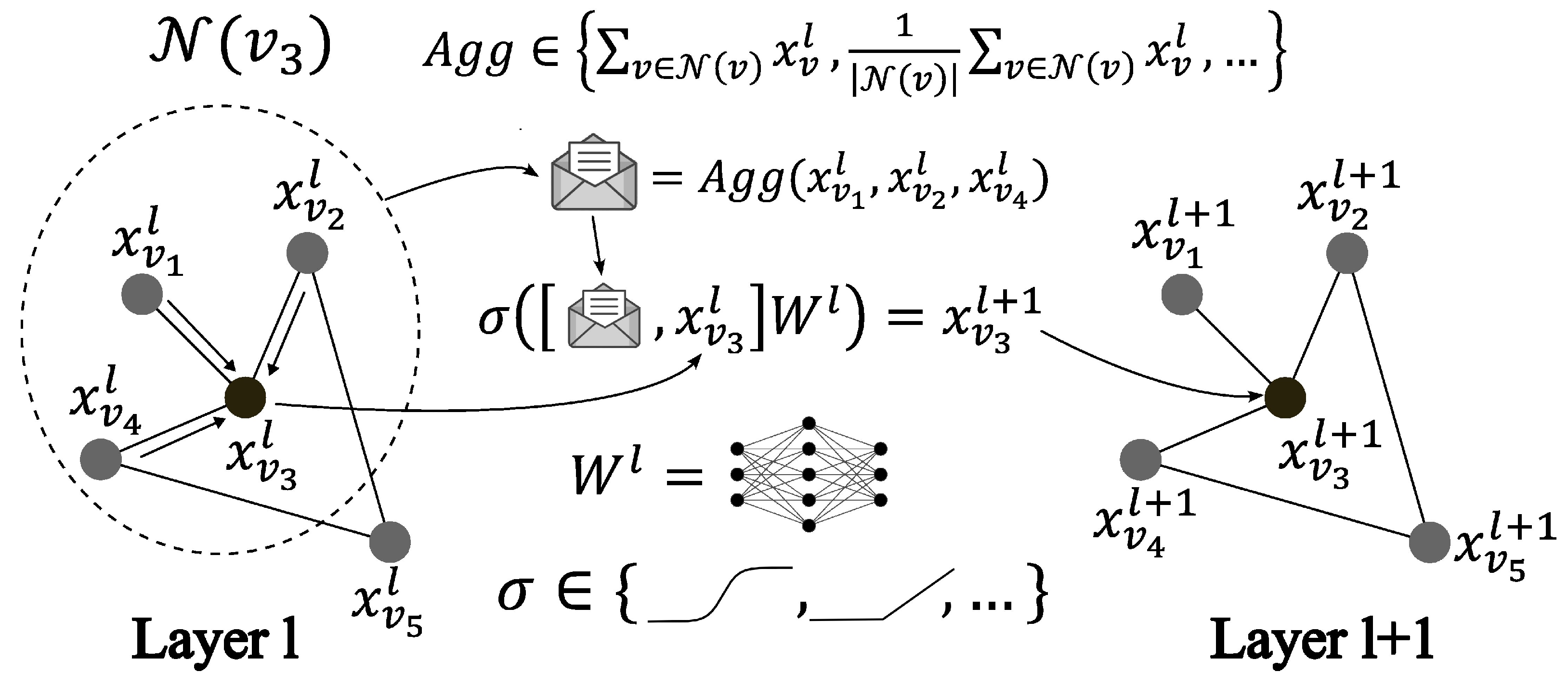






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agg MP | Agg CLA | No. of Layers | MLP Size (Flow, Update, CLA) in Number of Neurons | BCE Weight |
|---|---|---|---|---|
| Sum | Sum | 0 | Small (2, 15, 15) | 1 |
| Avg | Avg | 1 | Medium (4, 30, 30) | 2 |
| Max | Max | 2 | Large (8, 60, 60) |
| TN = 1,791,832 | FP = 5240 |
| FN = 555 | TP = 627,373 |
| TN = 1,796,452 | FP = 620 |
| FN = 133 | TP = 627,795 |
| TN = 1,796,452 | FP = 11 |
| FN = 327 | TP = 627,795 |
| Model | Recall | Precision | F1 | Accuracy | |||
|---|---|---|---|---|---|---|---|
| TNR | TPR | NPV | PPV | F1-N | F1-P | ||
| Thresholding | 99.708% | 99.912% | 99.969% | 99.172% | 99.839% | 99.540% | 99.761% |
| MLP | 99.965% | 99.979% | 99.993% | 99.901% | 99.979% | 99.940% | 99.969% |
| Decision tree | 99.999% | 99.948% | 99.982% | 99.998% | 99.991% | 99.973% | 99.986% |
| GNN-1 | 99.964% | 99.975% | 99.991% | 99.898% | 99.978% | 99.937% | 99.967% |
| GNN-2 | 99.975% | 99.942% | 99.980% | 99.927% | 99.977% | 99.935% | 99.966% |
| GNN-3 | 99.974% | 99.905% | 99.967% | 99.924% | 99.970% | 99.914% | 99.956% |
| GNN-4 | 99.956% | 99.950% | 99.983% | 99.874% | 99.969% | 99.912% | 99.954% |
| GNN-5 | 99.954% | 99.936% | 99.978% | 99.869% | 99.966% | 99.902% | 99.949% |
| Model | Agg MP | Agg CLA | N Layers | MLPs’ Size | BCE Weight |
|---|---|---|---|---|---|
| GNN-1 | Max | Max | 1 | Medium | 2 |
| GNN-2 | Avg | Sum | 1 | Large | 1 |
| GNN-3 | Sum | Sum | 1 | Small | 2 |
| GNN-4 | Sum | Avg | 1 | Small | 2 |
| GNN-5 | Max | Avg | 1 | Large | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hembert, P.; Ghnatios, C.; Cotton, J.; Chinesta, F. Assessing Sensor Integrity for Nuclear Waste Monitoring Using Graph Neural Networks. Sensors 2024, 24, 1580. https://doi.org/10.3390/s24051580
Hembert P, Ghnatios C, Cotton J, Chinesta F. Assessing Sensor Integrity for Nuclear Waste Monitoring Using Graph Neural Networks. Sensors. 2024; 24(5):1580. https://doi.org/10.3390/s24051580
Chicago/Turabian StyleHembert, Pierre, Chady Ghnatios, Julien Cotton, and Francisco Chinesta. 2024. "Assessing Sensor Integrity for Nuclear Waste Monitoring Using Graph Neural Networks" Sensors 24, no. 5: 1580. https://doi.org/10.3390/s24051580
APA StyleHembert, P., Ghnatios, C., Cotton, J., & Chinesta, F. (2024). Assessing Sensor Integrity for Nuclear Waste Monitoring Using Graph Neural Networks. Sensors, 24(5), 1580. https://doi.org/10.3390/s24051580