
A Deep Long-Term Joint Temporal–Spectral Network for Spectrum Prediction


Abstract
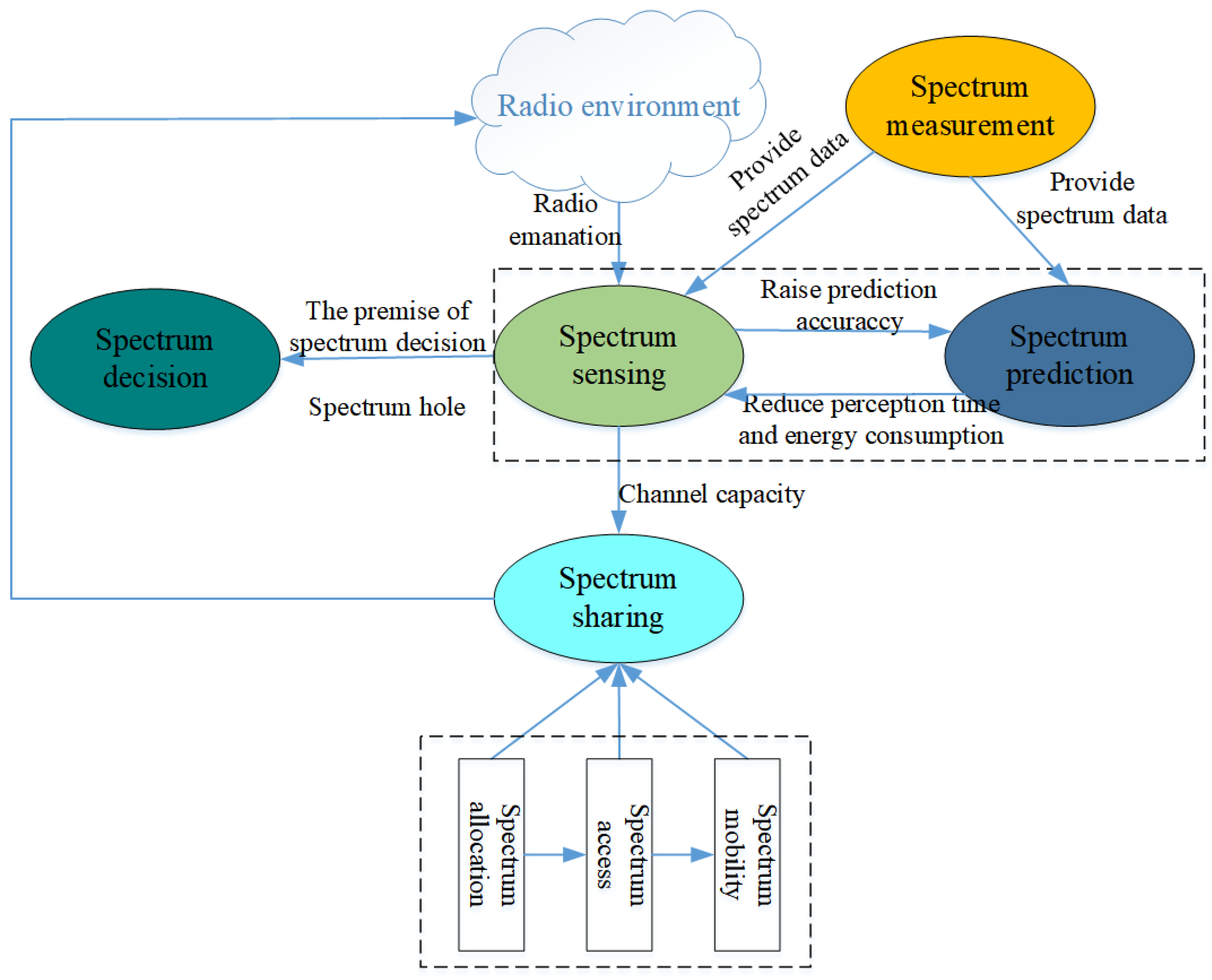
1. Introduction
- We propose a spectrum data construction method with a simple structure to make multi-dimensional and long-term spectrum predictions simultaneously. Different from the existing spectrum prediction in a slot-by-slot manner, the proposed approach is more efficient and can predict multi-slot spectrum states ahead of multiple spectrum points.
- We combine Bi-ConvLSTM and seq2seq to construct the proposed networks that can achieve both temporal–spectral and long-term spectrum prediction.
- Validated on real-world datasets, the experimental results show that our proposed spectrum prediction model achieves 6.15%, 0.7749, 1.0978, and 0.9628 in mean absolute percentage error (MAPE), mean absolute error (MAE), root mean square error (RMSE), and R-squared (), respectively, which is better than all the baseline deep learning models. Furthermore, the designed model is robust against missing spectrum data.
2. Problem Formulation
3. Deep Long-Term Joint Temporal–Spectral Network
| Algorithm 1 The proposed model training algorithm. |
|
4. Experiments
4.1. Settings
4.2. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, G.; Wang, J.; Wu, Q.; Yao, Y.D.; Li, R.; Zhang, H.; Zou, Y. On the limits of predictability in real-world radio spectrum state dynamics: From entropy theory to 5G spectrum sharing. IEEE Commun. Mag. 2015, 53, 178–183. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Lo, B.F.; Balakrishnan, R. Cooperative spectrum sensing in cognitive radio networks: A survey. Phys. Commun. 2011, 4, 40–62. [Google Scholar] [CrossRef]
- Eze, J.; Zhang, S.; Liu, E.; Eze, E. Cognitive radio-enabled Internet of Vehicles: A cooperative spectrum sensing and allocation for vehicular communication. IET Netw. 2018, 7, 190–199. [Google Scholar] [CrossRef]
- Hu, F.; Chen, B.; Zhu, K. Full spectrum sharing in cognitive radio networks toward 5G: A survey. IEEE Access 2018, 6, 15754–15776. [Google Scholar] [CrossRef]
- Tandra, R.; Sahai, A. Fundamental limits on detection in low SNR under noise uncertainty. In Proceedings of the 2005 International Conference on Wireless Networks, Communications and Mobile Computing, Maui, HI, USA, 13–16 June 2005; Volume 1, pp. 464–469. [Google Scholar]
- Jia, M.; Zhang, X.; Sun, J.; Gu, X.; Guo, Q. Intelligent resource management for satellite and terrestrial spectrum shared networking toward B5G. IEEE Wirel. Commun. 2020, 27, 54–61. [Google Scholar] [CrossRef]
- Ghasemi, A.; Sousa, E.S. Collaborative spectrum sensing for opportunistic access in fading environments. In Proceedings of the First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, 2005. DySPAN 2005, Baltimore, MD, USA, 8–11 November 2005; pp. 131–136. [Google Scholar]
- Lan, K.; Zhao, H.; Zhang, J.; Long, C.; Luo, M. A spectrum prediction approach based on neural networks optimized by genetic algorithm in cognitive radio networks. In Proceedings of the 10th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM 2014), Beijing, China, 26–28 September 2014; pp. 131–136. [Google Scholar]
- Ding, G.; Jiao, Y.; Wang, J.; Zou, Y.; Wu, Q.; Yao, Y.D.; Hanzo, L. Spectrum Inference in Cognitive Radio Networks: Algorithms and Applications. IEEE Commun. Surv. Tutor. 2018, 20, 150–182. [Google Scholar] [CrossRef]
- Akbar, I.A.; Tranter, W.H. Dynamic spectrum allocation in cognitive radio using hidden Markov models: Poisson distributed case. In Proceedings of the 2007 IEEE SoutheastCon, Richmond, VA, USA, 22–25 March 2007; pp. 196–201. [Google Scholar]
- Zhao, Y.; Luo, S.; Yuan, Z.; Lin, R. A New Spectrum Prediction Method for UAV Communications. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 826–830. [Google Scholar]
- Chen, X.; Yang, J.; Ding, G. Minimum Bayesian risk based robust spectrum prediction in the presence of sensing errors. IEEE Access 2018, 6, 29611–29625. [Google Scholar] [CrossRef]
- Pandian, P.; Selvaraj, C.; Bhalaji, N.; Arun Depak, K.G.; Saikrishnan, S. Machine Learning based Spectrum Prediction in Cognitive Radio Networks. In Proceedings of the 2023 International Conference on Networking and Communications (ICNWC), Chennai, India, 5–6 April 2023; pp. 1–6. [Google Scholar]
- Naikwadi, M.H.; Patil, K.P. A Survey of Artificial Neural Network based Spectrum Inference for Occupancy Prediction in Cognitive Radio Networks. In Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI)(48184), Tirunelveli, India, 15–17 June 2020; pp. 903–908. [Google Scholar]
- Ge, C.; Wang, Z.; Zhang, X. Robust long-term spectrum prediction with missing values and sparse anomalies. IEEE Access 2019, 7, 16655–16664. [Google Scholar] [CrossRef]
- Sun, J.; Wang, J.; Ding, G.; Shen, L.; Yang, J.; Wu, Q.; Yu, L. Long-term spectrum state prediction: An image inference perspective. IEEE Access 2018, 6, 43489–43498. [Google Scholar] [CrossRef]
- M, S.; G, S.M. Study of Spectrum Prediction Techniques in Cognitive Radio Networks. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; Volume 1, pp. 467–471. [Google Scholar]
- Nandakumar, R.; Ponnusamy, V.; Mishra, A.K. LSTM Based Spectrum Prediction for Real-Time Spectrum Access for IoT Applications. Intell. Autom. Soft Comput. 2023, 35, 2805–2819. [Google Scholar] [CrossRef]
- Yu, L.; Chen, J.; Ding, G.; Tu, Y.; Yang, J.; Sun, J. Spectrum prediction based on Taguchi method in deep learning with long short-term memory. IEEE Access 2018, 6, 45923–45933. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Q.; Yu, X. Research on Spectrum Prediction Technology Based on B-LTF. Electronics 2023, 12, 247. [Google Scholar] [CrossRef]
- Aygül, M.A.; Nazzal, M.; Sağlam, M.İ.; da Costa, D.B.; Ateş, H.F.; Arslan, H. Efficient spectrum occupancy prediction exploiting multidimensional correlations through composite 2D-LSTM models. Sensors 2020, 21, 135. [Google Scholar] [CrossRef] [PubMed]
- Aygül, M.A.; Nazzal, M.; Ekti, A.R.; Görçin, A.; da Costa, D.B.; Ateş, H.F.; Arslan, H. Spectrum occupancy prediction exploiting time and frequency correlations through 2D-LSTM. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Yu, L.; Guo, Y.; Wang, Q.; Luo, C.; Li, M.; Liao, W.; Li, P. Spectrum availability prediction for cognitive radio communications: A DCG approach. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 476–485. [Google Scholar] [CrossRef]
- Shawel, B.S.; Woldegebreal, D.H.; Pollin, S. Convolutional LSTM-based long-term spectrum prediction for dynamic spectrum access. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Ding, X.; Feng, L.; Zou, Y.; Zhang, G. Deep learning aided spectrum prediction for satellite communication systems. IEEE Trans. Veh. Technol. 2020, 69, 16314–16319. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, Q.; Han, Y. Multi channel spectrum prediction algorithm based on GCN and LSTM. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–5. [Google Scholar]
- Zhang, X.; Guo, L.; Ben, C.; Peng, Y.; Wang, Y.; Shi, S.; Lin, Y.; Gui, G. A-GCRNN: Attention Graph Convolution Recurrent Neural Network for Multi-Band Spectrum Prediction. IEEE Trans. Veh. Technol. 2024, 73, 2978–2982. [Google Scholar] [CrossRef]
- Yu, L.; Chen, J.; Zhang, Y.; Zhou, H.; Sun, J. Deep spectrum prediction in high frequency communication based on temporal-spectral residual network. China Commun. 2018, 15, 25–34. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, L.T.; Yang, J.; Wang, H.; Zhao, Y. Attention U-Net Based on Bi-ConvLSTM and Its Optimization for Smart Healthcare. IEEE Trans. Comput. Soc. Syst. 2023, 10, 1966–1974. [Google Scholar] [CrossRef]
- Zuo, P.; Peng, T.; Wang, X.; You, K.; Jing, H.; Guo, W.; Wang, W. Spectrum prediction for frequency bands with high burstiness: Analysis and method. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–7. [Google Scholar]
- Wellens, M. Empirical Modelling of Spectrum Use and Evaluation of Adaptive Spectrum Sensing in Dynamic Spectrum Access Networks. Ph.D. Thesis, RWTH Aachen University, Aachen, Germany, 2010. [Google Scholar]
- Tusha, A.; Kaplan, B.; Cırpan, H.A.; Qaraqe, K.; Arslan, H. Intelligent Spectrum Occupancy Prediction for Realistic Measurements: GRU based Approach. In Proceedings of the 2022 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Sofia, Bulgaria, 6–9 June 2022; pp. 179–184. [Google Scholar]
- Ben, C.; Peng, Y.; Zhang, X.; Wang, Y.; Guo, L.; Lin, Y.; Gui, G. Multi-Band Spectrum Prediction Method via Singular Spectrum Analysis and A-BiLSTM. In Proceedings of the 2023 IEEE 23rd International Conference on Communication Technology (ICCT), Wuxi, China, 20–22 October 2023; pp. 645–650. [Google Scholar]
- Ren, X.; Mosavat-Jahromi, H.; Cai, L.; Kidston, D. Spatio-Temporal Spectrum Load Prediction Using Convolutional Neural Network and ResNet. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 502–513. [Google Scholar] [CrossRef]
- Li, L.; Xie, W.; Zhou, X. Cooperative Spectrum Sensing Based on LSTM-CNN Combination Network in Cognitive Radio System. IEEE Access 2023, 11, 87615–87625. [Google Scholar] [CrossRef]
- Yilihamu, D.; Ablimit, M.; Hamdulla, A. Speech Language Identification Using CNN-BiLSTM with Attention Mechanism. In Proceedings of the 2022 3rd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 22–24 July 2022; pp. 308–314. [Google Scholar]
- Anneswa, G.; Sneha, K.; Jacobus, V.D.M. Spectrum Usage Analysis And Prediction using Long Short-Term Memory Networks. In Proceedings of the 24th International Conference on Distributed Computing and Networking, Kharagpur, India, 4–7 January 2023; pp. 270–279. [Google Scholar]
- Cui, Y.; Yin, B.; Li, R.; Du, Z.; Ding, M. Short-time Series Load Forecasting By Seq2seq-LSTM Model. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 517–521. [Google Scholar]
- Ke, X.; Guoqiang, Z.; Zhaoyang, D.; Kang, Z.; Kaizhu, H. Self-supervised Generative Learning for Sequential Data Prediction. Appl. Intell. 2023, 53, 20675–20689. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAE | MAPE | RMSE | |
|---|---|---|---|---|
| LSTM | 0.8982 | 8.23% | 1.6512 | 0.8223 |
| BiLSTM | 0.8796 | 8.07% | 1.5728 | 0.8473 |
| GRU | 0.8847 | 8.17% | 1.5851 | 0.8398 |
| CNN | 0.8679 | 7.93% | 1.5695 | 0.8491 |
| CNN-LSTM | 0.8533 | 7.67% | 1.5588 | 0.8587 |
| CNN-BiLSTM | 0.8498 | 7.45% | 1.5537 | 0.8619 |
| CNN-BiLSTM-attention | 0.8345 | 7.25% | 1.4218 | 0.9065 |
| Seq2seq-LSTM | 0.8556 | 7.47% | 1.5618 | 0.8578 |
| Seq2seq-LSTM-attention | 0.8436 | 7.36% | 1.5465 | 0.8783 |
| Seq2seq-Bi-ConvLSTM | 0.8064 | 6.64% | 1.2355 | 0.9362 |
| Seq2seq-Bi-ConvLSTM-attention | 0.7749 | 6.15% | 1.0978 | 0.9628 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Hu, J.; Jiang, R.; Chen, Z. A Deep Long-Term Joint Temporal–Spectral Network for Spectrum Prediction. Sensors 2024, 24, 1498. https://doi.org/10.3390/s24051498
Wang L, Hu J, Jiang R, Chen Z. A Deep Long-Term Joint Temporal–Spectral Network for Spectrum Prediction. Sensors. 2024; 24(5):1498. https://doi.org/10.3390/s24051498
Chicago/Turabian StyleWang, Lei, Jun Hu, Rundong Jiang, and Zengping Chen. 2024. "A Deep Long-Term Joint Temporal–Spectral Network for Spectrum Prediction" Sensors 24, no. 5: 1498. https://doi.org/10.3390/s24051498
APA StyleWang, L., Hu, J., Jiang, R., & Chen, Z. (2024). A Deep Long-Term Joint Temporal–Spectral Network for Spectrum Prediction. Sensors, 24(5), 1498. https://doi.org/10.3390/s24051498