1. Introduction
State estimation is crucial for unmanned mobile platforms, especially when operating in GPS-denied areas. Simultaneous localization and mapping (SLAM) algorithms have the ability to provide real-time pose estimation and build consistent maps; thus, it is a crucial technique for robots, self-driving cars and augmented reality (AR) devices [
1]. Pure visual SLAM algorithms [
2,
3,
4], which use cameras as the sole sensor, are lightweight, low-cost, and have gained popularity over the past decade. However, they lack strong robustness because of sensitivity to illumination change and motion blur.
Many researchers have found that combining a camera with an inertial measurement unit (IMU) offers complementary advantages [
5]. IMUs output high-frequency and biased inertial measurements while cameras produce images with rich information. Based on this, numerous visual–inertial odometry and SLAM systems are designed to obtain accurate and robust pose estimation. According to the estimation strategy, they can be divided into two categories: optimization-based methods and filter-based methods. The former constructs a factor graph with visual re-projection errors and IMU pre-integration errors to optimize poses and feature landmarks such as OKVIS [
6] and VINS-Mono [
7]. The computational load is managed using a sliding window and marginalization to achieve real-time performance. The latter holds a state vector which consists of body states (position, speed, orientation, and inertial biases) and a fixed number of history poses such as MSCKF [
8] and HybVIO [
9]. State propagation is finished on the basis of IMU kinematic model and visual update provides multi-frame constraints to produce an accurate trajectory. However, the aforementioned algorithms rely solely on points for visual constraints, which can lead to divergence or failure in low-texture environments.
As line features are abundant in human-made worlds, more and more VIO frameworks fuse both points and lines to improve their performance. PL-VIO [
10] is the first optimization-based point–line visual–inertial odometry framework. Points, lines and IMU pre-integration terms are integrated into the optimization window to recover trajectories and scene appearances. Hence, it can outperform its predecessor VINS-Mono in some large difficult environments with severe sacrifice of running time. To speed up the processing of line features, the effect of the hidden parameters in the LSD algorithm [
11] was studied in PL-VINS [
12]. The authors modified a proper set of parameters to balance the speed and quality of line feature extraction in the original LSD for pose estimation tasks. In this way, PL-VINS is capable of outputting estimated poses in real-time. FPL-VIO [
13] applied two methods to make the front end lightweight. It uses a fast line detection algorithm FLD [
14] instead of LSD to extract line features and BRIEF descriptors [
15] of midpoints to perform line matching, which greatly reduces the running time of the front end. The authors in [
16] presented a similar solution, choosing EDlines [
17] with gamma correction for rapid detection of long line features. They tracked a certain number of points on the line, instead of the entire segment, using the sparse KLT algorithm for line matching. As a result, the consumed time of line features in the front end is declined. However, the back end of these optimization-based methods is still a heavy module because of the repeated linearization of visual and inertial error terms, which becomes worse after fusing both point and line features [
10].
Since filter-based methods avoid the re-linearization, they are considered to be more efficient [
5]. Trifo-VIO [
18] is a stereo point–line VIO algorithm based on MSCKF. After state propagation, both point and line features are used for visual update. However, the line features are parameterized using a 3D point and a normal vector in this system, which is an over-parameterized representation because a space line has only four degrees of freedom. Another MSCKF with lines framework is proposed in [
19]. This system adopts the closest point method to represent line features and shows a good performance in real-world experiments. However, its front end uses LBD [
20] to match line features; thus, its real-time performance is severely limited. A hybrid point–line MSCKF algorithm is proposed in [
21]. Based on the sparse KLT algorithm, it tracks sampled points on the line between three consecutive frames in a predicting–matching way; thus, a new line can be recovered if the original one is lost. However, extra memories and operations are required in the hybrid framework since line feature landmarks are preserved in the state vector.
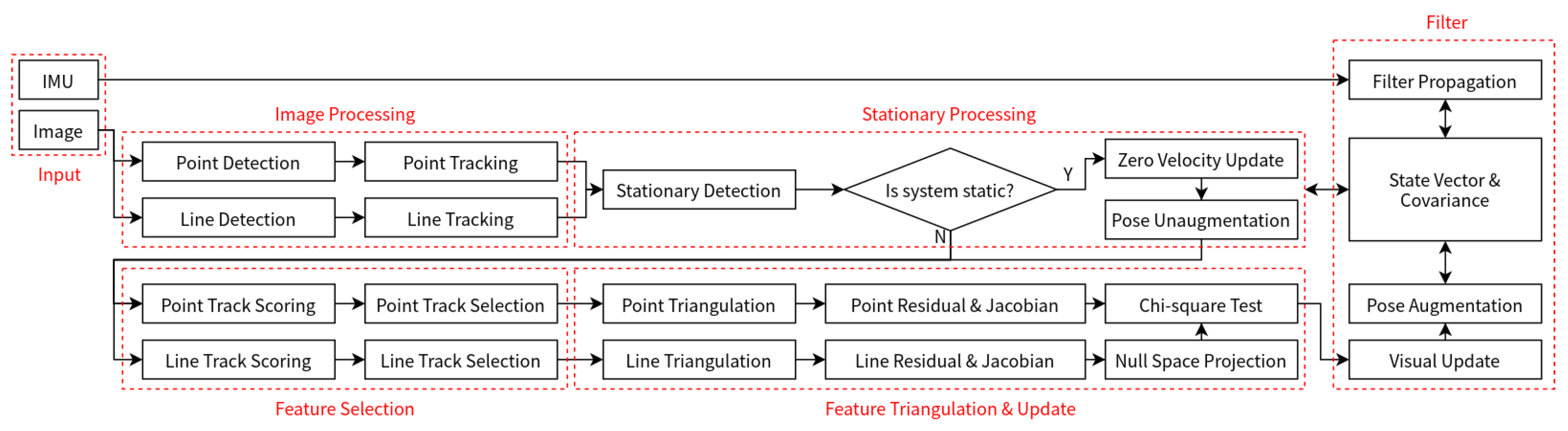
Most SLAM and odometry algorithms run on small-sized devices with limited available resources. How to provide accurate and high-frequency pose estimation with low computational consumption for multiple feature frameworks is still an open problem. To solve this, we propose a novel lightweight point–line visual–inertial odometry algorithm which can robustly track the poses of moving platforms. The main contributions of this paper are as follows:
A novel filter-based point–line VIO framework with a unique feature selection scheme is proposed to produce high-frequency and accurate pose estimation results. The whole system is fast, robust, and accurate to work in complex environments such as weak texture and motion blur.
A fast line matching method is proposed in order to decline the running time of the front end. The lines are matched using an endpoint–midpoint tracking way and a complete prediction–tracking–rejection scheme, which can ensure the matching quality with a fast speed.
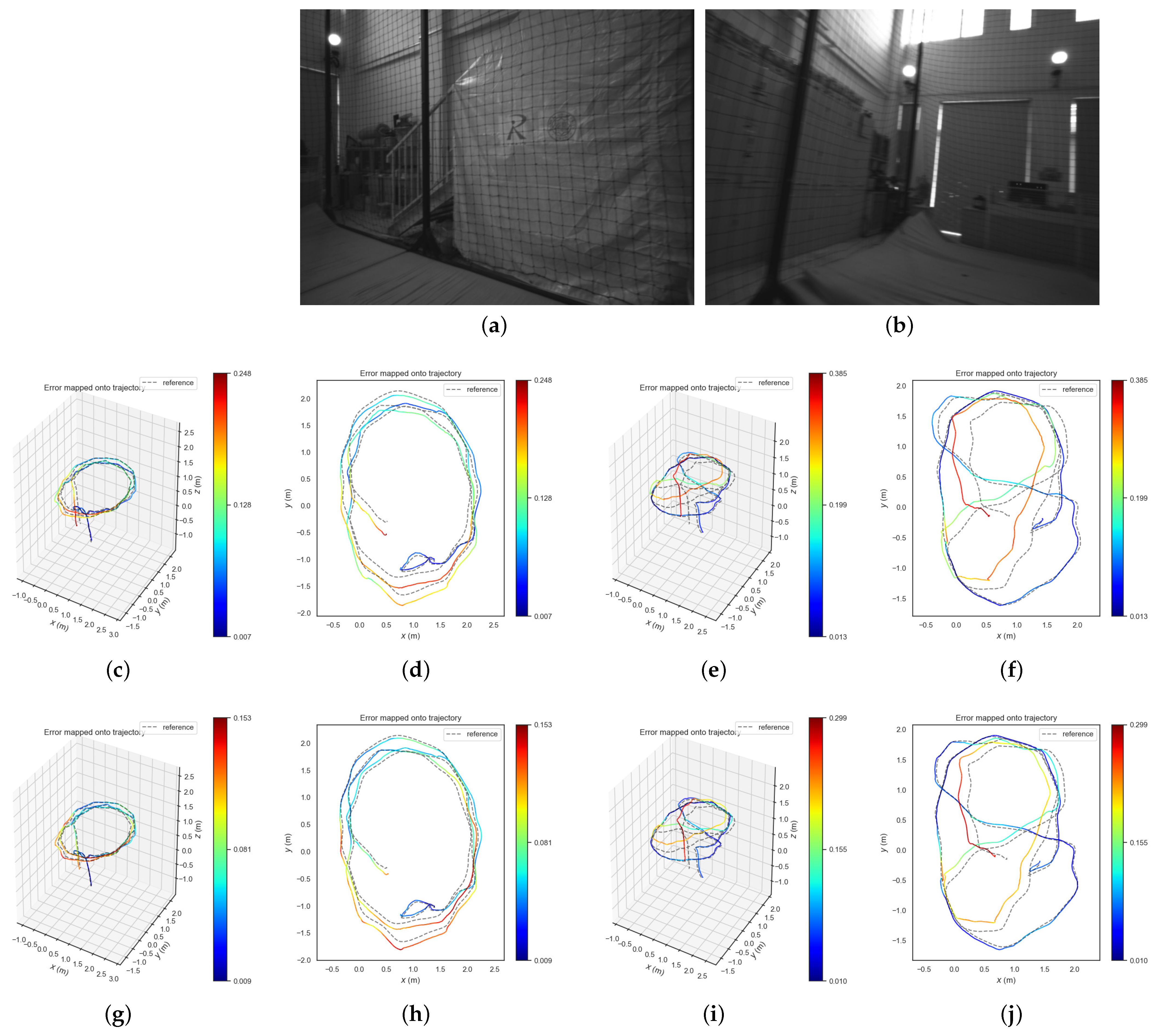
Validation experiments on public datasets and in real-world tests are conducted to evaluate the proposed LRPL-VIO. The results prove the better performance of LRPL-VIO compared with other state-of-the-art systems (HybVIO [
9], VINS-Mono [
7], PL-VIO [
10], and PL-VINS [
12]), especially in terms of speed and robustness.
The rest of this paper is organized as follows.
Section 2 describes our filter-based point–line VIO system. The proposed fast line matching method is detailed in
Section 3. The experiment results are explained and presented in
Section 4. Finally, conclusion and future works are discussed in
Section 5.
3. Fast Line Matching
The complex pixel distribution of line features makes their matching more challenging and time-consuming compared to point features. In this section, we propose a novel fast line matching method to break this bottleneck. An overview of our method is shown in Algorithm 1 and details are explained below.
| Algorithm 1 Fast Line Matching |
- Require:
, , , , - Ensure:
- 1:
- 2:
for
do - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
end for - 9:
- 10:
- 11:
returnL2
|
Extraction: For each line feature, tracking is focused on its two endpoints and midpoint, rather than the entire line or other sampled points. In other words, for n line features, we have points in total.
Prediction: To counteract aggressive motions, inertial measurements between two camera frames are used to determine the initial positions of the points for tracking. Specifically, for two consecutive frames,
and
, a point transformation between them is:
where
and
are pixel coordinates of the same point in these frames.
and
are the corresponding depth measurements.
is the intrinsic matrix which is considered as a static variable. The pose between
and
is represented by
and
. By taking the assumption that the translation
between two consecutive frames is small enough to be ignored,
and
can be removed from Equation (
28). Thus, a simplified version is:
We obtain the rotation
through gyroscope measurements integration and then the predicted positions of the points using Equation (
29).
Tracking: After the above stages, the line matching task becomes the tracking of the points, which is finished based on the photometric invariance assumption in LRPL-VIO. Take a single line endpoint as an example. With its original pixel coordinate
in
, our idea is to find the target pixel coordinate
in
to satisfy Equation (
30):
where
is the photometric value of the pixel
in
. Apparently we can not obtain
using one equation; thus, another assumption that the movements of all pixels in a local window are the same is applied. That is, we have
for all
w pixels in the window. To solve Equation (
31), a nonlinear optimization problem is constructed:
where
Equation (
32) is a typical least squares problem and can be solved in an iterative way with the initial values provided by Equation (
29). In addition, the image pyramids are introduced to improve the tracking quality.
Outlier Rejection: As long as the points of a line feature are tracked, we first check the average photometric values of two endpoints. In other words, an endpoint track is considered as an inlier if
where
is the threshold. However, Equation (
34) is not enough to reject outliers when there is a large repeated texture area in the image. For this reason, an angle variation check is also performed if both two endpoints passed Equation (
34). Namely, if a line matching pair
meets
where
and
are the angles of the line in consecutive frames,
is seen as a candidate line.
Generally, endpoints have the potential to move out of view or be tracked unsuccessfully. Hence, after obtaining the first batch of candidate lines by checking endpoints, we take tracked midpoints as new endpoints of the line features which failed to pass the above tests. For example, if
is not an acceptable tracking result, it will be replaced by
or
. Certainly, the replaced line pairs have to satisfy both Equations (
34) and (
35). This scheme is able to improve the tracking length of line features with no additional sampled points. Finally, an 8-point RANSAC is performed to further reject outliers in these candidates.
Matching: After all this, we build matched line features through connecting the reserved endpoints and remove short ones which are useless for pose estimation.





{kind=link}
{kind=link}
{kind=link}