
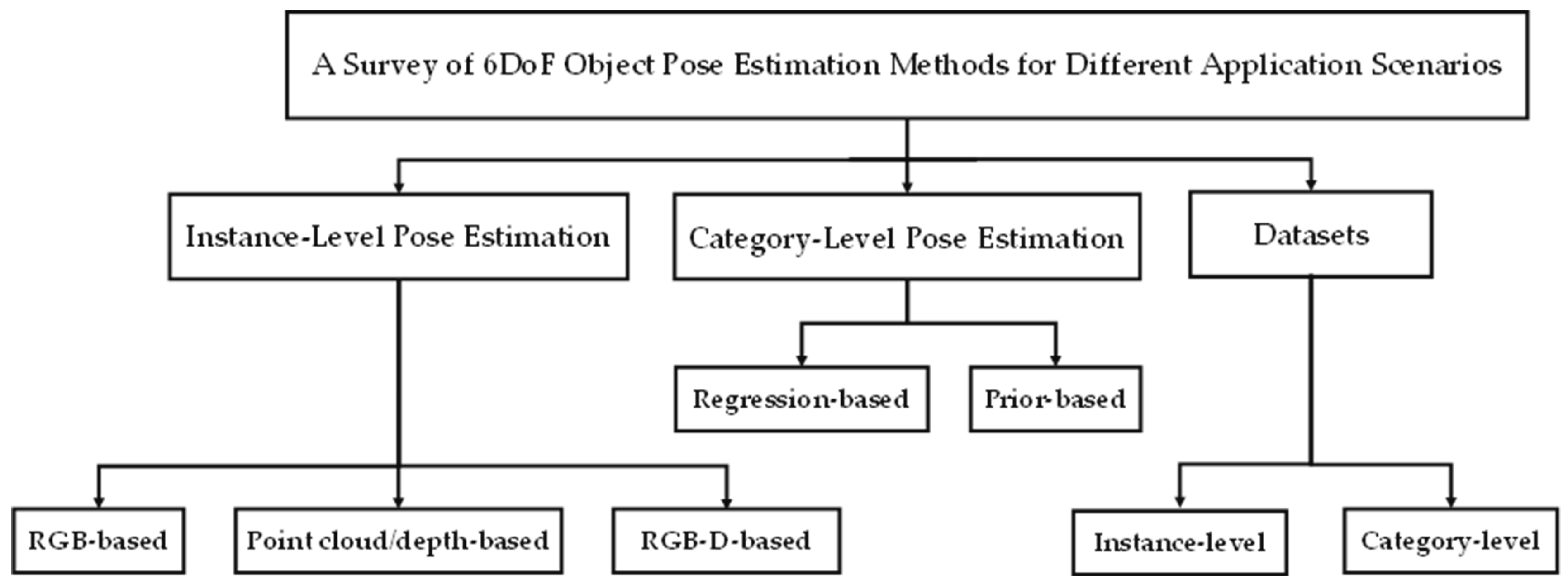
A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios

 ,
,
Abstract
1. Introduction
2. Instance-Level 6DoF Object Pose Estimation
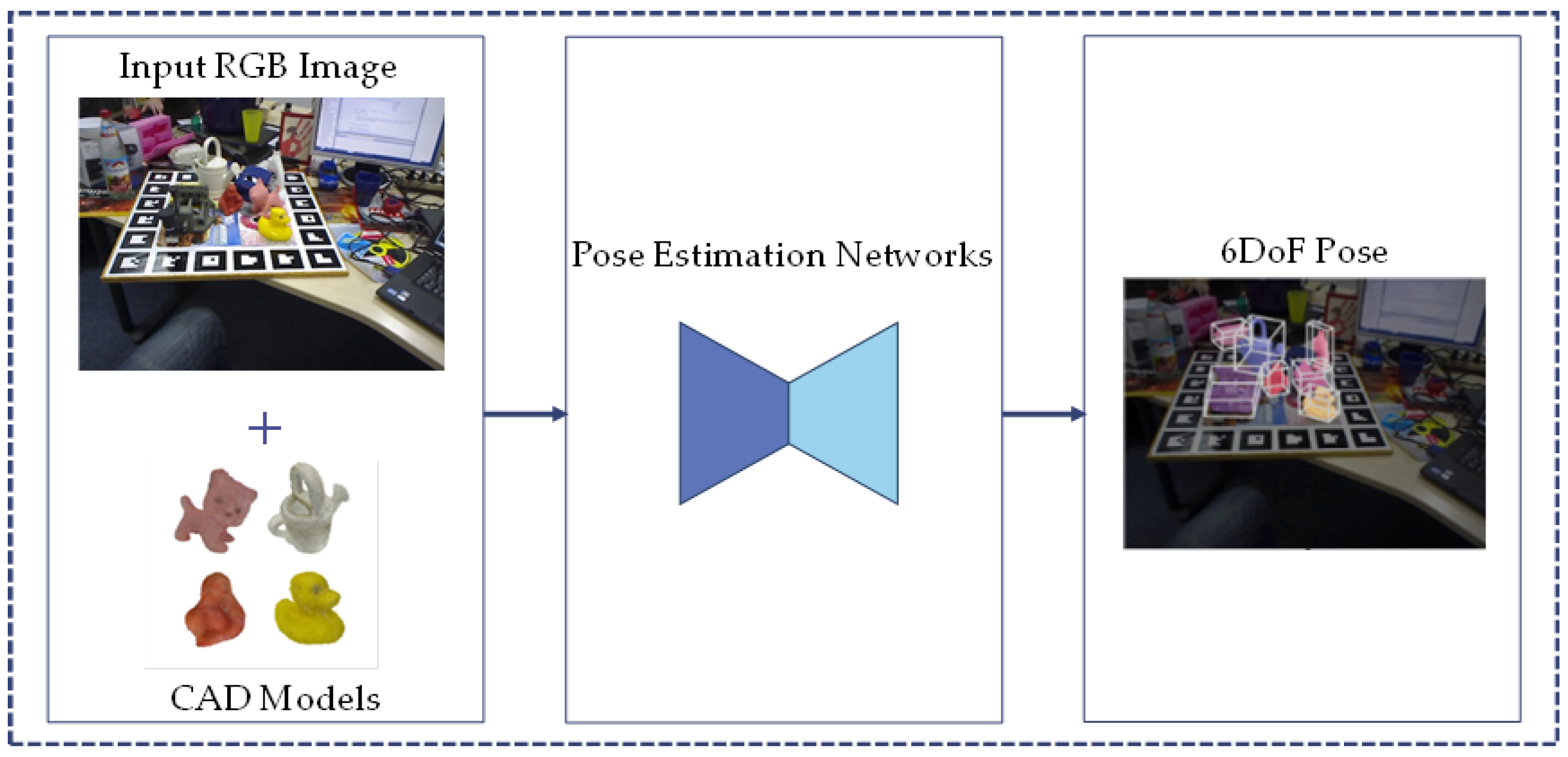
2.1. RGB-Based Methods
2.1.1. Regression-Based Methods
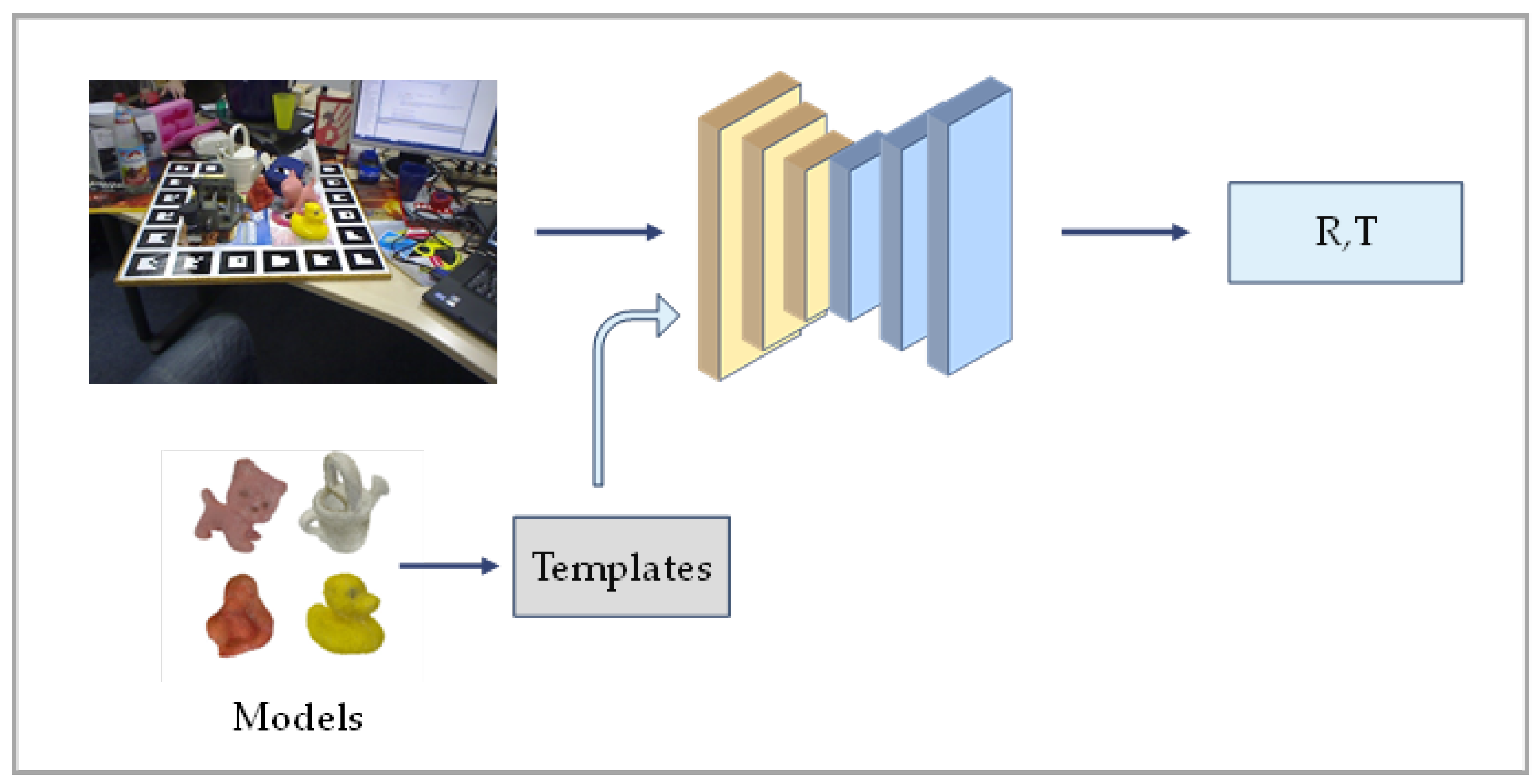
2.1.2. Template-Based Methods
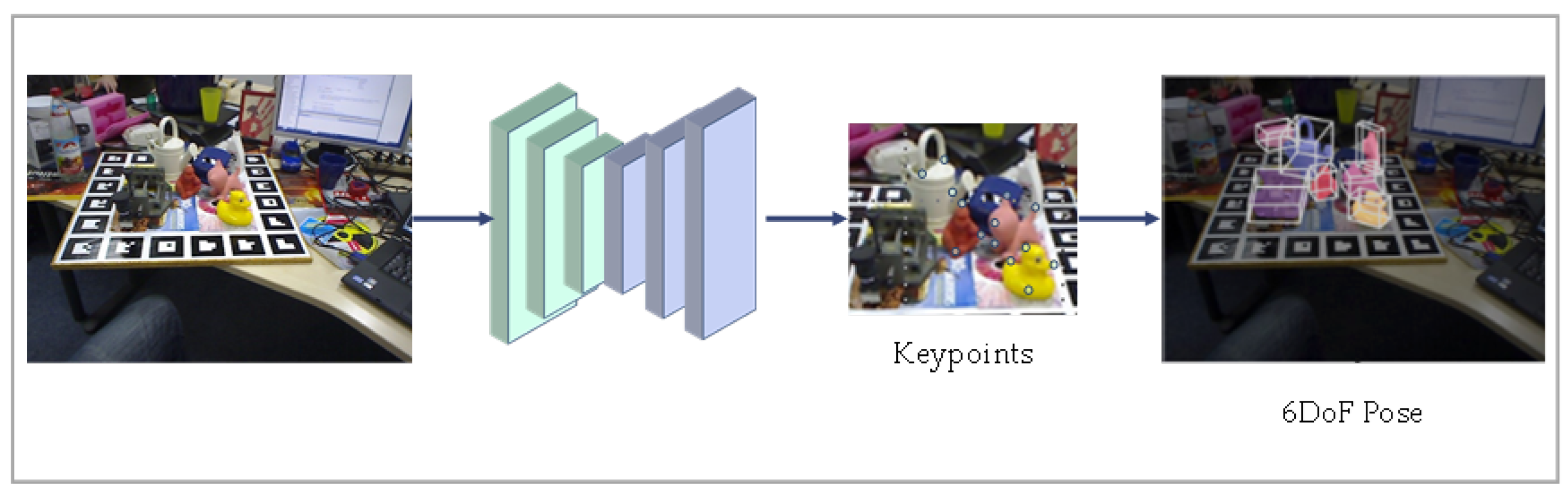
2.1.3. Feature-Based Methods
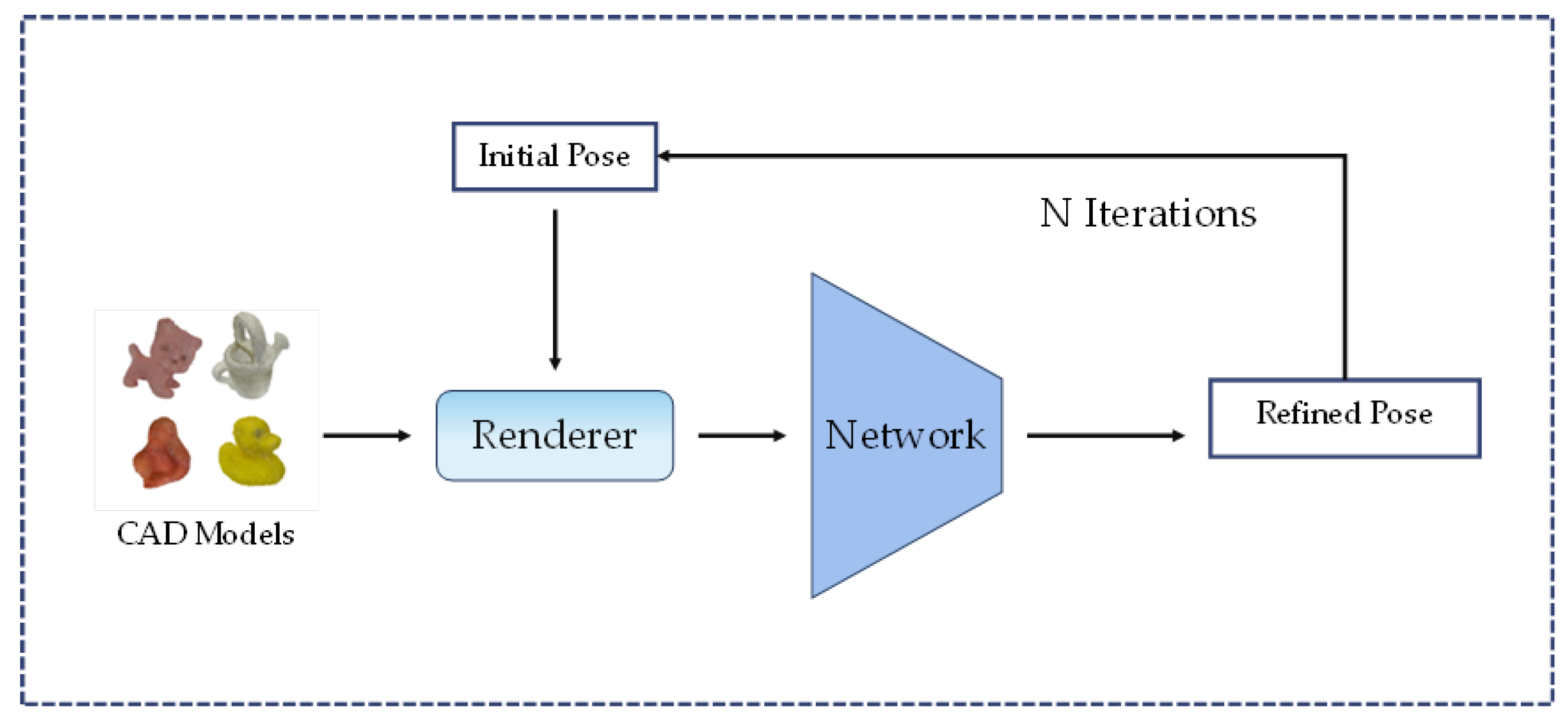
2.1.4. Refinement Methods
2.2. Point Cloud or Depth-Based Methods
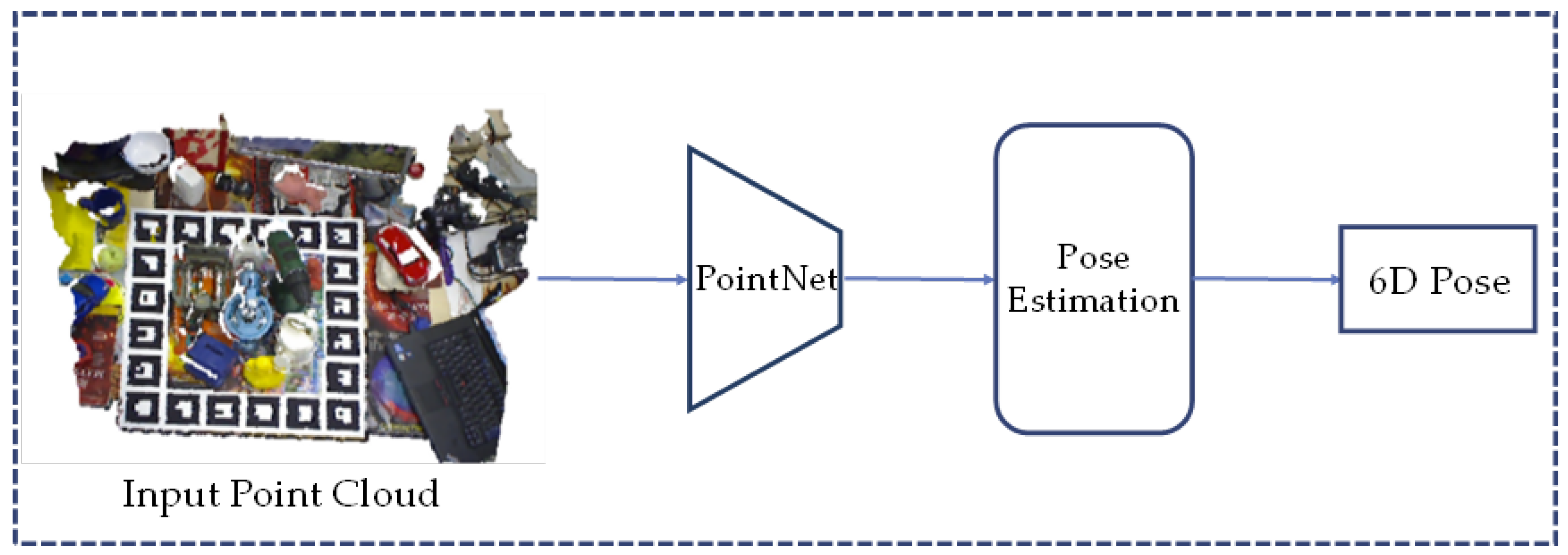
2.2.1. Point Cloud-Based Methods
2.2.2. Depth-Based Methods
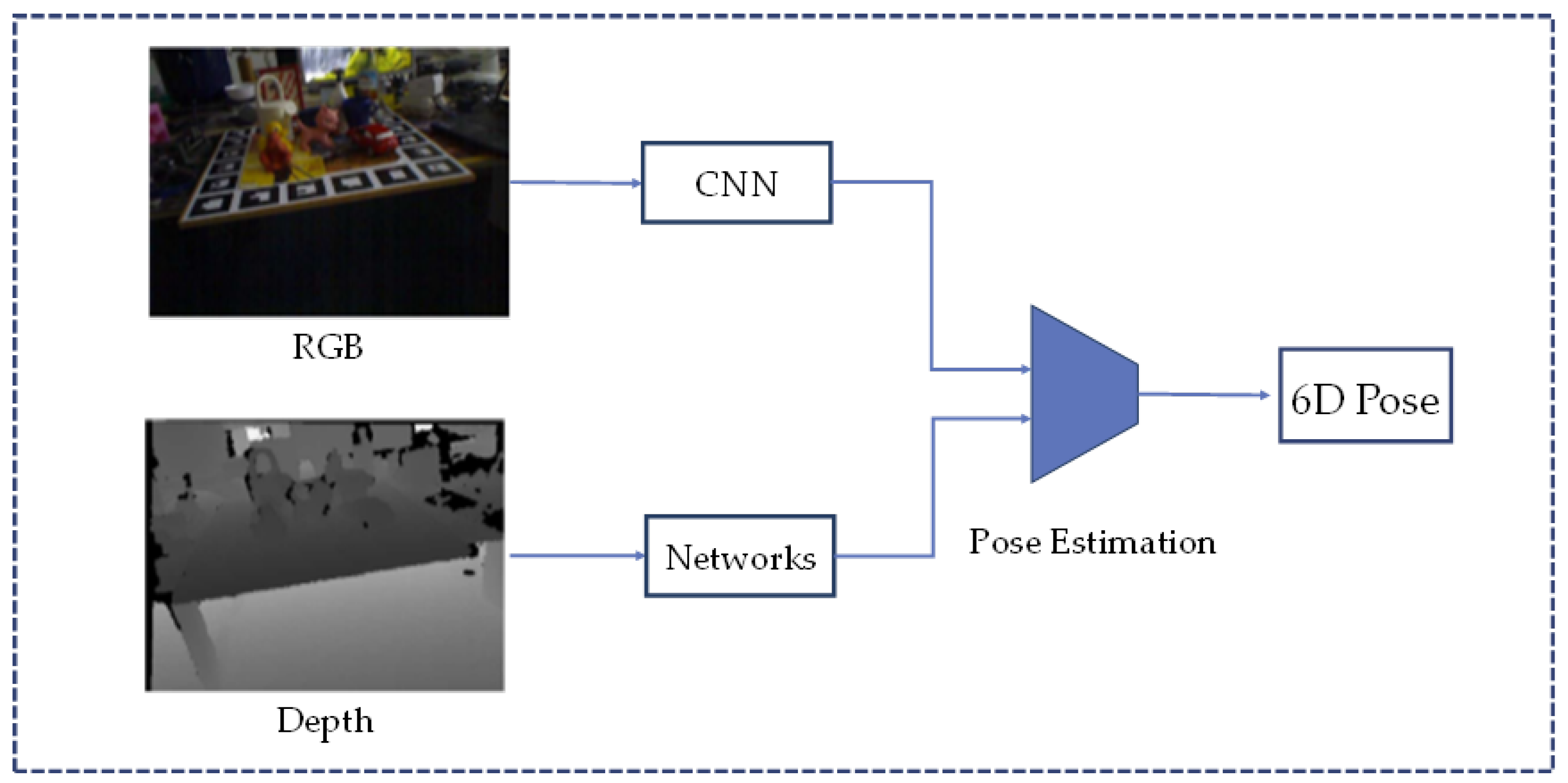
2.3. RGB-D-Based Methods
2.3.1. Fusion-Based Methods
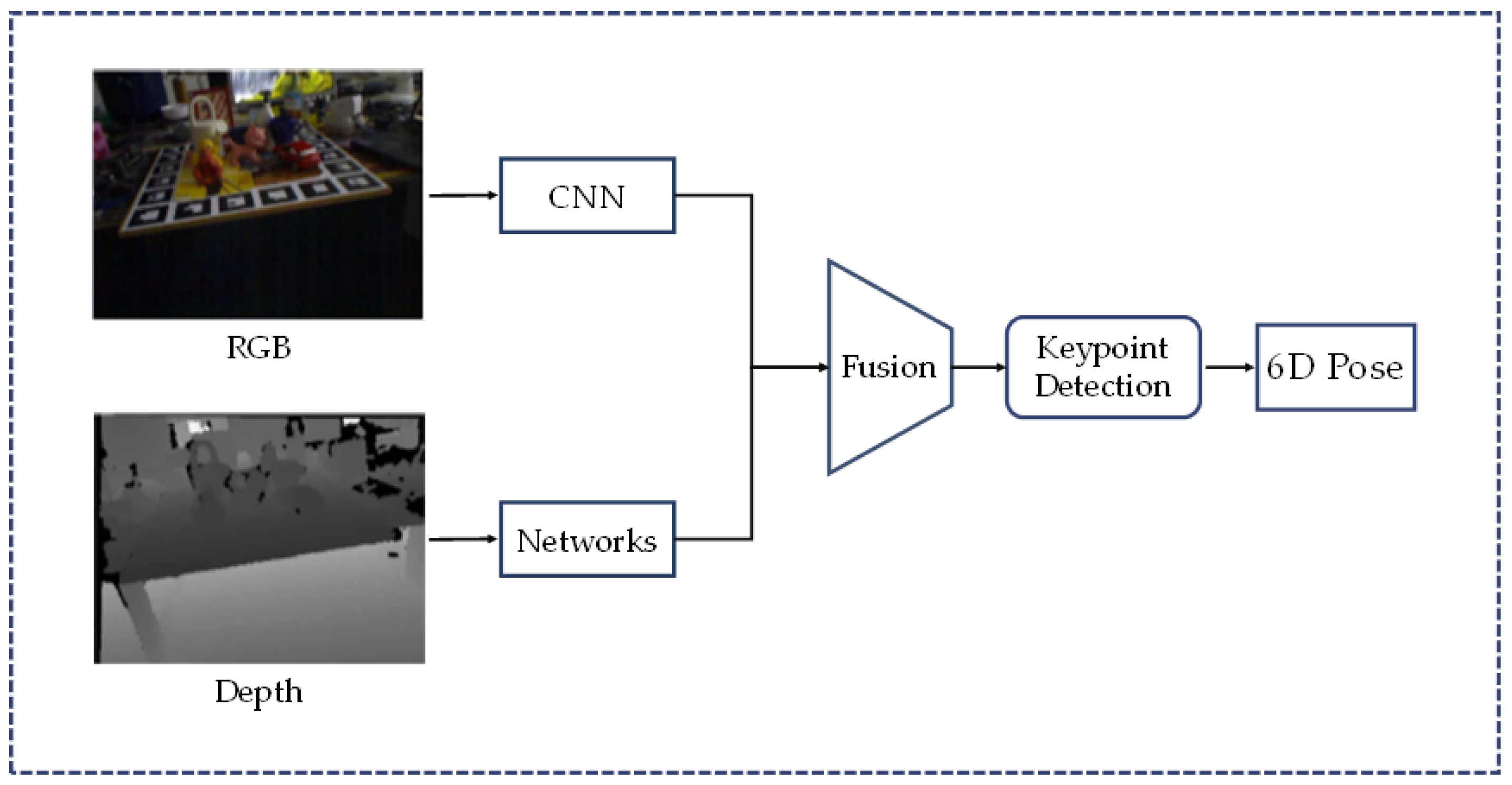
2.3.2. Keypoints-Based Methods
2.3.3. Other Methods
3. Category-Level 6DoF Object Pose Estimation
3.1. Regression-Based Methods
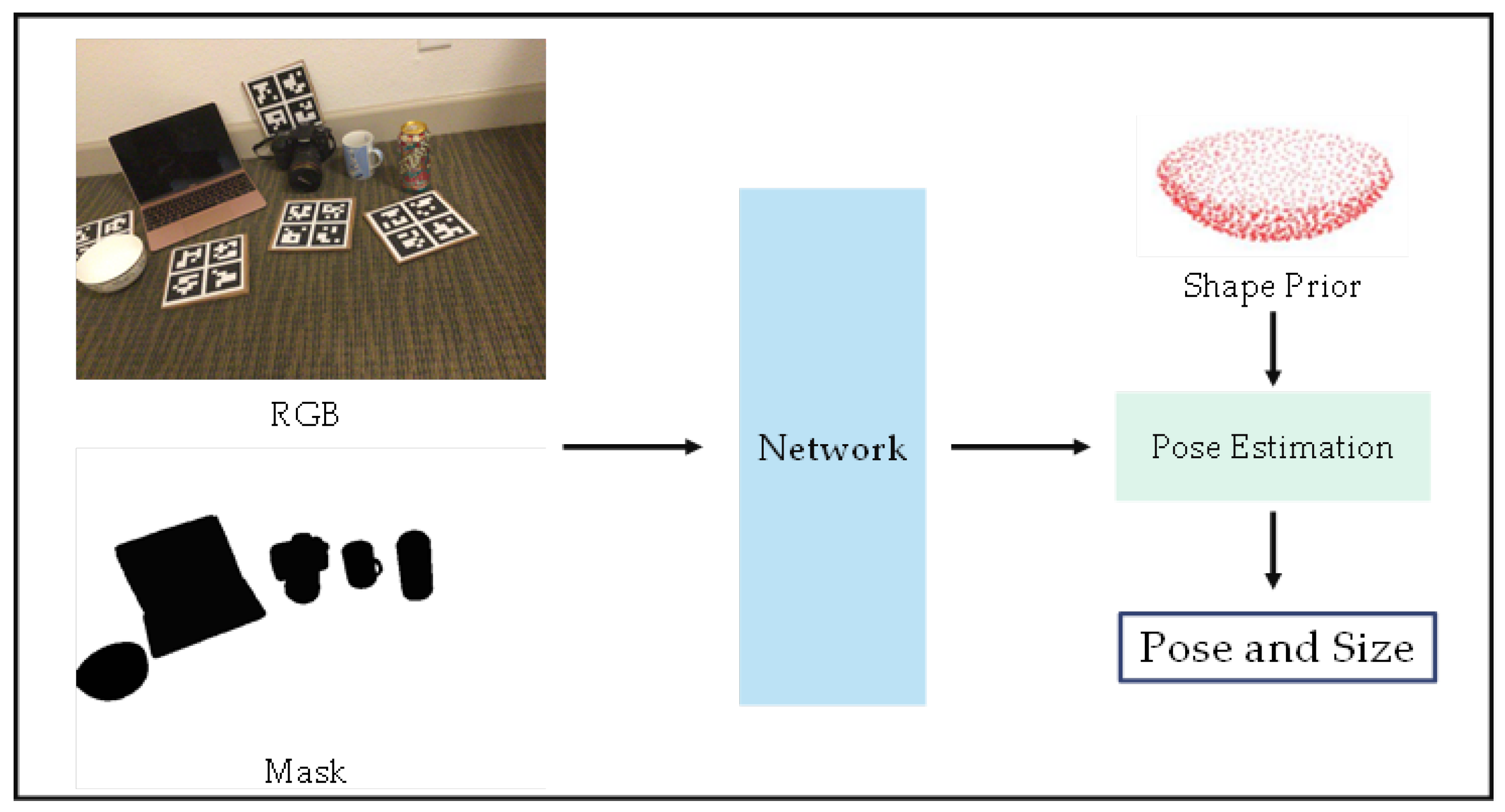
3.2. Prior-Based Methods
3.3. Other Methods
4. Datasets and Metrics
4.1. Datasets
4.2. Metrics
5. Analysis and Possible Future Directions
5.1. Analysis of Task
5.2. Challenges and Possible Future Directions
5.3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Bai, H.; Song, G.; Zhao, Y.; Han, J. Augmented reality system training for minimally invasive spine surgery. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, China, 5–8 December 2017; pp. 1200–1205. [Google Scholar]
- Kalia, M.; Navab, N.; Salcudean, T. A real-time interactive augmented reality depth estimation technique for surgical robotics. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8291–8297. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3D object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Fan, Z.; Zhu, Y.; He, Y.; Sun, Q.; Liu, H.; He, J. Deep learning on monocular object pose detection and tracking: A comprehensive overview. ACM Comput. Surv. 2022, 55, 1–40. [Google Scholar] [CrossRef]
- Wada, K.; Sucar, E.; James, S.; Lenton, D.; Davison, A.J. Morefusion: Multi-object reasoning for 6D pose estimation from volumetric fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14540–14549. [Google Scholar]
- Du, G.; Wang, K.; Lian, S.; Zhao, K. Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: A review. Artif. Intell. Rev. 2021, 54, 1677–1734. [Google Scholar] [CrossRef]
- Pérez, L.; Rodríguez, Í.; Rodríguez, N.; Usamentiaga, R.; García, D.F. Robot guidance using machine vision techniques in industrial environments: A comparative review. Sensors 2016, 16, 335. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Wang, Z.; Zhang, S.; He, X.; Zhao, H.; Zhang, G.; Zhou, X. Onepose: One-shot object pose estimation without cad models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6825–6834. [Google Scholar]
- Cui, Y.; Chen, X.; Zhang, Y.; Dong, J.; Wu, Q.; Zhu, F. Bow3D: Bag of words for real-time loop closing in 3D lidar slam. IEEE Robot. Autom. Lett. 2022, 8, 2828–2835. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3D bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 880–888. [Google Scholar]
- Drost, B.; Ulrich, M.; Bergmann, P.; Hartinger, P.; Steger, C. Introducing mvtec itodd-a dataset for 3D object recognition in industry. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2200–2208. [Google Scholar]
- Zhu, Y.; Li, M.; Yao, W.; Chen, C. A review of 6D object pose estimation. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; Volume 10, pp. 1647–1655. [Google Scholar]
- Wang, G.; Manhardt, F.; Tombari, F.; Ji, X. Gdr-net: Geometry-guided direct regression network for monocular 6D object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16611–16621. [Google Scholar]
- Haugaard, R.L.; Buch, A.G. Surfemb: Dense and continuous correspondence distributions for object pose estimation with learnt surface embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6749–6758. [Google Scholar]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. Fs-net: A flow sequence network for encrypted traffic classification. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Marullo, G.; Tanzi, L.; Piazzolla, P.; Vezzetti, E. 6D object position estimation from 2D images: A literature review. Multimed. Tools Appl. 2023, 82, 24605–24643. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6D object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Besl, P.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Do, T.T.; Cai, M.; Pham, T.; Reid, I. Deep-6Dpose: Recovering 6D object pose from a single rgb image. arXiv 2018, arXiv:1802.10367. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Hu, Y.; Hugonot, J.; Fua, P.; Salzmann, M. Segmentation-driven 6D object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3385–3394. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-time seamless single shot 6D object pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 292–301. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T.Y. inerf: Inverting neural radiance fields for pose estimation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1323–1330. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. Deepim: Deep iterative matching for 6D pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 683–698. [Google Scholar]
- Labbé, Y.; Carpentier, J.; Aubry, M.; Sivic, J. Cosypose: Consistent multi-view multi-object 6D pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 574–591. [Google Scholar]
- Hodan, T.; Michel, F.; Brachmann, E.; Kehl, W.; GlentBuch, A.; Kraft, D.; Drost, B.; Vidal, J.; Ihrke, S.; Zabulis, X.; et al. Bop: Benchmark for 6D object pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Su, Y.; Saleh, M.; Fetzer, T.; Rambach, J.; Navab, N.; Busam, B.; Stricker, D.; Tombari, F. Zebrapose: Coarse to fine surface encoding for 6Dof object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6738–6748. [Google Scholar]
- Hai, Y.; Song, R.; Li, J.; Ferstl, D.; Hu, Y. Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 14075–14085. [Google Scholar]
- Wang, G.; Manhardt, F.; Liu, X.; Ji, X.; Tombari, F. Occlusion-aware self-supervised monocular 6D object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Wang, G.; Manhardt, F.; Shao, J.; Ji, X.; Navab, N.; Tombari, F. Self6D: Self-supervised monocular 6D object pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 108–125. [Google Scholar]
- Sock, J.; Garcia-Hernando, G.; Armagan, A.; Kim, T.K. Introducing pose consistency and warp-alignment for self-supervised 6D object pose estimation in color images. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 291–300. [Google Scholar]
- Bukschat, Y.; Vetter, M. EfficientPose: An efficient, accurate and scalable end-to-end 6D multi object pose estimation approach. arXiv 2020, arXiv:2011.04307. [Google Scholar]
- Sundermeyer, M.; Hodaň, T.; Labbe, Y.; Wang, G.; Brachmann, E.; Drost, B.; Rother, C.; Matas, J. Bop challenge 2022 on detection, segmentation and pose estimation of specific rigid objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2784–2793. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. Ssd-6D: Making rgb-based 3D detection and 6D pose estimation great again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1521–1529. [Google Scholar]
- Park, K.; Mousavian, A.; Xiang, Y.; Fox, D. Latentfusion: End-to-end differentiable reconstruction and rendering for unseen object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10710–10719. [Google Scholar]
- Zakharov, S.; Shugurov, I.; Ilic, S. Dpod: 6D Pose object detector and refiner. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1941–1950. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. Pvnet: Pixel-wise voting network for 6Dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4561–4570. [Google Scholar]
- Deng, X.; Mousavian, A.; Xiang, Y.; Xia, F.; Bretl, T.; Fox, D. PoseRBPF: A Rao–Blackwellized particle filter for 6-D object pose tracking. IEEE Trans. Robot. 2021, 37, 1328–1342. [Google Scholar] [CrossRef]
- Shugurov, I.; Li, F.; Busam, B.; Ilic, S. Osop: A multi-stage one shot object pose estimation framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6835–6844. [Google Scholar]
- Nguyen, V.N.; Hu, Y.; Xiao, Y.; Salzmann, M.; Lepetit, V. Templates for 3D object pose estimation revisited: Generalization to new objects and robustness to occlusions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6771–6780. [Google Scholar]
- Balntas, V.; Doumanoglou, A.; Sahin, C.; Sock, J.; Kouskouridas, R.; Kim, T.K. Pose guided RGBD feature learning for 3D object pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3856–3864. [Google Scholar]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Marton, Z.C.; Pangercic, D.; Blodow, N.; Beetz, M. Combined 2D–3D categorization and classification for multimodal perception systems. Int. J. Robot. Res. 2011, 30, 1378–1402. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. LightGlue: Local Feature Matching at Light Speed. arXiv 2023, arXiv:2306.13643. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.G.; Daniilidis, K. 6-dof object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May 2017–3 June 2017; pp. 2011–2018. [Google Scholar]
- Rad, M.; Lepetit, V. Bb8: A scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3828–3836. [Google Scholar]
- Hu, Y.; Fua, P.; Salzmann, M. Perspective flow aggregation for data-limited 6D object pose estimation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 89–106. [Google Scholar]
- Hodan, T.; Barath, D.; Matas, J. Epos: Estimating 6D pose of objects with symmetries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11703–11712. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2pose: Pixel-wise coordinate regression of objects for 6D pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 7668–7677. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Xu, Y.; Lin, K.Y.; Zhang, G.; Wang, X.; Li, H. Rnnpose: Recurrent 6-dof object pose refinement with robust correspondence field estimation and pose optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14880–14890. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Song, C.; Song, J.; Huang, Q. Hybridpose: 6D Object pose estimation under hybrid representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 431–440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Castro, P.; Kim, T.K. Crt-6D: Fast 6D object pose estimation with cascaded refinement transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5746–5755. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EP n P: An accurate O (n) solution to the P n P problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Chen, H.; Tian, W.; Wang, P.; Wang, F.; Xiong, L.; Li, H. EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation. arXiv 2023, arXiv:2303.12787. [Google Scholar]
- Li, Z.; Wang, G.; Ji, X. Cdpn: Coordinates-based disentangled pose network for real-time rgb-based 6-dof object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7678–7687. [Google Scholar]
- Iwase, S.; Liu, X.; Khirodkar, R.; Yokota, R.; Kitani, K.M. Repose: Fast 6D object pose refinement via deep texture rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3303–3312. [Google Scholar]
- Sundermeyer, M.; Marton, Z.C.; Durner, M.; Brucker, M.; Triebel, R. Implicit 3D orientation learning for 6D object detection from rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 699–715. [Google Scholar]
- Manhardt, F.; Kehl, W.; Navab, N.; Tombari, F. Deep model-based 6D pose refinement in rgb. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 800–815. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes. In Proceedings of the Computer Vision–ACCV 2012: 11th Asian Conference on Computer Vision, Daejeon, Republic of Korea, 5–9 November 2012; Revised Selected Papers, Part I 11. Springer: Berlin/Heidelberg, Germany, 2013; pp. 548–562. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D object pose estimation using 3D object coordinates. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part II 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 536–551. [Google Scholar]
- Di, Y.; Manhardt, F.; Wang, G.; Ji, X.; Navab, N.; Tombari, F. So-pose: Exploiting self-occlusion for direct 6D pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12396–12405. [Google Scholar]
- Shugurov, I.; Zakharov, S.; Ilic, S. Dpodv2: Dense correspondence-based 6 dof pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7417–7435. [Google Scholar] [CrossRef] [PubMed]
- Dong, Z.; Liu, S.; Zhou, T.; Cheng, H.; Zeng, L.; Yu, X.; Liu, H. PPR-Net: Point-wise pose regression network for instance segmentation and 6D pose estimation in bin-picking scenarios. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1773–1780. [Google Scholar]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular depth estimation using deep learning: A review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Sun, Y.; Xu, S.; Pan, Y.; Peng, Y.; Mao, Z. Recent Advances and Perspectives in Deep Learning Techniques for 3D Point Cloud Data Processing. Robotics 2023, 12, 100. [Google Scholar] [CrossRef]
- Gao, G.; Lauri, M.; Hu, X.; Zhang, J.; Frintrop, S. Cloudaae: Learning 6D object pose regression with on-line data synthesis on point clouds. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11081–11087. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Choi, C.; Christensen, H.I. RGB-D object pose estimation in unstructured environments. Robot. Auton. Syst. 2016, 75, 595–613. [Google Scholar] [CrossRef]
- Liu, C.; Chen, F.; Deng, L.; Yi, R.; Zheng, L.; Zhu, C.; Wang, J.; Xu, K. 6DOF Pose Estimation of a 3D Rigid Object based on Edge-enhanced Point Pair Features. arXiv 2022, arXiv:2209.08266. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Hagelskjær, F.; Buch, A.G. Pointvotenet: Accurate object detection and 6 dof pose estimation in point clouds. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2641–2645. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Chen, W.; Duan, J.; Basevi, H.; Chang, H.J.; Leonardis, A. PointPoseNet: Point pose network for robust 6D object pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2824–2833. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppfnet: Global context aware local features for robust 3D point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 195–205. [Google Scholar]
- Hoang, D.C.; Stork, J.A.; Stoyanov, T. Voting and attention-based pose relation learning for object pose estimation from 3D point clouds. IEEE Robot. Autom. Lett. 2022, 7, 8980–8987. [Google Scholar] [CrossRef]
- Li, Z.; Stamos, I. Depth-based 6DoF Object Pose Estimation using Swin Transformer. arXiv 2023, arXiv:2303.02133. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cai, D.; Heikkilä, J.; Rahtu, E. Ove6D: Object viewpoint encoding for depth-based 6D object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6803–6813. [Google Scholar]
- Gao, G.; Lauri, M.; Wang, Y.; Hu, X.; Zhang, J.; Frintrop, S. 6D object pose regression via supervised learning on point clouds. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3643–3649. [Google Scholar]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Data-driven 3D voxel patterns for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1903–1911. [Google Scholar]
- Kehl, W.; Milletari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep learning of local rgb-d patches for 3D object detection and 6D pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 205–220. [Google Scholar]
- Li, C.; Bai, J.; Hager, G.D. A unified framework for multi-view multi-class object pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6D Object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- He, Y.; Huang, H.; Fan, H.; Chen, Q.; Sun, J. Ffb6D: A full flow bidirectional fusion network for 6D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3003–3013. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. Pvn3D: A deep point-wise 3D keypoints voting network for 6Dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11632–11641. [Google Scholar]
- Lin, S.; Wang, Z.; Ling, Y.; Tao, Y.; Yang, C. E2EK: End-to-end regression network based on keypoint for 6D pose estimation. IEEE Robot. Autom. Lett. 2022, 7, 6526–6533. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, K.; Xu, L.; Dou, Q.; Qin, J. Deep Fusion Transformer Network with Weighted Vector-Wise Keypoints Voting for Robust 6D Object Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13967–13977. [Google Scholar]
- Jiang, X.; Li, D.; Chen, H.; Zheng, Y.; Zhao, R.; Wu, L. Uni6D: A unified cnn framework without projection breakdown for 6D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11174–11184. [Google Scholar]
- Chen, W.; Jia, X.; Chang, H.J.; Duan, J.; Leonardis, A. G2l-net: Global to local network for real-time 6D pose estimation with embedding vector features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4233–4242. [Google Scholar]
- Shi, Y.; Huang, J.; Xu, X.; Zhang, Y.; Xu, K. Stablepose: Learning 6D object poses from geometrically stable patches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15222–15231. [Google Scholar]
- Labbé, Y.; Manuelli, L.; Mousavian, A.; Tyree, S.; Birchfield, S.; Tremblay, J.; Carpentier, J.; Aubry, M.; Fox, D.; Sivic, J. Megapose: 6D Pose estimation of novel objects via render & compare. arXiv 2022, arXiv:2212.06870. [Google Scholar]
- Lipson, L.; Teed, Z.; Goyal, A.; Deng, J. Coupled iterative refinement for 6D multi-object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6728–6737. [Google Scholar]
- Hai, Y.; Song, R.; Li, J.; Salzmann, M.; Hu, Y. Rigidity-Aware Detection for 6D Object Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8927–8936. [Google Scholar]
- Zhou, G.; Wang, H.; Chen, J.; Huang, D. Pr-gcn: A deep graph convolutional network with point refinement for 6D pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2793–2802. [Google Scholar]
- Wu, Y.; Zand, M.; Etemad, A.; Greenspan, M. Vote from the center: 6 Dof pose estimation in rgb-d images by radial keypoint voting. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 335–352. [Google Scholar]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized object coordinate space for category-level 6D object pose and size estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2642–2651. [Google Scholar]
- Deng, X.; Geng, J.; Bretl, T.; Xiang, Y.; Fox, D. iCaps: Iterative category-level object pose and shape estimation. IEEE Robot. Autom. Lett. 2022, 7, 1784–1791. [Google Scholar] [CrossRef]
- Lin, H.; Liu, Z.; Cheang, C.; Fu, Y.; Guo, G.; Xue, X. Sar-net: Shape alignment and recovery network for category-level 6D object pose and size estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6707–6717. [Google Scholar]
- Lin, J.; Wei, Z.; Li, Z.; Xu, S.; Jia, K.; Li, Y. Dualposenet: Category-level 6D object pose and size estimation using dual pose network with refined learning of pose consistency. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3560–3569. [Google Scholar]
- Irshad, M.Z.; Kollar, T.; Laskey, M.; Stone, K.; Kira, Z. Centersnap: Single-shot multi-object 3D shape reconstruction and categorical 6D pose and size estimation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 10632–10640. [Google Scholar]
- Tian, M.; Ang, M.H.; Lee, G.H. Shape prior deformation for categorical 6D object pose and size estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 530–546. [Google Scholar]
- Fan, Z.; Song, Z.; Xu, J.; Wang, Z.; Wu, K.; Liu, H.; He, J. ACR-Pose: Adversarial canonical representation reconstruction network for category level 6D object pose estimation. arXiv 2021, arXiv:2111.10524. [Google Scholar]
- Chen, K.; Dou, Q. Sgpa: Structure-guided prior adaptation for category-level 6D object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2773–2782. [Google Scholar]
- Lin, J.; Wei, Z.; Ding, C.; Jia, K. Category-level 6D object pose and size estimation using self-supervised deep prior deformation networks. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 19–34. [Google Scholar]
- Li, G.; Li, Y.; Ye, Z.; Zhang, Q.; Kong, T.; Cui, Z.; Zhang, G. Generative category-level shape and pose estimation with semantic primitives. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 1390–1400. [Google Scholar]
- Chen, X.; Dong, Z.; Song, J.; Geiger, A.; Hilliges, O. Category level object pose estimation via neural analysis-by-synthesis. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 139–156. [Google Scholar]
- Lin, Y.; Tremblay, J.; Tyree, S.; Vela, P.A.; Birchfield, S. Single-stage keypoint-based category-level object pose estimation from an RGB image. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 1547–1553. [Google Scholar]
- Wang, C.; Martín-Martín, R.; Xu, D.; Lv, J.; Lu, C.; Fei-Fei, L.; Savarese, S.; Zhu, Y. 6-pack: Category-level 6D pose tracker with anchor-based keypoints. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 10059–10066. [Google Scholar]
- Weng, Y.; Wang, H.; Zhou, Q.; Qin, Y.; Duan, Y.; Fan, Q.; Chen, B.; Su, H.; Guibas, L.J. Captra: Category-level pose tracking for rigid and articulated objects from point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13209–13218. [Google Scholar]
- Liu, X.; Wang, G.; Li, Y.; Ji, X. Catre: Iterative point clouds alignment for category-level object pose refinement. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 499–516. [Google Scholar]
- Wang, J.; Chen, K.; Dou, Q. Category-level 6D object pose estimation via cascaded relation and recurrent reconstruction networks. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4807–4814. [Google Scholar]
- Zhang, R.; Di, Y.; Lou, Z.; Manhardt, F.; Tombari, F.; Ji, X. RBP-Pose: Residual bounding box projection for category-level pose estimation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 655–672. [Google Scholar]
- Zhang, R.; Di, Y.; Manhardt, F.; Tombari, F.; Ji, X. SSP-Pose: Symmetry-Aware Shape Prior Deformation for Direct Category-Level Object Pose Estimation. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 7452–7459. [Google Scholar]
- Zhang, J.; Wu, M.; Dong, H. GenPose: Generative Category-level Object Pose Estimation via Diffusion Models. arXiv 2023, arXiv:2306.10531. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Brégier, R.; Devernay, F.; Leyrit, L.; Crowley, J.L. Symmetry aware evaluation of 3D object detection and pose estimation in scenes of many parts in bulk. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2209–2218. [Google Scholar]
- Kleeberger, K.; Landgraf, C.; Huber, M.F. Large-scale 6D object pose estimation dataset for industrial bin-picking. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2573–2578. [Google Scholar]
- Ahmadyan, A.; Zhang, L.; Ablavatski, A.; Wei, J.; Grundmann, M. Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7822–7831. [Google Scholar]
- Hoque, S.; Arafat, M.Y.; Xu, S.; Maiti, A.; Wei, Y. A comprehensive review on 3D object detection and 6D pose estimation with deep learning. IEEE Access 2021, 9, 143746–143770. [Google Scholar] [CrossRef]
- Sahin, C.; Garcia-Hernando, G.; Sock, J.; Kim, T.K. A review on object pose recovery: From 3D bounding box detectors to full 6D pose estimators. Image Vis. Comput. 2020, 96, 103898. [Google Scholar] [CrossRef]
- Fu, M.; Zhou, W. DeepHMap++: Combined projection grouping and correspondence learning for full DoF pose estimation. Sensors 2019, 19, 1032. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the continuity of rotation representations in neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5745–5753. [Google Scholar]
- Marion, P.; Florence, P.R.; Manuelli, L.; Tedrake, R. Label fusion: A pipeline for generating ground truth labels for real rgbd data of cluttered scenes. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3235–3242. [Google Scholar]
- Denninger, M.; Sundermeyer, M.; Winkelbauer, D.; Zidan, Y.; Olefir, D.; Elbadrawy, M.; Lodhi, A.; Katam, H. Blenderproc. arXiv 2019, arXiv:1911.01911. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Fan, Z.; Pan, P.; Wang, P.; Jiang, Y.; Xu, D.; Jiang, H.; Wang, Z. POPE: 6-DoF Promptable Pose Estimation of Any Object, in Any Scene, with One Reference. arXiv 2023, arXiv:2305.15727. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Amini, A.; Selvam Periyasamy, A.; Behnke, S. YOLOPose: Transformer-based multi-object 6D pose estimation using keypoint regression. In Proceedings of the International Conference on Intelligent Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 392–406. [Google Scholar]
- Zhang, Z.; Chen, W.; Zheng, L.; Leonardis, A.; Chang, H.J. Trans6D: Transformer-Based 6D Object Pose Estimation and Refinement. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 112–128. [Google Scholar]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set transformer: A framework for attention-based permutation-invariant neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3744–3753. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point transformer v2: Grouped vector attention and partition-based pooling. Adv. Neural Inf. Process. Syst. 2022, 35, 33330–33342. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–794. [Google Scholar]
- Haugaard, R.L.; Iversen, T.M. Multi-view object pose estimation from correspondence distributions and epipolar geometry. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1786–1792. [Google Scholar]
- Liu, Y.; Wen, Y.; Peng, S.; Lin, C.; Long, X.; Komura, T.; Wang, W. Gen6D: Generalizable model-free 6-DoF object pose estimation from RGB images. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 298–315. [Google Scholar]
- Mousavian, A.; Eppner, C.; Fox, D. 6-dof graspnet: Variational grasp generation for object manipulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2901–2910. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Years | Input | Types | LM | LM-O | YCB-V |
|---|---|---|---|---|---|---|
| PoseCNN [20] | 2017 | RGB | Regression | - | 24.9 | 61.3 |
| SSD-6D [43] | 2017 | RGB | Refinement | 79 | - | - |
| YOLO-6D [25] | 2018 | RGB | Regression | 55.95 | - | - |
| DeepIM [33] | 2018 | RGB | Refinement | 88.6 | 55.5 | 81.9 |
| Deep-6DPose [22] | 2018 | RGB | Regression | 65.2 | - | - |
| BB8 [60] | 2018 | RGB | Refinement | 43.6 | - | - |
| PVNet [46] | 2018 | RGB | Feature | 86.27 | 40.77 | 73.4 |
| Hu et al. [24] | 2019 | RGB | Regression | - | 27.0 | - |
| CDPN [40] | 2019 | RGB | Feature | 89.86 | - | - |
| DPOD [45] | 2019 | RGB | Template | 95.2 | 47.3 | - |
| Pix2Pose [63] | 2019 | RGB | Feature | 72.4 | 32.0 | - |
| Efficientpose [41] | 2020 | RGB | Regression | 97.35 | 83.98 | - |
| CosyPose [34] | 2020 | RGB | Regression | - | - | 84.5 |
| LatentFusion [44] | 2020 | RGB | Template | 87.1 | - | - |
| Hybridpose [68] | 2020 | RGB | Feature | 91.3 | 47.5 | - |
| GDR-Net [15] | 2021 | RGB | Regression | 93.7 | 62.2 | 84.4 |
| SO-Pose [80] | 2021 | RGB | Feature | 94.0 | 62.3 | 83.9 |
| RePose [74] | 2021 | RGB | Refinement | 96.1 | 51.6 | 82.0 |
| PoseRBPF [47] | 2021 | RGB | Template | 79.76 | - | - |
| Zebrapose [36] | 2022 | RGB | Regression | - | 76.9 | 85.3 |
| RNNPose [65] | 2022 | RGB | Refinement | 97.37 | 60.65 | 83.1 |
| DPOD-v2 [81] | 2022 | RGB | Feature | 93.59 | - | - |
| EPro-PnP-v2 [72] | 2023 | RGB | Feature | 96.36 | - | - |
| Hai et al. [37] | 2023 | RGB | Regression | 92.2 | 65.4 | - |
| CRT-6D [70] | 2023 | RGB | Feature | - | 66.3 | 87.5 |
| Methods | Years | Input | LM | LM-O | YCB-V |
|---|---|---|---|---|---|
| Gao et al. [99] | 2020 | D | - | - | 94.7 |
| Pointvotenet [91] | 2020 | Point Cloud | 96.3 | 75.1 | - |
| CloudAAE [85] + ICP | 2021 | Point Cloud | 95.5 | 66.1 | 94.0 |
| OVE6D [98] | 2022 | D | 96.4 | 70.9 | - |
| Depth-Based [96] | 2023 | D | 97.5 | 77.1 | - |
| Methods | Years | Input | LM | LM-O | YCB-V |
|---|---|---|---|---|---|
| Li et al. [102] | 2018 | RGB-D | - | - | 94.3 |
| DenseFusion [103] | 2019 | RGB-D | 94.3 | - | 91.2 |
| Morefusion [5] | 2020 | RGB-D | - | - | 91.0 |
| PVN3D [105] | 2020 | RGB-D | 99.4 | 70.2 | 91.8 |
| G2L-Net [109] | 2020 | RGB-D | 98.7 | - | 92.4 |
| PR-GCN [114] | 2020 | RGB-D | 99.6 | 65.0 | 95.8 |
| FFB6D [104] | 2021 | RGB-D | 99.7 | 66.2 | 92.7 |
| Uni6d [108] | 2022 | RGB-D | - | - | 88.8 |
| E2EK [106] | 2022 | RGB-D | 99.8 | 75.3 | 94.4 |
| RCVPose [115] | 2022 | RGB-D | 99.4 | 70.2 | 95.2 |
| Deepfusion [107] | 2023 | RGB-D | 99.8 | 77.7 | 94.4 |
| Methods | Years | Input | 5°5 cm | 10°5 cm | IoU50 | IoU75 |
|---|---|---|---|---|---|---|
| NOCS [116] | 2019 | RGB-D | 10.0 | 25.2 | 78.0 | 30.1 |
| SPD [121] | 2020 | RGB-D | 21.4 | 54.1 | 77.3 | 53.2 |
| 6-PACK [128] | 2020 | RGB-D | 33.3 | - | - | - |
| DualPoseNet [119] | 2021 | RGB-D | 35.9 | 66.8 | 79.8 | 62.2 |
| FS-Net [17] | 2021 | RGB-D | 28.2 | 60.8 | 92.2 | 63.5 |
| ACR-Pose [122] | 2021 | RGB-D | 36.9 | 65.9 | 82.8 | 66.0 |
| SGPA [123] | 2021 | RGB-D | 39.6 | 70.0 | 80.1 | 61.9 |
| CAPTRA [129] | 2021 | D | 62.16 | - | - | - |
| DPDN [124] | 2022 | RGB-D | 50.7 | 78.4 | 83.4 | 76.0 |
| CATRE [130] + SPD | 2022 | RGB-D | 54.4 | 73.1 | - | 43.6 |
| CR-Net [131] | 2021 | RGB-D | 34.3 | 47.2 | 79.3 | 55.9 |
| RBP-Pose [132] | 2022 | RGB-D | 48.1 | 79.2 | - | - |
| SSP-Pose [133] | 2022 | RGB-D | 44.6 | 77.8 | 82.3 | 66.3 |
| GenPose [134] | 2023 | D | 60.9 | 84.0 | - | - |
| Methods | Years | Input | 5°5 cm | 10°5 cm | IoU50 | IoU75 |
|---|---|---|---|---|---|---|
| NOCS [116] | 2019 | RGB-D | 40.9 | 64.6 | 83.9 | 69.5 |
| SPD [121] | 2020 | RGB-D | 59.0 | 81.5 | 93.2 | 83.1 |
| DualPoseNet [119] | 2021 | RGB-D | 70.7 | 84.7 | 92.4 | 86.4 |
| ACR-Pose [122] | 2021 | RGB-D | 74.1 | 87.8 | 93.8 | 89.9 |
| SGPA [123] | 2021 | RGB-D | 74.5 | 88.4 | 93.2 | 88.1 |
| CATRE [130] + SPD | 2022 | RGB-D | 80.3 | 89.3 | - | 76.1 |
| CR-Net [131] | 2021 | RGB-D | 76.4 | 87.7 | 93.8 | 88.0 |
| RBP-Pose [132] | 2022 | RGB-D | 79.6 | 89.5 | 93.1 | 89.0 |
| SSP-Pose [133] | 2022 | RGB-D | 75.5 | 87.4 | - | 86.8 |
| GenPose [134] | 2023 | D | 84.4 | 89.6 | - | - |
| Dataset | Years | Levels | Categories | Suitable Scenes |
|---|---|---|---|---|
| LM [78] | 2012 | Instance-Level | 15 | Objects are cluttered and untextured with limited viewpoints. |
| LM-O [79] | 2014 | Instance-Level | 8 | Objects are cluttered and more severely occluded. |
| Shapenet [135] | 2016 | Category-Level | 16 | Point cloud dataset of common objects in life with fine segmentation. |
| T-LESS [12] | 2017 | Instance-Level | 30 | Industry-related scenes with few object textures, strong symmetry, and mutual occlusion. |
| ITODD [13] | 2017 | Instance-Level | 28 | Industrial scenes with strong and scarce color information in the case of random projections. |
| Siléane [136] | 2017 | Instance-Level | 8 | Different symmetry objects. |
| YCB-V [20] | 2018 | Instance-Level | 21 | Daily objects with occlusion in different light situations, and applicable to the video needs of the object. |
| TUD-L/TYO-L [35] | 2018 | Instance-Level | 24 | Different light conditions. |
| NOCS [116] | 2019 | Category-Level | 6 | Category-level position of common objects, meet real and synthetic dataset requirements. |
| Fraunhofer [137] | 2019 | Instance-Level | 10 | Industrial large-scale dataset, including different modalities, is suitable for grasping tasks. |
| Objectron [138] | 2021 | Category-Level | 9 | Meeting generalizability and tracking task requirements with large-scale multiple views. |
| Methods | Level | Advantages or Applicable Scenarios | Limitation |
|---|---|---|---|
| Regression-based methods | Instance-level | Simple design and wide application. | Applicability to complex environments may be limited. |
| Feature-based methods | Instance-level | Situations with rich features and not severe occlusion. | Symmetry needs to be considered. |
| Fusion-based methods | Instance-level | Industrial applications, are suitable for occlusion. | The method design is relatively complex. |
| Point cloud-based methods | Instance-level | Robot grabbing-related tasks. | Surface reflections may result in poorer results. |
| Regression-based methods | Category-level | Everyday objects, perform better in generalization. | Poor handling of intra-category differences. |
| Prior-based methods | Category-level | More robust to intra-class differences and color changes. | High demand for computing resources. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, J.; Hao, Y.; Wu, Q.; Li, S.; Fang, Y. A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios. Sensors 2024, 24, 1076. https://doi.org/10.3390/s24041076
Guan J, Hao Y, Wu Q, Li S, Fang Y. A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios. Sensors. 2024; 24(4):1076. https://doi.org/10.3390/s24041076
Chicago/Turabian StyleGuan, Jian, Yingming Hao, Qingxiao Wu, Sicong Li, and Yingjian Fang. 2024. "A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios" Sensors 24, no. 4: 1076. https://doi.org/10.3390/s24041076
APA StyleGuan, J., Hao, Y., Wu, Q., Li, S., & Fang, Y. (2024). A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios. Sensors, 24(4), 1076. https://doi.org/10.3390/s24041076