1. Introduction
In the rapidly advancing field of unmanned aerial vehicle (UAV) technology, object detection remains a pivotal challenge, especially in the context of indoor environments. Indoor scenarios pose unique difficulties for UAVs, including constrained spaces, varied lighting conditions, and complex backgrounds, making effective human detection a task of critical importance. While current advancements in deep learning have provided substantial progress in this domain, there is a significant need to tailor these technologies to suit the intricacies of indoor surveillance and navigation.
In recent years, the integration of unmanned aerial vehicles (UAVs) in surveillance and monitoring tasks has catalyzed the evolution of human detection systems. While vision-based systems, using algorithms like deep learning models, have been the cornerstone of UAV-based human detection, alternative approaches are emerging, addressing the limitations of purely visual techniques. Radar-spectrogram analysis, for instance, utilizes deep learning models to interpret micro-Doppler signatures of targets, presenting a novel method for identifying human activities from UAVs in real-time scenarios [
1]. Alternatively, recent studies in sensors are increasingly leveraging a variety of sensor modalities to enhance detection accuracy, particularly in challenging environments like indoor or obscured environments. Thermal imaging and ultrawideband (UWB) sensing technologies offer significant advancements in detecting humans, even in conditions where visual systems cannot succeed. UWB sensing, specifically, has shown remarkable capabilities in distinguishing between drone and human movements in confined indoor spaces, demonstrating the effectiveness of multi-modal sensing strategies in UAV-based surveillance [
2]. These advancements in integrating diverse data sources, such as air quality monitoring and heat source detection, not only improve detection precision but also pave the way for UAV applications in more complex and dynamic environments. The use of these alternative technologies underscores a significant shift in UAV surveillance methodology, broadening the spectrum of applications and offering more robust solutions for real-time human detection in various operational scenarios. In addition to vision-based systems, alternative approaches for real-time human detection are leveraging various data sources such as air quality monitoring and heat source detection. Thermal imaging-based systems have become crucial in smart video surveillance for moving human detection in thermal videos, even in low-light or cluttered backgrounds. This technology captures heat generated from humans, offering a vital solution for safety and security by minimizing crime and trespassing through enhanced identification and monitoring [
3]. Furthermore, the integration of Internet of Things (IoT) sensor grids in households with multiple heating systems has opened new avenues for air contaminant migration monitoring. This approach offers continuous monitoring with data transfer to the cloud, enabling the near-real-time detection of unscheduled or unauthorized access to specific areas. The utilization of such technology in UAVs could transform surveillance capabilities, allowing for the dynamic measurement of contaminants and providing real-time access control. This novel application of IoT, in line with the Industry 4.0 concept, allows for extensive data analysis over longer periods, enabling predictions of occupant behavior or the need for ventilation in specific rooms or areas, thus enhancing the capabilities of UAVs in complex surveillance scenarios [
4].
Small-object detection, a crucial aspect of UAV image processing, aims to identify objects that are small, complex, and challenging to distinguish by color. Traditional detection methods, which depend on manually designed features, encounter significant challenges in UAV-based applications. These challenges include sensitivity to varying lighting conditions, angles, and obstructions, and difficulties in processing complex backgrounds. While effective in simpler environments, these methods often lead to false positives and missed detections in more intricate scenarios [
5,
6,
7]. Conversely, the advent of deep learning, especially convolutional neural networks (CNNs), has markedly improved the detection of small-scale objects in UAV imagery, addressing many limitations inherent in traditional techniques [
8,
9].
In deep learning for UAV small-object detection, the algorithms are primarily divided into two categories: two-stage and single-stage detectors. Two-stage detectors, including algorithms like R-CNN [
10], Faster R-CNN [
11], Mask R-CNN [
12], and Cascade R-CNN [
13], are recognized for their higher accuracy. They are particularly effective in detecting small objects against complex backgrounds, employing a process that initially generates proposal regions and subsequently performs classification and regression on these regions. However, this method is computationally intensive, leading to slower processing speeds. In contrast, single-stage detectors such as the YOLO series [
14], SSD [
15], RetinaNet [
16], and CenterNet [
17] are known for their rapid processing speeds and real-time performance capabilities. However, these models tend to have lower accuracy in detecting small targets within complex backgrounds, which can result in false positives or missed detections. The trade-offs between these two approaches underscore the ongoing challenges and developments in UAV image processing, emphasizing the need for a balance between accuracy, speed, and computational efficiency. Han et al. [
18] introduced the DRFBNet300, a lightweight single-stage method achieving high accuracy and real-time performance in UAV imagery. Additionally, Zhang et al. [
19] proposed the DAGN, a YOLOv3 based model, which improved detection accuracy while maintaining real-time detection capabilities. These studies show the advancements and ongoing research in UAV-based object detection systems.
While the performance of general object detectors has been commendable, their application in indoor human detection using drones necessitates addressing specific challenges unique to this context. Unlike outdoor, indoor environments are characterized by varying lighting conditions, potential obstructions like furniture, and confined spaces, all of which can severely affect the quality of detection. In the realm of indoor drone operations, objects are often captured from diverse perspectives and at varying distances. This variability can be more pronounced indoors due to the limited space and the drone’s proximity to objects. As a result, performing object detection at a consistent scale becomes challenging, often leading to significant errors and missed detections. This is especially critical in scenarios where human detection is paramount, such as search-and-rescue operations or security surveillance.
Moreover, indoor scenes frequently contain densely packed elements and small-scale features. Humans might be partially or heavily occluded by furniture or other indoor structures, making the distinct features necessary for accurate detection less discernible. These challenges are compounded by the tendency of drone images to lose detail due to down sampling during detection. In indoor environment, this can mean the critical loss of features necessary for identifying and distinguishing humans, especially in crowded or complex scenes.
Considering these factors, current detection methods often struggle with precisely detecting humans in the indoor drone’s line of sight. Due to these reasons, this study aims to develop a human detection model that detects in real-time on an onboard computer equipped within a drone, demonstrating resilience to indoor environmental conditions.
This paper focuses on adapting and enhancing the YOLOv7 architecture, a state-of-the-art object detection model, to better suit indoor scenarios. YOLOv7’s exceptional balance of speed and accuracy makes it a suitable candidate for real-time applications; however, its standard implementation is primarily oriented towards outdoor or generic settings. Recognizing this, our research aims to modify and optimize YOLOv7-tiny, creating a variant specifically tuned for the challenges of indoor UAV operations. This involves customizing the model to better handle the diverse range of indoor conditions and to improve its efficiency in accurately detecting humans in such environments.
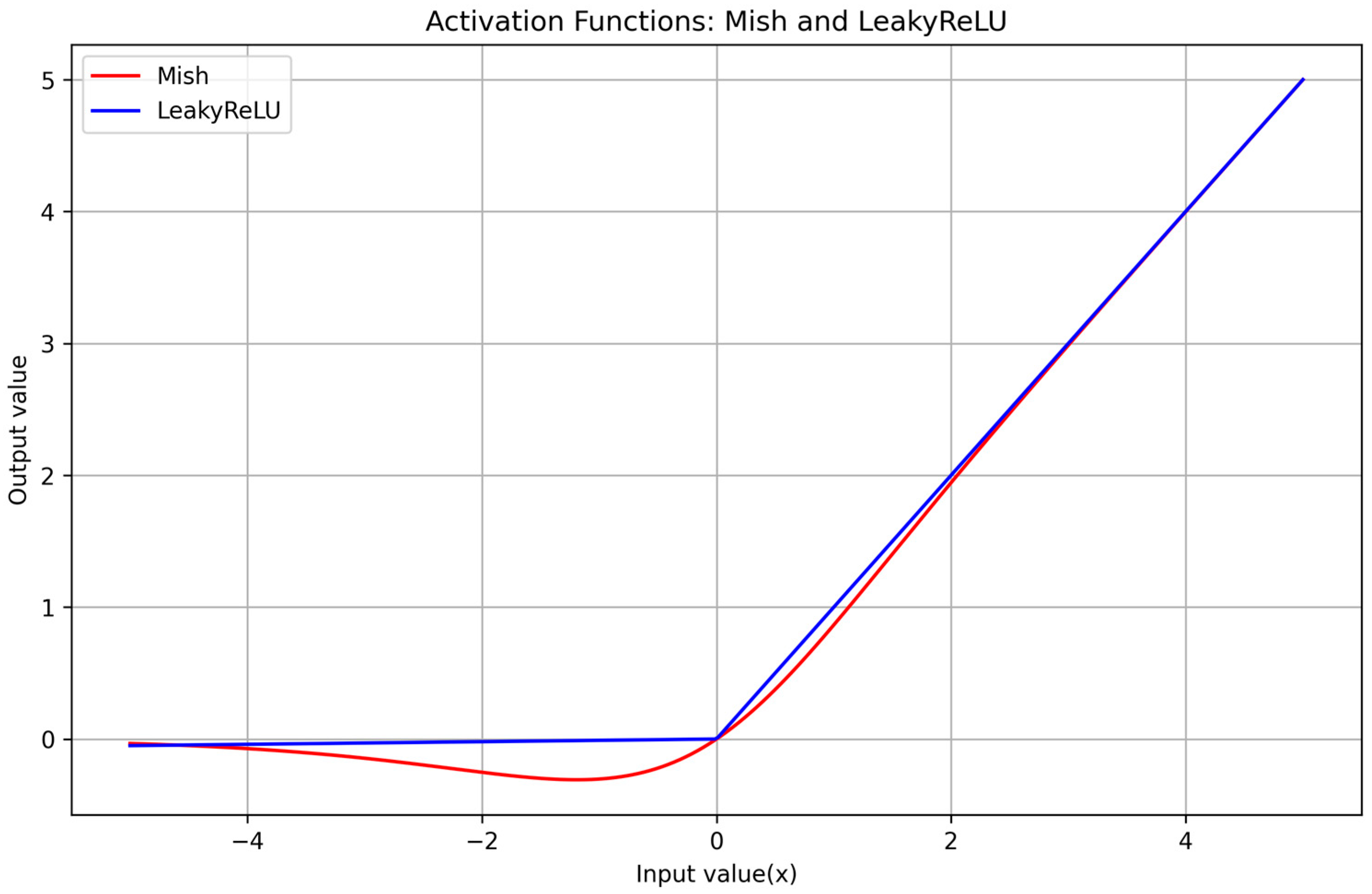
The proposed methodology of this research is twofold. First, we adapt the YOLOv7-tiny model through a long process of retraining and fine-tuning, using a dataset specifically curated for indoor UAV scenarios. This dataset comprises a diverse range of UAV perspective images and indoor human environments, encompassing various lighting conditions, room sizes, and clutter levels to ensure comprehensive learning. Second, we introduce modifications to the YOLOv7-tiny architecture to enhance its ability to detect humans in indoor settings. These modifications include optimizing the model’s convolutional layers, integrating enhanced spatial pyramid pooling (SPP), and implementing a more robust activation function to improve network performance to reduce false positives and improve detection accuracy in confined spaces.
The main contributions of this paper are as follows:
The development of YOLO-IHD, an adaptation of the YOLOv7 architecture specifically tailored for indoor UAV-based human detection, which significantly enhances detection accuracy in complex indoor environments.
The proposed model of this paper outperforms the pre-trained YOLOv7-tiny model in terms of average precision, with a 42.51% increase in mAP@0.5 on the IHD dataset, and a 33.05% increase on the VisDrone dataset. This advancement is critical for applications demanding high precision in human detection from drones.
The lack of a dataset for indoor human detection by drones led to the creation of the IHD dataset. This new dataset presents a wide range of human images from diverse indoor perspectives, combined with existing, widely utilized datasets, resulting in a unique and comprehensive resource tailored to models specializing in indoor human detection.
The optimization of the convolutional layers and attention mechanism in YOLO-IHD, which adeptly process complex visual data from indoor environments, ensuring higher reliability in scenarios such as disaster response and indoor rescue missions.
This paper is structured so as to first provide a detailed overview of related work in indoor drone-based human detection and the evolution of YOLO models. Subsequently, we deep-dive into the methodology, elaborating on the model modifications and customizations, and dataset preparation and training processes. This is followed by a comprehensive presentation of our experimental setup, results, and comparative analysis with existing models. Finally, this paper concludes by discussing the implications of our findings for indoor UAV applications and suggesting directions for future research.
2. Related Work
2.1. Deep Learning-Based Detection Methods
Deep learning-based detectors can be broadly categorized into two types: two-stage and one-stage detectors. Within the domain of one-stage detectors, the Single Shot Multibox Detector (SSD) [
20] and You Only Look Once (YOLO) have been developed to address the balance between accuracy and processing time. Notably, YOLO is acknowledged for effectively managing performance in terms of both accuracy and processing time.
The CNN-based detectors, comprising RCNN [
21], Fast RCNN [
22], and Faster RCNN [
11], belong to the two-stage category, showcasing superior accuracy compared to various other detection algorithms. Nevertheless, these methods are associated with a downside of heightened computational costs, resulting in extended processing durations.
2.2. Two-Stage Detectors
In multi-stage detectors, one model is used to extract regions of objects, and the other one is used to classify and further detect the location of the object. R-CNN, which stands for region-based convolutional neural network, is an algorithm designed for object detection and comprises multiple versions. In the initial iteration of R-CNN, a technique called selective search is employed for region proposal, identifying potential areas containing objects. These identified regions undergo resizing and processing through a pre-trained convolutional neural network (CNN) to extract features. Support vector machine (SVM) classifiers are then trained for each object category, and a regression model for bounding boxes refines the localization. Fast R-CNN builds upon this improvement by introducing RoI (region of interest) pooling, eliminating the necessity for region warping. This advancement allows for end-to-end training, making the entire system jointly trainable. Faster R-CNN takes efficiency a step further by incorporating a region proposal network (RPN) into the model. This integration removes the dependence on external region proposal methods, enabling end-to-end training and resulting in a unified framework.
2.3. One-Stage Detectors
One-stage detection focus on predicting bounding boxes directly; there is no intermediate task such as region proposals which must be performed in order to produce an output. Therefore, a simpler and faster model architecture is obtained.
Single Shot Multibox Detector (SSD) is an object detection algorithm designed for the efficient and accurate detection of objects in images. Unlike traditional two-stage detectors, SSD is a one-stage detector, aiming to balance speed and accuracy using the concept of “multibox”. Multiboxes incorporate multiple bounding boxes with different aspect ratios and scales for each location in the feature map. Default or anchor boxes at various positions in the feature maps act as initial points for predicting both object bounding boxes and class scores. The model employs a feature pyramid network (FPN) to extract features at multiple scales, thereby improving its capability to detect objects of varying sizes. The prediction of object scores and bounding box coordinates occurs directly from multiple feature maps at different scales within a single forward pass. SSD’s loss function combines classification loss (utilizing softmax) and regression loss (employing smooth L1 loss) to facilitate accurate model training for localization. SSD offers advantages such as the ability to conduct object detection in a single forward pass, handling objects with diverse sizes and shapes through default boxes, and efficient training by simultaneously optimizing classification and localization tasks. It is well suited for real-time applications, including video processing. Nevertheless, SSD involves trade-offs, including potential accuracy compromises compared to more thorough two-stage detectors, and difficulties in detecting small objects, particularly in the presence of larger objects in the same image [
23].
The YOLO (You Only Look Once) algorithm represents a significant leap in computer vision for real-time object detection. Unlike conventional approaches, YOLO conducts detection in a single pass through the neural network by dividing the input image into a grid. Each grid cell predicts bounding boxes and class probabilities, allowing the identification of multiple objects within the same cell. The predictions involve simultaneous determination of both direct bounding box coordinates and associated class probabilities. YOLO incorporates multiple scales to enhance object detection efficiency, accommodating objects of various sizes. Following predictions, non-maximum suppression is applied to enhance the precision of the final set of detected objects by removing redundant bounding boxes.
YOLO receives acclaim for its ability to operate in real-time, making it well suited for applications such as video analysis and autonomous vehicles. Its unified framework removes the need for separate region proposal networks, contributing to overall efficiency. YOLO manages to strike a balance between accuracy and speed, making it adaptable for diverse applications. However, YOLO may encounter difficulties in accurately identifying small objects due to the limitations of a single-grid cell. Additionally, there might be a trade-off in localization accuracy compared to two-stage detectors, particularly for objects with intricate shapes. In summary, YOLO has gained prominence for its efficient and effective real-time object detection capabilities across a wide range of applications.
2.4. YOLOv7
YOLOv7 [
24] represents a significant advancement in the field of real-time object detection, known for its impressive speed and accuracy. Its development is attributed to the collaborative efforts of Wong Kin Yiu and Alexey AB, who have made substantial contributions to the YOLO family of models. YOLOv7 was designed to set new benchmarks in object detection by predicting bounding boxes more accurately and quickly compared to its predecessors and peers. One of the key elements of YOLOv7 is its efficient layer aggregation, which focuses on the convolutional layers in the backbone. This efficiency is critical for fast inference speeds. The model builds on the concept of cross stage partial networks, which was instrumental in making YOLOv4 [
25] and YOLOv5 [
26] more efficient. The final layer aggregation in YOLOv7, known as E-ELAN (extended–efficient layer aggregation network), is an extended version of the ELAN computational block. This design optimizes both the gradient path length and the stacking number of computational blocks, leading to a network that learns more diverse features effectively. Model scaling is another crucial aspect of YOLOv7. The model considers the depth and width of the network, scaling these attributes in concert while concatenating layers. This compound scaling approach ensures optimal architecture while scaling the model for different sizes, making it adaptable for various applications that require different levels of accuracy and inference speeds. Re-parameterization techniques in YOLOv7 involve averaging a set of model weights to create a more robust model. This approach focuses on module-level re-parameterization, where different parts of the network have their own re-parameterization strategies based on gradient flow propagation paths. The YOLOv7 network also features an innovative auxiliary head concept, referred to as the lead head and coarse-to-fine lead head. The auxiliary head is supervised in addition to the lead head during training, with the former learning coarser and the latter finer details. This deep supervision enables the model to capture more nuanced features and improves overall detection performance. In terms of results, YOLOv7 surpasses previous object detectors in both speed and accuracy, showing significant improvement over a range of 5 FPS to 160 FPS. The model demonstrates its superiority by outperforming earlier YOLO versions and other baseline models in mean average precision (mAP) across various model sizes.
2.5. YOLOv7-Tiny Model
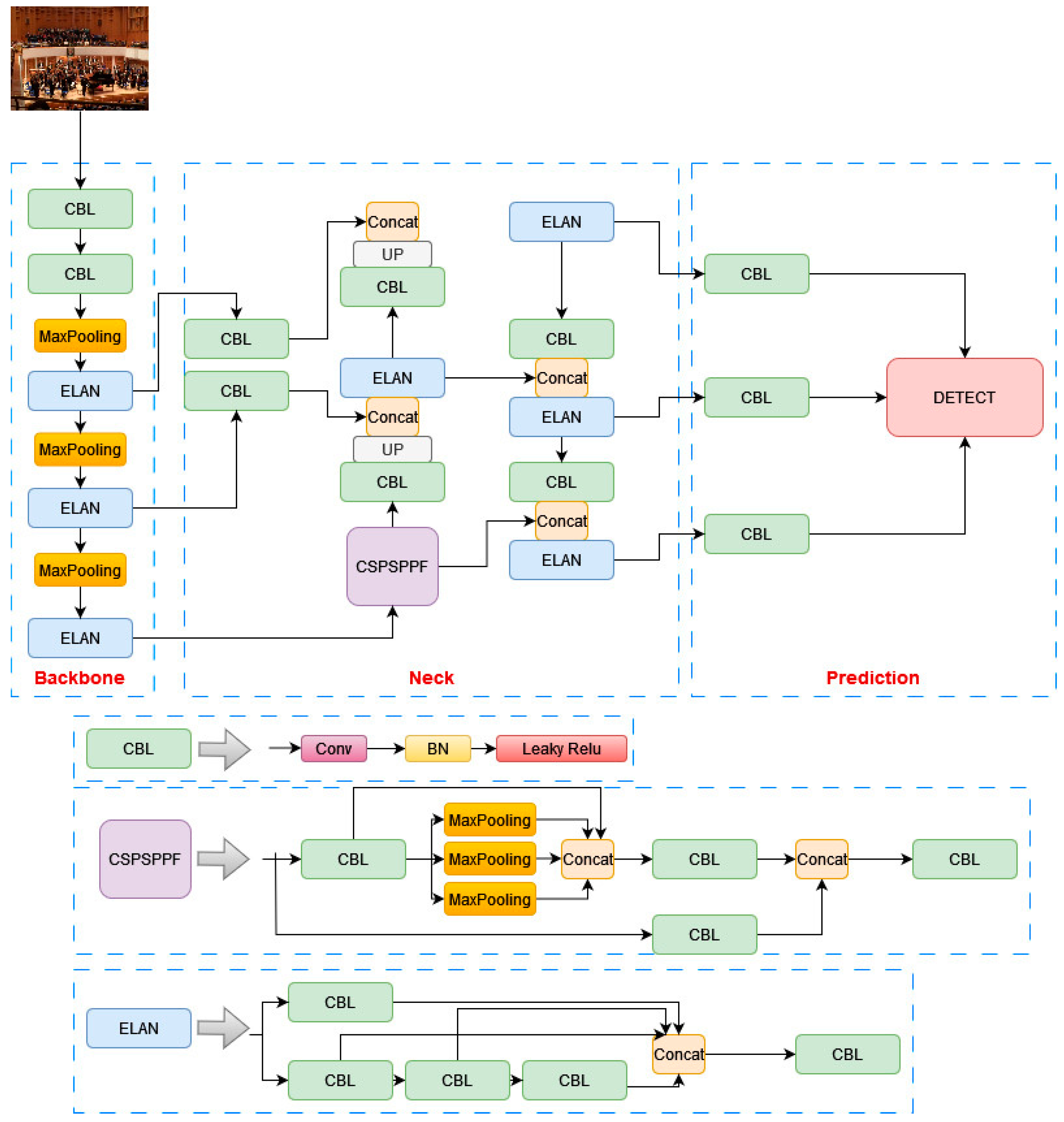
YOLOv7-tiny is an adaptation of the more complex YOLOv7 model, tailored specifically for edge GPUs, which are known for their limited computational resources. In order to make it suitable for such environments, YOLOv7-tiny employs a streamlined architecture, as shown in
Figure 1, while maintaining the core components of the YOLOv7 model: the backbone, neck, and head. The backbone of YOLOv7-tiny uses ELAN-T, a simpler version of the extended–efficient layer aggregation network (E-ELAN) found in the full YOLOv7 model. This change includes the removal of the convolution operation in MPConv, relying solely on pooling for down sampling. Despite these reductions, the optimized spatial pyramid pooling (SPP) structure is retained, ensuring that rich feature maps are still provided to the neck layer. This balance between simplification and feature richness is crucial for maintaining effective detection capabilities within the constraints of edge devices. In the neck, YOLOv7-tiny continues to use the PANet structure, a design choice that facilitates efficient feature aggregation from different levels of the backbone. This helps in preserving important information necessary for accurate object detection. At the head of the network, YOLOv7-tiny opts for standard convolution to adjust channel numbers instead of using the more complex REPConv. This modification is part of the model’s strategy to reduce computational load and memory requirements. While YOLOv7-tiny has decreased accuracy compared to its full-sized counterpart, it offers significant advantages in terms of speed and model size, making it well suited for applications where resources are limited and real-time performance is essential. This balance of speed, weight, and accuracy makes YOLOv7-tiny an appealing option for edge computing applications in real-time object detection.
2.6. Real-Time Detection
This section encapsulates the state of the art in real-time object detection using indoor drones, examining the technological advancements, the challenges faced, and the future directions of real-time UAV systems. By analyzing recent studies and developments, it aims to offer a comprehensive understanding of how indoor drones are being equipped to perform real-time object detection, their current capabilities, and the potential they hold for future applications. The list of studies is shown in
Table 1.
2.7. Techniques for Drone Positioning and Attitude
The effectiveness of unmanned aerial vehicles (UAVs) in indoor human detection is significantly influenced by their ability to accurately determine their position and attitude within complex indoor environments. Precise positioning and attitude data are essential for creating a reliable dataset and enabling the fine-grained perception of human activities. These challenges are exacerbated in indoor settings due to the lack of GPS signals and the presence of obstacles affecting UAV navigation and stability. In response, innovative methods have been developed specifically for indoor UAV applications. Cao et al. [
49] have enhanced indoor positioning accuracy using a WiFi RTT algorithm, capable of compensating for LOS and identifying NLOS conditions, crucial for UAV stability in indoor environments. Concurrently, Bi et al. [
50] introduced a low-cost UAV detection method through WiFi traffic analysis combined with machine learning, offering a novel approach for UAV monitoring in complex environments. Complementing these, Liang et al. [
51] proposed an attitude estimation method for quadrotor UAVs based on the quaternion unscented Kalman filter (QUKF), enhancing navigational precision. Furthermore, Cheng et al. [
52] addressed GPS-denied environments by proposing a dynamic autonomous docking scheme for UAVs and UGVs, facilitating effective navigation and operation in constrained settings. Integrating these methods into UAV-based human detection systems significantly enhances the reliability and accuracy of data collection. Precise indoor positioning, coupled with effective attitude estimation, enables UAVs to accurately navigate and capture data in challenging indoor environments, proving vital for applications in surveillance, search-and-rescue operations, and detailed human activity monitoring.
Integrating light detection and ranging (LiDAR) and visual odometry for indoor drones has shown significant advancements in improving positioning and attitude determination in GPS-denied environments. Bautista et al. [
53] developed a system combining a vision-based photogrammetric position sensor and visual inertial odometry for precise quadcopter landing, while Wang et al. [
54] demonstrated a 74.61% improvement in positioning accuracy using a LiDAR-aided integrated navigation system. Additionally, Qiu et al. [
55] introduced a LiDAR-inertial navigation system that effectively addresses the challenges in feature extraction within spatial grid structures, enhancing pose estimation accuracy in GNSS-denied settings. These studies collectively highlight the progress and potential of sensor integration in unmanned aerial vehicles for reliable and precise indoor navigation.
Upon a thorough examination of the indoor drone navigation and positioning techniques previously discussed, this study has determined that the most suitable approach for implementation is the combination of LiDAR and visual odometry. This decision is underpinned by the distinct advantages of each technology: LiDAR’s exceptional accuracy in distance measurement and obstacle detection, and visual odometry’s capability in precise position tracking through visual techniques.
Related to this method, for indoor flights and data collection phases, it has been resolved that employing LiDAR for its robust obstacle detection capabilities will greatly enhance the safety and efficiency of the drone’s navigation in complex indoor environments. Concurrently, the integration of visual odometry will provide a reliable method for real-time positioning, ensuring a high degree of accuracy in the drone’s trajectory and spatial orientation. This combination approach not only mitigates the individual limitations of each system but also capitalizes on their combined strengths to offer a comprehensive solution for indoor drone position and attitude.
2.8. Security Aspects in UAV Communication Systems
The evolution of drone technology has expanded the capabilities and applications of unmanned aerial vehicles (UAVs), but it also introduces significant security challenges, particularly in communication systems. Drones, especially in complex environments like indoor human detection, require secure and reliable communication channels to function effectively. One of the fundamental concerns is the vulnerability of these channels to various cyber threats. The research by Krichen et al. [
56] highlights the susceptibility of drone communications to attacks such as man-in-the-middle, denial-of-service, and data interception. These vulnerabilities can have dire consequences, especially when drones are used in sensitive areas or for critical missions. The authors emphasize the necessity of robust security protocols and propose countermeasures like blockchain technology and machine learning techniques to enhance drone communication security.
The security of drone communication systems is not just limited to preventing unauthorized access or data breaches. It extends to ensuring the integrity and confidentiality of the transmitted data. Ronaldo et al. [
57] discuss the implementation of a Forward Prediction Scheduling-based Stream Control Transmission Protocol (FPS-SCTP) in drones, which offers an enhanced real-time data transmission capability while ensuring robust security through encryption mechanisms like AES and digital signatures with ECDSA. This approach is particularly beneficial in environments where drones are used for delivery services or situations requiring immediate data transmission with high security.
Moreover, Ko et al. [
58] address the pressing need for secure UAV-to-UAV communication, emphasizing the importance of protocols that provide non-repudiation and perfect forward secrecy, especially in military settings. They propose a security protocol with two sub-protocols to secure communication between UAVs and between a UAV and a ground control station, achieving essential security requirements such as confidentiality, integrity, mutual authentication, non-repudiation, and resilience against various attacks, including DoS and man-in-the-middle attacks.
In conclusion, the security of drone communication systems is crucial in ensuring their effective and safe operation. Advanced encryption techniques and innovative protocols like FPS-SCTP are essential in safeguarding these systems against a wide range of cyber threats, thus enhancing the overall reliability and functionality of drones in various applications.
2.9. Ethical and Privacy Considerations in Indoor Surveillance by Autonomous Drones
In this study, the introduction of the proposed model, aimed at real-time human detection in indoor environments using autonomous drones, is presented. The focus extends beyond technical enhancements, encompassing the broader implications of its application in the context of ethical, privacy, and societal impacts. The importance of balancing technological advancement with the preservation of human rights is underscored, highlighting the need to take into account ethical considerations, privacy concerns, regulatory compliance, and public engagement in the deployment of such surveillance technologies.
The integration of drones for surveillance, particularly in indoor settings, raises significant ethical considerations. The primary concern revolves around the balance between enhancing security and respecting individual privacy rights. It is imperative to ensure that such technology is employed responsibly, adhering to legal and ethical standards. Moreover, the deployment of surveillance drones necessitates compliance with local and international privacy regulations. This includes securing necessary permissions and consents, especially when operating in private indoor spaces. These steps are crucial to maintain public trust and the legitimacy of using drones for security purposes [
59].
Privacy implications of indoor drone surveillance are a paramount concern. Effective measures, such as data anonymization and secure data storage protocols, must be implemented to safeguard individual privacy. Additionally, transparency in the operational use of drones is essential. Clear policies should be established outlining who has access to the data, their intended use, and accountability mechanisms. Engaging the public through education about the technology’s benefits, limitations, and the measures taken to uphold privacy and ethical standards is also vital for gaining public acceptance and trust [
60].
Continuing with the theme of ethical considerations and privacy implications, another important aspect to consider is the impact of autonomous surveillance drones on societal norms and expectations of privacy. The use of drones for human detection in indoor environments challenges traditional notions of privacy, necessitating a reevaluation of what constitutes reasonable expectations in the age of advanced surveillance technologies. It is crucial to engage in an ongoing dialogue with stakeholders, including policymakers, technologists, and the public, to establish norms and guidelines that respect individual rights while leveraging the benefits of drone technology. This dialogue should aim to create a consensus on the acceptable use of such technologies, ensuring that their deployment does not infringe on fundamental privacy rights and civil liberties [
61,
62].
5. Discussion
In this study, the YOLO-IHD method was evaluated in various indoor environments like garages, shopping centers, and concert venues, focusing on detecting human subjects of different sizes. The results highlight the method’s effectiveness in diverse settings, emphasizing its significance for models used in densely populated indoor areas and its adaptability in challenging conditions.
In a comparison of object detection models, the proposed YOLO-IHD model demonstrates significant advancements over existing state-of-the-art models in the VisDrone dataset, as evidenced by the data in
Table 7 and
Table 8. YOLO-IHD achieves a remarkable 69.55% mAP@0.5 in human detection, substantially outperforming previous models in the ‘Pedestrian’ and ‘People’ categories. For example, it shows marked improvement over YOLOv3, which scored 12.8% and 7.8%, and YOLOv7-tiny, with 36.5% and 34.4%, in these categories. Even compared to recent models like YOLOv7, PDWT-YOLO, and YOLOv8, with scores between 44.25% to 45.15%, YOLO-IHD stands out for its higher accuracy. Furthermore, it surpasses MS-YOLOv7, a robust model with 63.2% and 51.7% in ‘Pedestrian’ and ‘People’. YOLO-IHD’s consistent AP in these categories highlights its reliability and effectiveness, attributed to its unique features like the added small-object detection layer, CSPSPPF module, data augmentation, and Mish activation function, specifically designed for aerial human detection.
The YOLO-IHD model was tested for its detection capabilities under different perspectives and indoor conditions.
Figure 10 illustrates that, compared to the baseline model, YOLO-IHD detected more objects. The addition of the small-object detection layer to YOLO-IHD, as evident from the images, yielded successful results in detecting small objects. In
Figure 11, the model successfully identified objects of varying sizes in a shopping mall under different angles and lighting conditions, outperforming the baseline model. This success can be attributed to the model being trained with an augmented dataset, which enhanced its prediction accuracy for objects of different sizes, angles, and views.
Figure 12 presents a detection study conducted in a closed garage. The baseline model also managed to detect human objects. However, the primary reason for the 31% increase in accuracy of the YOLO-IHD model in darker areas is its enhancement with CSPSPPF and Mish functions. Additionally, a series of experiments were conducted involving multiple subjects in an enclosed garage environment. These experiments demonstrated that the YOLO-IHD model not only surpasses the baseline model in terms of accuracy but also exhibits superior detection capabilities. This is particularly evident in scenarios involving small-scale objects, as illustrated in
Figure 13. In these instances, whereas the baseline model failed to detect a small human object, the YOLO-IHD model successfully detected it, underscoring its enhanced performance in complex low-light environments. In
Figure 14, the model was tested in an auditorium, a setting characterized by a complex background and varying lighting conditions. This was among the most challenging experiments due to the combination of complex context and varying light. Despite these challenges, the YOLO-IHD model showed improved performance over the baseline model in this complex context.
The conditions and ambiance in
Figure 14 are considered crucial for future development efforts. The ability of YOLO-IHD to perform well in such a challenging and dynamic environment highlights its potential for further enhancements and wider applications in real-world scenarios.
6. Conclusions
This study introduces significant advancements for indoor human detection methods using a refined version of the YOLOv7-tiny. The YOLO-IHD model incorporates specific modifications that substantially enhance its precision in human detection, making it particularly effective for drone-based applications. These modifications include the integration of a small-object detection layer, the adoption of the Mish activation function, and an enhanced spatial pyramid pooling (SPP) mechanism. Together, these enhancements have resulted in a robust model for the complexities of indoor environments and drone-specific challenges. Relative to the baseline YOLOv7-tiny model, YOLO-IHD has shown a significant improvement in performance, achieving a 42.51% increase in the IHD dataset and a 33.05% increase in the VisDrone dataset. This considerable enhancement in accuracy underscores the model’s sophisticated design and its alignment with practical human detection surveillance needs. The proposed model’s real-time applicability was evaluated on edge computing platforms, revealing that YOLO-IHD operates at 27 FPS on Jetson Nano and 45 FPS on Xavier NX. These frame rates are indicative of the model’s capacity to function efficiently in real-time applications, suggesting its suitability for deployment in edge devices where computational efficiency is important.
The YOLO-IHD model represents a substantial advancement in the field of real-time indoor human detection, offering a robust and well-tested solution that enhances the surveillance capabilities of drones. This research provides insights and developments poised to revolutionize autonomous surveillance in complex indoor scenarios. Its novel integration of a small-object detection layer, the utilization of the Mish activation function, and the enhancement of the spatial pyramid pooling mechanism demonstrate a significant improvement in current lightweight detection models. Furthermore, the quantization of the proposed model for onboard edge devices is noteworthy for its real-time detection capability. These unique features ensure exceptional accuracy in complex indoor environments, a critical aspect for real-world applications.
For future work, to enhance YOLO-IHD’s efficiency in crowded areas, integrating a multi-scale detection mechanism is proposed. This mechanism allows the model to distinguish between individuals in close proximity by using distinct spatial features at various scales. For low-light conditions, a dual-phase approach involving automatic image enhancement algorithms coupled with infrared spectrum analysis could be implemented, enabling the model to adaptively switch between visual and thermal imaging for optimal detection. In occlusion scenarios, leveraging the depth data from Intel D435i, a 3D reconstruction of the environment can be utilized in conjunction with 2D image data. This hybrid approach will enable the model to infer the presence of humans even when partially obscured, by reconstructing the likely shape and position of occluded parts based on the environmental context. This technical enhancement aims not only to improve accuracy in complex scenarios but also to expand the operational versatility of YOLO-IHD in varied indoor environments.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}