
CSI-F: A Human Motion Recognition Method Based on Channel-State-Information Signal Feature Fusion


Abstract
1. Introduction
- Demonstrating the adaptability and sensitivity of CSI data to periodic movements and proposing a periodic feature slicing method. The method enhances the model’s recognition precision by superimposing periodic action CSI signals, which could offer more application scenarios for context-aware computing, such as device-free indoor pedometers, fitness activity counters, and more.
- The direction-independent nature of the CSI-F method has been validated. The dependency of human motion recognition methods on direction has been resolved using Doppler characteristics and antenna selection techniques. Experiments demonstrate that the direction of movement does not significantly affect the experimental results.
- A multi-task feature-sharing and information fusion model is proposed. Combining CNN, GRU, and multi-task learning facilitates information sharing and specific information fusion among tasks. The data-driven components in this hybrid model structure can identify complex non-linear relationships between the temporal and spatial layers of the input. Moreover, the model’s generalizability and predictive accuracy are effectively enhanced through coordination and assistance among tasks.
- In most cases, the indoor motion-sensing of individuals can be recognized within two to three cycles, enhancing the accuracy and usability of Wi-Fi signal perception. Additionally, the periodic nature of the movements allows for the expansion of the sensing distance to up to 6 m.
2. Related Work
2.1. Action Recognition Method
2.1.1. Contact Action Recognition Method
2.1.2. Non-Contact Action Recognition Method

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Related Literature | Research Object | Equipment | Advantage | Disadvantage |
|---|---|---|---|---|---|
| Sensor-based technology | Reference [9] | Human motion data | Triaxial accelerometers | High-precision detection, which can fully and accurately reflect the motion properties of objects. | Troublesome to wear, and poor privacy. |
| Reference [10] | Human motion data | Smart phone built-in sensor | |||
| Reference [11] | Human motion data | Wearable accelerometer | |||
| Computer vision | Reference [12] | Human motion data | Camera | Reliable data, real-time monitoring, fast information processing, non-contact. | Poor privacy, greatly affected by light and other factors. |
| Reference [13] | Human motion data | Camera | |||
| RFID | Reference [15] | Head gesture data | RFID tags | Reliable data, real-time monitoring, fast information processing, non-contact. | Short operating distance (generally in the scale of tens of meters) and poor privacy. |
| UWB | Reference [16] | Human motion data | UWB | High positioning accuracy, short working time and low power consumption. | There should be no obstacle to block the radio transmission, and there should be a perfect positioning network. |
| Wi-FiRSS | Reference [17] | Human motion data | AROCOV 6260 ap | No contact, no need for equipment, privacy. | Vulnerable to the impacts of dynamic environments, and difficulties in dealing with environmental noise. |
| Wi-FiCSI | CSI-F | Human motion data | Intel 5300 network card | It can overcome the shortcomings of all the above technologies, and is cost-effective, with strong privacy and wide coverage. | The recognition of micro-motions in harsh wireless environments is limited, and the optimization of the model is not perfect. |
| Related Work | Object | Equipment | Method | Advantage | Shortcoming |
|---|---|---|---|---|---|
| Reference [19] | Human activity data | Intel 5300 network card | Bidirectional Long Short Term Memory Network BiLSTM | Recognition of human activities by models in various experimental scenarios, with a recognition accuracy of 90%. | The generalization ability of the model and the recognition accuracy of the model need to be improved |
| Reference [20] | Human activity data | Intel 5300 network card | LSTM | By integrating multiple CSI data from various activities, the impact of inconsistent activities and certain topic-specific issues were eliminated. | The mobility and universality of motion-recognition methods are not considered. |
| Reference [21] | Human motion data | Intel 5300 network card | A dual-channel neural network | It can accurately classify various human activities, with an average accuracy rate of 93.3%. | Mobility in multiple environments without considering action recognition methods. |
| CSI-F | Human daily motion data | Intel 5300 network card | GRU + CNN | Improves the generalization ability and prediction accuracy of the model through information enhancement and multi-task sharing. | No discussion as to finer-grained actions. |
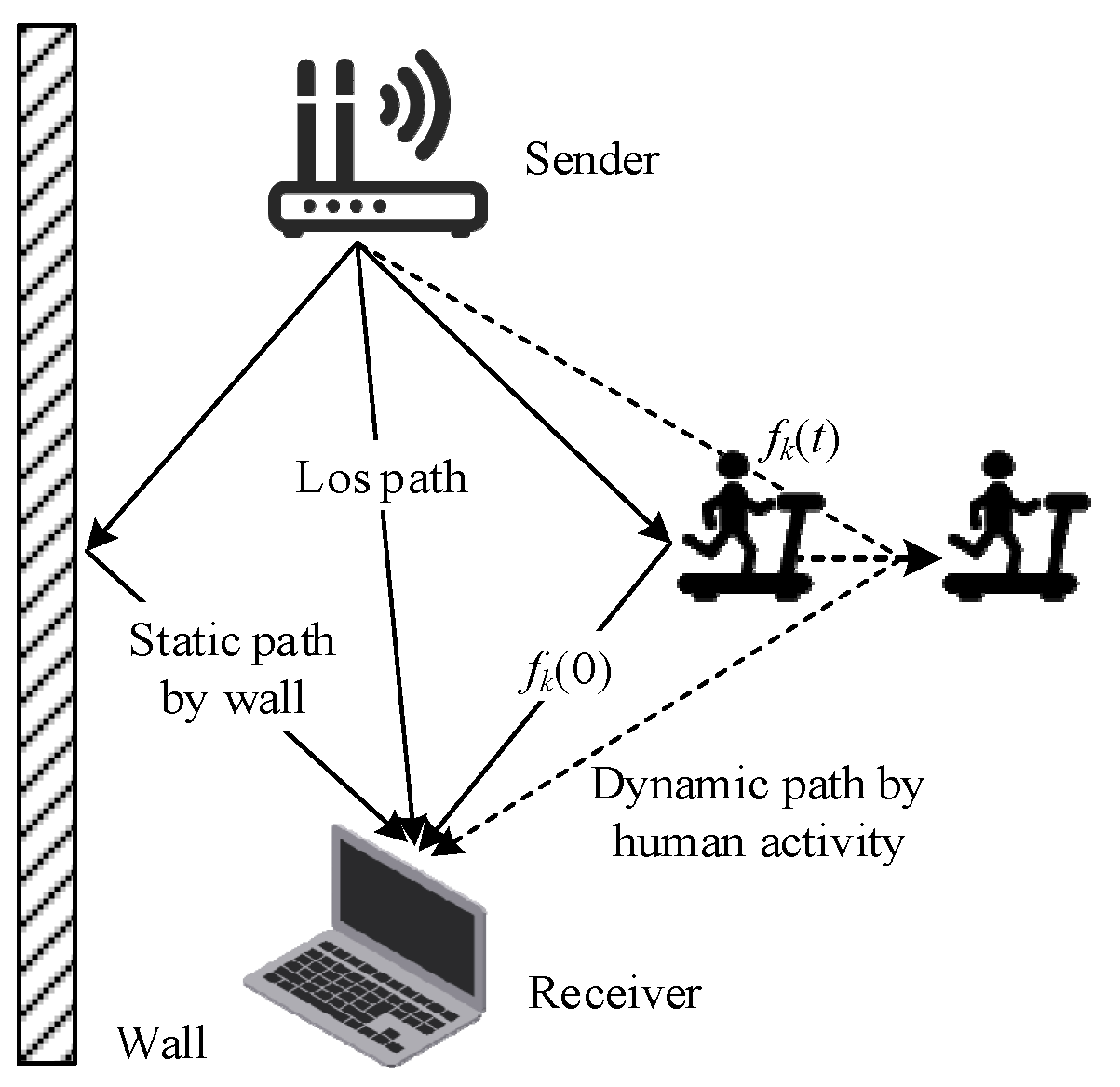
2.2. Human Activity Perception Principle
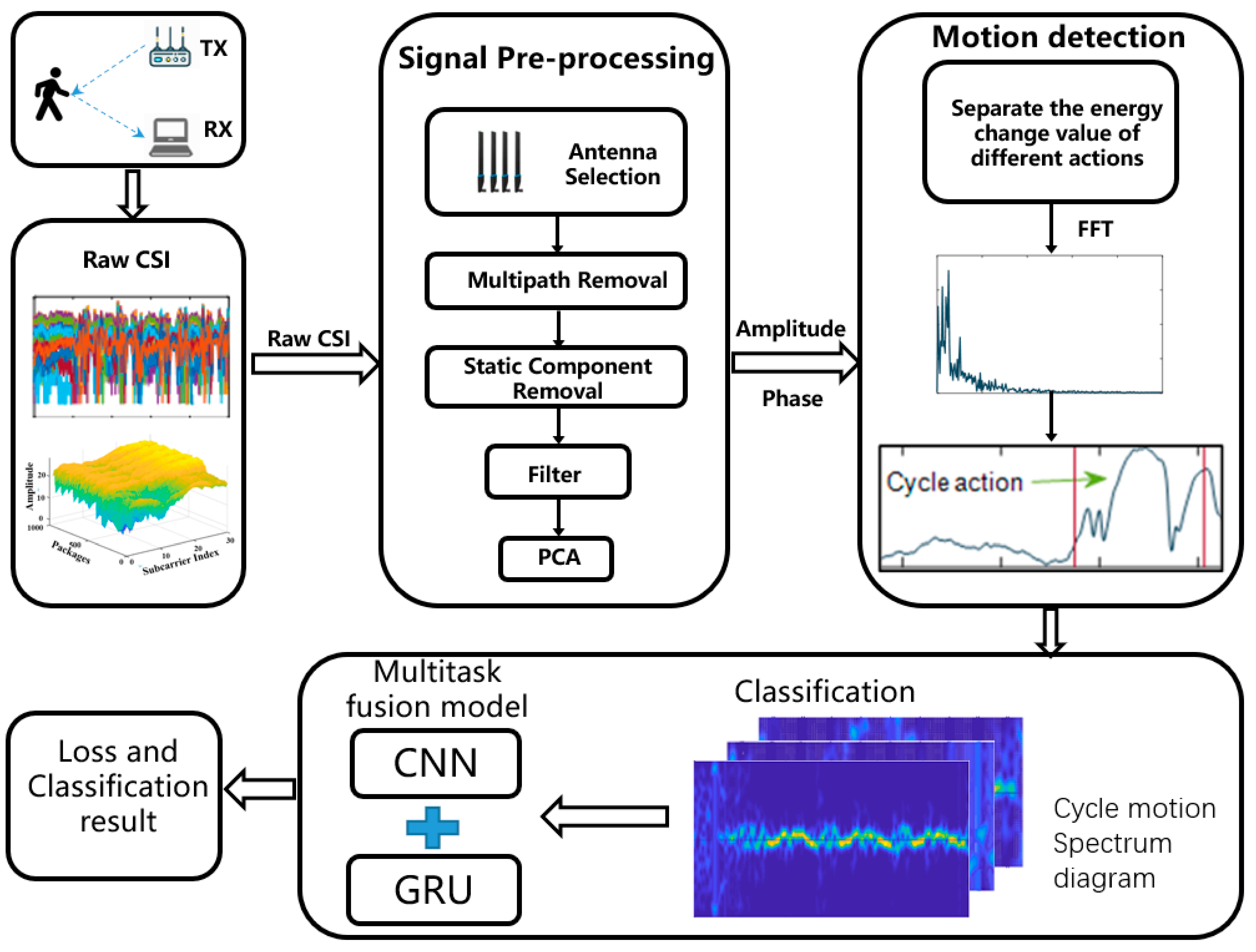
3. Data Preprocessing
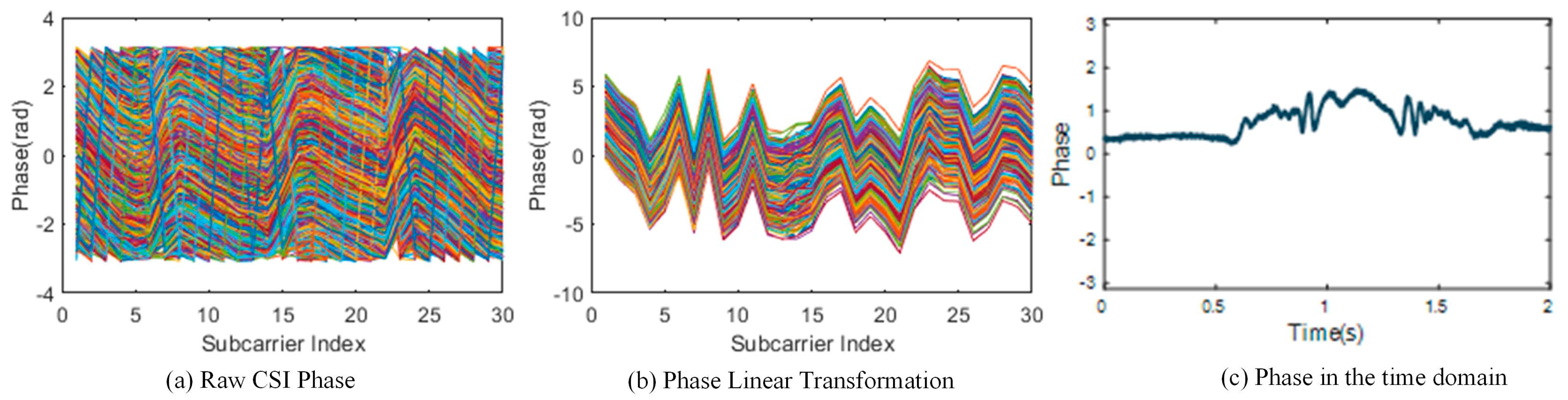
3.1. Phase Preprocessing
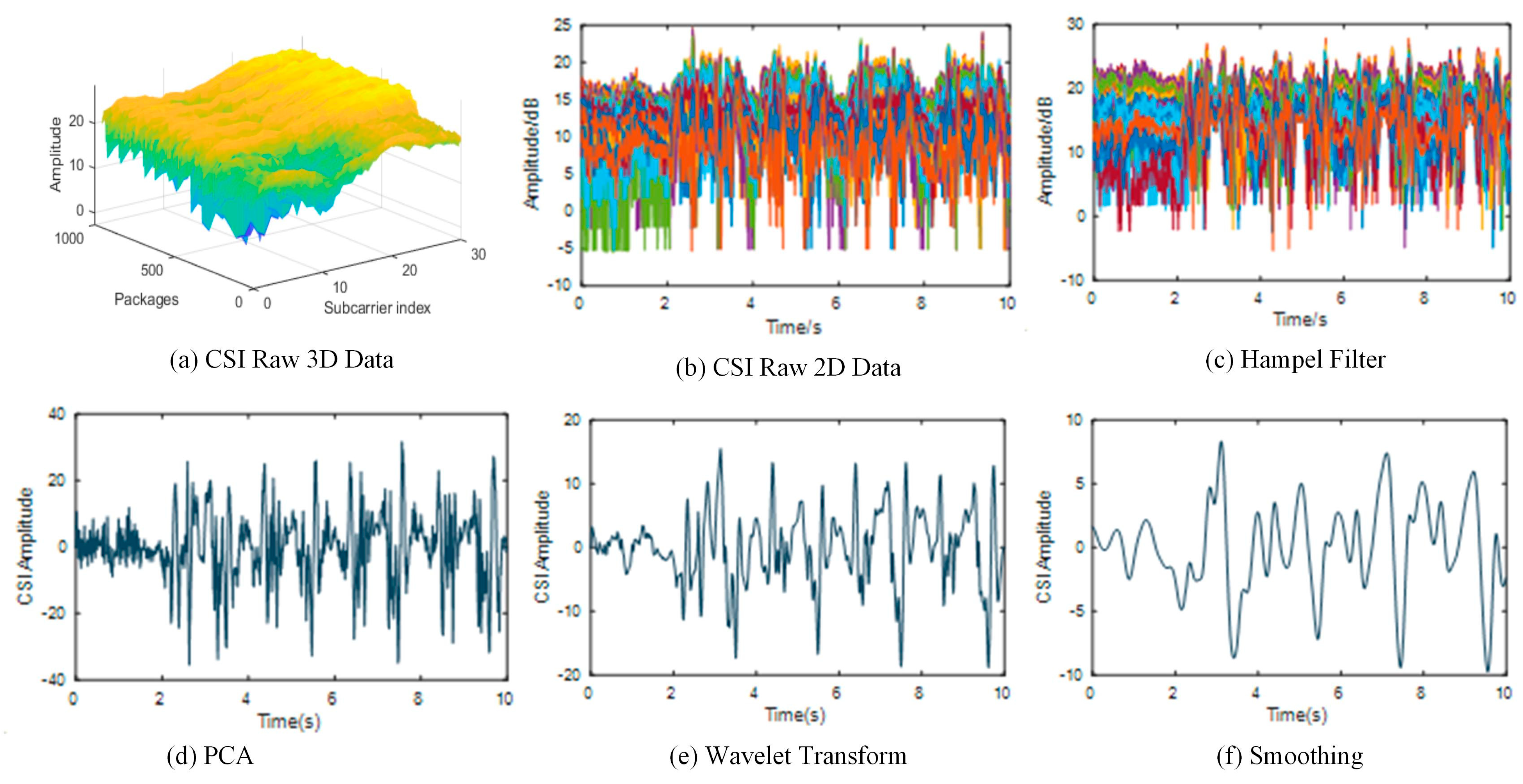
3.2. Amplitude Information
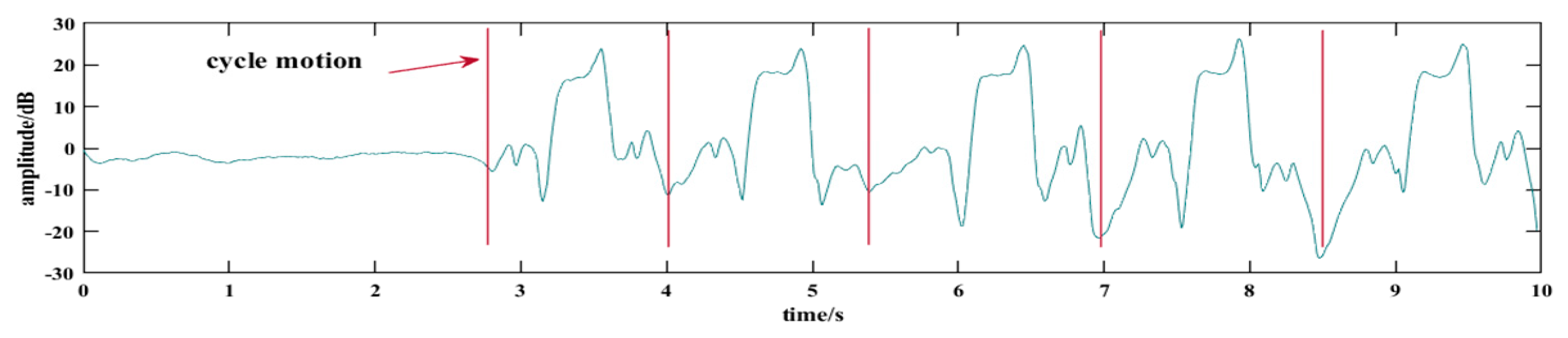
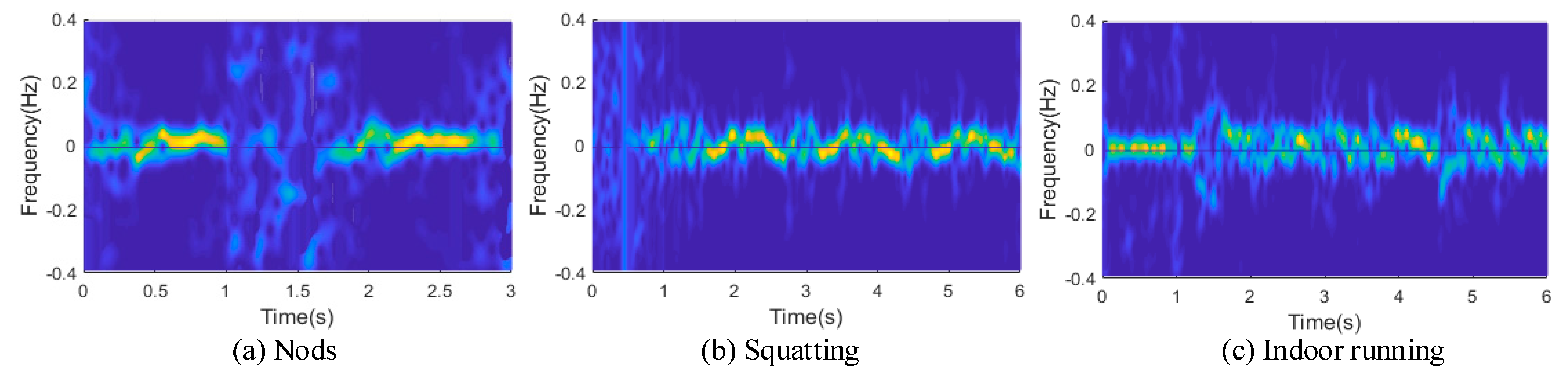
3.3. Cyclicity Segmentation
4. Methods of CSI-F
4.1. Overview
4.2. Data Processing and Feature Extraction
4.3. Human Activity Recognition Using CSI
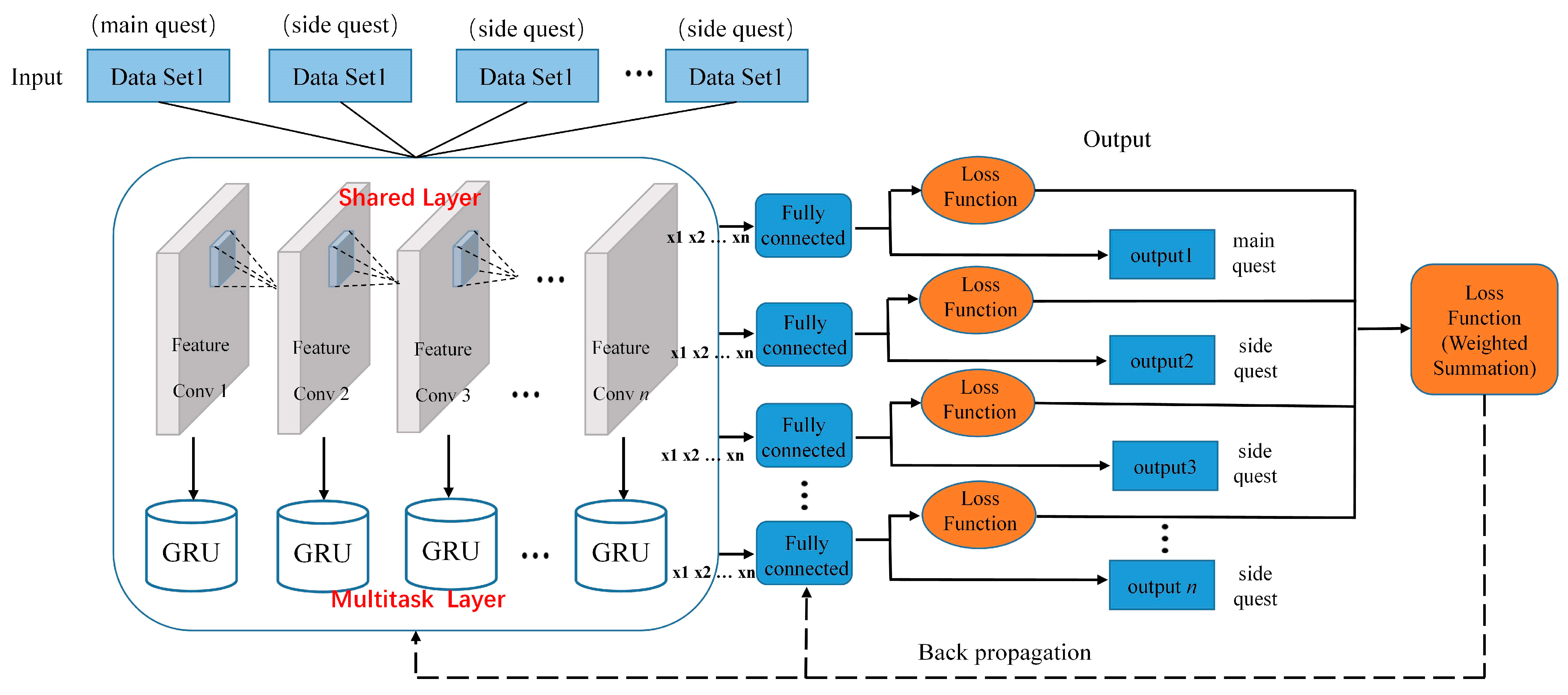
4.3.1. Shared Layer
4.3.2. Multitask Layer
4.3.3. The Training Process of the Model
| Algorithm 1: Motion recognition method |
| Input: training data set Dn (1 < n < N); The upper limit I of the learning time; Learning rate a initialize all adjustable parameters |
| Calculate Dn by Equation (10) |
| for i to I do |
| for n = 1 to N do |
| Calculate Ln by Equation (10) |
| end for |
| Calculate L by Equation (12) |
| If L stops decreasing after ten times then |
| break |
| end if |
| end for |
5. Experimental Design and Analysis
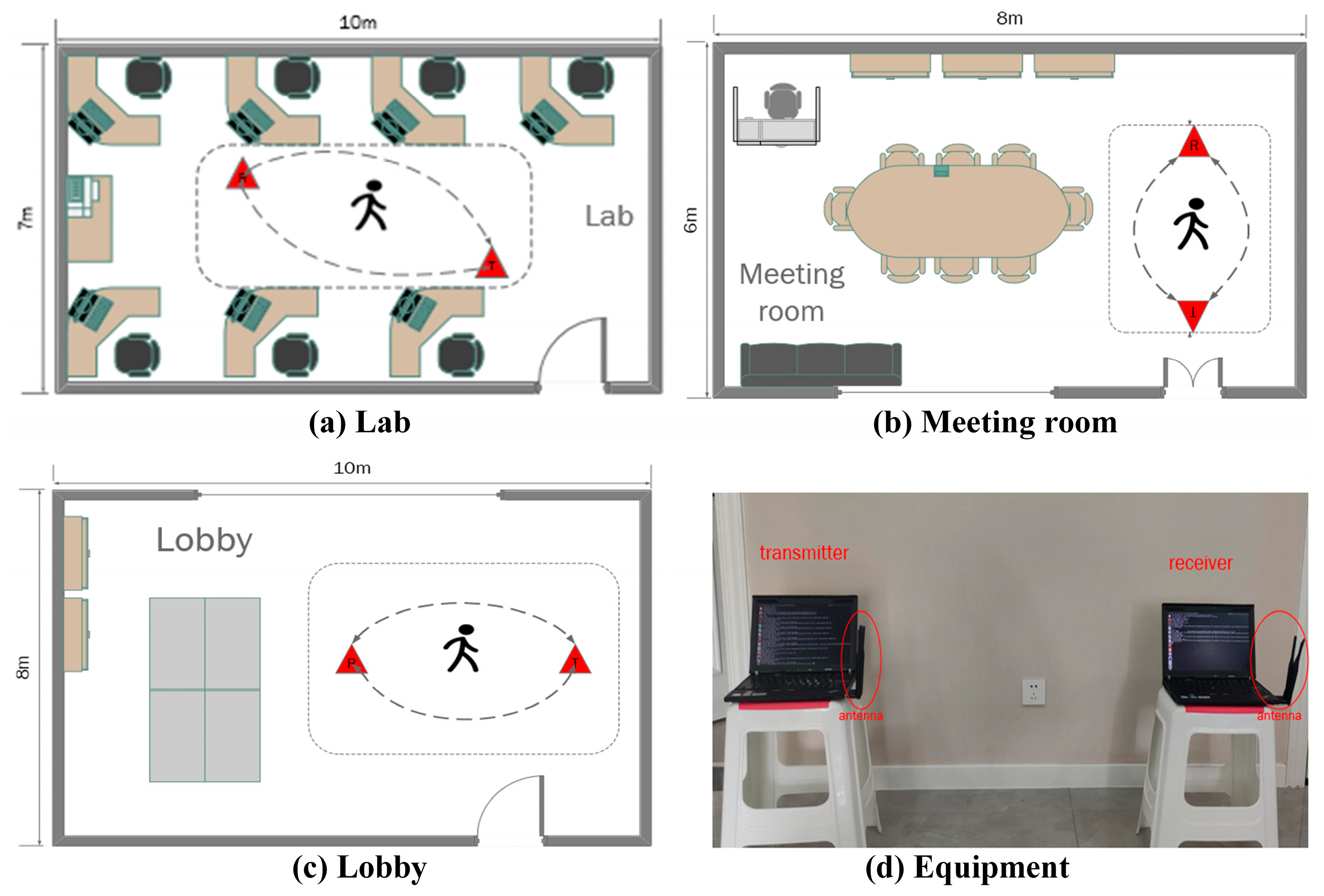
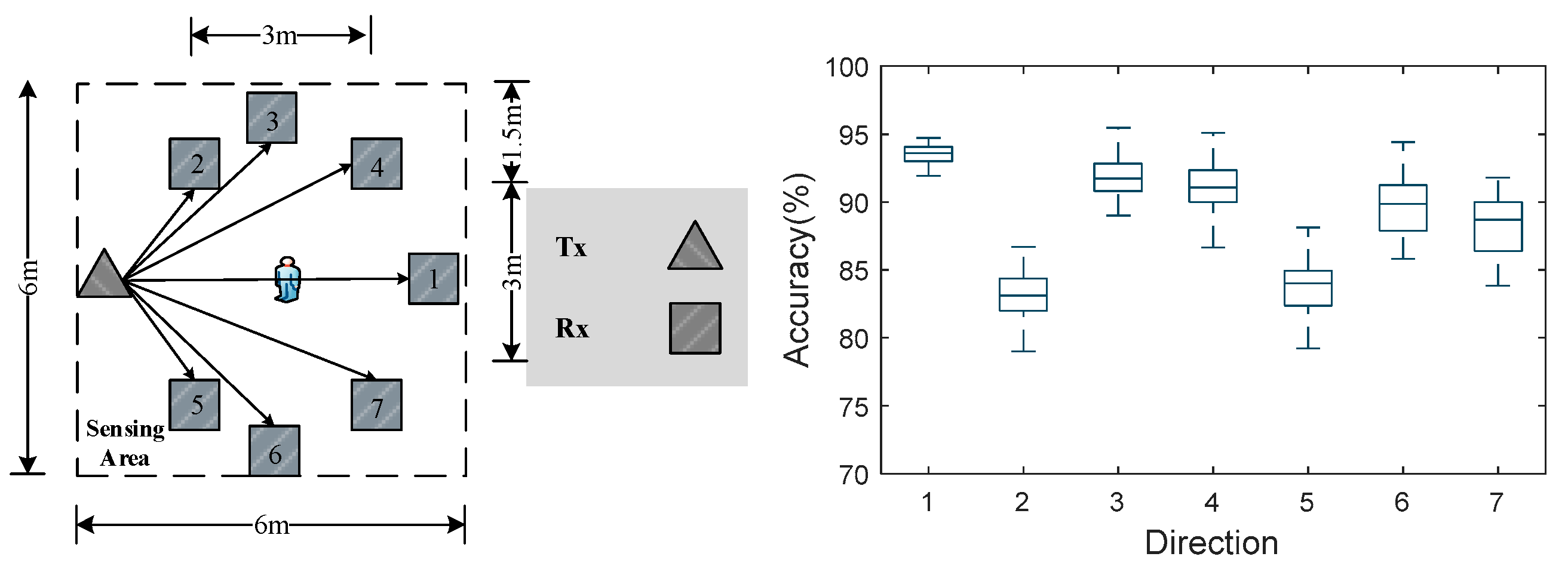
5.1. Experimental Setup
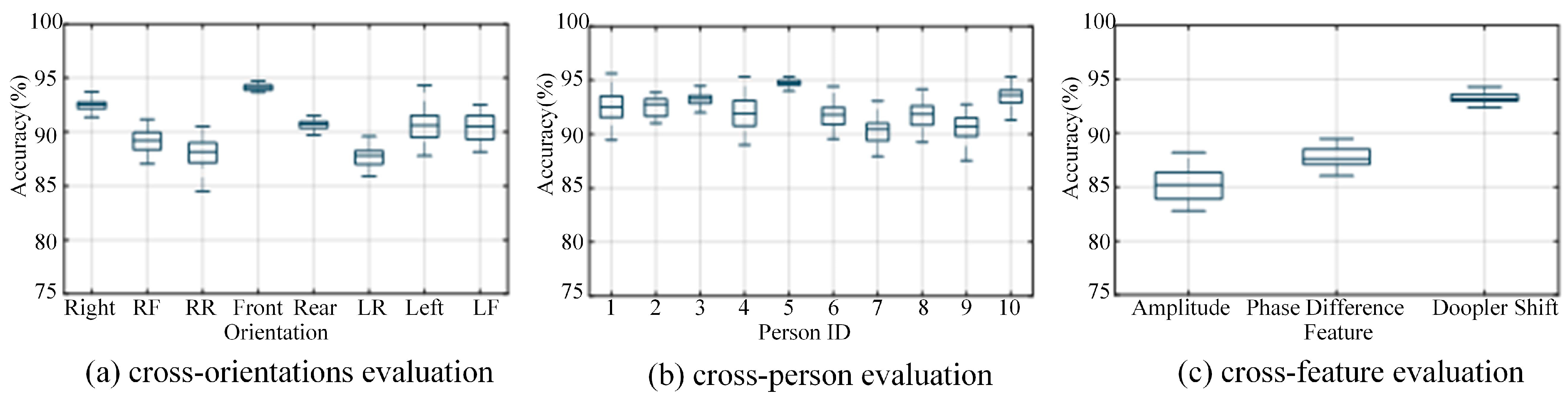
5.2. Experimental Factor Analysis
Overall Accuracy
- Orientation diversity
- 2.
- Personal variety
- 3.
- Feature difference
- 4.
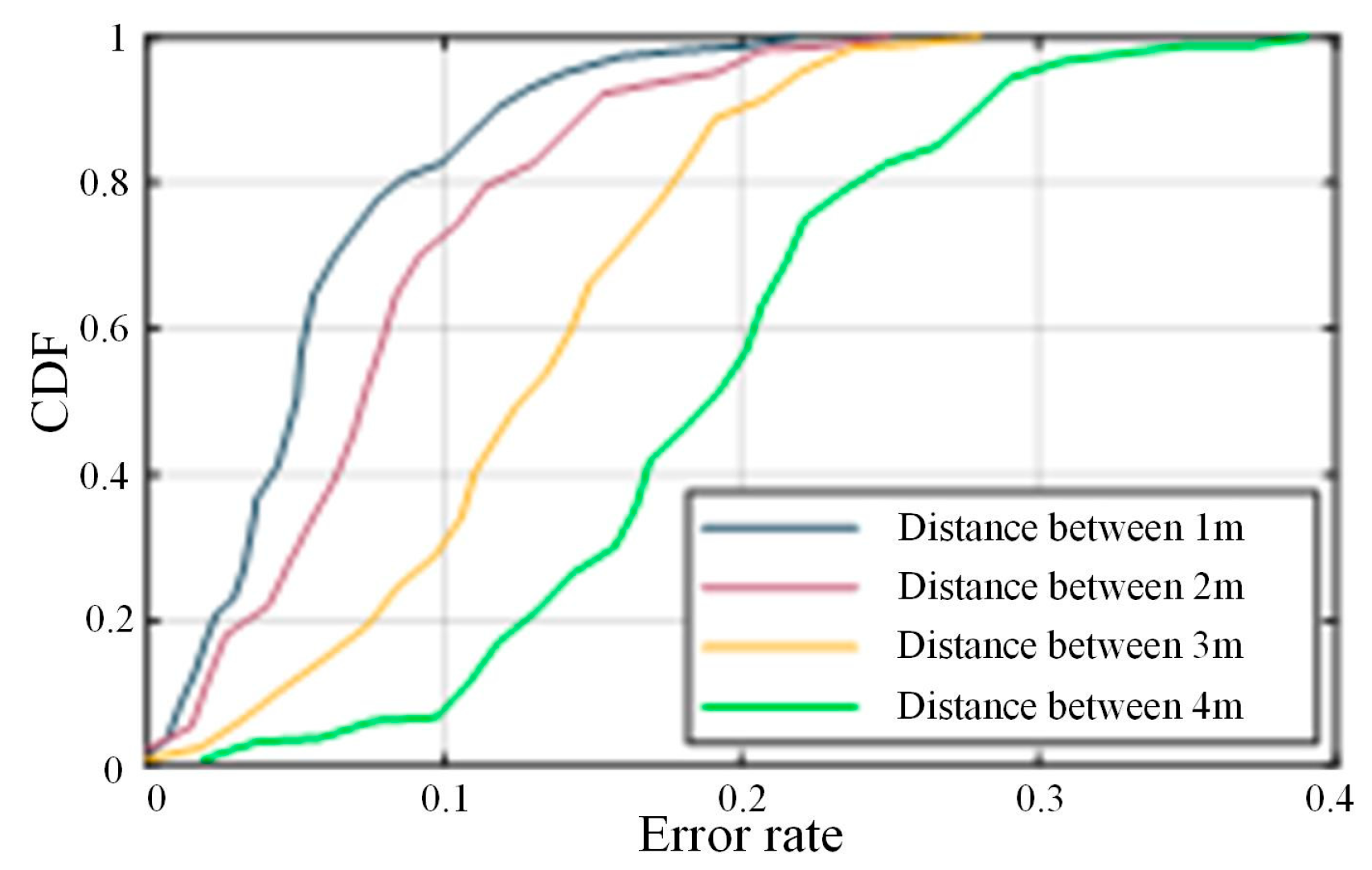
- Diversity of equipment parameters
- 5.
- Parameter difference
- 6.
- Difference in number of cycles
5.3. Comprehensive Performance Evaluation
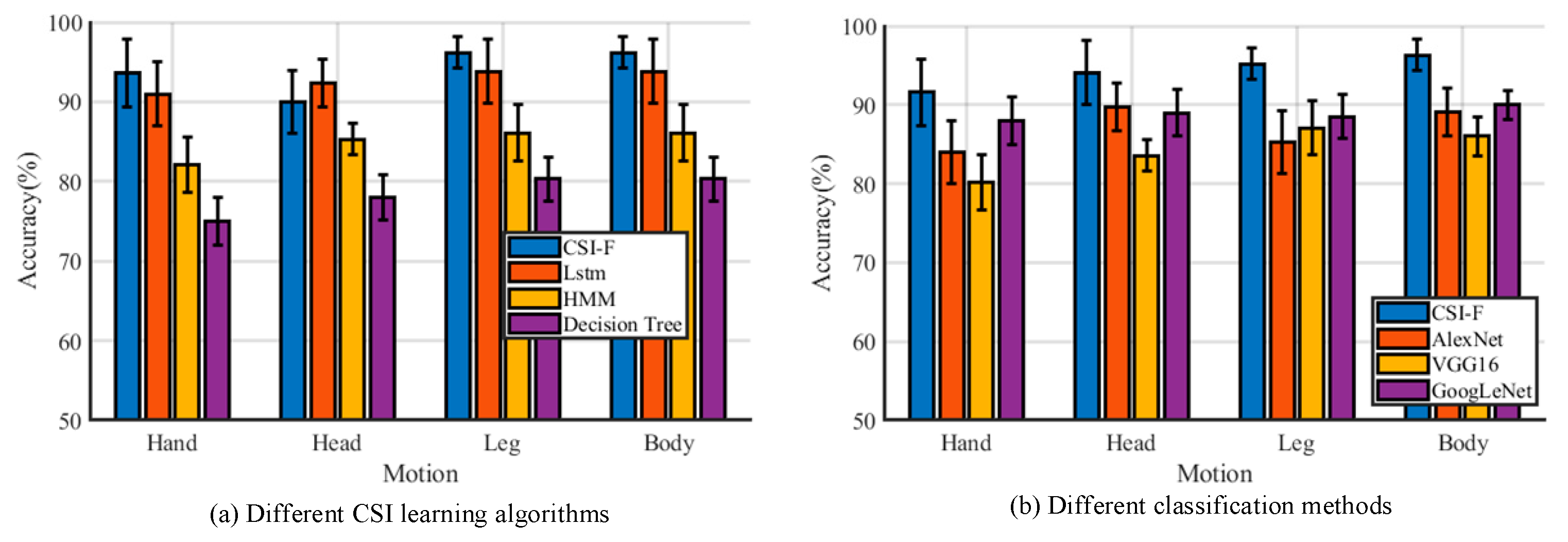
5.3.1. Evaluation of CSI-F’s Mobility
5.3.2. Comparison of Different Classification Algorithms
5.3.3. Comparison of Different Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, C.; Wang, W.; Zhang, Y.; Qin, J.; Yu, S.; Zhang, Y. An Indoor Localization System Using Residual Learning with Channel State Information. Entropy 2021, 23, 574. [Google Scholar] [CrossRef]
- Wang, D.; Guo, Z.; Gui, L.; Huang, H.; Xiao, F. WiPasLoc: A Novel Passive Indoor Human Localization Method Based on WiFi. Comput. Sci. 2022, 49, 259–265. [Google Scholar] [CrossRef]
- Li, L.; Guo, X.; Zhang, Y.; Ansari, N.; Li, H. Long Short-Term Indoor Positioning System via Evolving Knowledge Transfer. IEEE Trans. Wirel. Commun. 2022, 21, 5556–5572. [Google Scholar] [CrossRef]
- Xia, Z.; Chong, S. WiFi-based indoor passive fall detection for medical Internet of Things. Comput. Electr. Eng. 2023, 109, 108763. [Google Scholar] [CrossRef]
- Xiao, C.; Lei, Y.; Liu, C.; Wu, J. Mean Teacher-Based Cross-Domain Activity Recognition Using WiFi Signals. IEEE Internet Things J. 2023, 10, 12787–12797. [Google Scholar] [CrossRef]
- Cheng, X.; Huang, B. CSI-Based Human Continuous Activity Recognition Using GMM–HMM. IEEE Sens. J. 2022, 22, 18709–18717. [Google Scholar] [CrossRef]
- Liu, J.; Liu, H.; Chen, Y.; Wang, Y.; Wang, C. Wireless Sensing for Human Activity: A Survey. IEEE Commun. Surv. Tutor. 2020, 22, 1629–1645. [Google Scholar] [CrossRef]
- Niu, K.; Zhang, F.; Wu, D.; Zhang, D. Exploring Stability in WiFi Sensing System Based on Fresnel Zone Model. J. Front. Comput. Sci. Technol. 2021, 15, 60–72. [Google Scholar]
- Imran, H.A. Khail-Net: A Shallow Convolutional Neural Network for Recognizing Sports Activities Using Wearable Inertial Sensors. IEEE Sens. Lett. 2022, 6, 7003104. [Google Scholar] [CrossRef]
- Khan, Y.A.; Imaduddin, S.; Singh, Y.P.; Wajid, M.; Usman, M.; Abbas, M. Artificial Intelligence Based Approach for Classification of Human Activities Using MEMS Sensors Data. Sensors 2023, 23, 1275. [Google Scholar] [CrossRef]
- Chen, Y.; Sheng, A.; Qi, G.; Li, Y. Diffusion self-triggered square-root cubature information filter for nonlinear non-Gaussian systems and its application to the optic-electric sensor network. Inf. Fusion 2020, 55, 260–268. [Google Scholar] [CrossRef]
- Kulbacki, M.; Segen, J.; Chaczko, Z.; Rozenblit, J.W.; Kulbacki, M.; Klempous, R.; Wojciechowski, K. Intelligent Video Analytics for Human Action Recognition: The State of Knowledge. Sensors 2023, 23, 4258. [Google Scholar] [CrossRef] [PubMed]
- Eriş, H.A.; Ertürk, M.A.; Aydın, M.A. A Framework for Personalized Human Activity Recognition. Int. J. Pattern Recognit. Artif. Intell. 2023, 37, 2356016. [Google Scholar] [CrossRef]
- Lorenc, A.; Szarata, J.; Czuba, M. Real-Time Location System (RTLS) Based on the Bluetooth Technology for Internal Logistics. Sustainability 2023, 15, 4976. [Google Scholar] [CrossRef]
- Chen, K.; Wang, F.; Li, M.; Liu, B.; Chen, H.; Chen, F. HeadSee: Device-free head gesture recognition with commodity RFID. Peer-to-Peer Netw. Appl. 2022, 15, 1357–1369. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, J.; Tong, J.; Wu, X. UWB-radar-based synchronous motion recognition using time-varying range–Doppler images. IET Radar Sonar Navig. 2019, 13, 2131–2139. [Google Scholar] [CrossRef]
- Yu, G.; Lianghu, Q.; Fuji, R. WiFi-assisted human activity recognition. In Proceedings of the 2014 IEEE Asia Pacific Conference on Wireless and Mobile, Bali, Indonesia, 28–30 August 2014; pp. 60–65. [Google Scholar]
- Xiao, C.; Lei, Y.; Ma, Y.; Zhou, F.; Qin, Z. DeepSeg: Deep-Learning-Based Activity Segmentation Framework for Activity Recognition Using WiFi. IEEE Internet Things J. 2021, 8, 5669–5681. [Google Scholar] [CrossRef]
- Fang, Y.; Xiao, F.; Sheng, B.; Sha, L.; Sun, L. Cross-scene passive human activity recognition using commodity WiFi. Front. Comput. Sci. 2022, 16, 161502. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data Augmentation and Dense-LSTM for Human Activity Recognition Using WiFi Signal. IEEE Internet Things J. 2021, 8, 4628–4641. [Google Scholar] [CrossRef]
- Gu, Z.; He, T.; Wang, Z.; Xu, Y.; Tang, P. Device-Free Human Activity Recognition Based on Dual-Channel Transformer Using WiFi Signals. Wirel. Commun. Mob. Comput. 2022, 2022, 4598460. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, B.; Yu, Z.; Zhou, X. Wi-Fi CSI-Based Behavior Recognition: From Signals and Actions to Activities. IEEE Commun. Mag. 2018, 56, 109–115. [Google Scholar] [CrossRef]
- Niu, K.; Zhang, F.; Jiang, Y.; Xiong, J.; Lv, Q.; Zeng, Y.; Zhang, D. WiMorse: A Contactless Morse Code Text Input System Using Ambient WiFi Signals. IEEE Internet Things J. 2019, 6, 9993–10008. [Google Scholar] [CrossRef]
- Feng, C.; Arshad, S.; Zhou, S.; Cao, D.; Liu, Y. Wi-Multi: A Three-Phase System for Multiple Human Activity Recognition With Commercial WiFi Devices. IEEE Internet Things J. 2019, 6, 7293–7304. [Google Scholar] [CrossRef]
- Lu, Y.; Lv, S.H.; Wang, X.D.; Zhou, X.M. A Survey on WiFi Based Human Behavior Analysis Technology. Jisuanji Xuebao/Chin. J. Comput. 2019, 42, 231–251. [Google Scholar] [CrossRef]
- Hao, Z.; Duan, Y.; Dang, X.; Zhang, T. CSI-HC: A WiFi-Based Indoor Complex Human Motion Recognition Method. Mob. Inf. Syst. 2020, 2020, 3185416. [Google Scholar] [CrossRef]
- Tang, Z.; Zhu, A.; Wang, Z.; Jiang, K.; Li, Y.; Hu, F. Human Behavior Recognition Based on WiFi Channel State Information. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 1157–1162. [Google Scholar]
- Yan, H.; Zhang, Y.; Wang, Y.; Xu, K. WiAct: A Passive WiFi-Based Human Activity Recognition System. IEEE Sens. J. 2020, 20, 296–305. [Google Scholar] [CrossRef]
- Zhu, A.; Tang, Z.; Wang, Z.; Zhou, Y.; Chen, S.; Hu, F.; Li, Y. Wi-ATCN: Attentional Temporal Convolutional Network for Human Action Prediction Using WiFi Channel State Information. IEEE J. Sel. Top. Signal Process. 2022, 16, 804–816. [Google Scholar] [CrossRef]
- Zhang, C.; Jiao, W. ImgFi: A High Accuracy and Lightweight Human Activity Recognition Framework Using CSI Image. IEEE Sens. J. 2023, 23, 21966–21977. [Google Scholar] [CrossRef]




| Hyperparameter | Meaning | Hyperparameter | Meaning |
|---|---|---|---|
| Net activation | Deviation | ||
| Element-level multiplication | Lossn | Weighted sum of losses | |
| Weight value of task n | tanh | Activation function | |
| Sigmoid function | ReLU | Activation function |
| Model | Evaluation | Head Motion | Hand Motion | Leg Motion | Body Motion |
|---|---|---|---|---|---|
| WiAct | Accuracy | 0.750 | 0.865 | 0.90 | 0.931 |
| Wi-ATCN | Accuracy | 0.792 | 0.829 | 0.866 | 0.914 |
| ImgFi | Accuracy | 0.856 | 0.881 | 0.885 | 0.903 |
| CSI-F | Accuracy | 0.913 | 0.925 | 0.914 | 0.937 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, J.; He, X.; Fang, B.; Han, G.; Wang, X.; He, J. CSI-F: A Human Motion Recognition Method Based on Channel-State-Information Signal Feature Fusion. Sensors 2024, 24, 862. https://doi.org/10.3390/s24030862
Niu J, He X, Fang B, Han G, Wang X, He J. CSI-F: A Human Motion Recognition Method Based on Channel-State-Information Signal Feature Fusion. Sensors. 2024; 24(3):862. https://doi.org/10.3390/s24030862
Chicago/Turabian StyleNiu, Juan, Xiuqing He, Bei Fang, Guangxin Han, Xu Wang, and Juhou He. 2024. "CSI-F: A Human Motion Recognition Method Based on Channel-State-Information Signal Feature Fusion" Sensors 24, no. 3: 862. https://doi.org/10.3390/s24030862
APA StyleNiu, J., He, X., Fang, B., Han, G., Wang, X., & He, J. (2024). CSI-F: A Human Motion Recognition Method Based on Channel-State-Information Signal Feature Fusion. Sensors, 24(3), 862. https://doi.org/10.3390/s24030862