
Binary Transformer Based on the Alignment and Correction of Distribution


Abstract
1. Introduction
- A distribution alignment binarization method is proposed that addresses the problem of binary feature distribution deviation by median shift and mean restore. Distribution alignment binarization was performed on attention and full-connection layers, and it was further discussed that the effective binary operator is still under a constraint of maximum information entropy.
- This paper introduces a knowledge distillation architecture for distribution correction. The teacher–student structure is built according to the full-precision and binary transformers. By performing the counterpoint distillation on the query Q and key K in attention and combining the label output of the full-precision teacher network to calculate the cross-entropy loss of the binary student network, the integrity and accuracy of binary transformer data are ensured.
- Combining distribution alignment and distillation correction, we propose a novel transformer framework, ACD-BiT. While ensuring maximum information entropy, the feature distribution is consistent with the full-precision data to the greatest extent. To evaluate the effectiveness of the proposed model, experiments are conducted on various datasets, including CIFAR10, CIFAR100, ImageNet-1k, and TinyImageNet. The results show that the proposed model outperforms most of the existing mechanisms. This proves that both information entropy and data distribution are important factors affecting the performance of the binary transformer.
2. Related Works
2.1. Lightweight Transformers
2.2. Binary Networks
3. Methods
3.1. Preliminary
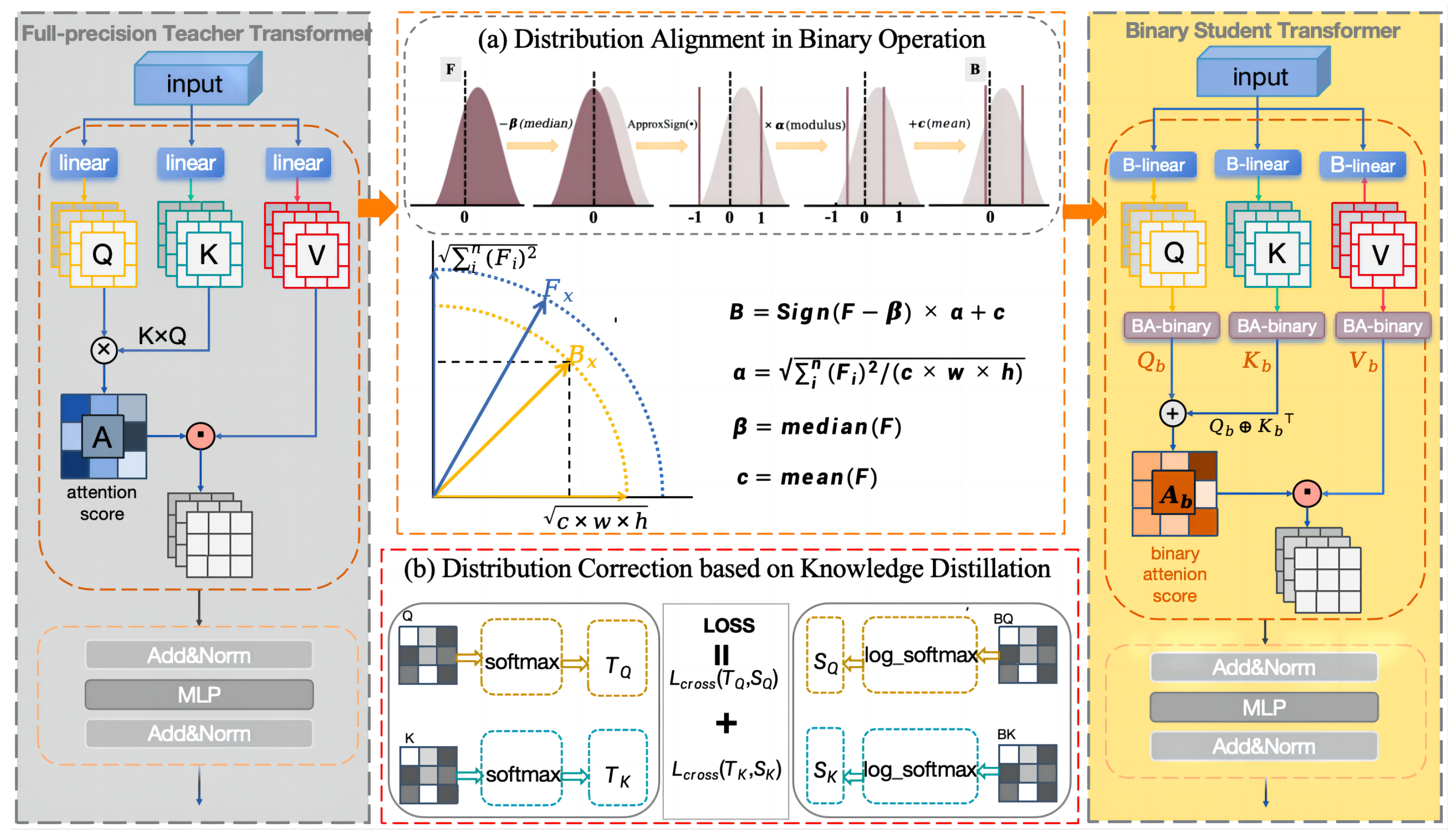
3.2. Overall Framework of Transformer Binarization
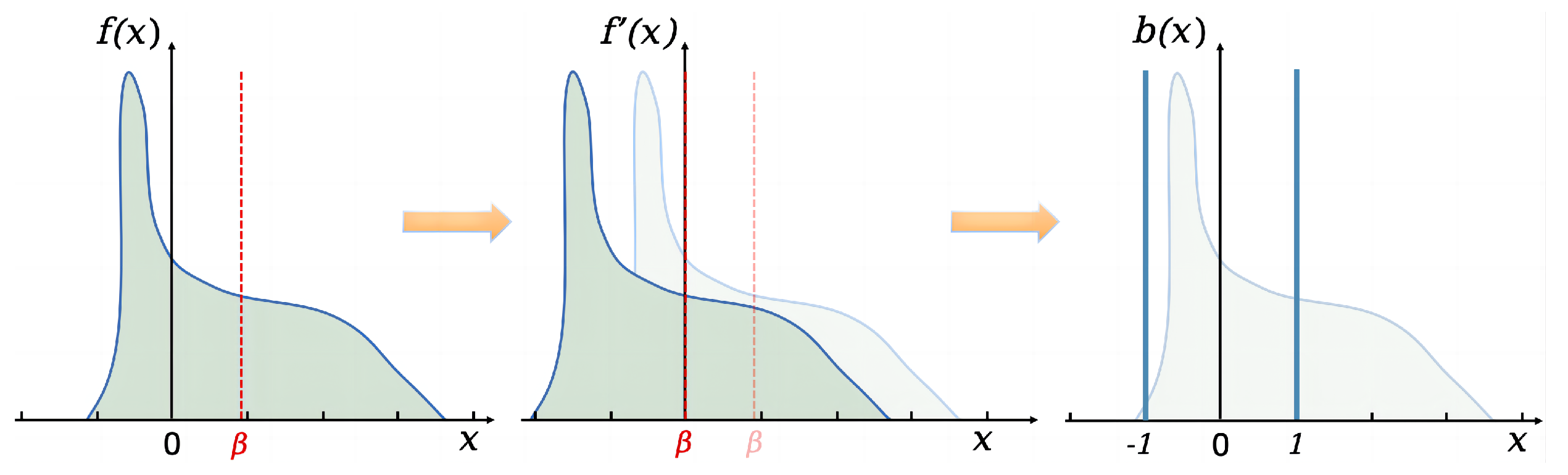
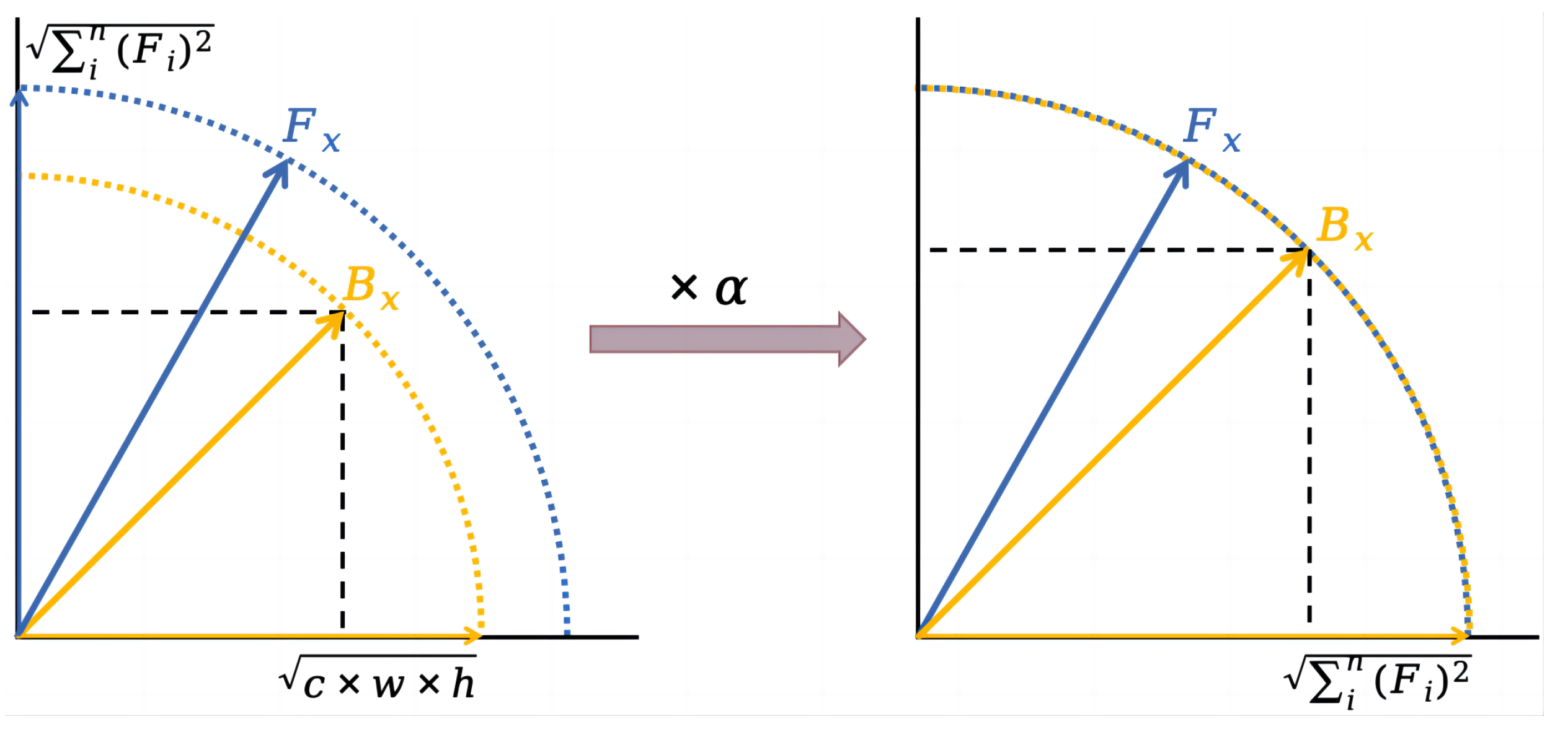
3.3. Distribution Alignment in Binary Operation
3.3.1. Binary Strategy for Distributed Alignment
3.3.2. Algorithm Flow in Attention
| Algorithm 1 Binary quantization in Attention |
|
3.4. Distribution Correction Based on Knowledge Distillation
4. Experiments
4.1. Implementation Details
- CIFAR10 [31] consists of 60,000 color images of size 32 × 32 divided into 10 categories with 6000 images each. It contains 50,000 training images and 10,000 test images, divided into five training batches and one test batch (each batch contains 10,000 images).
- CIFAR100 [31] contains 100 categories with 600 images per category. Each category is divided into 500 training images and 100 test images. The 100 categories are organized into 20 superclasses such that each image has a “fine” label and a “coarse” label.
- ImageNet-1k [32] consists of 1,281,167 training images and 50,000 validation images covering 1000 categories. Each image is carefully labeled and contains diverse and refined categories, making this one of the most complex large-scale image classification datasets.
- Tiny-ImageNet [32] is extracted from the ImageNet dataset and contains 100,000 images of 200 categories (500 for each class) downsized to 64 × 64 colored images. There are 500 training images and 50 test images for each class.
4.2. Hyperparameter Tuning Validation
4.3. Comparative Experiments and Analysis
4.3.1. Performance Comparison
4.3.2. Efficiency Comparison
4.3.3. Robustness Comparison
4.3.4. Comparative Experimental Analysis
4.4. Ablation Experiments and Analysis
4.4.1. Effectiveness of Two Modules in Binary Strategy
4.4.2. Ablation Experimental Analysis
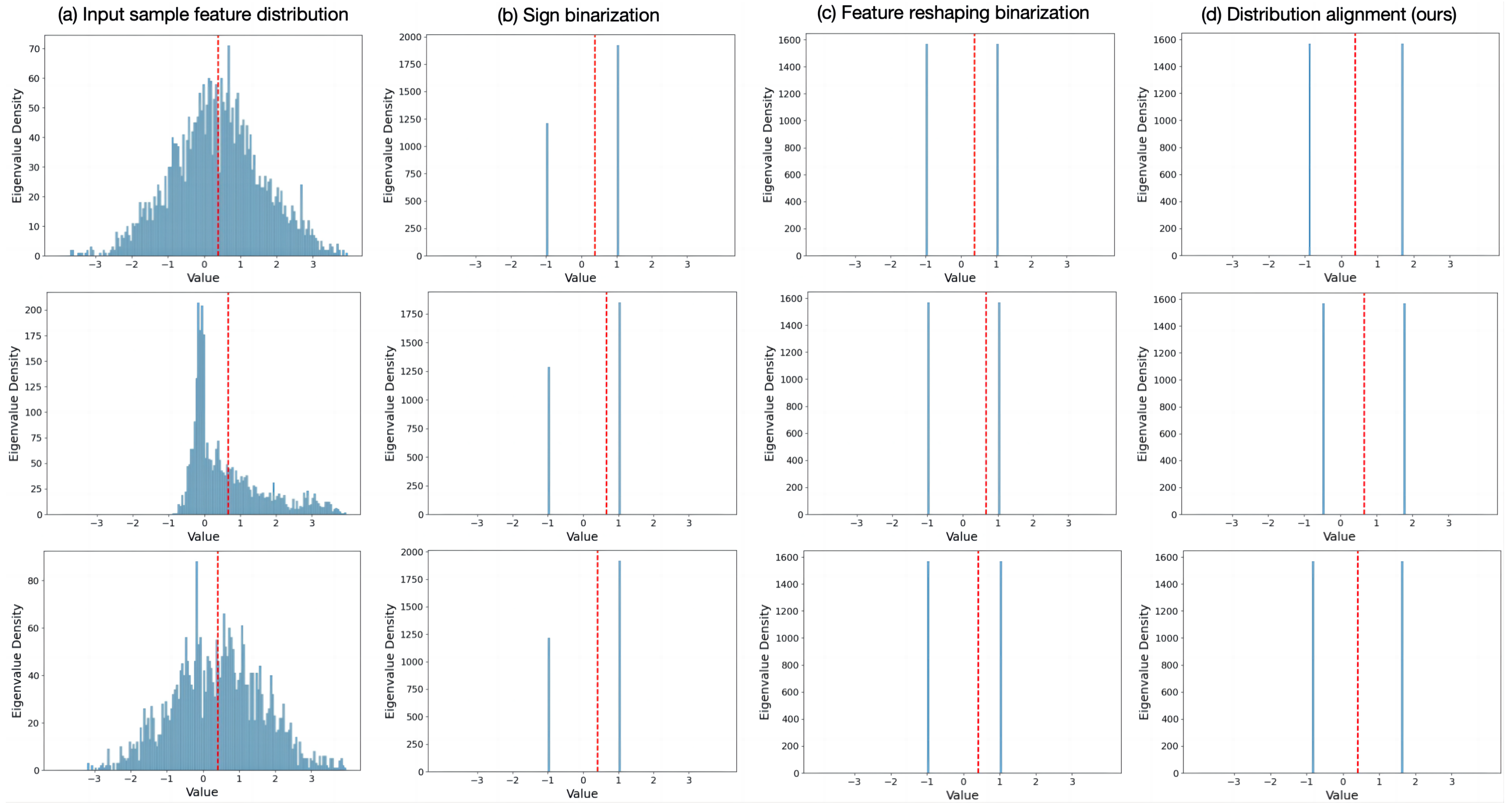
4.5. Visualization Analysis Experiments
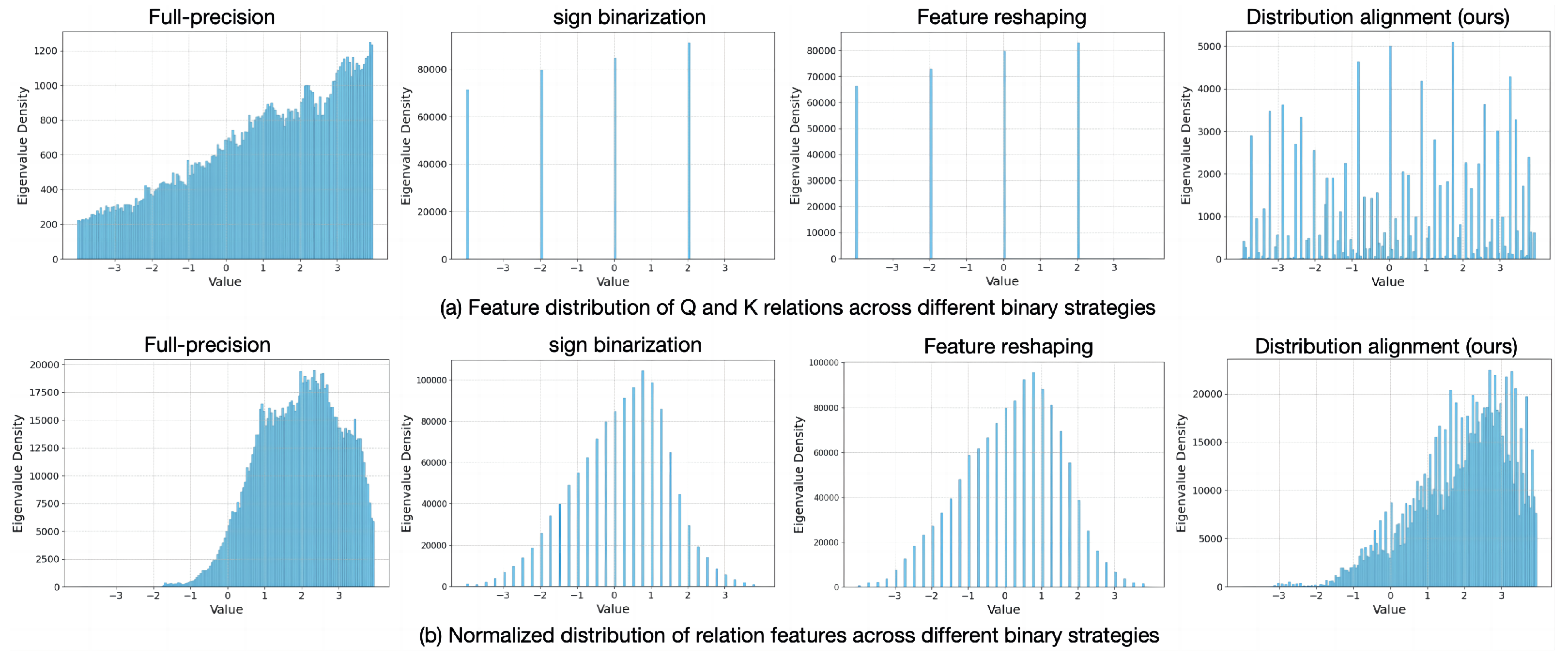
4.5.1. Effectiveness of Distribution Alignment
4.5.2. Performance of Feature Representation
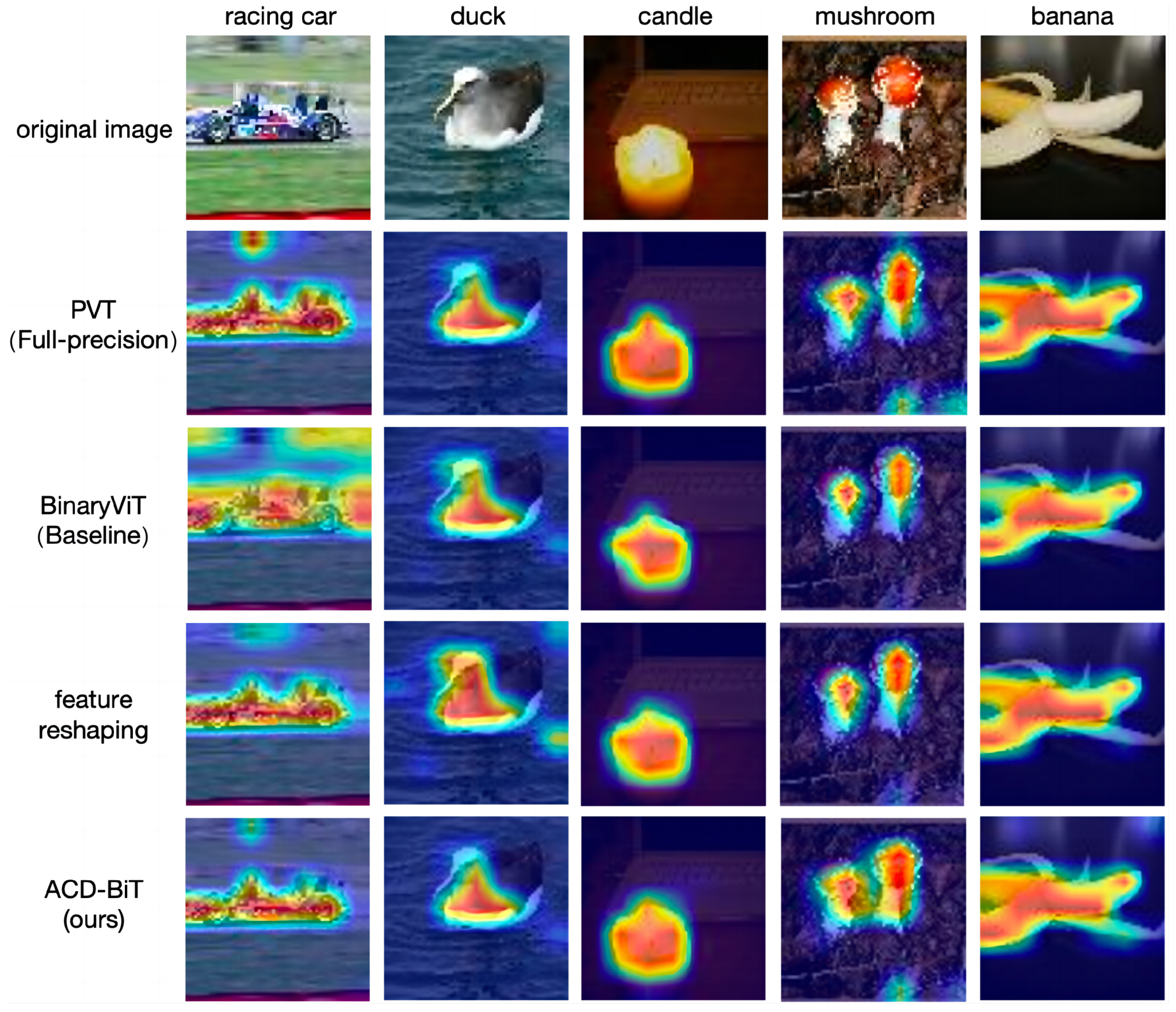
4.5.3. Attention Feature-Guided Visualization
4.5.4. Quantization Error Effect on Attention Matrix
4.5.5. Visual Experimental Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alexey, D.; Lucas, D.; Alexer, K.; Dirk, W.; Zhai, X.H.; Thomas, U.; Mostafa, D.; Matthias, M.; Georg, H.; Sylvain, G.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; Volume 1, p. 3. [Google Scholar]
- Liu, F.; Song, Q.; Jin, G. The classification and denoising of image noise based on deep neural networks. Appl. Intell. 2020, 50, 2194–2207. [Google Scholar] [CrossRef]
- Benjamin, G.; Alaaeldin, E.N.; Hugo, T.; Pierre, S.; Arm, J.; Hervé, J.; Matthijs, D. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12259–12269. [Google Scholar]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Nicolas, C.; Francisco, M.; Gabriel, S.; Nicolas, U.; Alexer, K.; Sergey, Z. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August, 2020; Volume 1, pp. 213–229. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7262–7272. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Zeng, K.; Wan, Z.; Gu, H.W.; Shen, T. Self-knowledge distillation enhanced binary neural networks derived from underutilized information. Appl. Intell. 2024, 54, 4994–5014. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, T.; Sun, P.; Li, Z.; Zhou, S. FQ-ViT: Post-training quantization for fully quantized vision transformer. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1173–1179. [Google Scholar]
- Narang, S.; Diamos, G.; Elsen, E.; Micikevicius, P.; Alben, J.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed precision training. In Proceedings of the Conference on Learning Representation, Toulon, France, 24–26 April 2017. [Google Scholar]
- Fan, A.; Stock, P.; Graham, B.; Grave, E.; Gribonval, R.; Jegou, H.; Joulin, A. Training with quantization noise for extreme model compression. In Proceedings of the Conference on Learning Representation, Vienna, Austria, 4–8 May 2021; pp. 1–13. [Google Scholar]
- Yuan, Z.; Xue, C.; Chen, Y.; Wu, Q.; Sun, G. PTQ4ViT: Post-training quantization framework for vision transformers. arXiv 2021, arXiv:2111.12293. [Google Scholar]
- Xu, S.; Li, Y.; Lin, M.; Gao, P.; Guo, G.; Lü, J.; Zhang, B. Q-detr: An efficient low-bit quantized detection transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3842–3851. [Google Scholar]
- Gu, J.; Li, C.; Zhang, B.; Han, J.; Cao, X.; Liu, J.; Doermann, D. Projection convolutional neural networks for 1-bit CNNs via discrete back propagation. In Proceedings of the Association for the Advancement of Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8344–8351. [Google Scholar]
- Wang, M.; Xu, Z.; Zheng, B.; Xie, W. BinaryFormer: A Hierarchical-Adaptive Binary Vision Transformer (ViT) for Efficient Computing. IEEE Trans. Ind. Inform. 2024, 20, 10657–10668. [Google Scholar] [CrossRef]
- Yuan, C.; AGaian, S.S. A comprehensive review of binary neural network. Artif. Intell. Rev. 2023, 56, 12949–13013. [Google Scholar] [CrossRef]
- Qin, H.; Zhang, X.; Gong, R.; Ding, Y.; Xu, Y.; Liu, X. Distribution-sensitive information retention for accurate binary neural network. Int. J. Comput. Vis. 2023, 131, 26–47. [Google Scholar] [CrossRef]
- Lin, M.; Ji, R.; Xu, Z.; Zhang, B.; Wang, Y.; Wu, Y.; Huang, F.; Lin, C.W. Rotated Binary Neural Network. Adv. Neural Inf. Process. Syst. (Neurips) 2020, 33, 7474–7485. [Google Scholar]
- Li, Y.; Xu, S.; Zhang, B.; Cao, X.; Gao, P.; Guo, G. Q-vit: Accurate and fully quantized low-bit vision transformer. Adv. Neural Inf. Process. Syst. (Neurips) 2022, 35, 34451–34463. [Google Scholar]
- Liu, C.; Ding, W.; Chen, P.; Zhuang, B.; Wang, Y.; Zhao, Y. RB-Net: Training highly accurate and efficient binary neural networks with reshaped point-wise convolution and balanced activation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6414–6424. [Google Scholar] [CrossRef]
- Tan, M.; Gao, W.; Li, H.; Xie, J.; Gong, M. Universal Binary Neural Networks Design by Improved Differentiable Neural Architecture Search. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 9153–9165. [Google Scholar] [CrossRef]
- Tu, Z.; Chen, X.; Ren, P.; Wang, Y. Adabin: Improving binary neural networks with adaptive binary sets. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 379–395. [Google Scholar]
- Yoshua, B.; Nicholas, L.; Aaron, C. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Messerschmitt, D. Quantizing for maximum output entropy (corresp.). IEEE Trans. Inf. Theory 1971, 17, 612. [Google Scholar] [CrossRef]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and backward information retention for accurate binary neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2250–2259. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Zhang, W.; Hou, L.; Yin, Y.; Shang, L.; Chen, X.; Jiang, X.; Liu, Q. Ternarybert: Distillation-aware ultra-low bit bert. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Aguilar, G.; Ling, Y.; Zhang, Y.; Yao, B.; Fan, X.; Guo, C. Knowledge distillation from internal representations. In Proceedings of the Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 7350–7357. [Google Scholar] [CrossRef]
- Le, P.H.C.; Li, X. BinaryViT: Pushing binary vision transformers towards convolutional models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4664–4673. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Computer Science University of Toronto: Toronto, ON, Canada, 2009; Volume 7. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Mohammad, R.; Vicente, O.; Joseph, R.; Ali, F. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Qin, H.; Ding, Y.; Zhang, M.; Yan, Q.; Liu, A.; Dang, Q.; Liu, Z.; Liu, X. BiBERT: Accurate fully binarized BERT. In Proceedings of the Conference on Learning Representation, Virtual, 25–29 April 2022; pp. 1–11. [Google Scholar]
- Liu, Z.; Oguz, B.; Pappu, A.; Xiao, L.; Yih, S.; Li, M.; Krishnamoorthi, R.; Mehdad, Y. BiT: Robustly binarized multi-distilled transformer. Adv. Neural Inf. Process. Syst. 2022, 35, 14303–14316. [Google Scholar]
- He, Y.; Lou, Z.; Zhang, L.; Liu, J.; Wu, W.; Zhou, H.; Zhuang, B. BiViT: Extremely compressed binary vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 5651–5663. [Google Scholar]
- Muhammad, M.B.; Yeasin, M. Eigen-CAM: Class activation map using principal components. In Proceedings of the International Joint Conference on Neural Network, Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| / | CIFAR10 (%) | CIFAR100 (%) | ||
|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | |
| 0.4/0.6 | 88.84 | 99.48 | 63.56 | 86.78 |
| 0.6/0.4 | 89.20 | 99.55 | 63.68 | 86.87 |
| 0.8/0.2 | 89.46 | 99.65 | 63.71 | 86.96 |
| 0.9/0.1 | 89.72 | 99.67 | 65.49 | 88.92 |
| Methods | W/A | Model Size | OPs | CIFAR10 (%) | CIFAR100 (%) | ImageNet-1k (%) | |||
|---|---|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | ||||
| ViT (Teacher) [1] | 32/32 | 86.9 M | 6.27 G | 91.63 | 99.74 | 79.59 | 92.40 | 80.0 | 94.94 |
| Mixed-Precision [11] | 16/16 | 47.8 M | 6.27 G | 94.58 | 99.79 | 83.06 | 97.13 | 76.02 | 92.52 |
| Quant-Noise [12] | 8/8 | 24.8 M | 6.27 G | 93.66 | 99.74 | 80.61 | 96.70 | 72.12 | 89.75 |
| FQ-ViT [10] | 8/4 | 13.4 M | 3.21 G | 92.21 | 99.60 | 77.84 | 95.84 | 64.79 | 86.58 |
| XNOR-Net [33] | 1/1 | 4.8 M | 3.21 G | 75.17 | 98.28 | 57.61 | 82.79 | 48.45 | 73.04 |
| BiBERT [34] | 1/1 | 4.8 M | 3.21 G | 80.13 | 98.77 | 58.45 | 83.04 | 50.32 | 77.73 |
| BiT [35] | 1/1 | 4.8 M | 3.21 G | 80.40 | 98.78 | 60.31 | 85.98 | 51.01 | 77.99 |
| BiViT [36] | 1/1 | 4.8 M | 3.21 G | 82.28 | 98.85 | 61.08 | 85.50 | 50.59 | 78.84 |
| BinaryViT (Baseline) [30] | 1/1 | 5.0 M | 3.27 G | 84.35 | 99.04 | 63.84 | 86.42 | 53.33 | 78.22 |
| BinaryFormer [16] | 1/1 | 4.8 M | 3.19 G | 87.07 | 99.30 | 64.27 | 86.22 | 54.46 | 80.82 |
| ACD-BiT (ours) | 1/1 | 5.0 M | 3.27 G | 89.72 | 99.67 | 65.49 | 88.92 | 58.76 | 81.61 |
| Modules | W/A | CIFAR10 (%) | CIFAR100 (%) | TinyImageNet (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Da | Dc | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | |
| - | - | 1/1 | 84.35 | 99.04 | 63.84 | 86.42 | 52.14 | 75.98 |
| √ | - | 1/1 | 87.61 | 99.27 | 64.62 | 87.81 | 54.13 | 76.76 |
| - | √ | 1/1 | 86.21 | 99.06 | 64.30 | 87.75 | 52.83 | 76.13 |
| √ | √ | 1/1 | 89.72 | 99.67 | 65.49 | 88.92 | 55.24 | 77.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Wang, M.; Wan, Z.; Shen, T. Binary Transformer Based on the Alignment and Correction of Distribution. Sensors 2024, 24, 8190. https://doi.org/10.3390/s24248190
Wang K, Wang M, Wan Z, Shen T. Binary Transformer Based on the Alignment and Correction of Distribution. Sensors. 2024; 24(24):8190. https://doi.org/10.3390/s24248190
Chicago/Turabian StyleWang, Kaili, Mingtao Wang, Zixin Wan, and Tao Shen. 2024. "Binary Transformer Based on the Alignment and Correction of Distribution" Sensors 24, no. 24: 8190. https://doi.org/10.3390/s24248190
APA StyleWang, K., Wang, M., Wan, Z., & Shen, T. (2024). Binary Transformer Based on the Alignment and Correction of Distribution. Sensors, 24(24), 8190. https://doi.org/10.3390/s24248190