1. Introduction
In recent years, there has been growing interest in developing Artificial Intelligence (AI) systems capable of accurately recognizing human emotions. This technology holds immense potential for applications in advertising, healthcare, and autonomous driving, among others [
1]. For example, in media effect studies used in advertising and promotion, human emotional values can serve as effective evaluation criteria [
2,
3]. Additionally, in the medical field, they can be utilized to support the diagnosis of diseases such as depression, dementia, and post-traumatic stress disorder (PTSD), as well as to assess stress and conditions in daily life [
4,
5]. In the field of autonomous driving technology, recognizing the emotions of the driver and combining them with information such as traffic and weather can enable the provision of optimal services [
6,
7].
Various approaches have been explored for emotion recognition, utilizing human facial expressions, voices, gestures, and texts [
8]. Among these, emotion estimation using biosignals is particularly promising [
9,
10]. Unlike facial expressions, gestures, and voices, biosignals are difficult to intentionally disguise, leading to potentially more accurate emotion estimation [
11,
12]. In particular, electroencephalogram (EEG) has become a popular non-invasive evaluation technique that is safe and easy to administer, leading to advancements in research exploring its relationship with emotions.
Various models such as Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN), and K-Nearest Neighbors (KNN) have been investigated for emotion estimation using EEG data [
13,
14,
15,
16]. However, these models often use fixed parameter settings, hindering their performance due to the insufficient optimization of parameters based on data characteristics. This highlights the need for methods that dynamically optimize model parameters. To address these limitations, we introduce Particle Swarm Optimization (PSO) to optimize the parameters of the LSTM model (number of units, batch size, dropout rate). PSO is a metaheuristic algorithm based on swarm intelligence, capable of efficiently finding optimal solutions in the entire search space [
17]. This allows for the more accurate capture of complex patterns in EEG data [
18].
Furthermore, to focus on the temporal and spatial features of EEG data, we incorporate an attention mechanism. The attention mechanism assigns weights to important parts of the input data, enabling the model to focus on significant information. This is expected to enhance the accuracy of emotion estimation by emphasizing the important features related to emotions in EEG data. By combining these techniques, we aim to improve the accuracy of emotion estimation based on EEG data.
This study focuses on the challenging task of four-class emotion classification, aiming to differentiate between high and low valence combined with high and low arousal states, with the goal of constructing a personalized model for each individual using Particle Swarm Optimization (PSO). Accurately classifying these emotional dimensions is crucial for effectively understanding and responding to human emotional states [
19]. To achieve this, we utilize two widely used datasets for human affective state analysis: the DEAP and SEED datasets. The DEAP dataset contains EEG and peripheral physiological signals recorded from 32 participants as they watched 40 one-minute-long video clips designed to elicit different emotional responses [
20]. The participants rated each video based on valence, arousal, liking, and dominance, allowing for a comprehensive analysis of emotional states. The SEED dataset comprises EEG data recorded from 15 subjects while watching 15 video clips, each approximately 4 min long [
21,
22]. The experiments were conducted three times for each subject, and each video was labeled as negative, neutral, or positive. Both datasets include preprocessed EEG signals, which are downsampled, filtered, and segmented into epochs, making them suitable for various emotion recognition tasks.
The remainder of this paper is organized as follows:
Section 2 reviews the previous research on emotion estimation using EEG.
Section 3 outlines the foundational technologies of this study, including LSTM, PSO, and the attention mechanism.
Section 4 covers the preprocessing methods for EEG data and the attention-based PSO-LSTM model.
Section 5 presents the experimental content, results, and discussion.
Section 6 discusses the limitations of our approach and potential directions for future research. Finally,
Section 7 provides a conclusion.
2. Related Research
EEG-based emotion recognition has seen significant advancements in recent years, with researchers exploring various datasets, methodologies, and learning techniques to improve emotion classification accuracy. This section discusses the key trends, challenges, and contributions from prior work, focusing on how they align with and differ from the current study.
Most studies utilized well-known datasets like DEAP and SEED, ensuring comparability of the results. However, the performance of these datasets can vary significantly based on the methodology and preprocessing techniques employed. The DEAP dataset, which includes EEG signals from 32 participants watching one-minute emotional video clips, is widely regarded for its balanced emotional stimuli and comprehensive annotations. Studies such as those of Marjit et al. (2021), Ajith et al. (2021), Nandi et al. (2021), and Bazargani et al. (2023) evaluated their methods for four-class emotion classification using the DEAP dataset [
23,
24,
25,
26]. Lin et al. (2023) and Deng et al. (2021) conducted evaluations using both the DEAP and SEED datasets [
27,
28], showing the effectiveness of validation across multiple datasets. The SEED dataset provides EEG recordings of subjects watching emotional film clips categorized into positive, neutral, and negative states. While both datasets aim to capture emotional states, they offer different characteristics: DEAP features shorter, varied clips with four-class classification, while SEED emphasizes longer-term responses with three-class classification.
We utilize DEAP and SEED datasets in this work to thoroughly validate our proposed PSO-LSTM approach. This dual-dataset evaluation strategy allows us to demonstrate the robustness and generalizability of our method across different experimental conditions, emotional categorizations, and temporal scales. By testing both datasets, we can provide a more comprehensive assessment of our model’s performance compared to existing benchmarks.
Most studies have focused on classifying emotions using the valence–arousal model, typically employing either binary (valence–arousal) or four-class emotion classification approaches.
A clear trend has emerged toward employing deep learning models to capture the spatiotemporal dynamics of EEG signals. Studies used handcrafted features such as Power Spectral Density (PSD) as seen in the work of Marjit et al. (2021). They utilized Power Spectral Density (PSD) features with a Genetic Algorithm-optimized Multi-Layer Perceptron (MLP), achieving high accuracies of 91% for binary classification and 83.52% for four-class classification. More recent efforts, like those of Deng et al. (2021) and Lin et al. (2023), leveraged advanced neural networks (e.g., CNNs and GNNs) to automatically learn the spatial and temporal features from raw EEG data. Their 3D Convolutional Neural Network approach achieved binary classification accuracies of 92.49% for valence and 91.94% for arousal, with a four-class classification accuracy of 74.23%. Lin et al. (2023) employed graph neural networks to extract intra- and inter-channel EEG features, demonstrating the importance of functional connectivity. Their approach achieved impressive four-class classification accuracies of 90.74% on the DEAP-Twente dataset and 91% on the DEAP-Geneva dataset. Bazargani et al. (2023) presented a lightweight deep learning model for emotion recognition, emphasizing binary classification. Their subject-dependent method achieved exceptionally high accuracies of 99.10% for valence and 99.20% for arousal, while the subject-independent method yielded accuracies around 90.76% for valence and 90.94% for arousal. Kan et al. (2023) proposed a self-supervised group meiosis contrastive learning framework that reduces reliance on labeled data [
29]. Their binary classification results showed accuracies of 94.72% for valence and 95.68% for arousal. Ajith et al. (2021) emphasized the significance of Convolutional Neural Networks (CNNs) for temporal feature extraction, focusing on classifying emotions into valence and arousal classes.
Multiple works highlight the importance of accounting for inter-subject variability. For example, Bazargani et al. (2023) demonstrated significantly higher accuracy in subject-dependent setups, a finding echoed by Lin et al. (2023). Such variability emphasizes the need for approaches like PSO, which dynamically optimize model parameters for individual subjects.
Kan et al. (2023) addressed the challenge of limited labeled data using contrastive learning, showcasing the potential for semi-supervised methods to reduce dependency on extensive labeling, a recurring limitation in the field.
Some studies extended EEG-based emotion recognition to real-time contexts, emphasizing practical applications such as e-learning. For instance, Nandi et al. (2021) proposed a real-time emotion classification system designed for educational environments, which processed EEG data streams to recognize emotional states in dynamic settings.
A recurring issue in EEG-based emotion recognition lies in the lack of standardization in testing and validation. Studies vary in their use of subject-dependent or subject-independent setups and cross-validation strategies. For instance, while Bazargani et al. (2023) reported results under both setups, Marjit et al. (2021) primarily focused on subject-dependent approaches. Such differences complicate the direct comparisons between methods. This study mitigates these challenges by maintaining a consistent evaluation protocol on both DEAP and SEED datasets, aligning with the most common practices in the field.
Unlike prior efforts that often relied on fixed model architectures or limited optimization strategies, this study employs advanced optimization techniques to dynamically adapt to individual subject variations. By maintaining a consistent evaluation protocol and focusing on maximizing four-class classification accuracy, the research aims to address existing methodological challenges and contribute to the evolving landscape of EEG-based emotion recognition.
3. Related Technology
3.1. Long Short Term Memory
Long Short-Term Memory (LSTM) is a kind of Recurrent Neural Network (RNN) model that is capable of processing time series data and was proposed by Hochreiter and Schmidhuber in 1997 [
17]. Compared to conventional RNNs, LSTM can store time-series data for extended periods. Due to its specialization in handling time-series data, LSTM has been widely used in the field of emotion estimation using EEG data [
30,
31]. In RNNs, the gradient of the objective function is used to update the parameters when learning them by backpropagation, but there is a problem, where the gradient disappears when the number of iterations exceeds a specific number. On the other hand, LSTM mitigates this issue by using a cell state that is updated through linear summation, which helps prevent excessive fluctuation of the gradient. While LSTMs still utilize sigmoid and tanh functions within their gates, the linear update of the cell state is key in preventing gradient loss [
32,
33].
Figure 1 illustrates the internal structure of an LSTM. In this context,
,
, and
represent the hidden state at time
t, the cell state, and the input vector at time
t, respectively. Additionally,
and tanh denote the sigmoid and hyperbolic tangent functions, respectively. LSTM has three gates: a forget gate, an input gate, and an output gate, which enable long-term memory storage. The hidden state
of LSTM is calculated as follows:
where
and
represent the input vector and cell state, respectively, while
and
are the weight matrix and bias. In Equation (1), the forget gate vector
is a weight vector that expresses how much of the previous cell state should be forgotten. In Equation (2), the input gate vector
is a weight vector that expresses how much information should be added to the cell state
. In Equation (4), the candidate cell state
is computed using the tanh function, which introduces nonlinearity into the cell state. These two gates together allow the cell state
to be updated as a linear combination of the previous cell state and the candidate cell state
as shown in Equation (5). In Equation (3), the output gate vector
is the weight vector that determines how much information from the cell state
should be transferred to the hidden state
. Finally, in Equation (6), the cell state
is passed through a
function and modulated by the output gate to produce the hidden state
.
3.2. Particle Swarm Optimization
Particle Swarm Optimization (PSO) is a heuristic optimization algorithm inspired by the social behavior of organisms, particularly bird flocking or fish schooling [
34,
35]. Introduced by Kennedy and Eberhart in 1995, PSO aims to iteratively improve a candidate solution’s fitness by mimicking the social interactions among particles in a multidimensional search space [
36]. In PSO, a population of potential solutions, termed “particles”, moves through the search space, guided by their own best-known position
and the global best-known position
of the entire swarm. Each particle adjusts its position
and velocity
based on these two factors, aiming to converge towards optimal solutions. Position
and velocity
are calculated as follows:
where
and
are uniformly distributed random numbers in the range [0, 1], generated at each iteration. In Equation (7), the velocity
is calculated by a linear combination of the particle’s momentum, the cognitive component (personal best-known position
), and the social component (global best-known position
). PSO has shown potential in finding optimal solutions for loss functions with multimodal features by helping to avoid local solutions, although it does not guarantee global optimality.
3.3. Attention Mechanism
The attention mechanism is one of the techniques used in the field of machine learning and natural language processing, particularly useful when processing sequential data such as text or time series. The attention mechanism improves model performance by allowing the model to focus on essential parts of the input data, effectively mimicking how humans pay selective attention to specific pieces of information when processing a large amount of data [
37]. In this paper, we introduce an attention mechanism to calculate the weight vector for each hidden state of an LSTM. This allows the model to determine which sequence parts are most relevant at each step of the computation [
38]. The attention mechanism is calculated as follows:
In Equation (9), a score function is defined to compute the relevance (or association) between the hidden state at each time t and the hidden state at the final time step n. In this score function, the hidden states and are combined and linearly transformed using the matrix . Then, a bias term is added to it, and the tanh function is applied to obtain the final score. In Equation (10), the attention weight at each time step t is calculated using the score function, which computes the association between the hidden state and the final hidden state at the last time n. In Equation (11), the context vector is created by taking a weighted sum of the hidden states . The weights (from Equation (10)) determine how much attention the model gives to each time step when forming the context vector. This context vector is then used by the model to make predictions.
4. Methodology
4.1. DEAP Dataset
The Database for Emotion Analysis using Physiological Signals (DEAP) is a dataset for emotion analysis [
20]. The DEAP dataset is a benchmark dataset for emotion estimation research using EEG and has been widely used in many previous studies. Therefore, we also adopted this dataset for our research. It includes 32-channel EEG signals and 8-channel peripheral physiological signals recorded from 32 subjects as they watched 40 music videos, each with a duration of 63 s. The peripheral biosignals provide valuable insights into the participants’ physiological responses to the stimuli and include Galvanic Skin Response (GSR), heart rate (HR), and Electromyography (EMG). These signals measure changes in skin conductance, heart rate, and muscle activity, respectively, which are often associated with emotional arousal, stress, and emotional expression.
The music videos were selected in a pre-experiment to avoid bias in the elicited emotions. For each video, the EEG data consisted of 3 s baseline data and 60 s experimental data. The EEG data were measured with 32 electrodes installed in accordance with international regulations. After viewing the music videos, the 32 subjects completed subjective ratings of four evaluation items: arousal, valence, liking, and dominance. These ratings were obtained using a 9-point Likert scale, where 1 represents the lowest level, and 9 represents the highest. Arousal expresses the intensity of emotion, and valence indicates the degree of pleasantness or unpleasantness, both ranging from 1 to 9. Liking represents the degree of preference, while dominance is an index expressing the degree of emotional control or influence.
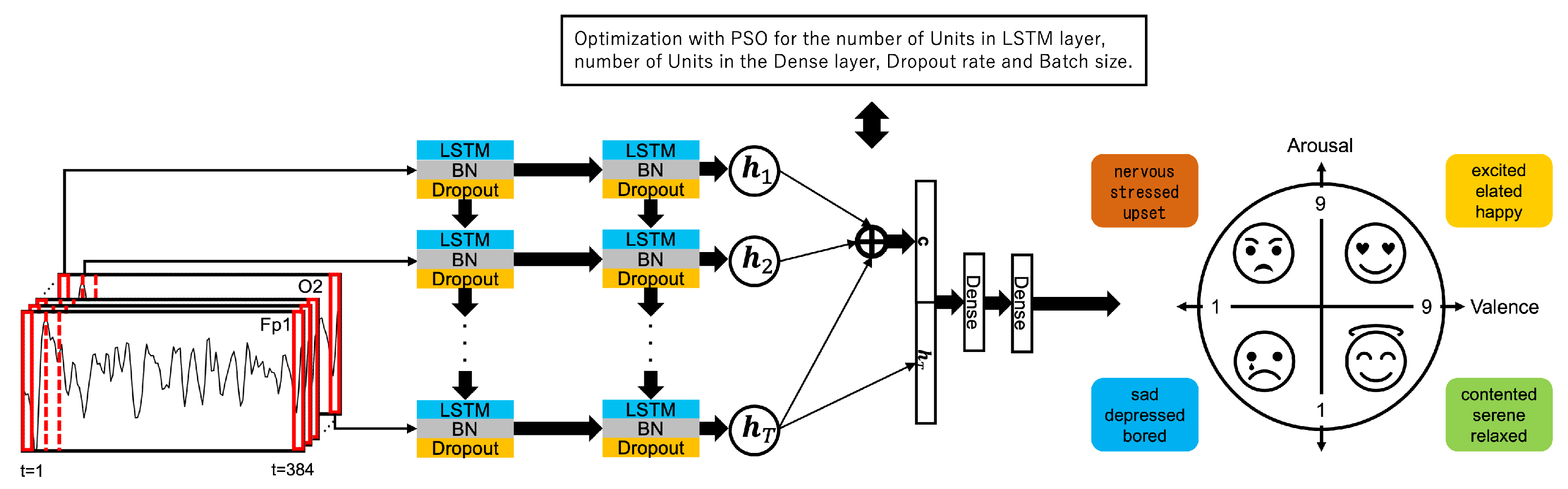
Figure 2 illustrates Russell’s circumplex model of affect, a widely used model in emotion research. It provides a continuous and quantitative way to describe and measure emotional states. Russell’s model represents emotions on a two-dimensional plane, with valence (ranging from unpleasant to pleasant) as the horizontal axis and arousal (ranging from calm to excited) as the vertical axis. Russell’s model offers a comprehensive framework for describing and measuring emotional states in a continuous space.
Table 1 shows the data arrays for each participant provided by DEAP. The sampling frequency was 512 Hz and was downsampled to 128 Hz. EOG artifacts were removed. Additionally, a bandpass filter was applied to provide data in the frequency range of 4–45 Hz.
In this paper, following previous studies, we do not use biological signals such as GSR, HR and EMG but only EEG data measured from all 32 electrodes provided by DEAP. For labels, of the four labels (arousal, valence, liking and dominance), only valence and arousal are used.
4.2. SEED Dataset
The SEED dataset, developed by the BCMI Laboratory at Shanghai Jiaotong University, is another widely used benchmark dataset for emotion recognition research using EEG signals [
21,
22]. This dataset was designed to investigate three distinct emotional states: neutral, negative, and positive.
The dataset consists of EEG recordings from 15 subjects participating in three separate experimental sessions on different days. This repeated measurement design enhances the reliability and generalizability of the collected data. Participants watched 15 carefully selected video clips to elicit specific emotional responses during each session. The experimental protocol for each video clip consisted of multiple segments: a 5 s movie prompt, followed by the main 4 min video content, a 45 s self-assessment period, and a 15 s rest interval. Each video clip was assigned an emotional label based on its content: for negative emotions, 0 for neutral states, and 1 for positive emotions.
The EEG signals were initially recorded using 62 channels positioned according to the international 10–20 system and downsampled to 200 Hz. In our research, to ensure consistency with the DEAP dataset, we selected 32 electrodes from the original 62 channels corresponding to the electrode positions used in DEAP. Due to varying video durations, we extracted the middle 60 s from each approximately 4 min video recording for standardized analysis [
28].
Table 2 presents the detailed structure of the SEED dataset after our electrode selection and temporal segmentation.
4.3. Feature Extraction of EEG Data
The preprocessing method for EEG data in this study follows the work of Yilong et al. and focuses on extracting time-domain features [
39]. The EEG data for each video consist of 3 s of baseline EEG data recorded before watching the video and 60 s of EEG data recorded during the video viewing (the SEED dataset does not provide pre-stimulus EEG recordings; therefore, we employ the first 3 s of EEG data collected during the video presentation as the baseline condition). In this study, the EEG data before watching the video are defined as representing the basic emotional state. The preprocessing steps for the EEG data are as follows:
- Step 1
Segmentation of EEG Data into 3 s Intervals
The EEG data for each video are segmented into 3 s intervals. Thus, the EEG data are divided into 21 segments, with the first segment representing the baseline signal and the remaining 20 segments representing the EEG data during the video viewing.
- Step 2
Calculation of Amplitude Changes between EEG Data and Baseline Signal
The amplitude changes are calculated by subtracting the baseline signal from the EEG data during the video viewing. Finally, the data are standardized. In this study, these amplitude changes are used as time-domain features for the learning process.
4.4. Attention-Based PSO-LSTM Model
In this study, we construct an emotion estimation model using LSTM to learn the temporal changes in EEG data, performing a four-class classification. The proposed emotion estimation model is illustrated in
Figure 3. The LSTM layers are stacked in two layers, each using the tanh activation function. Additionally, Batch Normalization and dropout layers are inserted immediately after each LSTM layer to prevent overfitting.
The attention mechanism assigns weights to the hidden states of the LSTM for each time series. Subsequently, the context vector generated by the attention mechanism is concatenated with the final hidden state of the LSTM and then input into a fully connected layer with the tanh activation function. Finally, the four-class classification uses a fully connected layer with the softmax activation function.
PSO is employed to optimize the following five-dimensional parameters: the number of units in the first LSTM layer, the number of units in the second LSTM layer, the number of units in the dense layer, the dropout rate, and the batch size. Each parameter is searched within a predefined range, and the PSO algorithm identifies the optimal values. In this experiment, the predefined ranges for the hyperparameters are as follows: the number of units in the first LSTM layer (1–200), the number of units in the second LSTM layer (1–200), the number of units in the dense layer (1–200), the dropout rate (0.1–0.9), and the batch size (1–128).
In addition, the initial particle swarm is randomly initialized, and each particle’s parameter settings are used to train the model. Each particle evaluates its position based on the loss value, updating both its best position and the global best position of the swarm. Through iterations, the optimal parameter settings are expected to converge. The parameter settings that result in the minimum loss value are adopted, aiming to enhance the model’s performance. In this experiment, the categorical cross-entropy loss function is used to evaluate the performance of the model during training.
5. Experiment and Results
5.1. Overview
First, to validate the usefulness of the proposed model, its performance is evaluated through four-class emotion classification. Valence and arousal are represented by values ranging from 1 to 9; therefore, using 5 as a threshold, we perform four-class classification into High Valence–High Arousal (HVHA), Low Valence–High Arousal (LVHA), Low Valence–Low Arousal (LVLA), and High Valence–Low Arousal (HVLA). The performance of the proposed model is measured by the average accuracy across all subjects.
Next, to verify the usefulness of the attention mechanism, we compare the classification accuracy of the proposed model with that of the model without the Attention mechanism.
Finally, to verify the usefulness of PSO, the loss values for each iteration are plotted graphically to see if the loss values are decreasing. We also compare the classification accuracy of the model with fixed hyperparameters to see if it is optimized by PSO. Regarding the hyperparameters of the model, we set the number of LSTM units in the first layer to 128, the number of LSTM units in the second layer to 64, the number of units in the dense layer to 16, the dropout rate to 0.2, and the batch size to 32 [
40].
5.2. Experiment Settings
The iteration number of the PSO is set to 10, and the number of particles is set to 15. The PSO weight parameters, w, , and , are set to 0.2, 0.3, and 0.5, respectively. With regard to the experimental conditions of the model, the number of epochs is set to 150. For the loss function, we use categorical cross-entropy. The optimization algorithm is Adam, with a learning rate of 0.0001. The evaluation metric is accuracy. To prevent overfitting caused by correlations in adjacent temporal segments of the input data, the input data are shuffled and then divided into 60% for training, 20% for validation, and 20% for testing. The classification accuracy of the proposed model is the average accuracy of the 32 subjects.
5.3. Experiment Results
Table 3 presents the classification accuracy of the proposed model. The model achieves an accuracy of 0.9404 in the four-class classification task using the DEAP dataset. This value surpasses the classification accuracies reported in previous studies, demonstrating the highest accuracy. Additionally, when using the SEED dataset, the model achieves an accuracy of 0.9732 in the three-class classification task.
Table 4 shows the classification accuracies of the model without the attention mechanism and the model with fixed hyperparameters. The model without the attention mechanism achieves an accuracy of 0.8382 for the DEAP dataset and 0.8814 for the SEED dataset. These values are approximately 0.1 lower than the proposed model for each dataset. Furthermore, the model with fixed hyperparameters achieves an accuracy of 0.9153 for the DEAP dataset and 0.9641 for the SEED dataset. These values are approximately 0.01–0.02 lower than the proposed model.
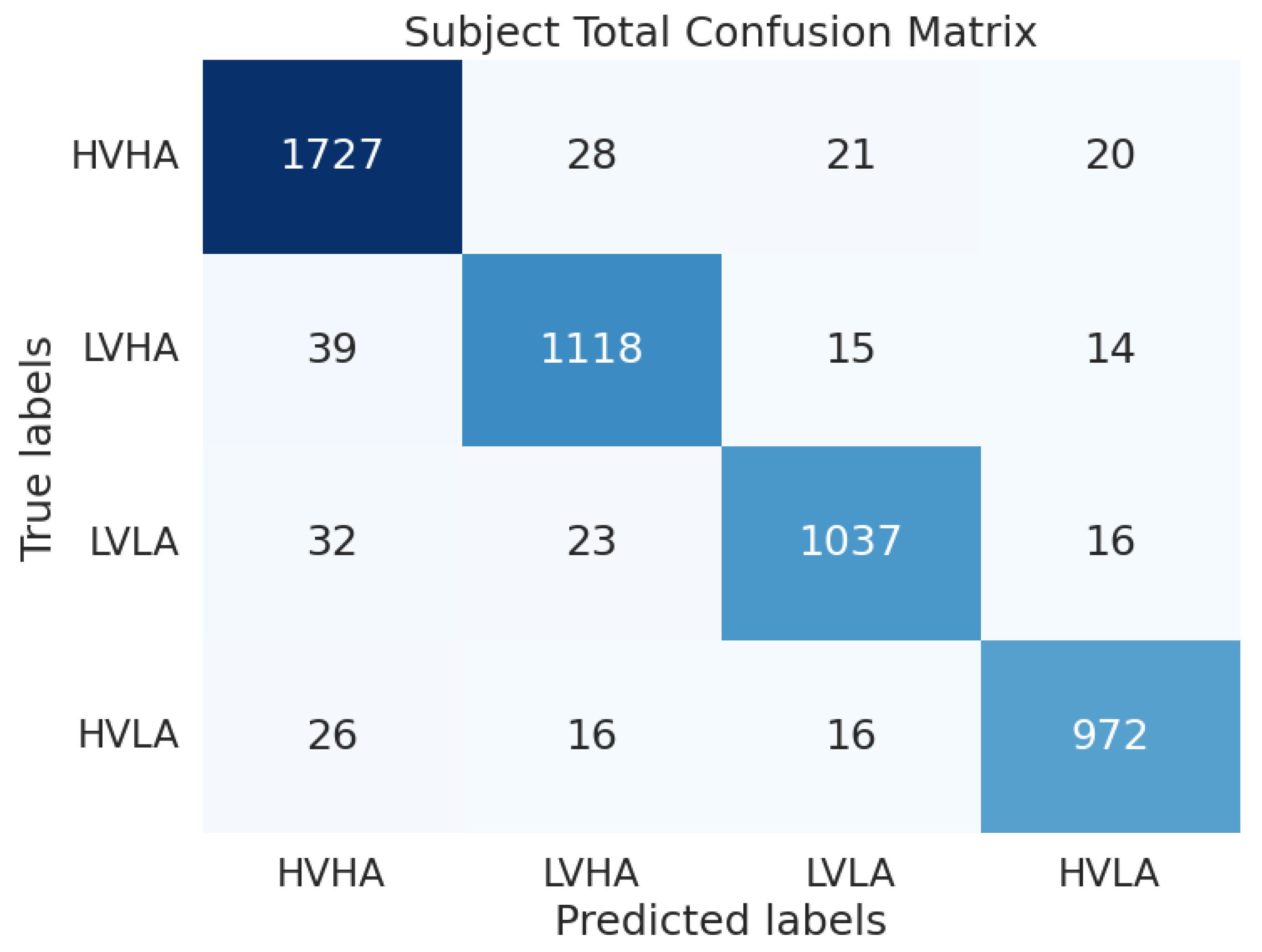
Figure 4 presents the element-wise aggregated confusion matrices across all subjects for the DEAP dataset when using the proposed model. The DEAP dataset has an imbalance, with more HVHA data. However, despite this data imbalance, the proposed model shows no significant bias, suggesting that it successfully extracts features and enables high-accuracy classification.
Figure 5 illustrates the progression of loss values per PSO iteration for Subject 1, who achieved a four-class classification accuracy of 0.9937 using the DEAP dataset. The graph clearly shows a steady decrease in loss values as iterations progress, indicating effective hyperparameter optimization by PSO. A sharp decrease in loss is observed during the initial iterations, followed by a consistent downward trend. Conversely, as shown in
Figure 6, Subject 17’s loss values for the DEAP dataset remained constant per iteration, indicating stagnation in optimization. Subject 17’s four-class classification accuracy was 0.7624.
Figure 7 shows box plots for each hyperparameter across all subjects in the DEAP datasets, highlighting significant inter-subject variability. Similar findings have been reported in prior studies, such as that of Bazargani et al. (2023), which demonstrated that subject-specific parameter tuning significantly improves model performance. The observed variation in hyperparameter values indicates that EEG data differences across individuals require tailored configurations for optimal results. These findings underscore the effectiveness of the PSO approach in identifying subject-specific optimal parameters and further highlight the necessity of personalized optimization in EEG-based emotion recognition.
5.4. Discussion
To the best of our knowledge, the state-of-the-art accuracy for four-class classification is 0.9100 as reported by Lin et al. [
27]. The classification accuracy of 0.9404 achieved by the proposed model in four-class classification surpasses the performance reported in previous studies, strongly indicating the effectiveness of our approach. Furthermore, the model recorded a classification accuracy of 0.9732 in three-class classification using the SEED dataset, demonstrating the versatility of the proposed method.
Comparison with the model lacking the attention mechanism reveals that the attention mechanism contributes to an accuracy improvement of approximately 0.1. This difference suggests that the attention mechanism effectively emphasizes important features in EEG data, enabling the model to focus on more relevant information. Given that EEG data tend to contain noise and irrelevant information, the introduction of the attention mechanism likely reduced these influences, improving both the learning efficiency and model accuracy.
Comparison with the fixed-hyperparameter model confirms that PSO effectively optimizes the model’s hyperparameters, resulting in subject-specific models. For instance, in the case of Subject 1, PSO demonstrates its ability to converge toward the optimal solution by balancing exploration (searching broadly across different possibilities) and exploitation (focusing on the most promising options).
However, cases of stagnant optimization were observed, as exemplified by Subject 17. Possible causes include insufficient parameter search range and particle number in the current PSO experimental settings or a highly complex objective function making it difficult to escape local optima. Addressing these issues may require increasing the number of iterations and particles, expanding the search range, and implementing strategic initial particle placement.
Ten PSO iterations were chosen based on a balance between computational efficiency and empirical observations during preliminary experiments. While significant changes in the loss function for Subject 1 in the eighth iteration suggest ongoing optimization, the overall performance metrics indicate diminishing returns in improvement beyond 10 iterations for most subjects. Extending the iteration count further could potentially improve convergence for specific cases, such as Subject 1. However, it would increase the computational overhead. Future work could explore subject-specific iteration tuning or adaptive stopping criteria to address such scenarios more effectively.
The box plots of hyperparameters reveal that the optimal hyperparameter values differ significantly among subjects. This variability aligns with prior studies using EEG data, such as those by Lin et al. (2023) and Marjit et al. (2021), which reported similar inter-subject differences in classification performance and hyperparameter tuning. These differences reflect the unique individual EEG patterns and responses to stimuli, further emphasizing the importance of subject-specific model construction in improving accuracy.
While our proposed model achieved high classification accuracy overall, there remain areas for future improvement. These include enhancing the data preprocessing techniques, exploring alternative model architectures, and investigating more advanced optimization methods. A more detailed discussion of these future directions and the current limitations is provided in
Section 6.
6. Limitations and Future Research
While the proposed attention-based PSO-LSTM model achieves strong results in emotion estimation from EEG data, several limitations need to be addressed. A possible limitation is that the PSO iteration count was fixed at 10 for all subjects without dynamic adjustment to individual optimization needs. Future work could investigate adaptive iteration tuning or stopping criteria to accommodate subject-specific variations better while balancing computational efficiency.
Another limitation involves the optimization stagnation observed in some cases, such as Subject 17. This could be attributed to insufficient iterations, an overly restricted search range, or the complexity of the objective function. Addressing these issues may involve increasing the number of iterations and particles, expanding the search range, or incorporating hybrid optimization techniques, such as combining PSO with evolutionary algorithms or simulated annealing.
Although EEG data preprocessing was carefully handled, EEG signals are inherently noisy. Exploring advanced noise reduction techniques, such as Independent Component Analysis (ICA), and implementing data augmentation could further enhance robustness. Data augmentation, a technique that artificially increases the diversity of training data by applying transformations such as scaling, cropping, or adding noise, could help the model generalize better to unseen data. Moreover, exploring alternative model architectures like transformer-based models, which have shown promise in time-series data, could enhance performance. Ensemble methods combining multiple models might also yield a more generalizable system.
The current study focuses on offline classification, which is not ideal for real-time applications. Future research could focus on reducing model latency and optimizing the system for real-time performance, potentially using model pruning techniques. Additionally, optimizing the model for edge computing would enable real-time deployment in devices with limited computational resources, which is essential for applications in healthcare or autonomous systems.
Finally, the model demonstrates significant subject-specific variability, highlighting the need for further personalization techniques. Transfer learning could allow the model to adapt quickly to new subjects without retraining, and on-the-fly model calibration methods could improve accuracy for new users. Addressing these limitations and expanding the model’s application to real-world contexts will further strengthen its performance and applicability.
7. Conclusions
This study introduces a novel attention-based PSO-LSTM model for emotion estimation from EEG data, achieving state-of-the-art accuracy in four-class emotion classification. The integration of attention mechanisms enhances the model’s ability to capture relevant temporal features, while PSO enables dynamic hyperparameter optimization. This combination successfully addresses key challenges in EEG-based emotion recognition, particularly in managing noise and temporal pattern complexity.
Our user-dependent approach effectively constructs subject-specific models that capture individual variations in EEG patterns, demonstrating significant advancements over fixed-hyperparameter approaches. However, this comes at the cost of broader generalizability, reflecting a fundamental trade-off in EEG-based emotion recognition: balancing individual accuracy with widespread applicability.
The model’s success in adapting to individual differences while maintaining robust performance suggests promising applications in healthcare, neuromarketing, and human–computer interaction, where accurate emotion recognition is essential. Moving forward, the development of user-independent models that maintain high individual accuracy while functioning effectively across subjects represents the next frontier in this field.
This study lays the groundwork for more versatile emotion recognition systems that can bridge the gap between individual optimization and broad applicability, advancing our understanding of human emotion and its practical applications in real-world scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}