
YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism


Abstract
1. Introduction
- To enhance the feature-extraction capabilities of the backbone network, we propose a novel Bi-level Routing Spatial Attention (BRSA) mechanism, which integrates the Bi-level Routing Attention (BRA) mechanism with the Spatial Attention Mechanism (SAM). This BRSA mechanism selectively filters features and dynamically adjusts the weights of spatial positions based on task requirements, facilitating focused attention on capturing intricate and subtle vehicle-related details and, therefore, enhancing the network’s ability to recognize salient features in complex backgrounds.
- In the head network, we integrate the Omni-directional Dynamic Convolution (ODConv), which dynamically learns complementary attention across four dimensions of the kernel space, enabling multi-dimensional information extraction. This enhances the convolutional neural network’s adaptability to variations in input data features, providing more flexible convolutional operations for handling complex and diverse data and thus better accommodating the intricate and changing conditions of road targets.
- To enhance the accuracy and robustness of vehicle target detection across various sizes, we introduce a novel loss function termed Shape-IOU. Building upon the traditional IOU, this loss function accounts for the impact of inherent bounding box attributes, namely shape and scale, on bounding box regression, therefore improving the localization precision of detected vehicles.
2. Related Work
2.1. Object Detection
2.2. Vehicle Detection
3. Methods
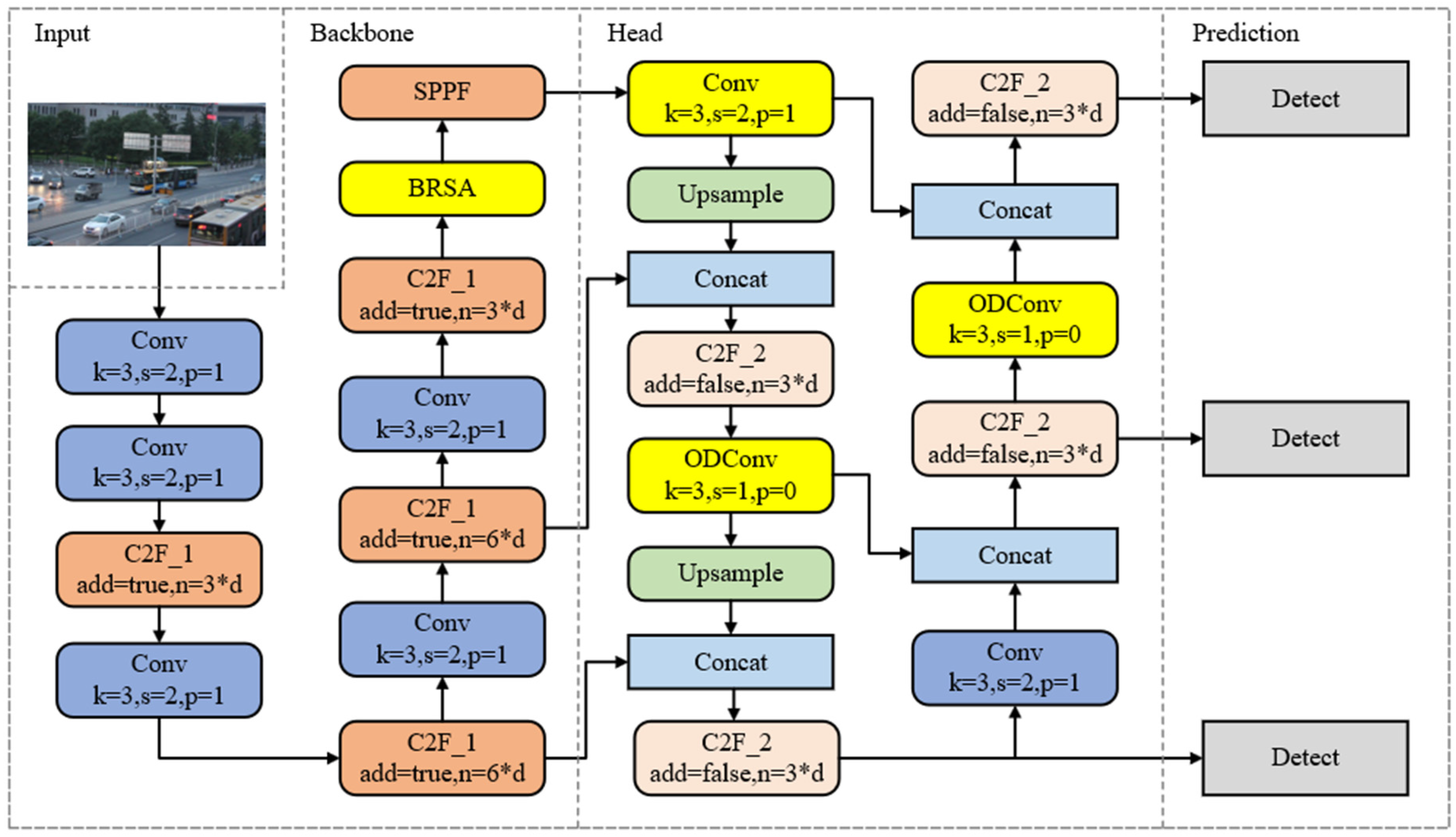
3.1. Network Architecture
3.2. BRSA Mechanism
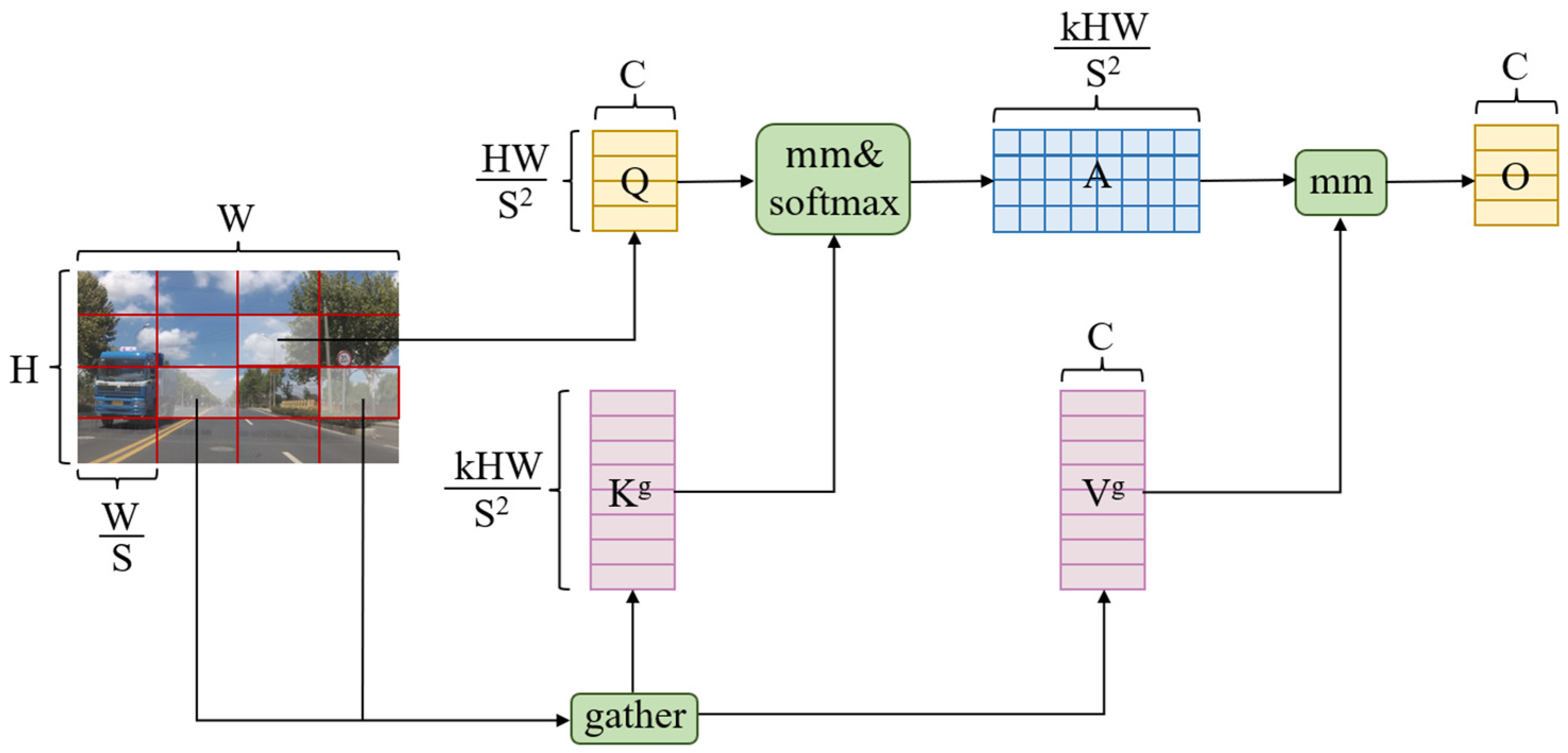
3.2.1. Bi-Level Routing Attention
3.2.2. Spatial Attention Mechanism
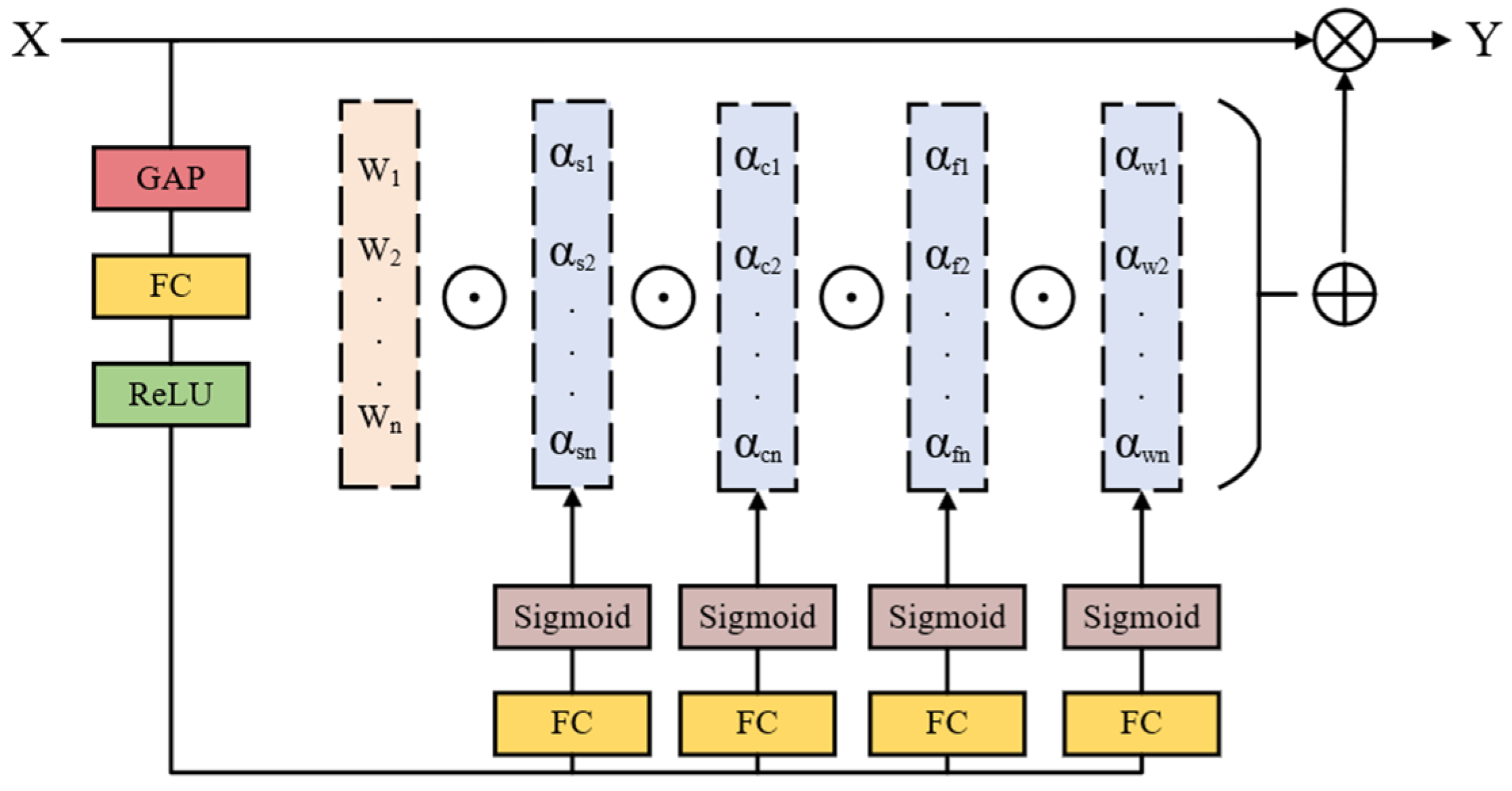
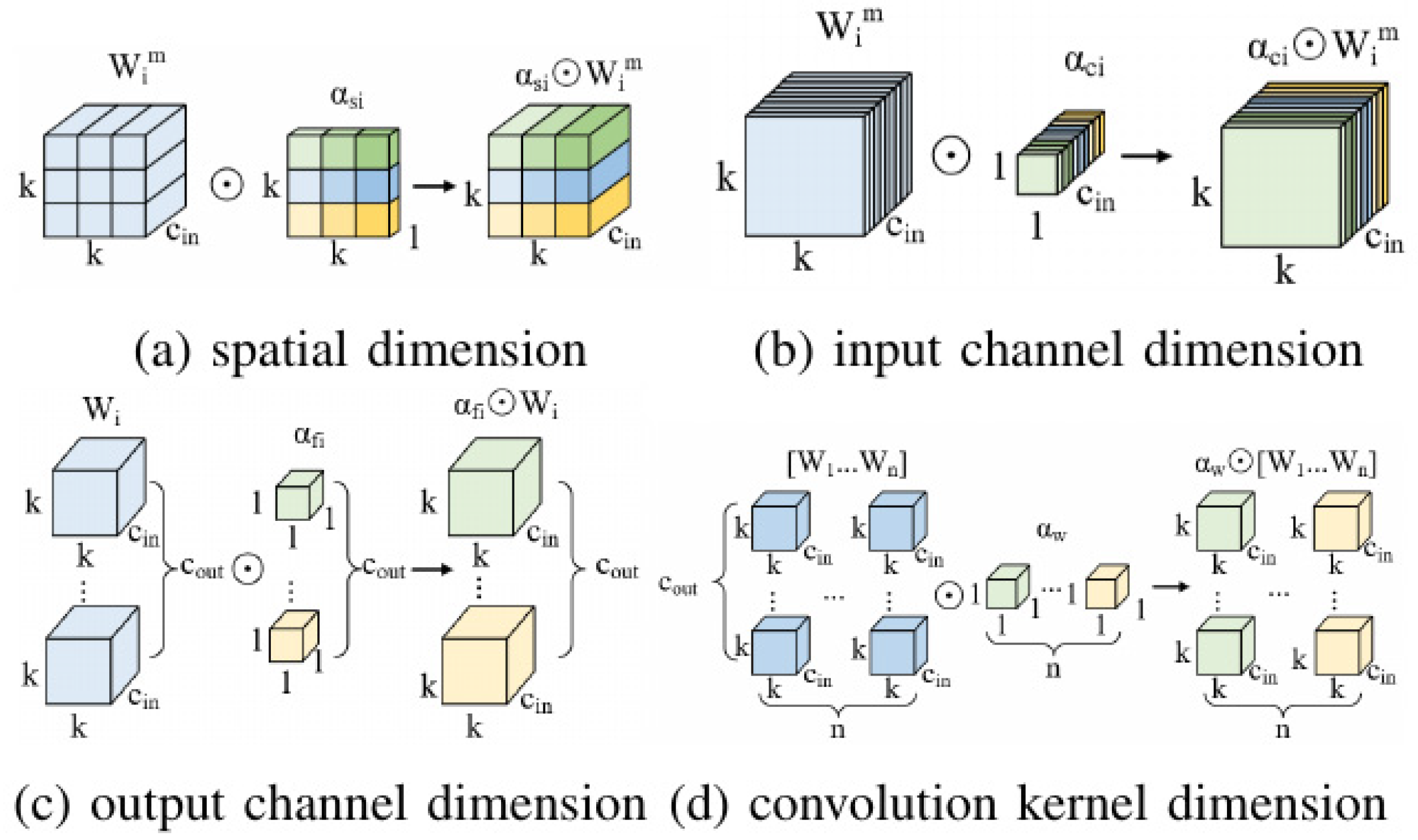
3.3. ODConv
3.4. Shape-IOU
4. Experiments
4.1. Datasets
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Impact of Different Modules on Model Performance
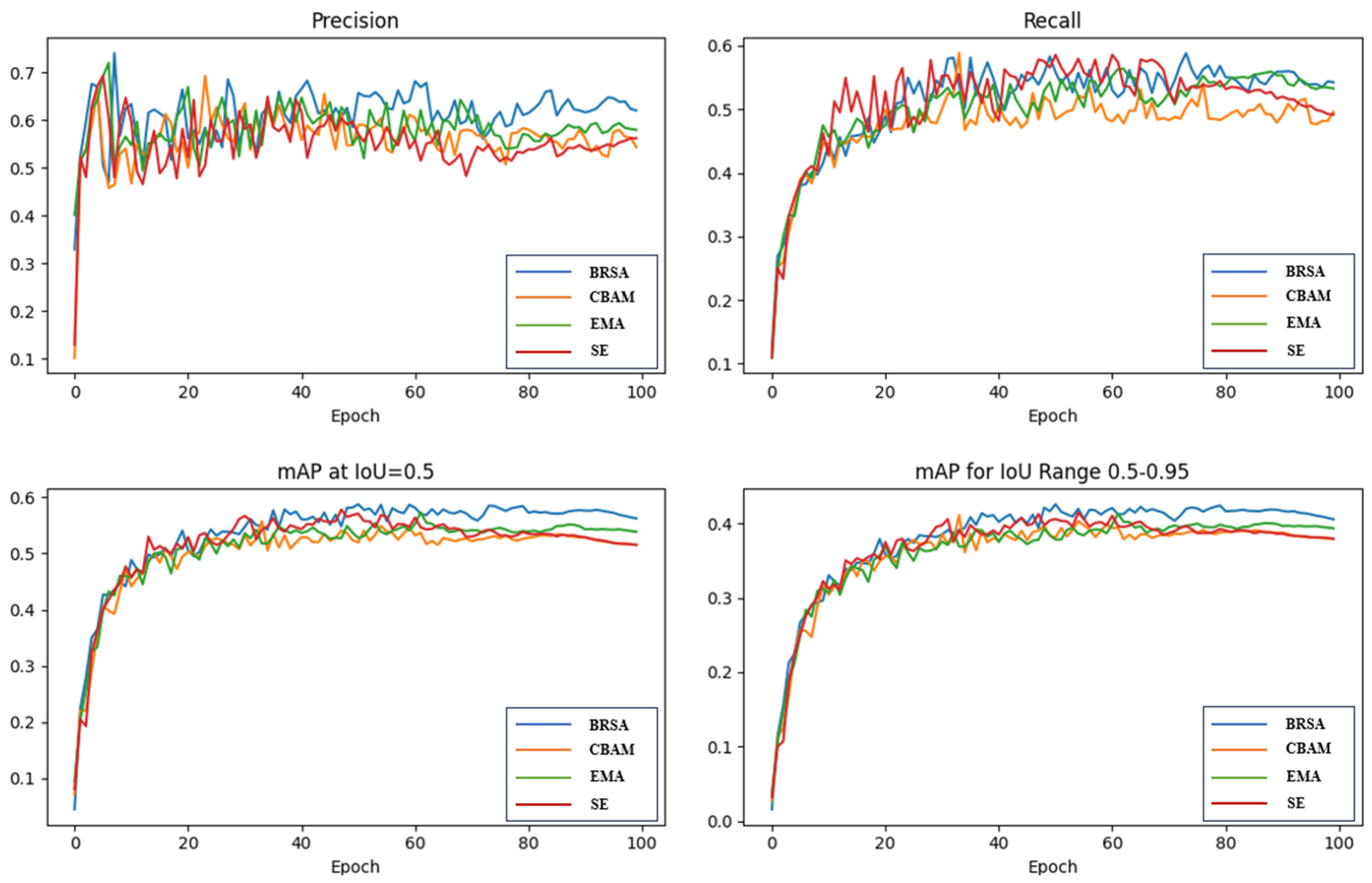
4.4.1. Effect Verification of BRSA Mechanism
4.4.2. The Impact of the Quantity and Placement of ODConv on Model Performance
4.4.3. The Impact of Different Loss Functions on Model Performance
4.5. Ablation Studies
4.6. Comparisons with Other Methods
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, P.; Zhang, R.; Sun, S.; Gao, M.; Zheng, B.; Zhang, D.; Zhang, Y.; Carmichael, G.R.; Zhang, H. Aggravated Air Pollution and Health Burden Due to Traffic Congestion in Urban China. Atmos. Chem. Phys. 2023, 23, 2983–2996. [Google Scholar] [CrossRef]
- Yuan, T.; da Rocha Neto, W.; Rothenberg, C.E.; Obraczka, K.; Barakat, C.; Turletti, T. Machine Learning for Next-Generation Intelligent Transportation Systems: A survey. Trans. Emerg. Telecommun. Technol. 2022, 33, e4427. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of Yolo Architectures in Computer Vision: From Yolov1 to Yolov8 and Yolo-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, H.; Shao, F.; Chu, W.; Dai, J.; Li, X.; Zhang, X.; Gong, C. Faster R-CNN Based on Frame Difference and Spatiotemporal Context for Vehicle Detection. Signal Image Video Process. 2024, 18, 7013–7027. [Google Scholar] [CrossRef]
- Xu, Y.; Chu, K.; Zhang, J. Nighttime Vehicle Detection Algorithm Based on Improved Faster-RCNN. IEEE Access 2023, 12, 19299–19306. [Google Scholar] [CrossRef]
- Othmani, M.J.M.T. A Vehicle Detection and Tracking Method for Traffic Video Based on Faster R-CNN. Multimed. Tools Appl. 2022, 81, 28347–28365. [Google Scholar] [CrossRef]
- Guo, D.; Wang, Y.; Zhu, S.; Li, X. A Vehicle Detection Method Based on An Improved U-YOLO Network for High-Resolution Remote-Sensing Images. Sustainability 2023, 15, 10397. [Google Scholar] [CrossRef]
- Zhang, Q.; Han, Z.; Zhang, Y. Vehicle Target Detection Method Based on Improved YOLO V3 Network Model. PeerJ Comput. Sci 2023, 9, e1673. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, A.; Zhao, F.; Wu, H. A Lightweight Vehicle-pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios. Sensors 2022, 22, 8480. [Google Scholar] [CrossRef]
- Wang, P.; Wang, X.; Liu, Y.; Song, J. Research on Road Object Detection Model Based on YOLOv4 of Autonomous Vehicle. IEEE Access 2024, 12, 8198–8206. [Google Scholar] [CrossRef]
- Chen, C.; Wang, C.; Liu, B.; He, C.; Cong, L.; Wan, S. Edge Intelligence Empowered Vehicle Detection and Image Segmentation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 13023–13034. [Google Scholar] [CrossRef]
- Miao, J.; Gong, S.; Deng, Y.; Liang, H.; Li, J.; Qi, H.; Zhang, M. YOLO-VSF: An Improved YOLO Model by Incorporating Attention Mechanism for Object Detection in Traffic Scenes. J. Shanghai Jiao Tong Univ. (Sci.) 2024, 1–14. [Google Scholar] [CrossRef]
- Li, H.; Zhuang, X.; Bao, S.; Chen, J.; Yang, C. SCD-YOLO: A Lightweight Vehicle Target Detection Method Based on Improved YOLOv5n. J. Electron. Imaging 2024, 33, 023041. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, S.; Wang, P.; Li, K.; Song, Z.; Zheng, Q.; Li, Y.; He, Q. Lightweight Vehicle Detection Based on Improved YOLOv5s. Sensors 2024, 24, 1182. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; He, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Ren, J.; Yang, J.; Zhang, W.; Cai, K. RBS-YOLO: A Vehicle Detection Algorithm Based on Multi-scale Feature Extraction. Signal Image Video Process. 2024, 18, 3421–3430. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, M.; Zhang, C.; Liang, H.; Li, P.; Zhang, W. YOLO-CCS: Vehicle Detection Algorithm Based on Coordinate Attention Mechanism. Digit. Signal Process. 2024, 153, 104632. [Google Scholar] [CrossRef]
- Wang, Z.; Men, S.; Bai, Y.; Yuan, Y.; Wang, J.; Wang, K.; Zhang, L. Improved Small Object Detection Algorithm CRL-YOLOv5. Sensors 2024, 24, 6437. [Google Scholar] [CrossRef] [PubMed]
- He, Q.; Xu, A.; Ye, Z.; Zhou, W.; Cai, T. Object Detection Based on Lightweight YOLOX for Autonomous Driving. Sensors 2023, 23, 7596. [Google Scholar] [CrossRef]
- Gao, X.; Yu, A.; Tan, J.; Gao, X.; Zeng, X.; Wu, C. GSD-YOLOX: Lightweight and More Accurate Object Detection Models. J. Vis. Commun. Image Represent. 2024, 98, 104009. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Huang, Z.; Yuan, H.; Li, P.; Jiang, X.; Wang, X.; Zhong, C.; Lin, Q. Improved YOLOv7-Based Algorithm for Detecting Foreign Objects on the Roof of a Subway Vehicle. Sensors 2023, 23, 9440. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y.; Wang, Z.; Jiang, Y. YOLOv7-RAR for Urban Vehicle Detection. Sensors 2023, 23, 1801. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Liu, X.; Chen, S.; Yang, L.; Du, Q.; Han, Z.; Wang, J. MST-YOLO: Small Object Detection Model for Autonomous Driving. Sensors 2024, 24, 7347. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wang, Y.; Yu, D.; Yuan, Z. YOLOv8-FDD: A Real-Time Vehicle Detection Method based on Improved YOLOv8. IEEE Access 2024, 12, 136280–136296. [Google Scholar] [CrossRef]
- Liu, J.; Yang, D.; Feng, T.; Fu, J. MDFD2-DETR: A Real-Time Complex Road Object Detection Model Based on Multi-Domain Feature Decomposition and De-Redundancy. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Jin, M.; Zhang, J. Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR). Sensors 2024, 24, 6987. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric Considering Bounding Box Shape and Scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.-C.; Qi, H.; Lim, J.; Yang, M.-H.; Lyu, S. UA-DETRAC: A New Benchmark and Protocol for Multi-object Detection and Tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef]
- Han, J.; Liang, X.; Xu, H.; Chen, K.; Hong, L.; Mao, J.; Ye, C.; Zhang, W.; Li, Z.; Liang, X. SODA10M: A Large-Scale 2D Self/Semi-Supervised Object Detection Dataset for Autonomous Driving. arXiv 2021, arXiv:2106.11118. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs Beat Yolos on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Zhao, L.; Yun, Q.; Yuan, F.; Ren, X.; Jin, J.; Zhu, X. YOLOv7-CHS: An Emerging Model for Underwater Object Detection. J. Mar. Sci. Eng. 2023, 11, 1949. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Configuration |
|---|---|
| CPU | E5–2678 v3@2.50 GHz |
| GPU | NVIDIA GeForce RTX 2080 Ti |
| Operating system | Windows 10 |
| RAM | 128 GB |
| CUDA | 11.6 |
| Programming language | Python 3.8 |
| Deep learning architecture | Pytorch 1.13.1 |
| Parameters | Value |
|---|---|
| Image size | 640 × 640 |
| Batch size | 32 |
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | |
| Workers | 8 |
| Module | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Layers | FPS |
|---|---|---|---|---|
| CBAM | 55.8 | 41.1 | 180 | 217.39 |
| EMA | 57.3 | 41.3 | 176 | 285.71 |
| SE | 56.9 | 41.5 | 175 | 285.71 |
| BRSA | 58.8 | 42.6 | 183 | 263.16 |
| Quantity | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Layers |
|---|---|---|---|---|---|
| 0 | 59.2 | 57.7 | 56.5 | 40.6 | 168 |
| 1 | 61.8 | 55.3 | 56.8 | 40.4 | 183 |
| 2 | 57.4 | 57.4 | 57.6 | 41.6 | 193 |
| 3 | 60.3 | 52.8 | 54.2 | 39.9 | 204 |
| Group | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Layers |
|---|---|---|---|---|---|
| 1 | 64.2 | 53.6 | 56.0 | 41.0 | 194 |
| 2 | 64.9 | 57.1 | 57.5 | 41.8 | 194 |
| 3 | 57.4 | 57.4 | 57.6 | 41.6 | 193 |
| 4 | 63.5 | 57.1 | 58.6 | 43.0 | 209 |
| 5 | 66.8 | 54.3 | 59.3 | 43.5 | 208 |
| Loss Function | FLOPs (G) | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) |
|---|---|---|---|---|---|
| Baseline | 8.1 | 59.2 | 57.7 | 56.5 | 40.6 |
| DIOU | 8.1 | 60.9 | 55.6 | 56.0 | 40.6 |
| EIOU | 8.1 | 55.3 | 54.1 | 54.8 | 39.5 |
| GIOU | 8.1 | 65.5 | 51.9 | 56.7 | 40.6 |
| SIOU | 8.1 | 67.1 | 51.7 | 57.0 | 40.6 |
| WIOU | 8.1 | 55.6 | 59.3 | 56.0 | 40.2 |
| Shape-IOU | 8.1 | 61.6 | 56.2 | 57.6 | 40.8 |
| Group | BRSA | ODConv | Shape-IOU | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 59.2 | 57.7 | 56.5 | 40.6 | 8.1 | 312.50 | |||
| 2 | √ | 65.6 | 55.8 | 58.8 | 42.6 | 18.7 | 263.16 | ||
| 3 | √ | 57.4 | 57.4 | 57.6 | 41.6 | 8.1 | 277.78 | ||
| 4 | √ | 61.6 | 56.2 | 57.6 | 40.8 | 8.1 | 303.03 | ||
| 5 | √ | √ | 66.8 | 54.3 | 59.3 (+2.8) | 43.5 | 18.5 | 285.71 | |
| 6 | √ | √ | 60.6 | 61.1 | 60.3 (+3.8) | 43.7 | 18.7 | 285.71 | |
| 7 | √ | √ | 59.3 | 40.9 | 59.1 (+2.6) | 40.9 | 8.1 | 277.78 | |
| 8 | √ | √ | √ | 64.5 | 58.4 | 61.2 (+4.7) | 45.0 | 18.5 | 263.16 |
| Category | YOLOv8n | Ours | ||||||
|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | |
| car | 70.5 | 70.7 | 74.1 | 53.2 | 68.8 | 71.7 | 74.3 | 53.0 |
| bus | 71.1 | 72.0 | 72.3 | 52.8 | 74.5 | 72.9 | 74.9 | 55.8 |
| vans | 53.2 | 52.4 | 50.1 | 38.3 | 51.9 | 52.9 | 51.3 | 39.1 |
| others | 41.9 | 35.6 | 29.6 | 18.1 | 62.8 | 35.8 | 44.3 | 32.1 |
| all | 59.2 | 57.7 | 56.5 | 40.6 | 64.5 | 58.4 | 61.2 | 45.0 |
| Model | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv5s | 59.3 | 55.5 | 55.0 | 39.2 | 7.02 | 15.8 |
| YOLOv5m | 70.6 | 53.3 | 57.3 | 41.2 | 20.87 | 47.9 |
| YOLOv7 | 82.0 | 51.9 | 53.4 | 41.7 | 36.50 | 103.2 |
| YOLOv7-CHS | 77.1 | 448.1 | 52.6 | 36.0 | 33.56 | 40.3 |
| YOLOv8n | 59.2 | 57.7 | 56.5 | 40.6 | 3.00 | 8.1 |
| YOLO11 | 61.8 | 51.7 | 55.9 | 40.2 | 2.58 | 6.3 |
| RT-DETR | 51.5 | 49.9 | 45.9 | 32.7 | 32.8 | 108.0 |
| Ours | 64.5 | 58.4 | 61.2 | 45.0 | 3.27 | 18.5 |
| Category | YOLOv8n | Ours | ||||||
|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | |
| pedestrian | 69.2 | 28.8 | 39.5 | 18.5 | 57.0 | 32.7 | 39.1 | 17.7 |
| cyclist | 73.0 | 53.6 | 63.7 | 36.8 | 69.6 | 55.9 | 61.9 | 34.8 |
| car | 85.1 | 76.8 | 84.3 | 61.8 | 78.3 | 78.4 | 83.0 | 59.3 |
| truck | 77.7 | 66.3 | 74.1 | 52.1 | 76.3 | 70.1 | 76.0 | 51.8 |
| tram | 71.6 | 63.9 | 69.5 | 52.1 | 72.0 | 64.9 | 70.4 | 52.8 |
| tricycle | 60.2 | 31.2 | 34.3 | 25.1 | 69.4 | 40.1 | 50.4 | 30.4 |
| all | 72.8 | 53.4 | 60.9 | 40.1 | 70.4 | 57.0 | 63.5 | 42.1 |
| Model | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv5s | 79.3 | 48.6 | 56.6 | 35.7 | 7.03 | 15.8 |
| YOLOv7 | 78.7 | 48.1 | 54.8 | 35.3 | 36.5 | 103.2 |
| YOLOv7-tiny | 65.9 | 35.3 | 40.3 | 25.8 | 6.02 | 13.1 |
| YOLOv8n | 70.8 | 53.4 | 60.9 | 40.1 | 3.0 | 8.1 |
| YOLO11 | 75.6 | 53.8 | 62.0 | 42.2 | 2.58 | 6.3 |
| RT-DETR | 73.3 | 50.5 | 55.3 | 35.6 | 32.0 | 108.0 |
| Ours | 70.4 | 57.0 | 63.5 | 42.1 | 3.27 | 18.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Fu, L.; Jia, X.; Cui, B.; Zhu, X.; Jin, J. YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism. Sensors 2024, 24, 8126. https://doi.org/10.3390/s24248126
Zhao L, Fu L, Jia X, Cui B, Zhu X, Jin J. YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism. Sensors. 2024; 24(24):8126. https://doi.org/10.3390/s24248126
Chicago/Turabian StyleZhao, Liang, Lulu Fu, Xin Jia, Beibei Cui, Xianchao Zhu, and Junwei Jin. 2024. "YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism" Sensors 24, no. 24: 8126. https://doi.org/10.3390/s24248126
APA StyleZhao, L., Fu, L., Jia, X., Cui, B., Zhu, X., & Jin, J. (2024). YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism. Sensors, 24(24), 8126. https://doi.org/10.3390/s24248126