

Advanced Monocular Outdoor Pose Estimation in Autonomous Systems: Leveraging Optical Flow, Depth Estimation, and Semantic Segmentation with Dynamic Object Removal

Abstract
:1. Introduction
- Novel Monocular Pose Estimation Framework: This paper introduces an advanced framework for pose estimation using monocular images, addressing the gap in research where most high-performing models rely on multi-sensor setups like LiDAR or stereo cameras. The proposed approach focuses on monocular vision, which is cost-effective and practical for various autonomous systems.
- Integration of Optical Flow, Depth Estimation, and Semantic Segmentation: The proposed framework combines optical flow, depth estimation, and semantic segmentation to improve the accuracy and robustness of visual odometry. These preprocessing steps allow the system to gather more environmental information, such as motion, spatial depth, and scene context.
- Dynamic Object Removal: An essential contribution is the dynamic object removal technique that filters out moving objects (e.g., cars, pedestrians) from the scene, reducing noise in pose estimation and focusing on static background elements. This improves pose accuracy in dynamic environments.
- Cost-effective and Lightweight Solution: By focusing on monocular vision and minimizing the need for additional sensors, this paper presents a lightweight and adaptable solution, making it highly suitable for applications in resource-constrained environments such as drones and autonomous vehicles.
- Experimental Validation: The framework’s performance is validated through experiments on the KITTI odometry dataset, demonstrating significant improvements in pose estimation accuracy compared to existing methods. The experimental results highlight the superiority of the proposed approach, particularly when combining optical flow, depth estimation, and semantic segmentation.
2. Related Work
2.1. Optical Flow
2.2. Depth Estimation
2.3. Semantic Segmentation
3. Vision-Base Pose Estimation
4. The Proposed Monocular Pose Estimator
4.1. Architecture
- Data Loader: This component retrieves data from the dataset in manageable sizes for processing (denoted by n batches of pair images). It ensures efficient data handling during the training or inference stages.
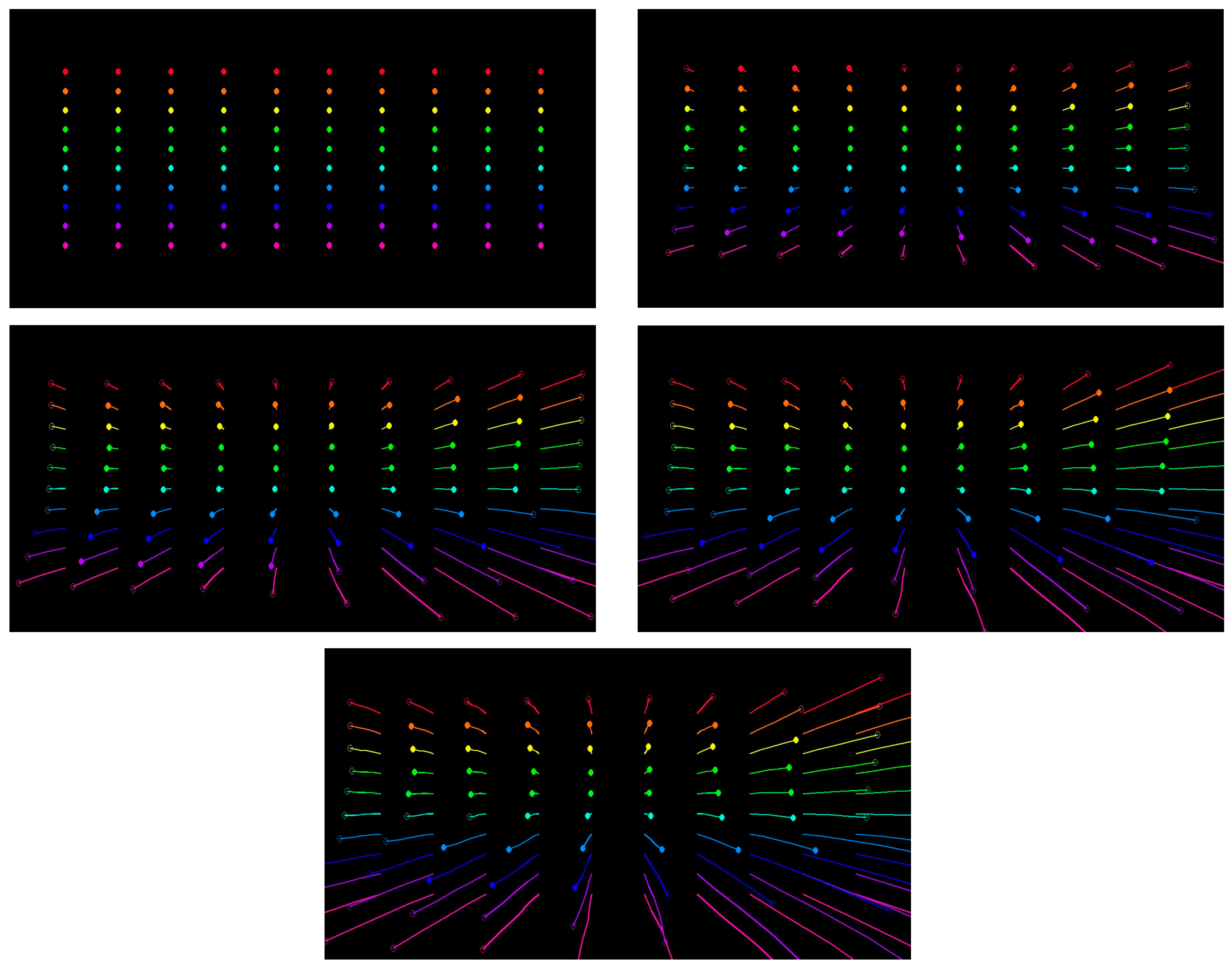
- Optical Flow Estimator: CoTracker [49] is presumably a transformer-based model designed for tracking objects across frames by estimating their motion (optical flow). It provides a dense field of motion vectors that represent the displacement of pixels between consecutive frames. The estimator’s output goes to a ten-by-ten grid matrix for every five frames. The track of the motion is drawn on each frame. Finally, the original image on the frame is removed to reduce the processing for the pose estimator, as shown in Figure 2.
- Depth Estimator [50]: This block estimates the depth from the camera to each point in the image. The cited approach suggests an integrated model that combines information from optical flow and direct depth estimation to produce a depth map; a sample output of the depth estimation process is shown in Figure 3.
- Semantic Estimator: HRNet [32,51], which stands for High-Resolution Network, is a neural network architecture for semantic segmentation that maintains high-resolution representations throughout the network. This allows it to predict fine-grained semantic labels, which is crucial for understanding different objects and regions within the frame; a sample output of the semantic segmentation process is shown in Figure 4.
- Masking: Here, based on the information from optical flow, depth, and semantic estimations, a masking operation focuses on certain regions or objects of interest by filtering out irrelevant parts of the image.
- Dynamic Object Filtration: This step filters out dynamic objects, which could be crucial for focusing the pose estimation on the static background or separating moving objects’ influence from the camera’s motion. The categories of objects to be removed include sky, car, pedestrian, bicycle, and motorcycle, as shown in Figure 5.
- Image Stacking: This block likely stacks or aligns multiple frames to comprehensively represent the scene, considering changes in view due to camera and object movements.
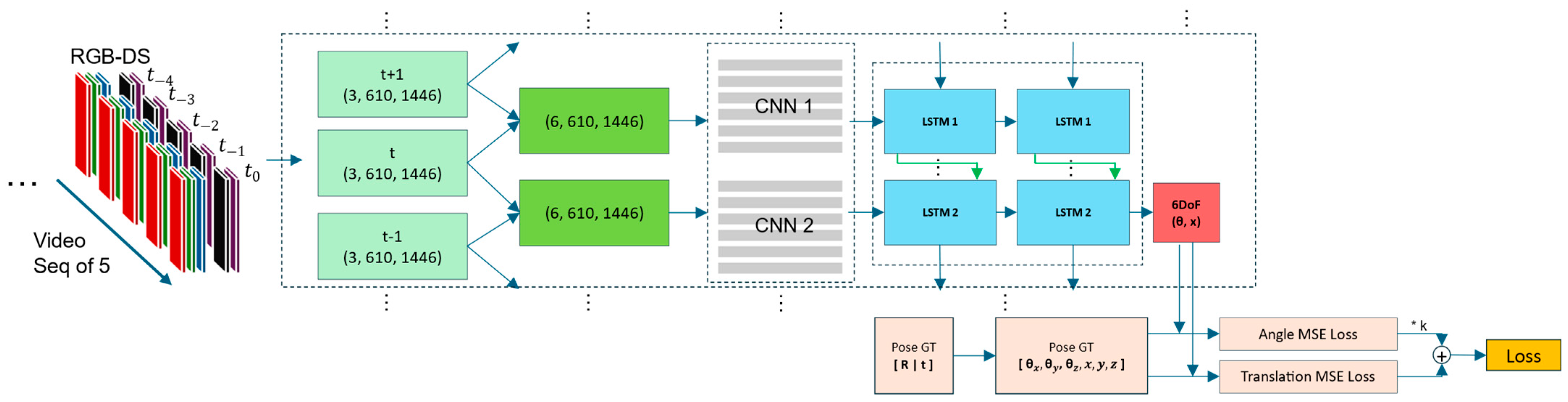
- Pose Estimator: The pose estimator network shown in Figure 7 processes a rich set of visual data to estimate a camera’s 6 degrees of freedom (6DoF) pose. The input to the network consists of an RGB optical flow image, a semantic segmentation map, and a depth map. These inputs are combined to comprehensively represent the scene across multiple frames. Initially, the input data is segmented into a sequence of frames, each representing five channels: three for the RGB optical flow, one for the semantic segmentation, and one for the depth map. These frames are then stacked in pairs to create a sequence of combined frames for each time step, labeled as t − 1, t, and t + 1, each with dimensions of (5, 610, 1446). The pairs of frames (t − 1, t) and (t, t + 1) are then processed to create stacked images with dimensions of (10, 610, 1446), which are fed into Convolutional Neural Networks (CNNs) to extract spatial features. The CNNs process these stacked frames to produce feature maps that capture the spatial structure of the scene. These feature maps are then passed to Long Short-Term Memory (LSTM) networks, which are specialized types of Recurrent Neural Networks (RNNs). The LSTM networks are designed to capture temporal dependencies and dynamics within the sequence of frames. Two layers of LSTMs, denoted as LSTM 1 and LSTM 2, are used to process the feature maps sequentially, capturing the evolution of the scene over time. The output from the LSTM layers consists of 6DoF pose estimates for each time step, represented as vectors of rotational and translational components (θ, x). These estimates are then compared to ground truth poses, which include both rotational matrices [R|t] for 12-DoF and individual rotational and translational components (θx, θy, θz, x, y, z) for 6-DoF. The network computes the Mean Squared Error (MSE) loss for the angle and translation estimates. These losses are combined and scaled by a constant factor to compute the final loss. The network is trained to minimize this loss, improving its accuracy in estimating the 6DoF poses from the given visual input data. This architecture effectively combines spatial and temporal information to provide robust pose estimations in dynamic environments.
4.2. Output Format
4.3. Advantages of the Architecture
- High Precision: Transformers across the pipeline allow for precise motion, depth, and semantics estimations due to their ability to capture long-range dependencies and contextual information within data.
- Integrated Depth and Motion Estimation: By unifying flow, stereo, and depth estimation, the system likely benefits from a more cohesive and robust depth map informed by motion across frames.
- Effective Semantic Segmentation: HRNet’s ability to maintain high-resolution information through the network provides detailed and accurate semantic segmentation, which can significantly improve the quality of masking and dynamic object filtration.
- Dynamic Object Handling: Including a dedicated block for dynamic object filtration helps the system isolate the camera’s motion from the motion of objects in the environment, which is critical for accurate pose estimation.
- Temporal Understanding: Stacking images over time enables the model to understand the temporal dynamics of the scene better, leading to more accurate pose estimations.
- Versatility: The architecture can be adapted to various environments by retraining with suitable datasets.
5. Experimental Results and Analysis
5.1. Experimental Setup
5.2. Dataset Division
5.3. Preprocessing Methods
- Base Model (Brown Color): This baseline model does not utilize preprocessing steps and directly inputs raw images into the neural network. It is the original architecture of DeepVO [52].
- Optical Flow Only (Yellow Color): This method involves computing optical flow between consecutive frames to capture motion information, which is then used as input to the model.
- Optical Flow with Depth Estimation (Green Color): In this approach, optical flow and depth maps are computed for each frame pair. The depth estimation provides additional spatial information about the scene, improving the model’s understanding of the environment.
- Optical Flow with Depth and Semantic Segmentation (Purple Color): This comprehensive preprocessing method combines optical flow, depth estimation, and semantic segmentation. The semantic segmentation provides context about different objects in the scene, further enhancing the model’s capability to interpret complex environments.
5.4. Evaluation Metrics
5.5. Training Results
5.6. Sensitivity Analysis
5.6.1. Training Loss Analysis
- (1)
- LR: 0.008: The training loss starts high and decreases steadily, indicating a good convergence rate. The curve shows a smooth decline, suggesting a stable training process.
- (2)
- LR: 0.005: This learning rate also demonstrates a steady decrease in training loss. The curve is similar to LR: 0.008 but with a slightly slower convergence rate due to the lower learning rate.
- (3)
- LR: 0.011: The training loss for this learning rate decreases rapidly initially but shows more fluctuations compared to the previous two. This suggests that the higher learning rate introduces instability while the convergence is fast.
- (4)
- LR: 0.014: The highest learning rate among the four shows the most rapid initial decrease in training loss. However, this curve also displays more pronounced fluctuations, indicating potential instability during training.
5.6.2. Validation Loss Analysis
- (1)
- LR: 0.008: The validation loss decreases steadily but exhibits some fluctuations. This indicates a good generalization with some overfitting tendencies, which might be addressed with further regularization techniques.
- (2)
- LR: 0.005: The validation loss shows a smooth decline with fewer fluctuations than LR: 0.008, suggesting a better generalization capability with reduced overfitting.
- (3)
- LR: 0.011: Similar to the training loss, the validation loss for this learning rate decreases rapidly but with noticeable fluctuations. This highlights the tradeoff between fast convergence and stability.
- (4)
- LR: 0.014: The validation loss curve shows the most significant fluctuations, indicating that while the model converges quickly, it may suffer from substantial overfitting and instability issues.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, A.; Yang, F.; Luo, K.; Li, X.; Fan, H.; Liu, S. Learning Optical Flow with Adaptive Graph Reasoning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1890–1898. [Google Scholar] [CrossRef]
- Jeong, J.; Lin, J.M.; Porikli, F.; Kwak, N. Imposing Consistency for Optical Flow Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 3171–3181. [Google Scholar] [CrossRef]
- Bai, S.; Geng, Z.; Savani, Y.; Kolter, J.Z. Deep Equilibrium Optical Flow Estimation. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 610–620. [Google Scholar] [CrossRef]
- Huang, Z.; Shi, X.; Zhang, C.; Wang, Q.; Cheung, K.C.; Qin, H.; Li, H. FlowFormer: A Transformer Architecture for Optical Flow; Springer Nature Switzerland: Cham, Switzerland, 2022. [Google Scholar]
- Wan, Z.; Dai, Y.; Mao, Y. Learning Dense and Continuous Optical Flow From an Event Camera. IEEE Trans. Image Process. 2022, 31, 7237–7251. [Google Scholar] [CrossRef] [PubMed]
- Deng, C.; Luo, A.; Huang, H.; Ma, S.; Liu, J.; Liu, S. Explicit Motion Disentangling for Efficient Optical Flow Estimation. In Proceedings of the 2023 IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 9487–9496. [Google Scholar] [CrossRef]
- Luo, A.; Yang, F.; Li, X.; Liu, S. Learning Optical Flow with Kernel Patch Attention. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 8896–8905. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, L.; Zhang, Z.; Zhou, E.; Metaxas, D. Global Matching with Overlapping Attention for Optical Flow Estimation. In Proceedings of the 2022 the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17571–17580. [Google Scholar] [CrossRef]
- Hu, L.; Zhao, R.; Ding, Z.; Ma, L.; Shi, B.; Xiong, R.; Huang, T. Optical Flow Estimation for Spiking Camera. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 17823–17832. [Google Scholar] [CrossRef]
- Tu, Z.; Li, H.; Xie, W.; Liu, Y.; Zhang, S.; Li, B.; Yuan, J. Optical flow for video super-resolution: A survey. Artif. Intell. Rev. 2022, 55, 6505–6546. [Google Scholar] [CrossRef]
- Guizilini, V.; Lee, K.-H.; Ambrus, R.; Gaidon, A. Learning Optical Flow, Depth, and Scene Flow Without Real-World Labels. IEEE Robot. Autom. Lett. 2022, 7, 3491–3498. [Google Scholar] [CrossRef]
- Liang, Y.; Liu, J.; Zhang, D.; Fu, Y. MPI-Flow: Learning Realistic Optical Flow with Multiplane Images. In Proceedings of the 2023 IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13811–13822. [Google Scholar] [CrossRef]
- Han, Y.; Luo, K.; Luo, A.; Liu, J.; Fan, H.; Luo, G.; Liu, S. RealFlow: EM-Based Realistic Optical Flow Dataset Generation from Videos; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Nature: Cham, Switzerland, 2022; Volume 13679 LNCS, pp. 288–305. [Google Scholar] [CrossRef]
- Luo, A.; Yang, F.; Li, X.; Nie, L.; Lin, C.; Fan, H.; Liu, S. GAFlow: Incorporating Gaussian Attention into Optical Flow. In Proceedings of the 2023 IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 9608–9617. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Tao, D. GMFlow: Learning Optical Flow via Global Matching. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 8111–8120. [Google Scholar] [CrossRef]
- Shi, X.; Huang, Z.; Li, D.; Zhang, M.; Cheung, K.C.; See, S.; Qin, H.; Dai, J.; Li, H. FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation. arXiv 2023, arXiv:2303.01237. Available online: http://arxiv.org/abs/2303.01237 (accessed on 2 June 2024).
- Dong, Q.; Cao, C.; Fu, Y. Rethinking Optical Flow from Geometric Matching Consistent Perspective. In Proceedings of the 2023 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; Volume 2023, pp. 1337–1347. [Google Scholar] [CrossRef]
- Zheng, Z.; Nie, N.; Ling, Z.; Xiong, P.; Liu, J.; Wang, H.; Li, J. DIP: Deep Inverse Patchmatch for High-Resolution Optical Flow. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 8915–8924. [Google Scholar] [CrossRef]
- Sui, X.; Li, S.; Geng, X.; Wu, Y.; Xu, X.; Liu, Y.; Goh, R.; Zhu, H. CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 17581–17590. [Google Scholar] [CrossRef]
- Lyu, X.; Liu, L.; Wang, M.; Kong, X.; Liu, L.; Liu, Y.; Chen, X.; Yuan, Y. HR-Depth: High Resolution Self-Supervised Monocular Depth Estimation. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 3B, pp. 2294–2301. [Google Scholar] [CrossRef]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1477–1485. [Google Scholar] [CrossRef]
- Li, Z.; Chen, Z.; Liu, X.; Jiang, J. DepthFormer: Exploiting Long-range Correlation and Local Information for Accurate Monocular Depth Estimation. Mach. Intell. Res. 2023, 20, 837–854. [Google Scholar] [CrossRef]
- Bhat, S.F.; Alhashim, I.; Wonka, P. AdaBins: Depth Estimation Using Adaptive Bins. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4008–4017. [Google Scholar] [CrossRef]
- Hoyer, L.; Dai, D.; Wang, Q.; Chen, Y.; Van Gool, L. Improving Semi-Supervised and Domain-Adaptive Semantic Segmentation with Self-Supervised Depth Estimation. Int. J. Comput. Vis. 2023, 131, 2070–2096. [Google Scholar] [CrossRef]
- Ramamonjisoa, M.; Firman, M.; Watson, J.; Lepetit, V.; Turmukhambetov, D. Single Image Depth Prediction with Wavelet Decomposition. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11084–11093. [Google Scholar] [CrossRef]
- Yuan, W.; Gu, X.; Dai, Z.; Zhu, S.; Tan, P. Neural Window Fully-connected CRFs for Monocular Depth Estimation. In Proceedings of the 2022 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 3906–3915. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Drenkow, N.; Ding, A.; Creighton, F.X.; Taylor, R.H.; Unberath, M. Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE International Conference on Computer Vision, Montreal, BC, Canada, 17 October 2021; pp. 6177–6186. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, Y.; Poggi, M.; Tosi, F.; Guo, X.; Zhu, Z.; Huang, G.; Tang, Y.; Mattoccia, S. MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–16 September 2022; pp. 668–678. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Miangoleh, S.M.H.; Dille, S.; Mai, L.; Paris, S.; Aksoy, Y. Boosting Monocular Depth Estimation Models to High-resolution via Content-adaptive Multi-Resolution Merging. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9680–9689. [Google Scholar] [CrossRef]
- Hoyer, L.; Dai, D.; Chen, Y.; Koring, A.; Saha, S.; Van Gool, L. Three Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11125–11135. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; Volume 2, pp. 9711–9720. [Google Scholar] [CrossRef]
- Huynh, C.; Tran, A.T.; Luu, K.; Hoai, M. Progressive Semantic Segmentation. In Proceedings of the 2021 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; Volume 1, pp. 16750–16759. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers. In Proceedings of the 2023 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; Volume 2023, pp. 19529–19539. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, W. HRNet- and PSPNet-based multiband semantic segmentation of remote sensing images. Neural Comput. Appl. 2023, 35, 8667–8675. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7242–7252. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object Context for Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Wu, H.; Liang, C.; Liu, M.; Wen, Z. Optimized HRNet for image semantic segmentation. Expert Syst. Appl. 2020, 174, 114532. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Zhi, H.; Yin, C.; Li, H.; Pang, S. An Unsupervised Monocular Visual Odometry Based on Multi-Scale Modeling. Sensors 2022, 22, 5193. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, T.; Liu, M. Joint estimation of pose, depth, and optical flow with a competition–cooperation transformer network. Neural Netw. 2024, 171, 263–275. [Google Scholar] [CrossRef]
- Zhao, C.; Tang, Y.; Sun, Q.; Vasilakos, A.V. Deep Direct Visual Odometry. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7733–7742. [Google Scholar] [CrossRef]
- Song, R.; Zhu, R.; Xiao, Z.; Yan, B. ContextAVO: Local context guided and refining poses for deep visual odometry. Neurocomputing 2023, 533, 86–103. [Google Scholar] [CrossRef]
- Tu, Z.; Chen, C.; Pan, X.; Liu, R.; Cui, J.; Mao, J. EMA-VIO: Deep Visual–Inertial Odometry With External Memory Attention. IEEE Sens. J. 2022, 22, 20877–20885. [Google Scholar] [CrossRef]
- Xu, K.; Hao, Y.; Yuan, S.; Wang, C.; Xie, L. AirVO: An Illumination-Robust Point-Line Visual Odometry. In Proceedings of the 2023 IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 3429–3436. [Google Scholar] [CrossRef]
- Zhu, R.; Yang, M.; Liu, W.; Song, R.; Yan, B.; Xiao, Z. DeepAVO: Efficient pose refining with feature distilling for deep Visual Odometry. Neurocomputing 2022, 467, 22–35. [Google Scholar] [CrossRef]
- Yang, N.; von Stumberg, L.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. In Proceedings of the 2020 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 1278–1289. [Google Scholar] [CrossRef]
- Karaev, N.; Rocco, I.; Graham, B.; Neverova, N.; Vedaldi, A.; Rupprecht, C. CoTracker: It is Better to Track Together. arXiv 2023, arXiv:2307.07635. Available online: http://arxiv.org/abs/2307.07635 (accessed on 2 June 2024).
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Yu, F.; Tao, D.; Geiger, A. Unifying Flow, Stereo and Depth Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13941–13958. [Google Scholar] [CrossRef] [PubMed]
- Lambert, J.W.; Liu, Z.; Sener, O.; Hays, J.; Koltun, V. MSeg: A Composite Dataset for Multi-Domain Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 796–810. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. Deepvo: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 2043–2050. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Ref. | Method | Key Features |
|---|---|---|---|
| Optical Flow | [1] | Graph reasoning for motion estimation | Decouples context reasoning from matching |
| [2] | Consistency on distrained pairs | Addresses distrained pairs | |
| [3] | Deep equilibrium models | Equilibrium via dynamic systems | |
| [4] | Transformer with MCVA | Cost volume autoencoding | |
| [5] | Event camera data | Event camera for fast motion | |
| [6] | Motion disentangling | Disentangling motion components | |
| [7] | Kernel Patch Attention | Focus on informative regions | |
| [8] | Global Matching with Overlapping Attention | Overlapping attention for global matching | |
| [9] | Spiking cameras | Uses spiking camera data | |
| [10] | Survey on video super-resolution | Optical flow for video enhancement | |
| [11] | Unsupervised learning | Unsupervised learning for optical flow | |
| [12] | Multiplane images | Leverages multiplane images | |
| [13] | EM for dataset generation | EM-based dataset generation | |
| [14] | Gaussian attention | Incorporates Gaussian attention | |
| [15] | Global Matching via softmax | Global matching with softmax | |
| [16] | VideoFlow with temporal info | Temporal coherence | |
| [17] | Geometric matching | Geometric constraints in matching | |
| [18] | Deep Inverse PatchMatch | Patchmatch refinement | |
| [19] | Cross-Attentional Flow Transformer | Cross-attention for robust flow | |
| Depth Estimation | [20] | Self-supervised monocular depth | Self-supervised depth estimation |
| [21] | Explicit depth supervision | Improves accuracy with depth supervision | |
| [22] | Transformer-CNN hybrid | Combines Transformer with CNN | |
| [23] | Adaptive bins | Adaptive depth bins | |
| [24] | Self-supervised with depth cues | Depth cues for segmentation | |
| [25] | Wavelet decomposition | Wavelet-based depth prediction | |
| [26] | CRFs with contextual refinement | CRF for depth refinement | |
| [27] | Transformer for stereo | It uses a transformer for stereo-depth | |
| [28] | Self-supervised vision transformer | Vision transformer for depth | |
| [29] | Attention-based aggregation | Attention to contextual aggregation | |
| [30] | Content adaptive multi-res merging | Merging for high-res depth | |
| [31] | Self-supervised depth estimation | Self-supervised depth for segmentation | |
| Semantic Segmentation | [32] | High-resolution representation learning | High-res representations |
| [33] | Real-time BiSeNet reevaluation | Optimized for real-time performance | |
| [34] | Progressive semantic segmentation | Progressive refinement | |
| [35] | PID controller-based network | PID control for segmentation | |
| [36] | HRNet and PSPNet for multiband | Multiband segmentation with HRNet | |
| [37] | Transformer for segmentation | Transformer-based model | |
| [38] | Object context for segmentation | Object context integration | |
| [39] | Optimized HRNet | Optimized HRNet for segmentation | |
| [40] | High-resolution with dual attention | High-res and boundary-aware |
| Study | Method | Key Features | Strengths | Limitations |
|---|---|---|---|---|
| [41] | Unsupervised Monocular Visual Odometry | Multiscale modeling with atrous convolutions, nonlocal self-attention | Enhances pose and depth estimation in rotating scenes | Inefficiencies in rescaling for feature fusion |
| [42] | Competition-Cooperation Transformer Network | Transformer-based architecture for the joint estimation of pose, depth, and optical flow | Captures complex visual perception tasks | High computational complexity |
| [43] | Deep Direct Visual Odometry | CNN/RNN-based deep learning framework for direct camera motion estimation | Real-time pose estimation for autonomous driving | Limited robustness in dynamic environments |
| [44] | ContextAVO | Local context guidance for pose refinement, CNN/RNN-based architecture | Refines poses in visual odometry with attention | Performance may degrade in highly dynamic scenarios |
| [45] | EMA-VIO | Deep visual-inertial odometry with external memory attention | Robust to long-term dependencies, sensor fusion | Requires inertial sensors, increasing system complexity |
| [46] | AirVO | Point-line feature combination for illumination robust odometry | Effective in varying illumination conditions | Sensitive to feature quality, may underperform in low-texture areas |
| [47] | DeepAVO | Deep learning-based pose refinement with feature distillation | Efficient pose refinement | Sensitive to visual noise and inconsistent lighting |
| [48] | D3VO | Deep depth, pose, and uncertainty estimation, self-supervised | High accuracy comparable to stereo/LiDAR systems | Limited adaptability across different cameras and environments |
| Preprocessing 1 | Seq 00 | Seq 01 | Seq 02 | Seq 04 | Seq 05 | Seq 06 | Seq 07 | Seq 08 | Seq 09 | Seq 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| No preprocess (DeepVO) | 45.58 | 257.7 | 625.7 | 37.33 | 70.95 | 231.5 | 80.48 | 91.39 | 177.5 | 577.1 |
| OpticalFlow | 3.806 | 56.50 | 72.57 | 252.9 | 13.56 | 305.4 | 15.22 | 24.79 | 72.17 | 1369 |
| OpticalFlow & Depth | 13.41 | 305.2 | 159.6 | 315.6 | 64.52 | 95.43 | 3.799 | 58.87 | 41.62 | 246.2 |
| OpticalFlow, Depth & Segmentation | 3.767 | 28.09 | 9.695 | 10.48 | 16.20 | 4.312 | 6.573 | 0.643 | 30.43 | 30.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghasemieh, A.; Kashef, R. Advanced Monocular Outdoor Pose Estimation in Autonomous Systems: Leveraging Optical Flow, Depth Estimation, and Semantic Segmentation with Dynamic Object Removal. Sensors 2024, 24, 8040. https://doi.org/10.3390/s24248040
Ghasemieh A, Kashef R. Advanced Monocular Outdoor Pose Estimation in Autonomous Systems: Leveraging Optical Flow, Depth Estimation, and Semantic Segmentation with Dynamic Object Removal. Sensors. 2024; 24(24):8040. https://doi.org/10.3390/s24248040
Chicago/Turabian StyleGhasemieh, Alireza, and Rasha Kashef. 2024. "Advanced Monocular Outdoor Pose Estimation in Autonomous Systems: Leveraging Optical Flow, Depth Estimation, and Semantic Segmentation with Dynamic Object Removal" Sensors 24, no. 24: 8040. https://doi.org/10.3390/s24248040
APA StyleGhasemieh, A., & Kashef, R. (2024). Advanced Monocular Outdoor Pose Estimation in Autonomous Systems: Leveraging Optical Flow, Depth Estimation, and Semantic Segmentation with Dynamic Object Removal. Sensors, 24(24), 8040. https://doi.org/10.3390/s24248040