1. Introduction
In recent years, there has been an increasing interest in utilizing and modeling energy-related large datasets. For example, to improve the accuracy of time-series data prediction in smart grids, researchers have introduced advanced short-term load prediction methods using matrix factorization [
1] and federated machine-learning frameworks [
2]. Efforts are being made to find effective solutions for classifying and clustering time-series data to solve real-world problems, such as detecting building occupancy, energy theft, and cyber attacks [
3,
4,
5,
6,
7,
8,
9,
10]. In addition, research has been conducted on missing value imputation [
11] and privacy-preserving methodologies [
12], which have improved the reliability and efficiency of smart grids.
Despite the growing demand for data application within the energy sector, a critical challenge lies in addressing data privacy concerns. A major issue regarding the privacy issue of energy datasets is that they often contain personal or household privacy information. For example, the dataset may reveal a household’s daily life and habits through electricity usage patterns and activity times. The privacy concern is a pertinent barrier in energy research and applications as privacy-related regulations often limit further data analyses, sharing, and publication [
13]. To address these challenges, the deployment of synthetic data has become increasingly essential. Synthetic data of energy data enables the sharing and disclosure of privacy-protected data. It is no longer necessary to disclose original data that contain sensitive privacy information.
Synthetic data are data that have been generated using a purpose-built mathematical model or algorithm, with the aim of solving data science tasks [
14]. As artificially generated datasets, they minimize the risk of re-identification of the individual. At the same time, by carefully designing the synthesis algorithm, a synthetic dataset can preserve the statistical structure and properties of the original dataset, allowing for various quantitative analyses, of which the results are practically the same as the analyses carried out on the original dataset. In other words, the use of synthetic data strikes a balance between data utility and privacy by anonymizing micro-level data while maintaining the usefulness of energy data. However, existing approaches, particularly those based on Generative Adversarial Networks (GANs) [
15,
16], often fail to fully capture the time-series nature of energy datasets, limiting their effectiveness in preserving temporal dependencies.
This paper addresses these challenges by proposing a general time-series energy-use data synthesis method designed to preserve both the longitudinal and cross-sectional characteristics of energy datasets. Our approach introduces two key innovations. First, to preserve the longitudinal information we synthesize the rate changes in energy consumption instead of the original consumption values. This conversion turns out to be effective as it can naturally link two consecutive values in a time-series dataset. Second, we apply a calibration technique so that the synthetic dataset has the same mean as the original datasets at each time point. This way the cross-sectional property of the original dataset can be preserved. Our numerical analysis using a real data from a condominium shows that the new method works better than the existing alternative synthesis methods. The contributions of this study are demonstrated through numerical analyses using real data from a condominium, showing that the proposed method outperforms existing alternatives in reproducing the time-series nature of energy datasets.
This paper is organized as follows:
Section 2 reviews previous work on synthetic data generation for energy data.
Section 3 introduces the methodology proposed in this study.
Section 4 includes an introduction to the target energy usage data, followed by the presentation of evaluation metrics and results. Finally,
Section 5 concludes with a discussion of limitations and outlines future research directions.
2. Related Work
The synthesis of time-series energy use has been conducted mainly around GANs. For example, Conditional Tabular GAN (CTGAN) [
17] has been popularly used for data synthesis. The model employs a Conditional GAN to model probability distributions, incorporating a mode-specific normalization approach and training-by-sampling technique. This approach effectively handles multimodal distributions in continuous variables and imbalanced distributions in discrete variables. However, CTGAN often fails to capture original data structure because it is not originally designed for time-series data.
To capture the temporal dependence of time-series data and achieve stable learning, Fekri et al. [
18] introduced R-GAN (Recurrent-GAN), an application of Wasserstein GAN (WGAN) [
19] and Metropolis–Hastings GAN (MH-GAN) [
20]. The R-GAN consists of two stacked Long Short-Term Memorys (LSTMs) [
21] and uses the WGAN algorithm, which updates the discriminator multiple times before updating the generator. The WGAN algorithm is used to mitigate the problem of mode collapse, where either the Generator or the Discriminator become too well trained. However, if it falls into mode collapse, it does not generate diverse data and converges to a certain mode. To avoid this, the MH-GAN method is adopted, which ensures diversity and maintains the quality of the generated data by having the discriminator pick and choose the data most similar to the actual data among the data generated by the Generator. In this way, R-GAN combines WGAN and MH-GAN to capture temporal dependence in time-series data and generate stable and diverse data at the same time.
Also, Li et al. [
22] proposed a Transformer-based Time-Series Generative Adversarial Network (TTS-GAN) designed to handle long-length time-series data, often seen in medical machine learning, where datasets are small and relationships are irregular. TTS-GAN uses transformer-based attention mechanisms, which compare each value to many others, to overcome the gradient loss issues typical of Recurrent Neural Networks (RNNs). This attention allows the model to consider multiple relevant values from different points in the time series simultaneously, ensuring important past values influence the current value. To manage long time-series data, positional embedding is employed, assigning unique vectors to represent each value’s position, ensuring contextualization within the series. TTS-GAN proves effective in generating long, multidimensional time-series energy-use data, addressing the challenges posed by extensive data and small datasets.
Table 1 summarizes the key features, advantages, and limitations of these models.
3. Methods
In this section, we introduce a new data synthesis method called Doubly Structured Data Synthesis (
). The proposed algorithm is designed to capture both cross-sectional and time-series data structures. Details of the algorithm are described step-by step in Algorithm 1.
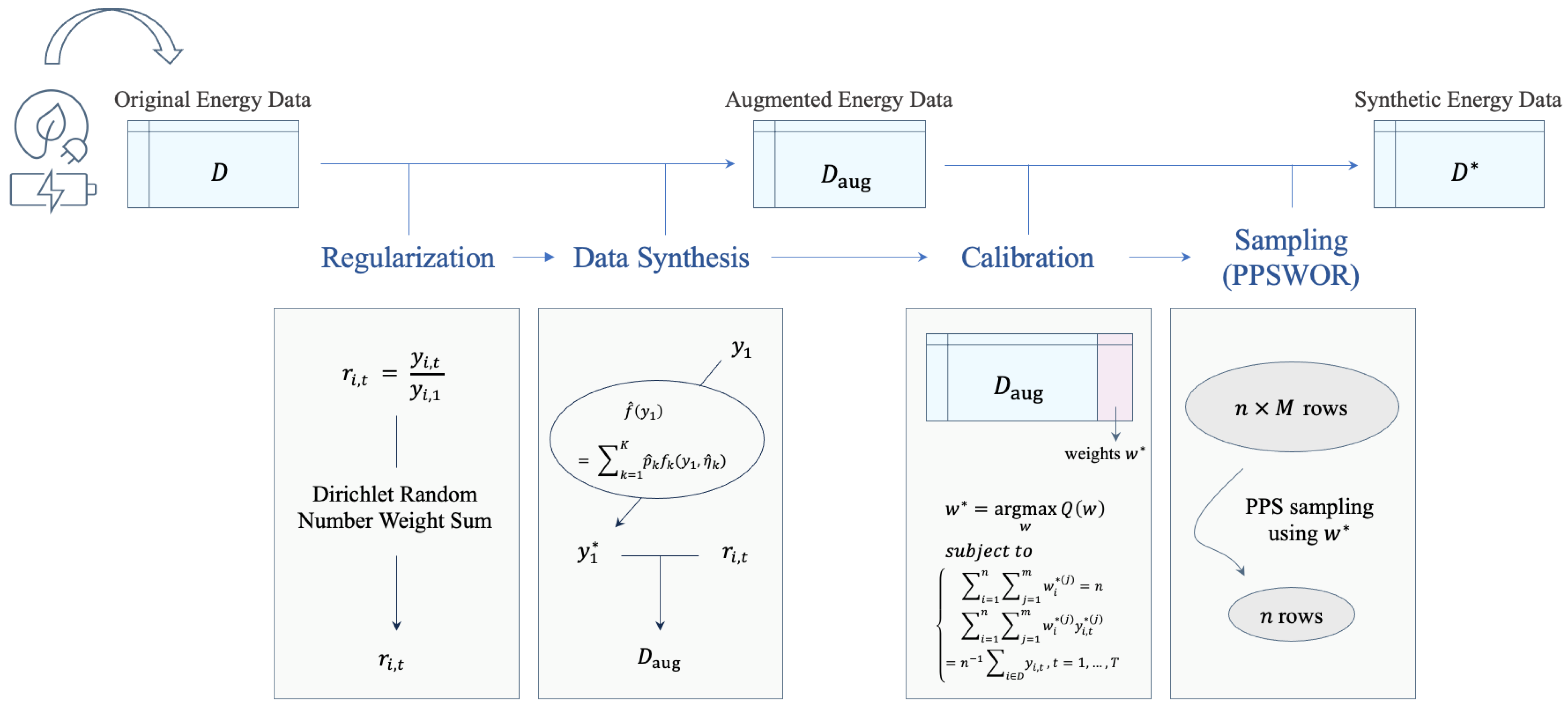
Figure 1 illustrates the overall process of the proposed methods in the diagram.
| Algorithm 1: Algorithm. |
![Sensors 24 08033 i001]() |
3.1. Regularization
Let be the original data with a sample size of n and a time length of T. Here, denotes the positive outcome of unit , measured at time . To handle the time-series data structure, we convert the target outcomes to scaled values with , where are the relative changes from the baseline observation . Furthermore, we define as the vectorized expression of the relative changes. This regularization helps to preserve the time-series structure in the sense that the synthetic values are constructed using the relative changes rather than the changes in original scale. This step is more efficient for large T.
3.2. Data Synthesis
Data synthesis involves two sub-procedures: (1) generating relative changes and (2) creating the synthetic outcomes. To avoid identity disclosure risks, we first create new relative changes using interpolation. For each unit
i,
m candidates of the relative changes are generated in a mixed-up way,
where
,
are randomly chosen from the other actual relative changes. The vector of mixing ratio
is here generated from a Dirichlet distribution with
. An important characteristic of the Dirichlet distribution is that the generated values are between 0 and 1 and their sum is equal to 1. The nuisance parameters
in the Dirichlet distribution controls the size of variations in each time window. The large values with
produce similar values in the range of
. If the disclosure risk is not a critical issue, each mixing ratio can be independently generated from a uniform distribution, for example,
with a large enough
.
After the synthetic relative changes are generated, we generate synthetic values for the target outcomes with a two-step procedure:
- (1)
Generate synthetic values for from a fitted Gaussian mixture distribution.
- (2)
Produce synthetic values for
with
To generate the starting value, we first fit
into a Gaussian Mixture Distribution (GMM),
where
and
is a Gaussian distribution with
. The GMM parameters are estimated using the conventional EM algorithm [
23]. This estimation procedure can be replaced with other parametric, semi-parametric, and non-parametric techniques.
3.3. Calibration
As the results of data synthesis, we have
observations. However, those observations may not preserve the cross-sectional data structure because preserving time structure is only considered during the data synthetic procedure. To capture the cross-sectional data structure, we apply a calibration technique [
24,
25] so that the calibration weights
satisfy the following two constraints:
Constraint (
1) implies that we treat the synthetic samples with a size of
n even if their actual size is
. Also, constraint (
2) indicates that the weighted mean of synthetic values should be similar to the value of the original values in each time window. Furthermore, if a specific condition should be preserved between the original and synthetic datasets, we can add further conditions with any continuous function
, such that
To find the calibration weights, we use a Lagrange method [
25] with a loss function in Equation (
3),
where
are the initial weights assigned on unit
i. Combining the loss function and constraints, we can construct a Lagrangian function,
The optimal values of
, which minimizes the Lagrangian function (
4), can be expressed as
and so we can rewrite constraints (
1) and (
2), incorporating the results in (
5),
From these results, we can compute the calibration weights by solving the estimating Equations (
6) and (
7) with conventional optimization techniques, such as Newton–Raphson or gradient descent algorithms. Note that the calibration weights should be updated several times across
T time windows. See [
25] for more details.
3.4. Sampling (PPSWOR)
We now have
synthetic values, which preserve both time-series and cross-sectional data structures. From these initial candidates, we select the final synthetic samples with a target sample size
. In this study, we assume
for simplicity. To capture the original data structure, we apply a Probability-Proportional-to-Size Without Replacement (PPSWOR) sampling technique, widely-utilized in survey sampling [
26]. This technique ensures that the selection probability of each unit is directly proportional to its size or weight within the target population. The detailed procedures are summarized below:
- (Step 1)
Normalize the calibration weights,
- (Step 2)
Enumerate the normalized calibration weights and synthetic time-series vectors in order of ;
- (Step 3)
Generate a random number, u, from a standard uniform distribution;
- (Step 4)
Select the
s-th synthetic time-series vector as a final sample,
where
- (Step 5)
Repeat Step 3 and Step 4 without replacement until units have been selected.
Since without replacement sampling is applied in this design, the number of replicates, m, should be large enough to preserve the original data structure. Note that or is popularly used in practice.
4. Experiments and Results
4.1. Summary of Data
To check the performance of our proposed algorithm, we applied it to the synthesis of the Advanced Metering Infrastructure (AMI) data. AMI is an integrated system of smart meters, communication networks, and data management systems that can remotely measures consumption data in real time for utilities such as gas, electricity, water, and heat. Thus, AMI plays a pivotal role in providing detailed and real-time insights into energy usage patterns.
The AMI data in this research, collected by the Korea Smart Grid Institute, encompass the records of energy consumption observed in 9986 individual households over nine condominiums in South Korea, spanning April to July 2022. The dataset includes condominium name, household IDs, and monthly electricity consumption. See
Table 2 for the average monthly electricity consumption in the nine condominiums. Note that the increasing trend in consumption suggests seasonality, influenced by rising temperatures and greater use of cooling appliances like air conditioners. Also, each household has different energy consumption patterns due to the different number of household members and life cycles.
4.2. Evaluation Metrics
We consider three data synthesis methods: (Ours), CTGAN, and TTS-GAN. Also, we consider three types of metric, including data similarity, data utility, and data privacy, to evaluate different aspects of the synthetic data. Details on each part are outlined below.
4.2.1. Data Similarity
This part evaluates statistical similarities and the comparison of descriptive statistics at the distributional level. In particular, we use the following specific metrics in this part.
Statistical Comparison and Visualization: To gauge the statistical similarity, the original and a synthetic datasets are compared in terms of standard descriptive statistics, such as mean value () and standard deviation (); clearly, close values indicate high similarity between the two datasets. In addition, kernel density estimation results are presented for a visual comparison of distributional similarities. The degree of overlap between two kernel densities visually indicates the similarity between the probability distributions.
Average Wasserstein Distance (Avg WD): The Wasserstein distance represents the minimum cost between two probability distributions and is calculated via , where is the joint probability distribution in the probability measure space, , and is the cost function. A smaller value of Avg WD indicates that the two datasets are close to one another, while a larger value suggests that the two datasets are far away from one another.
Difference in Correlation (Diff. Corr.): This measures the difference between the correlation of the two datasets. It is calculated by , where the correlation coefficient is obtained by , where is the covariance and and are the respective standard deviations. A smaller Diff.Corr. value means that the two datasets are similarly correlated, while a larger value indicates that the correlation between the two datasets is considerably different.
4.2.2. Data Utility
Data utility represents the usefulness of the synthetic data, indicating the extent to which the synthetic data can be used for a specific analysis or model training. In this research, we evaluate how similar the electricity bills generated using the synthetic dataset are to those generated using the original dataset. The smaller the difference between the two amounts, the more representative the synthetic data is of the original data and the more likely it is to provide actionable information.
In South Korea, electricity bills are composed of the sum of the basic charge, electricity volume charge, climate environment charge, and fuel cost adjustment charge.
Table 3 presents the calculation details for both the base rate and metered rate. More specifically:
The total electricity bill amount is calculated as the sum of the electricity bill, VAT, and electricity industry base fund.
Table 3.
Base rate and metered rate calculation table.
Table 3.
Base rate and metered rate calculation table.
| Base Rate (KRW/Unit) | Metered Rate (KRW/kWh) |
|---|
| 200 kWh or less used | 730 | First 200 kWh | 78.2 |
| 201–400 kWh used | 1260 | Next 200 kWh used | 147.2 |
| More than 400 kWh used | 6060 | Over 400 kWh | 215.5 |
4.2.3. Data Privacy
Data privacy measures how well the synthetic data protects the privacy of the original data provider. If it is difficult to identify or extract sensitive information from the synthetic dataset, the synthetic dataset is deemed highly protective. The data privacy metrics used in this research are presented below.
Distance to Closest Record (DCR): DCR evaluates the ability to identify an individual by calculating the Euclidean distance of the closest record between the synthetic dataset and the original one. The higher the DCR, the lower the likelihood of identification risk in the synthetic data. DCR is defined as
Nearest Neighbor Distance Ratio (NNDR): NNDR represents the ratio of the Euclidean distance between the nearest and next closest neighbors of each synthetic data to the original data, which is in the range [0, 1]. Higher NNDR values indicate better privacy, while lower values indicate the possibility of leaking sensitive information from the nearest original data.
Data Utility and Privacy Index (DUPI): DUPI [
27] was originally designed to evaluate both data similarity and privacy simultaneously. Given the trade-off between data similarity and data privacy, we use this metric for the data privacy evaluation. DUPI and optimal score,
, is calculated using the following equations:
where
and
are the
i-th and
j-th observations of the original and synthetic datasets, with sizes of
and
, respectively. Here,
d can be any metric (distance) function. The value of DUPI can range from 0 to 1, and its expected value becomes approximately 0.5 when
, which represents the optimal case. For a given synthetic dataset, a larger DUPI means higher utility and lower privacy protection, and a smaller DUPI suggests lower utility and higher privacy protection. Addressing the utility–privacy trade-off is essential for synthetic data generation, particularly when sensitive information is involved, as is the case for energy data, which often contain private information. The use of the DUPI metric is especially relevant in this context, as it provides a comprehensive assessment by identifying the optimal balance between data utility and privacy, offering a more effective evaluation compared to conventional metrics. DUPI can be calculated for a given synthetic energy dataset to evaluate the balance between utility and privacy. A DUPI value greater than 0.5 indicates that the synthetic data exhibits higher utility but lower privacy protection, whereas a value less than 0.5 suggests lower utility and higher privacy protection. A DUPI value equal to or close to 0.5 signifies that the synthesis achieves an optimal balance between utility and privacy, aligning with the characteristics of the original energy dataset. Later we will present a graphical representation of the results obtained by applying DUPI to the dataset.
4.3. Results
The data synthesis results are presented below. For simplicity, we have summarized the results for three condominiums: Gongdeok A (Condominium 1), Daegu G (Condominium 2), and Dongjak I (Condominium 3). The results for other condominiums are similar to those of these selected three.
4.3.1. Data Similarity
The comparison of mean and standard deviations of the average monthly electricity energy use for the three selected condominiums is presented in
Table 4.
demonstrates the closest alignment to the original data in both metrics, outperforming CTGAN and TTS-GAN in nearly all cases. This highlights the superior ability of
to accurately replicate the central tendencies and variability of the original dataset.
Figure 2 presents the estimated kernel density functions constructed from households’ original and synthetic electricity usages. TTS-GAN demonstrates notable deviations from the original data across all scenarios, failing to replicate the distribution accurately. On the other hand, CTGAN captures the overall shape reasonably well but tends to overemphasize peaks in certain cases. In contrast,
achieves the closest alignment with the density of the original dataset.
Also,
Figure 3 shows the monthly electricity usage in kWh for Condominium 1 against time in months. It is evident that the synthetic dataset produced from the
method is most similar to the original dataset, capturing the non-decreasing trend over the observation time period. Also, the other two methods exhibit unnatural fluctuations over time, which are not found in the original dataset and the synthetic one from the
method.
As the final similarity comparison, the Avg WD and Dff. Corr. are computed and compared in
Table 5. For the Avg WD side, we see that both
and CTGAN have small distribution differences from the original dataset for all three condominiums, indicating that the synthetic dataset reflects the original one well. On the other hand, the Diff. Corr. comparison shows that both CTGAN and TTS-GAN yield quite large values, implying significant deviation from the original dataset. This shows that GAN-based synthesis methods are rather limited in their ability to model the dependence structure of the original dataset.
4.3.2. Data Utility
Turning to data utility,
Table 6 compares three synthesis methods with estimated electricity bills converted from synthetic electricity usages. We see that, for all three condominiums, the performance of the
method is the best in terms of similarity with the original bills.
The distribution-wise visual comparison based on kernel density estimation for the electricity bill amounts is given in
Figure 4. The figures show that
create a synthetic dataset that is most similar to the original one in terms of the density shape. CTGAN is also capable of producing good synthetic datasets but is sometimes inadequate in properly describing the peak area in the density. Unfortunately, TTS-GAN is subpar in most cases, as shown in the figure. In fact, this visual comparison gives us the same conclusion we have drawn from the data similarity counterparts in
Figure 2.
4.3.3. Data Privacy
The data privacy is evaluated using the DCR and NNDR metrics introduced earlier. The results in
Table 7 show that
has relatively low DCR and NNDR values compared to CTGAN and TTS-GAN, suggesting that it is a model that balances privacy and utility.
The DUPI results are provided in
Table 8. As we set the size of the synthetic datasets to be the same as that of the original dataset, the optimal DUPI value is close to 0.5. From the values in
Table 8 we can see that, for all three condominiums, the
method produces relatively stable DUPI values close to the optimal value, confirming the effectiveness of the method in maintaining the utility and privacy of the original data. The other two methods, CTGAN and TTS-GAN, give much smaller DUPI values close to zero, which implies that these GAN-based methods tend to achieve a high level of privacy protection in exchange for substantial loss in data utility. The results presented in
Table 8 are illustrated in
Figure 5. The x-axis represents the utility metric, while the y-axis represents the privacy metric, with both ranging from 0 to 1. Along the pink curve, the DUPI values are derived, reflecting the trade-off relationship between utility and privacy. In
Figure 5, the intersection of the gray dotted lines represents the point where utility and privacy are balanced. It can be observed that the result of
is the closest to this point.
5. Conclusions
The generation of high-quality synthetic data that can preserve the intricate structure of the original energy-use data and keep the privacy risk minimum is an important issue in data-driven applications and policies in the energy sector.
In this paper, we have introduced a novel data synthesis approach, the methodology, aimed at safeguarding the privacy of AMI-based power consumption data while retaining its essential cross-sectional and time-series characteristics. Carefully crafted with the Dirichlet distribution and Gaussian Mixture models, and further with weight calibration and PPS sampling techniques, this innovative method has solid theoretical foundations, with a great potential to enhance the utility of energy data sharing and analysis.
The simulation results, employing real AMI data, show the exceptional performance of the method. Various comparative analyses demonstrate that the method outperforms existing synthesis methods such as CTGAN and TTS-GAN by accurately preserving the underlying characteristics of the actual AMI dataset with an adequate level of privacy protection. In contrast, CTGAN fails to capture temporal dependencies effectively, limiting its applicability to time-series energy data. TTS-GAN, while capable of handling long time series, requires a significant number of long-term time points for effective training. These limitations highlight the robustness and adaptability of the method in diverse energy data synthesis scenarios.
The proposed method pioneers data synthesis by integrating both the time-series and cross-sectional characteristics of energy consumption data, yet there remains room for future research. First, handling extreme values is a critical challenge in data synthesis due to their rarity and the risks they pose. Retaining extreme values without proper treatment can heighten privacy risks, while eliminating them may distort analyses and predictions for the quantity of interest. A more balanced approach involves implementing robust outlier detection mechanisms to manage extreme values effectively while preserving the utility of the synthesized data. To address this, we are currently enhancing the method by developing a novel utility–privacy scoring framework at the record level, enabling controlled treatment of extreme observations based on their utility–privacy trade-offs.
Future research will also explore the scalability and robustness of when applied to larger datasets or longer time series to ensure its utility and privacy-preserving capabilities. Furthermore, efforts will focus on advancing privacy-preserving algorithms and expanding the applicability of to a wider range of domains, enhancing its adaptability to diverse energy data scenarios. These advancements in synthetic data techniques will significantly improve the sharing and utilization of energy data, providing vital support for energy demand prediction and management.
Author Contributions
Conceptualization: J.K., C.L. and J.H.T.K.; methodology: J.K. and J.H.T.K.; validation: J.K., C.L. and J.C.; formal analysis: J.K. and J.J.; investigation: C.L. and J.C.; resources: C.L. and J.C.; data curation: J.C.; writing—original draft preparation: J.K. and C.L.; writing—review and editing: J.K., C.L., J.J. and J.C.; visualization: J.K.; supervision: J.K., C.L. and J.H.T.K.; project administration: J.K. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Korea Institute of Energy Technology Evaluation and Planning (KETEP) and the Ministry of Trade, Industry & Energy (MOTIE) of the Republic of Korea (No. 2021202090028A).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mansoor, H.; Ali, S.; Khan, I.U.; Arshad, N.; Khan, M.A.; Faizullah, S. Short-Term Load Forecasting Using AMI Data. IEEE Internet Things J. 2023, 10, 22040–22050. [Google Scholar] [CrossRef]
- Biswal, M.; Tayeen, A.S.M.; Misra, S. AMI-FML: A Privacy-Preserving Federated Machine Learning Framework for AMI. arXiv 2021, arXiv:abs/2109.05666. [Google Scholar]
- Ahmed, S.; Lee, Y.; Hyun, S.H.; Koo, I. Unsupervised Machine Learning-Based Detection of Covert Data Integrity Assault in Smart Grid Networks Utilizing Isolation Forest. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2765–2777. [Google Scholar] [CrossRef]
- De Nadai, M.; van Someren, M. Short-term anomaly detection in gas consumption through ARIMA and Artificial Neural Network forecast. In Proceedings of the 2015 IEEE Workshop on Environmental, Energy, and Structural Monitoring Systems (EESMS) Proceedings, Trento, Italy, 9–10 July 2015; pp. 250–255. [Google Scholar] [CrossRef]
- Feng, C.; Mehmani, A.; Zhang, J. Deep Learning-Based Real-Time Building Occupancy Detection Using AMI Data. IEEE Trans. Smart Grid 2020, 11, 4490–4501. [Google Scholar] [CrossRef]
- Ibrahem, M.I.; Abdelfattah, S.; Mahmoud, M.; Alasmary, W. Detecting Electricity Theft Cyber-attacks in CAT AMI System Using Machine Learning. In Proceedings of the 2021 International Symposium on Networks, Computers and Communications (ISNCC), Dubai, United Arab Emirates, 31 October–2 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision Tree and SVM-Based Data Analytics for Theft Detection in Smart Grid. IEEE Trans. Ind. Inform. 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Maamar, A.; Benahmed, K. Machine learning Techniques for Energy Theft Detection in AMI. In Proceedings of the 2018 International Conference on Software Engineering and Information Management (ICSIM ’18), Casablanca, Morocco, 4–6 January 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 57–62. [Google Scholar] [CrossRef]
- Cui, M.; Wang, J.; Yue, M. Machine Learning-Based Anomaly Detection for Load Forecasting Under Cyberattacks. IEEE Trans. Smart Grid 2019, 10, 5724–5734. [Google Scholar] [CrossRef]
- Seem, J.E. Using intelligent data analysis to detect abnormal energy consumption in buildings. Energy Build. 2007, 39, 52–58. [Google Scholar] [CrossRef]
- Kwon, H.R.; Kim, P.K. A Missing Data Compensation Method Using LSTM Estimates and Weights in AMI System. Information 2021, 12, 341. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, W.; Fan, C.I.; Chang, L.; Cheng, C. A Practical Privacy-Preserving Data Aggregation (3PDA) Scheme for Smart Grid. IEEE Trans. Ind. Inform. 2019, 15, 1767–1774. [Google Scholar] [CrossRef]
- Lee, J.T.; Freitas, J.; Ferrall, I.L.; Kammen, D.M.; Brewer, E.; Callaway, D.S. Review and Perspectives on Data Sharing and Privacy in Expanding Electricity Access. Proc. IEEE 2019, 107, 1803–1819. [Google Scholar] [CrossRef]
- Jordon, J.; Szpruch, L.; Houssiau, F.; Bottarelli, M.; Cherubin, G.; Maple, C.; Cohen, S.N.; Weller, A. Synthetic Data—What, why and how? arXiv 2022, arXiv:cs.LG/2205.03257. [Google Scholar]
- Asre, S.; Anwar, A. Synthetic Energy Data Generation Using Time Variant Generative Adversarial Network. Electronics 2022, 11, 355. [Google Scholar] [CrossRef]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Generative Adversarial Network for Synthetic Time Series Data Generation in Smart Grids. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional GAN. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Fekri, M.N.; Ghosh, A.M.; Grolinger, K. Generating Energy Data for Machine Learning with Recurrent Generative Adversarial Networks. Energies 2019, 13, 130. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, PMLR. Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Volume 70, pp. 214–223. [Google Scholar]
- Turner, R.; Hung, J.; Frank, E.; Saatci, Y.; Yosinski, J. Metropolis-Hastings Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6345–6353. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Metsis, V.; Wang, H.; Ngu, A.H.H. TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Halifax, NS, Canada, 14–17 June 2022. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Deville, J.C.; Särndal, C.E. Calibration Estimators in Survey Sampling. J. Am. Stat. Assoc. 1992, 87, 376–382. [Google Scholar] [CrossRef]
- Lee, H.H.; Park, S.; Im, J. Resampling Approach for One-class Classification. Pattern Recognit. 2023, 143, 109731. [Google Scholar] [CrossRef]
- Hansen, M.H.; Hurwitz, W.N. On the Theory of Sampling from Finite Populations. Ann. Math. Stat. 1943, 14, 333–362. [Google Scholar] [CrossRef]
- Jeong, D.; Kim, J.H.T.; Im, J. A New Global Measure to Simultaneously Evaluate Data Utility and Privacy Risk. IEEE Trans. Inf. Forensics Secur. 2023, 18, 715–729. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}