1. Introduction
Human Activity Recognition (HAR) refers to the automatic detection and classification of human actions or behaviors using various data sources. HAR plays a pivotal role in ubiquitous computing by enabling intelligent services that can enhance daily life, improve health outcomes, and ensure safety. Some of the key applications of HAR include the following:
Ambient Assisted Living: Supporting independent living for the elderly and individuals with disabilities by monitoring daily activities [
1].
Fitness and Sports: Enhancing performance tracking and providing personalized feedback for athletes and fitness enthusiasts [
2].
Rehabilitation: Assisting in the recovery process by monitoring and analyzing patient movements [
3].
Security Surveillance: Enhancing security systems by detecting suspicious or unusual activities [
4].
Health Monitoring: Continuously tracking health-related activities to prevent and manage medical conditions [
5].
HAR methodologies are broadly classified into two categories: sensor-based and camera-based approaches.
Sensor-based HAR leverages data from embedded and wearable devices, which have seen widespread adoption due to their portability and ability to collect continuous data. The proliferation of these devices has made sensor-based HAR highly popular, finding applications across various domains, as mentioned above.
Camera-based HAR, on the other hand, utilizes cameras or video data to recognize human activities. While this approach can capture rich contextual information and detailed movements, it also presents challenges such as performance degradation under low-light conditions, obstructed camera viewpoints, and significant privacy concerns.
Given these considerations, this review primarily focuses on sensor-based HAR, particularly addressing the challenges associated with data heterogeneity. Data heterogeneity in sensor-based HAR encompasses variations in sensor types, data formats, and environmental conditions, which can significantly impact the accuracy and reliability of activity recognition systems.
Currently, most state-of-the-art sensor-based HAR machine learning algorithms assume that the test and training samples satisfy the hypothesis of IID (Independent and Identically Distributed) data [
6] to ensure the generalization ability of the sensor-based HAR model. However, the practical situation often deviates from this ideal scenario encountered in experimental environments, as shown in
Figure 1, leading to a dramatic decline in model performance. For instance, different individuals exhibit varying physiological characteristics, such as age, weight, and height, resulting in distinct activity data distributions. This variation in data distributions is commonly referred to as data heterogeneity [
7].
Data heterogeneity frequently arises in embedded and IoT sensors, where datasets collected from diverse devices, users, and environments exhibit non-uniform distributions. This poses a significant challenge to conventional HAR methods, as their performance typically depends on consistent and uniform data assumptions. Although data heterogeneity is a common issue across the AI community, its manifestation in sensor-based HAR is uniquely influenced by the specific application context [
8]. Addressing data heterogeneity can greatly enhance model performance; reduce computational costs; and facilitate the development of personalized, adaptive, and robust HAR models with minimal annotation effort [
9].
Given the complexity and variability of HAR data, traditional rule-based or statistical methods are insufficient for capturing the intricate relationships in heterogeneous datasets. This has led to the increasing adoption of machine learning-based approaches, which offer several advantages for sensor-based HAR:
Learning Complex Patterns: Machine learning algorithms can automatically identify and learn intricate patterns and dependencies in large-scale sensor data, enabling superior performance in recognizing diverse human activities.
Adaptability to Non-Stationary Data: Modern machine learning models, particularly deep learning techniques, can adapt to non-stationary and heterogeneous data, making them well-suited for real-world scenarios.
Generalization Across Scenarios: Through transfer learning, domain adaptation, and other advanced techniques, machine learning methods can generalize effectively across users and environments, addressing the challenges of data heterogeneity.
Reduced Manual Effort: Machine learning approaches minimize the need for hand-crafted features and domain-specific expertise, streamlining the model development process.
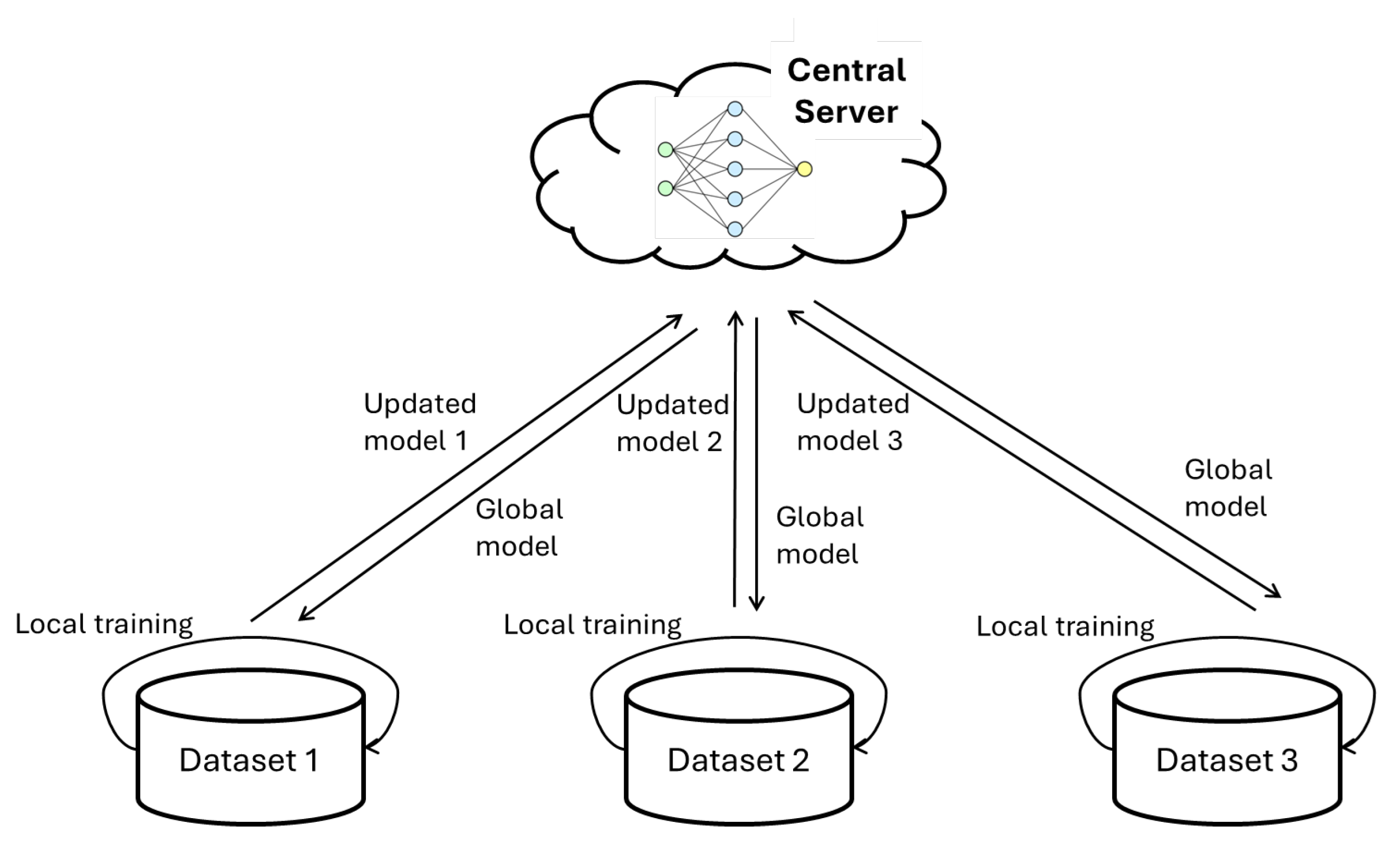
Support for Personalization: With techniques like meta-learning and federated learning, machine learning methods enable the development of personalized HAR models that cater to individual users’ unique characteristics and preferences.
Therefore, machine learning has become a fundamental component of sensor-based HAR research, driving innovations aimed at tackling data heterogeneity.
In this review, we seek to answer the following research questions:
This review analyzes recent advancements in the field, providing insights into the suitability of various machine learning approaches for different types of data heterogeneity. Furthermore, it identifies gaps that warrant further exploration. To the best of our knowledge, this is the first review that specifically focuses on data heterogeneity issues in sensor-based HAR applications.
In order to keep a clear focus, we applied some constraints to our survey. This review focuses on the sensor-based HAR data heterogeneity issues, and camera-based HAR is not considered in this study unless it is used in conjunction with sensor-based approaches. Also, this review specifically focuses on sensor-based HAR for general physical and daily activities such as walking, jumping, taking a shower, washing dishes, etc. Application-specific activities such as fall detection or human disease/ill responses are not covered in this review.
The remainder of this paper is structured as follows.
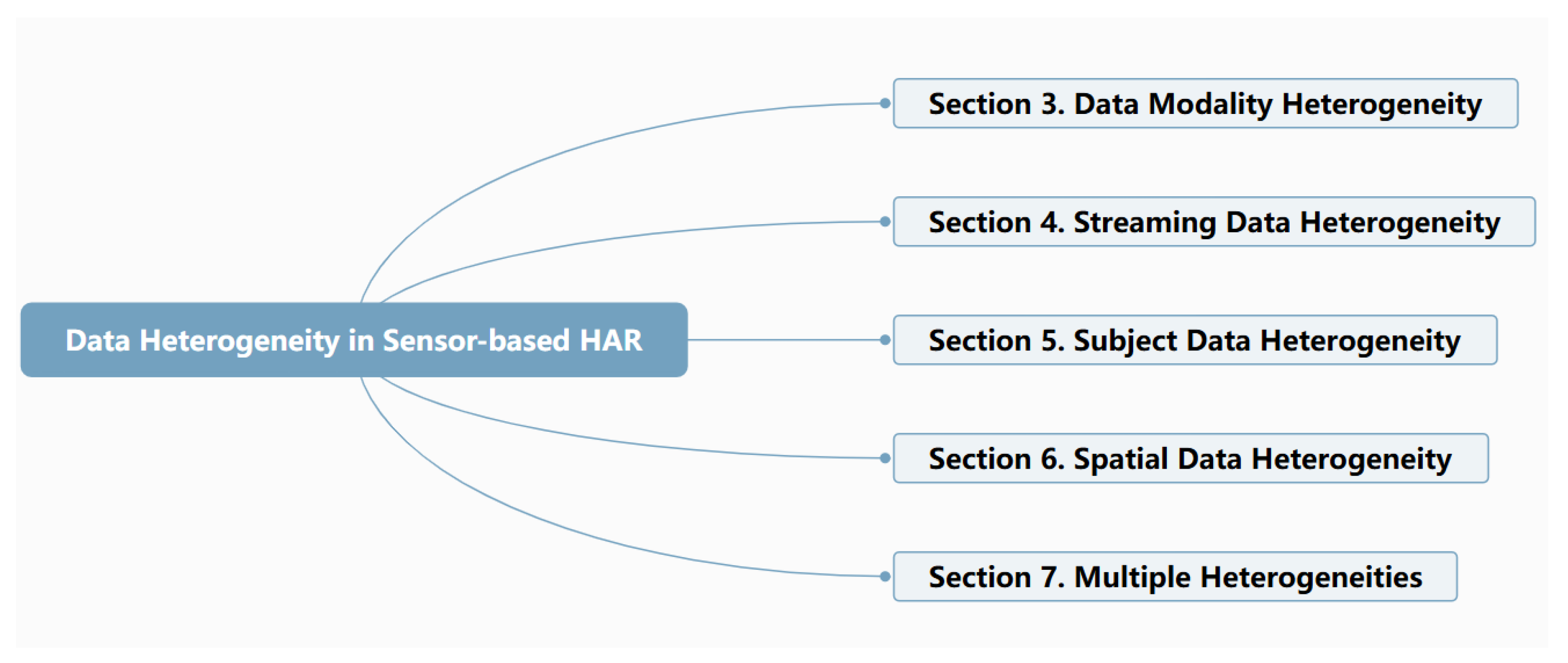
Section 2 summarizes and categorizes the different types of data heterogeneity in sensor-based HAR, followed by a background introduction to the typical machine learning paradigms.
Section 3,
Section 4,
Section 5,
Section 6 and
Section 7 review different machine learning paradigms in different types of sensor-based HAR data heterogeneity, namely, data modality heterogeneity, streaming data heterogeneity, subject data heterogeneity, and spatial data heterogeneity, as well as a general framework for multiple heterogeneities.
Section 8 introduces the available public datasets for various types of data heterogeneity in sensor-based HAR. Finally, future directions and conclusions are presented in
Section 9.
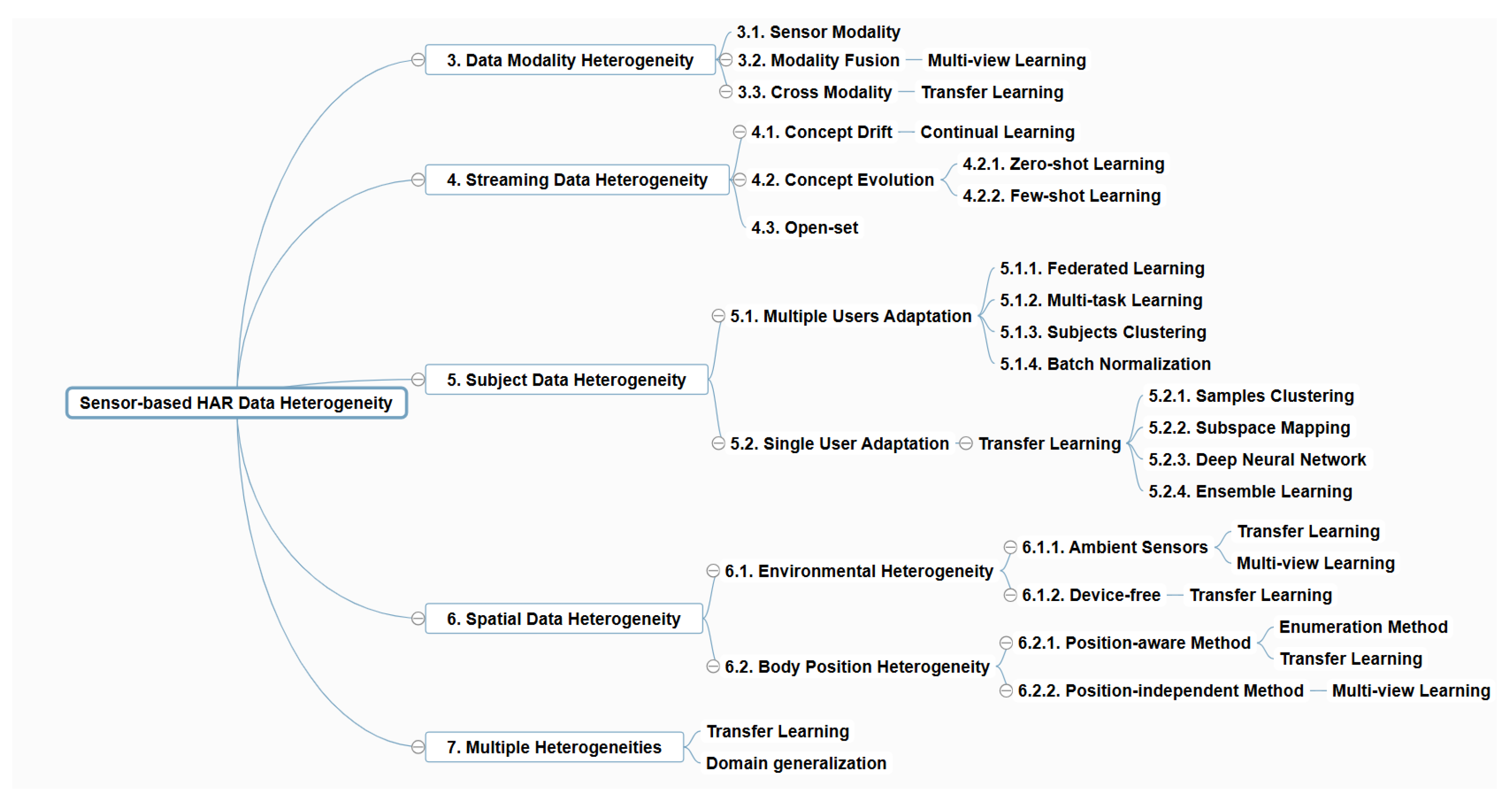
3. Data Modality Heterogeneity
We begin by discussing data modality heterogeneity in sensor-based HAR. Various types of data modalities are employed in different scenarios to implement sensor-based HAR, as summarized in
Table 2. The performance of such systems is highly dependent on the choice of sensor modalities used as data sources. Machine learning techniques for addressing data modality heterogeneity are mainly partitioned into modality fusion and cross-modality methods. Modality fusion aims to combine and integrate multiple sensor modalities into a unified form using multi-view learning. For example, IMU sensor-based HAR can be combined with camera-based HAR to provide broader views and compensate for the limitations of IMU sensors alone. Cross-modality methods focus on transforming data from one modality to another to achieve certain goals under transfer learning paradigms. For instance, knowledge from camera-based HAR can be transferred to sensor-based HAR to enhance its performance.
3.1. Sensor Modality
Sensor modalities are classified into three types: inertial measurement unit sensors, ambient sensors, and device-free sensors [
24,
25,
26].
IMU sensors measure the angular rate; force; and, sometimes, magnetic fields. They are portable and can be deployed at different body positions, such as the waist, ankle, arm, leg, back, and chest, to directly capture data on body context. IMU sensors can also be embedded in smartphone carried in pockets or held in hands to collect data. They are very common in HAR research and have broad application scenarios such as daily activity recognition [
27], sports activity recognition [
28], and working activity recognition [
29].
Ambient sensors are typically deployed in the environment at fixed positions to capture interaction information between humans and their surroundings. In HAR scenarios, they are essential devices in smart homes (or related applications) and can be embedded with additional position information.
Device-free sensors represent a new trend in wireless sensing research for HAR. Wireless signals can not only be utilized as communication tools to exchange data but also have the ability to reflect differences in various human behaviors and sense variations in the surrounding environment. This type of sensor normally has a transmitter and receiver to send and receive electromagnetic waves. Different human activities lead to different reflected signal patterns. Device-free sensors can usually be deployed on the walls or ceilings of a room.
3.2. Modality Fusion
The purpose of modality fusion is to integrate various sensor modalities to improve the performance of sensor-based HAR systems. The mainstream learning paradigm in modality fusion is multi-view learning, which treats each sensor modality as a separate view. Multiple views synchronously observe the same activity and unite to accomplish the common activity classification task. There are mainly two types of modality fusion: data-level/feature-level fusion and classifier-level fusion. The human activities researched in modality fusion include activities such as going up stairs, going down stairs, walking, biking, standing, pressing buttons, plugging in cables, rotating chairs, using hammers, clapping, crossing arms, bowling, tennis serves, and baseball swings.
Data-level/feature-level fusion extracts features from each sensor and combines them to train a single classification model. The most common approach in feature-level fusion is aggregation, which concatenates the extracted features or certain raw data from all sensors. Ehatisham et al. [
30] focused on feature-level data fusion from two modalities: RGB/depth video camera and inertial body sensors. They extracted features separately, then concatenated the two feature vectors. These features include densely extracted histograms of oriented gradient features from the camera and statistical time-series characteristics from wearable sensor data. Li et al. [
4] combined a Kinect depth camera and wearable sensors as a complementary fusion to improve performance. The depth data features and wearable sensor data are joined in a data-level fusion. Data contraction is realized by feature selection with metaheuristic methods. Finally, incremental learning is applied via the Hoeffding tree and the swarm decision table.
Inspired by the design of the non-local block in self-attention deep networks, which is used to compute relations between different space-time locations of the same instance, Byvshev et al. [
31] adapted the non-local block for heterogeneous data fusion of video and smart-glove data. There are two main modifications: (1) changing from self-attention to cross-modal attention via two multi-modal inputs replacing the input in the original design and (2) adjusting the non-local operation in a way that does not require the matching of spatio-temporal dimensions for data fusion.
In contrast to most work in this field with relatively big differences in modalities, such as ambient sensors and video, Stisen et al. [
32] conducted systematic research on the heterogeneity of 36 smartphones, smartwatches, and tablets with various device models from four manufacturers. Data heterogeneity mainly originates from sensor biases (poor sensor quality or accidental device damage), sampling rate heterogeneity (different device factory settings), and sampling rate instability (varying I/O loads affecting the actual sampling rate). To mitigate the effects caused by heterogeneities, the kNN clustering method is applied to group similar devices; then, a classifier is trained based on the devices’ sensor data in each cluster.
Classifier-level fusion aims to combine classifiers trained on each sensor modality to build a more robust model. This fusion strategy overcomes the drawback of feature-level fusion of feature compatibility issues regarding heterogeneous sampling frequencies and configuration parameters. Garcia-Ceja et al. [
33] proposed a stacking ensemble-based multi-view learning method for modality fusion. Unlike traditional multi-view learning via aggregation, which mixes the feature spaces from multiple views, this method builds individual models for each view and combines them using stacked generalization. The highlight of this paper is the comparison of the audio view, accelerometer view, aggregation view, and multi-view stacking, with results showing that multi-view stacking achieves the best performance.
Using the same stacking ensemble technique as Garcia-Ceja et al. [
33], Chung et al. [
34] extended the meta-learner to include a voting strategy and compared it with the stacking method. They also compared three machine learning models—Random Forest (RF), k-Nearest Neighbors (kNN), and Support Vector Machine (SVM)—in stacking ensembles. Xue et al. [
35] proposed a deep learning architecture for unified multi-modality fusion that considers the different sensors’ data quality for information-weighted adjustment and the correlations among various sensors. The sensor-representation module is a Convolutional Neural Network (CNN) structure that extracts low-dimensional features of the same size, even with non-uniform heterogeneous input. The weighted-combination module is inspired by the attention mechanism, which estimates the quality of each sensor’s data and combines the information in a weighted manner. The cross-sensor module captures the correlations among the various sensor information to learn a more robust model via an averaging operation.
As shown in
Table 3, data-level/feature-level fusion follows a fine-grained fusion approach, considering all the features/data in different modalities together. After the learning process, the weighted contributions of the features/data for the final task can be obtained. In this way, only one classifier is required, which saves training time and computational resources. However, unifying different modality features/data into the same format is an extra step, and feature/data compatibility issues need to be carefully addressed.
The classifier-level fusion approach is a coarse-grained fusion method that focuses on the co-decision of multiple classifiers. It is convenient because there is no need to consider the compatibility issues of different modalities, and each modality can be trained based on its own common method. However, the different classifiers may have biases, and dealing with inconsistent results across classifiers is another problem. Regarding activity categories, data-level/feature-level fusion focuses on atomic activity, daily living activity, and sports fitness activity, while classifier-level fusion considers daily living activity.
3.3. Cross-Modality Methods
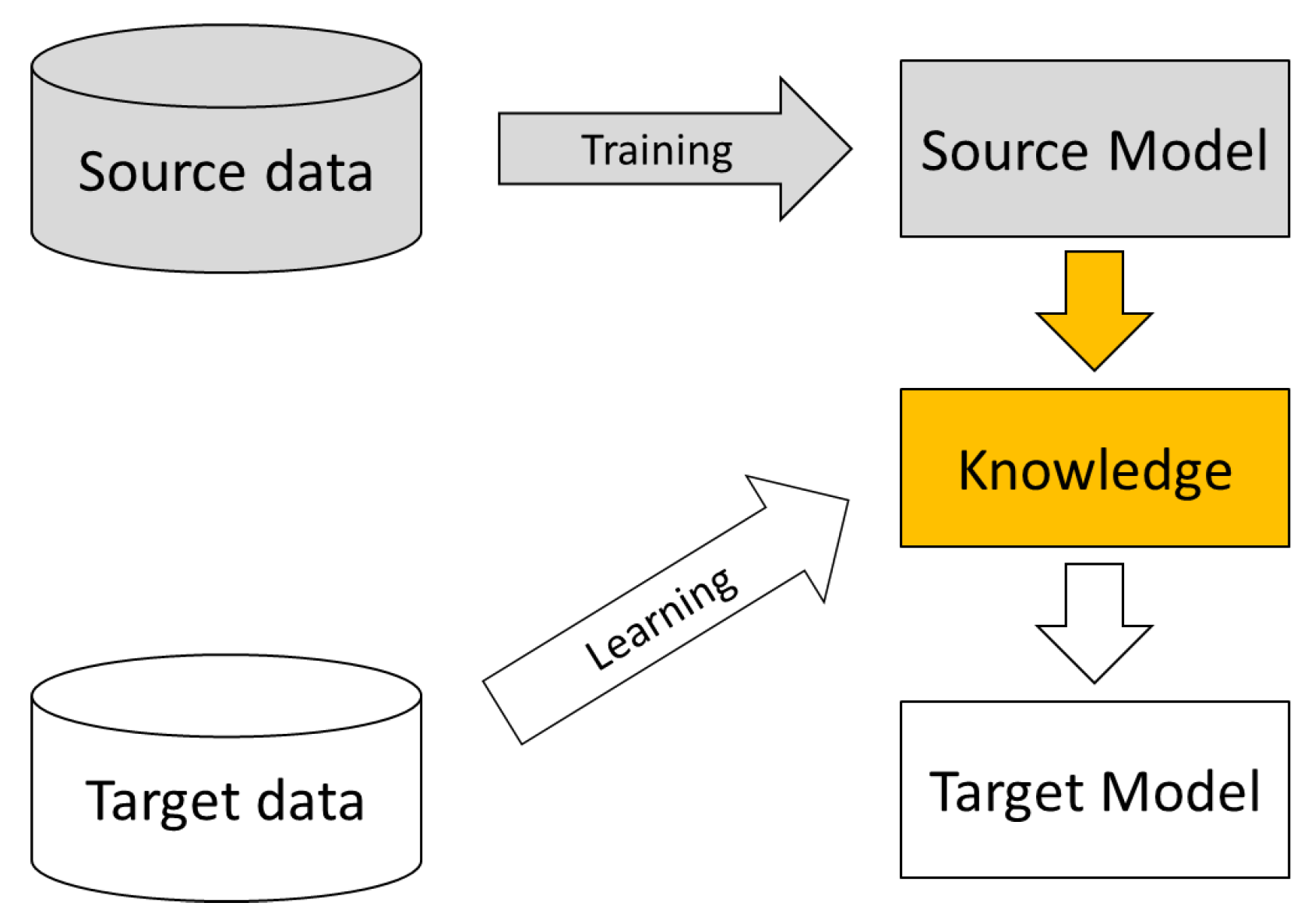
Cross-modality methods aim to transfer knowledge from one modality to another to assist in achieving goals with different data modalities. The main learning paradigm in cross-modality sensor-based HAR is transfer learning because of directional knowledge transformation, the goal of which is to transfer useful information from the source modality to the target modality. Cross-modality knowledge transformation aims to build a bridge and find the latent relationships between different data modalities to take advantage of knowledge from the source domain. There are four main branches in sensor-based HAR cross-modality approaches: deep neural network fine tuning, multi-view transfer learning, knowledge distillation, and generative network methods.
Xing et al. [
36] proposed the deep learning fine-tuning method, which can transfer knowledge across vision, audio, and IMU sensors. For knowledge transfer, source-domain data are fed into a pre-trained model to calculate the activation values in an intermediate layer as a cross-domain shared feature vector. Then, target domain-data are used to train a network to map the shared feature vector to a unified feature space across multiple domains. For task transfer, if the tasks are the same between the source and target domains, the source-domain model’s higher layers for classification can be reused directly in the target-domain model. If the tasks are different, the target model’s low and intermediate layers are frozen, and the target model’s higher layers are re-trained using limited target-domain data.
Feuz and Cook [
37] introduced a multi-view transfer learning algorithm applicable with or without labeled data in the target domain. Ambient sensors, smartphone/wearable sensors, and video cameras use transfer learning to act as colleagues. In scenarios where a small amount of labeled data is available in each view, a separate weak classifier is trained for each view; then, all classifiers select the unlabeled samples to add to the labeled set based on a confidence score. In scenarios with unlabeled target-domain data, subspace learning is utilized to project the source and target domains onto a latent feature space via Principal Component Analysis (PCA) dimensionality reduction. After aligning the subspaces between views via Procrustes analysis, projected data from the source view are used to train a classifier that tests projected data from the target view for data annotation. Finally, a classifier is trained using labeled data in the target view.
Kong et al. [
38] presented a knowledge distillation method for transferring knowledge from a wearable sensor modality to a video camera modality. Knowledge distillation allows the student network to capture the information provided by the ground-truth labels and the finer structure learned by the teacher network [
39]. In the first step of generating the teacher model, multi-view learning is applied to multiple wearable sensors to train a classifier for each sensor; then, a weighted adaptive method is used to combine the classifiers according to their feature representations. In the second step, the teacher model’s knowledge is transferred to the student model by training with classification loss and distillation loss.
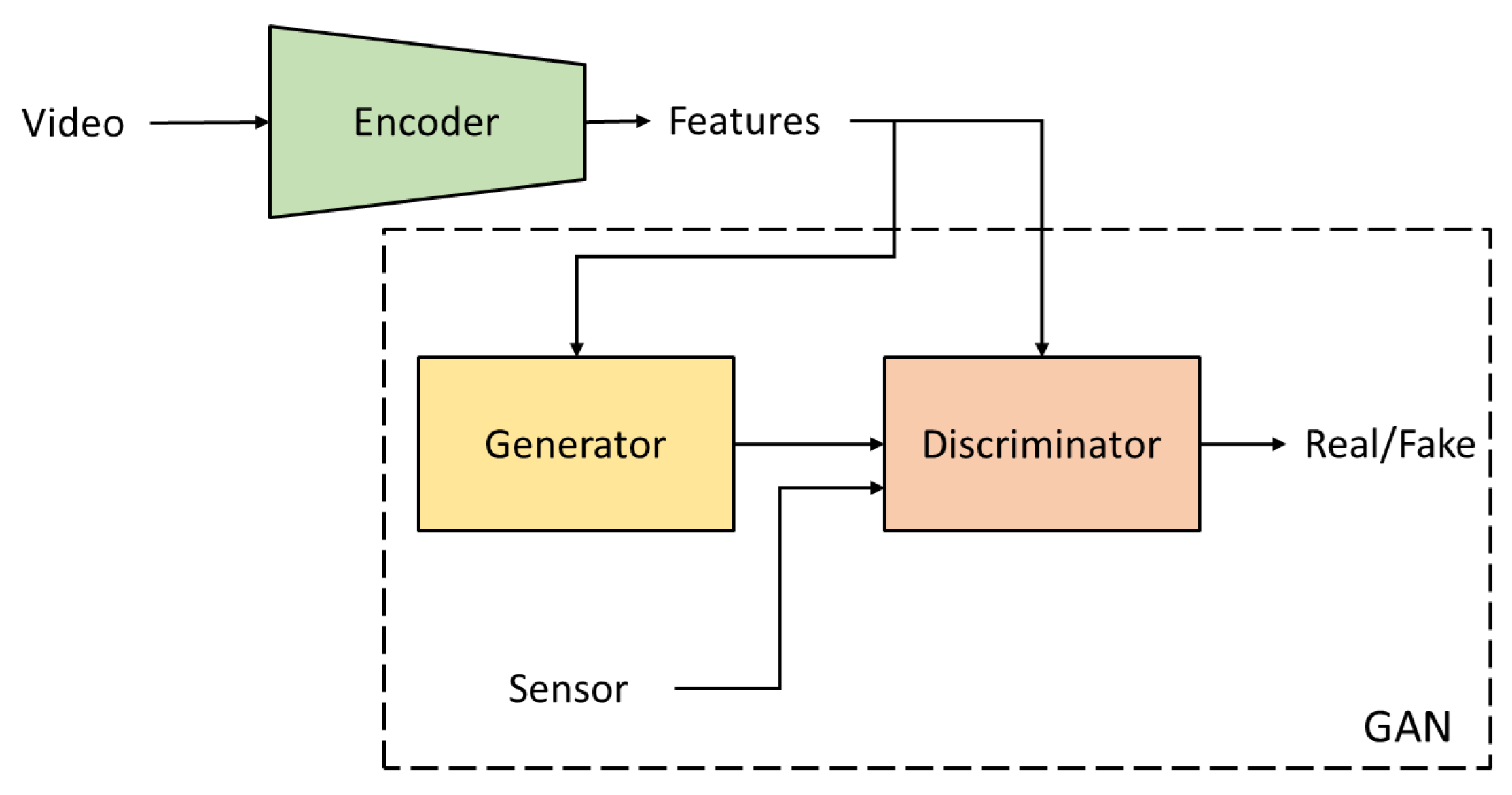
Zhang et al. [
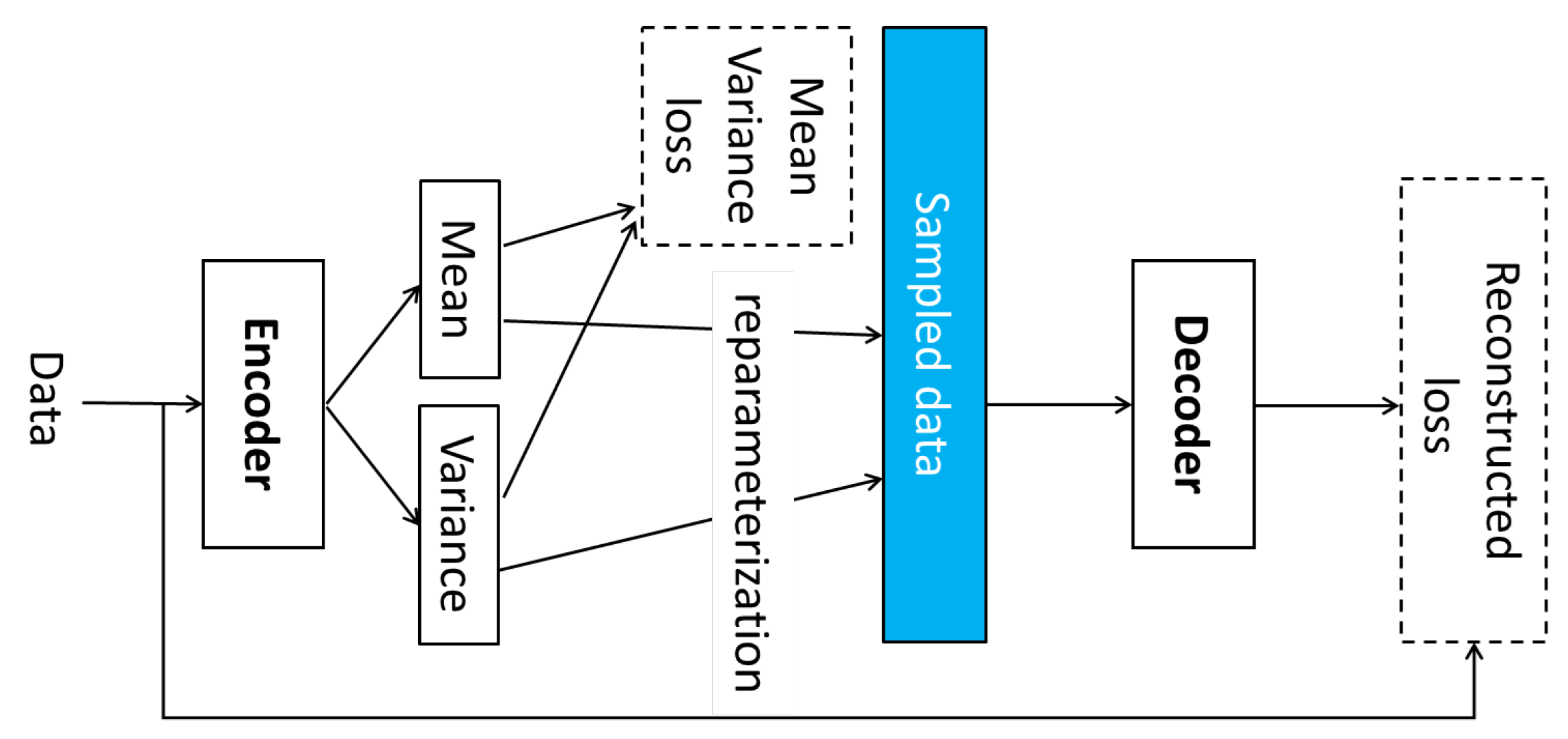
40] worked on deep generative networks for transferring video data to synthetic accelerometer data. They proposed two algorithms: a conditional generative adversarial network (cGAN) and conditional variational autoencoder-conditional GAN (cVAE-cGAN). For cGAN, a video encoder is used to compress the video clip into a feature vector. Then, a GAN models the conditional distribution of sensor data based on the video feature vector, as shown in
Figure 5. cVAE-cGAN is an extended version of cGAN. A cVAE uses the information from the video to learn a conditional distribution of the sensor data based on the idea that prior knowledge from cVAE will improve the generative capability of the GAN.
As shown in
Table 4, among the cross-modality approaches, multi-view transfer learning is the only method that can be applied in scenarios without labeled target-domain data. It considers various classifiers’ results and provides comprehensive views for the target domain’s generation of pseudo-labels, leveraging the wisdom of the masses. However, more training resources are required. In contrast, fine tuning is a more computationally resource-friendly method and does not require training of the model from scratch. The drawback of fine tuning is that performance may drop significantly if the new task is very different from the original task. Knowledge distillation trains the distilled model on the combination of the original model’s predictions and the ground-truth labels, which may improve generalization to new data compared to the original model. However, this type of model compression technique may not capture all the information and nuances present in the original model, potentially resulting in lower performance on certain tasks. The generative network can produce a large amount of synthetic target-domain modality data, which can be useful for data augmentation. However, the generated data may not capture all the nuances and details present in real data, possibly resulting in lower quality or unrealistic outputs. The corresponding human activity categories in each approach are also listed in
Table 4. Fine tuning and generative networks focus on daily living activity and sports fitness activity. The knowledge distillation approach aims to handle daily living activity and atomic activity, while multi-view transfer learning focuses on composite activity.
7. General Framework for Multiple Heterogeneities
Some researchers presented a general framework to handle multiple sensor-based HAR data heterogeneity issues with a sufficient and complete experiment other than the four categories of sensor-based HAR data heterogeneity issues discussed in the previous sections: data modality heterogeneity, streaming data heterogeneity, subject data heterogeneity, and spatial data heterogeneity. Some research has focused on solving sensor-based HAR mixed data heterogeneity scenarios. Here, the transfer learning paradigm is the dominant method.
To better align source-domain and target-domain features, some methods require source-domain data and labeled target-domain data. Feng et al. [
102] proposed a general cross-domain deep transfer learning framework combined with parameter-based transfer learning and cross-domain class-wise similarity. In the first step, a stacked LSTM network with a feature extractor and a classifier is trained, and the training data are source-domain samples. In the second step, the network parameters of the source feature extractor and classifier are transferred to a target network with the same structure. In particular, the weight of the transferred source classifier parameters is dependent on a cross-domain class-wise relevance measure, which includes cosine similarity, sparse reconstruction, and semantically normalized Google distance. Then, the transferred classifier parameters and the source feature extractor parameters are used to initialize the target network. In the last step, fine tuning is applied to adjust the feature extractor and classifier in the target network.
Some work only requires labeled source-domain data and unlabeled target-domain data. Sanabria et al. [
103] proposed a transfer learning framework from the source domain(s) to the target domain via Bi-GAN. The architecture of Bi-GAN consists of two GANs of a generator and a discriminator in the source and target domain, respectively. In the feature-space transformation step, both generators are trained to generate fake samples as close to the real samples in the other domains as possible, and both discriminators are binary classifiers to detect whether an input is generated by their corresponding generators or a real sample from the other domains. In the feature distribution alignment step, the transformed features are shifted to the real target data via kernel mean matching to improve classification accuracy. Then, a classifier is trained on the aligned transformed features, and the features’ corresponding labels are inherited from the source domain. Finally, the classifier is used to label data in the target domain.
Domain generalization is an emerging area of transfer learning that explores how to acquire knowledge from various related domains. It only assumes that samples from multiple source domains can be accessed and target domain can provide no data at all. Limited work has been done in this field. Erfani et al. [
104] proposed the elliptical summary randomization framework for domain generalization comprising a randomized kernel and elliptical data summarization. The data are projected to a lower-dimensional latent space using a randomized kernel, which reduces domain bias while maintaining the data’s functional relationship. The Johnson–Lindenstrauss method provides probabilistic assurances that a dataset’s relative distances between data points are preserved when randomly projected to a lower feature space. Therefore, ellipsoidal summaries are employed to replace the samples to increase generalization by reducing noise and outliers in the projected data. The focal distance between pairs of ellipsoids is then used as a measure of domain dissimilarity. Lu et al. [
105] considered global correlation and local correlation of time-series data. Local and global features-learning and alignment framework was proposed for generalizable human activity recognition.
9. Future Directions
The research work surveyed in this review also identified some future research directions that require further discussion.
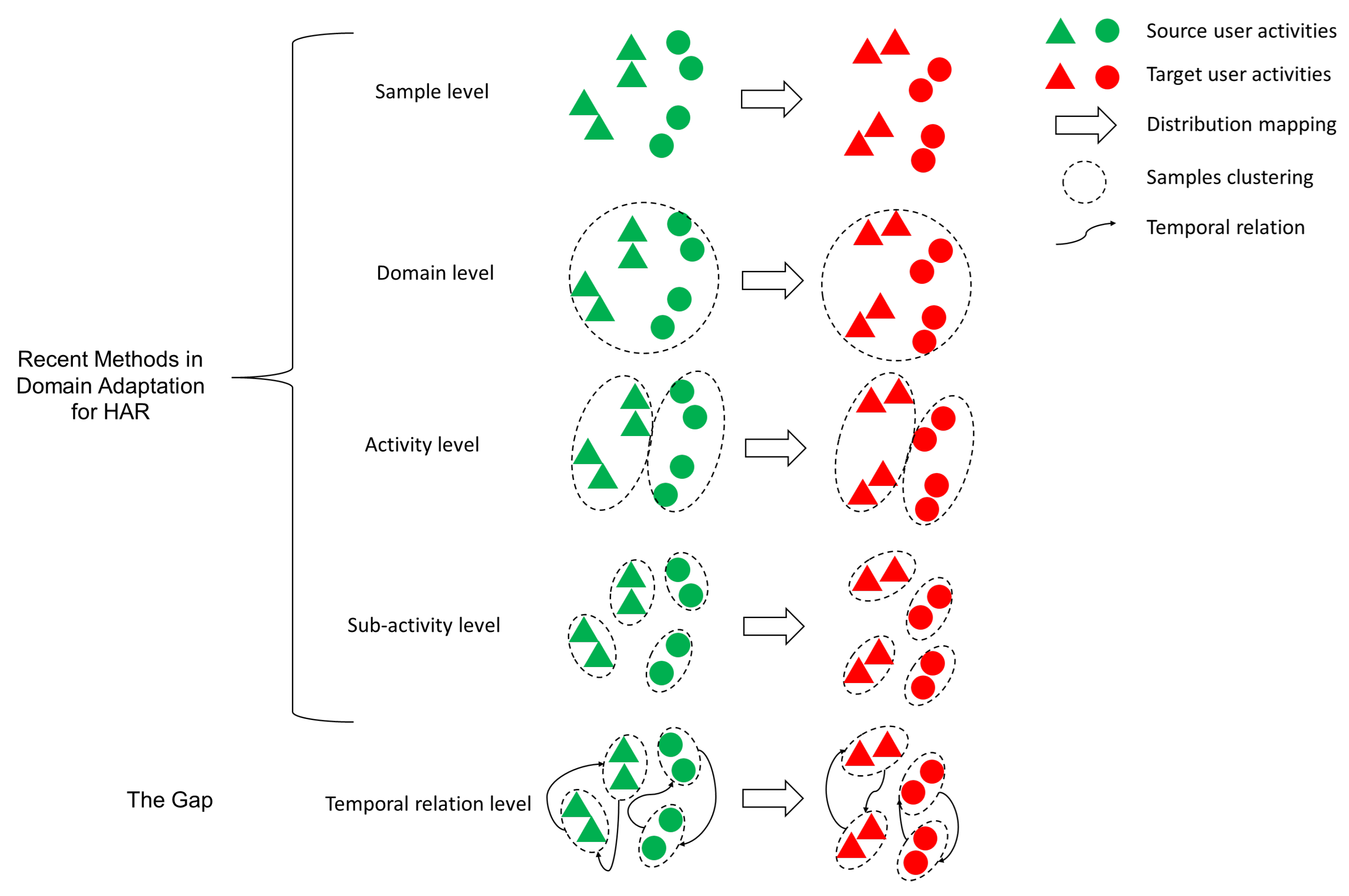
Temporal relationship integration in domain adaptation is a critical and emerging area that requires focused attention in sensor-based HAR. Temporal dynamics are fundamental to HAR, as they capture the sequential dependencies and interactions within time-series data. Despite their importance, current methods often neglect temporal relationships or address them in a limited manner, leading to suboptimal performance when transferring knowledge across domains, as shown in
Figure 8. Recent methods primarily focus on sample-level, domain-level, activity-level, and sub-activity-level domain adaptation for data distribution mapping, whereas temporal relation-level mapping remains less explored. Therefore, future research should prioritize the development of domain adaptation techniques that explicitly model and incorporate temporal relationships to enhance alignment between source and target domains. Methods leveraging temporal patterns can significantly improve generalization, particularly in scenarios involving cross-user or cross-device data heterogeneity. Exploring advanced temporal modeling approaches such as temporal graph networks or attention-based mechanisms could pave the way for breakthroughs in this area.
Cross-modality knowledge transformation in sensor-based HAR is a new and promising research direction. There is still very limited work in this area. Its purpose is to build a bridge and find the relationships between different data modalities to take advantage of knowledge from the source domain, especially under scenarios of difficult data collection from the target domain. If the gap between some modalities’ feature spaces is relatively big and these domains have no direct correlations, it may be difficult to achieve cross-modality knowledge transformation via traditional transfer learning methods. Transitive transfer learning (TTL) [
123] is a potential solution inspired by the idea of transmissibility for indirect reasoning and learning. This method has the capability of assisting in connecting concepts and passing knowledge between seemingly unrelated concepts. Normally, the bridge is built to link unrelated concepts by introducing intermediate concepts. TTL is an important extension of traditional transfer learning to enable knowledge transformation across domains with huge differences in data distribution. There are two key points the need to be considered: (1) how to select the appropriate intermediate domain as the bridge between the source domain and target domain and (2) how to transfer knowledge efficiently across the connected domains.
The use of adaptive methods for unseen activities is another relatively new topic in sensor-based HAR at present and can be applied to more challenging and practical scenarios. It aims to learn a model that can generalize to a target domain with one or several differences but related source domain(s). It only assumes that samples from multiple source domains can be accessed and has no access to the target domain. For HAR, this research topic is suitable for various situations. For example, the activity data originate from multiple existing users (source domains) are difficult to obtain from a new user (target domain). In this case, the methods of domain generalization can be explored to handle this type of challenge. Moreover, extra semantic information can be introduced as external Supplementary Information. Current research focuses on embedding word vectors such as Word2Vec that build the semantic connections between the activity verbs and object nouns to transfer the classification label space to word vector space. Other types of external Supplementary Informationmay also be explored and introduced to help adaptive methods for unseen activities. For example, research on the the human skeleton and muscle structure in the medical field can be applied to HAR.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}