1. Introduction
In accurate photogrammetry, exact localization of keypoints in images directly influences the fidelity of the resulting 3D reconstruction. Traditionally, in marker-based photogrammetry, optical markers, a type of retro-reflective fiducial marker, have been utilized to achieve high levels of measurement precision and accuracy by using their centers as keypoints. However, employing them requires adhering stickers onto the surfaces of objects and scenes to be measured, which can be laborious and time-consuming.
This study explores the use of molded markers, which are created during the fabrication (molding) process of composite pieces. Initially intended to guide specific operations, these markers are integrated into composite parts. This integration not only eliminates the need for the manual application and removal of stickers but also facilitates the use of these markers in photogrammetry systems, particularly within assembly lines. Moreover, as they are designed and placed to be the reference of the operations, it eliminates the need for further referencing of the photogrammetric systems, reducing the uncertainty chain.
The approach also addresses the challenge of applying stickers to pieces with materials that have specific processing properties, which may prevent adhesion. The molded markers, which come in various forms such as crosses and dots, are relief features on the surface of the composite material. This study specifically focuses on cross-shaped molded markers as fiducial markers, aiming to develop a detection system suited for controlled environments, such as those found in industrial settings. The conditions addressed in this work reflect those typically encountered in such environments.
Non-uniform lighting conditions and composite materials introduce complexity into the detection process due to their lack of reflective properties compared to optical targets. This is heightened at distances exceeding 500 mm, a common scenario in photogrammetric applications. To overcome these challenges and effectively leverage the relief texture of the markers, this paper explores the use of polarimetric cameras.
The contributions of this study are as follows:
Introduction of a Novel Detection Method: A new, accurate method for detecting the centers of molded markers used in photogrammetry systems is introduced. This method integrates deep learning techniques for initial detection with advanced image processing for accurate center localization.
Analysis of Data Augmentation Techniques: Data augmentation techniques that incorporate polarimetric physics directly into camera outputs (intensities) are examined, along with various polarimetric image representations.
Enhanced Marker Distinguishability: Improved distinguishability of relief-type markers on composite materials is demonstrated using polarimetric images.
3D Photogrammetric Reconstructions: 3D photogrammetric reconstructions based on these markers are conducted, with results compared to ground truth data obtained from a laser tracker to assess the accuracy of the system.
2. Related Work
This section presents a comprehensive review of the relevant literature on photogrammetry systems, with a particular focus on the various types of markers utilized in these systems. Following the discussion on markers and their detection, it also examines advancements in object detection methods, which are critical for their localization. Additionally, it explores the role of polarimetry as an enabling technology for detecting accurately molded markers, its applications across different fields, and the integration of polarimetric images with neural networks.
2.1. Photogrammetry Systems
Photogrammetry entails accurately measuring the 3D coordinates of keypoints using various perspective images [
1] reconstructed by triangulation [
2]. This can be achieved using multiple fixed cameras or a portable system with a single camera that is moved to capture different viewpoints. In the domain of accurate industrial metrology, especially in large volumes, it has emerged as one of the preferred choices due to its versatility and relatively lower investment requirements [
3].
Markers
Photogrammetry systems involve detecting keypoints on the objects to be measured. These keypoints can be identified using a variety of methods, which are broadly categorized into marker-less techniques and fiducial marker-based approaches.
Marker-less techniques leverage natural features in the images. Traditional approaches often rely on natural descriptors, such as corners or texture patterns, for keypoint detection [
4,
5]. However, their effectiveness is limited in industrial environments, where objects may lack sufficient texture or distinctive features. Structured light-based approaches address this challenge by projecting patterns onto the object to facilitate keypoint detection [
6,
7]. While these techniques can be highly effective, their accuracy depends heavily on the quality of the projection system, which introduces high costs and system complexity, limiting their applicability in certain scenarios. Alternatively, other marker-less techniques use specific edges or geometric features as references to define virtual keypoints. For example, some methods analyze the relative positions of edges to estimate motion and vibrations, as seen in rotating cylindrical structures [
8] or wind turbine blades [
9]. These methods are typically limited to easily detectable edges, making them more suited for motion analysis than dimensional reconstruction. Furthermore, Artificial Intelligence (AI)-based approaches for keypoint estimation have emerged. In applications like railway maintenance, AI models have been used to estimate predefined keypoints for displacement measurements [
10]. However, the accuracy of these AI models remains insufficient.
Thus, when high dimensional accuracy is required, fiducial marker-based approaches remain the preferred method [
3]. Among these, optical marker stickers are the most commonly used due to their retro-reflective properties, which allow for clear differentiation from surrounding objects [
11,
12]. However, this approach requires the application and removal of stickers, which is time-consuming and impractical for automatic processes. To avoid the need for stickers, mechanical markers have been explored. One study introduced a novel design using CNC-machined components with two holes of varying diameters as fiducial markers [
13]. However, creating such markers is not always feasible, as it requires modifications to the measured object and can be time-consuming.
2.2. Object Detection
Object detection, a core task in computer vision, involves identifying and localizing objects within an image. Detecting fiducial markers, especially complex ones like the molded markers in this work, often requires advanced methods. Neural networks, particularly Convolutional Neural Networks (CNNs) and transformers, have significantly advanced object detection. Methods are typically categorized as one-stage or two-stage approaches: one-stage models directly predict bounding boxes and classes in a single step, offering speed, while two-stage models first identify regions of interest for classification, prioritizing accuracy.
2.2.1. CNNs
CNN-based one-stage detectors, such as Single Shot Detector (SSD) [
14] and You Only Look Once (YOLO) [
15], along with their various iterations, have revolutionized object detection by offering faster inference speeds, making them suitable for real-time applications while maintaining acceptable accuracy. On the other hand, two-stage methods generally achieve higher accuracy and have been extensively studied. For instance, Faster R-CNN [
16] is well known for its popularity, superior accuracy, and reduced training and inference times compared to earlier models like R-CNN [
17] and Fast R-CNN [
18].
2.2.2. Transformers
More recently, transformer-based models leveraging attention mechanisms have redefined the field of computer vision, often outperforming traditional CNNs. In object detection, one-stage models like DETR [
19] and its successor Deformable DETR [
20] have achieved state-of-the-art results. However, these architectures require substantial amounts of training data to outperform CNN-based methods, limiting their suitability for industrial applications where data availability is often restricted.
A comprehensive overview of the evolution of object detection models introduced in recent years can be found in [
21].
2.3. Polarimetry
Light, as an electromagnetic wave, exhibits three primary physical elements: amplitude, representing brightness; wavelength, indicating colors; and polarization, denoting the direction of wave oscillation [
22]. Unpolarized light, like sunlight or fluorescent lamp emissions, oscillates in multiple directions, whereas polarized light oscillates exclusively in one direction.
Polarization filters in digital cameras selectively pass rays of specific polarization angles, polarizing non-polarized light upon passage (
Figure 1a). When non-polarized light reflects off a material, it generates partially polarized rays depending on the surface normal and material refractive index. Polarimetric cameras typically employ polarizers at angles of
,
,
, and
, giving at each pixel the corresponding intensities (
Figure 1b). From them, as shown by Equation (1), Stokes parameters,
,
, and
can be derived. Specifically,
denotes total light intensity, akin to a grayscale image.
captures the excess polarized light intensity between horizontal and vertical filters, while
gives the surplus between
and
ones. These parameters define the intensity profile (cf. Equation (2)), and the sum of intensities at two polarizers separated by
equals
(cf. Equation (3)). Moreover, the Angle of Polarization (
) and the Degree of Polarization (
) are derived from the Stokes parameters. They indicate the orientation of polarized light (cf. Equation (4)) and the intensity of polarized light relative to the total intensity (cf. Equation (5)) [
23].
2.3.1. Use of Polarimetric Images
Polarimetric imaging has been extensively used to differentiate between specular and diffuse reflections [
24,
25] or to eliminate these reflections entirely [
26]. This distinction arises due to surface inconsistencies: light reflected from rough surfaces generates unpolarized light (diffuse reflections), whereas smooth surfaces produce more polarized light (specular reflections). This polarization property has been leveraged in various applications, such as enhancing contrast in underwater imaging [
27] and segmenting transparent objects [
28]. Moreover, by analyzing polarization from multiple views, ambiguities in surface normal estimation can be resolved, enabling the generation of depth maps [
29] and aiding in pose estimation [
30].
Additionally, because polarization inherently contains information about surface normals, it has been widely applied in surface defect detection, such as in steel strip inspection [
31] and composite material evaluation [
32]. Molded markers, as irregularities on surfaces, can be interpreted as defects, and polarization techniques can be particularly effective in detecting and localizing them.
2.3.2. Neural Networks Fed by Polarimetric Images
When integrating polarization information into neural networks, it is imperative to pre-process the data appropriately to align with the network architecture. Several representations of polarization data have been proposed (
Table 1), each presenting distinct advantages tailored to specific applications.
The authors of [
23] found that representations using three intensities, Stokes, and Pauli-style, were optimal for road scene analysis. Conversely, Ref. [
28] demonstrated that fusing the HSL-like representation with attention layers yielded the best results in transparent object detection. Similarly, Ref. [
34] achieved superior performance in urban scene understanding tasks by leveraging the HSL-like representation. Additionally, Ref. [
33] utilized polarimetric images with a quarter-wave plate to have a four-component Stokes vector to reconstruct scenes in 3D polarimetric images, surpassing other representations in detection tasks, even in challenging conditions like low light levels and partial occlusion of targets. Overall, while these studies highlight the benefits of integrating polarization information into neural networks through appropriate data representations, the choice of representation appears to be dependent on the specific domain, with no universally preferred option.
In order to address the limited amount of data, numerous studies have investigated data augmentation techniques tailored specifically for polarimetric images, focusing on physically realistic transformations to improve neural network performance. The literature claims that applying a comprehensive transformation of polarimetric values, prior to flipping and rotation transformations, can notably enhance dataset generalization and performance [
28,
34]. For instance, when rotating images by an angle
, adjusting the corresponding
value by subtracting
has shown benefits, as well as multiplying
values by
for flipped images. These methodologies capitalized on polarization properties in those works, yielding superior outcomes compared to traditional transformations.
3. Materials and Methods
3.1. Dataset
The images that comprised the dataset used in the methodology were captured using a FLIR Blackfly S BFS-PGE-123S6P-C camera [
35], featuring a resolution of
superpixels with angles at
, and
. It was complemented by a Computar V2520-MPZ lens with a focal length of 25 mm. A DCM ALB1716A-W00i/AN white, narrow-angle ring light was used during image acquisition.
The dataset comprises 196 annotated images of Carbon Fibre-Reinforced Polymer (CFRP) composite pieces, each containing at least one molded marker, taken at a working distance of 500–600 mm. The fixed size of the molded cross markers is
mm, with a height of 1.5 mm and a cross thickness of 0.5 mm. Various examples of images from the dataset are depicted in
Figure 2. Due to the material properties and the positioning of the lighting, the central markers are better illuminated than those farther from the center.
Overall, the dataset was divided into three subsets: the training set (65%) to fine-tune the Faster R-CNN detection model; the validation set (15%) to select hyperparameters and the final model instance; and the test set (20%) to test and validate the generalization of the trained model. The dataset contains 471 instances of molded markers of a mean size of pixels.
Despite employing an exposure time of 60 ms (lower exposure times resulted in insufficient illumination, while higher exposure times increased noise), high noise was observed in the polarimetric images, as previously noticed in [
36,
37], which could adversely affect mostly the accurate center detection. To mitigate the issue, each image in the dataset was denoised by averaging consecutive images. This method effectively reduced the noise generated by the polarimetric technology of the lens.
3.2. Detection System
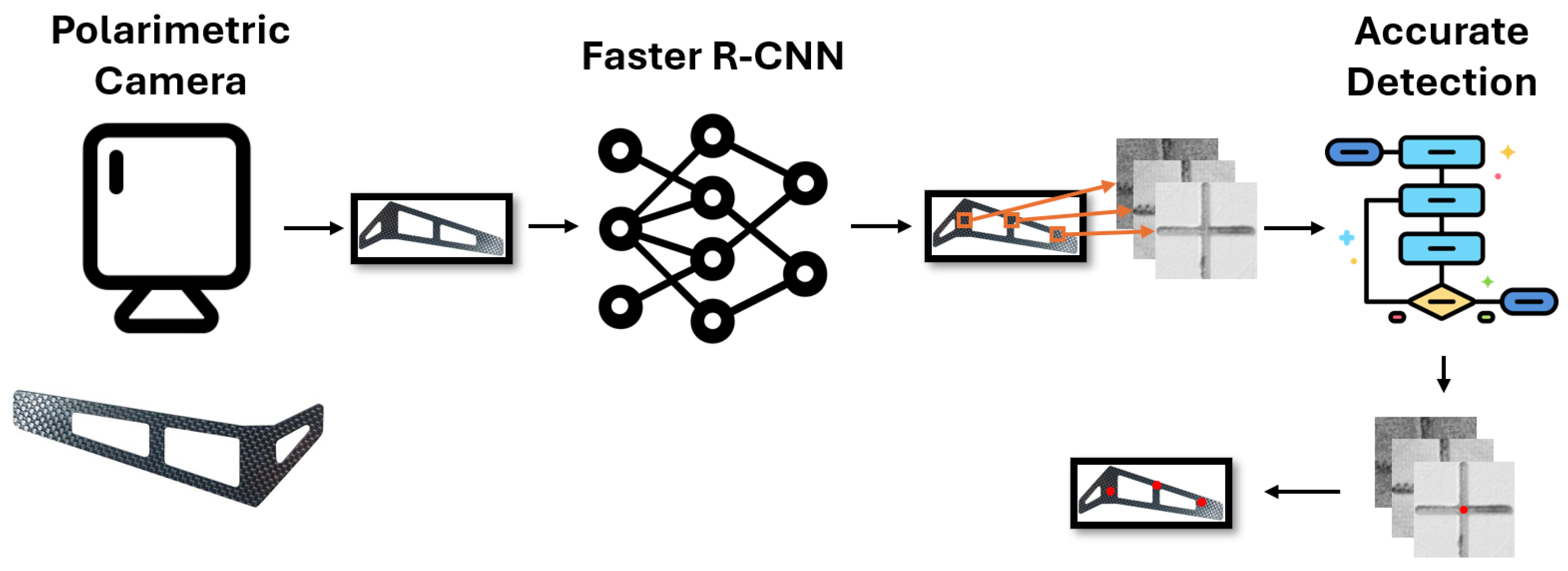
A two-step approach was employed to accurately detect the centers of molded markers, as illustrated in
Figure 3. First, a neural network was trained/fed by a polarimetric representation to detect candidates as seeds for the second step. Faster R-CNN was selected because of its wide adoption, accessibility, and ease of implementation at the time.
Second, accurate detection of the marker center on a polarimetric image was carried out using classical computer vision techniques, specifically customized for cross markers. Initially, the image undergoes binarization using the Sauvola method [
38] after pre-processing. Next, segments are detected through the Hough transform [
39] and their corresponding directions are organized in a histogram. Then, two groups of segments in the image are formed, according to the two most prominent and most separated directions in that histogram. The axes of the cross are finally obtained through least-square fitting, weighting by segment lengths. Finally, the binarized image is compared with the synthetic ideal reconstructed cross from the calculated axes to decide whether the marker is retained or discarded. If the comparison succeeds, the obtained center is the intersection of the axes. Examples of discarded and retained molded marker crop images are illustrated in
Figure 4.
In this system, markers that are excessively blurred or occluded are discarded. The approximate detection network was specifically trained to identify only complete and high-quality markers, with markers that were severely occluded or blurry excluded from annotation during training. Moreover, in the final step of the accurate center detection process, markers that are either occluded or blurred are filtered out based on a comparison between the synthetic ideal binarized image and the real binary image. Occluded markers are missing parts of the marker, while blurry markers result in excessively wide lines in the binary image. Although the material and size of the markers minimize major deformations, the ellipse-fitting detection method employed in the accurate detection phase is robust enough to determine the center of markers even with minor deformations.
3.3. Data Augmentation Polarimetric Techniques
Unlike previous approaches, which primarily focused on manipulating the field, in this work these extra transformations will be tested, locally performed directly on original intensity fields , , and .
3.3.1. Image Flip
Flipping the image, either horizontally or vertically, will physically interchange the values of the channels and seen by the camera. Therefore, before the conventional flip transformation of the image, it is required to permute locally those intensity values per pixel.
3.3.2. Image Rotation
Solely rotations of the images around their optical axis are considered here. If the sensor is physically rotated around the target through an angle
, then the local polarimetric intensity profiles need to be translated by the opposite angle,
, as follows (four- and three-channel versions are shown):
Equation (6) is derived as follows. The rotated intensities are expressed as a function of the Stokes parameters by giving values , , , and in Equation (2). The Stokes parameters are, in turn, related to the unrotated intensities thanks to Equation (1), finally obtaining Equation (6) after some manipulations with matrices. Equation (7) is derived from Equation (6), after applying Equation (3).
Note that the matrix in Equation (6) is singular because one of the intensities is linearly dependent on the rest according to Equation (3). Immediately after this local transformation of pixel values, the conventional rotation transformation would be applied to the image. However, the angle for this rotation actually does not need to be equal to , in the case that eventual relative rotations between the lighting and the camera are considered.
Figure 5 illustrates that utilizing polarization-based transformations yields an image closer to the physically rotated one compared to conventional rotation transformations for
.
4. Experiments
4.1. Implementation and Execution Environment
For the approximate detection, training was conducted using the PyTorch library in Python using a cloud solution with an NVIDIA T4 GPU. The molded marker center detection, on the other hand, was developed using Python in conjunction with the OpenCV library purely on the CPU.
The detection experiments were executed in a system equipped with an Intel Core Ultra 9 185H CPU (22 threads) with 32 GB RAM. The approximate marker detection stage was executed on the CPU, as the primary focus was to achieve accuracy before optimizing for system efficiency.
4.2. Approximate Detection
The Faster R-CNN model with a FPN-ResNet-50 backbone was selected due to its superior small object detection capabilities [
40], which aligns with the dimensions of the molded markers in our images. Moreover, its effectiveness in mitigating vanishing gradients in deep networks is recognized, offering performance comparable to larger backbones with improved inference time [
41]. Training utilized a pre-trained Faster R-CNN model from the COCO dataset [
42] as the basis, with image sizes reduced to
to accommodate GPU memory and training time constraints. The training process employed a batch size of eight with the Adam optimizer [
43] and a learning rate of
, lasting for 100 epochs, as additional epochs did not significantly improve training outcomes.
Different training experiments were conducted to provide insights into how different data augmentation strategies, including conventional and polarization-preserving rotations and flips, impact the training behavior of the model. Initially, training was conducted without any data augmentation to establish a baseline result. Subsequently, conventional rotation (random angle) and flip (50% horizontal and vertical flip) transformations were applied. Following this, the same transformations were applied while preserving the polarization physics, as explained in
Section 3.3. After that, both conventional and polarization-preserving transformations were combined. This involved combining both types of transformations, where the angle of polarization rotation could differ from the angle used to rotate the image, and polarization could be flipped horizontally and vertically while keeping the image unchanged, and vice versa.
In addition to the data augmentation techniques, considering the previous literature’s indication that different representations of polarimetric images are optimal for different applications, this study compared various representations aligned with the requirement of the pre-trained model, typically trained on RGB images (three channels). The explored representations included three intensities (, , and ), Stokes (, , ), and the HSL-like representation (, , and ). Subsequently, training was conducted using only the channel to emulate a conventional grayscale image, enabling a comparison of detection outcomes without leveraging polarimetry. Additionally, a final training iteration was performed using only , as it was presumed to be the representation where the cross markers were most distinguishable from the background.
To assess the performance of the trained detection model, the mean Average Precision at 50% Intersection over Union (IoU) metric (
) was employed [
44]. This metric is widely used in object detection tasks to evaluate the accuracy of predicted bounding boxes by comparing them to the ground truth based on the degree of overlap (IoU). It combines precision and recall to assess detection performance. In this study, an IoU threshold of 50% was selected, meaning that a predicted bounding box is considered correct if its overlap with the ground truth is at least 50%. This choice aligns with the objective of the approximate detection phase, which focuses on identifying markers and obtaining approximate localization information. Given the small size of some markers, with higher IoU values, minor differences of just a few pixels could cause detections to be classified as incorrect, despite being sufficient to seed the next accurate step.
4.3. Accurate Center Detection
The detection rate was calculated for each polarimetric image type to evaluate the ease of marker distinguishability. This experiment was conducted using denoised mean images, as well as with the original noise ones, to assess how noise affected the accurate center detection rate.
4.4. Three-Dimensional Accurate Photogrammetric Reconstruction of Markers
The final experiment aimed to validate the system’s performance in a real-world setting and assess its detection accuracy. For this purpose, an aeronautic component (approximately 3600 × 1300 mm) was used, and the distances between the molded markers on it were measured within an industrial environment.
To accurately locate each molded marker in 3D space, a polarimetric camera was securely mounted on a platform attached to the gripper of a KUKA IIWA robotic arm. The robotic arm, positioned on a linear track, was able to move the camera close to each molded marker on the CFRP piece. The arm captured five photographs of each marker from different perspectives, with each image taken at a minimum distance of 500 mm from the marker. Capturing images from multiple angles enabled the system to triangulate the 2D centers of each marker, allowing for accurate 3D photogrammetric reconstruction of their center positions.
To determine the 3D positions of the molded markers within the world reference frame, the pose of the robotic arm’s gripper was tracked by a commercially available accurate four-camera photogrammetric system [
45] (see
Figure 6), which has a stated accuracy of 0.045 mm. Optical coded markers were attached to the gripper to enable precise tracking by this multi-camera system. An eye–hand calibration was then conducted to establish the spatial relationship between the camera and the robotic arm’s gripper.
The process for obtaining the 3D position of each molded marker involved three main steps: first, capturing five images of each marker to calculate its 3D position within the camera’s reference frame; next, applying eye–hand transformation to convert these positions to the gripper’s reference frame; and finally, using the four-camera photogrammetric system to track the gripper’s global position, which ultimately allowed for mapping the final 3D positions of the molded markers to the world reference frame.
Seventeen markers spread across the CFRP piece were measured (see
Figure 7), and the distances between each pair of markers were compared with those obtained from a Leica AT960 laser tracker, which provided the 3D ground truth measurements for the experiment. Only distances exceeding one meter were considered to ensure the results are representative of practical large-scale usage scenarios. The median, interquartile range (IQR), and uncertainty with
were calculated to assess the system’s accuracy based on the 22 measured distances. The measurements were conducted four times to ensure the absence of any significant precision issues.
5. Results
5.1. Approximate Detection
The diverse outcomes obtained from employing various input representations and applying different data augmentation techniques are summarized in
Table 2. Overall, the model achieves a
exceeding 0.9 in most cases, demonstrating that it is sufficient for obtaining nearly perfect results in approximate detection. This level of performance suggests that exploring newer models or alternative techniques to further enhance accuracy is unnecessary. The inference time for the approximate detection stage was approximately 1 s per image when executed on the CPU.
Interestingly, the application of any data augmentation technique appeared to enhance training, likely due to the relatively small size of the dataset used in this study. However, there were no significant differences observed among the results obtained from employing either conventional transformations, polarization-preserving ones, or combining both. Given the small size of the test set, differences around 4% may not be deemed significant, as they could be influenced by non-deterministic training outcomes. This suggests that achieving excellent outcomes with conventional transformations may render additional techniques redundant in this particular scenario.
Finally, the results indicated that input representation is not a critical factor in this dataset, as all approaches yielded similar outcomes. Particularly noteworthy is the effectiveness of using only (closest to a standard grayscale camera image) and applying conventional transformations, which implies that polarization physics may not substantially contribute to the approximate detection task.
5.2. Accurate Center Detection
The accurate center detection rates obtained using each polarimetric image are detailed in
Table 3. Firstly, denoising by averaging ten consecutive images improves the center detection rate in any polarimetric image, showing an improvement of around 10% in the best case. Secondly, the polarization-based
image exhibited a 79% improvement in the detection rate compared to the common grayscale image, represented by
, significantly outperforming all other polarization-based images. The execution time for the accurate detection stage was approximately 40 ms per marker.
Figure 8a,b compare the accurate detection of crosses’ centers using
and
.
All the markers were successfully detected by the approximate stage. However, while
performs satisfactorily under direct or nearby light conditions, it struggles with markers situated farther from the light source, resulting in inferior illumination. This limitation was effectively overcome by employing the
image, which captures more nuanced information owing to its broader value range and clearer differentiation between the marker and background. Additionally, the histograms of
and
values for the top-left crop in
Figure 8c,d further underscore the advantages of utilizing the
image under conditions of less-than-ideal illumination. Their analyses reveals a stark contrast in pixel value distribution. The
histogram shows a limited range of values, while the
one demonstrates a wider spread, suggesting richer information for marker center detection.
5.3. Three-Dimensional Accurate Photogrammetric Reconstruction of Markers
The experimental results revealed a median accuracy of 0.17 mm/m (IQR: 0.069 to 0.368 mm/m) or 0.463 mm/m of uncertainty at
. The histogram of errors is depicted in
Figure 9. This system demonstrates an accuracy one order of magnitude worse than other optical marker-based systems [
46]. Despite this, at this initial research stage, the presented concept exhibits enhancements in usability and automation, and it would already be suitable for various industrial applications such as alignment, material handling, assembly of large components, or even coating.
6. Discussion
This study introduces the innovative use of molded markers for photogrammetry measurements, and it also explores the use of polarization-based images throughout the center detection process.
Results indicate that, while polarization representations and data augmentation did not significantly enhance detection performance in the initial phase compared to grayscale images with standard transformations, they played a crucial role in subsequent accurate center localization. Particularly, the polarization-based image significantly boosted detection rates by 79%, offering higher quality data, especially in suboptimal lighting conditions. Polarimetric image noise reduction also resulted in an improvement in the center detection rate.
The experiment conducted in a real photogrammetric scenario confirmed the viability of molded markers for accurate photogrammetric measurement systems. The accuracy obtained is suitable for various industrial applications, including alignment, drilling, machining guidance, and the tracking of composite pieces.
This methodology has certain limitations, as the material molding process must be compatible with embedding the molded markers. Additionally, this approach is unsuitable for pieces where the final finish must remain unaltered, as the molded markers would modify the original surface. In such cases, a post-processing step would be required to remove the molded markers, which may be time consuming. Furthermore, while molded markers can tolerate some deformation, they are not suitable for areas with extreme deformations or highly curved surfaces, as this could hinder their detection.
Future research will focus on refining the accuracy of the cross center detection algorithm to enhance 3D measurement accuracy, potentially through the integration of classical filters or machine learning techniques. Additionally, future research should explore the potential of leveraging polarization physics, such as utilizing polarization angles to detect the peaks of relief on the markers. This approach could enable a more refined delineation of marker edges, ultimately improving detection accuracy. Furthermore, the detection system will be expanded to incorporate the capability to identify and differentiate between various shapes, thereby increasing its flexibility. To achieve this, additional physical samples will be produced, and the training dataset will be appropriately augmented. Expanding the system’s capacity to operate over larger volumes is also a key goal to broaden its applicability.
The industrialization of the system will necessitate optimizing both stages of the detection process, including the adoption of newer and more efficient models for the approximate detection stage. Furthermore, leveraging the detected centers as ground truth annotations for keypoints and exploring direct center detection through alternative neural network architectures, such as keypoint detectors, could further streamline the process and enhance efficiency. The total detection execution time after optimizing should be around 100 ms, which aligns with commonly used optical detection algorithms [
47]. This target speed is crucial for adopting molded markers in industrial settings without affecting performance.
In applications involving uncontrolled environments with extreme lighting conditions or high noise levels, further investigation into advanced filtering techniques will be essential to improve detection robustness.
Author Contributions
Conceptualization, I.A.I. and I.H.; data curation, I.A.I.; formal analysis, O.S.d.E.; funding acquisition, I.H.; investigation, I.A.I.; methodology, I.A.I.; project administration, I.H.; resources, O.S.d.E.; software, I.A.I., O.S.d.E. and P.G.d.A.M.; supervision, I.H.; validation, O.S.d.E.; visualization, I.A.I.; writing—original draft, I.A.I.; writing—review and editing, P.G.d.A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research, including the APC, was funded by the Spanish CDTI Programas Duales grant number IDI-20211064.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset presented in this article is not available due to privacy and commercial restrictions.
Acknowledgments
We are thankful to our colleagues Pablo Puerto and Roberto Alonso, who provided expertise and helped in the validation process, and Ibai Leizea, whose expertise greatly assisted the research.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kraus, K. Photogrammetrie: Grundlagen und Standardverfahren/mit Beitr. von Peter Waldhäusl, 5th ed.; Dümmler: Bonn, Germany, 1994. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar] [CrossRef]
- Bösemann, W. Industrial photogrammetry: Challenges and opportunities. In Videometrics, Range Imaging, and Applications XI; Remondino, F., Shortis, M.R., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2011; Volume 8085, p. 80850H. [Google Scholar] [CrossRef]
- Lingua, A.M.; Marenchino, D.; Nex, F. Performance Analysis of the SIFT Operator for Automatic Feature Extraction and Matching in Photogrammetric Applications. Sensors 2009, 9, 3745–3766. [Google Scholar] [CrossRef]
- Ruiz de Oña, E.; Barbero-García, I.; González-Aguilera, D.; Remondino, F.; Rodríguez-Gonzálvez, P.; Hernández-López, D. PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching. Appl. Sci. 2023, 13, 5467. [Google Scholar] [CrossRef]
- Ye, N.; Zhu, H.; Wei, M.; Zhang, L. Accurate and dense point cloud generation for industrial Measurement via target-free photogrammetry. Opt. Lasers Eng. 2021, 140, 106521. [Google Scholar] [CrossRef]
- Harvent, J.; Coudrin, B.; Brèthes, L.; Orteu, J.J.; Devy, M. Multi-view dense 3D modelling of untextured objects from a moving projector-cameras system. Mach. Vis. Appl. 2013, 24, 1645–1659. [Google Scholar] [CrossRef]
- Javed, A.; Park, J.; Lee, H.; Han, Y. Vibration signal separation of rotating cylindrical structure through target-less photogrammetric approach. J. Sound Vib. 2023, 547, 117540. [Google Scholar] [CrossRef]
- Wang, W.; Chen, A. Target-less approach of vibration measurement with virtual points constructed with cross ratios. Measurement 2020, 151, 107238. [Google Scholar] [CrossRef]
- Shi, D.; Šabanovič, E.; Rizzetto, L.; Skrickij, V.; Oliverio, R.; Kaviani, N.; Ye, Y.; Bureika, G.; Ricci, S.; Hecht, M. Deep learning based virtual point tracking for real-time target-less dynamic displacement measurement in railway applications. Mech. Syst. Signal Process. 2022, 166, 108482. [Google Scholar] [CrossRef]
- Cuypers, W.; Van Gestel, N.; Voet, A.; Kruth, J.P.; Mingneau, J.; Bleys, P. Optical measurement techniques for mobile and large-scale dimensional metrology. Opt. Lasers Eng. 2009, 47, 292–300. [Google Scholar] [CrossRef]
- Cucci, D.A. Accurate Optical Target Pose Determination for Applications in Aerial Photogrammetry. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 257–262. [Google Scholar] [CrossRef]
- Digiacomo, F.; Bologna, F.; Inglese, F.; Stefanini, C.; Milazzo, M. MechaTag: A Mechanical Fiducial Marker and the Detection Algorithm. J. Intell. Robot. Syst. 2021, 103, 46. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), ICCV ’15, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Goldstein, D. Polarized Light; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Blin, R.; Ainouz, S.; Canu, S.; Meriaudeau, F. A new multimodal RGB and polarimetric image dataset for road scenes analysis. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 867–876. [Google Scholar] [CrossRef]
- Wen, S.; Zheng, Y.; Lu, F. Polarization Guided Specular Reflection Separation. IEEE Trans. Image Process. 2021, 30, 7280–7291. [Google Scholar] [CrossRef]
- Kajiyama, S.; Piao, T.; Kawahara, R.; Okabe, T. Separating Partially-Polarized Diffuse and Specular Reflection Components under Unpolarized Light Sources. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 2548–2557. [Google Scholar] [CrossRef]
- Lei, C.; Huang, X.; Zhang, M.; Yan, Q.; Sun, W.; Chen, Q. Polarized Reflection Removal with Perfect Alignment in the Wild. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1747–1755. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, Y.; Li, X.; Lin, Y.; Cheng, Z.; Liu, T. Polarimetric underwater image recovery via deep learning. Opt. Lasers Eng. 2020, 133, 106152. [Google Scholar] [CrossRef]
- Kalra, A.; Taamazyan, V.; Rao, S.K.; Venkataraman, K.; Raskar, R.; Kadambi, A. Deep Polarization Cues for Transparent Object Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8599–8608. [Google Scholar] [CrossRef]
- Fukao, Y.; Kawahara, R.; Nobuhara, S.; Nishino, K. Polarimetric Normal Stereo. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 682–690. [Google Scholar] [CrossRef]
- Cui, Z.; Larsson, V.; Pollefeys, M. Polarimetric Relative Pose Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2671–2680. [Google Scholar] [CrossRef]
- Kazama, A.; Oshige, T. A defect inspection technique using polarized images for steel strip surface. In Optics and Photonics for Information Processing II; Awwal, A.A.S., Iftekharuddin, K.M., Javidi, B., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2008; Volume 7072, p. 70720L. [Google Scholar] [CrossRef]
- Ding, Y.; Ye, J.; Barbalata, C.; Oubre, J.; Lemoine, C.; Agostinho, J.; Palardy, G. Next-generation perception system for automated defects detection in composite laminates via polarized computational imaging. arXiv 2021, arXiv:2108.10819. [Google Scholar]
- Usmani, K.; Krishnan, G.; O’Connor, T.; Javidi, B. Deep learning polarimetric three-dimensional integral imaging object recognition in adverse environmental conditions. Opt. Express 2021, 29, 12215–12228. [Google Scholar] [CrossRef] [PubMed]
- Blanchon, M.; Sidibé, D.; Morel, O.; Seulin, R.; Meriaudeau, F. Towards urban scenes understanding through polarization cues. arXiv 2021, arXiv:2106.01717. [Google Scholar] [CrossRef]
- Solutions, S.S. The Principle of Reflection Removal Utilizing Polarization and Features of Polarization Image Sensor, Sony White Paper, 2021. Available online: https://info.sony-semicon.com/en/whitepaper-form0002 (accessed on 15 January 2023).
- Li, X.; Li, H.; Lin, Y.; Guo, J.; Yang, J.; Yue, H.; Li, K.; Li, C.; Cheng, Z.; Hu, H.; et al. Learning-based denoising for polarimetric images. Opt. Express 2020, 28, 16309–16321. [Google Scholar] [CrossRef]
- Powell, S.B.; Gruev, V. Calibration methods for division-of-focal-plane polarimeters. Opt. Express 2013, 21, 21039–21055. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Puerto, P.; Leizea, I.; Herrera, I.; Barrios, A. Analyses of Key Variables to Industrialize a Multi-Camera System to Guide Robotic Arms. Robotics 2023, 12, 10. [Google Scholar] [CrossRef]
- Martin, O.C.; Robson, S.; Kayani, A.; Muelaner, J.E.; Dhokia, V.; Maropoulos, P.G. Comparative Performance between Two Photogrammetric Systems and a Reference Laser Tracker Network for Large-Volume Industrial Measurement. Photogramm. Rec. 2016, 31, 348–360. [Google Scholar] [CrossRef]
- Mendikute, A.; Leizea, I.; Herrera, I.; Yagüe-Fabra, J. In-process portable photogrammetry using optical targets for large scale industrial metrology. In Proceedings of the 19th International Conference & Exhibition, Bilbao, Spain, 3–7 June 2019; pp. 340–343. [Google Scholar]
Figure 1.
Usage of polarization filters in cameras. (a) Effect of a polarization filter on unpolarized light. (b) Distribution of superpixel polarization filters in cameras (each camera pixel contains four different polarization intensity values). The angle indicates the polarization angle associated with each filter.
Figure 1.
Usage of polarization filters in cameras. (a) Effect of a polarization filter on unpolarized light. (b) Distribution of superpixel polarization filters in cameras (each camera pixel contains four different polarization intensity values). The angle indicates the polarization angle associated with each filter.
Figure 2.
Examples of images from the dataset utilized in this study.
Figure 2.
Examples of images from the dataset utilized in this study.
Figure 3.
Proposed molded marker center detection pipeline. Firstly, an image is captured using a polarimetric camera. Afterwards, molded markers are detected within the image using the Faster R-CNN model, followed by the determination of their centers using an accurate cross center detection algorithm.
Figure 3.
Proposed molded marker center detection pipeline. Firstly, an image is captured using a polarimetric camera. Afterwards, molded markers are detected within the image using the Faster R-CNN model, followed by the determination of their centers using an accurate cross center detection algorithm.
Figure 4.
Examples of molded marker crops retained and discarded by the accurate center detection algorithm. (a) Retained crops. (b) Discarded crops.
Figure 4.
Examples of molded marker crops retained and discarded by the accurate center detection algorithm. (a) Retained crops. (b) Discarded crops.
Figure 5.
Original image , results from applying conventional and polarization-based rotation to the original image and the obtained by physically rotating the camera.
Figure 5.
Original image , results from applying conventional and polarization-based rotation to the original image and the obtained by physically rotating the camera.
Figure 6.
Illustration of the actual photogrammetric scenario used. A four-camera multi-camera system tracks the object on the robotic arm containing optical coded markers, which holds the polarimetric camera.
Figure 6.
Illustration of the actual photogrammetric scenario used. A four-camera multi-camera system tracks the object on the robotic arm containing optical coded markers, which holds the polarimetric camera.
Figure 7.
Illustration of the measurement process on the component. (a) Robotic arm measuring molded markers on the component. (b) Examples of measured distances.
Figure 7.
Illustration of the measurement process on the component. (a) Robotic arm measuring molded markers on the component. (b) Examples of measured distances.
Figure 8.
Molded markers with accurately detected centers highlighted in white within the corresponding images (every molded marker was successfully detected by the Faster R-CNN model). (a) image and crop. (b) image and crop. Additionally, the top-left crop of a molded marker under imperfect illumination is shown, along with its corresponding histogram. (c) marker crop histogram. (d) marker crop histogram.
Figure 8.
Molded markers with accurately detected centers highlighted in white within the corresponding images (every molded marker was successfully detected by the Faster R-CNN model). (a) image and crop. (b) image and crop. Additionally, the top-left crop of a molded marker under imperfect illumination is shown, along with its corresponding histogram. (c) marker crop histogram. (d) marker crop histogram.
Figure 9.
Histogram of absolute distance errors obtained between the photogrammetric system with molded markers and the laser tracker.
Figure 9.
Histogram of absolute distance errors obtained between the photogrammetric system with molded markers and the laser tracker.
Table 1.
Different detection model input representations of polarimetric images.
Table 1.
Different detection model input representations of polarimetric images.
| Data Format | Channel 1 | Channel 2 | Channel 3 | Channel 4 | Used in Article |
|---|
| Int. (3 ch) | | | | - | [23] |
| Int. (4 ch) | | | | | [28] |
| Stokes | | | | - | [23,33] |
| Pauli | | | | - | [23] |
| HSL-like | | | | - | [23,28,34] |
| Poincaré | | | | - | [23] |
Table 2.
Test set detection results after training with different input representations and different data augmentation techniques. Bold values indicate the best-performing data augmentation method for each input representation.
Table 2.
Test set detection results after training with different input representations and different data augmentation techniques. Bold values indicate the best-performing data augmentation method for each input representation.
| | , , | , , | , , | | |
|---|
| No data augmentation | 0.843 | 0.79 | 0.875 | 0.862 | 0.828 |
| Conventional transformations | 0.96 | 0.925 | 0.946 | 0.926 | 0.915 |
| Polarization based transformations | 0.922 | 0.925 | 0.954 | 0.938 | 0.924 |
| Conv. + Polariz. based transforms. | 0.94 | 0.936 | 0.939 | 0.935 | 0.913 |
Table 3.
Accurate center detection rate of different polarimetric images using the average of 10 images and using just 1 original image. Bold values highlight the best-performing polarimetric image and the highest detection rate achieved.
Table 3.
Accurate center detection rate of different polarimetric images using the average of 10 images and using just 1 original image. Bold values highlight the best-performing polarimetric image and the highest detection rate achieved.
| Image Used | Acc. Center Det. Rate |
|---|
|
Avg. of 10
|
Single Img.
|
|---|
| 0.1 | 0.06 |
| 0.59 | 0.56 |
| 0.36 | 0.33 |
| 0.59 | 0.57 |
| 0.48 | 0.47 |
| 0.15 | 0.13 |
| 0.01 | 0.006 |
| 0.09 | 0.03 |
| 0.86 | 0.79 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}