



Attention-Based Malware Detection Model by Visualizing Latent Features Through Dynamic Residual Kernel Network


Abstract
1. Introduction
- This study proposes a novel malware detection approach by transforming binary files into image representations. Unlike traditional platform-dependent methods, this representation is platform-independent and significantly reduces the preprocessing time, enabling efficient and scalable classification.
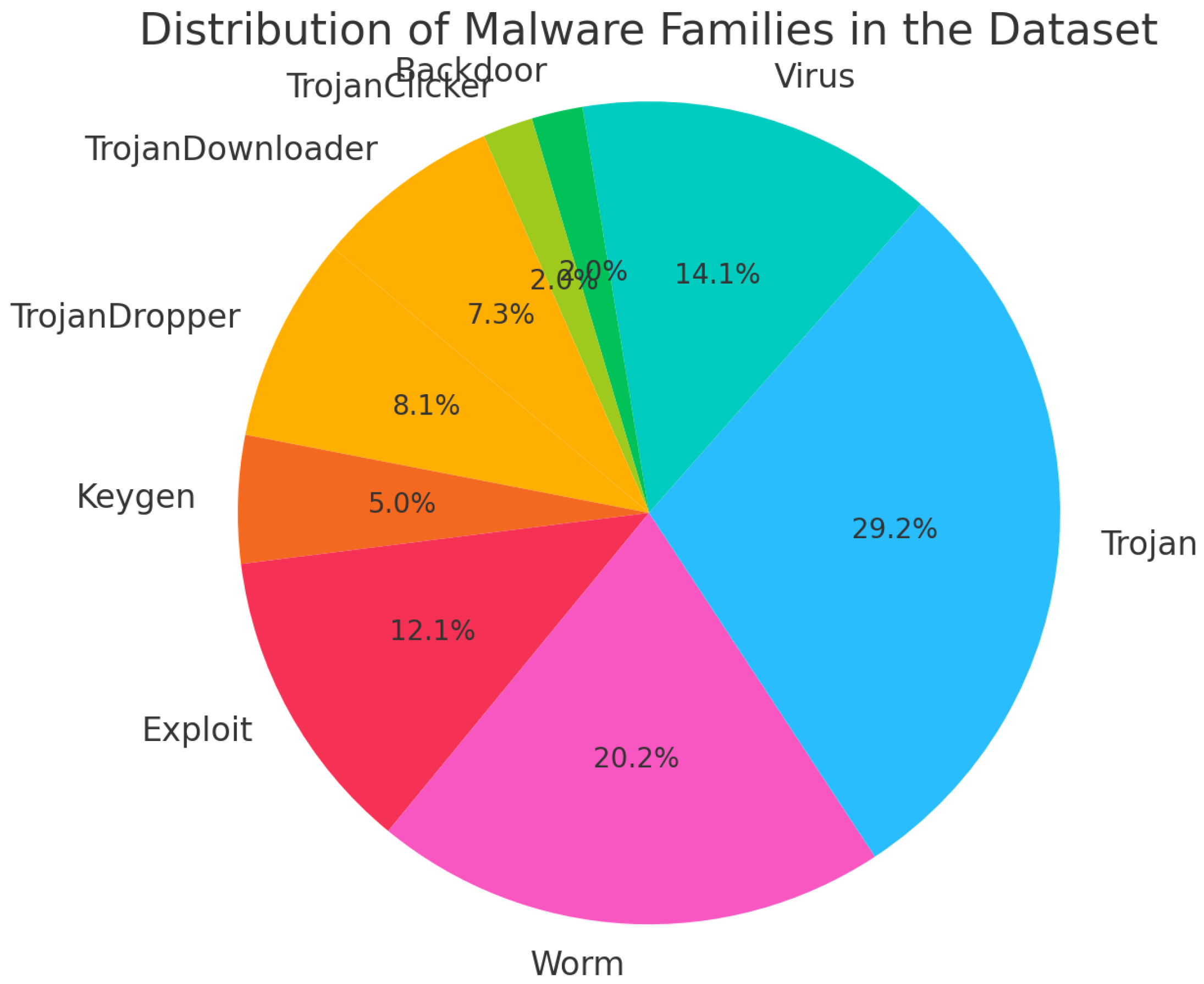
- A large dataset (Figure 1) of over 40,000 malware samples was constructed by aggregating data from repositories such as Malshare [13], VirusShare [14], and VirusTotal [15]. Rigorous labeling was performed using Microsoft’s antivirus engine, ensuring accurate and consistent classification across multiple malware families.
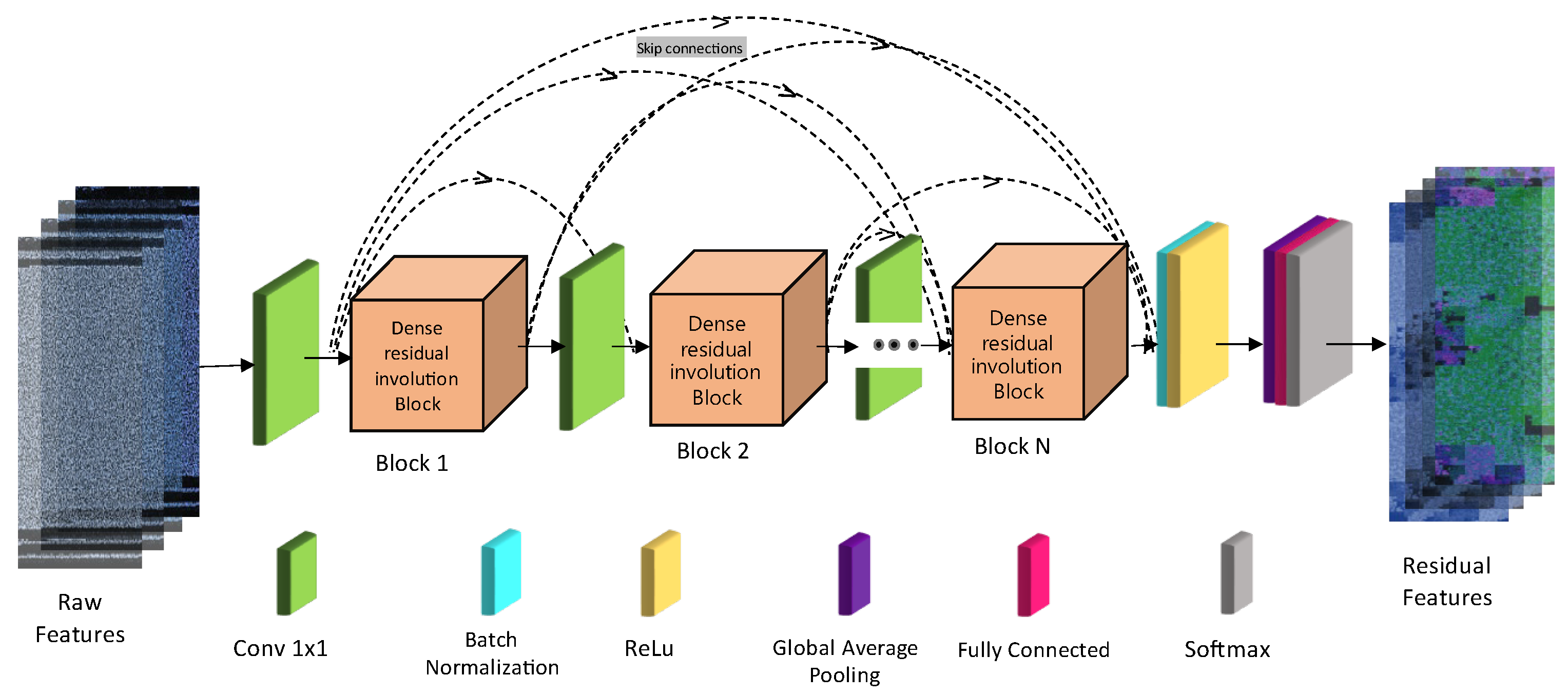
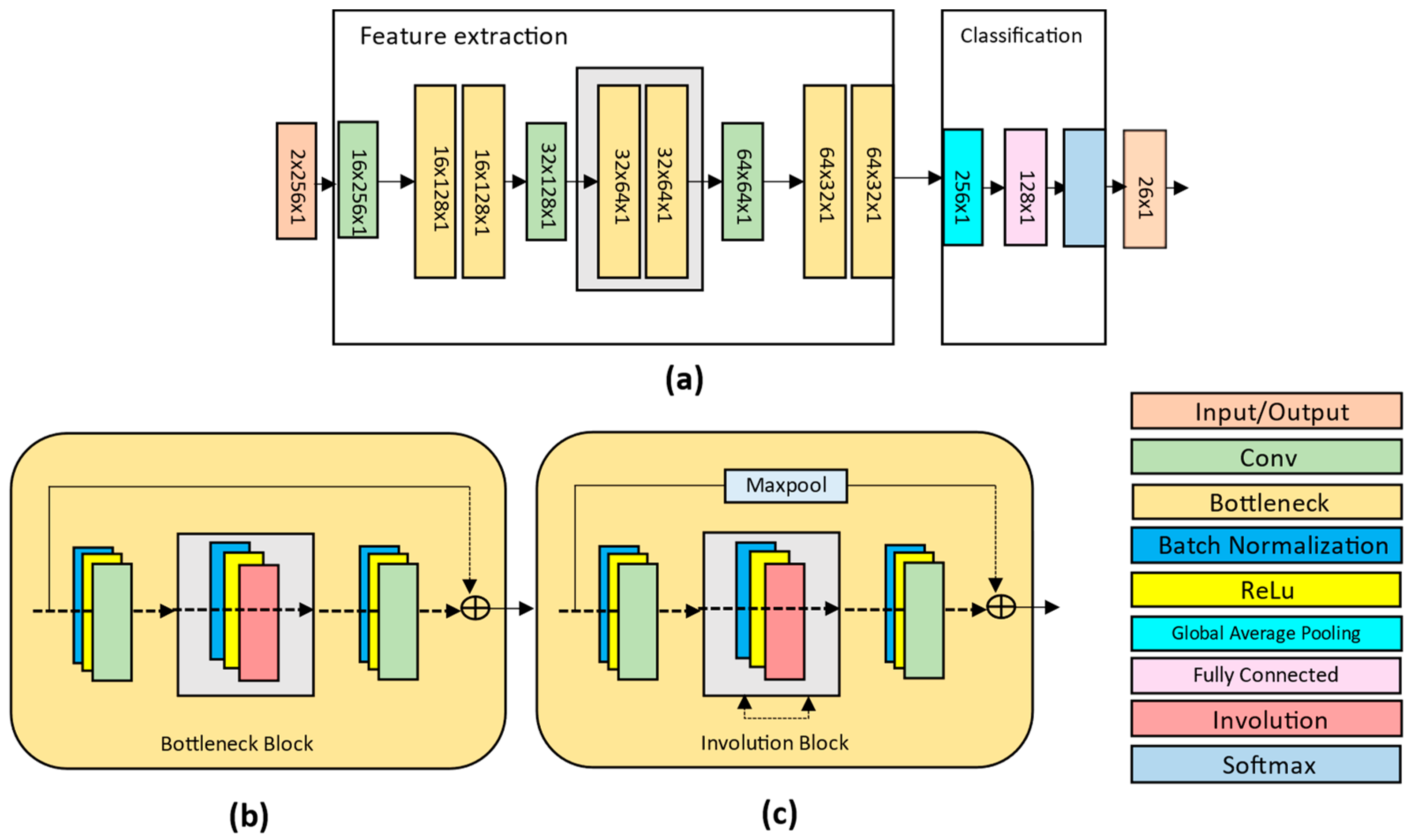
- A Dynamic Residual Involution Network (DRIN) is introduced as the core architecture, utilizing involution layers to capture long-range spatial dependencies and residual connections to enhance learning stability. This innovative design overcomes the limitations of traditional convolutional layers in feature extraction.
- The proposed method achieves state-of-the-art performance, with a classification accuracy of 99.50%. It also reduces computational complexity by 40%, making it suitable for real-time malware detection in resource-constrained environments.
- By retaining pixel-level information and avoiding spatial downsampling, the model is optimized for practical deployment, ensuring robust and scalable malware detection. This work sets the stage for further advancements in image-based malware analysis.
2. Related Study
3. Materials and Methods
3.1. Dataseet
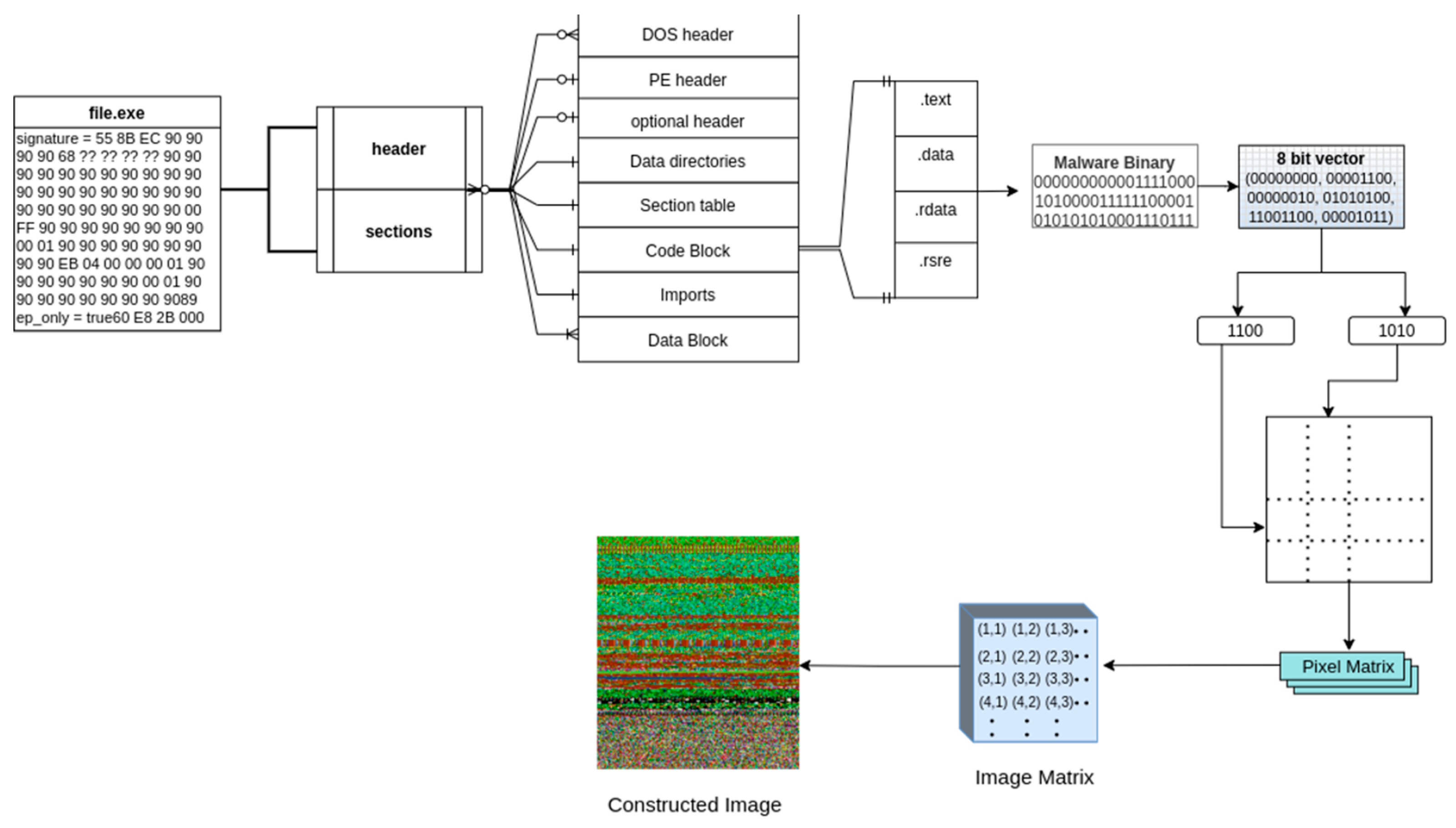
3.2. Malware Binary File to Image Conversion
| Algorithm 1 Conversion of malware binary File to 2D Image vector |
| 1: Input: PE file 2: Output: 2D Image Matrix 3: procedure PEtoImage(PEfile) 4: binaryStream ← ConvertToBinaryStream(PEfile) 5: imageWidth ← DetermineWidth(binaryStream) 6: pixelV alues ← empty list 7: for each byte in binaryStream do 8: integerV alue ← BinaryToInteger(byte) 9: Append(pixelV alues, integerV alue) 10: end for 11: imageMatrix ← ConvertTo2DMatrix(pixelV alues, imageWidth) 12: coloredImage ← ApplyColorMap(imageMatrix) 13: return coloredImage 14: end procedure 15: function ConvertToBinaryStream(PEfile) 16: Read the PE file as a binary stream 17: return binaryStream 18: end function 19: function DetermineWidth(binaryStream) 20: Determine a fixed width based on the file size 21: return width 22: end function 23: function BinaryToInteger(byte) 24: Convert 8-bit binary substring to an unsigned integer 25: return integerV alue 26: end function 27: function ConvertTo2DMatrix(pixelValues, width) 28: height ←⌈len(pixelValues)/width⌉ 29: Reshape the list of pixel values into a 2D matrix of dimensions height x width 30: return matrix 31: end function 32: function ApplyColorMap(imageMatrix) 33: Apply an RGB color map to the 2D image matrix 34: return coloredImage 35: end function |
3.3. Overview of the Proposed Framework
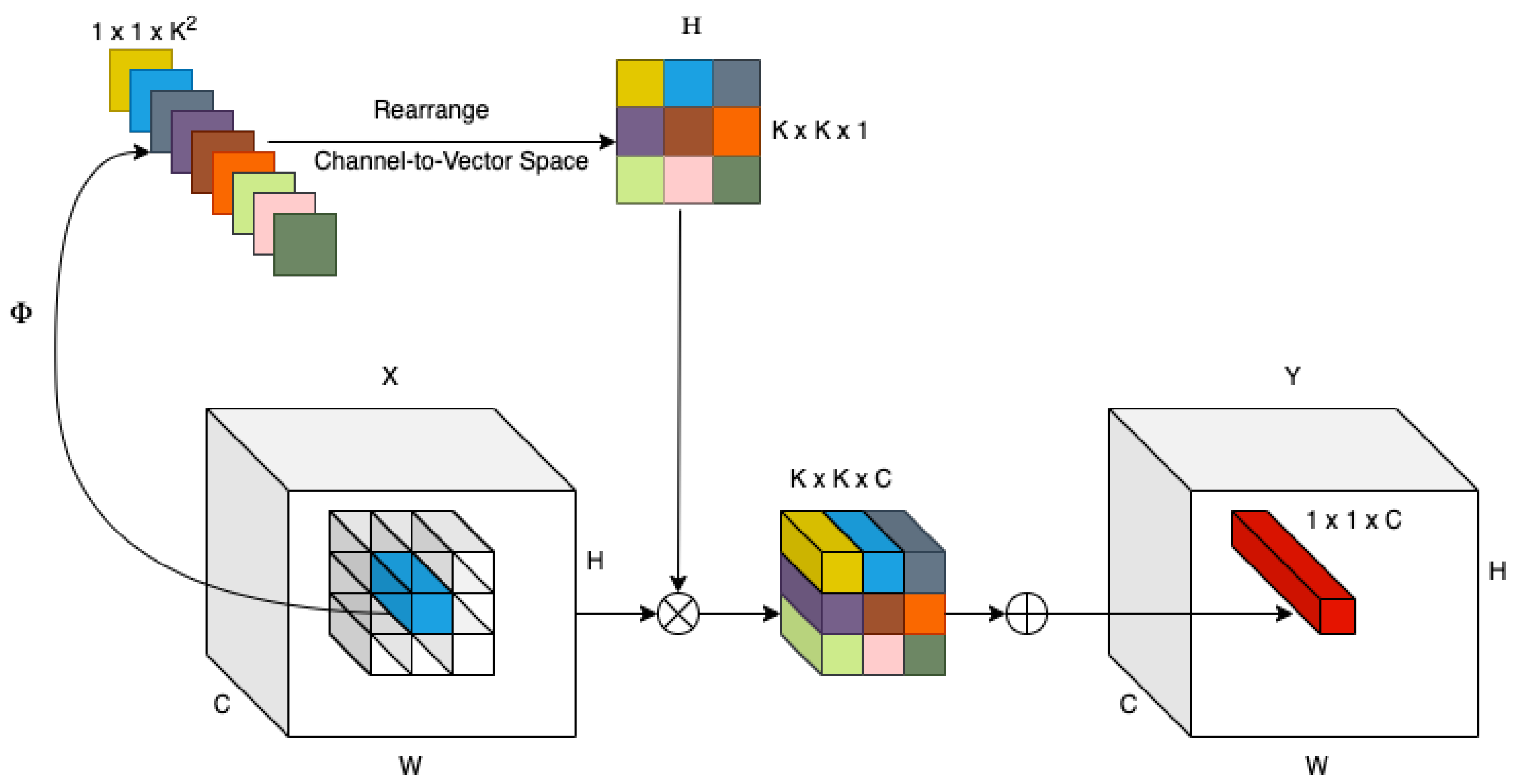
3.4. Proposed Network Operation
3.4.1. Feature Extraction Module
3.4.2. Classification Module
4. Experimental Results
- -
- CPU: Intel i7-7700K.
- -
- Memory: 16 GB RAM.
- -
- GPU: NVIDIA GTX 1080 Ti (Santa Clara, CA, USA).
4.1. Experimental Results for CNN
4.2. Experimental Results for Proposed Residual Involution (RI) Network
4.3. Ablation Study
5. Limitations
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, J.A.; Xu, P.C.; Mukkamala, S. Static Analyzer of Vicious Executables (SAVE). In Proceedings of the 20th Annual Computer Security Applications, Tucson, AZ, USA, 6–10 December 2004. [Google Scholar]
- Alazab, M.; Venkataraman, S.; Watters, P. Towards Understanding Malware Behaviour by the Extraction of API calls. In Proceedings of the 2nd CTC 2010 Ballarat (VIC), Ballarat, Australia, 19–20 July 2010. [Google Scholar]
- Anderson, B.; Quist, D.; Neil, J.; Storlie, C.; Lane, T. Graph Based Malware Detection Using Dynamic Analysis. J. Comput. Virol. 2011, 7, 247–258. [Google Scholar] [CrossRef]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- AV-Test. Malware Statistics. 2017. Available online: http://www.av-test.org/en/statistics/malware/ (accessed on 2 December 2023).
- Bayer, U.; Comparetti, P.; Hlauschek, C.; Kruegel, C. Scalable, Behavior Based Malware Clustering. In Proceedings of the 16th Annual Network and Distributed System Security Symposium, San Diego, CA, USA, 8–11 February 2009. [Google Scholar]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 28–30 May 2013. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Kang, B.; Yerima, S.Y.; McLaughlin, K.; Sezer, S. N-opcode Analysis for Android Malware Classification and Categorization. In Proceedings of the 2016 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), London, UK, 13–14 June 2016. [Google Scholar]
- Christodorescu, M.; Jha, S.; Kruegel, C. Mining specifications of malicious behavior. In Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESECFSE), Dubrovnik, Croatia, 3–7 September 2007. [Google Scholar]
- Clarify. Convolutional Neural Networks. 2014. Available online: https://www.clarifai.com/technology (accessed on 2 December 2023).
- Cohen, F. Computer Viruses: Theory and Experiments. 1987. Available online: http://web.eecs.umich.edu/~aprakash/eecs588/handouts/cohen-viruses.html (accessed on 2 December 2023).
- MalShare. MalShare Project: Malware Repository. Available online: http://malshare.com/ (accessed on 2 December 2023).
- VirusShare. VirusShare Malware Repository. Available online: https://virusshare.com/ (accessed on 2 December 2023).
- VirusTotal. VirusTotal-Free Online Virus, Malware, and URL Scanner. Available online: https://www.virustotal.com/ (accessed on 2 December 2023).
- Maron, M.E. Automatic Indexing: An Experimental Inquiry. J. ACM 1961, 8, 404–417. [Google Scholar] [CrossRef]
- Helfman, J. Dotplot patterns: A literal look at pattern languages. Theory Pract. Object Syst. 1995, 2, 31–41. [Google Scholar] [CrossRef]
- Honkela, A. Nonlinear Switching State-Space Models. 2001. Available online: https://www.cs.helsinki.fi/u/ahonkela/dippa/ (accessed on 2 December 2023).
- Hubel, D.; Wiesel, T. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef] [PubMed]
- ICT Conference of Statistics. ICT: Facts and Figures. 2016. Available online: http://www.itu.int/en/ITU-D/Statistics/Documents/facts/ICTFactsFigures2016.pdf (accessed on 2 December 2023).
- Farfoura, M.E.; Mashal, I.; Alkhatib, A.; Batyha, R.M. A lightweight machine learning methods for malware classification. Clust. Comput. 2025, 28, 1. [Google Scholar] [CrossRef]
- Indyk, P.; Motwani, R. Approximate Nearest Neighbor: Towards Removing the Curse of Dimensionality. In Proceedings of the 30th Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998. [Google Scholar]
- Islam, R.; Tian, R.; Batten, L.M.; Versteeg, S. Classification of malware based on integrated static and dynamic features. J. Netw. Comput. Appl. 2013, 36, 646–656. [Google Scholar] [CrossRef]
- Kaspersky. Cybercrime, Inc.: How Profitable Is the Business? 2014. Available online: https://blog.kaspersky.com/cybercrime-inc-how-profitable-is-the-business/15034 (accessed on 2 December 2023).
- Ki, Y.; Kim, E.; Kim, H.K. A Novel Approach to Detect Malware Based on API Call Sequence Analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Kolbitsch, C. Anubis: Efficient and Comprehensive Mobile App Classification Through Static and Dynamic Analysis. 2011. University of California, Santa Barbara. Available online: https://seclab.cs.ucsb.edu/files/publications/Lindorfer2015Marvin_Efficient.pdf (accessed on 12 January 2024).
- Kolter, J.; Maloof, M. Learning to detect malicious executables in the wild. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Kong, D.; Yan, G. Discriminant malware distance learning on structural information for automated malware classification. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; ACM: New York, NY, USA, 2013. [Google Scholar]
- Liu, L.; Wang, B.-S.; Yu, B.; Zhong, Q.-X. Automatic Malware Classification and New Malware Detection using Machine Learning. Front. Inf. Technol. Electron. Eng. 2016, 18, 1336–1347. [Google Scholar] [CrossRef]
- Schultz, M.M.; Eskin, E.Z.; Stolfo, F. Data Mining Methods for Detection of New Malicious Executables. In Proceedings of the 22nd IEEE Symposium on Security and Privacy, Oakland, CA, USA, 14–16 May 2001. [Google Scholar]
- Makandar, A.; Patrot, A. Malware Analysis and Classification using Artificial Neural Network. In Proceedings of the 2015 International Conference on Trends in Automation, Communications and Computing Technology, Bangalore, India, 21–22 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Microsoft Joint Meet on Security. Naming Malware. 2017. Available online: https://www.microsoft.com/en-us/security/portal/mmpc/shared/malwarenaming.aspx (accessed on 2 December 2023).
- Van Rijsbergen, C.J. Information Retrieval; Butterworth-Heinemann: London, UK, 1979; pp. 25–30. [Google Scholar]
- Moser, A.; Kruegel, C.; Kirda, E. Limits of Static Analysis for Malware Detection. In Proceedings of the Twenty-Third Annual Computer Security Applications Conference, Miami Beach, FL, USA, 10–14 December 2007. [Google Scholar]
- Nari, S.; Ghorbani, A. Automated Malware Classification Based on Network Behaviour. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), San Diego, CA, USA, 28–31 January 2013. [Google Scholar]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B. Malware Images: Visualization and Automatic Classification. In Proceedings of the International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011. [Google Scholar]
- Ollmann, G. The Evolution of commercial malware development kits and colour-by-numbers custom malware. Comput. Fraud. Secur. 2008, 2008, 4–7. [Google Scholar] [CrossRef]
- Pandalabs Library Control Centre. Quaterly Report. 2016. Available online: http://www.pandasecurity.com/mediacenter/src/uploads/2016/05/Pandalabs-2016-T1-EN-LR.pdf (accessed on 2 December 2023).
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B. MalimgDataset. 2011. Available online: https://vision.ece.ucsb.edu/research/signal-processing-malware-analysis (accessed on 2 December 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Tian, R.; Batten, L.; Versteeg, S. Function length as a tool for malware classification. In Proceedings of the 2008 3rd International Conference on Malicious and Unwanted Software (MALWARE), Alexandria, VA, USA, 7–8 October 2008. [Google Scholar]
- Radu, S.P.; Hansen, S.S.; Larsen, T.M.; Stevanovic, M.; Pedersen, J.M.; Czech, A. Analysis of malware behavior: Type classification using machine learning. In Proceedings of the 2015 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), London, UK, 8–9 June 2015. [Google Scholar]
- Raghakot. Deep Residual Learning for Image Recognition ResNet. 2015. Available online: https://github.com/raghakot/keras-resnet (accessed on 2 December 2023).
- Rieck, K.; Holz, T.; Willems, C.; Dussel, P.; Laskov, P. Learning and classification of Malware behaviour. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Paris, France, 10–11 July 2008. [Google Scholar]
- Staniford, V.P.S.; Weaver, N. How to own the internet in your spare time. In Proceedings of the 11th USENIX Security Symposium, San Francisco, CA, USA, 5–9 August 2002. [Google Scholar]
- Santos, I.; Devesa, J.; Brezo, F.; Nieves, J.; Bringas, P.G. OPEM: A Static-Dynamic Approach for Machine-Learning-Based Malware Detection. In International Joint Conference CISIS’12-ICEUTE’12-SOCO’12 Special Sessions; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Santos, I.; Nieves, J.; Bringas, P. Semi-Supervised Learning for Unknown Malware Detection. In Proceedings of the Symposium on Distributed Computing and Artificial Intelligence Advances in Intelligent and Soft Computing, Salamanca, Spain, 6–8 April 2011. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Siddiqui, M.; Wang, M.C. Detecting Internet Worms Using Data Mining Techniques. J. Syst. Cybern. Inform. 2009, 6, 48–53. [Google Scholar]
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-On Guide to Dissecting Malicious Software; No Starch Press: San Francisco, CA, USA, 2012. [Google Scholar]
- Agarwal, D.; Kaushik, S.; Hasteer, N.; Rajput, P.; Khari, M. MaleVis: A Benchmark Dataset for Malware Visualization and Classification. Multimedia Tools Appl. 2021, 80, 18565–18583. [Google Scholar] [CrossRef]
- Szor, P. The Art of Computer Virus Research and Defense. Addison 2005, 2, 46–51. [Google Scholar]
- Torralba, A.; Murphy, K.; Freeman, W.; Rubin, M. Classification of malware based on integrated static and dynamic features. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV 2003), Nice, France, 14–17 October 2003. [Google Scholar]
- Vinod, P.; Laxmi, V.; Gaur, M. Survey on Malware Detection Methods. In Proceedings of the 3rd Hacker’s Workshop on Computer and Internet Security (IITKHACK’09), Kanpur, India, 17–19 March 2009; pp. 74–79. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- VirusTotal Labs on Security and Detection. Daily Statistics. 2017. Available online: https://www.virustotal.com/en/statistics/ (accessed on 2 December 2023).
- Wagener, G.; State, R.; Dulaunoy, A. Malware behaviour analysis. J. Comput. Virol. 2008, 4, 279–287. [Google Scholar] [CrossRef]
- Wikipedia. Malware Detection and Types Mirai Malware. 2016. Available online: https://en.wikipedia.org/wiki/Mirai_(malware) (accessed on 2 December 2023).
- Wikipedia. New Age Malware Detection: Ransomware. 2017. Available online: https://en.wikipedia.org/wiki/Ransomware (accessed on 2 December 2023).
- Wikipedia. Recent Trends: WannaCry Ransomware. 2017. Available online: https://en.wikipedia.org/wiki/WannaCry_ransomware_attack (accessed on 2 December 2023).
- Willems, C.; Holz, T.; Freiling, F. Toward Automated Dynamic Malware Analysis Using Cwsandbox. IEEE Secur. Priv. 2007, 5, 32–39. [Google Scholar] [CrossRef]
- Yoo, I.S. Visualizing windows executable virus using self-organizing maps. In Proceedings of the ACM Workshop on Visualization and Data Mining for Computer Security, Washington, DC, USA, 29 October 2004. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901S. [Google Scholar]
- Zhang, Q.; Reeves, D. Metaware: Identifying Metamorphic Malware. In Proceedings of the 23rd Annual Computer Security Applications Conference, Miami Beach, FL, USA, 10–14 December 2007. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with Local and Global Consistency. Adv. Neural Inf. Process. Syst. 2004, 16, 321–328. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. Digit. Signal Process. 2017, 73, 1–15. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Power | Advantages | Disadvantages | Differences | Gap Points |
|---|---|---|---|---|---|
| Signature-Based [5] | Fast and accurate for known malware | Quick detection of known threats [2,5] | Ineffective for zero-day attacks; high dependency on database updates [2,5] | Relies on byte-sequence matching [5] | Struggles with detecting new polymorphic and metamorphic malware |
| Anomaly-Based [6] | Effective for detecting unknown threats | Can identify previously unseen malware [6] | High false-positive rate; computationally expensive | Compares behavior against a baseline | Requires extensive training data and fine-tuning |
| Image-Based [7] | Platform-independent; highly scalable | Detects structural similarities in malware; avoids execution for analysis [7] | Dependent on image representation quality | Leverages visual features for classification | Needs further exploration in dynamic feature extraction and efficiency |
| Proposed Method | High accuracy, lightweight, and adaptable | Captures long-range spatial interactions; reduces preprocessing requirements | Slightly higher training cost due to deep neural network | Utilizes involution kernels and residual blocks for feature extraction [4] | Future refinement needed for kernel efficiency and scalability across diverse datasets |
| Type | Family | # |
|---|---|---|
| TrojanDropner | Sventoure.C | 1605 |
| Keygen! | 1002 | |
| Sventoure.B | 1654 | |
| Exploit | IframeRef.gen! | 2268 |
| IfraneRef.NM! | 3134 | |
| JuiceExp.gen | 989 | |
| Worm | Yuner.A | 3906 |
| Allaple.A | 3017 | |
| VB.AT | 3748 | |
| ExploreZip | 1010 | |
| Trojan | Redirector.BW | 2185 |
| Iframe.AE | 1487 | |
| BlacoleRef.W | 1665 | |
| IframeRef.I | 2483 | |
| BlacoleRef.CZ | 1838 | |
| Iframeinject.AF | 2088 | |
| Comame!gmb | 1875 | |
| Virus | Krepper.30760 | 1127 |
| Luder.B | 2088 | |
| Ramnit.gen!C | 4233 | |
| Backdoor | Agent | 840 |
| FinSpy | 223 | |
| TrojanClicker | Faceliker.C | 1044 |
| TrojanDownloader | Tuggspay.B | 2775 |
| FatherChristmas.S | 1090 | |
| Total | 49,374 | |
| Classes | Precision | Recall | F1-Score | # |
|---|---|---|---|---|
| 0 | 0.980068 | 0.965425 | 0.974123 | 711 |
| 1 | 0.99406 | 0.97661 | 0.985263 | 291 |
| 2 | 0.997627 | 0.996657 | 0.996247 | 931 |
| 3 | 0.78122 | 0.790142 | 0.785602 | 789 |
| 4 | 1 | 0.957627 | 0.978355 | 708 |
| 5 | 0.650273 | 0.760383 | 0.701031 | 313 |
| 6 | 0.973333 | 0.99455 | 0.983827 | 367 |
| 7 | 0.994071 | 0.994071 | 0.994071 | 506 |
| 8 | 0.990403 | 0.923077 | 0.955556 | 559 |
| 9 | 0.998944 | 0.98954 | 0.99422 | 956 |
| 10 | 0.98677 | 0.996072 | 0.9914 | 1273 |
| 11 | 0.998106 | 1.0 | 0.999052 | 527 |
| 12 | 1.0 | 0.993927 | 0.996954 | 494 |
| 13 | 0.990172 | 0.98533 | 0.987745 | 818 |
| 14 | 0.99308 | 0.97619 | 0.984563 | 588 |
| 15 | 1.0 | 1.0 | 1.0 | 1324 |
| 16 | 0.983498 | 0.996656 | 0.990033 | 598 |
| 17 | 0.879959 | 0.859841 | 0.869784 | 1006 |
| 18 | 0.995652 | 0.980029 | 0.987779 | 1402 |
| 19 | 0.72517 | 0.794337 | 0.758179 | 671 |
| 20 | 0.879959 | 0.859841 | 0.869784 | 356 |
| 21 | 0.981268 | 0.965957 | 0.973553 | 221 |
| 22 | 1.0 | 1.0 | 1.0 | 303 |
| 23 | 0.983498 | 0.996656 | 0.990033 | 1002 |
| 24 | 0.650273 | 0.760383 | 0.701031 | 376 |
| 25 | 0.973333 | 0.99455 | 0.983827 | 291 |
| Average | 0.95482 | 0.952458 | 0.95338 | 17,378 |
| Classes | Precision | Recall | F1-Score | # |
|---|---|---|---|---|
| 0 | 0.985955 | 0.995745 | 0.990826 | 705 |
| 1 | 0.989761 | 0.986395 | 0.988075 | 294 |
| 2 | 0.998924 | 0.998924 | 0.998924 | 929 |
| 3 | 0.879854 | 0.916561 | 0.897833 | 791 |
| 4 | 0.988555 | 0.975989 | 0.982232 | 708 |
| 5 | 0.848138 | 0.945687 | 0.89426 | 313 |
| 6 | 0.997268 | 0.99455 | 0.995907 | 367 |
| 7 | 1.0 | 0.994071 | 0.997027 | 506 |
| 8 | 0.987522 | 0.991055 | 0.989286 | 559 |
| 9 | 0.993763 | 1.0 | 0.996872 | 956 |
| 10 | 0.998426 | 0.996858 | 0.997642 | 1273 |
| 11 | 1.0 | 1.0 | 1.0 | 527 |
| 12 | 1.0 | 0.997976 | 0.998987 | 494 |
| 13 | 0.996324 | 0.993888 | 0.995104 | 818 |
| 14 | 0.996581 | 0.991497 | 0.994032 | 588 |
| 15 | 1.0 | 1.0 | 1.0 | 1324 |
| 16 | 1.0 | 0.996656 | 0.998325 | 598 |
| 17 | 0.945304 | 0.910537 | 0.927595 | 1006 |
| 18 | 0.998574 | 0.999287 | 0.99893 | 1402 |
| 19 | 0.97527 | 0.940387 | 0.957511 | 671 |
| 20 | 0.955304 | 0.920537 | 0.937595 | 356 |
| 21 | 0.874985 | 0.912561 | 0.895833 | 221 |
| 22 | 0.858138 | 0.942687 | 0.89226 | 303 |
| 23 | 0.942304 | 0.920537 | 0.926595 | 1002 |
| 24 | 0.959304 | 0.920237 | 0.947595 | 376 |
| 25 | 0.884985 | 0.912561 | 0.895833 | 291 |
| Average | 0.982062 | 0.988123 | 0.982176 | 17,378 |
| Metric | Mean | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|
| Accuracy (%) | 99.5 | ±0.12 | 99.3 | 99.7 |
| Precision | 0.9932 | ±0.001 | 0.992 | 0.9945 |
| Recall | 0.9905 | ±0.001 | 0.989 | 0.9917 |
| F1-Score | 0.9948 | ±0.001 | 0.9935 | 0.996 |
| Metrics | Malimg Dataset | MaleVis Dataset | Our Dataset |
|---|---|---|---|
| Accuracy (%) | 99.3 | 98.9 | 99.5 |
| Precision | 0.992 | 0.99 | 0.9932 |
| Recall | 0.989 | 0.988 | 0.9905 |
| F1-Score | 0.9905 | 0.9892 | 0.9948 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet-50 | 97.32 | 0.9520 | 0.9563 | 0.9704 |
| DenseNet201 | 98.50 | 0.9730 | 0.9755 | 0.9842 |
| EfficientNet-B4 | 96.82 | 0.9334 | 0.9357 | 0.9578 |
| InceptionV4 | 98.76 | 0.9801 | 0.9832 | 0.9884 |
| MobileNetV3 [57] | 99.08 | 0.9823 | 0.9815 | 0.9901 |
| SE-ResNet-50 [58] | 97.65 | 0.9594 | 0.9608 | 0.9789 |
| NASNet | 98.15 | 0.9685 | 0.9678 | 0.9812 |
| ShuffleNetV2 | 97.89 | 0.9602 | 0.9630 | 0.9773 |
| Resnet18 | 98.70 | 0.9789 | 0.9763 | 0.9865 |
| Squeezenet1 | 98.47 | 0.9711 | 0.9712 | 0.9824 |
| XceptionNet [59] | 98.66 | 0.9614 | 0.9609 | 0.97755 |
| DRIN (Proposed) | 99.50 | 0.9932 | 0.9905 | 0.9948 |
| Model | FLOPs (Giga) | Inference Time (ms) | Reduction in Complexity (%) |
|---|---|---|---|
| ResNet-50 | 3.8 | 12.4 | 25.20 |
| DenseNet201 | 4.3 | 14.2 | - |
| EfficientNet-B4 | 2.7 | 9.5 | 17.40 |
| MobileNetV3 | 0.9 | 4.3 | 46.10 |
| NASNet | 4.9 | 15.3 | - |
| DRIN (Proposed) | 2.3 | 7.8 | 39.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basak, M.; Kim, D.-W.; Han, M.-M.; Shin, G.-Y. Attention-Based Malware Detection Model by Visualizing Latent Features Through Dynamic Residual Kernel Network. Sensors 2024, 24, 7953. https://doi.org/10.3390/s24247953
Basak M, Kim D-W, Han M-M, Shin G-Y. Attention-Based Malware Detection Model by Visualizing Latent Features Through Dynamic Residual Kernel Network. Sensors. 2024; 24(24):7953. https://doi.org/10.3390/s24247953
Chicago/Turabian StyleBasak, Mainak, Dong-Wook Kim, Myung-Mook Han, and Gun-Yoon Shin. 2024. "Attention-Based Malware Detection Model by Visualizing Latent Features Through Dynamic Residual Kernel Network" Sensors 24, no. 24: 7953. https://doi.org/10.3390/s24247953
APA StyleBasak, M., Kim, D.-W., Han, M.-M., & Shin, G.-Y. (2024). Attention-Based Malware Detection Model by Visualizing Latent Features Through Dynamic Residual Kernel Network. Sensors, 24(24), 7953. https://doi.org/10.3390/s24247953