Edge-Cloud Synergy for AI-Enhanced Sensor Network Data: A Real-Time Predictive Maintenance Framework

 , , , , and
, , , , and 
Abstract
1. Introduction
1.1. Background and Motivation
1.2. Problem Statement
1.3. Research Objectives
- Hybrid AI Model Deployment: Developing a lightweight AI model suitable for edge devices for real-time anomaly detection complemented by deep learning models in the cloud for comprehensive analytics.
- Dynamic Workload Management: Designing a novel algorithm to dynamically balance workloads between edge devices and cloud servers depending on network conditions, data volume, and sensor operations while ensuring uninterrupted performance.
- Predictive Maintenance: To implement a full-fledged predictive maintenance system that analyzes time-series sensor data, predicts potential equipment failures and optimizes maintenance schedules to facilitate improved operational efficiency.
- Resource Optimization: Evaluate strategies for efficient resource allocation between the edge and cloud to minimize energy consumption, network bandwidth usage, and latency.
1.4. Core Contributions
- Hybrid AI Model Deployment: We propose the development of lightweight AI models deployed on edge devices to perform immediate anomaly detection. These models operate in conjunction with cloud-based deep learning algorithms, which provide comprehensive analytics and long-term insights.
- Dynamic Workload Management Algorithm: A novel algorithm for real-time workload offloading is introduced, which dynamically shifts workloads between the edge and cloud-based on sensor activity, network conditions, and computational demands. This ensures seamless operation and prevents bottlenecks.
- Predictive Maintenance Using Time-Series Data: The framework utilizes AI to analyze sensor data streams, predicting potential equipment failures. By doing so, it enables proactive scheduling of maintenance, reducing downtime and extending equipment lifespan.
- Resource Optimization for Energy and Bandwidth Efficiency: We investigate resource allocation strategies to optimize the distribution of computational tasks between the edge and cloud. The goal is to minimize energy consumption and bandwidth usage while maintaining low-latency operations.
2. Literature Review
2.1. Edge Computing in AI-Enhanced Sensor Networks
2.2. Cloud-Based AI Analytics
2.3. Hybrid Edge-Cloud Frameworks
2.4. Predictive Maintenance in Sensor Networks
2.5. Recent Advancements in Hybrid Edge-Cloud Frameworks
3. Methodology
3.1. Dataset Description and Preprocessing
3.1.1. Dataset Features
3.1.2. Data Preprocessing
3.2. Comparative Analysis for Hardware and AI Model Selection
3.2.1. Edge Device Selection
3.2.2. AI and ML Model Selection
3.2.3. Cloud Service and Model Selection
3.2.4. Deep Learning Model Selection
3.2.5. Addressing Retraining Challenges in Machine Learning Models
3.2.6. Justification for the Choice of Metric in KNN
3.2.7. Selection of Optimal Parameters for KNN
3.3. Data Transfer Protocols and Their Limitations
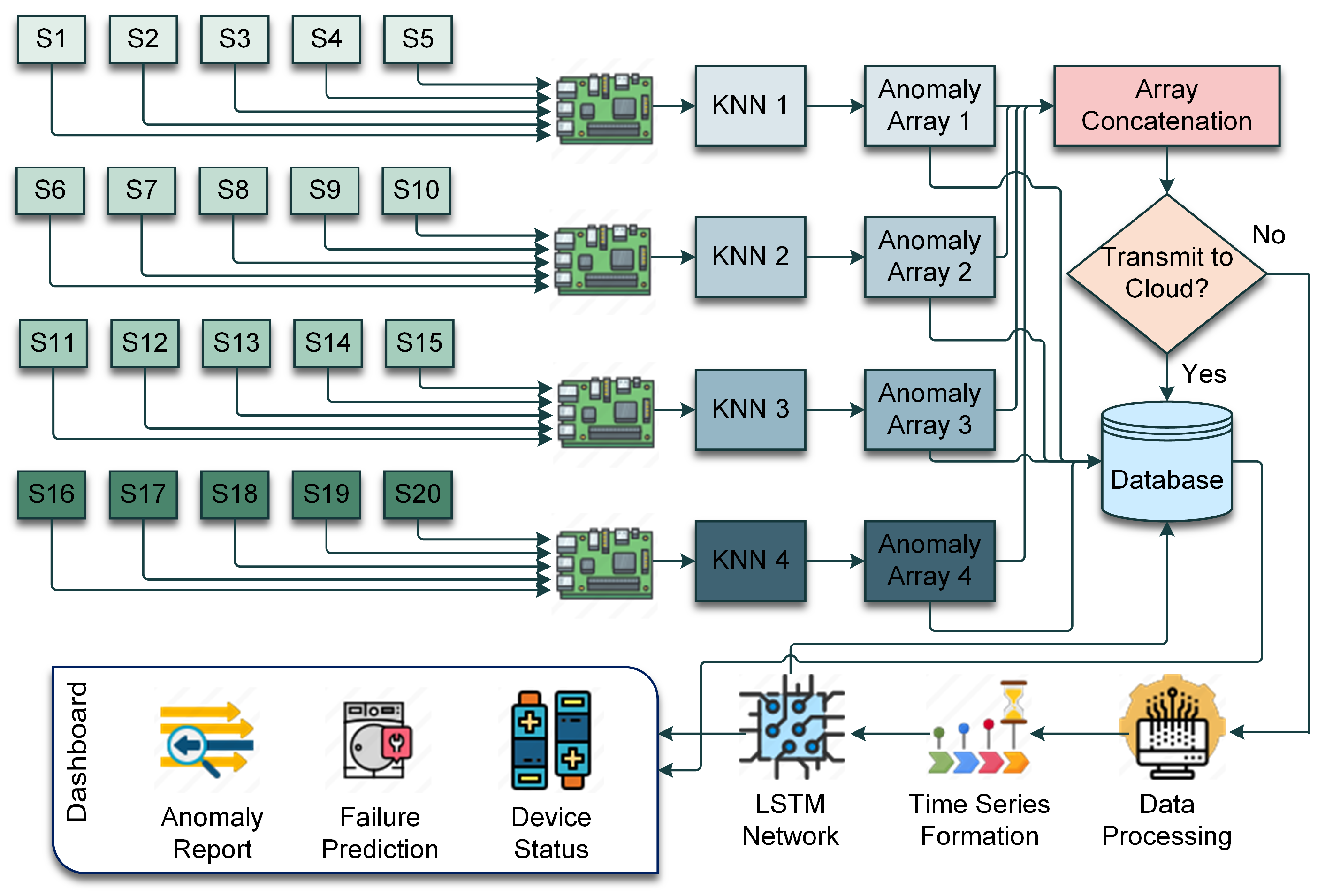
3.4. Conceptual Design of the Hybrid AI Model
3.4.1. Anomaly Detection at the Edge
3.4.2. Threshold Calculation for Anomaly Detection
3.4.3. Failure Prediction in the Cloud
3.4.4. Hybrid AI Model Operation Algorithm
| Algorithm 1 Hybrid AI Model for Predictive Maintenance |
|
3.5. Dynamic Workload Management Algorithm
| Algorithm 2 Dynamic Workload Management Algorithm |
|
Reproducibility of the Algorithm
3.6. Resource Optimization Mechanism
| Algorithm 3 Resource Optimization Mechanism |
|
3.7. Security Considerations in Information Processing
3.7.1. Transmission Security
3.7.2. Storage Security
3.7.3. Processing Security
4. Implementation
4.1. KNN Development and Implementation
4.2. LSTM Network for Failure Prediction in the Cloud
4.3. Workflow
5. Experimental Results and Performance Analysis
5.1. Anomaly Detection at the Edge
5.2. LSTM Failure Prediction at the Cloud
5.3. Latency Performance
5.4. Energy Consumption Performance
5.5. Bandwidth Usage Performance
5.6. Comparison with Fog Computing Approaches
5.7. Comparison with State-of-the-Art Workload Management Algorithms
5.8. Scalability Considerations for Larger Sensor Networks and Higher Data Velocities
5.9. Comparison with Existing Hybrid Approaches
6. Limitation and Future Direction
6.1. System Downtime
6.2. Extendability Issue
6.3. Constraint in Workload Distribution
6.4. Sensor Lifespan
6.5. Maintenance Cost
7. Keys Aspects and Discussion
7.1. Industrial Automation and Smart Manufacturing
7.2. Energy Sector and Smart Grids
7.3. Environmental Monitoring and Agriculture
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| ML | Machine Learning |
| KNN | K-Nearest Neighbors |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| IoT | Internet of Things |
| 3Vs | Volume, Velocity, Variety |
| AWS | Amazon Web Services |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- Karthick Raghunath, K.; Koti, M.S.; Sivakami, R.; Vinoth Kumar, V.; NagaJyothi, G.; Muthukumaran, V. Utilization of IoT-assisted computational strategies in wireless sensor networks for smart infrastructure management. Int. J. Syst. Assur. Eng. Manag. 2024, 15, 28–34. [Google Scholar] [CrossRef]
- Aggarwal, A. Identification of quality parameters associated with 3V’s of Big Data. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1135–1140. [Google Scholar]
- Choudhury, A.; Ghose, M.; Islam, A.; Yogita. Machine learning-based computation offloading in multi-access edge computing: A survey. J. Syst. Archit. 2024, 148, 103090. [Google Scholar] [CrossRef]
- Ali, S.; Wadho, S.A.; Yichiet, A.; Gan, M.L.; Lee, C.K. Advancing cloud security: Unveiling the protective potential of homomorphic secret sharing in secure cloud computing. Egypt. Inform. J. 2024, 27, 100519. [Google Scholar] [CrossRef]
- Gong, L.; Chen, Y. Machine learning-enhanced loT and wireless sensor networks for predictive analysis and maintenance in wind turbine systems. Int. J. Intell. Netw. 2024, 5, 133–144. [Google Scholar] [CrossRef]
- Pech, M.; Vrchota, J.; Bednář, J. Predictive maintenance and intelligent sensors in smart factory. Sensors 2021, 21, 1470. [Google Scholar] [CrossRef]
- Mukherjee, M.; Guo, M.; Lloret, J.; Zhang, Q. Leveraging intelligent computation offloading with fog/edge computing for tactile internet: Advantages and limitations. IEEE Netw. 2020, 34, 322–329. [Google Scholar] [CrossRef]
- Abid, A.; Jemili, F.; Korbaa, O. Real-time data fusion for intrusion detection in industrial control systems based on cloud computing and big data techniques. Clust. Comput. 2024, 27, 2217–2238. [Google Scholar] [CrossRef]
- Alhosban, A.; Pesingu, S.; Kalyanam, K. CVL: A Cloud Vendor Lock-In Prediction Framework. Mathematics 2024, 12, 387. [Google Scholar] [CrossRef]
- Sharma, M.; Tomar, A.; Hazra, A. Edge computing for industry 5.0: Fundamental, applications and research challenges. IEEE Internet Things J. 2024, 11, 19070–19093. [Google Scholar] [CrossRef]
- Wu, N.; Jiang, R.; Wang, X.; Yang, L.; Zhang, K.; Yi, W.; Nallanathan, A. AI-Enhanced Integrated Sensing and Communications: Advancements, Challenges, and Prospects. IEEE Commun. Mag. 2024, 62, 144–150. [Google Scholar] [CrossRef]
- Hong, C.H.; Varghese, B. Resource management in fog/edge computing: A survey on architectures, infrastructure, and algorithms. ACM Comput. Surv. (CSUR) 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, S.; Valls, V.; Ko, B.J.; Lee, W.H.; Leung, K.K.; Tassiulas, L. Model pruning enables efficient federated learning on edge devices. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 10374–10386. [Google Scholar] [CrossRef] [PubMed]
- Capra, M.; Peloso, R.; Masera, G.; Ruo Roch, M.; Martina, M. Edge computing: A survey on the hardware requirements in the internet of things world. Future Internet 2019, 11, 100. [Google Scholar] [CrossRef]
- Djigal, H.; Xu, J.; Liu, L.; Zhang, Y. Machine and deep learning for resource allocation in multi-access edge computing: A survey. IEEE Commun. Surv. Tutor. 2022, 24, 2449–2494. [Google Scholar] [CrossRef]
- Zhao, L.; Sakr, S.; Liu, A.; Bouguettaya, A.; Zhao, L.; Sakr, S.; Liu, A.; Bouguettaya, A. Cloud computing. In Cloud Data Management; Springer: Cham, Switzerland, 2014; pp. 9–20. [Google Scholar]
- Schmitt, J.; Bönig, J.; Borggräfe, T.; Beitinger, G.; Deuse, J. Predictive model-based quality inspection using Machine Learning and Edge Cloud Computing. Adv. Eng. Inform. 2020, 45, 101101. [Google Scholar] [CrossRef]
- Simaiya, S.; Lilhore, U.K.; Sharma, Y.K.; Rao, K.B.V.B.; Maheswara Rao, V.V.R.; Baliyan, A.; Bijalwan, A.; Alroobaea, R. A Hybrid Cloud Load Balancing and Host Utilization Prediction Method Using Deep Learning and Optimization Techniques. Sci. Rep. 2024, 14, 1337. [Google Scholar] [CrossRef]
- Tengku Asmawi, T.N.; Ismail, A.; Shen, J. Cloud failure prediction based on traditional machine learning and deep learning. J. Cloud Comput. 2022, 11, 47. [Google Scholar] [CrossRef]
- Raviprasad, B.; Mohan, C.R.; Devi, G.N.R.; Pugalenthi, R.; Manikandan, L.; Ponnusamy, S. Accuracy determination using deep learning technique in cloud-based IoT sensor environment. Meas. Sens. 2022, 24, 100459. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, T.; Zhang, S.; Zhang, J. An intelligent big data collection technology based on micro mobile data centers for crowdsensing vehicular sensor network. Pers. Ubiquitous Comput. 2023, 27, 563–579. [Google Scholar] [CrossRef]
- Bergui, M.; Najah, S.; Nikolov, N.S. A survey on bandwidth-aware geo-distributed frameworks for big-data analytics. J. Big Data 2021, 8, 40. [Google Scholar] [CrossRef]
- Tang, B.; Luo, J.; Zhang, J. Container-based data-intensive application scheduling in hybrid cloud-edge collaborative environment. Softw. Pract. Exp. 2024, 54, 1217–1240. [Google Scholar] [CrossRef]
- Grzesik, P.; Mrozek, D. Combining Machine Learning and Edge Computing: Opportunities, Challenges, Platforms, Frameworks, and Use Cases. Electronics 2024, 13, 640. [Google Scholar] [CrossRef]
- Xu, X.; Zang, S.; Bilal, M.; Xu, X.; Dou, W. Intelligent architecture and platforms for private edge cloud systems: A review. Future Gener. Comput. Syst. 2024, 160, 457–471. [Google Scholar] [CrossRef]
- Ucar, A.; Karakose, M.; Kırımça, N. Artificial intelligence for predictive maintenance applications: Key components, trustworthiness, and future trends. Appl. Sci. 2024, 14, 898. [Google Scholar] [CrossRef]
- Prabha, S.; Upadhyay, R.; Goswami, P.K. The Smart Predictive Network Maintenance Model using AI/ML Time Series Analysis in Cloud Networks. In Proceedings of the 2024 International Conference on Optimization Computing and Wireless Communication (ICOCWC), Debre Tabor, Ethiopia, 29–30 January 2024; pp. 1–7. [Google Scholar]
- Maguluri, L.P.; Suganthi, D.; Dhote, G.M.; Kapila, D.; Jadhav, M.M.; Neelima, S. AI-enhanced predictive maintenance in hybrid roll-to-roll manufacturing integrating multi-sensor data and self-supervised learning. Int. J. Adv. Manuf. Technol. 2024, 1–10. [Google Scholar] [CrossRef]
- Chiang, S.; Zito, J.; Rao, V.R.; Vannucci, M. Time-series analysis. In Statistical Methods in Epilepsy; Chapman and Hall/CRC: London, UK, 2024; pp. 166–200. [Google Scholar]
- Leng, J.; Guo, J.; Wang, D.; Zhong, Y.; Xu, K.; Huang, S.; Liu, J.; Yu, C.; Ye, Z.; Liu, Q. Blockchain-of-Things-Based Edge Learning Contracts for Federated Predictive Maintenance Toward Resilient Manufacturing. IEEE Trans. Comput. Soc. Syst. 2024, 11, 7990–8004. [Google Scholar] [CrossRef]
- Souza, P.; Ferreto, T.; Calheiros, R. Maintenance Operations on Cloud, Edge, and IoT Environments: Taxonomy, Survey, and Research Challenges. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Ren, L.; Liu, Y.; Wang, X.; Lü, J.; Deen, M.J. Cloud–edge-based lightweight temporal convolutional networks for remaining useful life prediction in iiot. IEEE Internet Things J. 2020, 8, 12578–12587. [Google Scholar] [CrossRef]
- Boiko, O.; Komin, A.; Malekian, R.; Davidsson, P. Edge-Cloud Architectures for Hybrid Energy Management Systems: A Comprehensive Review. IEEE Sens. J. 2024, 24, 15748–15772. [Google Scholar] [CrossRef]
- Chauhan, M.A.; Babar, M.A.; Shen, H. KRIOTA: A framework for Knowledge-management of dynamic Reference Information and Optimal Task Assignment in hybrid edge-cloud environments to support situation-aware robot-assisted operations. Future Gener. Comput. Syst. 2024, 160, 489–504. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, R.; Kuang, Z.; Wang, B.; Li, Y. ArchGPT: Harnessing large language models for supporting renovation and conservation of traditional architectural heritage. Herit. Sci. 2024, 12, 220. [Google Scholar] [CrossRef]
- Shahra, E.Q.; Wu, W.; Basurra, S.; Aneiba, A. Intelligent Edge-Cloud Framework for Water Quality Monitoring in Water Distribution System. Water 2024, 16, 196. [Google Scholar] [CrossRef]
- Bhoi, S.K.; Chakraborty, S.; Verbrugge, B.; Helsen, S.; Robyns, S.; El Baghdadi, M.; Hegazy, O. Intelligent data-driven condition monitoring of power electronics systems using smart edge–cloud framework. Internet Things 2024, 26, 101158. [Google Scholar] [CrossRef]
- Faruqui, N.; Yousuf, M.A.; Chakraborty, P.; Hossain, M.S. Innovative automation algorithm in micro-multinational data-entry industry. In Proceedings of the Cyber Security and Computer Science: Second EAI International Conference, ICONCS 2020, Dhaka, Bangladesh, 15–16 February 2020; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2020; pp. 680–692. [Google Scholar]
- Zhang, C.; Liu, Y.; Tie, N. Forest Land Resource Information Acquisition with Sentinel-2 Image Utilizing Support Vector Machine, K-Nearest Neighbor, Random Forest, Decision Trees and Multi-Layer Perceptron. Forests 2023, 14, 254. [Google Scholar] [CrossRef]
- Arpaci, I.; Masrek, M.N.; Al-Sharafi, M.A.; Al-Emran, M. Evaluating the actual use of cloud computing in higher education through information management factors: A cross-cultural comparison. Educ. Inf. Technol. 2023, 28, 12089–12109. [Google Scholar] [CrossRef]
- Khan, S.; Kumar, V. A novel hybrid GRU-CNN and residual bias (RB) based RB-GRU-CNN models for prediction of PTB Diagnostic ECG time series data. Biomed. Signal Process. Control. 2024, 94, 106262. [Google Scholar] [CrossRef]
- ArunKumar, K.; Kalaga, D.V.; Kumar, C.M.S.; Kawaji, M.; Brenza, T.M. Comparative analysis of Gated Recurrent Units (GRU), long Short-Term memory (LSTM) cells, autoregressive Integrated moving average (ARIMA), seasonal autoregressive Integrated moving average (SARIMA) for forecasting COVID-19 trends. Alex. Eng. J. 2022, 61, 7585–7603. [Google Scholar] [CrossRef]
- Siraj, M.S.; Ahad, M. A hybrid deep learning framework using CNN and GRU-based RNN for recognition of pairwise similar activities. In Proceedings of the 2020 Joint 9th International Conference on Informatics, Electronics & Vision (ICIEV) and 2020 4th International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 26–29 August 2020; pp. 1–7. [Google Scholar]
- Amalou, I.; Mouhni, N.; Abdali, A. Multivariate time series prediction by RNN architectures for energy consumption forecasting. Energy Rep. 2022, 8, 1084–1091. [Google Scholar] [CrossRef]
- Ghaleb, B.; Al-Dubai, A.Y.; Ekonomou, E.; Alsarhan, A.; Nasser, Y.; Mackenzie, L.M.; Boukerche, A. A survey of limitations and enhancements of the ipv6 routing protocol for low-power and lossy networks: A focus on core operations. IEEE Commun. Surv. Tutor. 2018, 21, 1607–1635. [Google Scholar] [CrossRef]
- Faruqui, N.; Yousuf, M.A.; Whaiduzzaman, M.; Azad, A.; Alyami, S.A.; Liò, P.; Kabir, M.A.; Moni, M.A. SafetyMed: A novel IoMT intrusion detection system using CNN-LSTM hybridization. Electronics 2023, 12, 3541. [Google Scholar] [CrossRef]
- Paula, L.P.O.; Faruqui, N.; Mahmud, I.; Whaiduzzaman, M.; Hawkinson, E.C.; Trivedi, S. A novel front door security (FDS) algorithm using GoogleNet-BiLSTM hybridization. IEEE Access 2023, 11, 19122–19134. [Google Scholar] [CrossRef]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Alsadie, D. A Comprehensive Review of AI Techniques for Resource Management in Fog Computing: Trends, Challenges and Future Directions. IEEE Access 2024, 12, 118007–118059. [Google Scholar] [CrossRef]
- Ramsauer, R.; Huber, S.; Schwarz, K.; Kiszka, J.; Mauerer, W. Static Hardware Partitioning on RISC-V: Shortcomings, Limitations, and Prospects. In Proceedings of the 2022 IEEE 8th World Forum on Internet of Things (WF-IoT), Yokohama, Japan, 26 October–11 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Yekta, M.; Shahhoseini, H. A Review on Machine Learning Methods for Workload Prediction in Cloud Computing. In Proceedings of the 2023 13th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 1–2 November 2023; pp. 306–311. [Google Scholar] [CrossRef]
- Cai, L.; Yao, K.; Xian, W.; Gong, C. Edge Computing Resource Management Based on Genetic Algorithm. In Proceedings of the 2023 IEEE 13th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 14–16 July 2023; pp. 153–157. [Google Scholar] [CrossRef]
- Abyaneh, A.H.A.; Liao, M.; Zahedi, S. Malcolm: Multi-agent Learning for Cooperative Load Management at Rack Scale. ACM SIGMETRICS Perform. Eval. Rev. 2023, 51, 39–40. [Google Scholar] [CrossRef]
- Avinash, S.; Srikar, A.S.; Naik, V.P.; Bhaskaran, S. SDN-based Hybrid Load Balancing Algorithm. In Proceedings of the 2023 3rd International Conference on Intelligent Technologies (CONIT), Hubli, India, 23–25 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Kavitha, S.; Rao, D.D.; Jain, A.; Sharma, S.; Pandey, S.V.P.R. Effectual Energy Optimization Stratagems for Wireless Sensor Network Collections Through Fuzzy-Based Inadequate Clustering. SN Comput. Sci. 2024, 5, 1–10. [Google Scholar]
- Symvoulidis, C.; Kiourtis, A.; Mavrogiorgou, A.; Tom-Ata, J.D.T.; Manias, G.; Kyriazis, D. Dynamic deployment prediction and configuration in hybrid cloud/edge computing environments using influence-based learning. In Proceedings of the 2023 10th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Palembang, Indonesia, 20–21 September 2023; pp. 315–320. [Google Scholar] [CrossRef]
- Silva, J.; Marques, E.R.B.; Lopes, L.M.B.; Silva, F.M.A. Jay: A software framework for prototyping and evaluating offloading applications in hybrid edge clouds. Softw. Pract. Exp. 2023, 53, 2007–2025. [Google Scholar] [CrossRef]
- Chen, Q.; You, Z.; Wen, D.; Zhang, Z. Enhanced Hybrid Hierarchical Federated Edge Learning over Heterogeneous Networks. IEEE Trans. Veh. Technol. 2023, 72, 14601–14614. [Google Scholar] [CrossRef]
- Faruqui, N.; Yousuf, M.A.; Kateb, F.A.; Hamid, M.A.; Monowar, M.M. Healthcare as a Service (HAAS): CNN-based cloud computing model for ubiquitous access to lung cancer diagnosis. Heliyon 2023, 9, e21520. [Google Scholar] [CrossRef]
- Janek, M. Investigating the Wavelength and Polarization of Electromagnetic Wave using Raspberry Pi Zero W. In Proceedings of the 2022 International Conference on Communications, Information, Electronic and Energy Systems (CIEES), Veliko Tarnovo, Bulgaria, 20–22 November 2022; pp. 1–5. [Google Scholar]
- Peruzzini, M.; Prati, E.; Pellicciari, M. A framework to design smart manufacturing systems for Industry 5.0 based on the human-automation symbiosis. Int. J. Comput. Integr. Manuf. 2024, 37, 1426–1443. [Google Scholar] [CrossRef]
- Saleem, M.U.; Shakir, M.; Usman, M.R.; Bajwa, M.H.T.; Shabbir, N.; Shams Ghahfarokhi, P.; Daniel, K. Integrating smart energy management system with internet of things and cloud computing for efficient demand side management in smart grids. Energies 2023, 16, 4835. [Google Scholar] [CrossRef]
- Shaikh, F.K.; Karim, S.; Zeadally, S.; Nebhen, J. Recent trends in internet-of-things-enabled sensor technologies for smart agriculture. IEEE Internet Things J. 2022, 9, 23583–23598. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Timestamp | ||||||||
|---|---|---|---|---|---|---|---|---|
| 2024-11-08 00:00:00 | 0.75 | 0.40 | 0.65 | 0.80 | 0.33 | 0.55 | Normal | 0 |
| 2024-11-08 00:01:00 | 0.77 | 0.38 | 0.68 | 0.82 | 0.32 | 0.56 | Normal | 0 |
| 2024-11-08 00:02:00 | 0.72 | 0.41 | 0.63 | 0.79 | 0.35 | 0.57 | Anomalous | 1 |
| 2024-11-08 00:03:00 | 0.76 | 0.39 | 0.66 | 0.81 | 0.34 | 0.58 | Normal | 0 |
| Device | Manufacturer | CPU | RAM | Power Consumption | Cost |
|---|---|---|---|---|---|
| Raspberry Pi Zero 2 W | Raspberry Pi Foundation, Cambridge, UK | Quad-core 1.0 GHz | 512 MB | Low | Low |
| NVIDIA Jetson Nano | NVIDIA Corporation, Santa Clara, CA, USA | Quad-core 1.43 GHz | 4 GB | Moderate | High |
| Coral Edge TPU | Google, Mountain View, CA, USA | Dual-core Cortex-A53 | 1 GB | Low | Moderate |
| Arduino Nano 33 IoT | Arduino AG, Somerville, MA, USA | ARM Cortex-M0+ | 32 KB | Very Low | Very Low |
| Model | Computational Complexity | Memory Usage | Accuracy |
|---|---|---|---|
| K-Nearest Neighbors (KNNs) | Low | Low | Moderate |
| Decision Tree | Moderate | Moderate | High |
| Support Vector Machine (SVM) | High | High | High |
| Naive Bayes | Low | Very Low | Low |
| Cloud Service | Scalability | Latency | Cost |
|---|---|---|---|
| AWS Lambda | High | Low | High |
| Google Cloud Functions | High | Moderate | Moderate |
| Microsoft Azure Functions | Moderate | Low | Moderate |
| IBM Cloud Functions | Moderate | Moderate | Low |
| Model | Suitability for Time-Series | Computational Complexity | Accuracy |
|---|---|---|---|
| LSTM | High | High | High |
| GRU | Moderate | Moderate | Moderate |
| CNN | Low | High | Moderate |
| RNN | High | Moderate | High |
| Metric | Classification Accuracy (%) | Computational Complexity |
|---|---|---|
| Euclidean Distance | 95.71 | Low |
| Manhattan Distance | 95.72 | Moderate |
| Minkowski Distance (p = 3) | 95.70 | High |
| Window Width (Time Steps) | Classification Accuracy (%) | Processing Time (ms) |
|---|---|---|
| 10 | 93.41 | 100 |
| 20 | 94.86 | 120 |
| 30 | 95.71 | 140 |
| 40 | 95.30 | 160 |
| 50 | 94.90 | 190 |
| Protocol | Latency | Bandwidth Efficiency | Security Features | Limitations |
|---|---|---|---|---|
| MQTT | Low | High | Basic encryption (TLS) | Limited Quality of Service (QoS) in high-traffic networks |
| HTTP | Moderate | Moderate | Robust (HTTPS) | High overhead for frequent small messages |
| WebSocket | Low | Moderate | Basic encryption (TLS) | Susceptible to connection interruptions |
| CoAP | Very Low | High | Basic encryption (DTLS) | Limited scalability for large deployments |
| Sensor | Specifications | Type | Functionality |
|---|---|---|---|
| Vibration Sensor | Range: ±25 g, Frequency: 10 Hz to 1 kHz, Sensitivity: 100 mV/g | Accelerometer | Monitors vibration levels to detect mechanical faults |
| Temperature Sensor | Range: −50 °C to +200 °C, Accuracy: ±0.5 °C | Thermocouple, RTD, Thermistor | Measures temperature to identify overheating and lubrication issues |
| Rotational Speed Sensor | Range: 0 to 10,000 RPM, Accuracy: ±1% | Optical, Magnetic | Monitors rotational speed to ensure safe operation limits |
| Proximity Sensor | Detection Range: Up to 30 mm | Inductive, Capacitive, Ultrasonic | Detects object presence/ absence for positioning and safety |
| Optical Sensor | Range: 10 mm to 2 m, Resolution: 0.01 mm | Photodetector, Infrared | Detects objects, measures distances, verifies positioning |
| Pressure Sensor | Range: 0–500 psi, Accuracy: ±0.25% FS | Piezoresistive, Capacitive | Measures pressure for hydraulic/ pneumatic systems |
| Tension Sensor | Range: 0–1000 N, Accuracy: ±0.5% FS | Strain Gauge | Measures material tension to maintain quality |
| Thickness Sensor | Range: 0–100 mm, Resolution: 0.01 mm | Laser-based, Ultrasonic | Measures thickness in processes like rolling and coating |
| Speed Sensor | Same as Rotational Speed Sensor | Optical, Magnetic | Measures speed of parts in assembly lines for synchronization |
| Load Cell | Range: 0–500 kg, Accuracy: ±0.1% FS | Strain Gauge, Piezoelectric | Measures force/load, commonly for weight measurements |
| Current Sensor | Range: 0–100 A, Accuracy: ±1% | Hall Effect, Shunt Resistor | Monitors electrical current to detect overloads or malfunctions |
| Voltage Sensor | Range: 0–1000 V, Accuracy: ±0.5% | Potential Transformer, Hall Effect | Measures voltage levels for safe operation |
| Feature | Description |
|---|---|
| Input Sequence Length | 30 time steps (sensor data sequences) |
| Input Dimensions | 20 (number of sensor features per time step) |
| LSTM Layers | 2 layers |
| Units per LSTM Layer | 50 units |
| Activation Function | Sigmoid for gates, Tanh for cell states |
| Output Layer | Fully connected layer for regression output |
| Loss Function | Mean Squared Error (MSE) |
| Optimizer | ADAM |
| Learning Rate | 0.001 (initial learning rate) |
| Batch Size | 32 |
| Epochs | 100 |
| Dropout Rate | 0.2 (for regularization to prevent overfitting) |
| Training Data | Historical time-series sensor data |
| Deployment Environment | AWS Lambda |
| Scalability | Automatically scales with AWS Lambda for large datasets |
| Prediction Target | Failure probability within future horizon |
| Metric | Formula | Value |
|---|---|---|
| Accuracy | 95.71% | |
| Precision | 96.79% | |
| Recall | 94.71% | |
| F1-Score | 95.74% |
| Metric | Formula | Value |
|---|---|---|
| Mean Absolute Error (MAE) | 0.12 | |
| Root Mean Squared Error (RMSE) | 0.15 |
| Metric | Description | Value (ms) |
|---|---|---|
| Edge Latency (Detection) | Average time for KNN anomaly detection | 120 |
| Cloud Latency (Prediction) | Average time for LSTM failure prediction | 300 |
| Data Transmission Latency | Average time to transmit data from edge to cloud | 80 |
| End-to-End Latency | Total time for edge detection and cloud prediction | 500 |
| Peak Latency (Under Load) | Max observed latency during high data flow | 600 |
| Latency Reduction (vs. Cloud-only) | Improvement over a cloud-only solution | 35% |
| Metric | Description | Value (J) |
|---|---|---|
| Edge Energy Consumption (Idle) | Baseline energy consumption in idle state | 0.30 |
| Edge Energy Consumption (Detection) | Energy per anomaly detection event (KNN) | 0.45 |
| Cloud Energy Consumption (Prediction) | Energy per failure prediction event (LSTM) | 2.30 |
| Data Transmission Energy | Energy for transmitting data to cloud per event | 0.12 |
| Total Energy Consumption (Edge + Cloud) | Combined energy for detection, transmission, and prediction | 2.87 |
| Energy Reduction (vs. Cloud-only) | Energy savings compared to cloud-only processing | 28% |
| Energy Efficiency (Edge-only Processing) | Energy saved when processing anomalies at edge only | 60% |
| Metric | Description | Value (KB) |
|---|---|---|
| Data per Anomaly | Average data sent to cloud per anomaly detected | 250 |
| Regular Update Data | Data sent periodically to update cloud without anomalies | 50 |
| Peak Data Transfer | Data transferred during peak anomaly events | 800 |
| Data Reduction (vs. Raw Transmission) | Reduction from transmitting only anomalies | 70% |
| Average Bandwidth Usage | Average bandwidth used per operation cycle | 150 |
| Bandwidth Savings (vs. Cloud-only) | Savings from processing data at the edge | 60% |
| Metric | Fog Computing | Proposed Hybrid Framework |
|---|---|---|
| Latency | Very Low (localized processing) | Low (edge anomaly detection, cloud prediction) |
| Scalability | Limited by fog node resources | High (scalable cloud resources) |
| Energy Efficiency | Moderate (fog nodes consume power) | High (edge devices are energy- efficient) |
| Bandwidth Usage | Low (localized processing reduces data transfer) | Low (edge filtering reduces data transfer) |
| Computational Complexity | High (fog nodes handle extensive tasks) | Balanced (edge for lightweight tasks, cloud for heavy analytics) |
| Algorithm | Latency Reduction (%) | Energy Efficiency (%) | Resource Utilization (%) | Scalability |
|---|---|---|---|---|
| Static Partitioning [50] | 15 | 20 | 65 | Moderate |
| Heuristic-Based Approach [51] | 20 | 25 | 70 | High |
| AI-Driven Dynamic [52] | 30 | 35 | 85 | High |
| Multi-Agent Learning (Malcolm) [53] | 28 | 34 | 80 | High |
| SDN-Based Hybrid Load Balancing [54] | 25 | 30 | 75 | High |
| Proposed Algorithm | 35 | 40 | 90 | Very High |
| Scenario | Sensor Count | Data Velocity (MB/s) | Latency (ms) | Energy Efficiency (%) |
|---|---|---|---|---|
| Small Network | 20 | 1 | 500 | 90 |
| Medium Network | 100 | 10 | 600 | 85 |
| Large Network | 500 | 50 | 700 | 80 |
| Very Large Network | 1000 | 100 | 800 | 75 |
| Approach | Latency Reduction (%) | Energy Efficiency (%) | Bandwidth Savings (%) | Scalability |
|---|---|---|---|---|
| Dynamic Deployment Framework [56] | 20 | 25 | 50 | Moderate |
| Jay: Offloading Framework [57] | 30 | 35 | 55 | High |
| Hybrid Federated Edge Learning [58] | 25 | 30 | 60 | High |
| Proposed Edge-Cloud Framework | 35 | 40 | 60 | Very High |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sathupadi, K.; Achar, S.; Bhaskaran, S.V.; Faruqui, N.; Abdullah-Al-Wadud, M.; Uddin, J. Edge-Cloud Synergy for AI-Enhanced Sensor Network Data: A Real-Time Predictive Maintenance Framework. Sensors 2024, 24, 7918. https://doi.org/10.3390/s24247918
Sathupadi K, Achar S, Bhaskaran SV, Faruqui N, Abdullah-Al-Wadud M, Uddin J. Edge-Cloud Synergy for AI-Enhanced Sensor Network Data: A Real-Time Predictive Maintenance Framework. Sensors. 2024; 24(24):7918. https://doi.org/10.3390/s24247918
Chicago/Turabian StyleSathupadi, Kaushik, Sandesh Achar, Shinoy Vengaramkode Bhaskaran, Nuruzzaman Faruqui, M. Abdullah-Al-Wadud, and Jia Uddin. 2024. "Edge-Cloud Synergy for AI-Enhanced Sensor Network Data: A Real-Time Predictive Maintenance Framework" Sensors 24, no. 24: 7918. https://doi.org/10.3390/s24247918
APA StyleSathupadi, K., Achar, S., Bhaskaran, S. V., Faruqui, N., Abdullah-Al-Wadud, M., & Uddin, J. (2024). Edge-Cloud Synergy for AI-Enhanced Sensor Network Data: A Real-Time Predictive Maintenance Framework. Sensors, 24(24), 7918. https://doi.org/10.3390/s24247918