4.1. 2D Garment Recognition
This subsection delves into the experiments conducted using four instance segmentation models (MaskRCNN, YOLACT, SOLOv2, SOLOv2-light) trained on various versions of our collected garment dataset and tested on different test sets emphasizing various features. The underlying expectation was that the custom dataset would enable the models to proficiently recognize garments (t-shirts) and the environment (desk) with diverse attributes. Subsequently, based on the evaluation of segmentation accuracy and inference speed, one model was selected for integration with the SLAM framework. All training and testing processes were performed on an Intel CORE i9 CPU paired with an NVIDIA RTX 3090 laptop GPU (Intel: Santa Clara, CA, USA; NVIDIA: Santa Clara, CA, USA).
The experimental results of models trained on the final dataset v4 emphasize that overall, as shown in
Figure 6 and
Table 3 and
Table 4, SOLOv2, and SOLOv2-light outshine YOLACT and Mask R-CNN in terms of the precision of their masks. Notably, MASK-RCNN displays superior accuracy over the other three models when it comes to scenarios with multiple garments. Especially in situations where the data are unfamiliar—instances of v3mcs that were not included in the training dataset—MASK-RCNN exhibits a slightly stronger generalization ability. However, for single-garment scenarios, or those involving a shift in viewing angle or the addition of the ‘desk’ class, the performance ranks as follows: SOLOv2 >= SOLOv2-light > YOLACT > Mask-RCNN. Interestingly, the overall trend of Recall closely mirrors that of Average Precision (AP). This consistency between recall and precision suggests that the trained models are well-balanced, showing similar tendencies in identifying relevant instances (recall) and correctly labeling instances as relevant (precision). It reflects a situation where the model has a good equilibrium between its ability to find all the relevant instances and its ability to minimize the incorrect classification of irrelevant instances, thus demonstrating both effective and reliable performance.
Comparisons of models’ mask precision throughout the addition of new training data, as illustrated in
Figure 7,
Figure 8,
Figure 9 and
Figure 10, demonstrate that generally, the expansion of the dataset improves models’ performances. Distinctly, the addition of v4’s new data led to a decrease in the accuracy of YOLACT’s recognition of the v3m dataset. This could be because YOLACT was ‘overfitting’ to multiple objects with similar sizes. On another note, YOLACT has better precision on untrained data type, e.g., tested on v4sd when only trained on v3, which implies that it has better generalization capabilities.
Examples of visualized estimated masks are demonstrated in
Table 5 and
Table 6. It is worth noting that, while SOLOv2 demonstrates satisfactory performance in recognizing and distinguishing multiple objects such as tables and clothing, it faces difficulties in identifying multiple pieces of clothing. Although it maintains the highest mask margin precision for all the test sets, which corresponds to the high AP evaluated, SOLOv2 struggles to tell different garments apart. This may be attributed to its nature as a location-based one-stage method, thereby limiting its capacity to discern multiple similar objects like garments. On the other hand, while YOLACT performs nicely on distinguishing multiple garments, it sometimes struggles with mask boundaries when garments are touching.
The models were also tested with a sequence of RGB images of resolution 1280 × 720, recorded by an Intel Realsense D435i camera. The camera’s movements were designed to imitate the motion needed to scan the environment, with the operating desk and garments roughly in the center of view. This mimics a real-world scenario, creating conditions for our models that reflect those they would encounter in practical applications. Example results are as presented in
Table 6. Mask-RCNN faces challenges in recognizing the desk, and the masks of garments lack precision as with the dataset. YOLACT, on the other hand, demonstrates an ability to accurately segment both the garments and the desk, despite occasional difficulties with an edge of the desk. SOLOv2 and SOLOv2-light present the most accurate desk masks, but they still struggle to differentiate between separate garments.
Furthermore, the models are tested directly using an Intel Realsense D435i camera to run in real-time. Input RGB frames are with sizes of 1280 × 720. The example results are as presented in
Table 6. The performances are similar to those of the recorded videos. YOLACT demonstrates a superior balance in the precision of mask margins and the differentiation of individual garments. Interestingly, YOLACT, SOLOv2, and SOLOv2-light are capable of detecting the partially visible second desk in the frame, even though such situations were not included in the training set. However, only YOLACT correctly identifies it as a separate desk; SOLOv2 and SOLOv2-light struggle to differentiate between individual objects and incorrectly perceive it as part of the central desk.
In the context of speed, SOLOv2-light leads the pack for recorded videos, while YOLACT emerges as the fastest when tested with camera real-time, as demonstrated in
Table 7.
In summary, the performance of the models can be ranked differently depending on the scenario at hand, as follows:
Single t-shirt. For the detection of a single clothing item, the models are ranked based on mask precision as follows: SOLOv2 >= SOLOv2-light > YOLACT > Mask-RCNN. The primary distinction in this scenario is the accuracy of mask edges.
Multiple t-shirts. When it comes to detecting multiple clothing items, the rankings shift to: Mask-RCNN > YOLACT >> SOLOv2-light >= SOLOv2, the main distinction lying in the models’ ability to differentiate between different pieces of clothing. Notably, even though SOLOv2 and SOLOv2-light yield the most accurate masks among the four models, in most cases, they struggle to distinguish different t-shirt pieces. This discrepancy may contribute to their higher rankings when only considering mask precision on the v3m test set, where the ranking is Mask-RCNN > SOLOv2 > SOLOv2-light > YOLACT.
Shifting view angle. In the context of recognizing objects from various angles and identifying desks, the ranking shifts to SOLOv2-light >= SOLOv2 > YOLACT > Mask-RCNN.
Reference speed. Finally, in terms of inference speed, SOLOv2-light and YOLACT are the fastest, trailed by Mask-RCNN and SOLOv2.
Considering all the results, YOLACT stands out as the model that strikes a good balance in all categories and performs commendably across all the tested scenarios. Hence, YOLACT was chosen for further experimentation and SLAM integration.
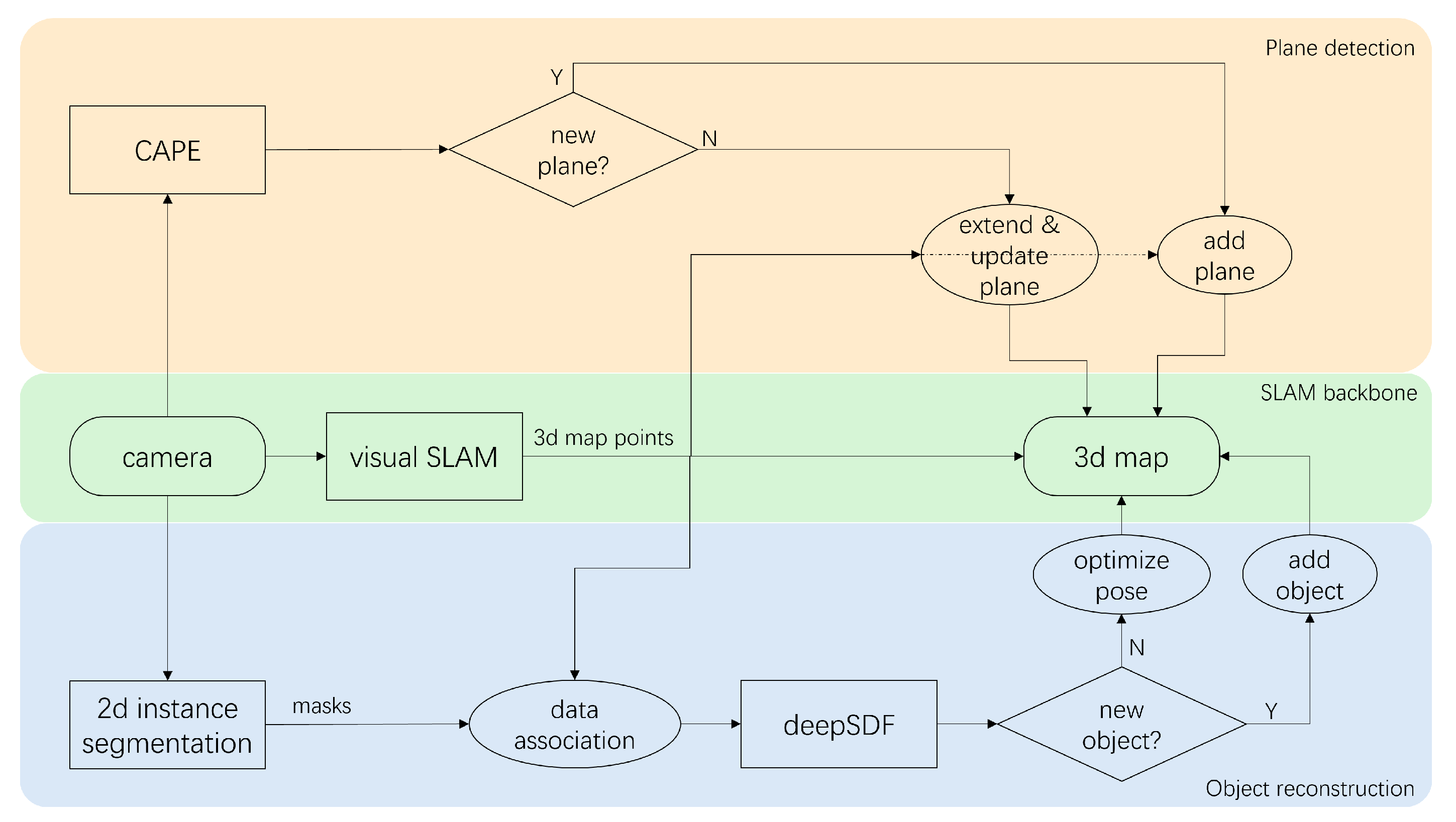
4.3. SLAM Integration
This subsection provides an overview of the experiments conducted on open-source datasets and real-time data, respectively, to test the feasibility of this integrated SLAM approach. To highlight the impact of integrated plane detection and object reconstruction functions on our system, tests were carried out on versions of the SLAM system: one that integrates only the object reconstruction, and another one that integrates only the plane detection. We will compare and contrast these results to provide a view of the different systems’ performances.
Firstly, only the object reconstruction component was introduced into the SLAM system (akin to DSP-SLAM). Utilizing a MaskRCNN model trained on the COCO dataset [
32] (Common Objects in Context), tests were conducted and object reconstruction was performed on the Redwood dataset [
33]. The camera trajectory error was then evaluated on the KITTI dataset [
34]. A Relative Translation Error (RTE) and a Relative Rotation Error (RRE) of 1.41 and 0.22 were achieved, which unfortunately could not outperform ORB-SLAM2’s 1.38 and 0.20.
Subsequently, only the plane detection component was integrated into the SLAM system and comparisons were carried out with ORBSLAM2 using the TUM dataset [
35]. On the sequence fr3_cabinet where ORB-SLAM failed to track due to insufficiency of feature points, integrating the plane thread achieved an absolute trajectory error (ATE) of 0.0202.
The SLAM systems were then tested using an Intel Realsense D435i camera as the input sensor capturing RGB and depth images with a size of 680 × 480. The systems ran on a laptop with an Intel i9 CPU and an NVIDIA RTX 3090 Laptop GPU. The results show that this SLAM-based approach could successfully detect and reconstruct the garments and large environmental planes, as presented in
Table 10. However, several challenges are evident: the quality of reconstruction and the execution speed. The reconstructed garments do not always accurately represent their real-world counterparts, and penetrations still occasionally occur. This could be attributed to both the reconstruction loss function and the mesh dataset. Regarding the speed, a decrease can be observed with the addition of each detection model, as demonstrated in
Table 11. Thus, an improved strategy for computing is necessary.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












































































