
Pedestrian Re-Identification Based on Fine-Grained Feature Learning and Fusion

Abstract
1. Introduction
- We propose a novel multimodal fine-grained feature-learning and fusion model for video-based pedestrian re-identification, which exploits both the appearance and motion features to learn a more comprehensive representation. To the best of our knowledge, this is the first attempt to combine fine-grained appearance and motion features for pedestrian Re-ID;
- We design a token-level alignment to learn discriminative and important information from different modalities of the features, and then the inter-modal relation is learned by a cross-attention method to fuse the different modalities of features;
- We conduct extensive experiments on three benchmark datasets to evaluate the performance of the proposed method, and all the evaluation metrices of mAP and Rank-K are improved by more than 0.4 percentage points.
2. Related Works
2.1. Uni-Modal Feature-Based Approaches
2.2. Multimodal Feature-Based Approaches
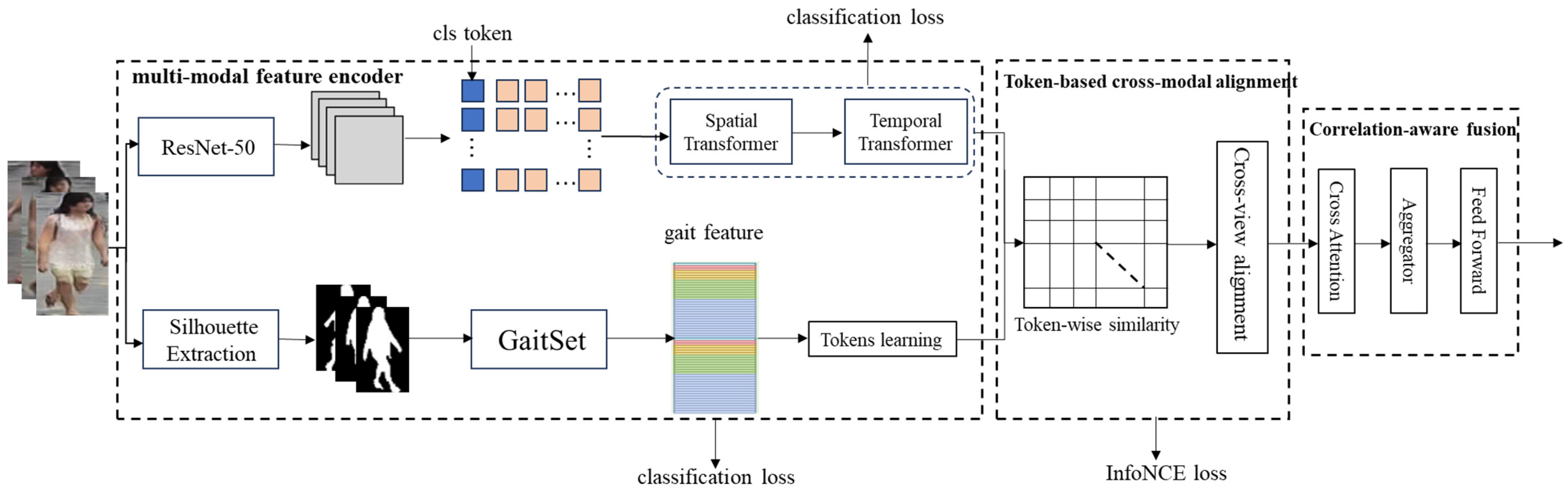
3. Proposed Model
3.1. Overview
3.2. Multimodal Feature Encoder
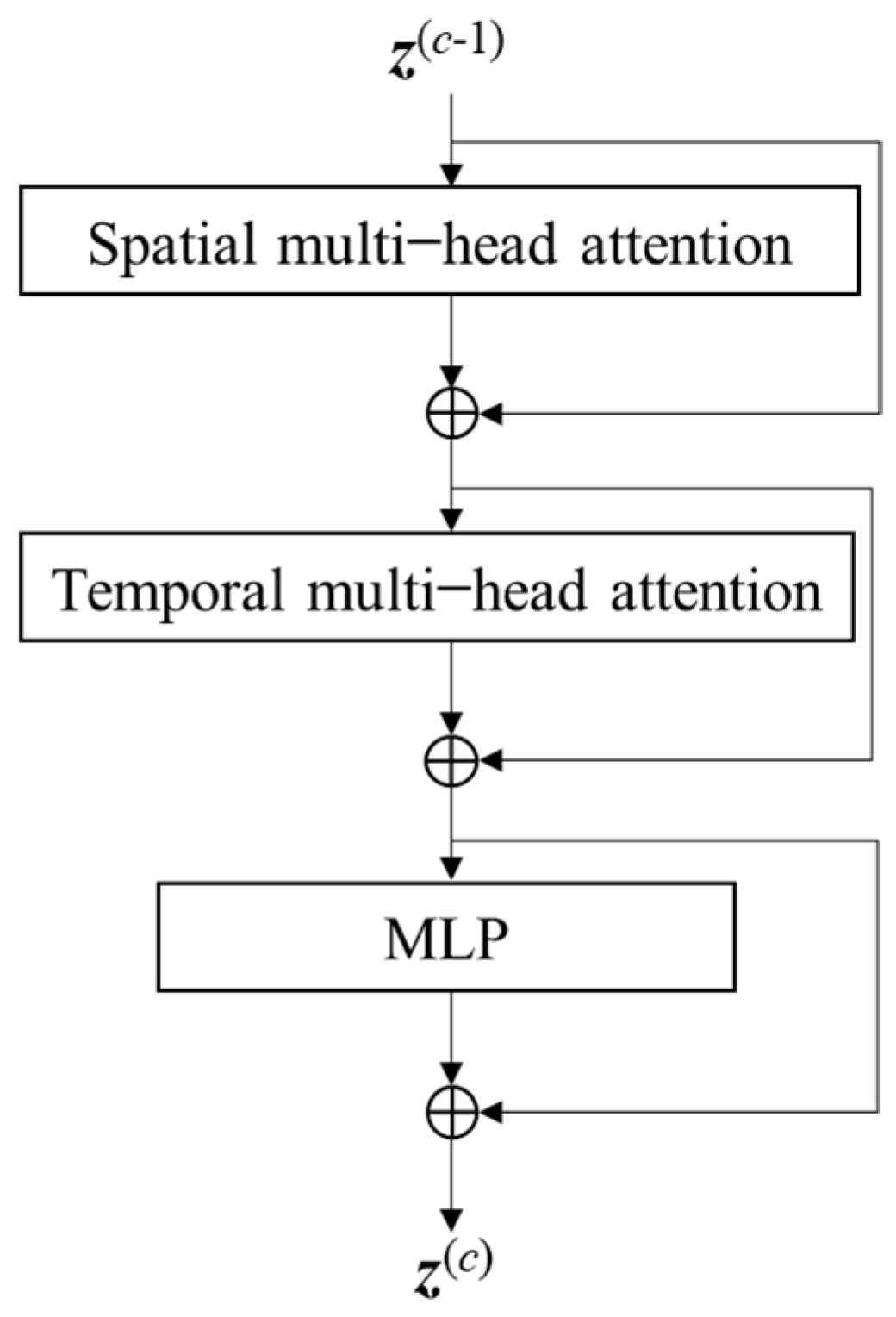
3.2.1. Visual Appearance Token Learning
- Spatial Attention
- 2.
- Temporal Attention
- 3.
- Classification Loss
3.2.2. Gait Token Learning
3.3. Token-Based Cross-Modal Alignment
3.4. Correlation-Aware Fusion
3.5. Pedestrian Re-ID
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Experiment Configuration
4.3. Comparison Result

{kind=link}
{kind=link}
{kind=link}
| Models | MARS | iLIDS-VID | PRID2011 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | |
| Snippet [34] | 76.1 | 86.3 | 94.7 | 98.2 | 85.4 | 96.7 | 99.5 | 93.0 | 99.3 | 100 |
| STAN [4] | 65.8 | 82.3 | - | - | 80.2 | - | - | 93.2 | - | - |
| STMP [9] | 72.7 | 84.4 | 93.2 | 96.3 | 84.3 | 96.8 | 99.5 | 92.7 | 98.8 | 99.8 |
| M3D [13] | 74.0 | 84.3 | 93.8 | 97.7 | 74.0 | 94.3 | - | 94.4 | 100 | - |
| Attribute [7] | 78.2 | 87.0 | 95.4 | 98.7 | 86.3 | 87.4 | 99.7 | 93.9 | 99.5 | 100 |
| PGANet [44] | 81.3 | 87.2 | 94.5 | 96.1 | 82.2 | 94.2 | 99.3 | |||
| VRSTC [35] | 82.3 | 88.5 | 96.5 | 97.4 | 83.4 | 95.5 | 99.5 | - | - | - |
| GLTR [36] | 78.5 | 87.0 | 95.8 | 98.2 | 86.0 | 98.0 | - | 95.5 | 100 | - |
| COSAM [37] | 79.9 | 84.9 | 95.5 | 97.9 | 79.6 | 95.3 | - | - | - | - |
| MGRA [6] | 85.9 | 88.8 | 97.0 | 98.5 | 88.6 | 98.0 | 99.7 | 95.9 | 99.7 | 100 |
| STGCN [38] | 83.7 | 89.9 | - | - | - | - | - | - | - | - |
| AFA [39] | 82.9 | 90.2 | 96.6 | - | 88.5 | 96.8 | 99.7 | - | - | - |
| TCLNet [11] | 85.1 | 89.8 | - | - | 86.6 | - | - | - | - | - |
| GRL [40] | 84.8 | 91.0 | 96.7 | 98.4 | 90.4 | 98.3 | 99.8 | 96.2 | 99.7 | 100 |
| MTV [55] | 85.8 | 91.1 | 96.9 | 98.7 | 90.9 | 98.2 | 99.8 | 96.0 | 99.5 | 100 |
| TMT [31] | 85.8 | 91.2 | 97.3 | 98.8 | 91.3 | 98.6 | 100 | 96.4 | 99.3 | 100 |
| DCCT [32] | 86.3 | 91.5 | 97.4 | 98.6 | 91.7 | 98.6 | - | 96.8 | 99.7 | - |
| MTLA (Ours) | 86.7 | 91.9 | 98.0 | 98.7 | 91.9 | 98.6 | 100 | 97.0 | 99.6 | 100 |
4.4. Ablation Experiments
4.5. Parameter Sensitivity
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, T.; Xie, L.; Wei, L.; Zhang, Y.; Li, B.; Tian, Q. Single camera training for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12878–12885. [Google Scholar]
- Li, J.; Zhang, S. Joint visual and temporal consistency for unsupervised domain adaptive person re-identification. In Proceedings of the European Conference on Computer Vision, online, 23–28 August 2020; pp. 483–499. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the International Conference on Computer Vision, Workshop on Cross-Domain Human Identification (CHI), Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Li, S.; Bak, S.; Carr, P.; Wang, X. Diversity regularized spatiotemporal attention for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Wellington, New Zealand, 18–22 June 2018; pp. 369–378. [Google Scholar]
- Fu, Y.; Wang, X.; Wei, Y.; Huang, T. Sta: Spatial-temporal attention for large-scale video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Hawaii, HI, USA, 27–31 January 2019; pp. 8287–8294. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Multi-granularity reference-aided attentive feature aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10407–10416. [Google Scholar]
- McLaughlin, N.; Rincon, J.; Miller, P. Recurrent convolutional network for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 1325–1334. [Google Scholar]
- Liu, Y.; Yuan, Z.; Zhou, W.; Li, H. Spatial and temporal mutual promotion for video-based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Hawaii, HI, USA, 27–31 January 2019; pp. 8786–8793. [Google Scholar]
- Li, J.; Zhang, S.; Huang, T. Multiscale 3d convolution network for video-based person reidentification. In Proceedings of the AAAI Conference on Artificial Intelligence, Hawaii, HI, USA, 27–31 January 2019; pp. 8618–8625. [Google Scholar]
- Liu, X.; Zhang, P.; Yu, C.; Lu, H.; Qian, X.; Yang, X. A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification. IEEE Trans. Intell. Transp. Syst. 2024, 25, 12818–12828. [Google Scholar] [CrossRef]
- Gong, X.; Luo, B. Video-based person re-identification with scene and person attributes. Multimed. Tools Appl. 2024, 83, 8117–8128. [Google Scholar] [CrossRef]
- Yang, Y.; Hospedales, T.M. A Unified Perspective on Multi-Domain and Multi-Task Learning. arXiv 2014, arXiv:1412.7489. [Google Scholar]
- Huang, F.; Zhang, X.; Xu Jie Zhao, Z.; Li, Z. Multimodal Learning of Social Image Representation by Exploiting Social Relations. IEEE Trans. Cybern. 2021, 51, 1506–1518. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, X.; Arnab, A.; Lu, Z.; Zhang, M.; Sun, C.; Schmid, C. Multiview Transformers for Video Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 3323–3333. [Google Scholar]
- Sun, J.; Xiu, X.; Luo, Z.; Liu, W. Learning High-Order Multi-View Representation by New Tensor Canonical Correlation Analysis. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5645–5654. [Google Scholar] [CrossRef]
- Han, L.; Zhang, X.; Zhang, L.; Lu, M.; Huang, F.; Liu, Y. Unveiling hierarchical relationships for social image representation learning. Appl. Soft Comput. 2023, 147, 110792. [Google Scholar] [CrossRef]
- Hazarika, D.; Zimmermann, R.; Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Zhang, L.; Zhang, X.; Pan, J. Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–28 February 2022; pp. 11676–11684. [Google Scholar]
- Han, W.; Chen, H.; Poria, S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9180–9192. [Google Scholar]
- Lu, Q.; Sun, X.; Gao, Z.; Long, Y.; Feng, J.; Zhang, H. Coordinated-joint translation fusion framework with sentiment-interactive graph convolutional networks for multimodal sentiment analysis. Inf. Process. Manag. 2024, 61, 103538. [Google Scholar] [CrossRef]
- Wang, L.; Peng, J.; Zheng, C.; Zhao, T. A cross modal hierarchical fusion multimodal sentiment analysis method based on multi-task learning. Inf. Process. Manag. 2024, 61, 103675. [Google Scholar] [CrossRef]
- Lin, Z.; Liang, B.; Long, Y.; Dang, Y.; Yang, M.; Zhang, M.; Xu, R. Modeling intra-and inter-modal relations: Hierarchical graph contrastive learning for multimodal sentiment analysis. In Proceedings of the 29th International Conference on Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 7124–7135. [Google Scholar]
- Dai, J.; Zhang, P.; Wang, D.; Lu, H.; Wang, H. Video person re-identification by temporal residual learning. IEEE Trans. Image Process. 2019, 28, 1366–1377. [Google Scholar] [CrossRef]
- Gu, X.; Chang, H.; Ma, B.; Zhang, H.; Chen, X. Appearance-preserving 3d convolution for video-based person re-identification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 228–243. [Google Scholar]
- Chen, D.; Li, H.; Xiao, T.; Yi, S.; Wang, X. Video person re-identification with compet-itive snippet-similarity aggregation and co-attentive snippet embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1169–1178. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Vrstc: Occlusion-free video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7183–7192. [Google Scholar]
- Zhao, Y.; Shen, X.; Jin, Z.; Lu, H.; Hua, X.-S. Attribute-driven feature disentangling and temporal aggregation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4913–4922. [Google Scholar]
- Subramaniam, A.; Nambiar, A.; Mittal, A. Co-segmentation inspired attention networks for video-based person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korean, 27–31 October 2019; pp. 562–572. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Temporal complementary learning for video person re-identification. In Proceedings of the European Conference on Computer Vision, online, 23–28 August 2020; pp. 388–405. [Google Scholar]
- Chen, G.; Rao, Y.; Lu, J.; Zhou, J. Temporal coherence or temporal motion: Which is more critical for video-based person re-identification? In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 660–676. [Google Scholar]
- Li, J.; Wang, J.; Tian, Q.; Gao, W.; Zhang, S. Global-local temporal representations for video per-son re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korean, 27–31 October 2019; pp. 3958–3967. [Google Scholar]
- Wang, K.; Ding, C.; Pang, J.; Xu, X. Context sensing attention network for video-based person re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 4, 19. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Meng, L.; Li, H.; Chen, B.C.; Lan, S.; Wu, Z.; Jiang, Y.G.; Lim, S.N. Adavit: Adaptive vision transformers for efficient image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Louisiana, LA, USA, 19–24 June 2022; pp. 12309–12318. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 347–356. [Google Scholar]
- Zheng, Y.; Jiang, W.; Huang, Y. Evaluation of Vision Transformers for Traffic Sign Classification. Wirel. Commun. Mob. Comput. 2022, 3041117. [Google Scholar] [CrossRef]
- He, Z.; Zhao, H.; Feng, W. PGGANet: Pose Guided Graph Attention Network for Person Re-identification. arXiv 2022, arXiv:2111.14411v2. [Google Scholar]
- Liu, X.; Yu, C.; Zhang, P.; Lu, H. Deeply Coupled Convolution–Transformer with Spatial–Temporal Complementary Learning for Video-Based Person Re-Identification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 13753–13763. [Google Scholar] [CrossRef]
- Tang, Z.; Zhang, R.; Peng, Z.; Chen, J.; Lin, L. Multi-Stage Spatio-Temporal Aggregation Transformer for Video Person Re-identification. IEEE Trans. Multimed. 2023, 25, 7917–7929. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Wang, Z.; Wang, L.; Wu, T.; Li, T.; Wu, G. Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding. arXiv 2021, arXiv:2109.04872. [Google Scholar] [CrossRef]
- Yuan, X.; Lin, Z.; Kuen, J.; Zhang, J.; Wang, Y.; Maire, M.; Kale, A.; Faieta, B. Multimodal contrastive training for visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021; pp. 6995–7004. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. Mine: Mutual information neural estimation. arXiv 2018, arXiv:1801.04062. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ba, L.J.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Iwamura, M.; Mori, S.; Nakamura, K.; Tanoue, T.; Yagi, Y. Individuality-Preserving Silhouette Extraction for Gait Recognition and Its Speedup. IEICE Trans. Inf. Syst. 2021, 104, 992–1001. [Google Scholar] [CrossRef]
- Chao, H.; Wang, K.; He, Y.; Zhang, J.; Feng, J. GaitSet: Cross-View Gait Recognition Through Utilizing Gait As a Deep Set. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Zang, X.; Li, G.; Gao, W. Multidirection and Multiscale Pyramid in Transformer for Video-Based Pedestrian Retrieval. IEEE Trans. Ind. Inform. 2022, 18, 8776–8785. [Google Scholar] [CrossRef]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person re-identification by video ranking. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 12–16 September 2014; pp. 688–703. [Google Scholar]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 12–14 May 2011; pp. 91–102. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 868–884. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Liu, X.; Zhang, P.; Yu, C.; Lu, H.; Yang, X. Watching you: Global-guided reciprocal learning for video-based person re-identification. arXiv 2021, arXiv:2103.04337. [Google Scholar]
- Yang, J.; Zheng, W.S.; Yang, Q.; Chen, Y.C.; Tian, Q. Spatial-temporal graph convolutional networkfor video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3289–3299. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, C.W.; Wu, J.; Zheng, Y.; Pan, P.; Hua, X.S. Token embeddings alignment for cross-modal retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 4555–4563. [Google Scholar]

| Dataset | # Tracklets | # Identities |
|---|---|---|
| iLIDS-VID | 600 | 300 |
| PRID-2011 | 400 | 200 |
| MARS | 20,478 | 1261 |
| Ablation Models | Definition |
|---|---|
| MTLA-loss | MTLA without the classification loss of the spatial and temporal transformer |
| MTLA-fusion | The multimodal tokens are concatenated directly without the correlation-aware fusion process |
| MTLA-align | The multimodal tokens are directly fed to the correlation-aware fusion procedure without alignment |
| MTLA-token | MTLA without the token-learning procedure, and the multimodal features learned by transform and GaitSet are directly fused for pedestrian Re-ID |
| MTLA + aug | Perform data augmentation before training |
| Models | MARS | iLIDS-VID | PRID2011 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | |
| MTLA-loss | 85.6 | 89.2 | 96.4 | 97.9 | 91.0 | 98.2 | 99.7 | 96.0 | 99.3 | 100 |
| MTLA-fusion | 86.1 | 90.9 | 97.1 | 98.1 | 90.6 | 98.1 | 99.8 | 96.3 | 99.4 | 100 |
| MTLA-align | 86.0 | 90.1 | 96.6 | 98.0 | 90.4 | 97.6 | 98.6 | 95.9 | 98.8 | 99.6 |
| MTLA-token | 84.5 | 88.6 | 95.2 | 97.8 | 89.3 | 95.9 | 99.1 | 93.2 | 97.1 | 99.2 |
| MTLA + aug | 86.8 | 91.9 | 98.2 | 98.7 | 92.0 | 98.6 | 100 | 97.0 | 99.7 | 100 |
| MTLA | 86.7 | 91.9 | 98.0 | 98.7 | 91.9 | 98.6 | 100 | 97.0 | 99.6 | 100 |
| Models | MARS | iLIDS-VID | PRID2011 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | |
| Length = 6 | 85.9 | 91.2 | 96.9 | 98.1 | 90.8 | 97.6 | 99.8 | 95.5 | 99.1 | 99.9 |
| Length = 8 | 86.7 | 91.9 | 98.0 | 98.7 | 91.9 | 98.6 | 100 | 97.0 | 99.6 | 100 |
| Length = 10 | 86.2 | 91.3 | 97.7 | 98.4 | 91.4 | 98.3 | 99.8 | 96.3 | 99.6 | 100 |
| Length = 12 | 85.3 | 90.5 | 96.5 | 97.6 | 90.5 | 97.5 | 99.9 | 96.4 | 99.3 | 99.7 |
| Models | MARS | iLIDS-VID | PRID2011 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | Rank 1 | Rank 5 | Rank 20 | |
| Depth = 2 | 86.7 | 91.9 | 98.0 | 98.7 | 91.9 | 98.6 | 100 | 97.0 | 99.6 | 100 |
| Depth = 4 | 86.3 | 91.5 | 97.5 | 98.3 | 91.5 | 98.5 | 100 | 96.4 | 99.1 | 99.9 |
| Depth = 6 | 86.1 | 91.0 | 97.1 | 98.0 | 91.1 | 98.0 | 99.8 | 95.9 | 98.7 | 99.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.; Liu, W. Pedestrian Re-Identification Based on Fine-Grained Feature Learning and Fusion. Sensors 2024, 24, 7536. https://doi.org/10.3390/s24237536
Chen A, Liu W. Pedestrian Re-Identification Based on Fine-Grained Feature Learning and Fusion. Sensors. 2024; 24(23):7536. https://doi.org/10.3390/s24237536
Chicago/Turabian StyleChen, Anming, and Weiqiang Liu. 2024. "Pedestrian Re-Identification Based on Fine-Grained Feature Learning and Fusion" Sensors 24, no. 23: 7536. https://doi.org/10.3390/s24237536
APA StyleChen, A., & Liu, W. (2024). Pedestrian Re-Identification Based on Fine-Grained Feature Learning and Fusion. Sensors, 24(23), 7536. https://doi.org/10.3390/s24237536