
A Comparison Between Single-Stage and Two-Stage 3D Tracking Algorithms for Greenhouse Robotics


Abstract
1. Introduction
2. Materials and Methods
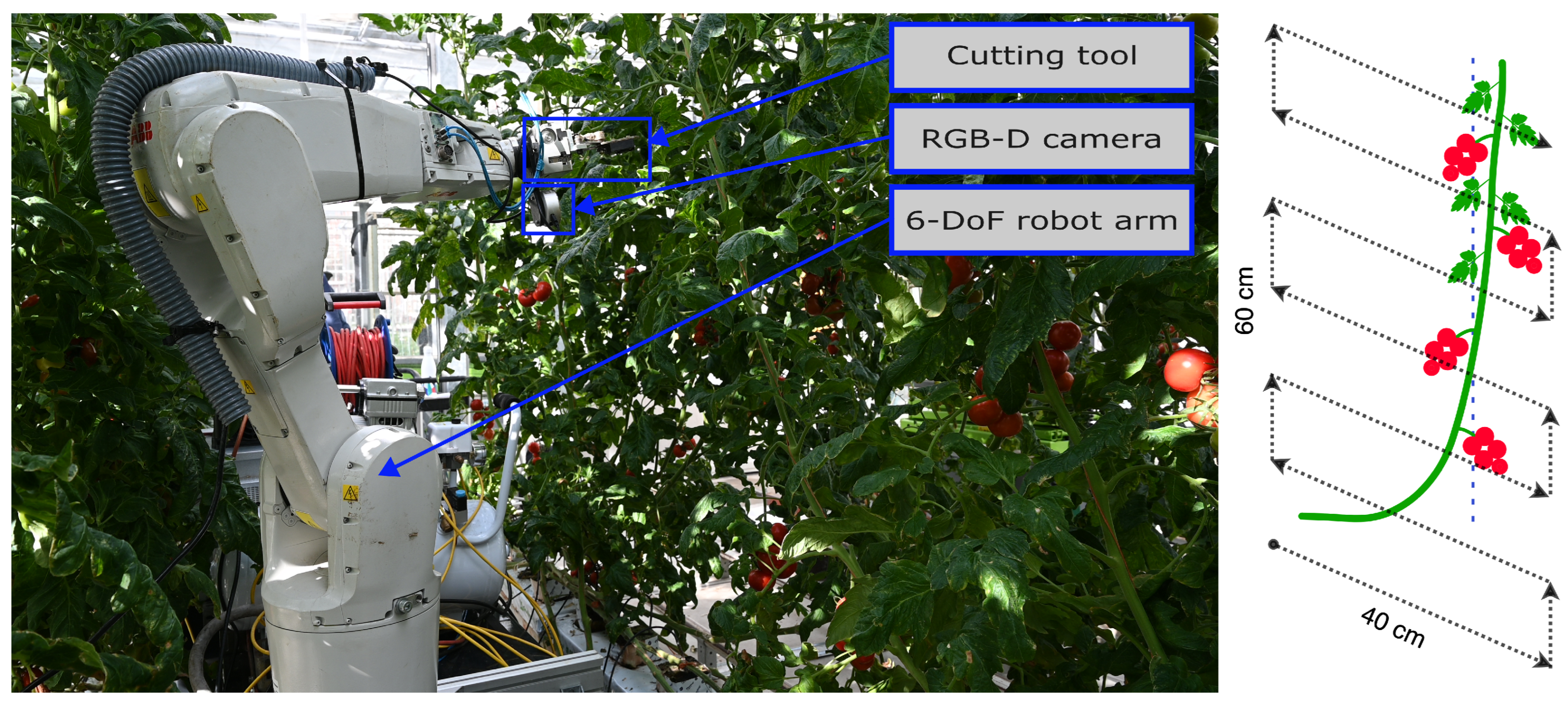
2.1. Data
2.2. Algorithms
2.3. Experiments
- Sort. For our test set, we used the available two sequences of 600 frames at two distances from the plant. For each sequence, 100 random viewpoints were randomly selected and sequentially ordered with the goal of minimizing frame-to-frame distance. The resulting sequence is similar to a video sequence with a low frame rate.
- Random. A total of 100 viewpoints were also selected out of the pool of viewpoints per sequence and plant. However, they were left unordered, which resulted in a sequence where jumps between frames were large and inconsistent, and objects were occluded during multiple frames.
- AP. Active perception improves the capacity of robots to deal with occlusions in unknown environments like tomato greenhouses [5]. Therefore, we studied the performance of our algorithm when 100 viewpoints were selected out of the pool of viewpoints using the AP algorithm developed by [5] that maximizes information gain between viewpoints. This method requires the definition of a region-of-interest (RoI). For this experiment, the region of interest was defined as a rectangular volume, approximately set around the middle-front of the robot where the stem of the tomato plant was expected.
3. Results and Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Active perception |
| AssA | Association Accuracy |
| DetA | Detection Accuracy |
| FoV | Field of view |
| HOTA | High Order Tracking Accuracy |
| IDSW | ID Switches |
| MOT | Multi-object tracking |
| MOTA | Multi-Object Tracking Accuracy |
| re-ID | re-identification |
| RoI | Region of interest |
References
- Kootstra, G.; Wang, X.; Blok, P.M.; Hemming, J.; van Henten, E. Selective Harvesting Robotics: Current Research, Trends, and Future Directions. Curr. Robot. Rep. 2021, 2, 95–104. [Google Scholar] [CrossRef]
- Crowley, J. Dynamic world modeling for an intelligent mobile robot using a rotating ultra-sonic ranging device. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 128–135. [Google Scholar] [CrossRef]
- Elfring, J.; van den Dries, S.; van de Molengraft, M.; Steinbuch, M. Semantic world modeling using probabilistic multiple hypothesis anchoring. Robot. Auton. Syst. 2013, 61, 95–105. [Google Scholar] [CrossRef]
- Arad, B.; Balendonck, J.; Barth, R.; Ben-Shahar, O.; Edan, Y.; Hellström, T.; Hemming, J.; Kurtser, P.; Ringdahl, O.; Tielen, T.; et al. Development of a sweet pepper harvesting robot. J. Field Robot. 2020, 37, 1027–1039. [Google Scholar] [CrossRef]
- Burusa, A.K.; Scholten, J.; Rincon, D.R.; Wang, X.; van Henten, E.J.; Kootstra, G. Semantics-Aware Next-best-view Planning for Efficient Search and Detection of Task-relevant Plant Parts. arXiv 2024, arXiv:2306.09801. [Google Scholar] [CrossRef]
- Persson, A.; Martires, P.Z.D.; Loutfi, A.; De Raedt, L. Semantic Relational Object Tracking. IEEE Trans. Cogn. Dev. Syst. 2020, 12, 84–97. [Google Scholar] [CrossRef]
- Rapado-Rincón, D.; van Henten, E.J.; Kootstra, G. Development and evaluation of automated localisation and reconstruction of all fruits on tomato plants in a greenhouse based on multi-view perception and 3D multi-object tracking. Biosyst. Eng. 2023, 231, 78–91. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649, ISSN 2381-8549. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Halstead, M.; McCool, C.; Denman, S.; Perez, T.; Fookes, C. Fruit Quantity and Ripeness Estimation Using a Robotic Vision System. IEEE Robot. Autom. Lett. 2018, 3, 2995–3002. [Google Scholar] [CrossRef]
- Kirk, R.; Mangan, M.; Cielniak, G. Robust Counting of Soft Fruit Through Occlusions with Re-identification. In Proceedings of the Computer Vision Systems, Virtual, 22–24 September 2021; pp. 211–222. [Google Scholar] [CrossRef]
- Halstead, M.; Ahmadi, A.; Smitt, C.; Schmittmann, O.; McCool, C. Crop Agnostic Monitoring Driven by Deep Learning. Front. Plant Sci. 2021, 12, 786702. [Google Scholar] [CrossRef]
- Hu, N.; Su, D.; Wang, S.; Nyamsuren, P.; Qiao, Y. LettuceTrack: Detection and tracking of lettuce for robotic precision spray in agriculture. Front. Plant Sci. 2022, 13, 1003243. [Google Scholar] [CrossRef] [PubMed]
- Villacrés, J.; Viscaino, M.; Delpiano, J.; Vougioukas, S.; Auat Cheein, F. Apple orchard production estimation using deep learning strategies: A comparison of tracking-by-detection algorithms. Comput. Electron. Agric. 2023, 204, 107513. [Google Scholar] [CrossRef]
- Rapado-Rincón, D.; van Henten, E.J.; Kootstra, G. MinkSORT: A 3D deep feature extractor using sparse convolutions to improve 3D multi-object tracking in greenhouse tomato plants. Biosyst. Eng. 2023, 236, 193–200. [Google Scholar] [CrossRef]
- Rapado-Rincon, D.; Nap, H.; Smolenova, K.; van Henten, E.J.; Kootstra, G. MOT-DETR: 3D single shot detection and tracking with transformers to build 3D representations for agro-food robots. Comput. Electron. Agric. 2024, 225, 109275. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 14 November 2024).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar] [CrossRef]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. HOTA: A Higher Order Metric for Evaluating Multi-object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef] [PubMed]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Type | Split | # Plants | # Viewpoints |
|---|---|---|---|
| Real | Train/Validation | 4 | 3570/630 |
| Test | 1 | 1200 |
| Sequence | Algorithm | HOTA↑ | DetA↑ | AssA↑ | LocA↑ | MOTA↑ | IDSW↓ |
|---|---|---|---|---|---|---|---|
| Sort | 3D-SORT | 52.45 | 65.59 | 42.13 | 92.79 | 65.95 | 41.8 |
| MOT-DETR | 60.4 | 56.3 | 65.17 | 79.17 | 70.38 | 23.8 | |
| Random | 3D-SORT | 33.37 | 66.17 | 16.92 | 92.81 | 46.24 | 200.2 |
| MOT-DETR | 59.63 | 56.32 | 63.44 | 79.14 | 66.86 | 57.4 | |
| AP | 3D-SORT | 63.99 | 79.89 | 52.08 | 93.21 | 76.95 | 84.2 |
| MOT-DETR | 71.66 | 66.08 | 78.58 | 80.16 | 88.09 | 4.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rapado-Rincon, D.; Burusa, A.K.; van Henten, E.J.; Kootstra, G. A Comparison Between Single-Stage and Two-Stage 3D Tracking Algorithms for Greenhouse Robotics. Sensors 2024, 24, 7332. https://doi.org/10.3390/s24227332
Rapado-Rincon D, Burusa AK, van Henten EJ, Kootstra G. A Comparison Between Single-Stage and Two-Stage 3D Tracking Algorithms for Greenhouse Robotics. Sensors. 2024; 24(22):7332. https://doi.org/10.3390/s24227332
Chicago/Turabian StyleRapado-Rincon, David, Akshay K. Burusa, Eldert J. van Henten, and Gert Kootstra. 2024. "A Comparison Between Single-Stage and Two-Stage 3D Tracking Algorithms for Greenhouse Robotics" Sensors 24, no. 22: 7332. https://doi.org/10.3390/s24227332
APA StyleRapado-Rincon, D., Burusa, A. K., van Henten, E. J., & Kootstra, G. (2024). A Comparison Between Single-Stage and Two-Stage 3D Tracking Algorithms for Greenhouse Robotics. Sensors, 24(22), 7332. https://doi.org/10.3390/s24227332