
A Refined and Efficient CNN Algorithm for Remote Sensing Object Detection


Abstract
1. Introduction
- (1)
- The refined and efficient module (REM) and RE_CSP block are proposed, enabling effective multi-scale feature extraction with minimal computational cost. Furthermore, RENet, constructed by stacking RE_CSP blocks, serves as the backbone network, offering strong feature-extraction capabilities. Experimental results demonstrate that the proposed method outperforms other state-of-the-art methods in detection performance.
- (2)
- To facilitate the fusion of multi-scale hierarchical and spatial features, a spatial extracted attention module (SEAM) is designed to establish long-range dependencies. It can be effectively combined with the RE_CSP block to generate attention maps that promote representative feature learning and capture richer semantic information, further improving the model’s performance in detecting small targets.
- (3)
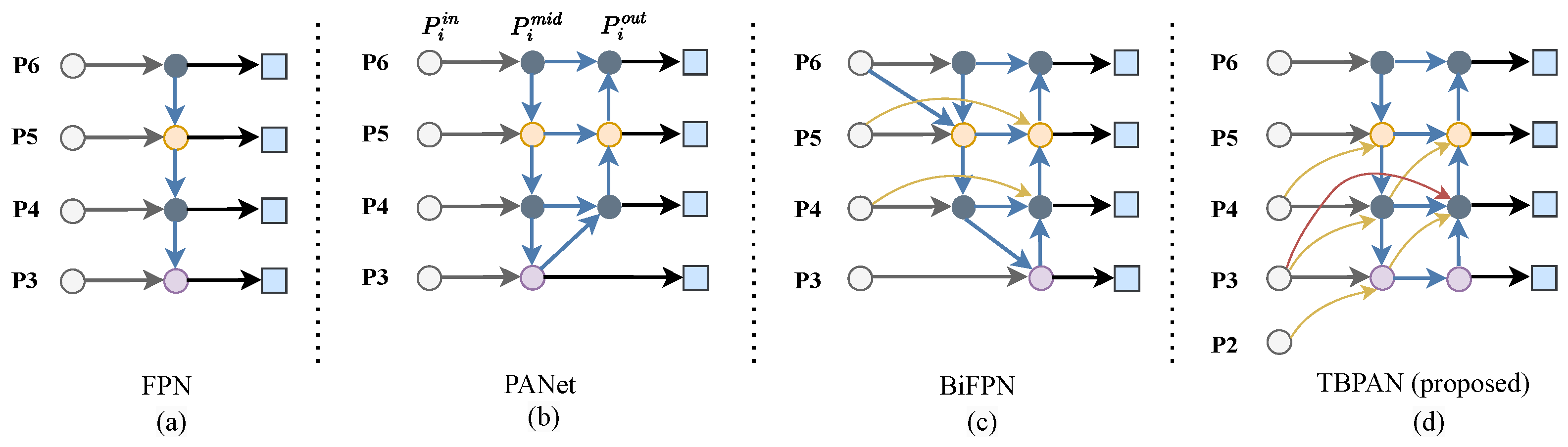
- Shallow feature extraction and multi-scale feature-fusion strategy are crucial for RSIs, determining whether the network can accurately identify densely arranged targets of varying scales in complex backgrounds. This paper proposes a three-branch path aggregation network (TBPAN), which aims to enhance the positional and salient information extracted from low-level feature maps. TBAPN incorporates additional branches between layers at different levels to establish cross-scale connections, enabling an effective multi-scale fusion of shallow features with deep semantic information. Experimental results demonstrate that TBPAN significantly alleviates the problem of missed detection for dense small targets and greatly improves the detection performance.
2. Preliminary
3. Related Works
3.1. Remote Sensing Object-Detection Framework
3.2. Multi-Scale Feature-Fusion Strategy
3.3. Semantic Information Exploitation
4. Main Results
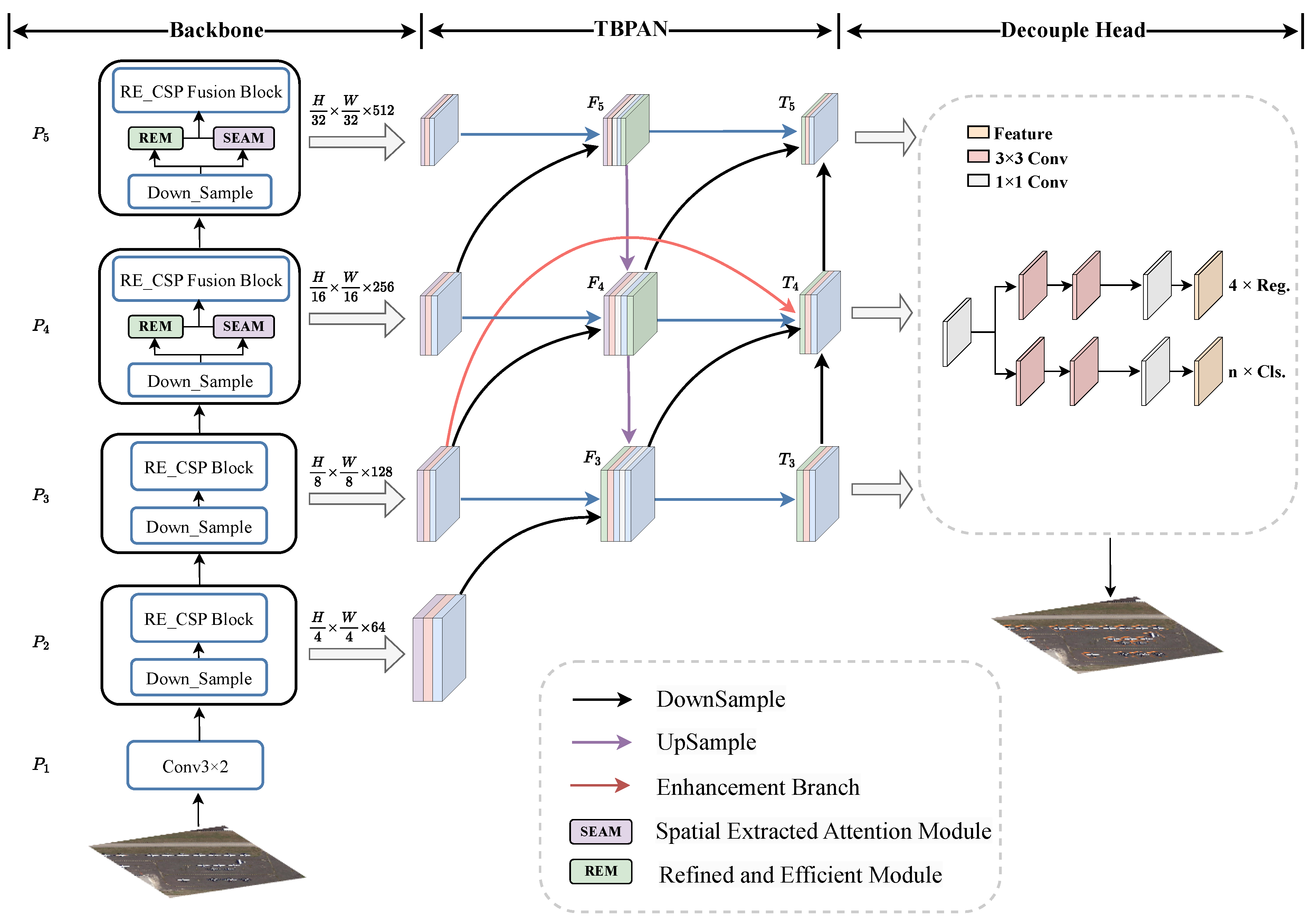
4.1. Proposed Methods
4.2. REM and RE_CSP Block
4.3. Spatial Extracted Attention Module
4.4. Structure of TBPAN
5. Experiment Results
5.1. Dataset
- (1)
- DOTA-v1.0 Dataset: This dataset consists of remote sensing images captured by various sensors and platforms, containing 2806 high-resolution aerial images of different sizes. Given that the dataset includes numerous small-sized targets, similar to the approach in [30,67], each image was cropped into sub-images of size with an overlap of 200 pixels to ensure smoother detection tasks. For the experiments, attention was focused on the five categories with the most instances for training and evaluation: small vehicle, large vehicle, ship, plane and storage tank. The training set comprises 6253 images, while the validation set contains 1794 images, all resized to pixels.
- (2)
- SCERL Dataset: This dataset primarily consists of remote sensing landslide images from the Longmenshan area of Sichuan Province. It includes 5434 images in the training set and 1461 images in the validation set with resolution of , which were cropped to . The dataset features a wide range of object sizes and includes a single category for Landslide. The SCERL dataset poses several challenges due to varying imaging conditions, such as differences in weather, lighting and overall image quality, making it a comprehensive test for evaluating object-detection performance in complex environments.
5.2. Evaluation Metrics
5.3. Training Setting
| Algorithm 1: Pseudocode of Training Process of RE-YOLO |
 |
5.4. Ablation Studies
5.5. Comparing the Detection Performance of Different Models
5.5.1. Experiments on the DOTA-v1.0 Dataset
5.5.2. Experiments on the SCERL Dataset
5.6. Efficiency Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining MODIS–EVI time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Sahar, L.; Muthukumar, S.; French, S.P. Using aerial imagery and GIS in automated building footprint extraction and shape recognition for earthquake risk assessment of urban inventories. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3511–3520. [Google Scholar] [CrossRef]
- Mo, P.; Li, D.; Liu, M.; Jia, J.; Chen, X. A lightweight and partitioned CNN algorithm for multi-landslide detection in remote sensing images. Appl. Sci. 2023, 13, 8583. [Google Scholar] [CrossRef]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale sequence joint deep learning (ss-jdl) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Fu, Y.; Zhao, C.; Wang, J.; Jia, X.; Yang, G.; Song, X.; Feng, H. An improved combination of spectral and spatial features for vegetation classification in hyperspectral images. Remote Sens. 2017, 9, 261. [Google Scholar] [CrossRef]
- Ren, S.; Fang, Z.; Gu, X. A cross stage partial network with strengthen matching detector for remote sensing object detection. Remote Sens. 2023, 15, 1574. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 391–405. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 27 October 2024).
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 27 October 2024).
- Ross, T.Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liang, T.; Wang, Y.; Tang, Z.; Hu, G.; Ling, H. Opanas: One-shot path aggregation network architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 10195–10203. [Google Scholar]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A cross-scale feature fusion pyramid network based remote sensing target detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 16794–16805. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolu-tional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Zhmoginov, A.; Chen, L.C.; Sandler, M.; Zhu, M. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive balanced network for multiscale object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Wang, J.; Sun, Y.; Lin, Y.; Zhang, K. Lightweight Substation Equipment Defect Detection Algorithm for Small Targets. Sensors 2024, 24, 5914. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. 2024, 36. [Google Scholar]
- Gao, T.; Wen, Y.; Zhang, J.; Chen, T. A novel dual-stage progressive enhancement network for single image deraining. Eng. Appl. Artif. Intell. 2024, 128, 107411. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Zhao, S.; Li, X. High-level semantic networks for multi-scale object detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3372–3386. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Han, G.; Shi, X.; Qian, G. Application of Object Detection Algorithms in Non-Destructive Testing of Pressure Equipment: A Review. Sensors 2024, 24, 5944. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, H.; Chen, M.; Tie, Y.; Li, W. A Universal Landslide Detection Method in Optical Remote Sensing Images Based on Improved YOLOX. Remote Sens. 2022, 14, 4939. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Chen, X.; Li, D.; Liu, M.; Jia, J. CNN and Transformer Fusion for Remote Sensing Image Semantic Segmentation. Remote Sens. 2023, 15, 4455. [Google Scholar] [CrossRef]
- Lv, F.; Zhang, T.; Zhao, Y.; Yao, Z.; Cao, X. An Improved Instance Segmentation Method for Complex Elements of Farm UAV Aerial Survey Images. Sensors 2024, 24, 5990. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Ioffe, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Gao, T.; Li, Z.; Wen, Y.; Chen, T.; Niu, Q.; Liu, Z. Attention-free global multiscale fusion network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5603214. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Yang, X.; Zhang, G.; Li, W.; Wang, X.; Zhou, Y.; Yan, J. H2rbox: Horizontal box annotation is all you need for oriented object detection. arXiv 2022, arXiv:2210.06742. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Chen, C.; Gong, W.; Hu, Y.; Chen, Y.; Ding, Y. Learning oriented region-based convolutional neural networks for building detection in satellite remote sensing images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 461–464. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation/Symbol | Full Name/Description |
|---|---|
| RSOD | Remote Sensing Object Detection |
| RSIs | Remote Sensing Images |
| CNNs | Convolutional Neural Networks |
| FPN | Feature Pyramid Network |
| ⊙ | Element-wise Multiplication |
| REM | Refined and Efficient Module |
| SEAM | Spatial Extracted Attention Module |
| TBPAN | Three-Branch Path Aggregation Network |
| IoU | Intersection Over Union |
| AP | Average Precision |
| mAP | Mean Average Precision |
| DWC | Depthwise Convolution |
| GC | Group Convolution |
| PWC | Pointwise Convolution |
| A | Average Precision at an IoU threshold of 50%. |
| mA | Mean Average Precision at an IoU threshold of 50%. |
| A 3D tensor with dimensions height, width and channel. | |
| RE_CSP block | The block that consists of several REM and convolutional layers. |
| Method | Modules | Precision (%) | Recall (%) | F1 (%) | mA (%) | mA (%) | Params (MB) | FLOPs (G) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| RENet | TBPAN | SEAM | ||||||||
| Input Image Size: 640 | ||||||||||
| Baseline YOLOv8s | 87.0 | 77.4 | 81.9 | 84.9 | 62.8 | 11.1 | 28.8 | |||
| Replace | CSPDarkNet [23] | ✓ | × | 87.1 | 79.4 | 83.1 | 85.2 | 63.5 | 13.9 | 40.0 |
| ✓ | PAFPN [23] | ✓ | 85.9 | 77.9 | 81.7 | 84.8 | 61.6 | 9.1 | 22.6 | |
| ✓ | BiFPN [27] | ✓ | 86.1 | 77.8 | 81.7 | 85.0 | 62.4 | 5.5 | 21.0 | |
| ✓ | ✓ | SE [52] | 87.0 | 79.0 | 82.8 | 85.4 | 63.3 | 12.4 | 34.8 | |
| Remove | ✓ | ✓ | × | 86.5 | 79.9 | 85.5 | 63.6 | 11.9 | 34.0 | |
| RE-YOLO | ✓ | ✓ | × | 86.5 | 79.9 | 83.1 | 85.5 | 63.6 | 11.9 | 34.0 |
| RE-YOLO | ✓ | ✓ | ✓ | 87.5 | 78.4 | 82.7 | 85.4 | 63.4 | 12.0 | 34.1 |
| Input Image Size: 1024 | ||||||||||
| Baseline YOLOv8s | 86.4 | 80.2 | 83.2 | 86.6 | 64.1 | 11.1 | 28.8 | |||
| Replace | CSPDarkNet [23] | ✓ | × | 87.3 | 80.8 | 83.9 | 87.1 | 65.4 | 13.9 | 40.0 |
| ✓ | PAFPN [23] | ✓ | 87.9 | 80.0 | 83.7 | 86.5 | 64.6 | 9.1 | 22.6 | |
| ✓ | BiFPN [27] | ✓ | 87.2 | 80.3 | 83.6 | 86.5 | 65.3 | 5.5 | 21.0 | |
| ✓ | ✓ | SE [52] | 87.0 | 79.0 | 82.8 | 85.4 | 63.3 | 12.4 | 34.8 | |
| Remove | ✓ | ✓ | × | 88.0 | 80.1 | 86.7 | 65.6 | 11.9 | 34.0 | |
| RE-YOLO | ✓ | ✓ | × | 88.0 | 80.1 | 83.8 | 86.7 | 65.6 | 11.9 | 34.0 |
| RE-YOLO | ✓ | ✓ | ✓ | 88.1 | 80.3 | 84.0 | 86.9 | 65.8 | 12.0 | 34.1 |
| Method | Small Vehicle | Large Vehicle | Plane | Ship | Storage Tank |
mA (%) |
mA (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | A | A | A | A | A | A | A | A | A | |||
| Image Size for Training: 640 × 640 | ||||||||||||
| YOLOv5s | 68.4 | 41.4 | 83.9 | 60.8 | 92.4 | 68.5 | 88.8 | 62.5 | 77.8 | 46 | 82.2 | 55.8 |
| YOLOv5m | 67.8 | 41.9 | 86.5 | 64.8 | 93.8 | 71.3 | 89.8 | 66.1 | 82.6 | 51.7 | 84.1 | 59.1 |
| LP-YOLO | 69.0 | 39.9 | 84.0 | 58.8 | 91.2 | 65.1 | 87.6 | 58.7 | 73.7 | 42.6 | 81.1 | 53.0 |
| YOLOv6t | 69.8 | 39.1 | 86.1 | 61.8 | 92.3 | 68.0 | 88.8 | 61.4 | 78.1 | 47.0 | 83.0 | 55.5 |
| YOLOv6s | 69.5 | 39.0 | 85.8 | 60.8 | 92.6 | 68.0 | 89.1 | 60.8 | 79.7 | 48.7 | 83.4 | 55.5 |
| YOLOv7 | 68.2 | 40.8 | 86.2 | 63.9 | 93.2 | 69.3 | 89.2 | 64.6 | 77.3 | 45.5 | 82.8 | 56.8 |
| YOLOv8s | 74.2 | 47.6 | 86.5 | 68.0 | 92.2 | 72.0 | 91.2 | 68.8 | 81.0 | 57.8 | 84.9 | 62.8 |
| YOLOv9s | 70.6 | 42.0 | 84.0 | 62.3 | 91.4 | 68.2 | 89.4 | 64.3 | 74.2 | 46.5 | 81.9 | 56.7 |
| YOLOv9m | 71.3 | 43.2 | 86.6 | 65.2 | 93.2 | 70.5 | 90.5 | 66.4 | 78.5 | 48.7 | 84.0 | 58.8 |
| YOLOv10s | 70.2 | 43.1 | 87.6 | 66.3 | 92.1 | 68.0 | 89.5 | 65.1 | 76.8 | 48.2 | 83.2 | 58.1 |
| RE-YOLO | 71.7 | 47.0 | 87.2 | 69.3 | 93.0 | 74.2 | 91.7 | 70.4 | 83.9 | 57.2 | 85.5 | 63.6 |
| RE-YOLO + SEAM | 74.5 | 48.4 | 86.6 | 68.6 | 92.8 | 73.3 | 91.3 | 69.9 | 81.7 | 56.8 | 85.4 | 63.4 |
| Image Size for Training: 1024 × 1024 | ||||||||||||
| YOLOv5s | 70.3 | 43.3 | 86.0 | 65.2 | 94.3 | 69.9 | 90.1 | 66.5 | 82.1 | 53.3 | 84.6 | 59.6 |
| LP-YOLO | 74.9 | 43.4 | 86.0 | 60.7 | 90.8 | 63.0 | 88.7 | 61.6 | 77.5 | 46.7 | 83.6 | 55.1 |
| YOLOv8s | 76.6 | 49.5 | 87.0 | 69.6 | 92.6 | 73.2 | 91.8 | 71.1 | 84.7 | 57.0 | 86.6 | 64.1 |
| YOLOv9m | 75.3 | 47.3 | 86.5 | 66.0 | 92.8 | 70.6 | 90.9 | 68.2 | 82.1 | 53.6 | 85.5 | 61.2 |
| YOLOv10s | 76.4 | 47.2 | 85.6 | 64.7 | 91.9 | 68.2 | 89.3 | 65.4 | 79.9 | 50.3 | 84.6 | 59.2 |
| RE-YOLO | 76.0 | 49.8 | 87.7 | 70.8 | 93.9 | 75.5 | 92.4 | 72.6 | 83.7 | 59.5 | 86.7 | 65.6 |
| RE-YOLO + SEAM | 76.1 | 50.2 | 88.5 | 71.2 | 93.6 | 75.4 | 92.2 | 72.5 | 83.7 | 59.8 | 86.9 | 65.8 |
| Method | Small Vehicle | Large Vehicle | Plane | Ship | Storage Tank | Pre (%) | Rec (%) | F1 (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | Pre | Rec | Pre | Rec | Pre | Rec | Pre | Rec | ||||
| Image Size for Training: 640 × 640 | |||||||||||||
| YOLOv5s | 73.6 | 65.9 | 87.6 | 79.7 | 94.3 | 87.8 | 92.8 | 84.7 | 92.3 | 66.6 | 88.1 | 77.0 | 82.2 |
| LP-YOLO | 73.2 | 65.7 | 85.3 | 78.4 | 93.2 | 85.5 | 91.7 | 82.8 | 93.0 | 60.2 | 87.3 | 74.5 | 80.4 |
| YOLOv6t | 72.0 | 65.4 | 84.7 | 80.7 | 95.0 | 88.0 | 92.3 | 85.2 | 83.9 | 69.9 | 85.6 | 77.8 | 81.5 |
| YOLOv6s | 71.4 | 67.0 | 83.0 | 81.6 | 93.3 | 88.6 | 91.5 | 86.1 | 88.5 | 69.7 | 85.5 | 78.6 | 81.9 |
| YOLOv7 | 64.2 | 67.4 | 83.8 | 81.4 | 94.2 | 88.0 | 92.3 | 86.0 | 92.3 | 64.8 | 85.4 | 77.5 | 81.2 |
| YOLOv8s | 70.2 | 72.7 | 85.3 | 80.7 | 93.7 | 86.0 | 92.4 | 85.2 | 93.4 | 62.5 | 87.0 | 77.4 | 81.9 |
| YOLOv9s | 69.6 | 70.8 | 84.6 | 80.0 | 93.1 | 86.4 | 92.5 | 85.0 | 95.0 | 61.1 | 87.0 | 76.7 | 81.5 |
| YOLOv9m | 66.6 | 73.1 | 82.7 | 83.5 | 95.0 | 87.6 | 92.4 | 86.5 | 93.3 | 64.5 | 86.0 | 79.0 | 82.3 |
| YOLOv10s | 65.1 | 72.5 | 86.6 | 82.2 | 92.8 | 86.6 | 92.5 | 85.2 | 88.6 | 64.5 | 85.1 | 78.2 | 81.5 |
| RE-YOLO | 69.5 | 73.1 | 85.4 | 83.0 | 94.2 | 87.9 | 91.7 | 86.5 | 91.9 | 69.1 | 86.5 | 79.9 | 83.1 |
| RE-YOLO + SEAM | 72.0 | 72.7 | 86.1 | 80.9 | 94.2 | 87.1 | 92.3 | 85.8 | 92.8 | 65.5 | 87.5 | 78.4 | 82.7 |
| Image Size for Training: 1024 × 1024 | |||||||||||||
| YOLOv5s | 70.2 | 70.8 | 88.6 | 80.5 | 94.8 | 87.6 | 93.4 | 86.5 | 95.8 | 70.0 | 88.5 | 79.1 | 83.5 |
| LP-YOLO | 74.9 | 69.4 | 85.2 | 80.5 | 94.3 | 83.1 | 92.4 | 83.7 | 94.0 | 64.1 | 88.2 | 76.2 | 81.8 |
| YOLOv8s | 69.5 | 74.6 | 84.9 | 82.2 | 93.1 | 87.1 | 91.6 | 86.8 | 92.7 | 70.0 | 86.4 | 80.2 | 83.2 |
| YOLOv9m | 70.4 | 73.6 | 84.9 | 82.2 | 93.9 | 87.4 | 92.6 | 86.8 | 93.1 | 68.1 | 87.0 | 79.6 | 83.1 |
| YOLOv10s | 74.8 | 74.4 | 84.2 | 79.2 | 91.6 | 85.1 | 90.4 | 85.3 | 87.74 | 67.1 | 85.8 | 78.2 | 81.8 |
| RE-YOLO | 73.4 | 74.2 | 86.2 | 82.8 | 94.5 | 88.5 | 92.6 | 87.4 | 93.5 | 67.8 | 88.0 | 80.1 | 83.9 |
| RE-YOLO + SEAM | 72.7 | 74.2 | 86.4 | 84.0 | 94.3 | 88.1 | 92.7 | 87.0 | 94.2 | 68.1 | 88.1 | 80.3 | 84.0 |
| Method | mA (%) | mA (%) | Precision (%) | Recall (%) | Params (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv5s | 42.6 | 22.4 | 48.9 | 46.0 | 7.0 | 15.8 |
| YOLOv6s | 45.8 | 24.7 | 46.6 | 52.5 | 18.8 | 48.9 |
| YOLOv7 | 45.7 | 24.9 | 48.7 | 49.2 | 39.9 | 109.8 |
| YOLOv8s | 44.8 | 26.9 | 51.4 | 39.3 | 11.1 | 28.8 |
| YOLOv9s | 41.3 | 22.8 | 44.4 | 45.7 | 6.2 | 22.1 |
| YOLOv9m | 43.3 | 22.4 | 50.2 | 46.6 | 16.5 | 60.0 |
| YOLOv10s | 40.6 | 20.8 | 45.1 | 45.2 | 8.1 | 24.4 |
| RE-YOLO | 45.8 | 28.4 | 56.3 | 36.5 | 11.9 | 34.0 |
| RE-YOLO + SEAM | 44.2 | 27.5 | 53.9 | 37.2 | 12.0 | 34.1 |
| Method | Backbone | Params-B (MB) | Params-M (MB) | Ratio (%) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | CSPDarkNet-s-C3 | 4.0 | 7.2 | 55.5 | 15.9 |
| YOLOv5m | CSPDarkNet-m-C3 | 12.2 | 21.2 | 57.5 | 49.2 |
| YOLOv6t | EfficientRep-t | 6.6 | 10.6 | 62.2 | 27.64 |
| YOLOv6s | EfficientRep-s | 12.3 | 18.8 | 65.1 | 48.9 |
| YOLOv7 | E-ELAN | 20.9 | 39.9 | 52.3 | 109.8 |
| YOLOv8s | CSPDarkNet-s-C2F | 5.1 | 11.1 | 45.9 | 28.8 |
| RE-YOLO | RENet | 3.1 | 11.9 | 26.1 | 34.0 |
| RE-YOLO + SEAM | RENet | 3.2 | 12.0 | 26.7 | 34.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Mo, P.; Wang, S.; Cui, Y.; Wu, Z. A Refined and Efficient CNN Algorithm for Remote Sensing Object Detection. Sensors 2024, 24, 7166. https://doi.org/10.3390/s24227166
Liu B, Mo P, Wang S, Cui Y, Wu Z. A Refined and Efficient CNN Algorithm for Remote Sensing Object Detection. Sensors. 2024; 24(22):7166. https://doi.org/10.3390/s24227166
Chicago/Turabian StyleLiu, Bingqi, Peijun Mo, Shengzhe Wang, Yuyong Cui, and Zhongjian Wu. 2024. "A Refined and Efficient CNN Algorithm for Remote Sensing Object Detection" Sensors 24, no. 22: 7166. https://doi.org/10.3390/s24227166
APA StyleLiu, B., Mo, P., Wang, S., Cui, Y., & Wu, Z. (2024). A Refined and Efficient CNN Algorithm for Remote Sensing Object Detection. Sensors, 24(22), 7166. https://doi.org/10.3390/s24227166