
Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR)

Abstract
1. Introduction
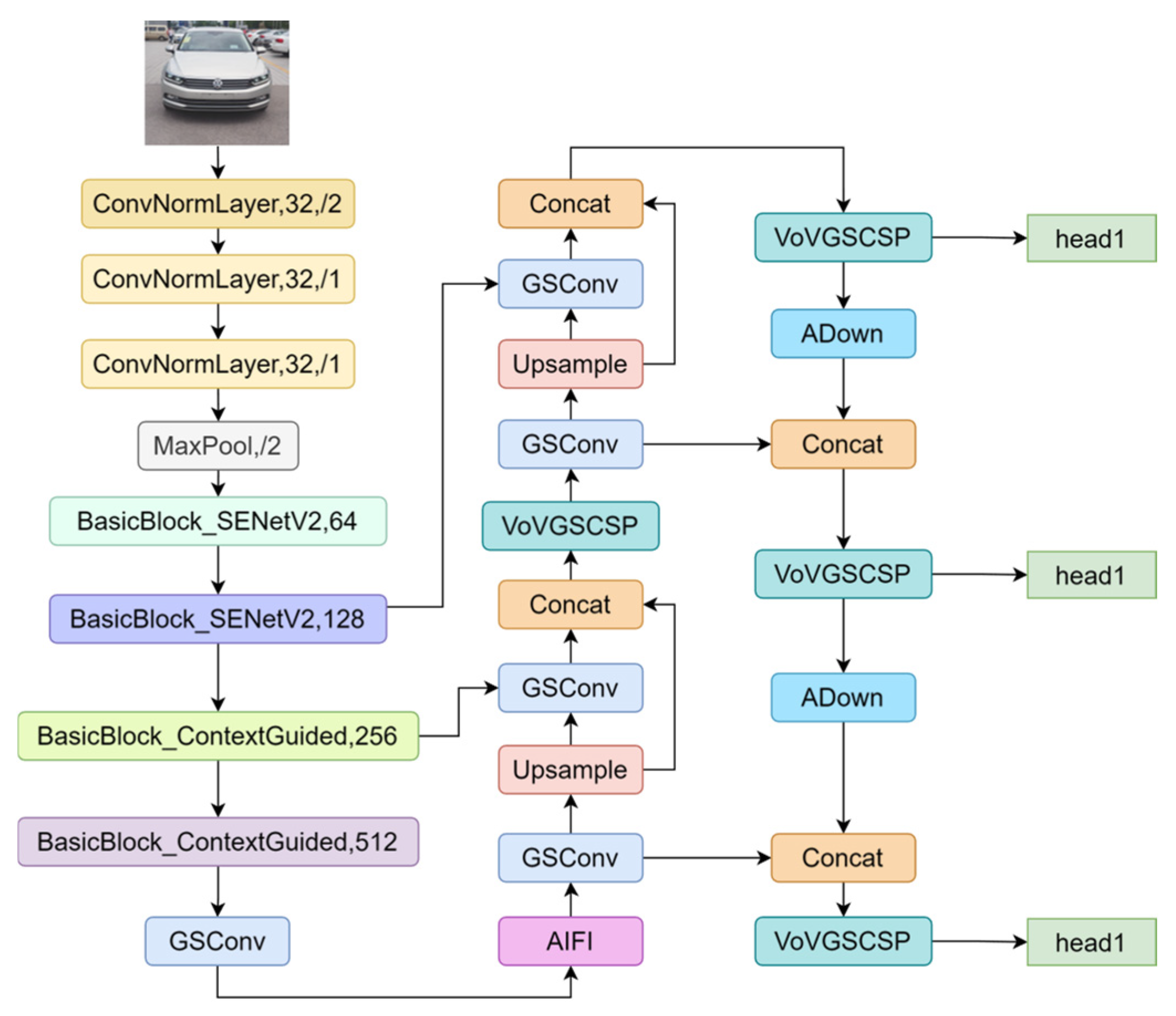
- The backbone network follows a “deep and thin” principle, leveraging ResNet-34 in conjunction with the lightweight CGBlock and the aggregated multilayer perceptron SENetV2. This combination enhances both shallow feature extraction and global feature representation, helping to preserve small object details through the integration of semantic and spatial information.
- The neck network adopts a Slim-Neck structure that incorporates the ADown block as a substitute for traditional downsampling convolutions. This modification streamlines the network architecture while preserving semantic consistency.
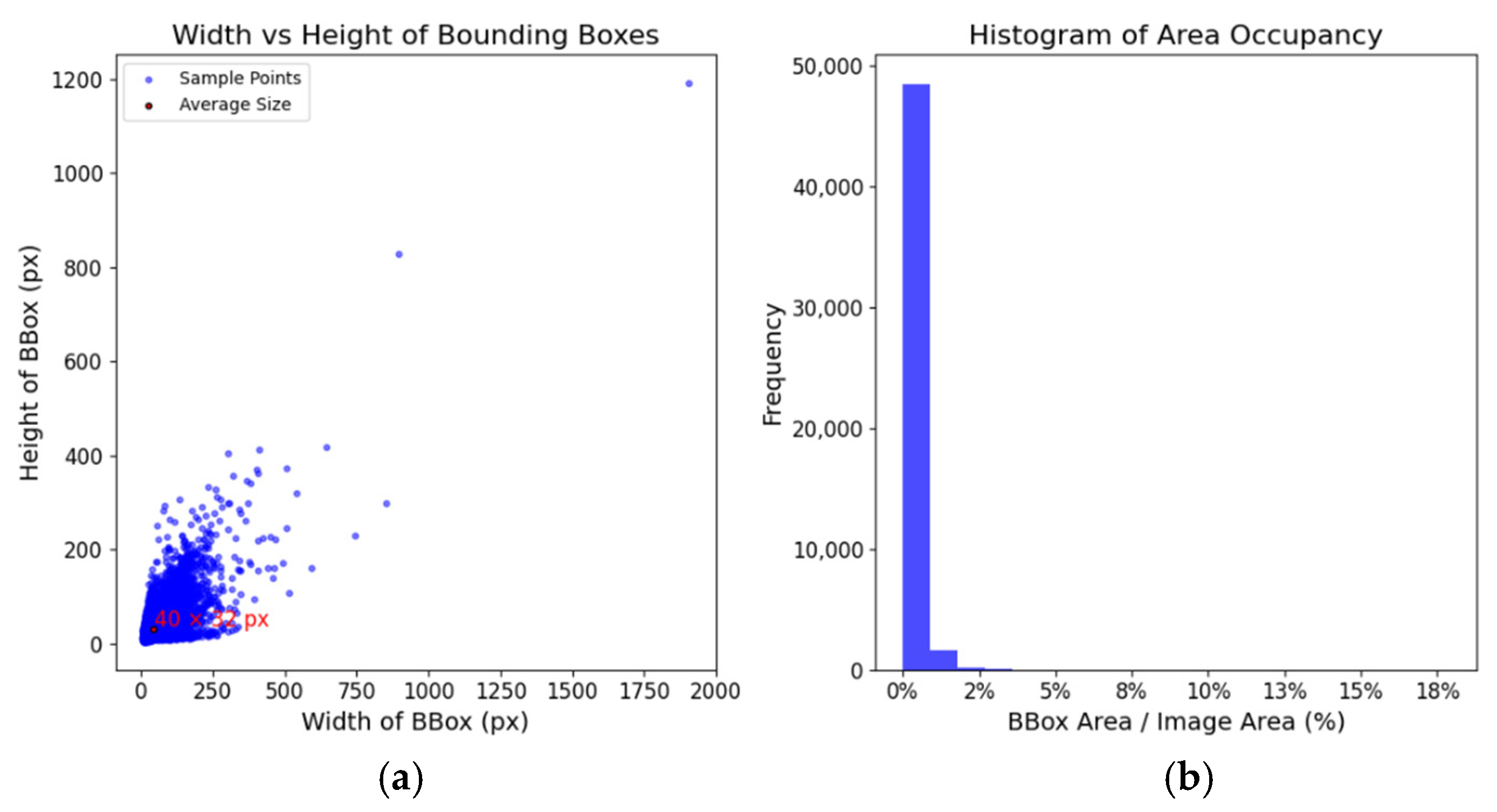
- A novel microscale vehicle logo dataset (VLD-Micro) featuring vehicle logos that are significantly smaller than those in traditional datasets, with an average size of 24 × 19 pixels, was introduced.
- Experiments conducted on the VLD-Micro dataset demonstrated that our model achieved a 1.6% higher mAP@50:95 than YOLOv8 and 7.4% higher than Faster R-CNN, with significantly fewer parameters. Relative to the original model, the mAP@50:95 increased by 1.5%, while the parameter count was reduced by approximately 37.6%, and the FLOPS decreased by 36.7%.
2. Related Works
2.1. Vehicle Logo Detection
2.2. RT-DETR
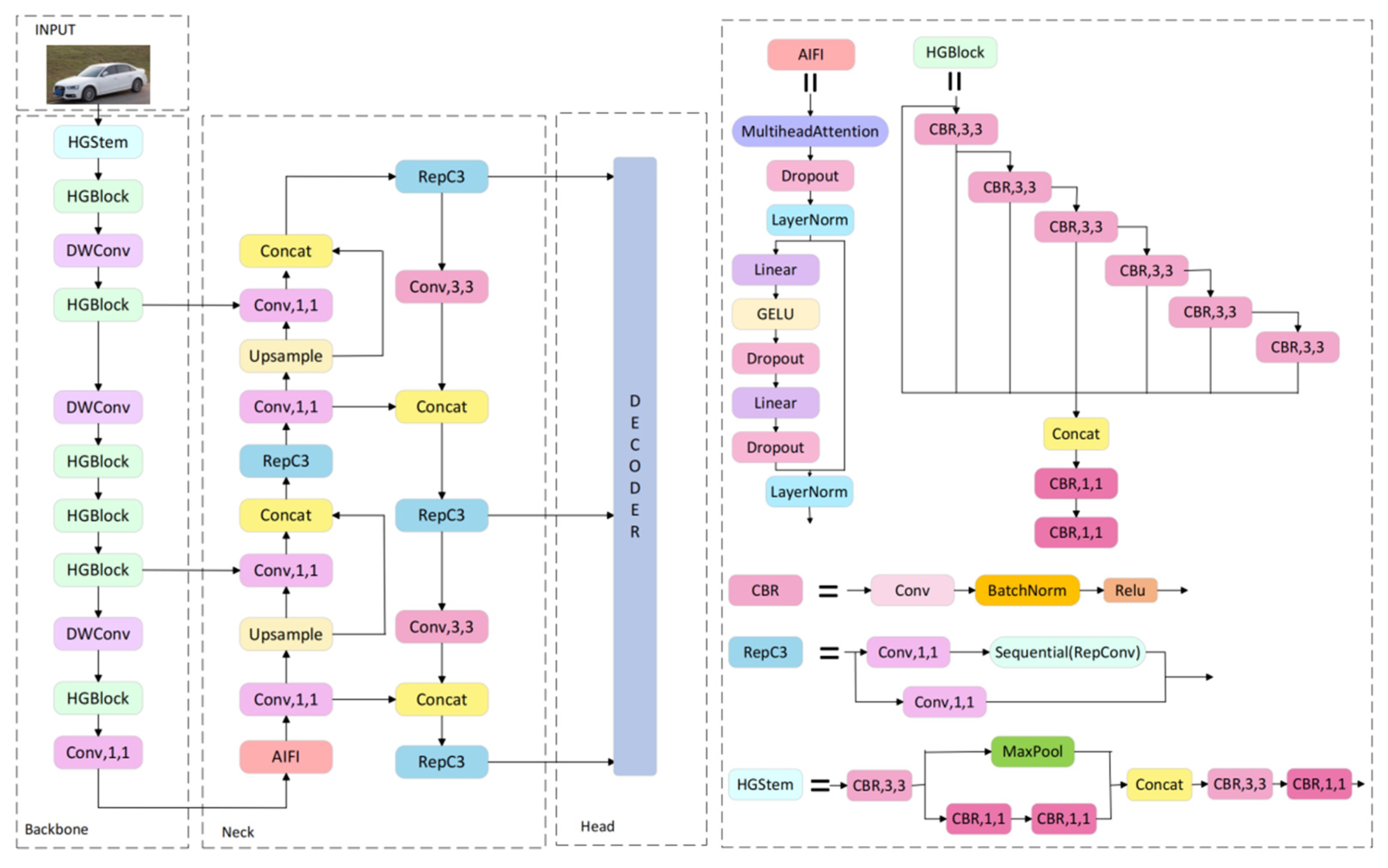
3. Method
3.1. RT-DETR Improvements
3.2. Backbone Improvements
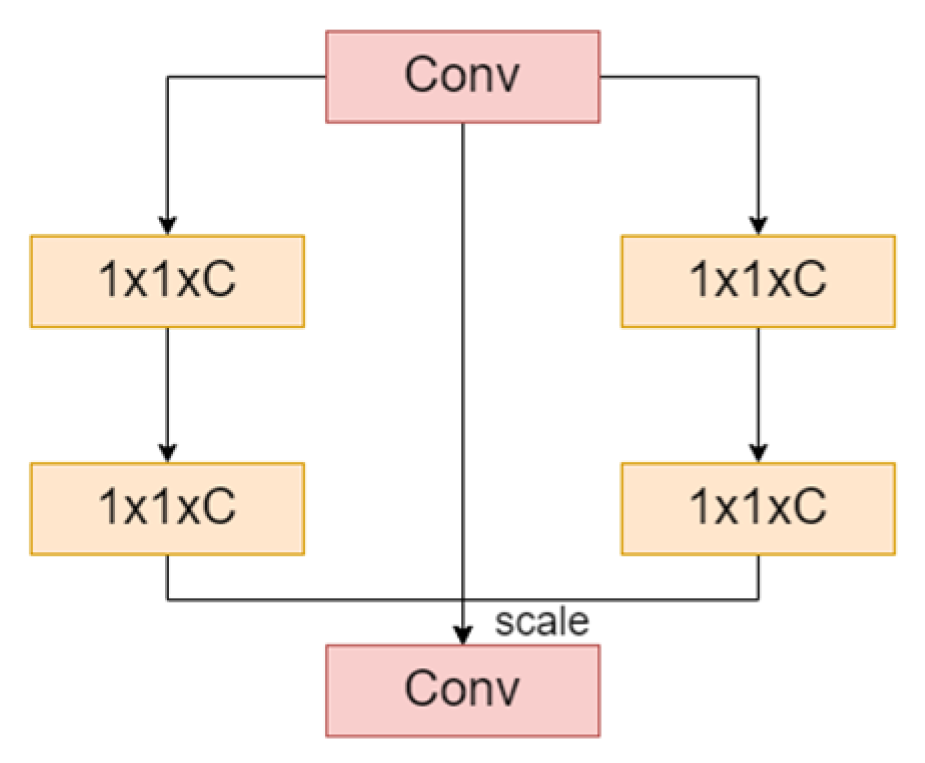
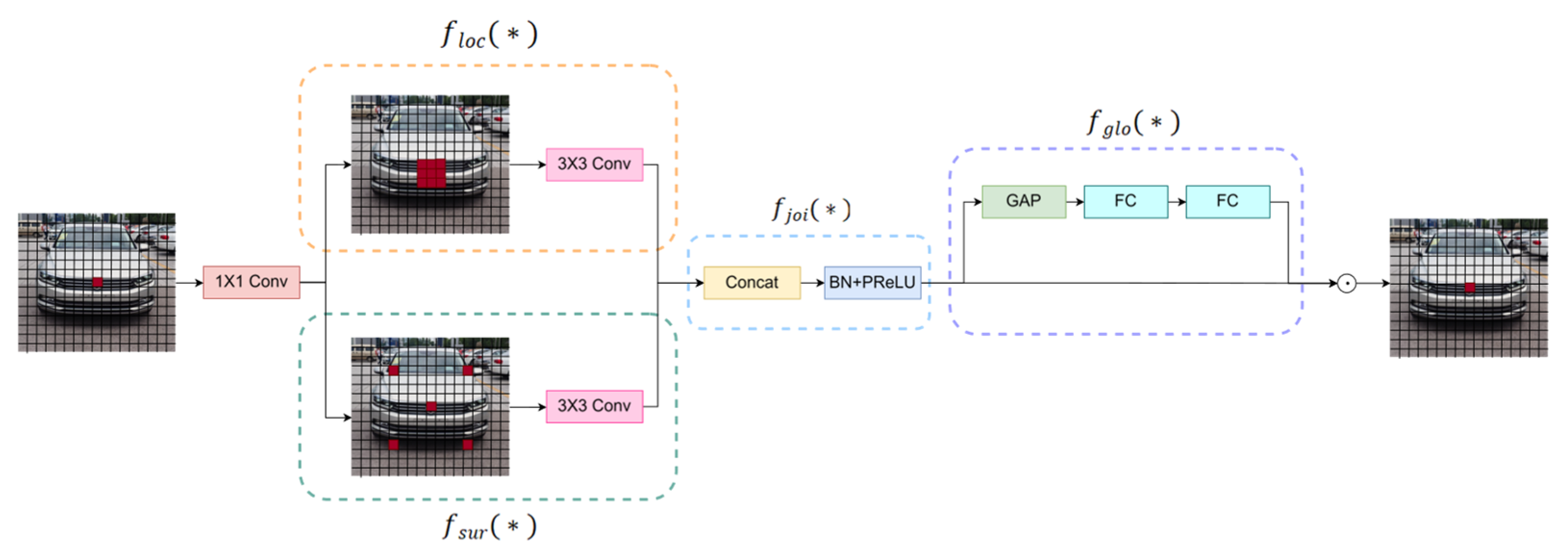
3.2.1. SENetV2
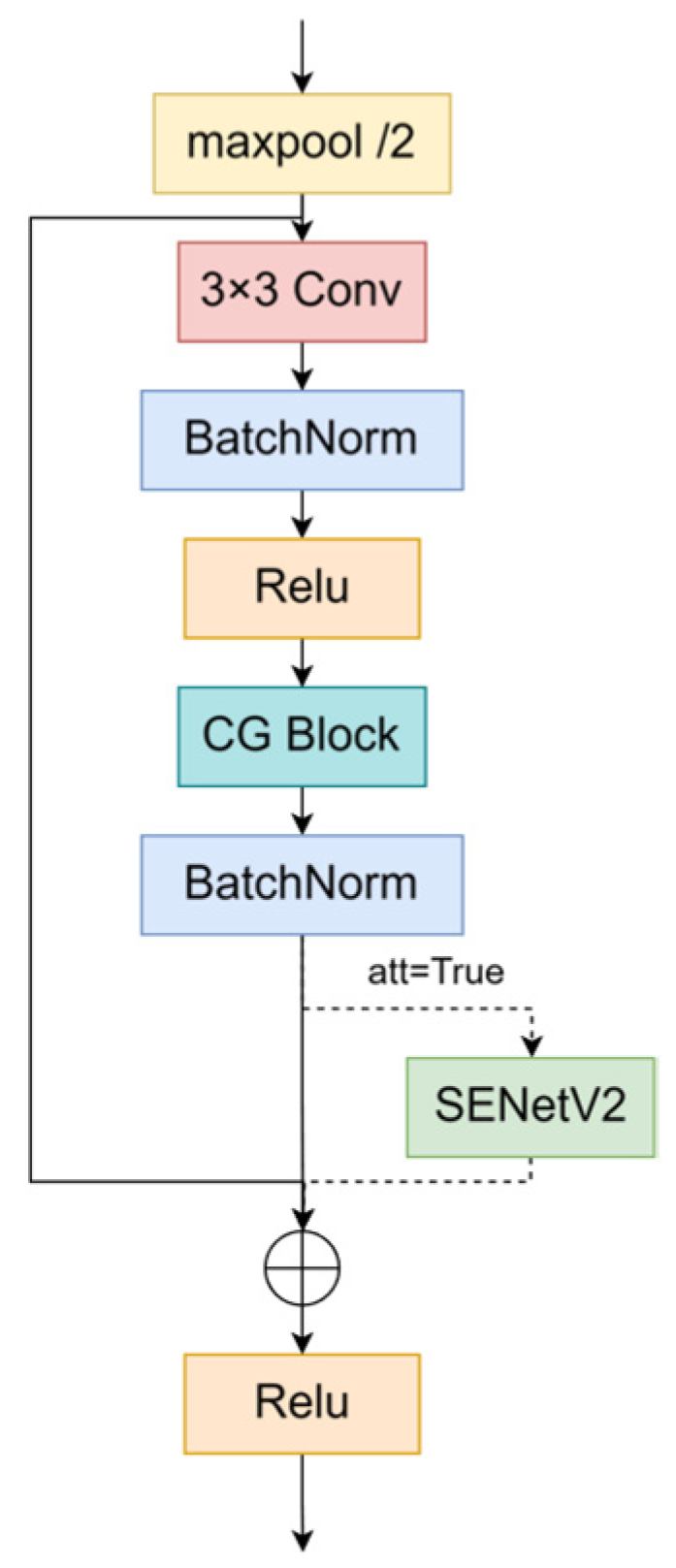
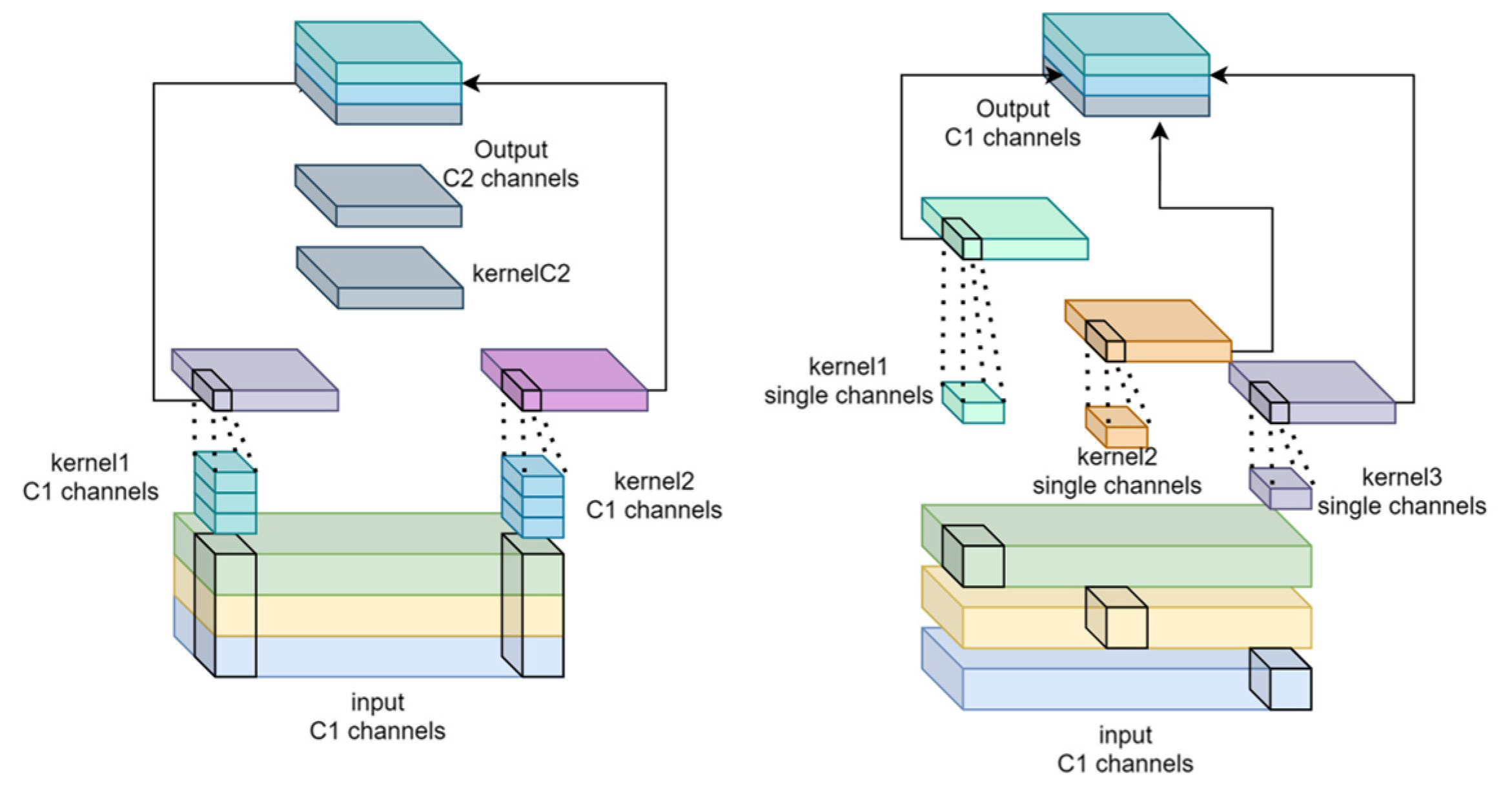
3.2.2. CG Block
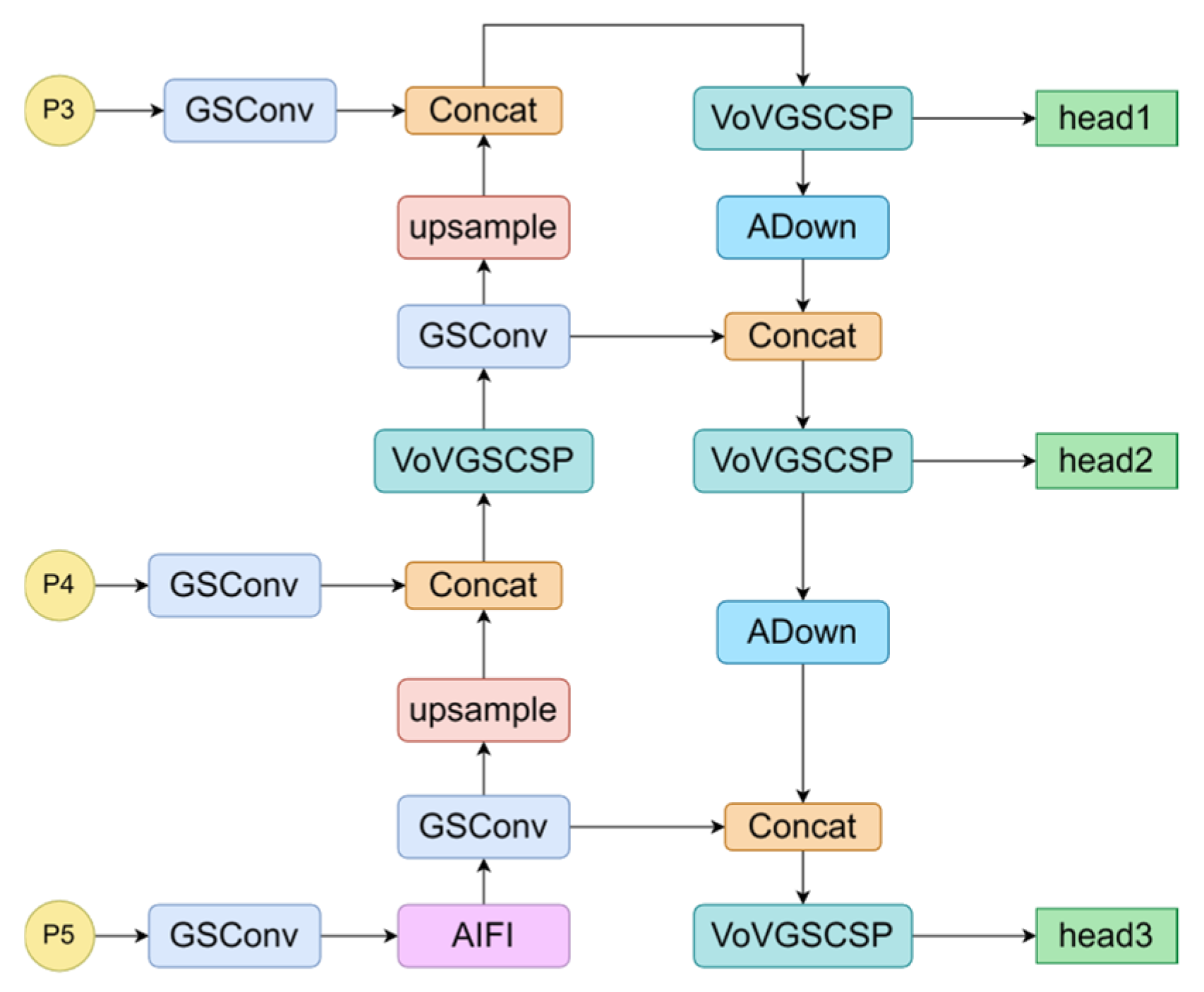
3.3. Neck Improvements
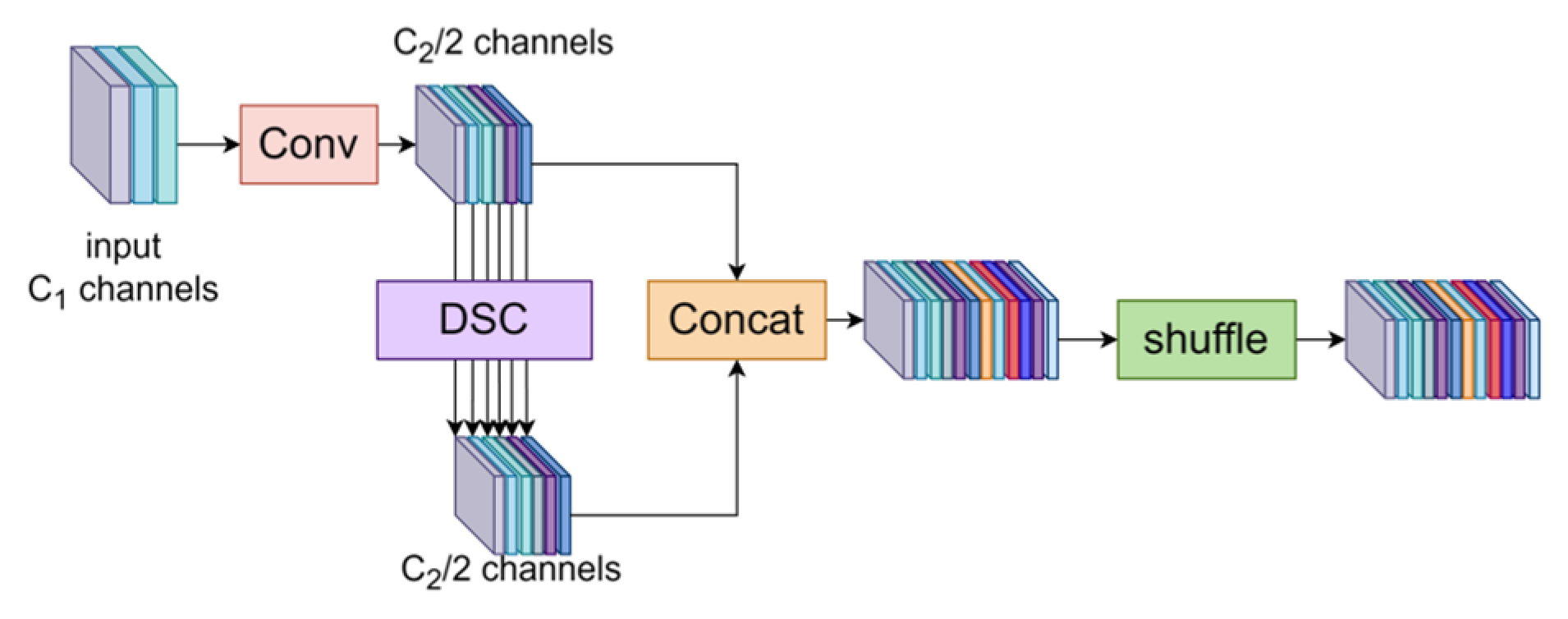
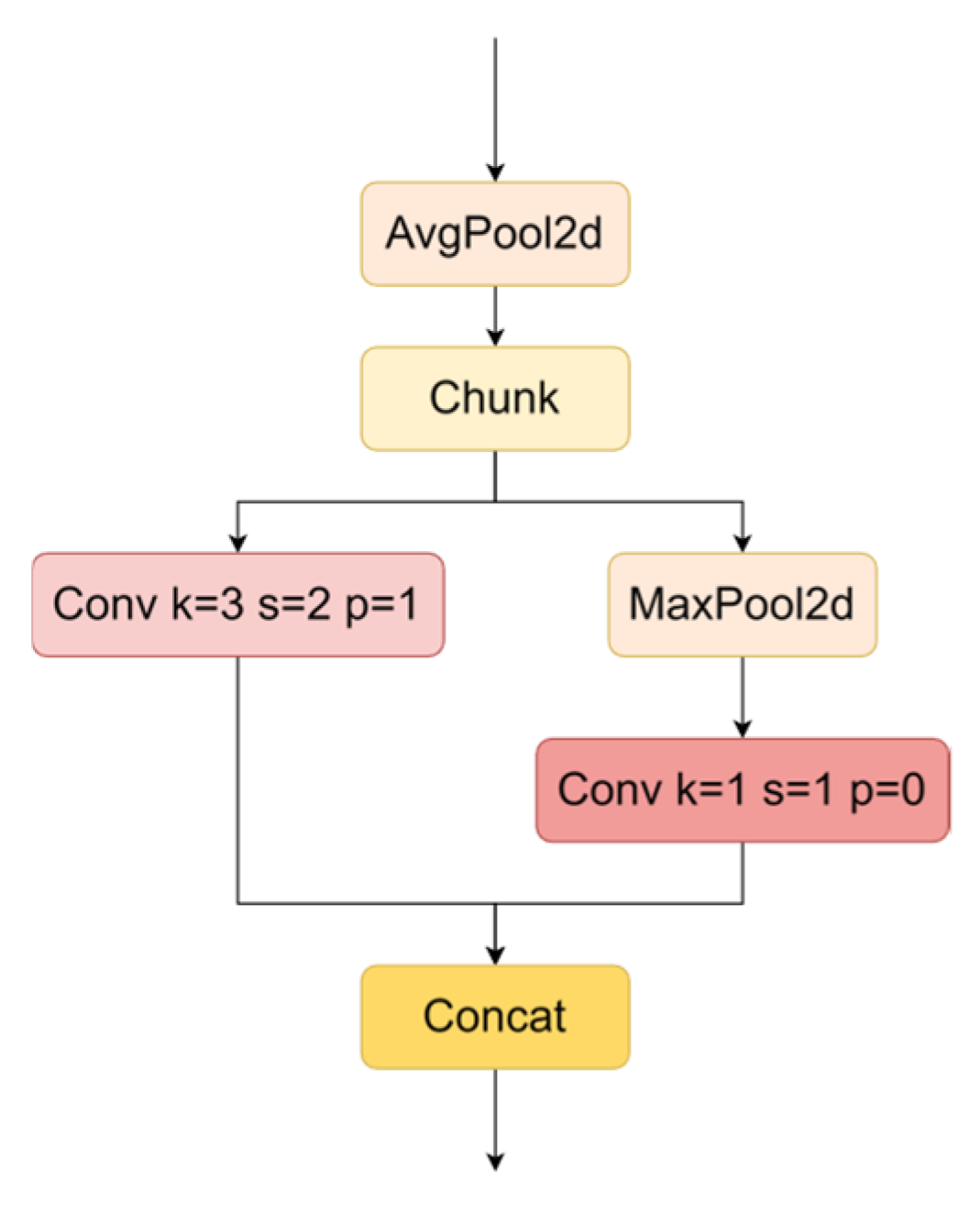
3.3.1. GSConv
3.3.2. VOVGSCSP
3.3.3. ADown
4. Experimental Design and Interpretation of Results
4.1. Experimental Equipment and Evaluation Indicators
4.2. Dataset
4.3. Comparison
4.4. Comparison of Test Results
4.5. Grad-CAM Visualization
4.6. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Wang, J.; Lu, J.; Xie, Y.; Nie, Z. Vehicle logo recognition based on overlapping enhanced patterns of oriented edge magnitudes. Comput. Electr. Eng. 2018, 71, 273–283. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, R.; Sun, Y.; Wang, W.; Ding, X. Vehicle logo recognition system based on convolutional neural networks with a pretraining strategy. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1951–1960. [Google Scholar] [CrossRef]
- Yang, S.; Bo, C.; Zhang, J.; Gao, P.; Li, Y.; Serikawa, S. VLD-45: A big dataset for vehicle logo recognition and detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 25567–25573. [Google Scholar] [CrossRef]
- Llorca, D.F.; Arroyo, R.; Sotelo, M. Vehicle logo recognition in traffic images using HOG features and SVM. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Soon, F.C.; Hui, Y.K.; Chuah, J.H. Pattern recognition of Vehicle Logo using Tchebichef and Legendre moment. In Proceedings of the 2015 IEEE Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 13–14 December 2015. [Google Scholar]
- Yu, S.; Zheng, S.; Hua, Y.; Liang, L. Vehicle logo recognition based on Bag-of-Words. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Zhaowei, C.; Nuno, V. Cascade R-CNN: Delv-ing into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Jocher, G. Yolov5 Release v7.0. Available online: https://github.com/ultralytics/yolov5/tree/v7.0 (accessed on 12 November 2022).
- Jocher, G. Yolov8. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 12 July 2023).
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. Pp-yolov2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Vaswani, A. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I. pp. 213–229. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised pre-training for object detection with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Psyllos, A.; Anagnostopoulos, C.-N.; Kayafas, E. M-SIFT: A new method for Vehicle Logo Recognition. In Proceedings of the 2012 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Istanbul, Turkey, 24–27 July 2012; pp. 261–266. [Google Scholar]
- Peng, H.; Wang, X.; Wang, H.; Yang, W. Recognition of low-resolution logos in vehicle images based on statistical random sparse distribution. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; Volume 16, pp. 681–691. [Google Scholar]
- Satzoda, R.K.; Trivedi, M.M. Multipart vehicle detection using symmetry-derived analysis and active learning. IEEE Trans. Intell. Transp. Syst. 2015, 17, 926–937. [Google Scholar] [CrossRef]
- Liao, Y.; Lu, X.; Zhang, C.; Wang, Y.; Tang, Z. Mutual enhancement for detection of multiple logos in sports videos. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4856–4865. [Google Scholar]
- Rajab, M.A.; George, L.E. Car logo image extraction and recognition using K-medoids, daubechies wavelets, and DCT transforms. Iraqi J. Sci. 2024, 431–442. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation tech report. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Volume 2014, pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chen, R.; Mihaylova, L.; Zhu, H.; Bouaynaya, N.C. A deep learning framework for joint image restoration and recognition. Circuits Syst. Signal Process. 2019, 39, 1561–1580. [Google Scholar] [CrossRef]
- Zhou, L.; Min, W.; Lin, D.; Han, Q.; Liu, R. Detecting motion blurred vehicle logo in IoV using filter-DeblurGAN and VL-YOLO. IEEE Trans. Veh. Technol. 2020, 69, 3604–3614. [Google Scholar] [CrossRef]
- Jiang, X.; Sun, K.; Ma, L.; Qu, Z.; Ren, C. Vehicle logo detection method based on improved YOLOv4. Electronics 2022, 11, 3400. [Google Scholar] [CrossRef]
- Song, L.; Min, W.; Zhou, L.; Wang, Q.; Zhao, H. Vehicle logo recognition using spatial structure correlation and YOLO-T. Sensors 2023, 23, 4313. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, D.; Xiao, J. A new method for vehicle logo recognition based on Swin Transformer. arXiv 2024, arXiv:2401.15458. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient DETR:improving end-to-end object detector with dense prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Gao, P.; Zheng, M.; Wang, X.; Dai, J.; Li, H. Fast convergence of DETR with spatially modulated co-attention. arXiv 2021, arXiv:2101.07448. [Google Scholar]
- Liu, F.; Wei, H.; Zhao, W.; Li, G.; Peng, J.; Li, Z. WB-DETR: Transformer-based detector without backbone. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2959–2967. [Google Scholar]
- Cao, X.; Yuan, P.; Feng, B.; Niu, K. CF-DETR: Coarse-to-fine Transformers for end-to-end object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Params (M) | FLPOS (G) | mAP@50 | mAP@50:95 | FPS |
|---|---|---|---|---|---|
| RT-DETR-L | 32.79 | 105.1 | 0.967 | 0.687 | 26.02 |
| ResNet-18 | 19.94 | 57.4 | 0.967 | 0.686 | 50.26 |
| ResNet-34 | 30.05 | 87.6 | 0.966 | 0.688 | 66.11 |
| ResNet-50 | 42.90 | 134.6 | 0.970 | 0.691 | 27.37 |
| Backbone | Params(M) | FLPOS(G) | Map@50 | mAP@50:95 | FPS |
|---|---|---|---|---|---|
| MobileNetv3 | 18.54 | 57.2 | 0.953 | 0.663 | 34.18 |
| EfficientNetv2 | 28.47 | 70.1 | 0.967 | 0.692 | 43.91 |
| ShuffleNetv2 | 18.80 | 59.5 | 0.92 | 0.626 | 13.7 |
| RepViT | 13.39 | 37.0 | 0.97 | 0.691 | 15.3 |
| EfficientViT | 10.76 | 27.4 | 0.947 | 0.66 | 53.73 |
| VanillanNet13 | 26.29 | 81.0 | 0.921 | 0.631 | 11.7 |
| Our Method | 18.74 | 55.4 | 0.976 | 0.698 | 68.11 |
| Category | YOLOv8 | YOLOv9 | Faster R-CNN | RT-DETR | Our Method |
|---|---|---|---|---|---|
| GMC | 0.676 | 0.699 | 0.651 | 0.679 | 0.687 |
| Audi | 0.75 | 0.743 | 0.677 | 0.72 | 0.732 |
| BAOJUN | 0.708 | 0.724 | 0.696 | 0.722 | 0.741 |
| HONDA | 0.698 | 0.726 | 0.670 | 0.712 | 0.728 |
| PEUGEOT | 0.643 | 0.689 | 0.604 | 0.667 | 0.672 |
| Buick | 0.743 | 0.749 | 0.676 | 0.712 | 0.741 |
| Soueast Motor | 0.701 | 0.702 | 0.676 | 0.72 | 0.759 |
| QOROS | 0.685 | 0.705 | 0.648 | 0.695 | 0.694 |
| Trumpchi | 0.633 | 0.67 | 0.625 | 0.687 | 0.692 |
| Chevrolet | 0.709 | 0.68 | 0.622 | 0.66 | 0.698 |
| Citroen | 0.706 | 0.706 | 0.632 | 0.672 | 0.682 |
| Infiniti | 0.602 | 0.721 | 0.647 | 0.694 | 0.707 |
| SKODA | 0.606 | 0.605 | 0.610 | 0.625 | 0.631 |
| Porsche | 0.691 | 0.601 | 0.574 | 0.61 | 0.618 |
| HYUNDAI | 0.685 | 0.683 | 0.652 | 0.675 | 0.689 |
| Huachen Auto Group | 0.661 | 0.681 | 0.617 | 0.67 | 0.678 |
| Volvo | 0.658 | 0.742 | 0.689 | 0.74 | 0.748 |
| Mitsubishi | 0.672 | 0.67 | 0.583 | 0.641 | 0.653 |
| Subaru | 0.696 | 0.678 | 0.635 | 0.661 | 0.687 |
| SGMW | 0.713 | 0.707 | 0.669 | 0.69 | 0.708 |
| BAIC GROUP | 0.678 | 0.744 | 0.686 | 0.741 | 0.745 |
| Venucia | 0.751 | 0.691 | 0.648 | 0.694 | 0.697 |
| Cadillac | 0.663 | 0.759 | 0.695 | 0.737 | 0.759 |
| GEELY | 0.688 | 0.68 | 0.630 | 0.692 | 0.689 |
| SUZUKI | 0.545 | 0.71 | 0.668 | 0.707 | 0.716 |
| Jeep | 0.743 | 0.593 | 0.519 | 0.568 | 0.596 |
| ROEWE | 0.521 | 0.718 | 0.692 | 0.73 | 0.738 |
| LINCOLN | 0.708 | 0.556 | 0.476 | 0.525 | 0.521 |
| TOYOTA | 0.728 | 0.717 | 0.656 | 0.697 | 0.765 |
| NISSAN | 0.689 | 0.761 | 0.723 | 0.741 | 0.752 |
| KIA | 0.605 | 0.692 | 0.658 | 0.699 | 0.7 |
| Chery | 0.588 | 0.643 | 0.566 | 0.622 | 0.618 |
| HAVAL | 0.675 | 0.627 | 0.556 | 0.61 | 0.612 |
| Renault | 0.737 | 0.696 | 0.615 | 0.676 | 0.677 |
| LEXUS | 0.699 | 0.756 | 0.714 | 0.753 | 0.757 |
| Ford | 0.653 | 0.726 | 0.711 | 0.722 | 0.732 |
| BMW | 0.765 | 0.683 | 0.626 | 0.664 | 0.668 |
| MAZDA | 0.782 | 0.776 | 0.721 | 0.748 | 0.762 |
| Mercedes-Benz | 0.699 | 0.779 | 0.706 | 0.749 | 0.761 |
| BYD | 0.702 | 0.718 | 0.682 | 0.707 | 0.732 |
| FAW Haima | 0.747 | 0.78 | 0.675 | 0.735 | 0.744 |
| LAND ROVER | 0.648 | 0.703 | 0.657 | 0.698 | 0.706 |
| Volkswagen | 0.693 | 0.719 | 0.647 | 0.692 | 0.696 |
| CHANGAN | 0.671 | 0.67 | 0.601 | 0.657 | 0.661 |
| Morris Garages | 0.744 | 0.746 | 0.682 | 0.731 | 0.732 |
| mAP@50-95 | 0.687 | 0.701 | 0.646 | 0.688 | 0.698 |
| Times (ms) | 6.8 | 57.8 | 181.7 | 15.1 | 8.2 |
| Params (M) | 3.02 | 50.8 | 41.58 | 30.05 | 18.74 |
| FLOPS (G) | 8.2 | 237.2 | 134.45 | 87.6 | 55.4 |
| Model | Params (M) | FLOPS (G) | mAP@50 | mAP@50:95 |
|---|---|---|---|---|
| RT-DETR | 30.05 | 87.6 | 0.966 | 0.688 |
| RT-DETR + SlimNeck | 29.21 | 83.6 | 0.968 | 0.690 |
| RT-DETR + SlimNeck + SENetv2 | 29.85 | 83.6 | 0.976 | 0.698 |
| RT-DETR + SlimNeck + SENetv2 + CGBlock | 18.74 | 55.5 | 0.976 | 0.698 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, M.; Zhang, J. Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR). Sensors 2024, 24, 6987. https://doi.org/10.3390/s24216987
Jin M, Zhang J. Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR). Sensors. 2024; 24(21):6987. https://doi.org/10.3390/s24216987
Chicago/Turabian StyleJin, Meiting, and Junxing Zhang. 2024. "Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR)" Sensors 24, no. 21: 6987. https://doi.org/10.3390/s24216987
APA StyleJin, M., & Zhang, J. (2024). Research on Microscale Vehicle Logo Detection Based on Real-Time DEtection TRansformer (RT-DETR). Sensors, 24(21), 6987. https://doi.org/10.3390/s24216987