
GCS-YOLOv8: A Lightweight Face Extractor to Assist Deepfake Detection


Abstract
1. Introduction
- (1)
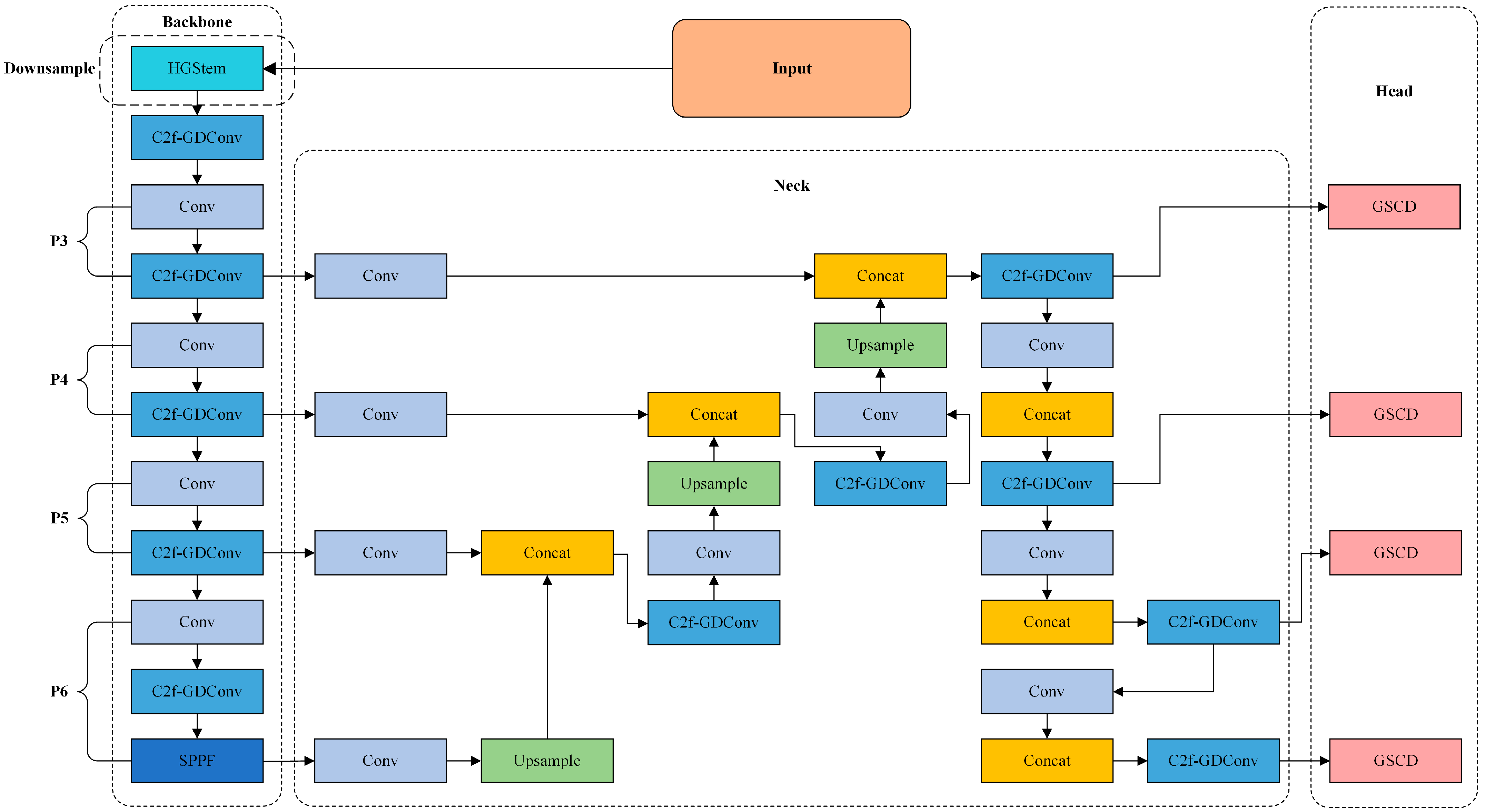
- In the Backbone section, we utilize HGStem to improve the original downsampling operation of the model, reducing false positives on small non-face objects. We also propose GDConv and integrate it with the C2f module to create the C2f-GDConv module, addressing the low-FLOPs pitfall and reducing model parameters. Additionally, we add a P6 large-object detection layer, expanding the model’s receptive field and enhancing its ability to learn multi-scale features. This allows for the accurate extraction of face information from highly compressed deepfake videos, improving performance.
- (2)
- In the Neck section, we design the cross-scale feature fusion module, CCFG, which effectively integrates features from different scales, improving the model’s adaptability to scale variations, reducing false positives on non-face areas, and significantly lowering model complexity. Compared to traditional face detectors, this makes the model more lightweight.
- (3)
- In the Head section, we propose a novel lightweight detection head called GSCD (Group Normalization and Shared Convolution Detect Head), which significantly improves accuracy in single-object detection tasks such as face detection, while effectively reducing the computational resources required by the model.
- (4)
- We refine the training dataset by removing low-accuracy small face labels, which enhances detection accuracy.
2. Related Work
2.1. Face Detection
2.2. YOLOv8
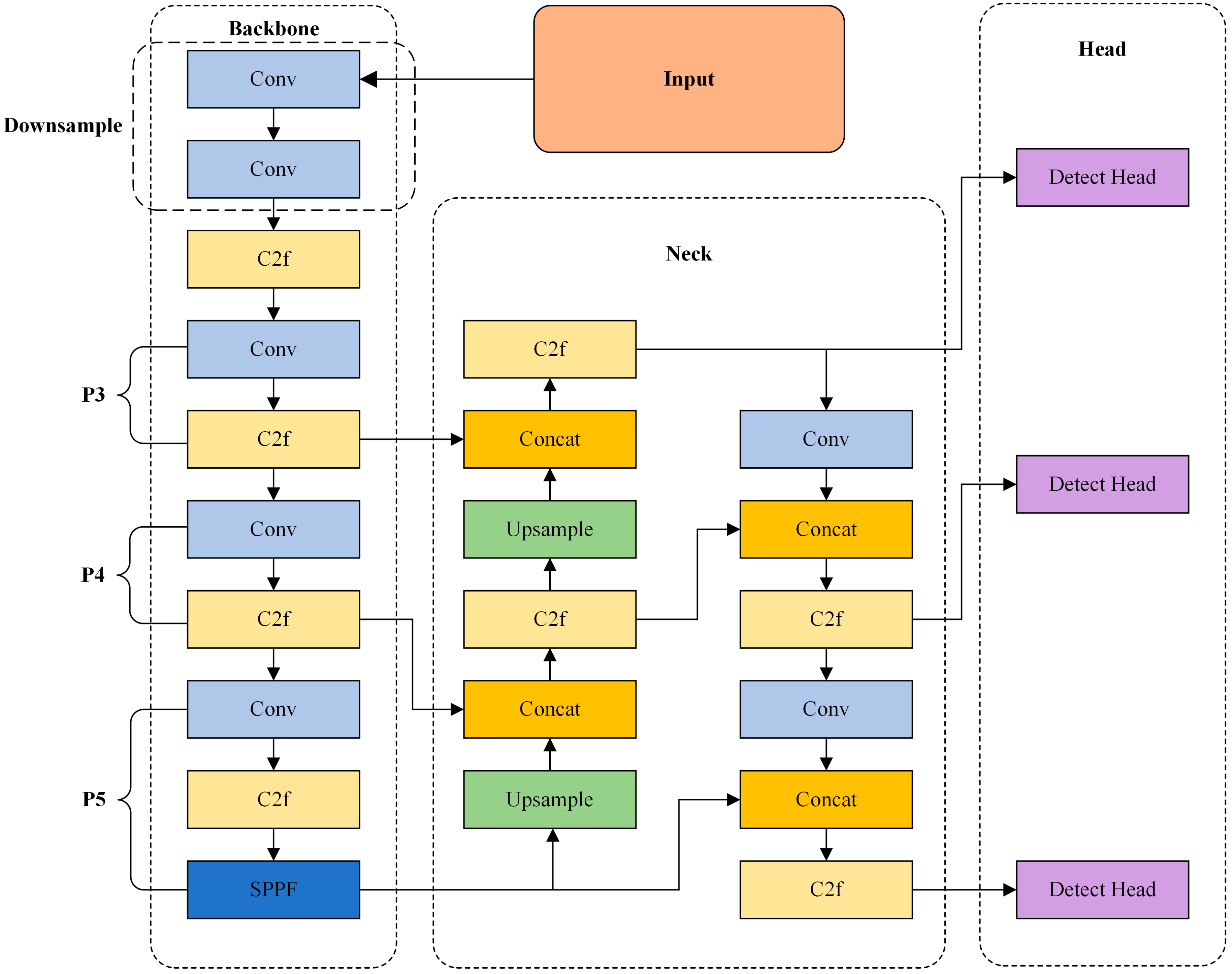
3. Methods
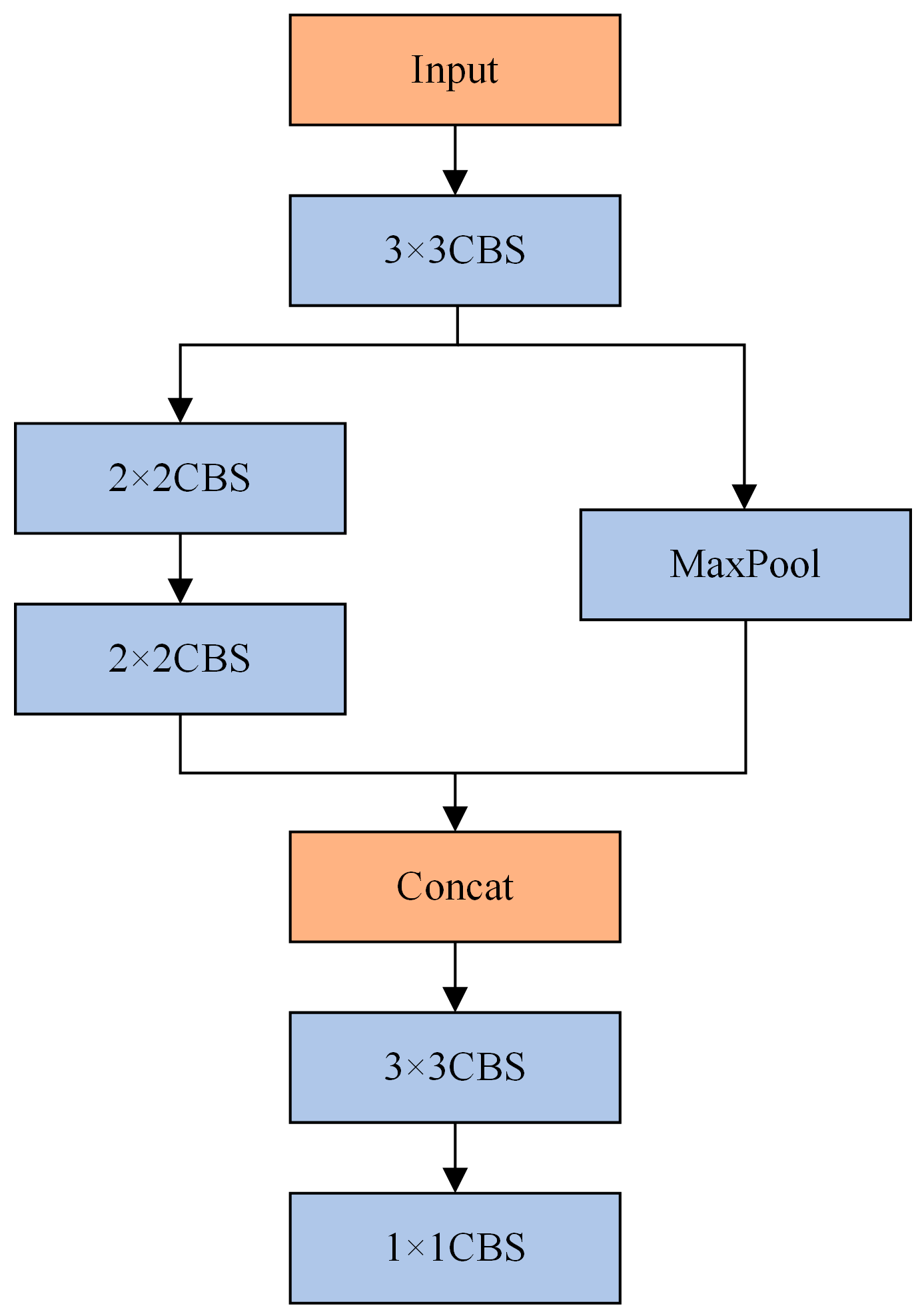
3.1. Downsampling Module HGStem
3.2. C2f-GDConv Module
3.3. P6 Large-Object Detection Layer
3.4. CCFG Module
3.5. GSCD Head
4. Experiments and Results Analysis
4.1. Experimental Environment and Training Parameter Configuration
4.2. Dataset Introduction and Improvements
4.2.1. Dataset Introduction
4.2.2. Dataset Improvements
4.3. Evaluation Metrics
4.4. Experimental Process and Results Analysis
4.4.1. Dataset Improvement Experiment
4.4.2. Module Comparison Experiments
4.4.3. Ablation Experiments
4.4.4. Comparison Experiments
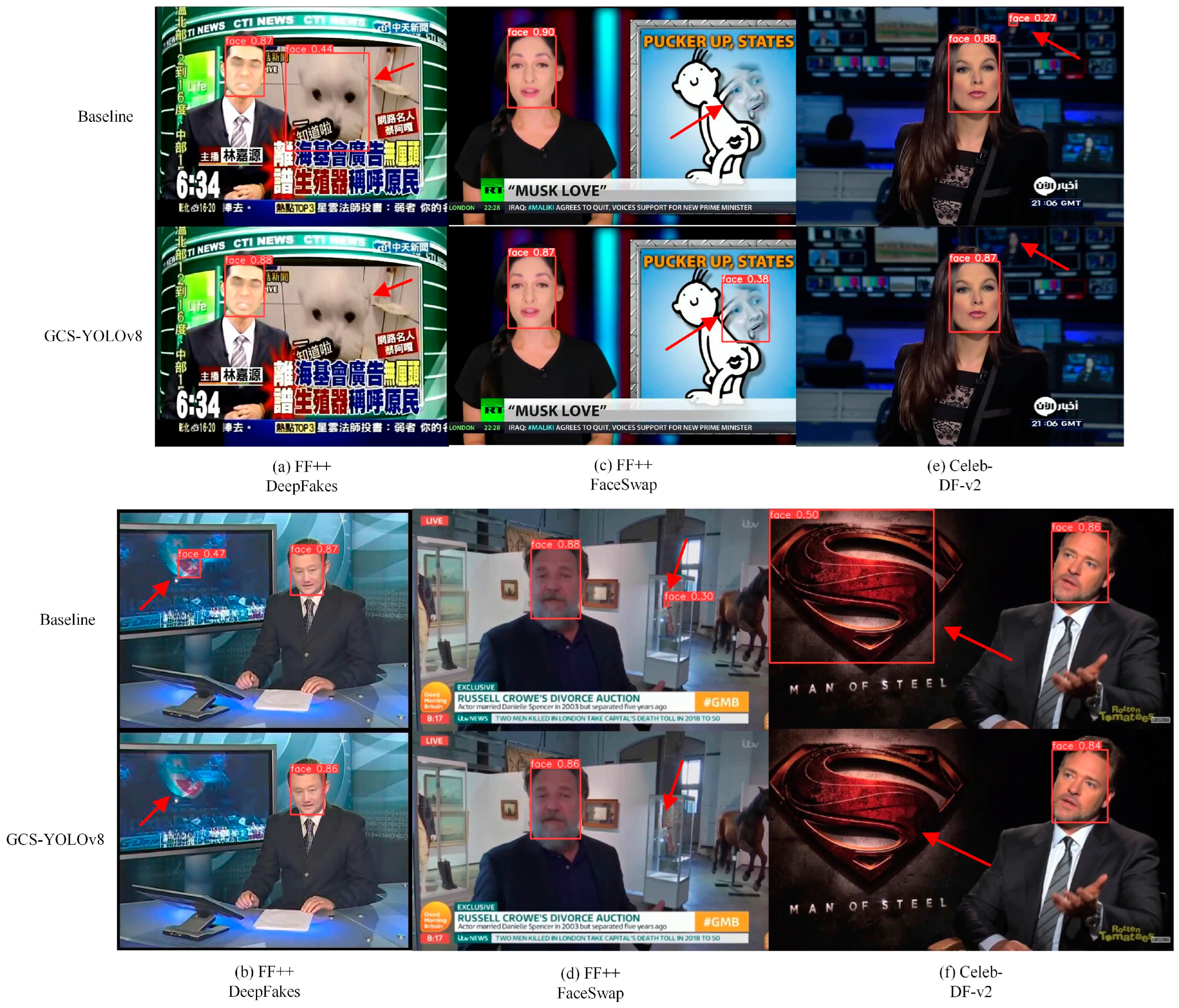
4.4.5. Visualization Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahmud, B.; Sharmin, A. Deep insights of deepfake technology: A review. arXiv 2020, arXiv:2105.00192. [Google Scholar] [CrossRef]
- Karaköse, M.; İlhan, İ.; Yetiş, H.; Ataş, S. A New Approach for Deepfake Detection with the Choquet Fuzzy Integral. Appl. Sci. 2024, 14, 7216. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Zhang, T. Deepfake generation and detection, a survey. Multimed. Tools Appl. 2022, 81, 6259–6276. [Google Scholar] [CrossRef]
- Hwang, Y.; Ryu, J.Y.; Jeong, S.H. Effects of disinformation using deepfake: The protective effect of media literacy education. Cyberpsychology Behav. Soc. Netw. 2021, 24, 188–193. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Chen, Y.; Wang, J.; Zhou, P.; Lai, J.; Wang, Q. A Robust and Efficient Method for Effective Facial Keypoint Detection. Appl. Sci. 2024, 14, 7153. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–12 June 2015; pp. 1440–1448. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Liu, Y.; Wang, F.; Deng, J.; Zhou, Z.; Sun, B.; Li, H. Mogface: Towards a deeper appreciation on face detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4093–4102. [Google Scholar]
- Xu, Y.; Yan, W.; Yang, G.; Luo, J.; Li, T.; He, J. CenterFace: Joint face detection and alignment using face as point. Sci. Program. 2020, 2020, 7845384. [Google Scholar] [CrossRef]
- Guo, J.; Deng, J.; Lattas, A.; Zafeiriou, S. Sample and computation redistribution for efficient face detection. arXiv 2021, arXiv:2105.04714. [Google Scholar] [CrossRef]
- Qi, D.; Tan, W.; Yao, Q.; Liu, J. YOLO5Face: Why reinventing a face detector. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 228–244. [Google Scholar]
- GitHub-Ultralytics/Ultralytics: NEW-YOLOv8 in PyTorch > ONNX > OpenVINO > CoreML > TFLite. Available online: https://github.com/ultralytics/ultralytics (accessed on 26 June 2024).
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Han, K.; Wang, Y.; Guo, J.; Wu, E. ParameterNet: Parameters Are All You Need for Large-scale Visual Pretraining of Mobile Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 15751–15761. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11030–11039. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A face detection benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5525–5533. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3207–3216. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beaci, CA, USA, 16–20 June 2019; pp. 1–11. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6153–6162. [Google Scholar]
- Zhong, J.; Chen, J.; Mian, A. DualConv: Dual convolutional kernels for lightweight deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9528–9535. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating spatial attention and standard convolutional operation. arXiv 2023, arXiv:2304.03198. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 10886–10895. [Google Scholar]
- GitHub-Derronqi/Yolov8-Face: Yolov8 Face Detection with Landmark. Available online: https://github.com/derronqi/yolov8-face (accessed on 26 June 2024).
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5203–5212. [Google Scholar]
- He, Y.; Xu, D.; Wu, L.; Jian, M.; Xiang, S.; Pan, C. LFFD: A light and fast face detector for edge devices. arXiv 2019, arXiv:1904.10633. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training parameters | Optimizer | SGD |
| Learning rate | 0.01 | |
| Momentum | 0.937 | |
| Weight decay | 0.005 | |
| Loss function | CIoU | |
| Batch size | 8 | |
| Epoch | 300 | |
| Experimental environment | Operation system | Windows 11 |
| CPU | i5-12600KF | |
| GPU | NVIDIA GeForce RTX 4070 | |
| Memory size | 32 GB DDR4 | |
| Programming language | Python 3.8.0 | |
| Module platform | Pytorch 2.0.1 + cuda 11.7 |
| Models | Easy Val AP | Medium Val AP | Hard Val AP |
|---|---|---|---|
| Baseline | 0.931 | 0.914 | 0.775 |
| Remove labels below 8-pixel | 0.94 | 0.921 | 0.754 |
| Remove labels below 7-pixel | 0.938 | 0.918 | 0.766 |
| Remove labels below 6-pixel | 0.936 | 0.917 | 0.782 |
| Remove labels below 5-pixel | 0.927 | 0.91 | 0.787 |
| Models | Easy Val AP | Medium Val AP | Hard Val AP | Parameters/MB | FLOPs |
|---|---|---|---|---|---|
| Baseline | 0.936 | 0.917 | 0.782 | 3.01 | 8.1 G |
| YOLOv8+HGStem | 0.941 | 0.925 | 0.795 | 3.00 | 7.9 G |
| YOLOv8+Adown [28] | 0.935 | 0.911 | 0.772 | 3.01 | 8.0 G |
| YOLOv8+V7Down [29] | 0.932 | 0.914 | 0.775 | 3.01 | 8.0 G |
| YOLOv8+C2f-GDConv | 0.931 | 0.917 | 0.775 | 2.18 | 7.9 G |
| YOLOv8+C2f-SCConv [30] | 0.927 | 0.911 | 0.762 | 2.86 | 7.9 G |
| YOLOv8+RepNCSPELAN4 [28] | 0.914 | 0.902 | 0.757 | 2.19 | 6.1 G |
| YOLOv8+C2f-DualConv [31] | 0.929 | 0.915 | 0.774 | 2.85 | 8.0 G |
| YOLOv8+CCFG | 0.932 | 0.915 | 0.794 | 1.96 | 6.6 G |
| YOLOv8+BiFPN [32] | 0.933 | 0.911 | 0.793 | 2.78 | 8.1 G |
| YOLOv8+GSCD | 0.939 | 0.92 | 0.788 | 2.36 | 6.5 G |
| YOLOv8+RFAHead [33] | 0.933 | 0.91 | 0.779 | 3.93 | 8.4 G |
| YOLOv8+DBBHead [34] | 0.93 | 0.919 | 0.785 | 5.91 | 11.7 G |
| Models | Easy Val AP | Medium Val AP | Hard Val AP | Parameters/MB | FLOPs | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | HGStem | C2f-GDConv | P6 | CCFG | GSCD | |||||
| √ | 0.936 | 0.917 | 0.782 | 3.01 | 8.1 G | |||||
| √ | √ | 0.941 | 0.925 | 0.795 | 3.00 | 7.9 G | ||||
| √ | √ | 0.931 | 0.917 | 0.775 | 2.18 | 5.8 G | ||||
| √ | √ | 0.94 | 0.921 | 0.787 | 4.78 | 8.1 G | ||||
| √ | √ | 0.932 | 0.915 | 0.794 | 1.96 | 6.6 G | ||||
| √ | √ | 0.939 | 0.92 | 0.788 | 2.36 | 6.5 G | ||||
| √ | √ | √ | 0.937 | 0.921 | 0.789 | 2.17 | 5.6 G | |||
| √ | √ | √ | √ | 0.939 | 0.925 | 0.793 | 3.61 | 5.8 G | ||
| √ | √ | √ | √ | √ | 0.938 | 0.925 | 0.803 | 2.20 | 4.6 G | |
| √ | √ | √ | √ | √ | √ | 0.942 | 0.927 | 0.812 | 1.68 | 3.5 G |
| Models | Easy Val AP | Medium Val AP | Hard Val AP | Parameters/MB | FLOPs |
|---|---|---|---|---|---|
| Baseline | 0.931 | 0.914 | 0.775 | 3.01 | 8.1 G |
| YOLO5Face | 0.936 | 0.915 | 0.805 | 1.73 | 2.1 G |
| YOLOv8Face | 0.945 | 0.922 | 0.79 | 3.08 | 8.3 G |
| SCRFD-2.5GF | 0.937 | 0.921 | 0.778 | 0.67 | 2.5 G |
| RetinaFace | 0.949 | 0.919 | 0.768 | 29.50 | 37.6 G |
| LFFD | 0.910 | 0.881 | 0.780 | 2.15 | 9.25 G |
| GCS-YOLOv8 (Ours) | 0.942 | 0.927 | 0.812 | 1.68 | 3.5 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Deng, B.; Cheng, X.; Zhao, H. GCS-YOLOv8: A Lightweight Face Extractor to Assist Deepfake Detection. Sensors 2024, 24, 6781. https://doi.org/10.3390/s24216781
Zhang R, Deng B, Cheng X, Zhao H. GCS-YOLOv8: A Lightweight Face Extractor to Assist Deepfake Detection. Sensors. 2024; 24(21):6781. https://doi.org/10.3390/s24216781
Chicago/Turabian StyleZhang, Ruifang, Bohan Deng, Xiaohui Cheng, and Hong Zhao. 2024. "GCS-YOLOv8: A Lightweight Face Extractor to Assist Deepfake Detection" Sensors 24, no. 21: 6781. https://doi.org/10.3390/s24216781
APA StyleZhang, R., Deng, B., Cheng, X., & Zhao, H. (2024). GCS-YOLOv8: A Lightweight Face Extractor to Assist Deepfake Detection. Sensors, 24(21), 6781. https://doi.org/10.3390/s24216781