1. Introduction
With the development of the Internet of Things (IoT), WSNs have become a primary technology for monitoring railway tunnels [
1,
2,
3]. WSNs consist of numerous sensors with sensing, computing, and communication capabilities [
4,
5,
6,
7,
8]. During monitoring, nodes are randomly deployed within the railway tunnel and periodically send data to the base station. Since internal batteries supply the energy for sensors, nodes will fail once the battery is depleted [
9]. Therefore, if energy consumption is imbalanced in the network, nodes may fail prematurely, leading to the network’s death [
10].
Researchers have conducted extensive studies to address this issue. One approach involves clustering the network, where many nodes are divided into multiple clusters, with specific nodes acting as cluster heads. These cluster heads are responsible for forwarding data to the base station, reducing direct communication between nodes and the base station, lowering network energy consumption, and extending the network lifespan [
11]. The key to clustering lies in how to elect cluster heads [
12], and current methods mainly rely on factors such as the remaining energy of nodes and the distance to the base station for election [
13,
14]. Furthermore, researchers have designed routing protocols to identify the optimal paths for data transmission, aiming to reduce energy consumption [
15,
16,
17].
In most cases, when monitoring railway tunnels, the nodes are arranged linearly, resulting in a linear topology known as an LWSN [
18,
19]. Compared with other types of WSNs, LWSNs exhibit fewer data transmission paths and lower network reliability due to their unique linear structure. Even the failure of a few nodes can lead to network disruption, especially in high-security railway tunnel monitoring scenarios. Therefore, traditional clustering and routing protocols based on WSNs are unsuitable for LWSNs. This paper proposes a self-organizing network and routing method based on an LWSN. After discovering the network topology, this method balances network energy consumption by optimizing network clustering and routing.
The main contributions of this paper are as follows:
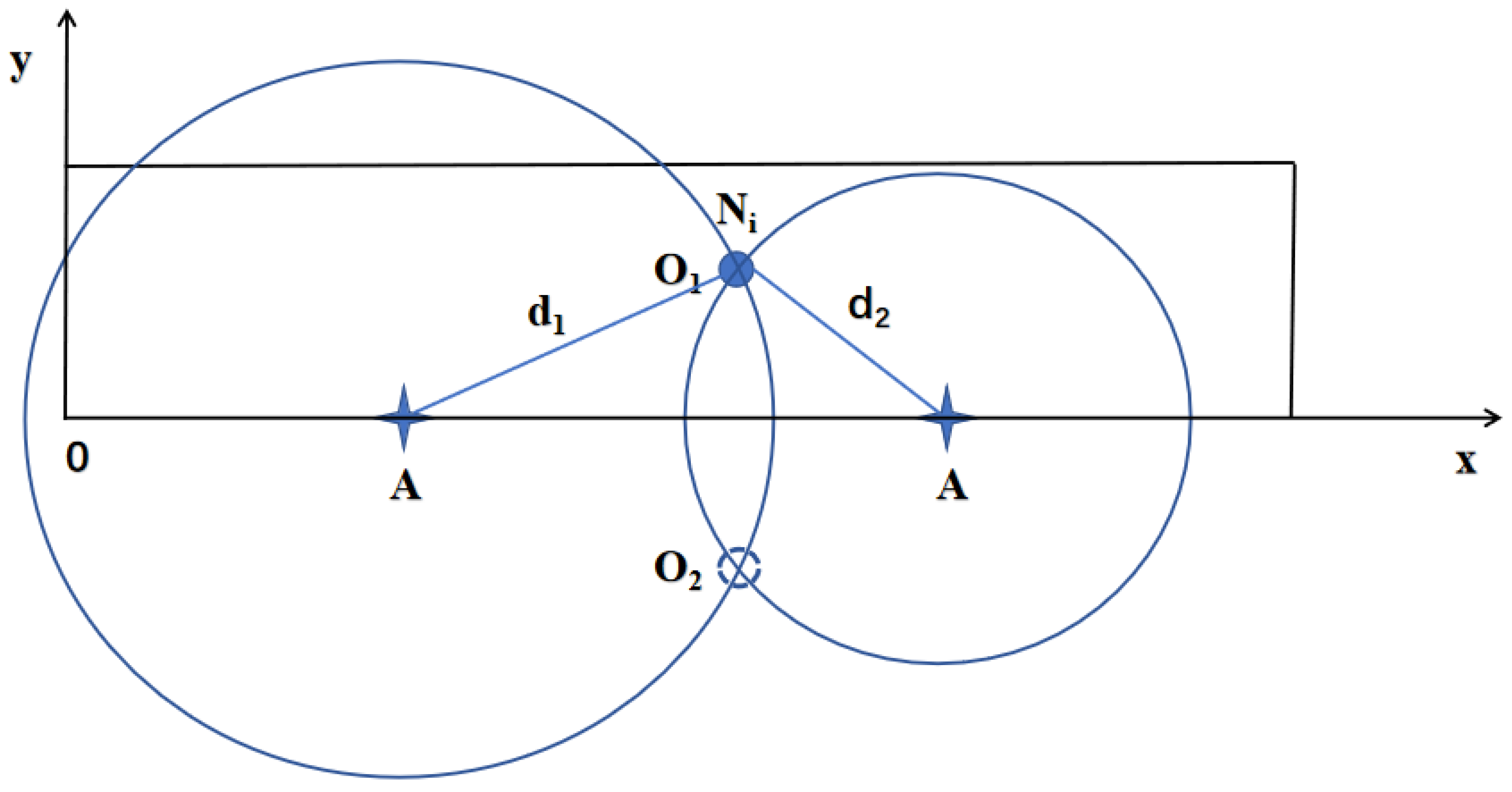
Network topology discovery is achieved using a small number of anchor nodes. By the triangular relationship between two anchor nodes and an unknown node, the position of the unknown node can be uniquely determined. We also identify the minimum number of anchor nodes required, reducing packet redundancy and network costs;
Set different communication radii for nodes to achieve unequal clustering, reducing the reconstruction energy of clusters closer to the sink. Moreover, a timing mechanism is used to select the optimal cluster head;
In routing, cluster heads closer to the sink transmit data directly to the sink in a single hop, and cluster heads further away from the sink calculate a selection value based on the energy factor, distance factor, and load factor of candidate cluster heads. Based on the computed selection values, choose the next-hop cluster head for multihop transmission.
The remainder of this paper is organized as follows.
Section 2 summarizes the related work.
Section 3 introduces the system model of this study.
Section 4 provides a detailed description of the implementation of the self-organizing method, including network topology discovery and clustering.
Section 5 elaborates on the design details of the routing protocol.
Section 6 compares the proposed method with the existing routing protocols.
Section 7 concludes the paper.
2. Related Work
Recently, researchers have conducted extensive studies on using WSNs to monitor railway tunnels [
20]. Since the nodes in the network are deployed randomly, network topology discovery before monitoring is necessary. In [
21], a cloud-orchestrated physical topology discovery scheme for large-scale IoT systems is proposed. It comprises two stages, logical topology discovery and three-dimensional localization. The scheme improves the efficiency and accuracy of logical topology discovery using the parallel Metropolis–Hastings random walk algorithm. It employs the discovered logical topology and multidimensional scaling method combined with drones for global three-dimensional localization. However, despite the high precision of existing methods, they also involve high costs and complexity. In railway tunnel monitoring, the deployed nodes are often resource-constrained, and this scheme has high computation, communication, and energy consumption requirements. It may not be suitable for such resource-limited environments, especially with the need for cloud coordination and parallel computing.
Due to the often unattended or harsh environments of monitoring areas, extending the lifespan of WSNs presents a significant challenge, with energy balance being a key factor determining network lifespan. Extensive research has been conducted on this. In [
22], a novel hybrid optimization algorithm, the Cuckoo Insisted–Rider Optimization Algorithm (CI-ROA) is proposed for cluster head selection in WSNs. The CI-ROA combines the advantages of the Rider Optimization Algorithm (ROA) and the Cuckoo Search Algorithm, aiming to significantly extend network lifespan by minimizing node distance, stabilizing energy, and reducing data transmission delay, but it may increase routing overhead. Although this strategy increases the algorithm’s complexity, it may also raise the difficulty of implementation and deployment, especially on resource-limited nodes. The algorithm’s performance is likely to be highly sensitive to the initial parameter settings. If the parameters are not chosen correctly, it may lead to suboptimal optimization results or even affect the network’s overall performance.
In [
23], an improved Stable Election Protocol–Energy Consider (SEP-EC) is proposed for multilevel heterogeneous WSNs. Building on the original SEP, this version extends its applicability to multilevel heterogeneous networks and introduces optimization based on node residual energy to enhance energy balance. The SEP-EC combines multipath routing with load energy balancing and link prediction mechanisms, effectively balancing network energy, reducing packet loss and delay, and improving routing discovery efficiency. However, it may lead to more difficulty in algorithm implementation and maintenance. Additionally, it overly relies on the optimization of heterogeneity between nodes. If the energy levels of the nodes in the network are relatively similar, the protocol’s advantages may be challenging to realize fully. The paper in [
24] proposes the Destination Oriented Routing Algorithm (DORA), which uses a mathematical analysis model to calculate the optimal transmission distance between any two nodes to minimize energy consumption and improve network efficiency. DORA selects the farthest forwarding node within the communication range based on this optimal distance. It constructs a multilink routing structure according to the direction toward the sink point, thereby effectively reducing energy loss. Moreover, the algorithm optimizes energy usage and extends network lifespan by employing a short-link strategy and dynamically adjusting the number of clusters and link configurations. However, DORA selects the farthest forwarding node within the communication range, which in some cases may increase the risk of packet transmission failure, especially when the communication environment between nodes is poor, or the channel quality is suboptimal, potentially leading to data loss or increased transmission delay. Although DORA optimizes energy usage by dynamically adjusting clusters and link configurations, these dynamic adjustments add to the algorithm’s execution overhead. Frequent adjustments, in particular, can increase communication and computation costs, impacting overall efficiency.
In [
25], a balanced multipath routing and hybrid transmission approach is proposed. This method jointly optimizes multipath, multihop, and single-hop transmissions to design multiple nonoverlapping shortest paths, ensuring that the load is evenly distributed within hot-spot areas and effectively avoiding energy concentration. The algorithm first calculates the optimal transmission path from each node to the receiver and determines the best path selection and transmission periods to achieve balanced energy distribution. However, in practical applications, some nodes may still bear excessive load because they are located at the intersection of multiple shortest paths, leading to localized energy depletion and affecting the overall lifespan of the network.
In [
26], an Improved Adaptive Ranking Energy-efficient Opportunistic Routing (I-AREOR) protocol is proposed to optimize energy efficiency in WSNs within Internet of Things (IoT) environments. The I-AREOR protocol selects optimal cluster heads by considering regional density, relative distance, and residual energy, effectively balancing energy consumption and maximizing network lifespan. The protocol adjusts energy parameters based on dynamic thresholds to extend the time until First Node Death (FND), Half Node Death (HND), and Last Node Death (LND). However, I-AREOR needs to dynamically adjust cluster head selection and energy parameters based on multiple factors (such as regional density, relative distance, and residual energy). This can increase computational overhead in resource-constrained sensor nodes, potentially affecting energy savings.
Selecting the optimal relay node is also crucial for balancing network energy. In [
27], a relay selection algorithm for energy harvest WSNs is proposed. This algorithm optimizes the cooperation probability and uses an outage probability threshold as a constraint to control the relay nodes involved in cooperative transmission, thus conserving system energy. A multicriteria relay selection strategy is employed to choose the optimal relay node by considering the nodes’ solar energy status, network energy balance, signal-to-noise ratio, and outage probability. However, in environments with unstable lighting conditions or insufficient solar energy, the solar energy status of nodes may not reliably reflect their actual energy levels, thereby affecting the accuracy of relay selection.
In summary, railway tunnel monitoring faces challenges such as high algorithm complexity, significant communication and computation overhead, and high parameter sensitivity. Therefore, this paper proposes a self-organizing network and routing method specifically for railway tunnel monitoring to balance network energy and extend network lifespan:
Given that a large number of nodes are randomly deployed in railway tunnel monitoring and that there is significant overlap in communication ranges, the precision requirements for localization are lower. In the topology discovery, this paper uses a small number of anchor nodes. It locates unknown nodes through geometric relationships while introducing a method for calculating the minimum number of anchor nodes. This approach significantly reduces communication losses between nodes and lowers network deployment costs, thus improving deployment efficiency.
In the network clustering phase, this method builds on existing uneven clustering by applying a timing mechanism for cluster head selection. The timing duration is determined based on the node’s remaining energy, adjacency (degree), and position. This approach effectively balances energy consumption between clusters and results in smoother changes in the number of clusters, thereby achieving better network stability.
Considering the linear characteristics of the monitoring targets and the significant distance differences between nodes and the sink, this method employs a hybrid transmission approach combining single-hop and multihop transmissions to reduce routing overhead. Furthermore, the next hop cluster head in multihop transmissions is determined based on the cluster head’s energy, distance, and load factors, further balancing energy consumption among nodes.
Overall, the proposed method effectively reduces the difficulty and cost of network deployment. Through comparison with existing classical methods, the results demonstrate that the proposed method in this paper has approximately doubled the network’s energy efficiency, effectively balanced network energy, and extended the network’s lifespan.
5. Energy Balanced Routing Protocol Based on Thick LWSN (EBRP-TL)
After each round of self-organization, ordinary nodes distributed across the monitoring area perceive the surrounding environment and transmit data to the base station for analysis, enabling real-time security monitoring of the entire monitoring area. During the intracluster routing phase, each node sends the data gathered to its respective cluster head via single-hop communication, and the cluster heads perform data fusion. We assume the packet size remains unchanged before and after data fusion is .
Due to the linear structure of the monitoring target, using a single-hop transmission approach for intercluster routing would result in significant energy consumption for cluster heads located far from the sink, demanding higher node power. Therefore, we employ a hybrid approach combining single-hop and multihop transmission methods. If the sink is within the communication radius of the cluster head, it directly transmits data to the sink via single-hop. Otherwise, the cluster head extends its communication radius three times to discover candidate cluster heads for the next hop. To ensure data forward transmission, the distance from candidate cluster heads to the sink must be less than that from the current cluster head node to the sink, as follows:
All nodes have the same initial energy, but their energy consumption differs due to their varying positions and surrounding connectivity. When selecting the next-hop cluster head node, priority should be given to those with higher remaining energy to protect nodes with lower energy from premature depletion and failure and help balance the network’s energy consumption. Therefore, the remaining energy of the nodes is a crucial factor in selecting the next-hop node, and the energy factor is defined as follows:
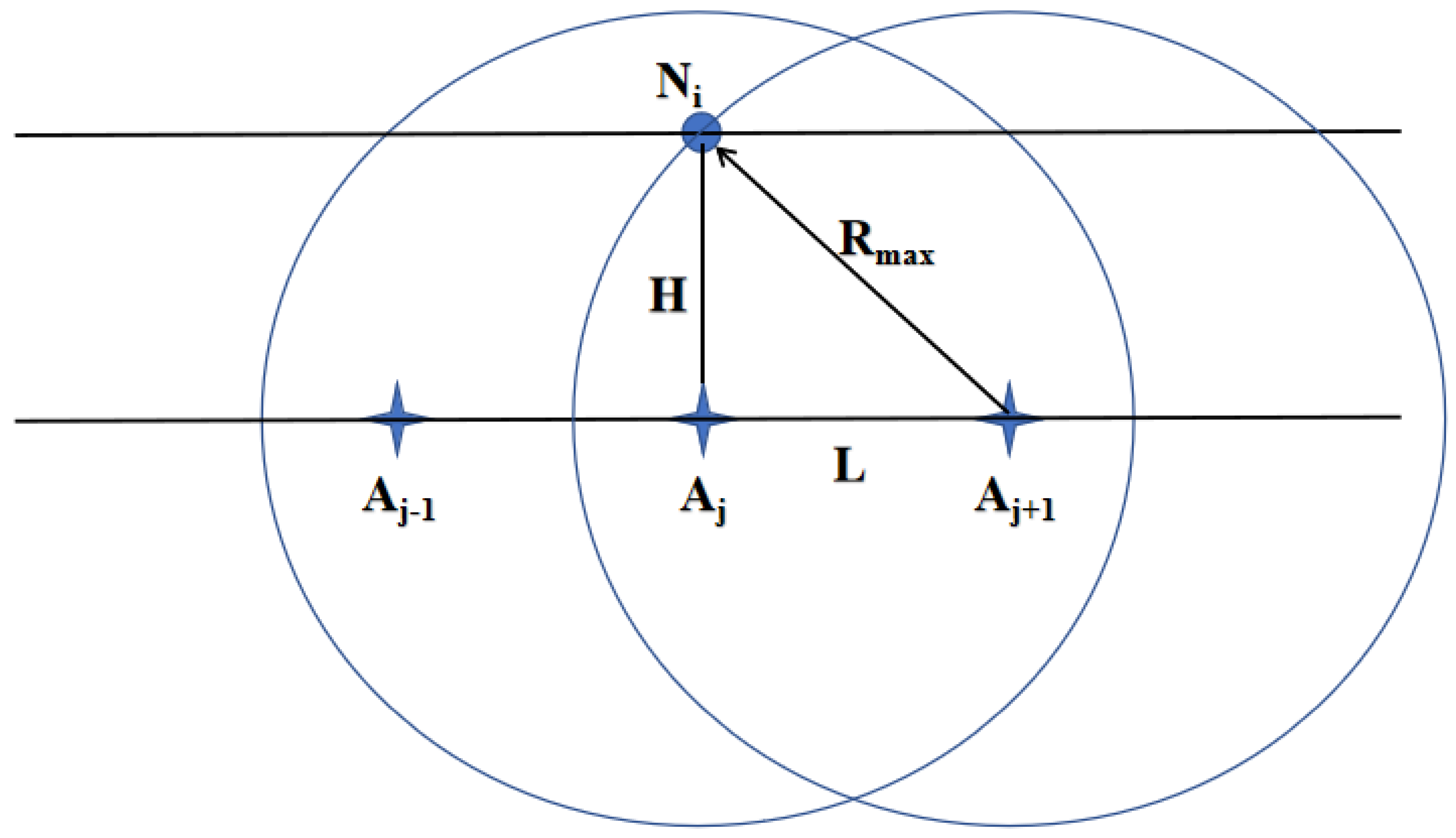
The transmission distance is an essential factor affecting node energy consumption. Under the same conditions, the farther the transmission distance, the more energy nodes consume. However, when monitoring linear infrastructure such as tunnels and bridges, where the length of the monitoring area is much greater than its width, as shown in
Figure 8, nodes
and
are candidate cluster heads for node
. In this case, the transmission distances from
through
and node
are almost equal. Therefore,
prefers to select node
as the next cluster head because this path involves fewer hops. Thus, those closer to the sink nodes are more likely to be chosen when selecting the next hop cluster head. The distance factor is defined as
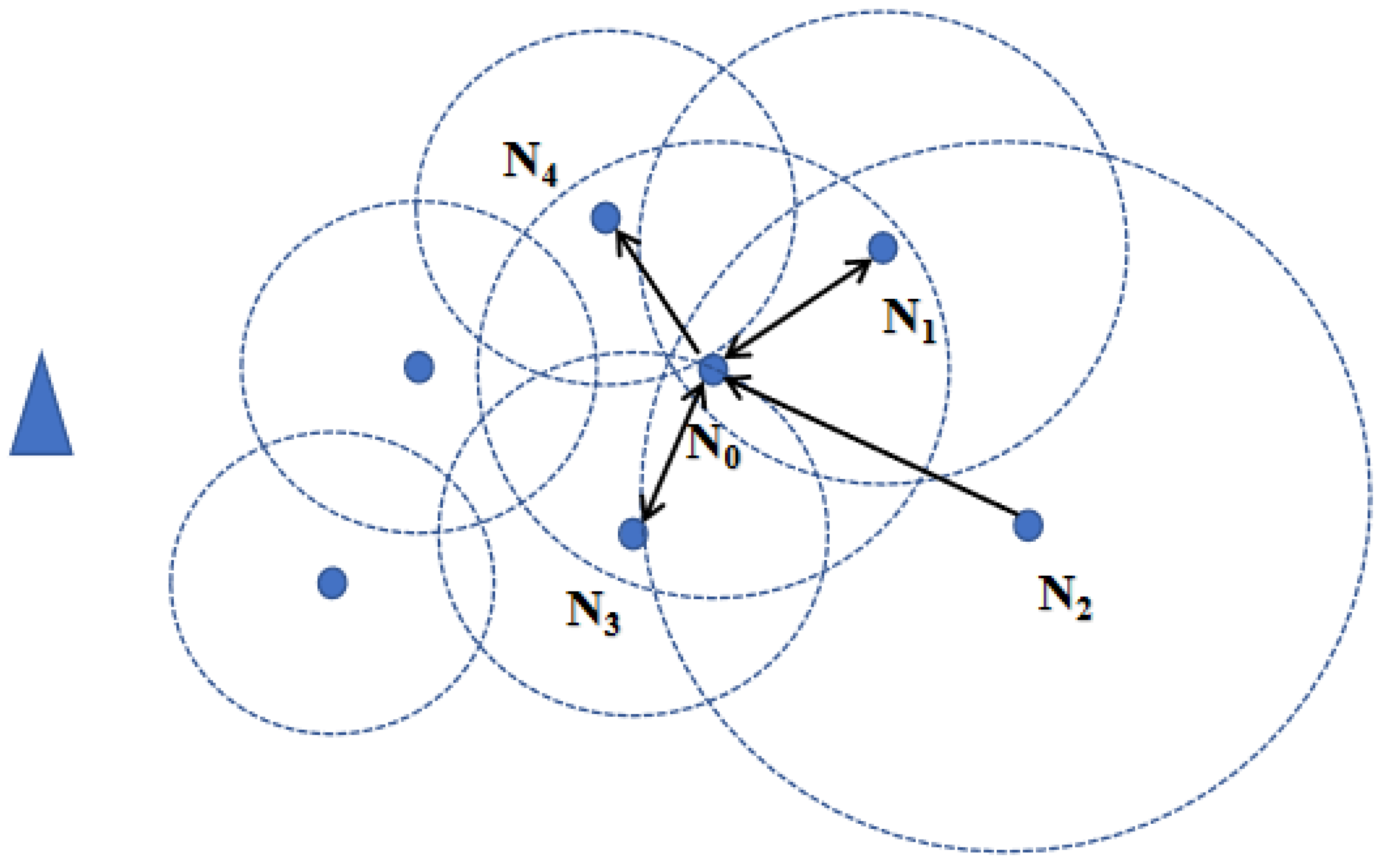
In intercluster routing, some cluster heads may be selected as next-hop nodes by multiple other cluster heads. This can lead to these nodes handling excessive data forwarding tasks in the current round, consuming too much energy and causing uneven energy distribution in the network. To prevent multiple nodes from choosing the same cluster head as the next hop, we define the load cluster heads in Formula (
16).
So, we choose cluster heads with fewer load cluster heads as the next hop nodes during the election process. The node’s load factor is as follows:
Here,
represents the maximum number of the load cluster heads among candidate cluster heads of
.
is the total number of cluster heads in the current round, calculated and communicated to all nodes by anchor nodes after clustering is completed.
We comprehensively consider the nodes’ energy, distance, and load factors, combining them into a selection value for choosing cluster heads. The cluster head
will select the candidate cluster head
with the highest selection value as the next-hop cluster head, and the definition of the selection value is as follows:
To elect the optimal next-hop cluster head, each cluster head node establishes a cluster head information table to calculate the selection value of candidate cluster heads and to inform other nodes about its information.
Table 1 describes the relevant information on the cluster heads. Cluster heads broadcast the first four types of information in data packets and calculate the remaining information to add to their information table upon receiving packets from other cluster heads.
6. Test and Analysis of Results
We conducted simulation experiments using Python to verify the effectiveness of the proposed method. Additionally, we compare the routing protocol proposed with the classical routing protocols LEACH, E-LEACH, and EEUC under identical conditions. In our experiments, we randomly deploy 200 sensor nodes within a 600 m × 30 m monitoring area, with the sink node located at the center of the left edge of the region. To validate the robustness and reliability of the method, we set up two scenarios for the experiment: in Scene I, the sink is located at
, and in Scene II, the sink is located at
. The results in both scenarios are similar, so we use Scene I as an example for the explanation.
Table 2 provides detailed parameter settings for the experiments.
After the topology discovery phase, the network enters the clustering stage.
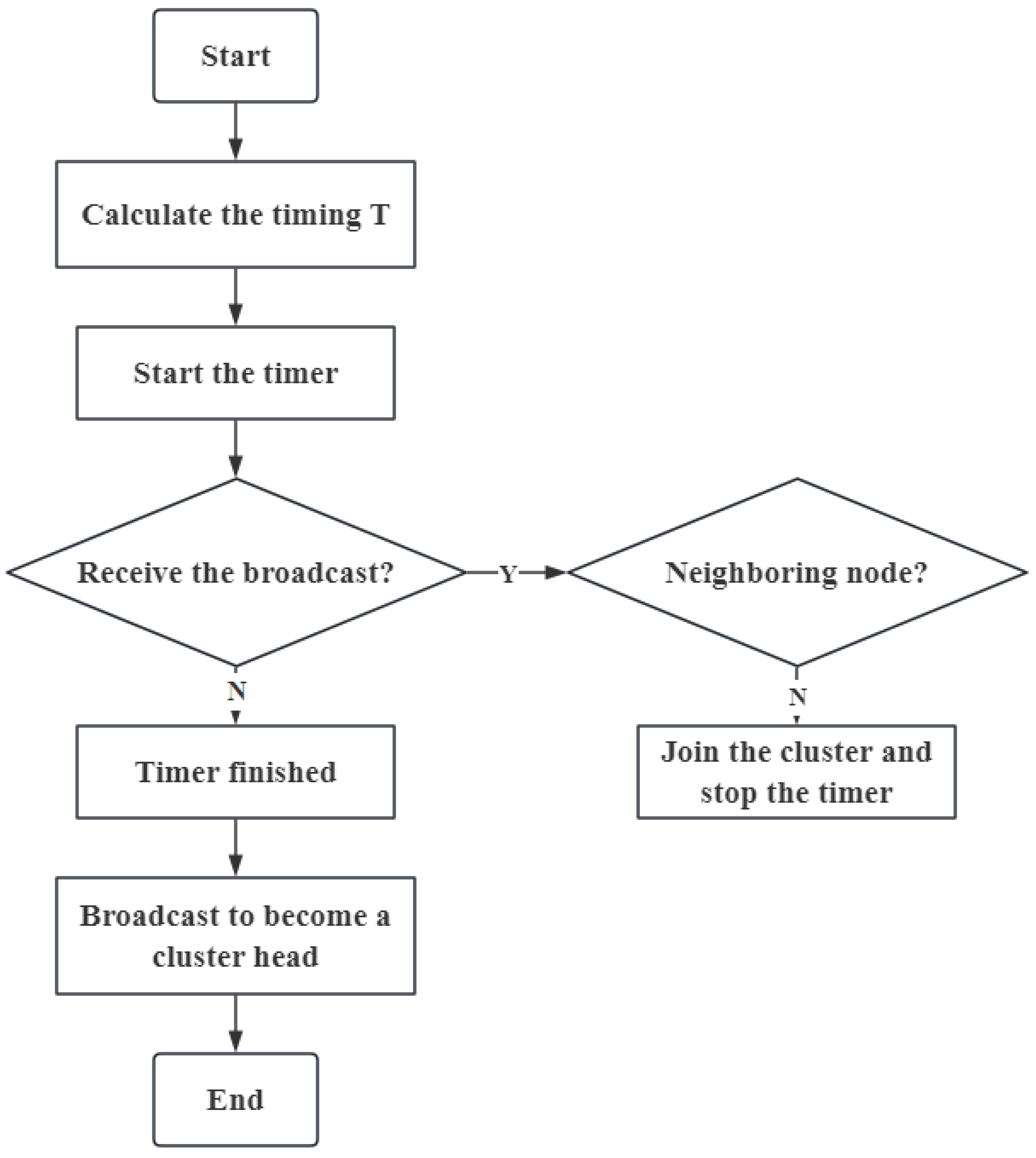
Figure 9 presents the flowchart of nodes participating in the cluster head competition by using the timing Formula (
12).
When the timer starts, nodes will enter the receiving state. If they receive a broadcast from other nodes becoming cluster heads before the timer ends, they will decide whether to join the cluster based on whether those nodes are their neighboring nodes. If no broadcasts are received by the end of the timer, the node will send out a broadcast to become a cluster head.
In the cluster head election process, we set each node’s timer duration
according to Formula (
12). In this equation, the timer duration
is influenced by the node’s remaining energy, node degree, and the distance to the sink, where
,
, and
represent their respective impact coefficients on
. The more residual energy the nodes have, the higher node degrees the nodes have, the greater the competition radius is, the shorter the set time is, it is more likely to become a cluster head. Timing began, and some nodes successively became cluster heads. In the early stages of the network’s operation, the energy levels between nodes are relatively balanced, and the timer duration is mainly determined by the distance from the node to the sink. After the network has been operating for a while, the nodes consume some energy, leading to an uneven energy distribution. At this point, the energy coefficient
is dominant. The impact of node degree is minimal, just in the clustering process, cluster heads with higher degrees can prevent the number of clusters in the network from becoming too large. Therefore, in the experiments, the values of
and
are relatively large.
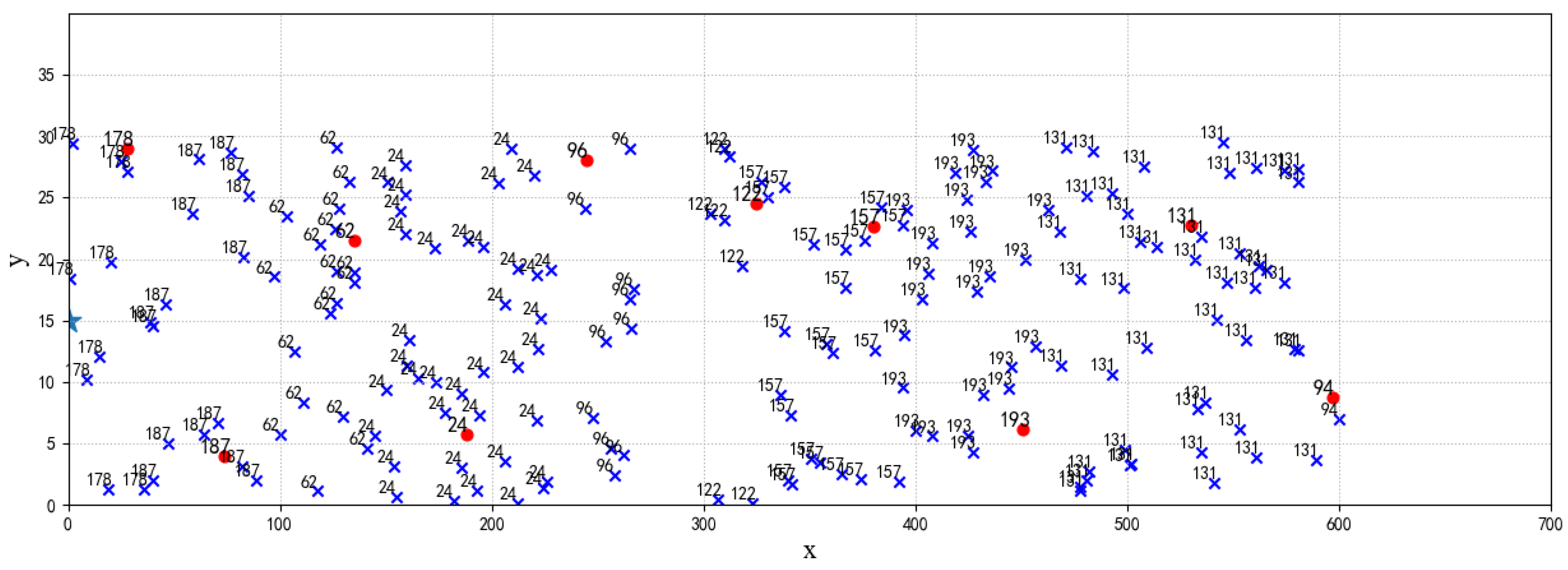
The cluster distribution in
Figure 10 illustrates a round of network clustering. We unevenly distribute clusters by Formula (
10), resulting in nodes farther from the sink having larger communication radii and thus forming larger clusters. For instance, node
is farther from the sink than
, and its cluster covers a larger area. However, network clusters use the timing mechanism where cluster head election considers factors such as remaining node energy, node degree, and distance to the sink. Node
might have a shorter timer duration and become a cluster head earlier than node
, resulting in surrounding nodes joining its cluster first. So it forms a smaller cluster despite node
being farther from the sink than node
. This clustering approach reduces energy consumption within clusters closer to the sink, preserving energy for intercluster forwarding and balancing the network energy consumption.
After clustering is complete, the surviving nodes will begin monitoring. In each round of network operation, each node will send a monitoring data packet to its cluster head only once. In intracluster routing, nodes send data to the cluster head using a single-hop method, and the cluster head fuses the data. In intercluster routing, the cluster head decides on the transmission method based on the distance to the sink. The operational details of the cluster head in intercluster routing are provided in Algorithm 1. During intercluster routing, the communication radius of the cluster head is expanded to three times its original size. If the sink is within this communication radius, single-hop transmission occurs. Otherwise, the cluster head will collect information about its candidate cluster heads. The candidate cluster heads are closer to the sink, and the cluster head will select the best candidate cluster head as the next hop for multihop transmission based on Formula (
18).
| Algorithm 1: Intercluster Routing Algorithm |
![Sensors 24 06502 i001]() |
When the energy consumption in a network becomes unbalanced, some nodes may prematurely exhaust their energy and fail. Therefore, to assess whether a network’s energy is balanced, one can evaluate the time the first node fails, reflecting the advantage of a routing protocol in balancing energy. The method proposed in this paper is suitable for the thick LWSNs in monitoring infrastructures such as railway tunnels and bridges. Hence, the number of failed nodes in the network had better be at most
of the total number of nodes for ensuring safety.
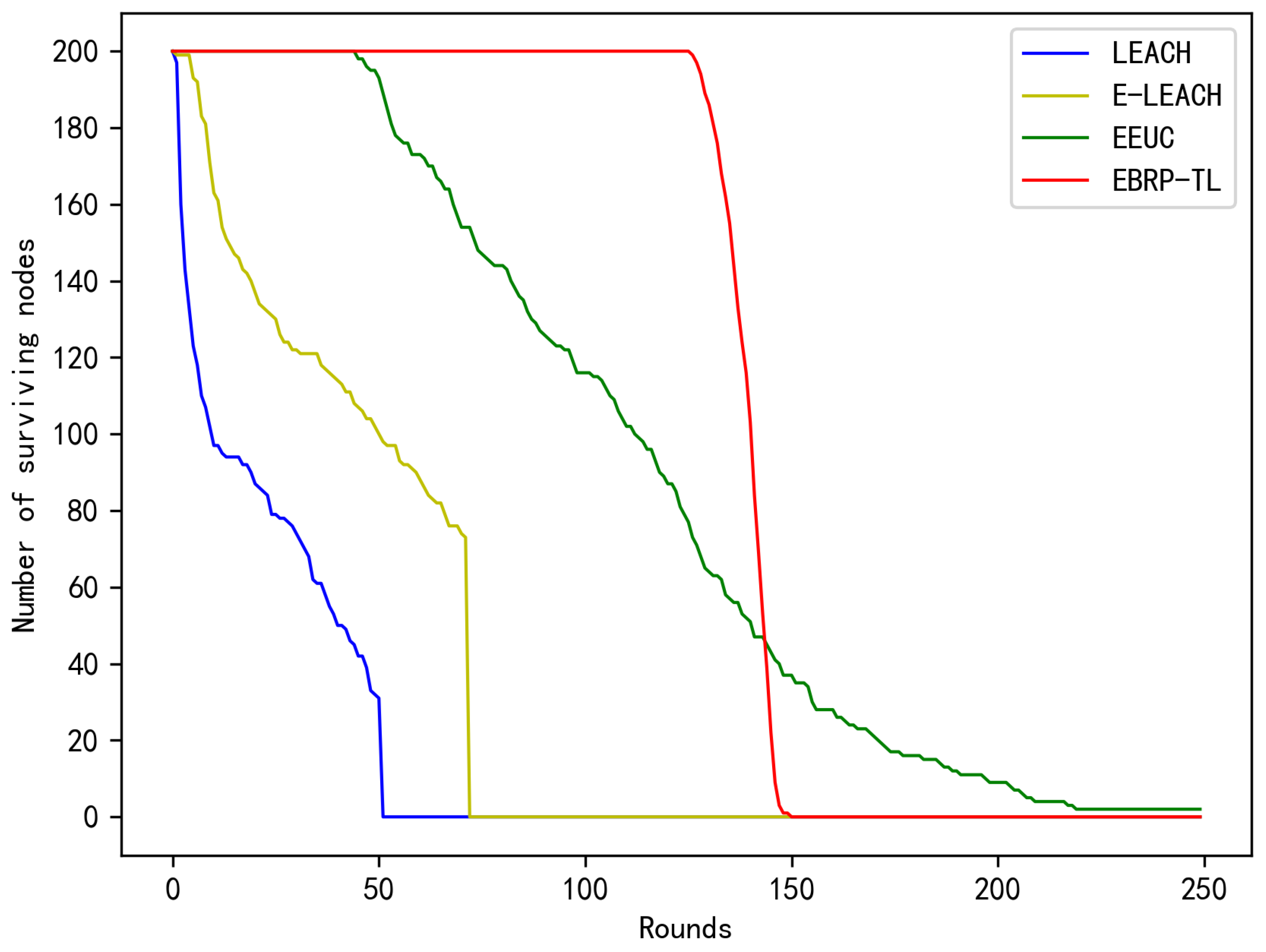
Figure 11 compares the changes in total surviving nodes across different rounds for the LEACH, E-LEACH, EEUC, and EBRP-TL. With the LEACH protocol, the network experiences the first node failure early, and the death of the network is faster, primarily due to the randomness in cluster head election and the energy consumption from single-hop transmissions. E-LEACH improves upon LEACH by considering the node’s energy during cluster head election and reduces energy consumption during intercluster data transmission by introducing a root cluster head. As a result, it offers improvements compared with LEACH. The EEUC protocol conducts unequal clustering. Moreover, it utilizes a mix of single-hop and multihop transmissions, resulting in FND occurring only after approximately 50 rounds. In the EBRP-TL, cluster heads are elected based on node degree and distance to the sink. The protocol selects the optimal next-hop cluster head during intercluster routing. As a result, the protocol experiences its FND around 130 rounds, with only about 20 rounds passing between the first and last node failures. This demonstrates that the protocol achieves more balanced energy consumption among network nodes, extending the network’s lifespan.
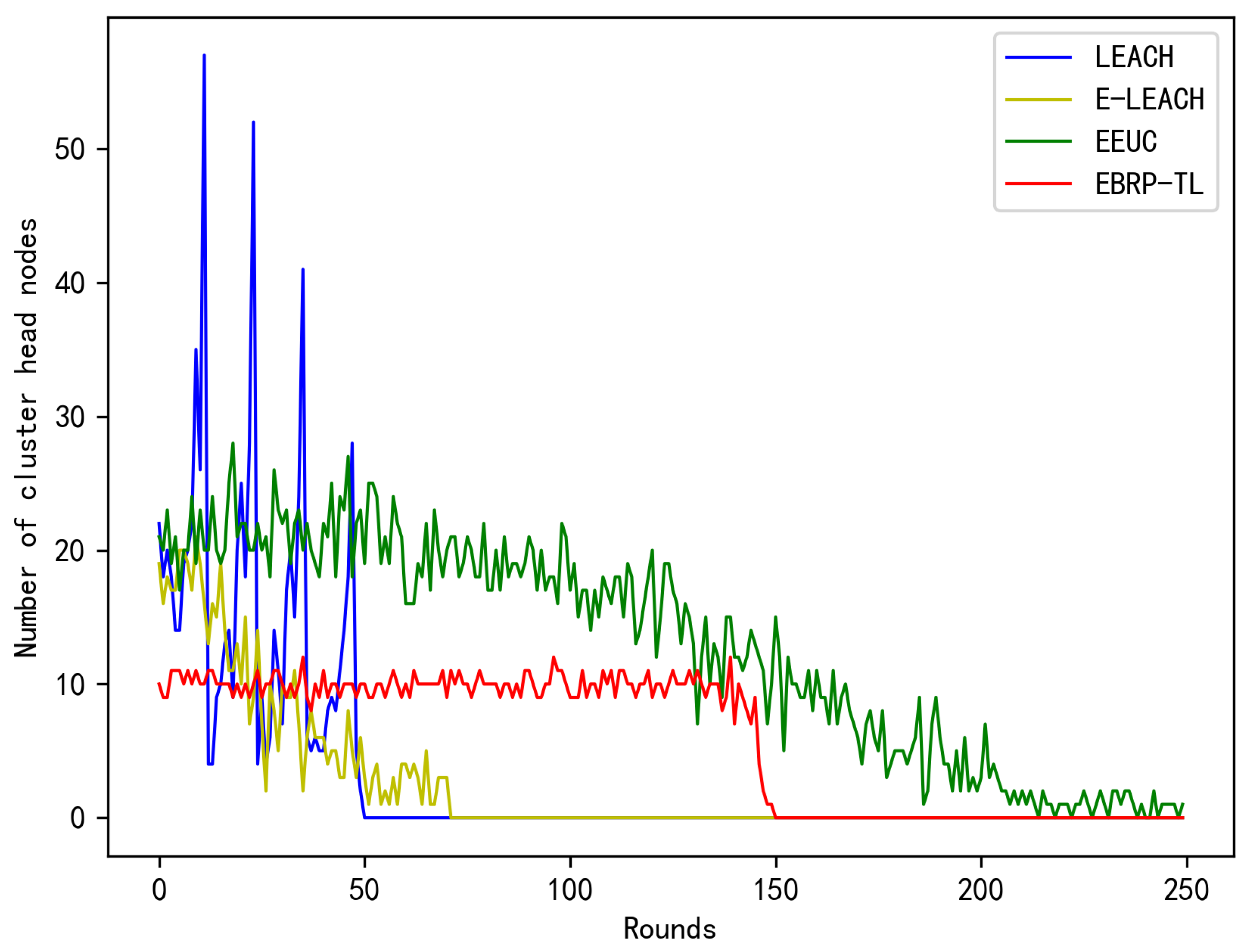
The number of clusters, or the number of cluster heads, is a crucial indicator for assessing network performance. Significant fluctuations in the number of cluster heads indicate substantial differences in energy consumption per round, leading to network imbalance and lower performance. The document in [
30] proved that when the number of clusters reaches
to
of the total number of nodes, the network’s energy efficiency is at its highest. In this paper, the number of nodes is 200, so we assume that the network’s energy efficiency is highest when the number of cluster heads is at
.
Figure 12 shows how the number of cluster heads varies with network rounds for three different protocols under the same conditions. In the LEACH protocol, where cluster heads are selected randomly, the number of cluster heads fluctuates considerably. Additionally, due to the rapid failure of nodes, the overall number of cluster heads shows a downward trend. E-LEACH takes the remaining energy of nodes into account during cluster head election, resulting in a significant reduction in the number of cluster heads. However, due to the inherent randomness in the cluster head election process, there is still considerable variation in the number of cluster heads. In contrast, while EEUC maintains a relatively stable number of cluster heads, this number is close to
of the total number of nodes, leading to lower energy efficiency. In contrast, EBRP-TL utilizes a timing mechanism for cluster head election based on uneven clustering, considering nodes’ remaining energy, degree, and distance to the sink. Nodes prioritized to become heads will have neighboring nodes within their communication radius join their cluster. This causes some nodes that might have become cluster heads to join clusters that broadcast earlier, electing the optimal cluster head and effectively controlling the number of clusters. As a result, the number of cluster heads corresponding to EBRP-TL in the graph remains around
of the total number of nodes, which is the optimal number of cluster heads.
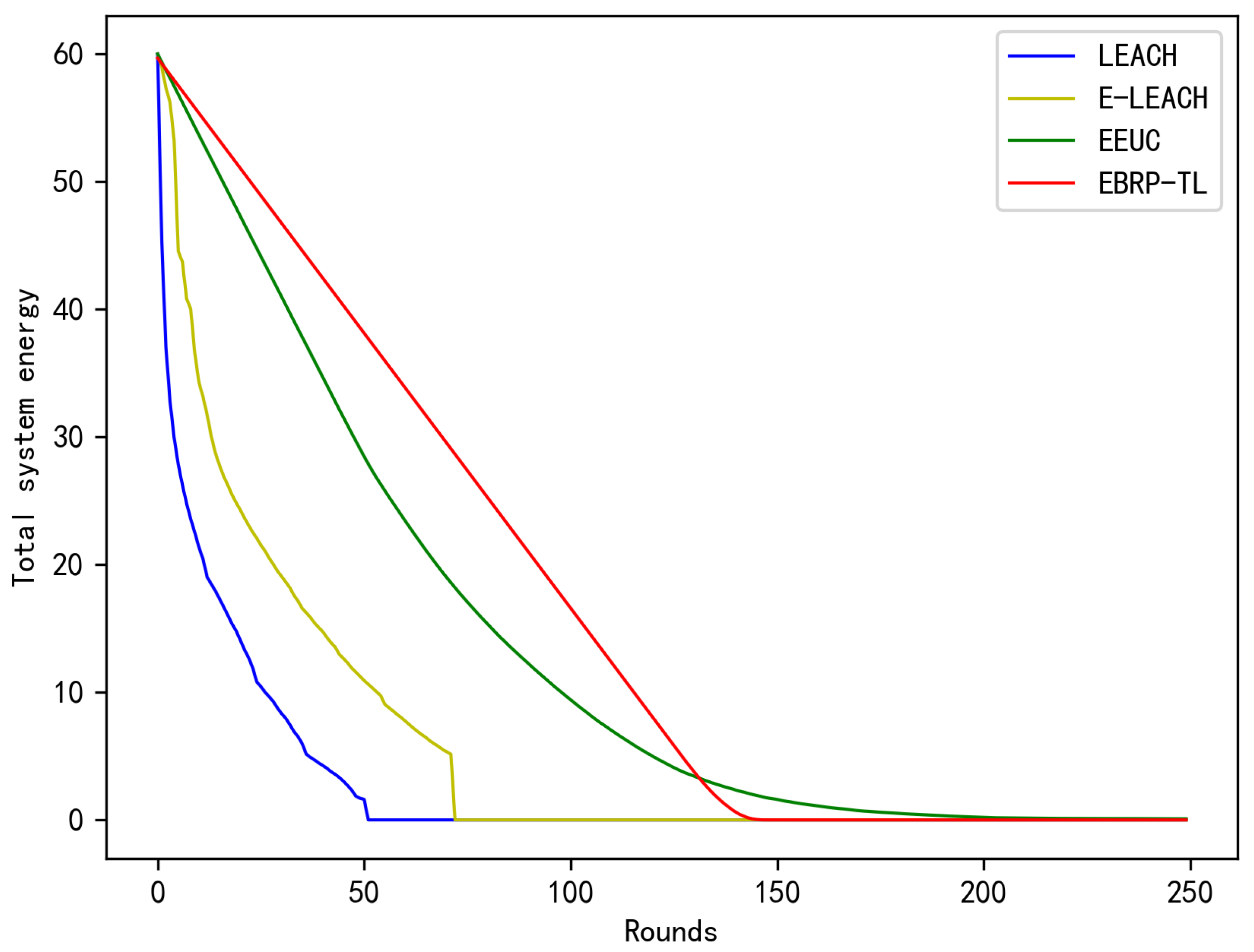
To visually compare the energy balance differences among the three protocols, we analyzed how the total network energy changes with each round under different protocols. As shown in
Figure 13, the initial total energy of the network is
, and the curve’s slope represents the energy change rate. Obviously, with the EBRP-TL, the network’s energy decreases almost uniformly, meaning the energy consumption per round is nearly equal. This result is consistent with the findings from the previous two experiments and further validates EBRP-TL’s advantage in energy balance.
The energy utilization rate refers to the ratio of energy consumed by the network during operation to the initial total energy. When the network experiences energy imbalance, the failure of a few nodes can disrupt regular network operation. However, the remaining nodes retain significant energy, leading to a decrease in energy utilization rate. After calculations, until the occurrence of 20 failed nodes ( of total nodes), LEACH achieves an energy utilization rate of , E-LEACH reaches , and EEUC reaches , whereas EBRP-TL reaches a high efficiency of .
In summary, multiple experiments were conducted in different scenarios to compare the proposed method with existing classical protocols regarding FND, the number of cluster heads, and energy consumption. The results show that with EBRP-TL, the network experiences the latest FND, occurring after 130 rounds. The number of cluster heads consistently remains around
of the total nodes, and the total network energy decreases uniformly with each round. This result is expected because, during clustering, we not only adopted the existing unequal clustering method to reduce the reclustering energy of cluster head nodes closer to the sink but also introduced a timing mechanism. This mechanism determines the order in which nodes become cluster heads by Formula (
12). Additionally, the timing mechanism ensures that the nodes prioritized as cluster heads absorb all neighboring nodes into their cluster, preventing the creation of closely spaced clusters, which would result in an excessive number of redundant clusters. During the routing phase, we selected the optimal next-hop cluster head for cluster heads far from the sink based on Formula (
18), considering the cluster head’s energy, load, and location. This effectively protects low-energy, heavily loaded cluster heads and ensures the forward transmission of data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}