
Click to Correction: Interactive Bidirectional Dynamic Propagation Video Object Segmentation Network


Abstract
1. Introduction
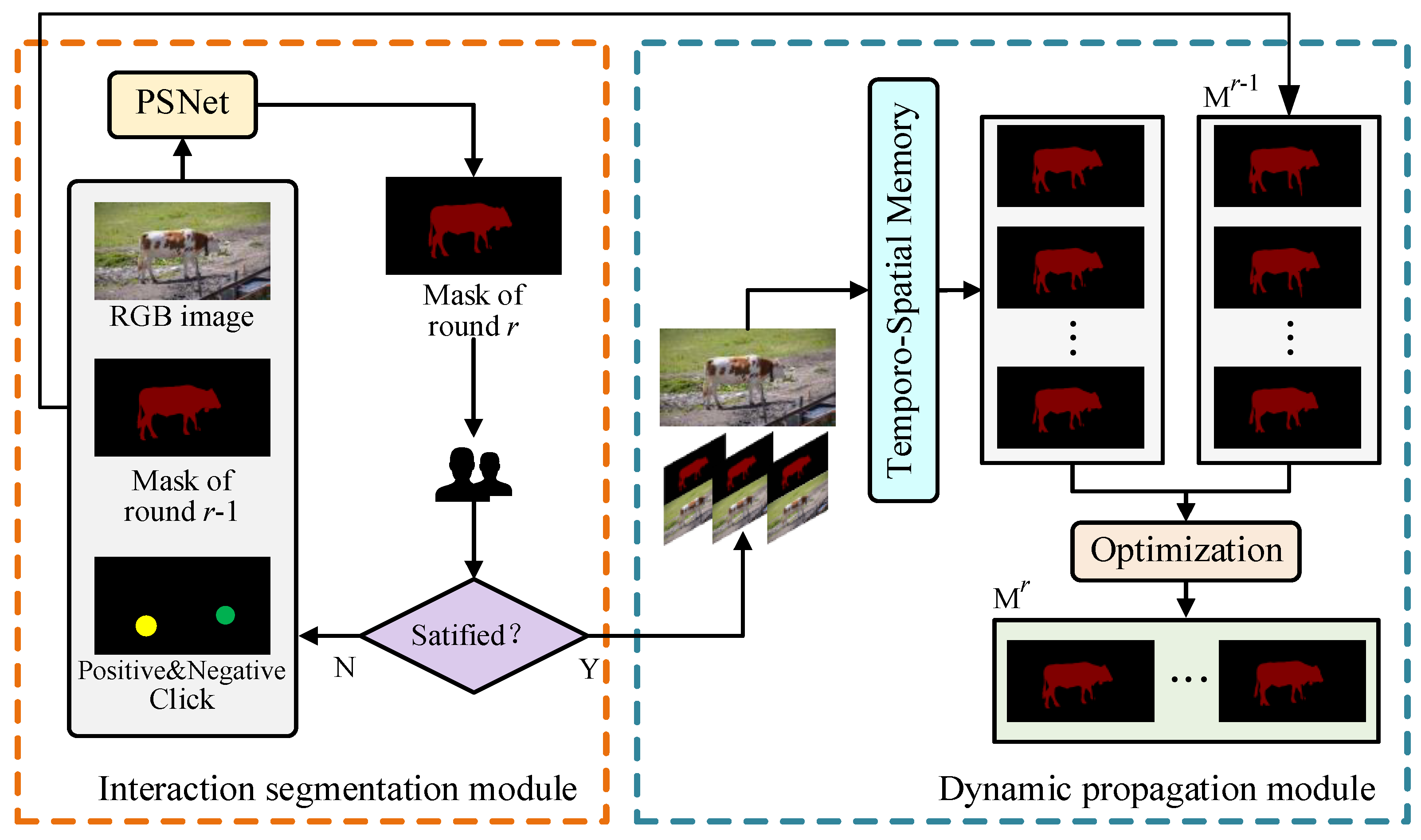
2. Methods
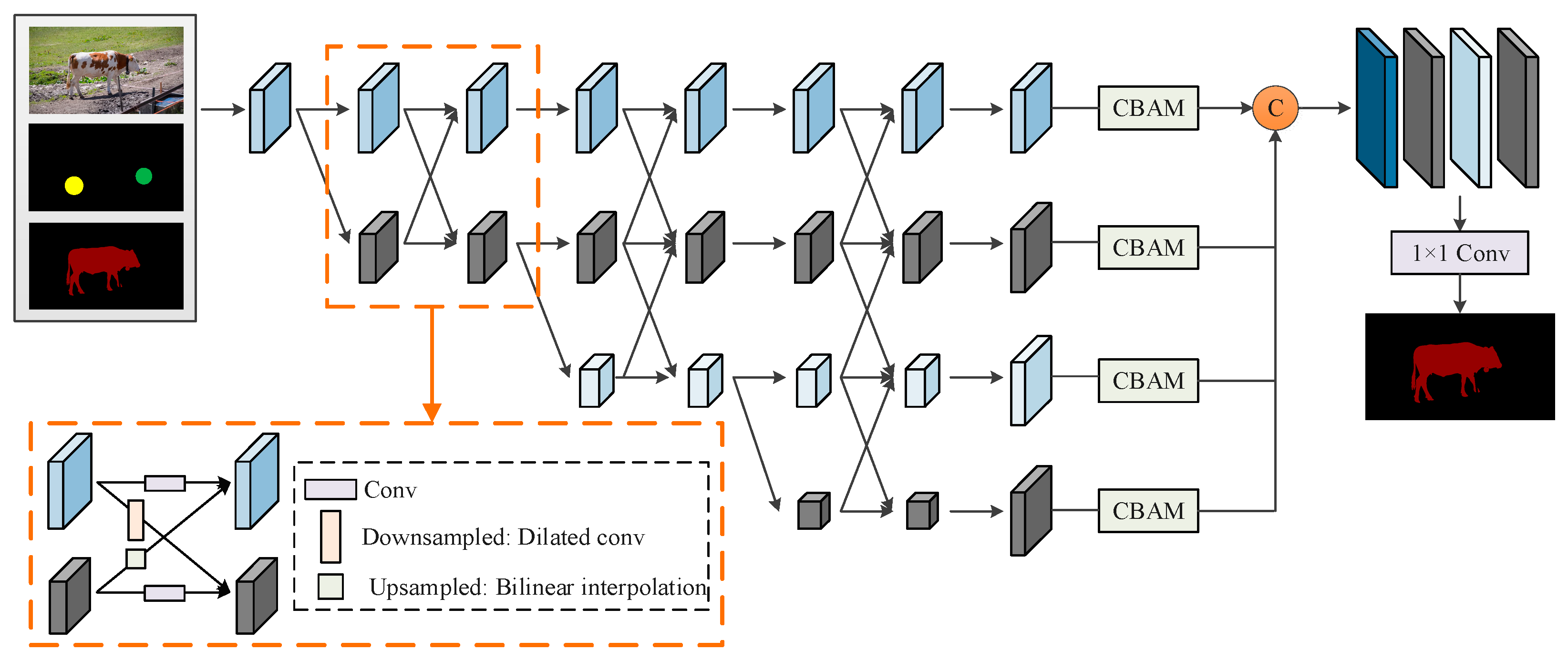
2.1. User Interaction Segmentation Module
2.2. Dynamic Propagation Module
2.2.1. Temporo-Spatial Memory Network
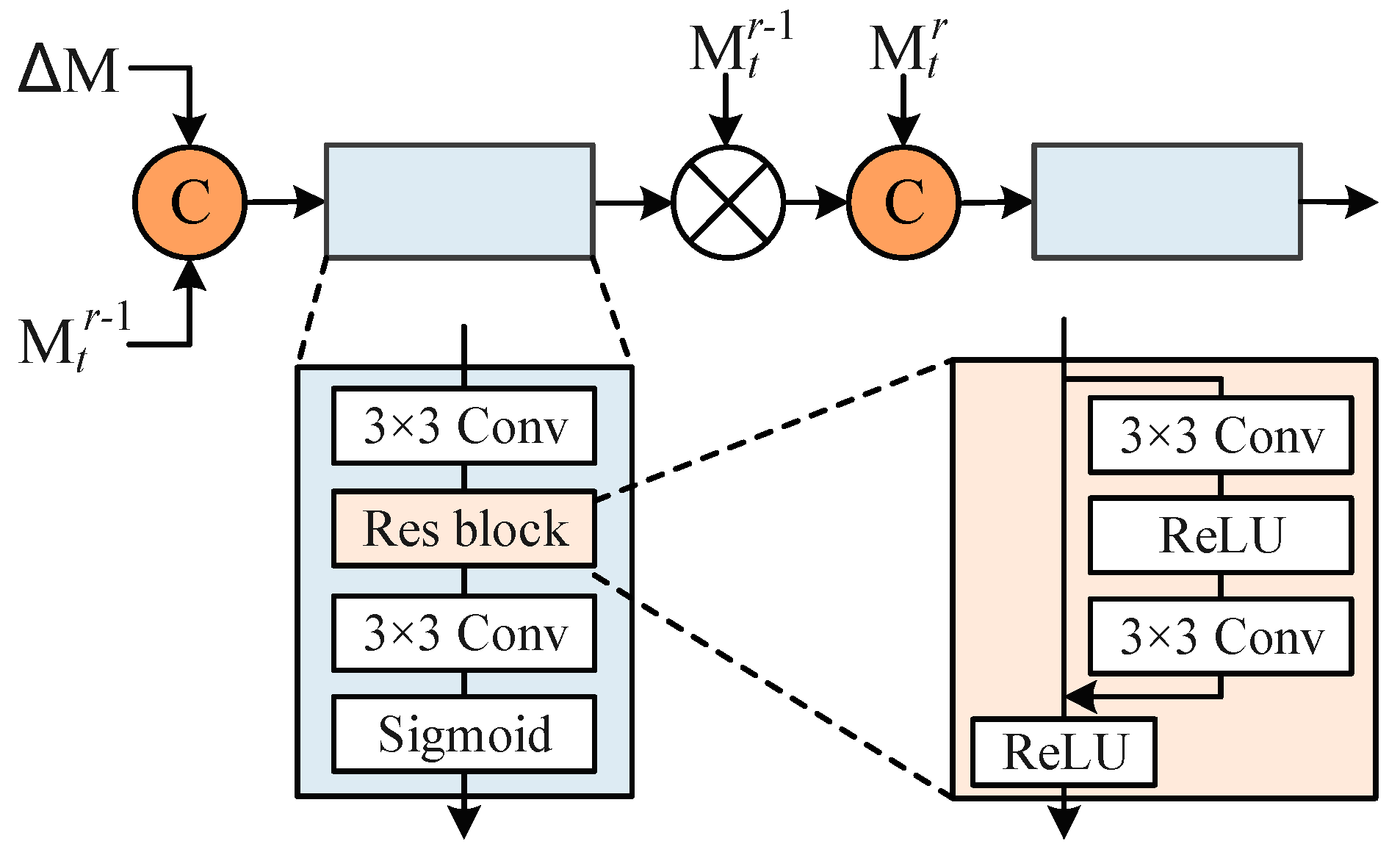
2.2.2. Optimization
- Mask Bidirectional Propagation
- 2.
- Optimization module
3. Experimental Results
3.1. Datasets, Metrics, and Implementation
3.1.1. Datasets
3.1.2. Metrics
3.1.3. Implementation
3.2. Evaluation of User Interaction Segmentation
3.3. Evaluation of Video Object Segmentation
3.3.1. Comparison to the State of the Art
3.3.2. Ablation Study
3.3.3. User Interaction Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benenson, R.; Popov, S.; Ferrari, V. Large-scale interactive object segmentation with human annotators. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sofiiuk, K.; Petrov, I.A.; Konushin, A. Reviving iterative training with mask guidance for interactive segmentation. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022. [Google Scholar]
- Oh, S.W.; Lee, J.Y.; Xu, N.; Kim, S.J. Fast user-guided video object segmentation by interaction-and-propagation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sofiiuk, K.; Petrov, I.; Barinova, O.; Konushin, A. f-BRS: Rethinking backpropagating refinement for interactive segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Chen, X.; Zhao, Z.Y.; Zhang, Y.L.; Duan, M.N.; Qi, D.L.; Zhao, H.H. Focalclick: Towards practical interactive image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022. [Google Scholar]
- Zhou, M.H.; Wang, H.; Zhao, Q.; Li, Y.X.; Huang, Y.W.; Meng, D.Y.; Zheng, Y.F. Interactive Segmentation as Gaussian Process Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023. [Google Scholar]
- Cheng, H.K.; Tai, Y.W.; Tang, C.K. Modular interactive video object segmentation: Interaction-to-mask, propagation and difference-aware fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Xu, N.; Lin, W.Y.; Lu, X.K.; Wei, Y.C. Video Object Segmentation: Tasks, Datasets, and Methods; Springer: Cham, Switzerland, 2024; ISBN 978-3-031-44655-9. [Google Scholar]
- Caelles, S.; Maninis, K.K.; Pont-Tuset, J.; Leal-Taixé, L.; Cremers, D.; Gool, V.L. One-shot video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 22–25 July 2017. [Google Scholar]
- Maninis, K.K.; Caelle, S.; Chen, Y.; Pont-Tuset, J.; Leal-Taixe, L.; Cremers, D.; Gool, L.V. Video object segmentation without temporal information. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1515–1530. [Google Scholar] [CrossRef] [PubMed]
- Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid data dreaming for video object segmentation. Int. J. Comput. Vis. 2019, 127, 1175–1197. [Google Scholar] [CrossRef]
- Li, X.; Loy, C.C. Video object segmentation with joint re-identification and attention-aware mask propagation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, Y.T.; Huang, J.B.; Schwing, A.G. Videomatch: Matching based video object segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Voigtlaender, P.; Chai, Y.; Schroff, F.; Adam, H.; Leibe, B.; Chen, L.C. Feelvos: Fast end-to-end embedding learning for video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yang, Z.; Wei, Y.; Yang, Y. Collaborative video object segmentation by foreground-background integration. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020. [Google Scholar]
- Wang, J.K.; Chen, D.D.; Wu, Z.X.; Luo, C.; Tang, C.X.; Dai, X.Y.; Zhao, Y.C.; Xie, Y.J.; Yuan, L.; Jiang, Y.G. Look Before You Match: Instance Understanding Matters in Video Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023. [Google Scholar]
- Oh, S.W.; Lee, J.Y.; Sunkavalli, K.; Kim, S.J. Fast video object segmentation by reference-guided mask propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, Z.; Xu, J.; Liu, L.; Zhu, F.; Shao, L. Ranet: Ranking attention network for fast video object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2November 2019. [Google Scholar]
- Ren, S.C.; Liu, W.X.; Liu, Y.T.; Chen, H.X.; Han, G.Q.; He, S.F. Reciprocal transformations for unsupervised video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Zhou, T.F.; Wang, S.Z.; Zhou, Y.; Yao, Y.Z.; Li, J.W.; Shao, L. Motion-attentive transition for zero-shot video object segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Oh, S.W.; Lee, J.Y.; Xu, N.; Kim, S.J. Video object segmentation using space-time memory networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Cheng, H.K.; Schwing, A.G. XMem: Long-Term Video Object Segmentation with an Atkinson-Shirin Memory Model. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Karim, R.; Zhao, H.; Wildes, R.P.; Siam, M. MED-VT: Multiscale Encoder-Decoder Video Transformer with Application to Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023. [Google Scholar]
- Dang, J.S.; Zheng, H.C.; Wang, B.M.; Wang, L.G.; Guo, Y.L. Temporo-Spatial Parallel Sparse Memory Networks for Efficient Video Object Segmentation. IEEE Trans. Intell. Transp. Syst. 2024. early access. [Google Scholar] [CrossRef]
- Zhang, Q.; Jin, G.; Zhu, Y.; Wei, H.J.; Chen, Q. BPT-PLR: A balanced partitioning and training framework with pseudo-label relaxed contrastive loss for noisy label learning. Entropy 2024, 26, 589. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Woo, S.Y.; Park, J.C.; Lee, J.W.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hariharan, B.; Arbel’aez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- McGuinness, K.; O’connor, N.A. Comparative evaluation of interactive segmentation algorithms. Pattern Recognit 2010, 43, 434–444. [Google Scholar] [CrossRef]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Gool, L.V.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Mahadevan, S.; Voigtlaender, P.; Leibe, B. Iteratively trained interactive segmentation. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 2–6 September 2018. [Google Scholar]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbeláez, P.; Sorkine-Hornung, A.; Van Gool, L. The 2017 DAVIS Challenge on Video Object Segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Gulshan, V.; Rother, C.; Criminisi, A.; Blake, A.; Zisserman, A. Geodesic star convexity for interactive image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Yang, J.; Huang, T. Deep interactive object selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Li, Z.; Chen, Q.; Koltun, V. Interactive image segmentation with latent diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Heo, Y.; Jun, K.Y.; Kim, C.S. Interactive video object segmentation using global and local transfer modules. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020. [Google Scholar]
- Varga, V.; Lőrincz, A. Fast interactive video object segmentation with graph neural networks. In Proceedings of the International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021. [Google Scholar]
- Miao, J.; Wei, Y.; Yang, Y. Memory aggregation networks for efficient interactive video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | SBD | Davis | Berkeley | |||
|---|---|---|---|---|---|---|---|
| 85% | 90% | 85% | 90% | 85% | 90% | ||
| Grabcut [33] | ICCV 01 | 13.60 | 15.96 | 15.13 | 17.41 | 12.45 | 14.22 |
| ESC [34] | CVPR 10 | 12.21 | 14.86 | 15.41 | 17.70 | - | 12.11 |
| DOS with GC [35] | CVPR 16 | 9.22 | 12.80 | 9.03 | 12.58 | - | - |
| LD [36] | CVPR 18 | 7.41 | 10.78 | 5.05 | 9.57 | - | - |
| f-BRS-B-50 [4] | CVPR 20 | 4.55 | 7.45 | 5.44 | 7.81 | 2.17 | 4.22 |
| FocalClick-18s-S2 [5] | CVPR 22 | 4.30 | 6.52 | 4.92 | 6.48 | 1.87 | 2.86 |
| GPCIS-50 [6] | CVPR 23 | 3.80 | 5.71 | 4.37 | 5.89 | 1.60 | 2.60 |
| PSNet | Ours | 4.07 | 6.18 | 3.34 | 4.68 | 1.60 | 1.76 |
| Method | Year | Interactive | J↑ | F↑ | Avg(J&F)↑ |
|---|---|---|---|---|---|
| IPN [3] | CVPR 19 | ✓ | 69.6 | 73.8 | 71.7 |
| ATNet [37] | ECCV 20 | ✓ | 70.6 | 76.2 | 73.4 |
| GNNannot [38] | IJCNN 21 | ✓ | 74.8 | 79.3 | 77.1 |
| MANet [39] | CVPR 20 | ✓ | 76.6 | 80.7 | 78.7 |
| MiVOS [7] | CVPR 22 | ✓ | 78.9 | 84.7 | 81.8 |
| MRIDP_VOS | Ours | ✓ | 79.8 | 84.9 | 82.4 |
| XMem [22] | ECCV 22 | ✗ | 77.4 | 84.5 | 81.0 |
| ISVOS [16] | CVPR 23 | ✗ | 79.3 | 86.2 | 82.8 |
| MED-VT [23] * | CVPR 23 | ✗ | 83.0 | 84.1 | 83.5 |
| MRIDP_VOS | Ours | ✓ | 79.8 | 84.9 | 82.4 |
| J↑ | F↑ | Avg(J&F) ↑ | |
|---|---|---|---|
| Standard MRIDP_VOS | 79.8 | 84.9 | 82.4 |
| (i) | 76.6 | 77.3 | 77.0 |
| (ii) | 77.2 | 78.9 | 78.1 |
| (iii) | 76.8 | 78.0 | 77.4 |
| Methods | Round 1 | Round 2 | Round 3 | Sum |
|---|---|---|---|---|
| MiVOS | 78.6 | 1.72 | 0.87 | 81.2 |
| MRIDP_VOS | 79.4 | 1.83 | 0.79 | 82.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Yuan, X.; Luo, S. Click to Correction: Interactive Bidirectional Dynamic Propagation Video Object Segmentation Network. Sensors 2024, 24, 6405. https://doi.org/10.3390/s24196405
Yang S, Yuan X, Luo S. Click to Correction: Interactive Bidirectional Dynamic Propagation Video Object Segmentation Network. Sensors. 2024; 24(19):6405. https://doi.org/10.3390/s24196405
Chicago/Turabian StyleYang, Shuting, Xia Yuan, and Sihan Luo. 2024. "Click to Correction: Interactive Bidirectional Dynamic Propagation Video Object Segmentation Network" Sensors 24, no. 19: 6405. https://doi.org/10.3390/s24196405
APA StyleYang, S., Yuan, X., & Luo, S. (2024). Click to Correction: Interactive Bidirectional Dynamic Propagation Video Object Segmentation Network. Sensors, 24(19), 6405. https://doi.org/10.3390/s24196405