1. Introduction
Agile optical satellites (AOSs), as a new generation of optical satellites, have superior attitude maneuverability, which can adjust attitude flexibly and quickly on the three axes of pitch, roll and yaw. Over past years, they have played increasingly significant roles in many fields, such as environmental monitoring, marine development, agricultural production, city planning, and military reconnaissance [
1,
2]. The agile characteristics improve the observation capability of AOSs but also lead to a more complex attitude maneuver process. With the surge in earth observation demand, scheduling an agile optical satellite has become a challenging problem.
Compared with traditional optical satellites, AOSs can observe the target during a much longer observable period due to its ability to rotate around the pitch axis, as shown in
Figure 1. The period during which the satellite can observe the target is called the visible time window (VTW), and the duration of the actual observation event is called the observation window (OW). In this study, the AOS adopts a common push-broom observation mode [
3] and adjusts its attitude only by rolling and pitching. In the observation process of an AOS, its pitch angle determines the start time of the OW, and its roll angle is determined by the relative position of the AOS and the target. Thus, in a VTW, the pitch angle is variable but the roll angle can be regarded as a fixed value. When an AOS observes two adjacent targets, a short period is needed for the attitude adjustment, which is called the transition time. The time interval between two successive observation actions must not be less than their required transition time [
4]. Only if the observation time of the previous task is determined can the observation time of the next one be determined. Therefore, the observation time of multiple tasks must be determined one by one, which is a sequential decision process.
The purpose of the single AOS scheduling problem (SAOSSP) is to reasonably arrange the observation sequence and observation time of tasks [
3]. The SAOSSP has been proven as an NP-hard problem [
5], exhibiting the characteristics of a combination explosion, and its solving time grows exponentially with the problem scale [
6]. The complexity of this problem is mainly reflected in three aspects. First, each target may have several VTWs in different orbits, causing multiple possibilities of the VTW selection, and the observation event can start at any time within the selected VTW, causing various optional possibilities of the OW. Second, owing to the complicated constraints and the considerable solution space, an enormous number of constraint-checking steps and a thorough search in the solution space are needed [
7], demanding high computational expenses. Third, this problem is typically an oversubscribed scheduling problem where only partial tasks have the chance to be accomplished [
8,
9], and the increase of the problem scale can further expand its computational complexity. Therefore, the SAOSSP is hard and complex to solve, and an efficient scheduling method is badly required to accomplish the more observation tasks and reach the maximum observation profit.
Over the past few decades, extensive research has been carried out, and many contributions have been made to solve the agile satellite scheduling problem. Existing approaches can be roughly distributed into three categories: exact algorithms, heuristic algorithms and deep reinforcement learning (DRL) algorithms. Some researchers adopt exact algorithms to solve this problem. Lemaître et al. [
5] gave the general description of the agile satellite scheduling problem for the first time and proposed a dynamic programming algorithm. Chu et al. [
10] presented a branch and bound algorithm with a look-ahead method and three pruning strategies to tackle the simplified problem in a small-size instance. Peng et al. [
11] considered the time-dependent profits and presented an adaptive-directional dynamic programming algorithm with decremental state space relaxation for the single-orbit scheduling of the single agile satellite. The above studies summarily prove that exact algorithms can explore the whole search space and obtain the optimal solution, and they are applicable to the single-orbit or small-scale satellite scheduling. However, as the problem scale expands, the computational cost of the exact algorithms tends to be unacceptable because of the NP-hard characteristic and the complex constraints.
Differing from exact algorithms, heuristic algorithms can iteratively search for a good solution with relatively lower computational cost, and they have been extensively applied to the agile satellite scheduling due to the excellent abilities of exploration and exploitation, such as genetic algorithms (GAs) [
12,
13], particle swarm optimization (PSO) algorithms [
14,
15], ant colony optimization (ACO) algorithms [
16,
17], artificial bee colony (ABC) algorithms [
18] and so on. Chatterjee and Tharmarasa [
19] formulated a mixed-integer non-linear optimization model and proposed an elitist mixed coded genetic algorithm algorithm to solve the agile satellite scheduling problem. Du et al. [
20] considered the drift angle constraint of the observation instrument and developed an improved ant colony algorithm based on a sensational and consciousness strategy to solve the area target observation problem of agile satellites. Yang et al. [
21] improved the three search phases of the basic ABC algorithm and presented a hybrid discrete artificial bee colony (HDABC) algorithm to address the satellite scheduling problem. These heuristic algorithms can optimize solutions through superior search mechanisms and iterative updates of population, but the issue of considerable computational time and the convergence problem still exist.
To avoid the above shortcomings, researchers demand for a novel, efficient, and non-iterative method to solve the agile satellite scheduling problem. With the development of artificial intelligence technology, deep reinforcement learning (DRL) methods have achieved excellent results in many fields [
22,
23,
24,
25], especially in large-scale combination optimization problems [
26,
27]. Because the agile satellite scheduling problem can be formulated as a sequential decision problem [
28,
29], DRL algorithms can be adopted to replace heuristic algorithms, which can directly generate solutions without an iterative search. Chen et al. [
30] developed an end-to-end network model with a convolution neural network (CNN) as the encoder, a gated recurrent unit (GRU) as the decoder, and an attention mechanism to obtain the relevance between the output task and each input task, and this model achieved good results in the small-scale scheduling instances. Zhao et al. [
31] proposed a two-phase neural combination optimization method, which adopted a Pointer Network (PtrNet) to generate a permutation of executable tasks and a deep deterministic policy gradient algorithm to determine the observation time of selected tasks. Wei et al. [
32] proposed a DRL and parameter transfer-based approach (RLPT), consisting of a task encoder composed of a GRU, a feature encoder composed of a CNN, and a decoder composed of an attention mechanism. These studies have preliminarily verified the feasibility and effectiveness of DRL, but there are still some weaknesses. First, the neural networks in these methods can only deal with the inputs of fixed dimensions, and no effective approach is provided to handle the inputs of variable dimensions, especially VTWs, the number of which may be different for different tasks. Second, the above methods based on the encoder–decoder structure all adopt the global attention mechanism whose computation is a bit large, and they do not pay attention to the internal connections among tasks. Third, the above studies only train and validate the proposed methods on the instances of a certain scale, and they do not really apply them to the large-scale problems. Therefore, it is necessary to further explore the improvement of DRL to overcome these deficiencies and efficiently solve the SAOSSP.
In this study, we propose a deep reinforcement learning algorithm with a local attention mechanism (DRLLA) to solve the SAOSP in a non-iterative manner. The primary contributions are summarized as follows:
- (1)
A neural network framework based on an encoder–decoder structure is designed to construct a high-quality scheduling solution in an auto-regression manner. Furthermore, a local attention mechanism is proposed to guide the network model to focus on the more promising tasks in the solution construction process by narrowing the candidate task range into a local one, which greatly improves the solution quality.
- (2)
An adaptive learning rate strategy is developed to guide the actor–critic training algorithm to train the proposed network model. In the training process, the adaptive learning rate strategy appropriately reduces or increases the learning rate of the training algorithm according to the reward curve trend, obtaining better training effectiveness.
- (3)
Extensive experiments are conducted to verify the proposed algorithm with our created SAOSSP datasets, which contain numerous various-scale instances and can be publicly available for related studies. The experimental results validate that the proposed algorithm has superior performance in solution quality, generalization performance, and computational efficiency over the comparison algorithms.
The remainder of this paper is organized as follows. In
Section 2, we describe the SAOSSP in detail and build the corresponding mathematical model with complicated constraints and an optimization objective.
Section 3 presents a neural network with a local attention mechanism for the SAOSSP and an actor–critic training algorithm with an adaptive learning rate for the training of the proposed network.
Section 4 presents the experimental results, and
Section 5 presents the conclusions of the study with a summary and directions for future work.
3. Method
In this section, we propose a deep reinforcement learning algorithm with a local attention mechanism (DRLLA) to address the SAOSSP. The architecture of the designed neural network, its crucial components, and a training approach are described in turn.
3.1. Architecture of the Proposed Neural Network
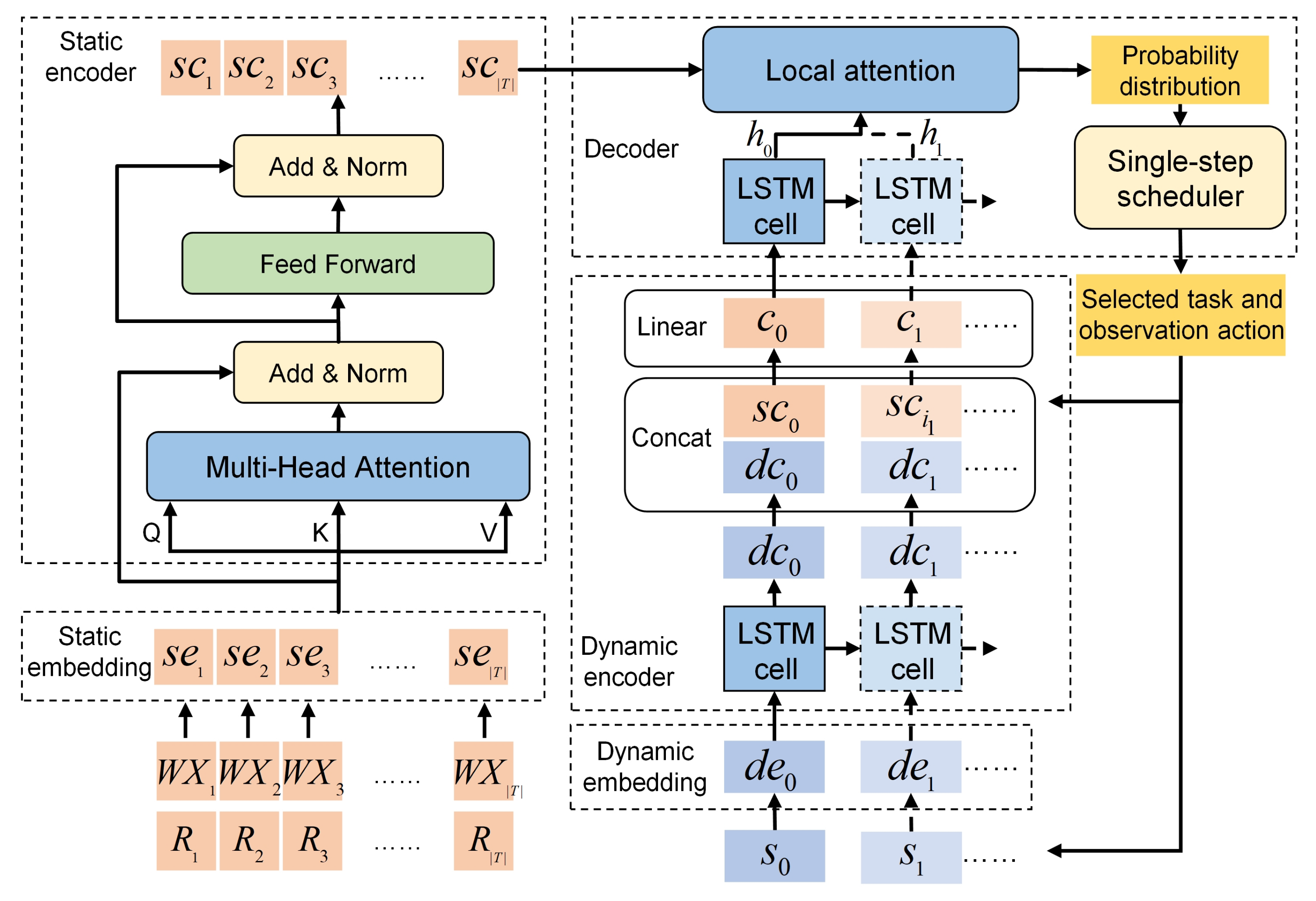
The architecture of the proposed neural network is depicted in
Figure 2, which is an end-to-end framework with an encoder–decoder structure. The neural network is composed of five components: a static embedding layer, a static encoder, a dynamic embedding layer, a dynamic encoder and a decoder. In addition, a local attention mechanism is proposed to improve the generation of solutions.
In the general SAOSSP, given a set of tasks , the neural network is used as the policy network to extract features from inputs and generate a permutation of the executable tasks and a corresponding observation action sequence in an auto-regression way, both of which compose the solution of the problem. The inputs of this problem comprise two parts: task information and satellite state information. Task information is static and consists of time window information and requirement information. For the task , its time window information is denoted by a set , and its requirement information is denoted by a vector . Satellite state information is dynamic and changes every time a task is executed. After the AOS executes the task through the observation action , its state information is denoted as a vector , where n is the step number and the observation end time is also the start time of the free state. The output permutation of the executable tasks is denoted as , where is the task index and N is the length of output permutation. Accordingly, the observation action sequence of the AOS is . Obviously, the elements of can be obtained in . To better utilize the above input information, the designed neural network must be able to process both static and dynamic information simultaneously. Therefore, the proposed neural network adopts a static embedding layer and a static encoder to handle the static inputs and a dynamic embedding layer and a dynamic encoder to deal with the dynamic inputs on the basis of the basic encoder–decoder structure. The above inputs have been normalized before they are formally inputted.
Formally, the set of inputs is denoted as . Each input is denoted as a sequence of tuples , where is the static element, and is the dynamic one at the decoding step n. In addition, denotes the state set of all inputs at the decoding step n, and is the initial state of the inputs. is the final permutation, where is an initial virtual tuple composed of the virtual static elements and the initial satellite state vector. is the decoded permutation up to the step n.
At every decoding step
, the neural network generates the probability distribution of inputs in
at first. Then,
points to an available input
with the highest probability which is chosen as the input of the next decoding step
and added into
, and
is updated to
according to the constraints of the actual problem, as formulated in the following equations:
where
is the state transition function to update the state set of inputs, and
θ are learnable parameters.
The above process continues until all the available tasks are completed, and the probability chain rule is adopted to factorize the probability of generating the sequence
Y as
The reward of the final scheduling results is the profit ratio of the completed tasks, which is denoted by .
3.2. Local Attention Mechanism
The decoding process of the neural network is dynamic, and every time, one task is selected through an attention mechanism according to the static encoding information and the current dynamic encoding information, which utilizes auto-regression. The attention mechanism is adopted to calculate the probability distribution of candidate tasks, and that with the highest probability is selected. In this process, the selection order of tasks represents their execution order. Notably, the unreasonable sorting order can form a low-quality solution.
In the previous research [
30,
31,
32], a global attention mechanism is adopted to calculate the probability distribution of all unselected tasks and make neural networks focus on the essential parts of global task information. However, as the scale of the problem expands, the length of the task sequence also becomes longer, making it more difficult for the global attention mechanism to find out the best candidate task quickly and accurately at every decoding step. In the early training process, the neural network has not formed the optimal decision policy, which is highly likely to generate unreasonable sorting orders. Once the task that should have been executed last is selected first, others will lose the opportunity to be executed. For example,
Figure 3 shows several VTWs of five tasks in the four orbits. The orbit
is not considered since no VTW exists in this orbit. As shown in
Figure 4a, the global attention mechanism is applied to this example, and all the unselected tasks are included in the candidate range at every decoding step. If
is selected to be executed in the VTW
, the tasks without later VTWs will have no chance to be completed, and
and
will be abandoned, which could have been executed in the previous orbits. Owing to the tendency to generate unseasonable sorting orders, it is hard for the global attention mechanism to generate great solutions in the training process, making it difficult for the neural network to learn excellent experiences and further influencing the training effect.
To avoid these deficiencies, we propose a local attention mechanism that reduces the range of candidate tasks and focuses on the local task information. An ideal scheduling solution can fully utilize orbit resources and arrange as many feasible tasks as possible in an orbit without causing conflicts. Thus, the range of candidate tasks is limited to the current several orbital cycles at every decoding step, and the local attention mechanism only considers the unselected tasks that satisfy the condition of having VTWs in this local range. The local attention is set to only consider the unselected tasks with VTWs in the current orbit or the next one at every decoding step. As illustrated in
Figure 4b, the local attention is employed for the above example. Only
,
,
, and
, which have VTWs in
or
, are taken into account at the first decoding step. If no unselected tasks have VTWs in the current orbit, those with VTWs in the following two orbits will be considered. If there is only one orbit left, the local attention will only need to focus on the left tasks in this orbit. In this way, the scheduling solutions can be significantly improved. For one thing, it is easier to find the best candidate task within a local range. For another, the observation time of the next task can be arranged close to that of the previous one, preventing some tasks from losing their observation opportunities.
In the proposed local attention mechanism, only the conditional probabilities of partial tasks need to be calculated. Let
be the set of encoded static elements of tasks meeting the above condition at the decoding step
n, and
is the number of these tasks. The conditional probabilities can be calculated as follows:
In Equations (
20) and (
21),
,
, and
are learnable parameters of the local attention layer.
3.3. Compositions of the Neural Network
The neural network consists of a static embedding layer, a static encoder, a dynamic embedding layer, a dynamic encoder, and a decoder, which are elaborated in detail below.
3.3.1. Static Embedding Layer
The static embedding layer is used to embed the static elements, including time window information and requirement information, into a high-dimensional vector space. The static elements have the following characteristics: first, the number of tasks is variable; second, the input task sequence does not have an apparent sorting order. However, the features of the time window information and the requirement information are distinct. The VTW number of different tasks is not a fixed value, and the time window information of a task is a time-related sequence. The requirement information of every task is a vector with fixed dimensions. Therefore, the static embedding layer must be able to process task window information and requirement information separately.
The structure of the static embedding layer is shown in
Figure 5. For
, its time window set
is embedded through a fully connected network (
) and an LSTM network (
) successively, and a vector
is obtained. Meanwhile, its requirement vector
is embedded through a fully connected network (
), and a vector
is obtained. Then, the concatenated form of
and
is further processed through a fully connected network (
). The concatenating operator is denoted by
. The final embedding output of
T is denoted as
. The calculating process of
is formulated as follows:
where
,
, and
are learnable parameters of the corresponding networks. With the static embedding layer, the proposed neural network can handle the inputs of variable dimensions.
3.3.2. Static Encoder
The static encoder is used to extract features from the static inputs for the subsequent solution construction. Because the input order of tasks is meaningless for this problem, position coding and recurrent neural networks are inapplicable to encoding. Thus, a multi-head self-attention sub-layer (
) and a fully connected feed-forward sub-layer (
) are adopted in the static encoder. The multi-head self-attention mechanism [
27] can divide the input sequence into multiple sub-sequences and perform self-attention on each sub-sequence. The self-attention extracts features by calculating the correlation among tasks, and the extracted features of a task contain not only its own feature information but also global feature information. Each sub-sequence corresponds to a head, and different heads focus on different aspects of the input sequence. This mechanism allows the network model to capture different relationships between tasks in the input sequence and efficiently extract features from a long sequence.
To improve the training efficiency and performance, each sub-layer adds a skip-connection structure [
40] to alleviate the gradient disappearance problem and a layer-normalization operator [
40] to stabilize the training process. The layer-normalization operator is denoted by
, the output of the multi-head self-attention layer is denoted by
, and the final encoding output of
is denoted by
. The static encoding process is formulated as below:
where
is the learnable parameter set of the multi-head attention layer, and
is the learnable parameter set of the fully connected feed-forward layer.
3.3.3. Dynamic Embedding Layer
In the dynamic embedding layer, a fully connected network (
) is adopted to embed the dynamic elements into a high-dimensional vector space, as formulated in the following equation:
where
is the embedding form of
at step
n, and
is the learnable parameter set of the fully connected network.
3.3.4. Dynamic Encoder
The dynamic encoder is used for the further extraction of dynamic features. At every step, its inputs comprise the embedding form of the current state and the encoding form of the task that is selected at the previous step. The states of the AOS have the following characteristics: first, it is dynamically changing; second, the current state is affected by the previous one; third, the state sequence is time related. Hence, the dynamic encoder is composed of an LSTM cell (
), a concatenating operator, and a fully connected network (
). At step
n,
converts to a feature vector
through the LSTM cell at first. Then, the concatenation of
and
is transformed to
by a fully connected network. This process is formulated as follows:
where
is the learnable parameter set of the LSTM cell, and
is the learnable parameter set of the fully connected network.
3.3.5. Decoder
The decoder makes decisions based on the outputs of the static encoder and the dynamic encoder, and it contains three components: an LSTM cell, a local attention layer, and a single-step scheduler.
At decoding step
n, the LSTM cell (
) is adopted to process the outputs of the dynamic encoder at first owing to it appearing as the sequential characteristic, which is formulated as below:
where
is the learnable parameter set of the LSTM cell.
Then, the designed local attention layer calculates the probability distribution of the candidate tasks according to the hidden state of the LSTM cell and the outputs of the static encoder, which are formulated in Equations (
20) and (
21), and the task with the highest probability will be selected to be scheduled. In this process, the range of the candidate tasks is narrowed, and the local attention mechanism only calculates the probability distribution of the tasks in this range. Significantly, the static encoding results of each task contain global feature information owing to the multi-head self-attention mechanism so that the task selection can tend toward global optimization.
Finally, the single-step scheduler selects the task with the highest probability and sets the earliest feasible time as its observation start time, and the single-step scheduling result is generated according to the complex constraints formulated in
Section 2.3. Once the task is successfully executed, the rest of the unselected tasks will be judged on whether they have VTWs in the remaining period, and those without VTWs will be deleted, whose probability will be recorded.
3.4. Training Method
An actor–critic algorithm with an adaptive learning rate is adopted to train the proposed neural network, as presented in Algorithm 1. The actor–critic algorithm and the adaptive learning rate strategy are elaborated in detail below.
| Algorithm 1 Training algorithm |
- 1:
Initialize actor network parameters θ - 2:
Initialize critic network parameters θc - 3:
Set actor network learning rate lr1 - 4:
Set critic network learning rate lrc - 5:
Training step counter κ ← 1 - 6:
for epoch ← 1, ⋯, Epoch do - 7:
for task_num ← 200, 150, 100, 50 do - 8:
for bn ← 1, ⋯, BN do - 9:
for b ← 1, ⋯, BS do - 10:
Decoding step counter n ← 0 - 11:
while not terminated do - 12:
Choose next task - 13:
Update - 14:
n ← n + 1 - 15:
end while - 16:
Calculate reward - 17:
Obtain evaluation value through critic network - 18:
end for - 19:
- 20:
- 21:
Update θ ← Adam(θ, dθ) - 22:
Update θc ← Adam(θc, dθc) - 23:
if κ mod 10 = 0 then - 24:
Update according to Equation ( 34) - 25:
else - 26:
- 27:
end if - 28:
κ ←κ + 1 - 29:
end for - 30:
end for - 31:
end for
|
3.4.1. Actor–Critic Algorithm
The actor–critic training algorithm is a common training algorithm for the optimization of neural networks [
32], and it comprises two neural networks: an actor network and a critic network. The actor network is the proposed neural network for generating the scheduling result, and the profit ratio of the scheduling result is the reward of the actor network. The critic network is a separate network for evaluating the reward of inputs. Both of these networks need to be trained. In this study, the critic network is composed of an embedding layer, an encoder, and a decoder. Its embedding layer and encoder employ the same architecture as the actor network, while its decoder consists of two one-dimensional convolutional layers.
Algorithm 1 shows the pseudo-code of the training algorithm. The neural networks are trained on four kinds of samples with different task sizes
Epoch times, which are introduced in
Section 4.1. Each kind of sample contains
BN batches. At the training step
κ, given a batch of samples whose size is
BS, the optimization process of the neural networks can be divided into five steps: (1) the actor network generates solutions through step-by-step construction; (2) the reward of every solution is calculated, and
is the reward of the solution
b; (3) the critic network generates the evaluation value of every sample, and
is the evaluation value of the sample
b; (4) the policy gradient of the actor network is calculated according to Equation (
31), and that of the critic network is formulated in Equation (
32); (5) Adam optimizer is adopted to optimize the parameters of the two networks according to the corresponding policy gradients and learning rates. The learning rate of the actor network is adjusted dynamically through the adaptive learning rate strategy, and that of the critic network is fixed.
3.4.2. Adaptive Learning Rate Strategy
In the training process of the neural network, the learning rate is a crucial hyperparameter that determines the update stride of network parameters. A large learning rate may lead to easy divergence, while a small learning rate may lead to slow convergence [
41]. In the prior experiments, the conventional fixed learning rates and exponential learning rates failed to balance the early exploration and the later convergence, and a slightly higher learning rate could bring the reward curve to a higher level but make it difficult to converge. Therefore, the learning rate should be adjusted dynamically, and its appropriate decay and increase can make the reward curve converge to a higher level.
To improve the training effect of the actor network, an adaptive learning rate strategy is proposed that dynamically adjusts the learning rate according to the training performance. The reward curve can intuitively reflect the training performance. However, the neural network is trained on the four kinds of samples with significantly different optimal rewards, resulting in the reward curve appearing as a step shape. Hence, the learning rate cannot be adjusted according to the reward value, but the trend of the reward curve can be selected as the indicator for adjusting the learning rate. The adjustment process of the adaptive learning rate contains two steps: first, the learning rate overall decays by a fixed decay rate to ensure the convergence of the reward curve; then, for every ten training steps, if the trend of the reward curve does not reach the expected value, the learning rate will increase slightly to help the reward curve reach a higher level. After the learning rate is initialized or increases, the reward curve may be at a lower level in the early stage, but it is expected to rise rapidly in the middle stage of the following training and converge stably in the later stage, similar to a cosine wave of half a cycle. Thus, a cosine curve is used as the reference curve, and the expected value is calculated according to its slope. Details of the adaptive learning rate strategy are elaborated below.
Firstly, some variables need to be defined to describe the adaptive learning rate: at training step κ, given a batch of samples, (1) is the learning rate of the actor network; (2) is the average reward of this batch of solutions, denoting the reward at the current step; (3) given which is the reward set of the previous ten steps, is its mean value; (4) is the average evaluation value of this batch of samples, denoting the evaluation value at the current step; (5) is the mean value of ; (6) is the slope of the reward curve; (7) represents the expected slope; (8) if , κ will be recorded as whose initial value is zero. (9) K is the total training steps; and (10) γ is the decay rate.
Secondly, the trend of the reward curve is expected to be close to that of a cosine curve, as shown in
Figure 6. After ten training steps, the slope of the reward curve is compared with the expected value, which is gained according to the slope of the reference cosine curve. If the slope of the reward curve is less than the expected value, the learning rate of the actor network will increase slightly; otherwise, the learning rate will keep decaying at the following ten training steps. Once the learning rate increases, the reward curve is expected to rise like a new cosine curve at the following training steps.
Thirdly, the reference cosine curve function
is formulated in Equation (
33), and its derivative is formulated in Equation (
34). The derivative function cannot be directly set as the expected slope for two reasons: (1)
is just an evaluation value and not the actual optimal value, and it may be inaccurate and larger than 1; (2)
and
are the values at one step and cannot accurately represent training results. Thus, some improvements are made based on the derivative function. First,
is replaced with
to ensure the outcome is between 0 and 1. Then,
and
are, respectively, replaced with the mean values
and
. In addition,
is replaced with
K, resulting in that the expected slope can be larger in the early stage of training and be smaller in the later stage. In this way, the learning rate can have more chances to rise in the early stage but can keep decaying in the later stage. The final expected slope
is formulated in Equation (
35) through these improvements.
Fourthly, the reward curve slope
is calculated according to the reward values of the previous ten steps through the least square method, which is formulated as outlined below:
where
is the mean value of one to ten.
Eventually, the adaptive learning rate
of the next step is calculated as follows:
where
As formulated in Equations (
37) and (
38), if the step number
κ is the multiple of 10 and the reward curve slope
is less than the expected value
, the learning rate will increase slightly; otherwise, the learning rate
will decay by the decay rate
γ. As formulated in Equation (
38), the increasing extent of the learning rate is determined by the difference between the evaluation value and the reward value and the difference between the last increased learning rate and the current one, and the learning rate cannot exceed the last increased learning rate. Through the adaptive learning rate strategy, the learning rate shows a downward trend but rises slightly at a few training steps, improving the exploration and convergence of the training algorithm.
3.5. Complexity Analysis
In the actor network, the time complexity of the static embedding layer is
, and that of the static encoder is
. At the decoding step
n, the time complexity of the dynamic embedding layer and that of the dynamic encoder are both
, and that of the decoder is
. The time complexity of the
N-step decoding process is formulated as follows:
where
is the computation time of the dynamical embedding layer at a step,
is the computation time of the dynamical encoder at a step, and
is the computation time of the decoder at a step.
,
, and
are constants. Since
and
, the time complexity of the actor network is
, which is formulated in Equation (
40). The time complexity of generating a solution through the well-trained actor network is also
.
In the critic network, the time complexity of its embedding layer is
, that of its encoder is
, and that of its decoder is
. Thus, the time complexity of the critic network is
, which is formulated in Equation (
41).
In the training process, the time complexity of training once for a batch of samples is formulated in Equation (
42). And solving an SAOSSP only needs the actor network to run once, so the time complexity of solving is also
.
From the above analysis, the training time and solving time of DRLLA rise polynomially as the task size increases. In addition, the training time is also directly affected by the training times, the number of sample types, and the batch size.
5. Conclusions and Future Work
In this paper, a deep reinforcement learning algorithm with a local attention mechanism is proposed to address the scheduling problem of a single agile optical satellite with different task scales. Two techniques are effectively adopted to improve the performance of the algorithm: (1) local attention mechanism and (2) adaptive learning rate strategy. The local attention mechanism narrows the range of candidate tasks and selects the next-scheduled task from a more promising range, significantly improving the quality of the generated solution. The adaptive learning rate strategy dynamically decreases or increases the learning rate according to the reward curve trend in the training process, enhancing the early exploration and later convergence abilities. Based on these techniques, the proposed algorithm exhibits superior performance in solution quality, generalization, and efficiency in comparison with the state-of-the-art algorithms. The experimental results also validate the effectiveness of the local attention mechanism for generating high-quality solutions and the adaptive learning rate strategy for improving the training effect.
This paper can provide an efficient and effective approach for agile optical satellite scheduling, while there are still some areas for improvement. Some practical factors are not fully considered, such as the influence of cloud cover, lighting conditions, and observation angles on the imaging results. For future work, we will give a comprehensive consideration of various practical constraints and establish a more realistic AOS scheduling model. In addition, we will further improve the proposed algorithm to make it more available for practical application, and the algorithm will be extended to more complex instances, such as multi-AOS scheduling, emergency scheduling of AOSs, and uncertainty scheduling of AOSs.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}