1. Introduction
Over the past years, federated learning (FL) [
1,
2] has become an emerging distributed machine learning framework that has received widespread attention from academia and industry. It can achieve the purpose of exchanging knowledge across users by sharing training models while avoiding the leakage of privacy, as it does not require uploading raw data related to user privacy to the server. Enabling federated learning in the Internet of Vehicles (IoV) [
3,
4] serves as an application case, not only protecting the privacy and user concerns but also increasing computational efficiency by distributed parallellism over the clients, utilizing the idle resources in vehicular networks. In this framework, millions of vehicles with local datasets are eager to participate in training. For example, in GBoard (a keyboard developed by Google Inc. for tablets and smartphones), over 1.5 million clients are involved in the language model learning process through federated training [
5]. Similarly, in FL-assisted IoV, there are over 3 million active vehicles in the Kanto area, Japan. As considered in [
3], in venues like concerts or sports events, precious wireless resources would become more scarce when all nodes (vehicles or phones) in such crowded scenarios participate in federated learning, further affecting the learning efficiency. Due to wireless bandwidth limitations, only a small fraction of users are selected as clients for learning in each round. In the classical federated learning framework, the server is responsible for client selection. To better improve overall performance, which variables to consider in the selection process is still under debate. Therefore, all participants willing to train the model must periodically update all active states. As mentioned in [
5], user devices must meet specific conditions, including dataset freshness, size, charging status, idle wireless connection, operating system version, and hardware requirements. Only considering the number of CPU cores, memory, and storage capability in heterogeneous FL, while neglecting the accuracy and loss of the model, is insufficient when selecting nodes [
4]. This approach has led to algorithms being unable to handle non-independent and identically distributed datasets effectively. In FL-assisted IoV, vehicle states such as location, network environment, velocity, acceleration, and dataset quality vary over time, requiring prompt updates to the server over a wireless connection. Compared to model uploading, the overhead of continuously updating the state from all participants to the server is very large, given the large number of participants.
Most classical federated learning frameworks adopt a centralized control scheme, where the server selects clients for learning. The server collects and updates the active state of all participants, choosing a set of participants with active states as training clients at the beginning of each communication round. Undoubtedly, the overhead from state updates is substantial when dealing with a large number of participants. These overheads consume precious wireless resources, increase communication delays, and often result in inefficiencies. For example, the resources in the wireless network cannot sustain the connection of so many nodes participating in FL [
3]. As concluded in [
6], achieving good performance can also be accomplished by selecting only a small fraction of devices in each round. Unfortunately, many researchers have not addressed the overhead associated with updating the state of all participants; instead, they have focused on frameworks that adapt decentralized client selection by updating the active state of all participants.
To address the issue of excessive information exchange, the server transfers the responsibility of client selection to the clients, no longer receiving participant information for evaluation. Meanwhile, the assessment of the node shifts from the server to the local. Each participant assesses themselves based on input parameters such as sample quantity, network throughput, computational capability, and diversity of the local dataset.
According to the description of the centralized selection process in [
6,
7], the fundamental differences between centralized client selection and distributed client schemes are listed below: firstly, whether information from all participants is collected for evaluation on the server side, and secondly, whether the server has the authority to select clients. Furthermore, participant assessment is conducted locally rather than on the server. Most traditional federated learning frameworks are developed under centralized schemes, resulting in significant overhead from information updates that cannot be eliminated. Conversely, distributed frameworks with client selection effectively eliminate this overhead.
Notice that the model and exchanged data are not the same. Exchanged data include the state information of the vehicle, such as position, available bandwidth, data samples, etc., which vary over time. These data play a key role in selecting the clients and need to be updated in real time [
6,
7]. Additionally, these data compete for wireless resources with the model when a centralized scheme (where all information is transmitted to the base stations (BSes) or the central server) is adopted. To reduce resource competition, a distributed scheme using dedicated short-range communication (DSRC) technology, such as data exchanged using IEEE 802.11p, is a better option [
3]. Our goal is to reduce competition between the model and vehicle data through an isolated transmission channel. Under this consideration, a distributed scheme may be better than a centralized scheme. Meanwhile, the distributed scheme results in less communication overhead compared to other schemes as well.
In federated learning-assisted IoV, selecting vehicles with high performance in each round can significantly accelerate model convergence. For instance, a client with a larger training dataset, stronger computational capability, higher network throughput, and local dataset with higher diversity (equivalent to higher loss function) ensures successful uploading of the client model with more knowledge to the central server. Consequently, global model accuracy improves as more local models participate in aggregation [
8]. However, there is no closed-form solution that comprehensively considers all influencing factors, posing a significant challenge in evaluating participating vehicles. To address this challenge, we propose a lightweight evaluation approach: fuzzy logic-based evaluator, which leverages fuzzy relationships between influencing factors to construct a participant assessment approach.
In conclusion, two research gaps in the existing studies have not yet been fully investigated: Firstly, the exchange of state information between the central server and all participants becomes significant as the number of participants in the centralized framework grows very large. Secondly, there is no closed-form solution for assessing nodes, especially when considering multiple variables. To this end, we propose a distributed client selection framework with fuzzy logic. The main contributions of the paper are outlined as follows:
A distributed client selection framework is proposed. In this framework, to reduce the exchange of state information between candidate nodes and the server, the server no longer has the authority to select clients, and state information is not updated to the central server. The selection process is performed at each node.
A multi-objective client evaluator based on fuzzy logic is proposed to address heterogeneity in federated learning. This evaluator considers four objectives: sample quantity, available throughput, computational capability, and the loss function of the local dataset. Moreover, the evaluator operates locally instead of on the central server, as the central server does not collect client information.
A simulator combined with realistic vehicular networks and federated learning is constructed to validate the proposal. Additionally, we synthesize a non-independent and identically distributed dataset with varying levels of heterogeneity to demonstrate the superiority of our framework under heterogeneous dataset conditions.
The remainder of the paper is organized as follows:
Section 2 summarizes significant existing works.
Section 3 introduces the system model including network architecture, federated learning framework, and FL-assisted IoV.
Section 4 and
Section 5 elaborate on the distributed client selection framework and the multi-objective client evaluator, respectively.
Section 6 discusses the simulator setup and experimental results. Finally,
Section 7 concludes the paper.
2. Related Works
Over the past years, the research gap in the exchange of state information between the FL server and the vehicle has been ignored. Most researchers have focused on addressing the bottleneck in communication costs between the server and clients for updating models in centralized FL [
9,
10,
11,
12,
13], while our advanced proposal primarily focuses on a distributed framework to eliminate this information exchange. Unlike the centralized schemes proposed below, such as gradient and model compression [
9,
10], biased client selection [
6,
11,
14], reinforcement learning-based client selection [
15,
16], learning on the edge [
12], and hierarchical federated learning [
17], we explore a distributed framework where the server does not select the clients. The federated learning frameworks mentioned above employ centralized client selection, where state information about participants must be gathered by the FL server to maintain their active state, and the FL server handles the client selection process. In fact, millions of nodes are willing to participate in federated learning training. For example, millions of vehicles can join training in IoV. Typically, only a small number of vehicles are selected as clients [
6]. In such scenarios, the communication overhead from maintaining the active state of all participants exceeds the overhead from updating the model between the FL server and clients. Reducing the exchange of state information is crucial in FL for saving bandwidth. Unfortunately, this issue has not been fully investigated.
The decentralized federated learning (DFL) framework has been widely discussed; however, it differs from our proposal. In DFL, there is no aggregating server required, and each client’s training model is sent to all other clients. Due to the lack of client selection, not only does the communication cost increase significantly but the robustness is also a concern in large-scale scenarios. The DFL based on peer-to-peer communication for medical applications proposed in [
18] performs well with fewer nodes. Another approach, presented in [
19], utilizes a DFL framework with a committee consensus blockchain, storing all models, including the global model from the server and local models from clients. Similarly, ref. [
20] introduced an asynchronous DFL framework based on blockchain to enhance stability and reliability in model transmission within IoV. Additionally, the authors in [
21] proposed decentralized federated learning based on blockchain specifically for vehicular networks, and analyzed its advantages theoretically. Meanwhile, unreliable networks and updating model are also taken into consideration in [
22]. The model will be fully updated when the connection state is good. Otherwise, the model will only be partially updated when the connection state is noisy. The DFL frameworks mentioned above are particularly suitable for dynamic network environments such as vehicular networks with mobility. Unfortunately, these distributed frameworks do not consider the overhead of exchanging state information. The distributed scheme in our proposal divides all vehicles into multiple small cells based on geographical position, and the information exchange among vehicles uses DSRC technology.
In contrast to the centralized client selection framework, distributed client selection does not involve the server gathering all participant information. Client evaluation and selection are removed from the server’s responsibilities. Client selection is classified as biased or unbiased. Unbiased client selection, such as random selection [
6], gives all participants an equal chance of being selected. Biased client selection selects clients based on specific criteria. In [
23], client selection is systematically summarized, involving opportunities and challenges, and emphasizing the importance of the heterogeneity. In [
24], the authors investigated existing works related to system architecture, applications, privacy concerns, and resource management in federated learning. In [
25], the authors provided a taxonomy and highlighted the challenges of client selection in terms of fairness to promote sustainability in the FL ecosystem. Likewise, ref. [
26] developed a novel global model aggregation algorithm focusing on group fairness rather than the weight related to sample quantity in local models. Furthermore, ref. [
14] selected clients based on larger loss functions to accelerate convergence. Ref. [
27] jointly considered wireless resource allocation and long-term client selection perspectives. Ref. [
7] incorporated multiple criteria like computational capability, memory, and energy in client selection to maximize model upload success rates. In contrast, ref. [
20] proposed asynchronous federated learning, where deep reinforcement learning (DRL) on the server selects nodes with higher communication and computation resources for training, uploading local models to the blockchain instead of the server. Finally, in aggregation, the server retrieves global models from the blockchain after local training. Ref. [
28] considered client selection from efficiency and fairness perspectives. Despite these advancements, challenges persist in complex networks like federated learning-assisted IoV due to client heterogeneity. In [
8], the authors proposed client selection considering multi-objective evaluation in the centralized client selection framework, failing to decrease the overhead of exchanging state information. Heterogeneity is one of the key challenges in the FL, encompassing statistical and system variations that reduce accuracy and slow convergence. To address statistical heterogeneity, FedProx [
29] introduced a proximal term in local objective functions to minimize gradient drift, yet did not address system heterogeneity. For example, vehicle mobility in IoV can disrupt connections. Ref. [
30] jointly considered node selection and wireless resource allocation in heterogeneous FL systems to maximize loss function decay and accelerate convergence. Addressing non-independent and identically distributedness, the authors in [
31] employed support vector machines (SVMs) to detect sample features and eliminate irrelevant samples. SCAFFOLD [
32] adjusted update directions by comparing global and local models. While these studies provide theoretical and methodological insights, their integration into real-world applications remains limited. Unfortunately, the mentioned works above have not proposed a selection approach involving multiple factors, such as heterogeneity and bandwidth etc.
Previous works did not consider a research gap, the exchange of state information between clients and servers, which is essential for node selection. The state information exchange becomes huge when the number of candidate nodes participating in training is large. Additionally, the heterogeneity is a key challenge in federated learning. Considering heterogeneity among nodes during the selection process can greatly enhance the model accuracy and accelerate the convergence. To address the issues above, we propose a distributed client selection scheme, which leverages two different channels, specifically, the cellular networks to transmit the model between vehicles and the central server, and DSRC technology to exchange the state information between vehicles in the vicinity. The proposal selects the clients by distributed approach, like each individual votes independently by in a election. To sort the all participants, a scalar value is required for the assessment of vehicle. Multi-objective evaluator is adopted to assess heterogeneous nodes with varying computational capability, communication bandwidth, sample quantity, and data with non-independent and identically distributedness.
4. Distributed Client Selection Framework
In this section, we firstly present the workflow of client selection in the distributed scheme. Then, the differences between centralized federated learning (CFL) and distributed federated learning are discussed. Three different client selection schemes are compared, and the advantages of the distributed client selection scheme are described. Following that, we present two types of communication overhead in federated learning: the overhead from exchanging models between the FL server and the clients, and the overhead from maintaining the active state of all participants. We also compare these two types of overhead using GBoard as an example. Finally, we describe the distributed client selection in detail.
4.1. Workflow of Distributed Client Selection
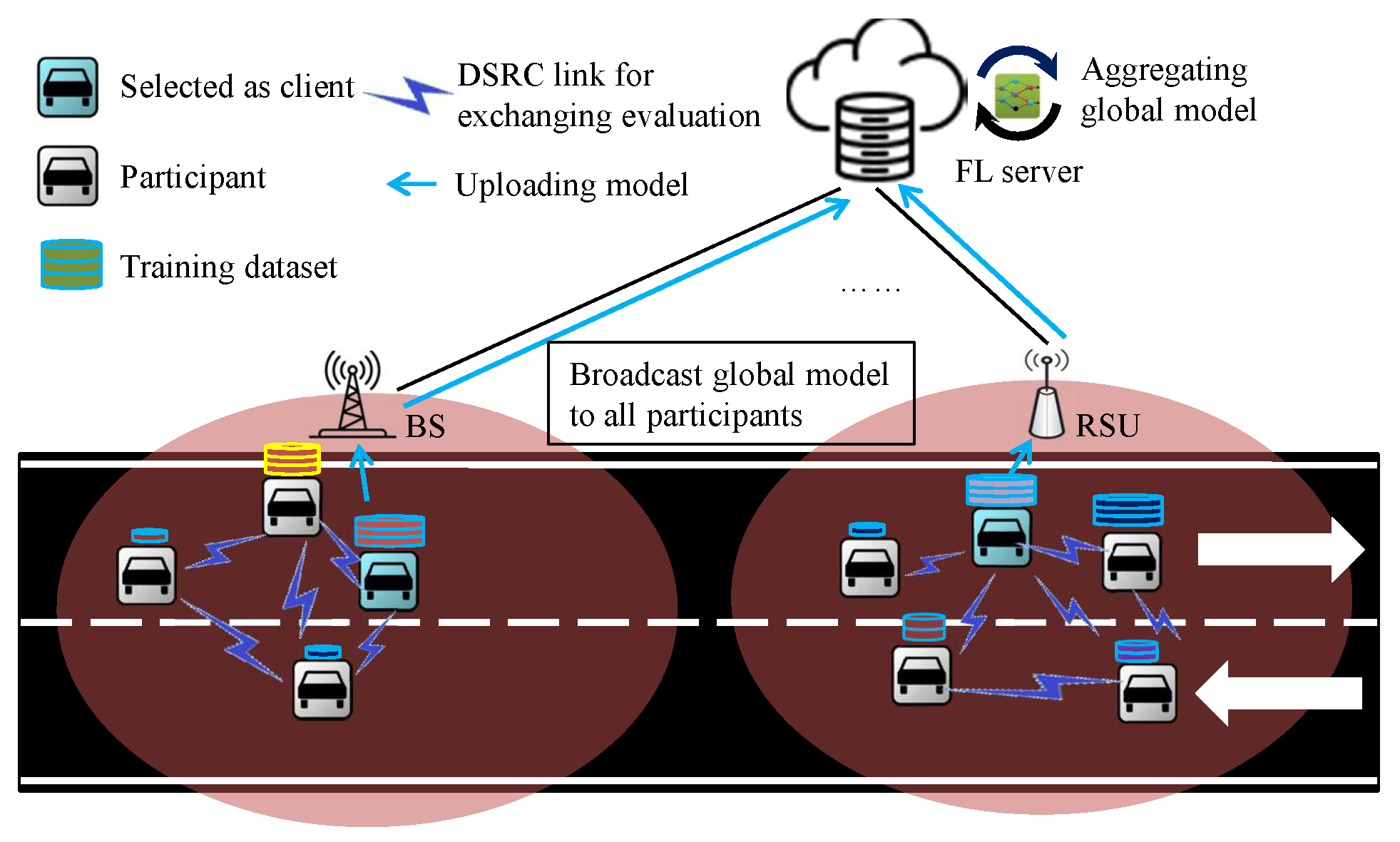
The workflow of the distributed client selection scheme is presented below as shown in
Figure 2. The selection process does not require the state information gathered in the server, including the assessment of nodes calculated by the fuzzy evaluator. Each communication round consists of seven steps, which can be grouped into two stages: the selection stage and the training stage. Steps ➀, ➁, ➂, and ➃ belong to the selection stage, while the remaining steps belong to the training stage.
Selection stage: The server is responsible for broadcasting fuzzy parameters involving the membership functions and the fuzzy rules to all participants at the beginning of the communication round. The vehicles assess themselves according to the current state information. Then, the assessment is exchanged with the neighbors. Finally, each participant sorts and selects the clients from the top
m neighbors as the clients. The fuzzy parameters are configured based on historical records stored on the server. It is assumed that the server can analyze the historical records and find the optimal fuzzy parameters to meet the system’s requirements. This stage corresponds to steps ➁–➃ in
Figure 2. Notably, step ➀ is run only once at the initialization of the FL.
Training stage: In this stage, every client updates their model over the local dataset. The local model is uploaded to the server once the training is finished. The server aggregates the local models to generate a new global model for the next round when the wall clock elapses. This stage corresponds to steps ➄–➆ in
Figure 2.
4.2. Distributed Client Selection Framework
In CFL, the FL server collects local models from the clients and then aggregates them into a global model using the federated averaging algorithm (FedAvg) [
1]. Meanwhile, all participant states are collected by the FL server for client selection. Conversely, in DFL, the server’s functions are distributed across all clients, including broadcasting the model, uploading the model to other clients, and aggregating the model. Thus, the server’s role is eliminated in FL. Compared with CFL, DFL is more suitable for dynamic networks and offers better scalability and robustness. However, in DFL, there is a potential waste of network resources because models are transmitted multiple times among the clients.
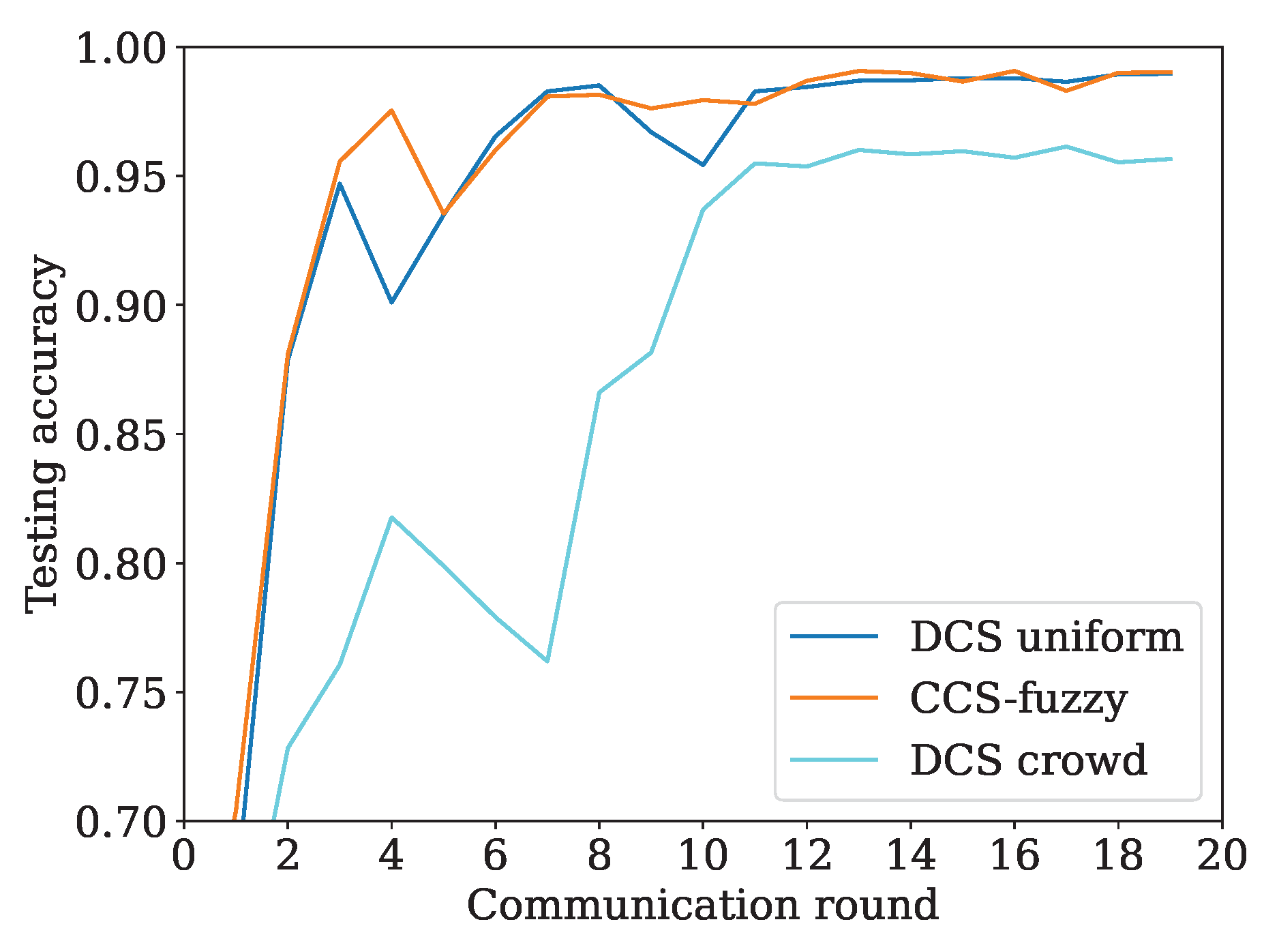
Next, we discuss three client selection schemes as shown in
Figure 3: client selection in CFL, client selection in CFL-fuzzy [
8], and distributed client selection. In CFL, the states of each vehicle are collected by the FL server, which then performs assessment, sorting, selection, broadcasting the global model to all clients, local training, uploading local models, and aggregation as shown in
Figure 3a. The FL server in CFL acts as the coordinator. For client selection in CFL-fuzzy, the assessment of each participant is processed locally and then updated to the FL server. Subsequently, the steps of sorting, selection, broadcasting the global model to all clients, local training, uploading local models, and aggregation are carried out as shown in
Figure 3b. In distributed client selection, the global model is broadcast to all participants at the start of each round, and the assessment is processed locally. Then, evaluations are exchanged among neighbors, and clients are selected. The selected clients train the model on their local dataset and upload their local models to the FL server. Finally, the FL server aggregates all local models received from the clients as shown in
Figure 3c. The detailed process is presented in
Section 4.4. The characteristic of distributed client selection is that client selection adopts a distributed scheme, while model aggregation adopts a centralized scheme. Furthermore, the FL server does not know which participants are selected as clients. This scheme minimizes the overhead caused by maintaining the active state of all participants while maintaining the high efficiency of centralized aggregation.
Adopting the advantages of the distributed client selection scheme, the wireless resource competition between the model and state information can be avoided by using two different channels, specifically, the cellular network and DSRC technology, to transmit the model and the state information, respectively. Conversely, DSRC technology fits well with the distributed scheme, as the vehicles in the vicinity can form a group and select the client. Additionally, the multi-objective evaluator can work well independently, only receiving information from the central server, such as the maximum value of historical bandwidth. Then, the evaluation of vehicles is exchanged among the neighbors without being updated to the central server. For more details about the multi-objective evaluator, please see
Section 5.
Considering the reproducibility of the proposal, firstly, some variables remain constant, such as the maximum network bandwidth, the maximum computational capability of the vehicle, and the maximum training data volume on the vehicle. For example, the maximum network bandwidth is typically related to the capacity of infrastructure like RSU. RSU are upgraded every decade or even longer, which can be considered constant for federated learning. Therefore, federated learning in vehicular networks only needs to consider the specific values of each variable in time to evaluate the assessment of the vehicle, continuously providing data for node selection in the distributed scheme. Secondly, DSRC technology, as a short-range communication technology, has a communication range among vehicles mainly determined by the transmitting power and frequency. Hence, the proposal can operate robustly in any scenario without requiring additional settings. Thirdly, the multi-objective evaluator employs fuzzy logic, which can easily reconfigure the weight between different variables. Meanwhile, removing or adding variables is also easy, making it adaptable to any scenario.
4.3. Communication Overhead
In the FL system, the communication overhead comprises two parts, the overhead by exchanging models and the overhead by maintaining the active state of all participants. In the dynamic network (e.g., IoV), the participant’s state needs to be constantly updated to the coordinator, such as the FL server, because the resources vary with time continuously. Notice that the participants send a message presenting “I have alive” to the coordinator. The state changes may increase the chance of being selected as a client. So, all participants update the active state to be chosen as a client by the server. In general, the size of maintaining an active state is far larger than the size of exchanging the model when millions of participants exist in the FL system. Next, we analyze a real example from Gboard [
5] to compare the two kinds of overhead. We choose the transmitted data size as a comparing metric. Here,
N is the number of all participants, and
denotes the interval of sending state.
s denotes the size of the state, which includes participant id, resource information (e.g., computational capability, available network throughput, and sample quantity), and other information (e.g., vehicle position, acceleration, and energy).
t denotes the length of a communication round.
m denotes the size of the model. The transmitted data size for maintaining the active state of all participants is defined by (
5):
The parameters referred from [
5] are listed in
Table 1.
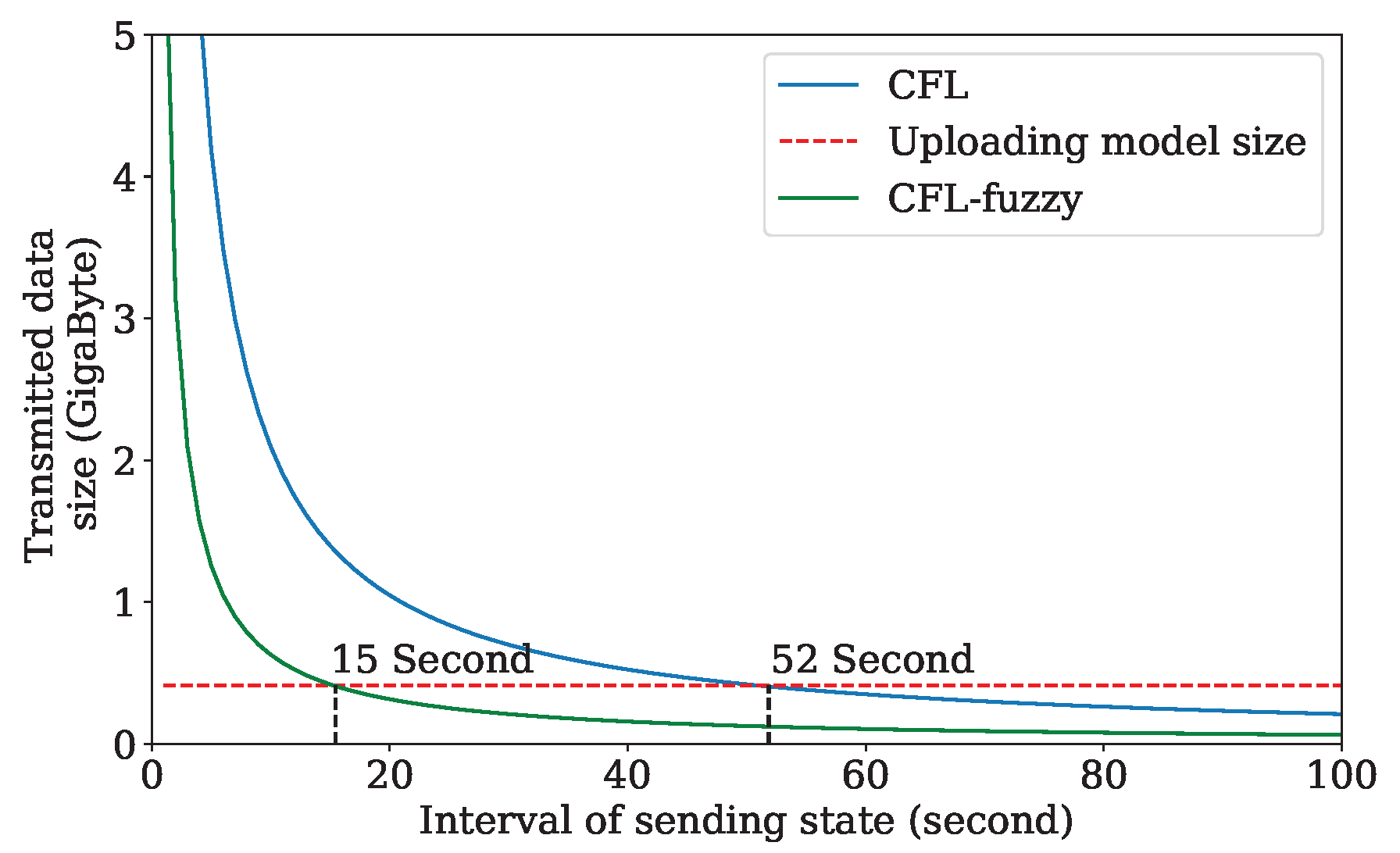
We compare with CFL and CFL-fuzzy [
8] in terms of the overhead maintaining an active state for all participating devices in the Gboard. The dashed red line represents the size of the uploading model in each round over on the selected 300 client devices. The observation from
Figure 4 is that the size of overhead maintaining the active state of all participating devices reaches 22.5 gigabytes in the interval of 1 s. In comparison, the uploading model size is only 0.41 gigabytes. The size of maintaining the active state of all participants decreases with the interval increase. Two curves, CFL and CFL-fuzzy, are crossed with the uploading model size curve at 52 s and 15 s, respectively. However, in a dynamic network, such as IoV, some clients with poor performance are selected and dropped down the model convergence and even cause traffic accidents because the state of the vehicles cannot be updated in such an interval. The distributed client selection framework proposed can achieve low communication overhead and the updating interval of the active state.
4.4. Distributed Client Selection Algorithm
We considered how much a client contributes to the global model in this framework. The client with a larger loss function has more contribution. So, the loss function of the dataset is introduced and used as one of the input variables in the multi-objective evaluation. To this end, the global model is broadcast to all participating vehicles at the start of each round. Every vehicle calculates the loss function without updating the model locally. Algorithm 1 presents the whole process in each round.
| Algorithm 1 Distributed client selection algorithm. |
FL server: - 1:
▹ Broadcast global model to all clients. - 2:
while The deadline is not expired do - 3:
Store from client i. - 4:
end while - 5:
Each participant : - 1:
▹ Calculate loss and no updating model. - 2:
Evaluate the participant . - 3:
if ≥ then ▹ is constant and used as a threshold. - 4:
is broadcast to the neighbors. - 5:
end if - 6:
if is the largest among the neighbors then - 7:
is a client. - 8:
- 9:
Uploading model to the FL server. - 10:
end if
|
Notably, the broadcasting of the model in the distributed client selection involves transmitting it to all participating vehicles. Technically, reliable broadcasting has not yet been achieved. Fortunately, transmitting the model does not necessarily require reliable transmission, as federated learning (FL) can tolerate errors in the model parameters during the transmission stage. Therefore, broadcasting can be implemented using technologies such as multi-cast streaming.
5. Multi-Objective Evaluator
In this section, we describe indispensable parts of the evaluator, including the prediction of the available network throughput and the time taken for training. We present four input variables for the fuzzy evaluator. Next, we explain the fuzzy evaluator, which includes fuzzy rules, the normalization of input variables, and final evaluation. Finally, we illustrate the process of exchanging evaluations.
The evaluator is another important component of distributed client selection, running on each participating vehicle. In the evaluator, we consider four variables—sample quantity, network throughput, computational capability, and loss function of the local dataset—all obtainable locally. Due to the absence of a closed-form solution for these variables, we adopt fuzzy logic as the evaluator, named the fuzzy evaluator. A detailed description about the fuzzy evaluator is provided in
Section 5.3.
The reasons for adopting multi-objective evaluator are listed below. Firstly, federated learning with heterogeneity needs to consider multiple factors, including local computational capability, network bandwidth, training data, and the non-independent and identically distributedness of training data. These factors need simultaneous consideration to enhance performance. Secondly, in practical scenarios, these factors fluctuate with the location of vehicles, time, and environments. Therefore, assessing the vehicles locally is better than using a central server to do so. Thirdly, the relationship among these factors lacks explicit expressions, and they exhibit fuzzy relationships with each other. A multi-objective evaluator with fuzzy logic does not require explicit expressions and is easy to configure for any new scenarios. Based on the above, we adopt a multi-factor evaluator with fuzzy logic to assess the vehicles.
5.1. Prediction to the Network Throughput
The network environment can directly affect exchanging the model between the FL server and the clients. In general, the network throughput at some time can be predicted according to the historical transmitting state in the past.
Communication between the FL server and the client mainly consists of two parts in each round, specifically, broadcasting the global model and uploading the local model to the FL server. The time to broadcast the global model does not affect the performance of the FL since the time can be considered a constant in each round [
35], and the constant does not change anytime or anywhere. The time to upload the local model is the main component in FL communication.
We consider reliable transmitting protocols, such as the transmission control protocol (TCP), used as the exchanging model protocol to upload the local model to the FL server. Therefore, TCP (Reno), a widely used protocol, is adopted to transmit the local model to ensure the trust and reliability of the model with the best effort.
The available throughput of the participating vehicles varies with the mobility of the vehicles. In practice, precisely predicting throughput is necessary for each participant when the fuzzy evaluator assesses the participating vehicle. To predict the throughput available, the sender’s congestion control (CWND_SND) window size in the TCP (RENO) is used to approximate the throughput of the participants. The assumptions are that every participating vehicle plays the sender’s role in sending the data to the FL server, and the history record of CWND_SND is stored in the sender when the data are transmitted. The available throughput of the participating vehicles achieves by averaging the CWND_SND values within a certain period.
The clarification is that the value of available throughput need not be exact, and the obtained value meets some criteria that keep the order, relatively. In other words, the order of the predicted throughput of the participating vehicles also keeps the order in terms of the real throughput in the real world since the evaluator only requires sorting the participating vehicles by the available throughput. In the real world, because of user privacy, predicting avaible throughput accurately has the difficulties.The congestion window size can reflect the variety of available throughput, while the network environment changes with mobility.
5.2. Training Time
Because of the characteristic of heterogeneity, participating vehicles owning the computational capability differ from each other. Meanwhile, the training dataset hardly distributes uniformly over participating vehicles in terms of the sample quantity and classification. The time spent in the training is not identical because every participant has a different computational capability and non-independent and identically distributed dataset (here, non-independent and identically distributed refers to the feature of independent and identically distributed). The drawback of the simulator is the time taken in training, which the client needs to learn previously. Moreover, the simulation process must show the heterogeneity of the FL system mentioned above. Hence, the time taken in the training is calculated by the equation below:
where
refers to the batch size, and
E refers to the number of epochs in the learning.
and
E are described as a constant and are the same for all participants in the FL learning process.
denotes the time to train the model on the client for
samples. The value of
averages a real value, which is obtained from a huge amount of the experiments conducted on PyTorch [
36]. Conducting experiments on the environments is described as follows. The hardware and software configurations are the Intel@Core™ i5 multi-core processor, CPU@2.50 GHz × 8 core, RAM@16 GiB, and PyTorch@1.8 version without GPU.
5.3. Fuzzy Evaluator with Multi-Objective
Fuzzy logic is an approach that does not need a close-form solution over considering the variables and can obtain the list of the output values, having the characteristic of the lightweight, fuzzy logic run on the participating vehicles. We consider four input variables, specifically, the sample quantity, throughput available, computational capability, and loss function of the dataset, which are related to the uploading model success rate as well as the contribution of the global model. These input variables are essential to evaluate whether a participating vehicle is “good” or “bad” for the FL. The reasons are listed as follows. On the one hand, the distance between the vehicle and BSes/RSU varies with the time domain, and the throughput also fluctuates. Similarly, the computational capability is also frequently changed over time. The two input variables above are the main factors affecting the uploading model’s success rate. On the other hand, the dataset with more samples contributes more to the convergence. Meanwhile, in the FL with the non-independent and identically distributed feature, the diversity of the dataset across the participating vehicles can accelerate the convergence and be measured by the loss function. The greater the loss function, the greater the diversity of the dataset [
14]. Therefore, the sample quantity and the loss function are introduced to measure the quality of the dataset. Next, we present the input variables and their description.
Sample quantity (SQ):The convergence can be accelerated when more samples are trained in machine learning. Similarly to FL, the client with more samples participates in the FL, speeding up the convergence. Hence, the participant with more samples should be selected as the client to join the FL. Considering the number of clients, selecting as many clients as possible is equivalent to training more samples in the round. However, the number of clients must be restricted because of the bandwidth limitation. Selecting a client with more samples is more efficient than the method that selects many clients. Therefore, the fuzzy evaluator uses the sample quantity as an input variable. The value of the sample quantity is normalized into [0, 1]. The normalization is mapped into three levels—sufficient, average, and shortage—as shown in
Figure 5a.
Throughput available (TA): The throughput determines whether the model is uploaded successfully. This variable represents the network environment of the vehicle and is affected by the number of nodes around, allocated RBs, and the distance to the BSes/RSU. Obtaining the throughput availability is described in
Section 5.1.
Figure 5b shows the membership function of the throughput availability. Similarly to the sample quantity, the throughput available is normalized and mapped into three levels of good, middle, and poor as shown in
Figure 5b.
Computational capability (CC): The computational capability determines how fast the learning is. This variable denotes the available computing power of the participant, which is one of the factors affecting the training time. Similarly to the sample quantity, the computational capability is also normalized and mapped into three levels of strong, middle, and weak as shown in
Figure 5c.
Loss function (LF):Training various samples can improve the generalization ability of the model. Selecting a client with diversity has more contribution to the convergence. In the paper, we adopt the loss function to measure the diversity of the dataset, calculated by (
7):
The loss function calculation is the same as the loss function in the training but without updating the gradient. In addition, all samples need to calculate the loss function once to average the error. The shuffling sample does not affect the result without updating the model. The greater loss function represents that the dataset owns higher diversity and some new features. The loss function is also normalized and mapped into three levels of greater, middle, and lower as shown in
Figure 5d.
All variables adopt the Gaussian function as the membership function to ensure that a different input value results in different output for the evaluation. The dashed line represents the mean of the input variable calculated from the historical records.
For the unity of the expression, all input variables are normalized into [0, 1] by (
8). Two variables named “
” and “
” need to be replaced by the actual value of a specific input variable in (
8):
where “
Value” denotes the result of a specific input variable gathered locally in real time, as variables with different measure need to be mapped to the same scale. “
Maximum of input variable” denotes the maximum value of an input variable in the historical record.
The fuzzy evaluator comprises four components: fuzzification, fuzzy rules, defuzzification, and client selection. The Mamdani method is used as the fuzzy inference technique. Regarding the fuzzification of the output value, the output of four variables is mapped into three levels as shown in
Figure 5a–d. The normalization of the input variable is associated with the output variable through fuzzy rules and output to nine levels from
to
. Detailed fuzzy rules are listed in
Table 2.
Fuzzification is such that the crisp input value needs to be transformed into three different linguistics. These linguistics are described in
Section 5.3. Moreover, the bound of each linguistic is defined through historical records.
The fuzzy rule contains 81 items since there are four input variables, and each input variable is mapped into three linguistics as shown in
Table 2. Each item in
Table 2 is implemented by a simple if–then logic with single or multiple antecedents. Finally, all antecedents are outputted to one consequent. Those rules are essential to the evaluation of participating vehicles. Many experiments are conducted to decide the mapping relationship between the input and output, and the experiment with the best performance is selected as the item of the fuzzy rule.
Defuzzification is that the output needs to be transformed to a scalar through the center of gravity (COG), one of the most commonly used methods. COG is defined as shown in (
9):
where
,
, and
n denote the sample element, the membership function, and the number of the element in the group, respectively.
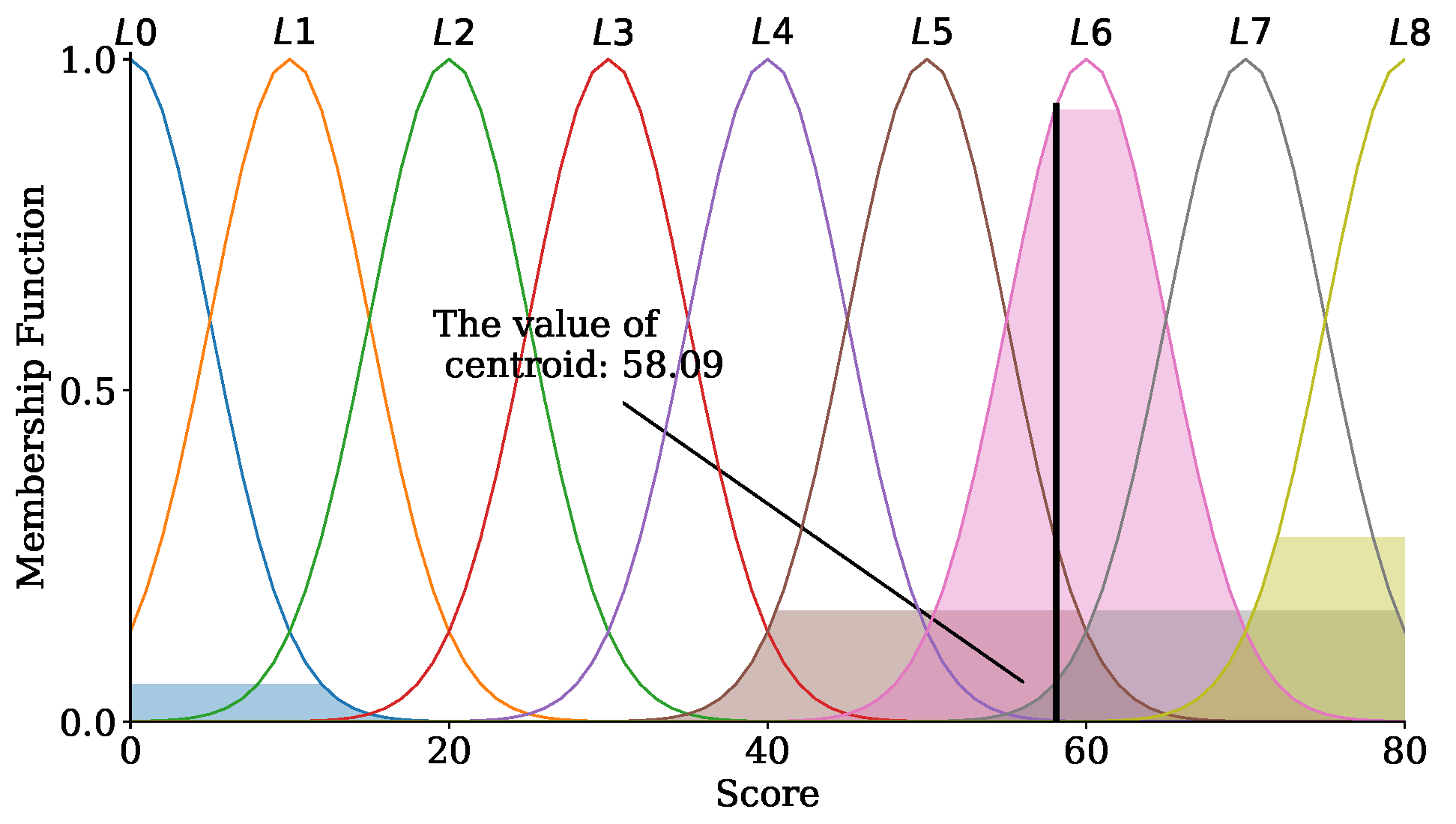
Figure 6 illustrates the COG. The value of 58.09 in
Figure 6 represents an output calculated by (
9), and the value belongs to the L6 level.
The final evaluation is broadcast over DSRC communication to all neighbors. Each participating vehicle maintains a table to store and update the evaluation received from the neighbors and itself. Ultimately, the table’s top m contains its id. The participating vehicle becomes a client, while the table contains its id and vice versa. Following this, the selected client trains the dataset and uploads their local model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}