
An Improved YOLOv7-Based Model for Real-Time Meter Reading with PConv and Attention Mechanisms


Abstract

1. Introduction
- (1)
- In grid meter detection, PConv was introduced into the base module of YOLOv7 and it obtained a relatively optimal replacement structure through multiple experiments, reducing the model’s FLOPs and parameters.
- (2)
- An adaptive calibration algorithm was proposed for pointer reading calculation, which exhibited a relatively high robustness and good detection accuracy.
- (3)
- DyHead was integrated into YOLOv7, incorporating an attention mechanism that boosted the accuracy when detecting small target features.
2. Related Work
2.1. Real-Time Object Detection
2.2. Pointer Meter Reading
3. Methods
3.1. Data Augmentation
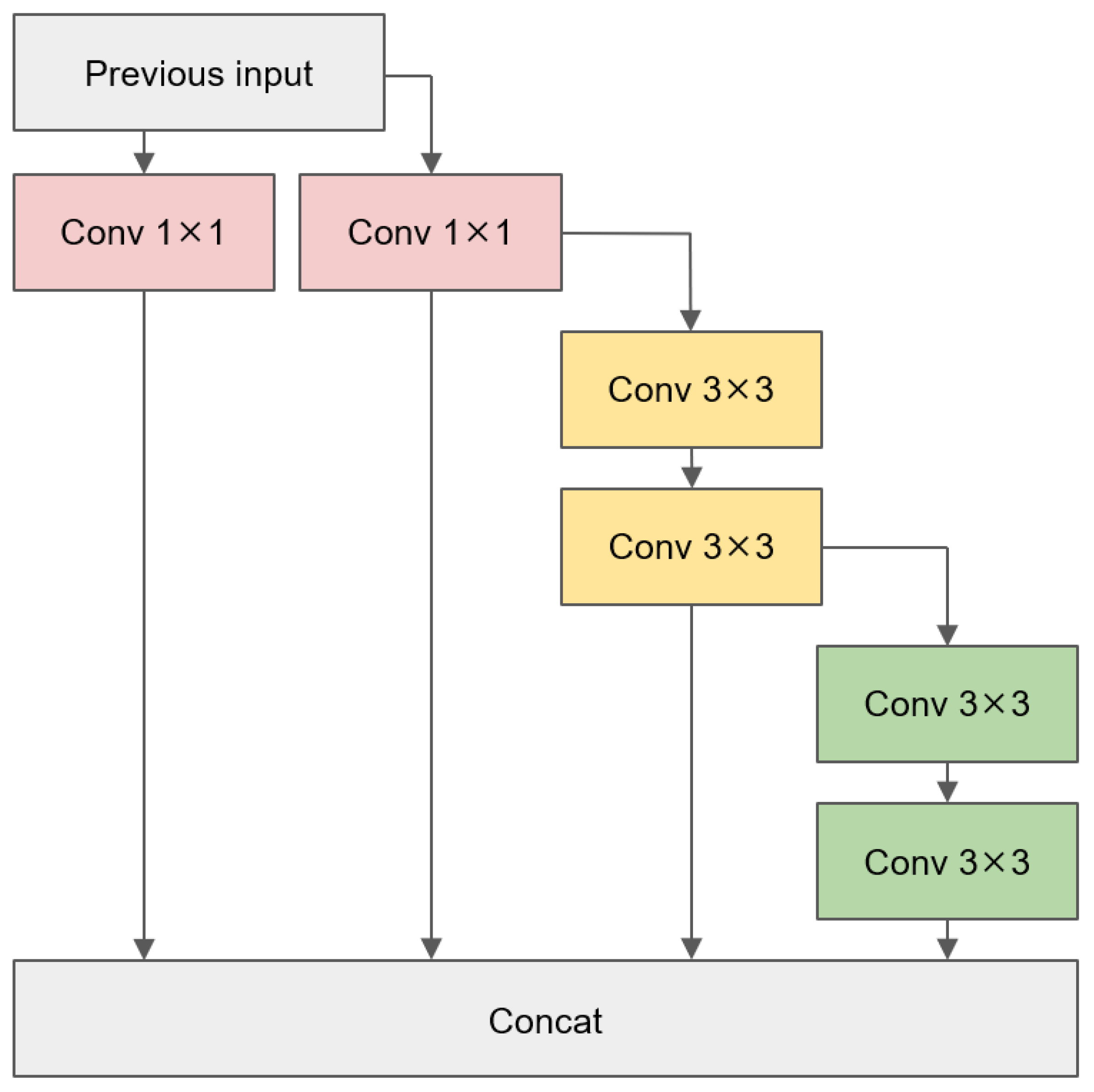
3.2. ELAN-PConv
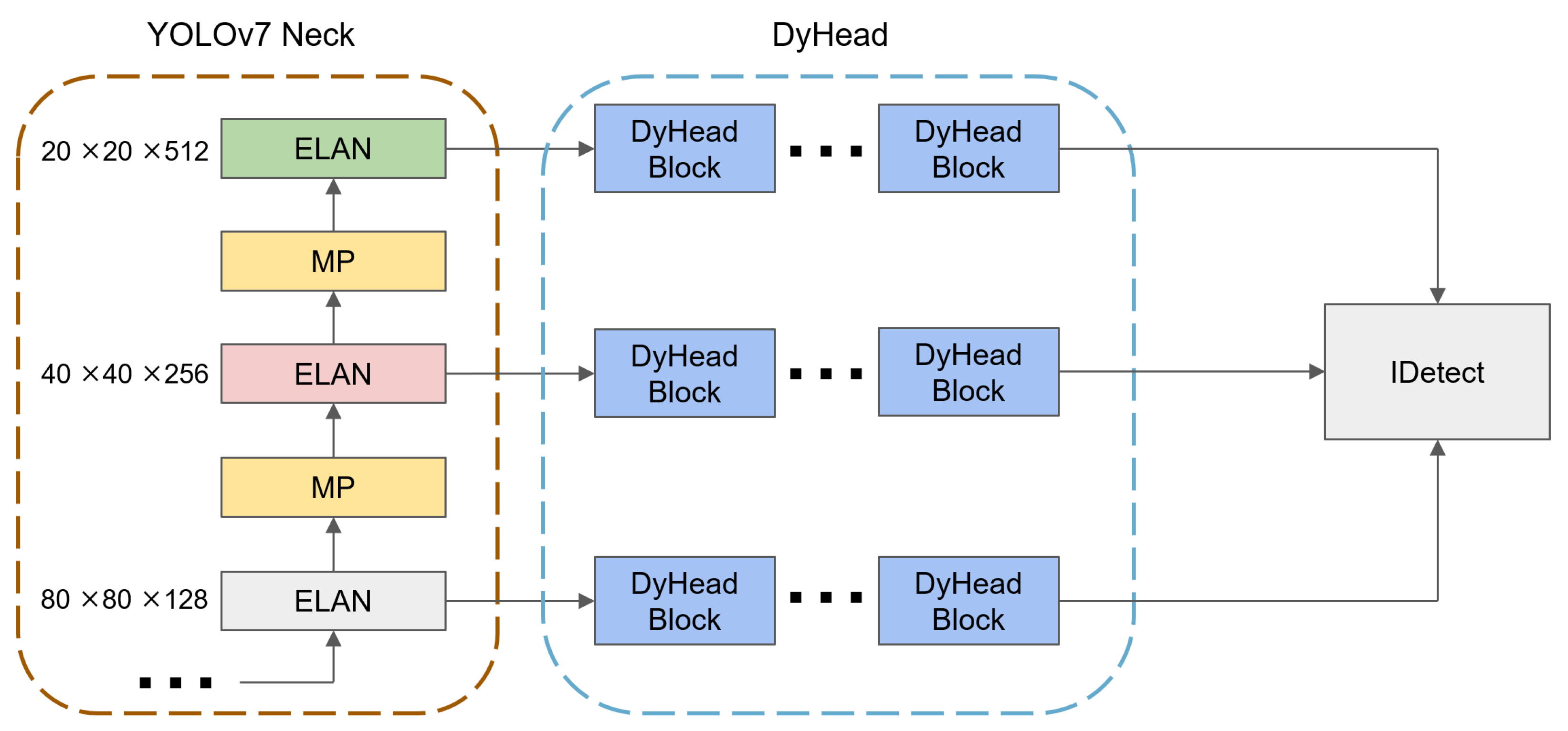
3.3. Change to DyHead
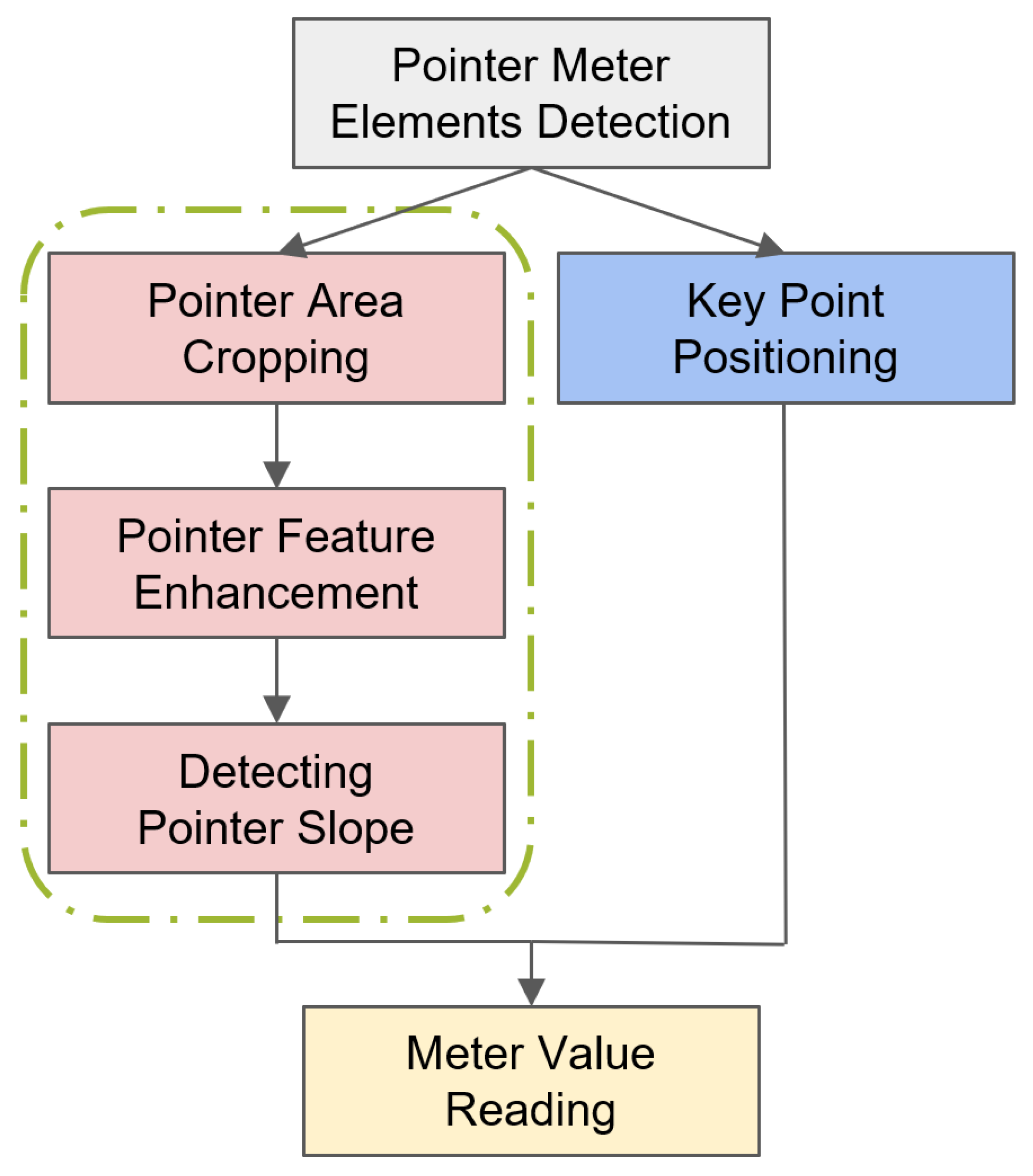
3.4. Adaptive Calibration Pointer
4. Experiments
4.1. Experimental Setup
4.2. Ablation Study
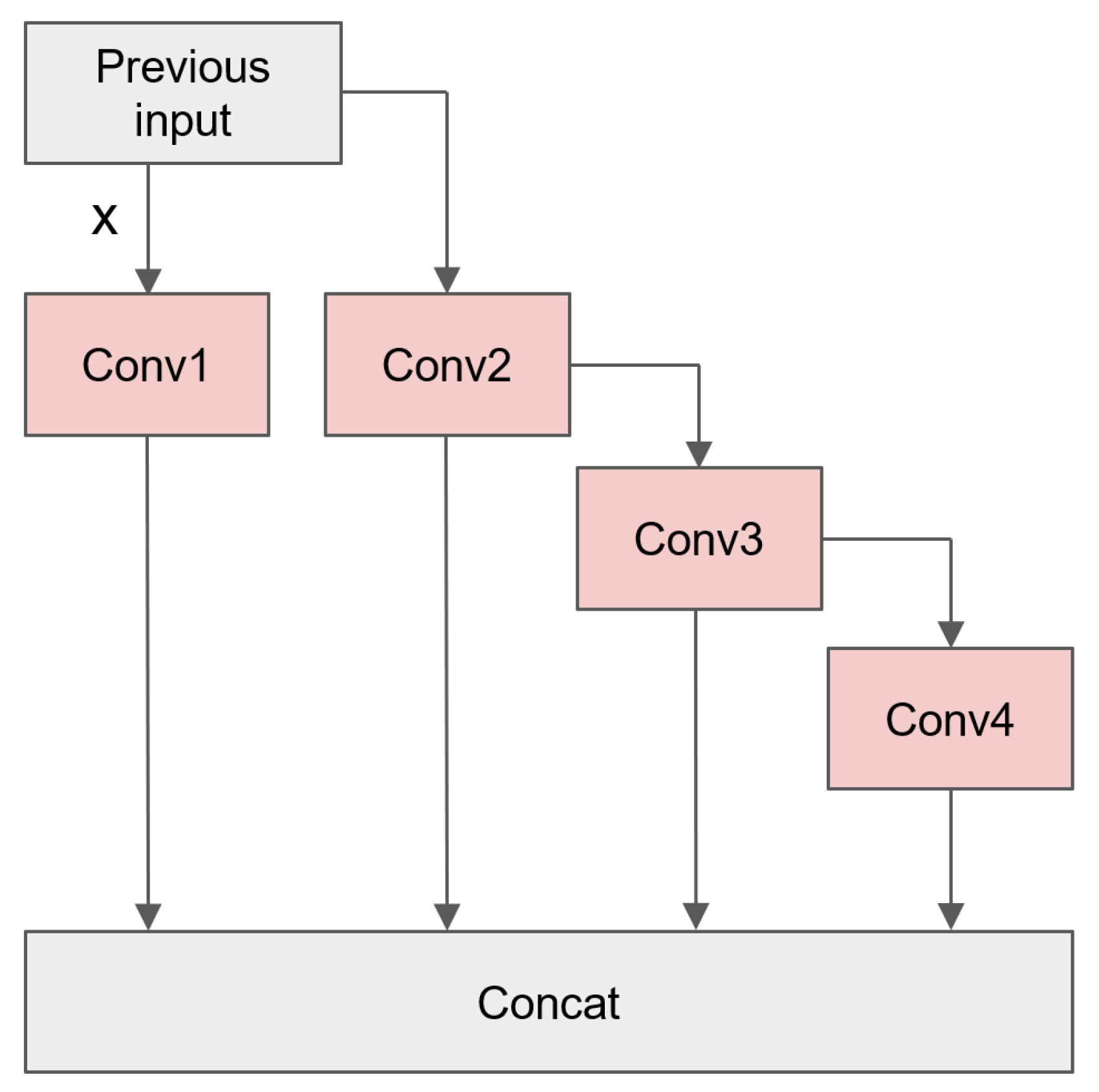
4.2.1. PConv Replacement Position in ELAN
4.2.2. Module Ablation Study
4.2.3. Meter Reading Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Fang, B.; Zhao, X.; Zhang, H.S. Pointer-type meter automatic reading from complex environment based on visual saliency. In Proceedings of the 2016 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Jeju Island, Republic of Korea, 10–13 July 2016; pp. 264–269. [Google Scholar] [CrossRef]
- Illingworth, J.; Kittler, J. A survey of the Hough transform. Comput. Vis. Graph. Image Process. 1988, 44, 87–116. [Google Scholar] [CrossRef]
- Meng, L.; Cheng, J. Research on the Visual Recognition Method of Pointer Water Meter Reading. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; Volume 5, pp. 909–914. [Google Scholar] [CrossRef]
- He, P.; Zuo, L.; Zhang, C.; Zhang, Z. A Value Recognition Algorithm for Pointer Meter Based on Improved Mask-RCNN. In Proceedings of the 2019 9th International Conference on Information Science and Technology (ICIST), Hulunbuir, China, 2–5 August 2019; pp. 108–113. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Fan, Z.; Shi, L.; Xi, C.; Wang, H.; Wang, S.; Wu, G. Real Time Power Equipment Meter Recognition Based on Deep Learning. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads With Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Sun, Y.; Li, Y.; Li, S.; Duan, Z.; Ning, H.; Zhang, Y. PBA-YOLOv7: An Object Detection Method Based on an Improved YOLOv7 Network. Appl. Sci. 2023, 13, 10436. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Conv1 | Conv2 | Conv3 | Conv4 |
|---|---|---|---|---|
| + PConv-1 | ✓ | ✓ | ✓ | ✓ |
| YOLOv7 + PConv-2 | ✓ | ✓ | ||
| + PConv-3 | ✓ | ✓ | ||
| + PConv-4 | ✓ | ✓ | ||
| + PConv-5 | ✓ | ✓ | ✓ |
| Model | FLOPs | ||
|---|---|---|---|
| 6.02 M | 1.31 M | 13.2 G | |
| + PConv-1 | 4.73 M | 0.41 M | 10.5 G |
| + PConv-2 | 6.12 M | 1.38 M | 13.6 G |
| + PConv-3 | 4.83 M | 0.33 M | 10.1 G |
| + PConv-4 | 5.35 M | 0.86 M | 11.9 G |
| + PConv-5 | 4.78 M | 0.37 M | 10.3 G |
| Model | FPS | |||
|---|---|---|---|---|
| 7.6 ms | 104 | 97.13% | 60.33% | |
| + PConv-1 | 6.2 ms | 109 | 97.09% | 59.61% |
| + PConv-2 | 5.9 ms | 114 | 98.12% | 59.23% |
| + PConv-3 | 7.1 ms | 104 | 98.27% | 59.05% |
| + PConv-4 | 6.5 ms | 108 | 97.75% | 60.48% |
| + PConv-5 | 6.1 ms | 110 | 97.55% | 59.34% |
| Model | Params | FLOPs | FPS | ||
|---|---|---|---|---|---|
| 6.02 M | 13.2 G | 104 | 97.13% | 60.33% | |
| + Dyhead | 5.96 M | 13.0 G | 106 | 97.83% | 62.43% |
| + Pconv-1 | 4.73 M | 10.5 G | 109 | 97.09% | 59.61% |
| + Pconv-4 | 5.35 M | 11.9 G | 108 | 97.75% | 60.48% |
| + Pconv-1 + Dyhead | 4.77 M | 10.5 G | 110 | 97.80% | 60.96% |
| + Pconv-4 + Dyhead | 5.37 M | 11.8 G | 108 | 97.87% | 62.67% |
| Model | Params | FLOPs | ||
|---|---|---|---|---|
| 6.02 M | 13.2 G | 97.13% | 60.33% | |
| + Pconv-1 + Dyhead | 4.77 M | 10.5 G | 97.80% | 60.96% |
| + Pconv-4 + Dyhead | 5.37 M | 11.8 G | 97.87% | 62.67% |
| 12.1 M | 19.0 G | 95.38% | 55.78% | |
| YOLOv5n | 1.7 M | 4.2 G | 96.62% | 59.32% |
| YOLOv5n6 | 3.1 M | 4.3 G | 96.72% | 58.94% |
| YOLOv5s | 7.2 M | 17.0 G | 97.18% | 59.35% |
| YOLOv6n | 4.2 M | 11.9 G | 96.77% | 59.51% |
| YOLOv8n | 3.0 M | 8.2 G | 96.51% | 59.73% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Chen, Y.; Cai, X.; Liu, J. An Improved YOLOv7-Based Model for Real-Time Meter Reading with PConv and Attention Mechanisms. Sensors 2024, 24, 3549. https://doi.org/10.3390/s24113549
Peng X, Chen Y, Cai X, Liu J. An Improved YOLOv7-Based Model for Real-Time Meter Reading with PConv and Attention Mechanisms. Sensors. 2024; 24(11):3549. https://doi.org/10.3390/s24113549
Chicago/Turabian StylePeng, Xiancheng, Yangzhuo Chen, Xiaowen Cai, and Jun Liu. 2024. "An Improved YOLOv7-Based Model for Real-Time Meter Reading with PConv and Attention Mechanisms" Sensors 24, no. 11: 3549. https://doi.org/10.3390/s24113549
APA StylePeng, X., Chen, Y., Cai, X., & Liu, J. (2024). An Improved YOLOv7-Based Model for Real-Time Meter Reading with PConv and Attention Mechanisms. Sensors, 24(11), 3549. https://doi.org/10.3390/s24113549