1. Introduction
In snow-covered and cold regions, which account for approximately 60% of the land area in Japan, numerous winter-related traffic accidents occur due to weather conditions, e.g., snowfall. Approximately 90% of these accidents are slip-related incidents associated with winter road surface conditions due to snow accumulation and ice formation [
1]. In this context, road managers need to undertake snow and ice control operations, e.g., snow removal and the spreading of anti-freezing agents by detecting or predicting road surface conditions to prevent slip accidents [
1,
2].
Previous studies have investigated the detection or prediction of winter road surface conditions [
3,
4,
5,
6,
7,
8]. In the literature [
3], the road surface condition was predicted based on the heat balance theory using digital geographical data, which represent the shape of the land, including roads on computers; however, this method requires the analysis of digital geographical data related to the road, and it is difficult to collect and accumulate such data for all roads. In another study [
7], the automatic detection of winter road surface conditions was realized using deep learning models trained on images captured by vehicle-mounted cameras. Similarly, winter road surface conditions were classified using hierarchical deep learning models applied to images also captured by vehicle-mounted cameras [
8]. Here, to use images captured by vehicle-mounted cameras, it is necessary to drive on the road to be analyzed with vehicles equipped with cameras. To reduce such efforts, in the literature [
4], data obtained from sensors and fixed-point cameras installed along roads were adopted to detect or predict the winter road surface conditions using rule-based methods. In addition, a previous study [
5] achieved detection by classifying road surface conditions using differential methods based on images captured by fixed-point cameras installed along the road (hereafter referred to as road surface images). However, due to the temporal variability of road surfaces and roadside features, methods based on differential approaches require manual updating of the reference images. Thus, there is a demand for models that can classify road surface conditions automatically and accurately to facilitate precise detection and prediction. Several studies have focused on the winter road surface condition classification using the images captured by vehicle-mounted cameras [
9,
10,
11]. The purpose of these studies is to help with the construction of autonomous vehicles; however, our purpose is to assist road managers in reducing winter-related traffic accidents using fixed-point cameras.
The multimodal analysis, which uses several information sources, e.g., images and natural languages, has attracted significant attention for improving the representational ability of models [
12,
13,
14,
15]. For example, contrastive language image pre-training has been proposed as the pre-training framework for the multimodal analysis of vision and language [
16]. Another example is to use the texts obtained from Twitter in addition to images for image sentiment analysis [
17]. In this way, most works on multimodal analysis have used vision and language modalities; however, in the classification task of winter road surface conditions, the text information does not exist, and the other information is needed for multimodal analysis. Then, we previously proposed an automated classification method for road surface conditions using a multimodal multilayer perceptron (MLP) using images and auxiliary data [
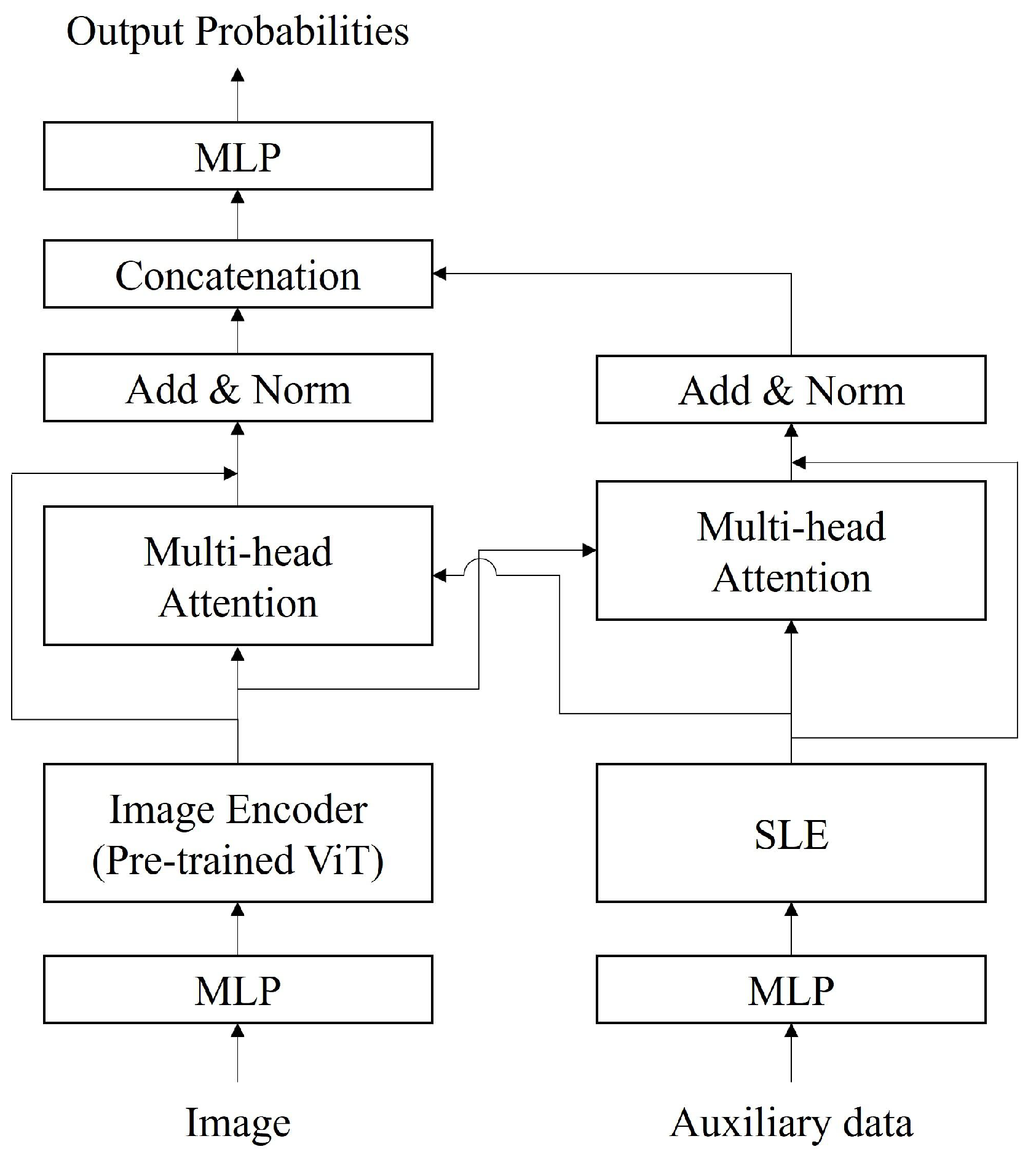
18]. Concretely, in that study, the features calculated from multiple modalities, including road surface images and auxiliary data related to the road surface conditions such as temperatures and traffic volume, were concatenated and input to the MLP to classify the road surface conditions. The cooperative use of multiple modalities allows for mutual complementation between modalities, and we improved classification accuracy compared to using a single modality. However, in the previous study, we focused on the construction of machine learning models using multiple modalities and performed multimodal analysis through a simple feature concatenation process. As a result, this approach may have inherent limitations in terms of classification accuracy. Thus, further improvements in classification accuracy can be expected by introducing the following processes.
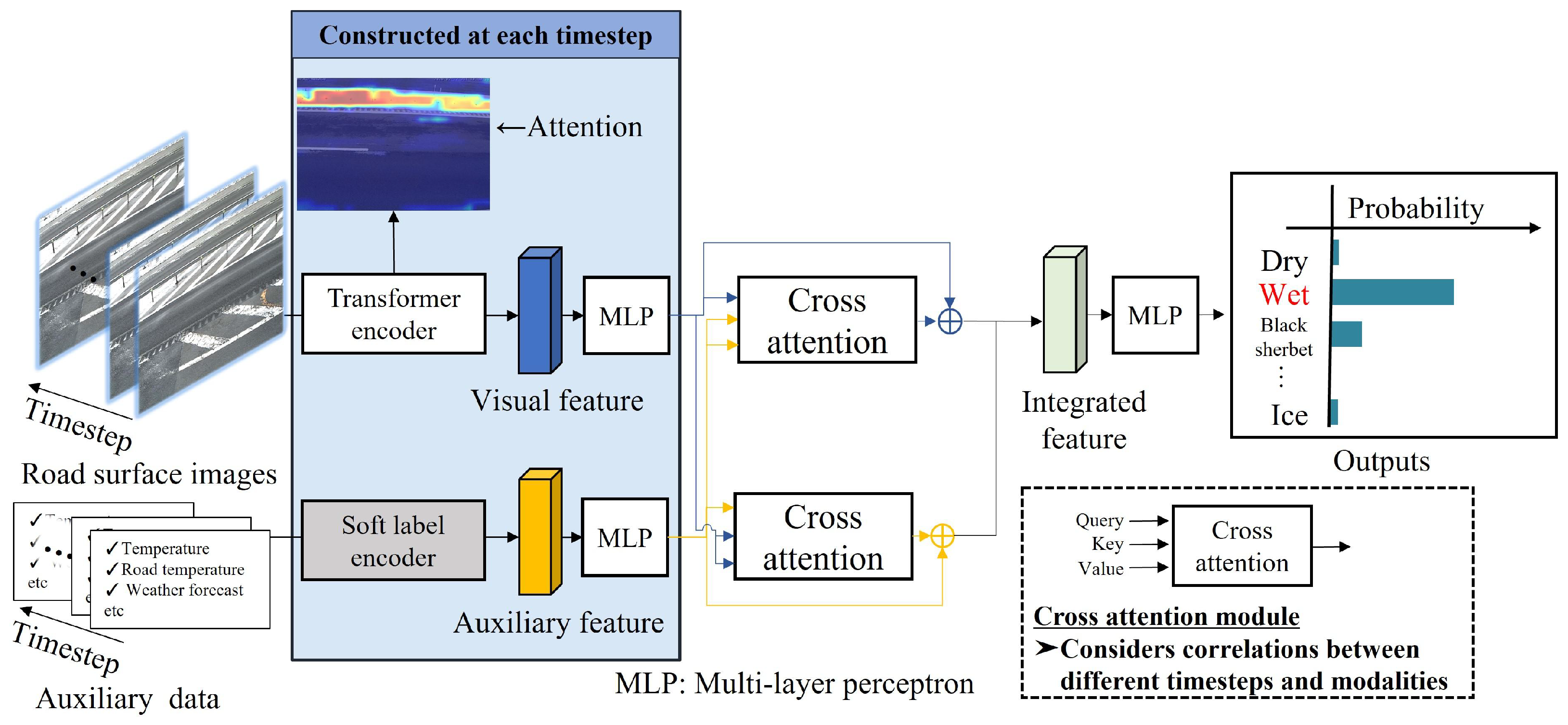
In this paper, we propose a new method for classifying winter road surface conditions using a multimodal transformer (MMTransformer) capable of processing time-series data. In the proposed method, image and auxiliary features are extracted from data spanning multiple timesteps, and feature integration considering temporal changes is performed by applying cross-attention. With cross-attention, correlations are calculated feature-wise for input data across multiple timesteps, and attention is computed for each timestep. This procedure enables feature integration that accounts for temporal changes in road surface conditions. Finally, the classification of winter road surface conditions is realized using an MLP. By exploring methods for integrating multiple modalities and introducing time-series processing, we aim to achieve improvements in accuracy in the detection and prediction of road surface conditions.
In addition, the proposed method can learn the relationship between the input data and the corresponding teacher labels, which are the labels related to winter road surface conditions for training the model. By altering the teacher labels assigned to the input data during training, the proposed method can be adapted to both detection and prediction tasks. In experiments conducted on real-world data, we evaluated the effectiveness of the proposed method for both detection and prediction tasks with two sets of teacher labels. One experiment was conducted with the teacher labels being the road surface condition corresponding to the input data, and the subsequent experiment was conducted with the teacher labels being the road surface condition a few hours after the input data. This dual approach allows for a comprehensive assessment of the capabilities of the proposed method in detecting the current road surface conditions and predicting future road surface conditions.
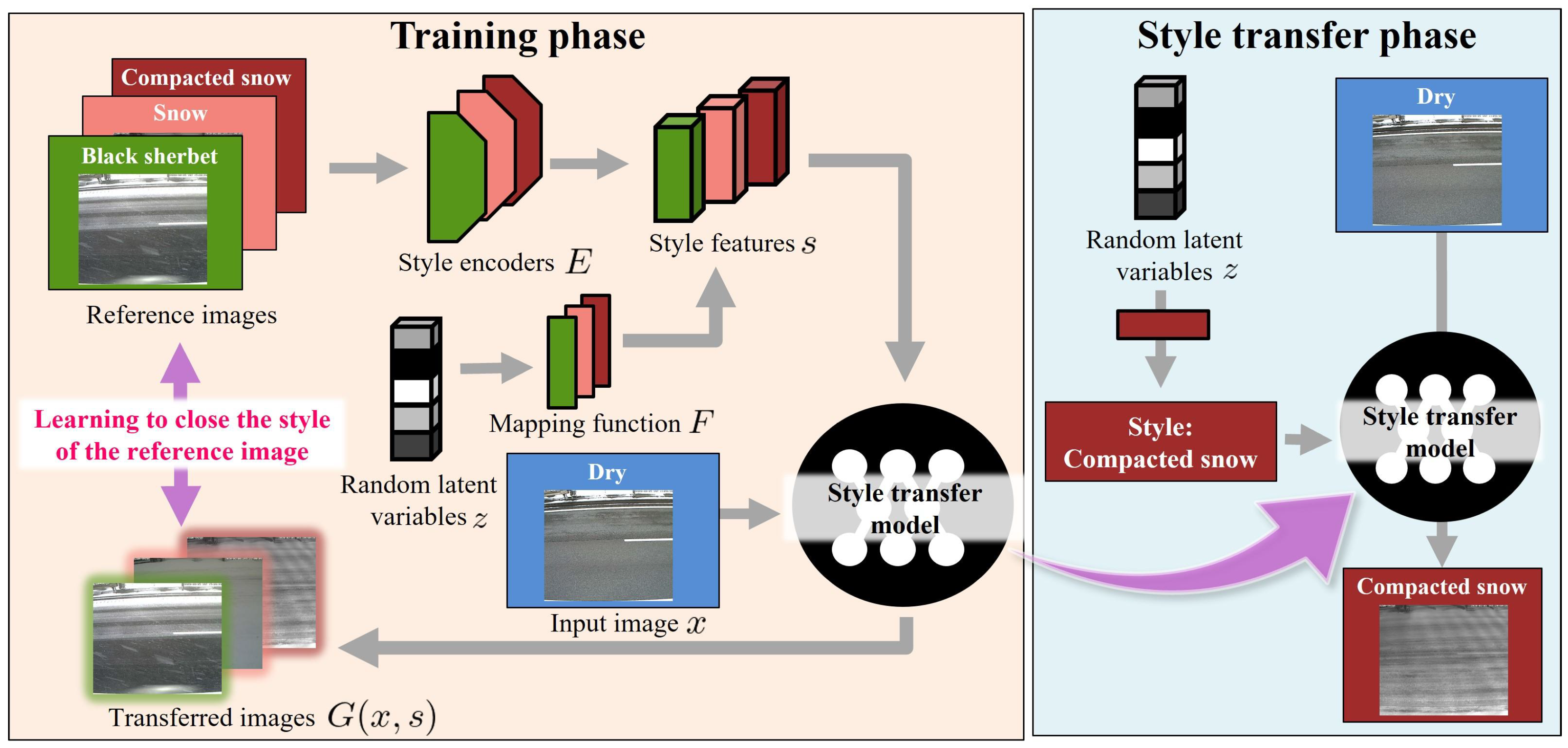
In addition to the experiments on the classification of winter road surface conditions, we conducted supplemental extended experiments on image generation to visualize the classification results, particularly the prediction results in the
Appendix A. To help road managers make decisions, it can be effective to incorporate classification results and road surface images that visualize the results. In this study, we generated such images using an image style transfer model conditioned by road surface conditions. Through these supplemental experiments and visualizing the transferred images, we confirmed the potential of the image transfer model for road surface images.
The primary contributions of this study are summarized as follows.
A multimodal transformer model based on time-series processing and attention mechanisms is constructed to classify road surface conditions.
Experiments conducted to evaluate the road surface condition detection and prediction tasks verify the effectiveness of the proposed classification model.
The results of the supplemental extended experiments in the
Appendix A demonstrate the potential of the image transfer model for road surface images.
The remainder of this paper is organized as follows.
Section 2 introduces the data used in this study. The proposed method for the classification of winter road surface conditions is explained in
Section 3. Then, the experimental results are reported in
Section 4, and the supplemental extended experiments are discussed in
Appendix A. Finally,
Section 5 concludes the paper.
2. Data
In the following, we describe the data used in this study. We utilized road surface images acquired using fixed-point cameras and auxiliary data related to the road surface conditions. Specifically, these data were provided by the East Nippon Expressway Company Limited and were acquired from 2017 to 2019. The road surface images were captured at 20-min intervals from 1 December at 00:00 to 31 March at 23:40 each year. In addition, each road surface image was labeled with one of the following seven categories related to road surface conditions.
Dry
The road surface is free of snow, ice, and wetness.
Wet
The road surface is wet due to moisture.
Black sherbet
Tire tread marks are present, the snow contains a high amount of moisture, and the color of the road surface is black.
White sherbet
Tire tread marks are present, the snow contains a high amount of moisture, and the color of the road surface is white.
Snow
Snow has accumulated on the road surface, and the snow does not contain a high amount of moisture.
Compacted snow
There is no black shine and no tire tread marks.
Ice
Snow and ice are present on the road surface, and it appears black and shiny.
These labels were assigned by three experienced road managers, and they divided the annotation task and assigned the labels through visual inspections. Example road surface images for each category are shown in
Figure 1, and the locations where the road surface images were captured are shown in
Figure 2. Here, the image size is
pixels. Please note that road surface images, including vehicles, were considered for analysis because the vehicles did not cover the entire road surface in the images.
Table 1 shows the contents of the auxiliary data and the corresponding data types. As shown in
Table 1, the “location of road surface images” and “weather forecast” are discrete information, while other data contents are represented as continuous values. As shown in
Figure 1 and
Table 1, the images and auxiliary data differ significantly; thus, a feature integration mechanism is required to complement the deficiencies in each modality. Thus, we attempt to improve the classification accuracy of road surface conditions by integrating multiple modalities at several timesteps.
5. Conclusions
This paper has proposed the MMTransformer method, which uses time-series data to detect and predict winter road surface conditions. The proposed method enhances the representational ability of the integrated features by performing feature correction through mutual complementation between modalities based on a cross-attention-based feature integration method for multiple modalities, e.g., road surface images and auxiliary data. In addition, by introducing time-series processing for the input data at multiple timesteps, the proposed method can integrate features in consideration of the temporal changes in winter road surface conditions. As a result, the proposed method improves the classification accuracy of winter road surface conditions by introducing a new integration for multiple modalities and time-series processing.
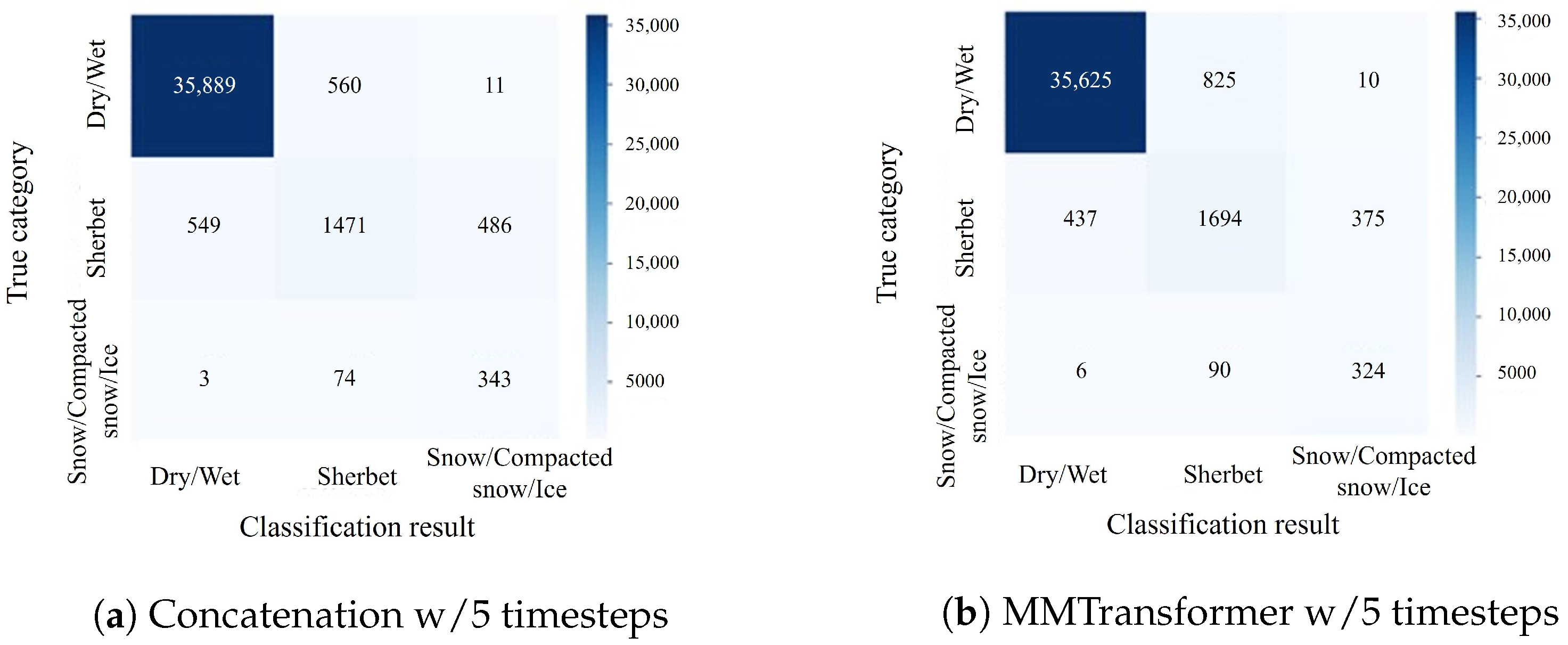
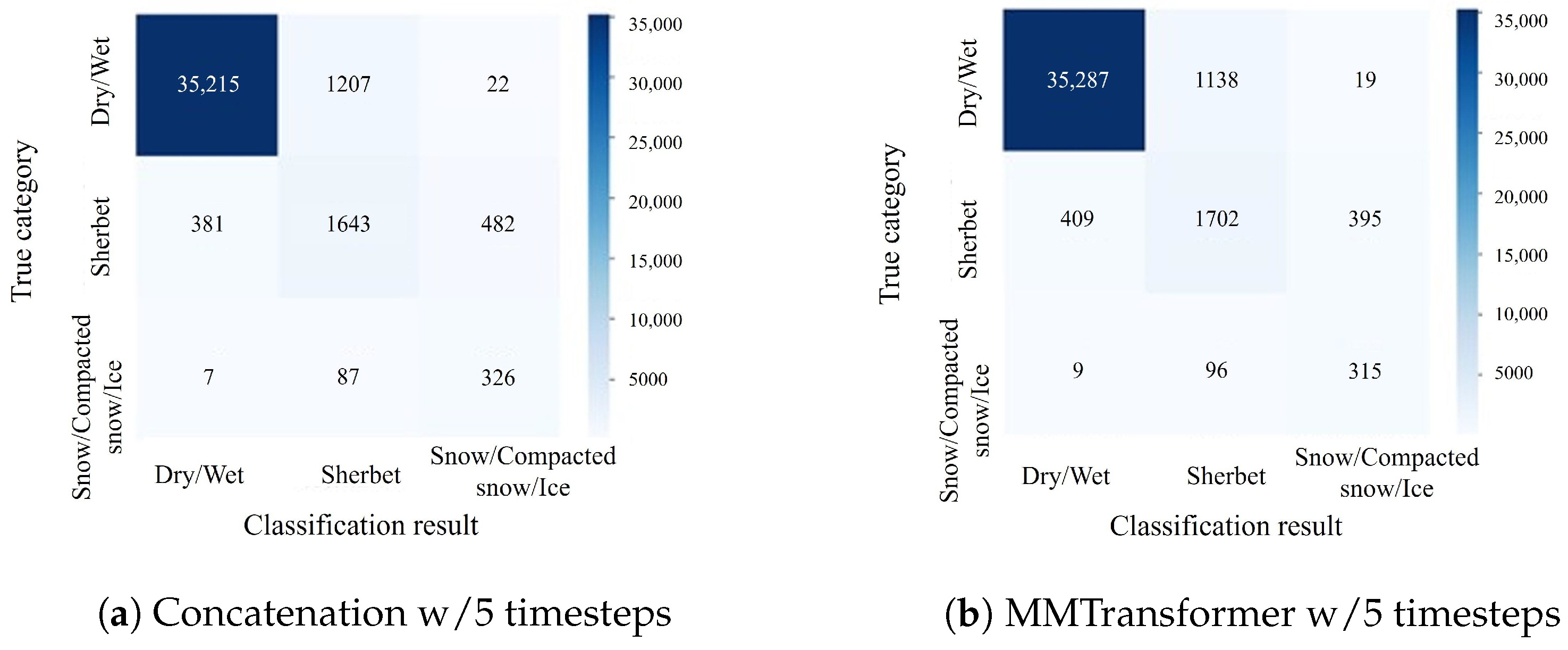
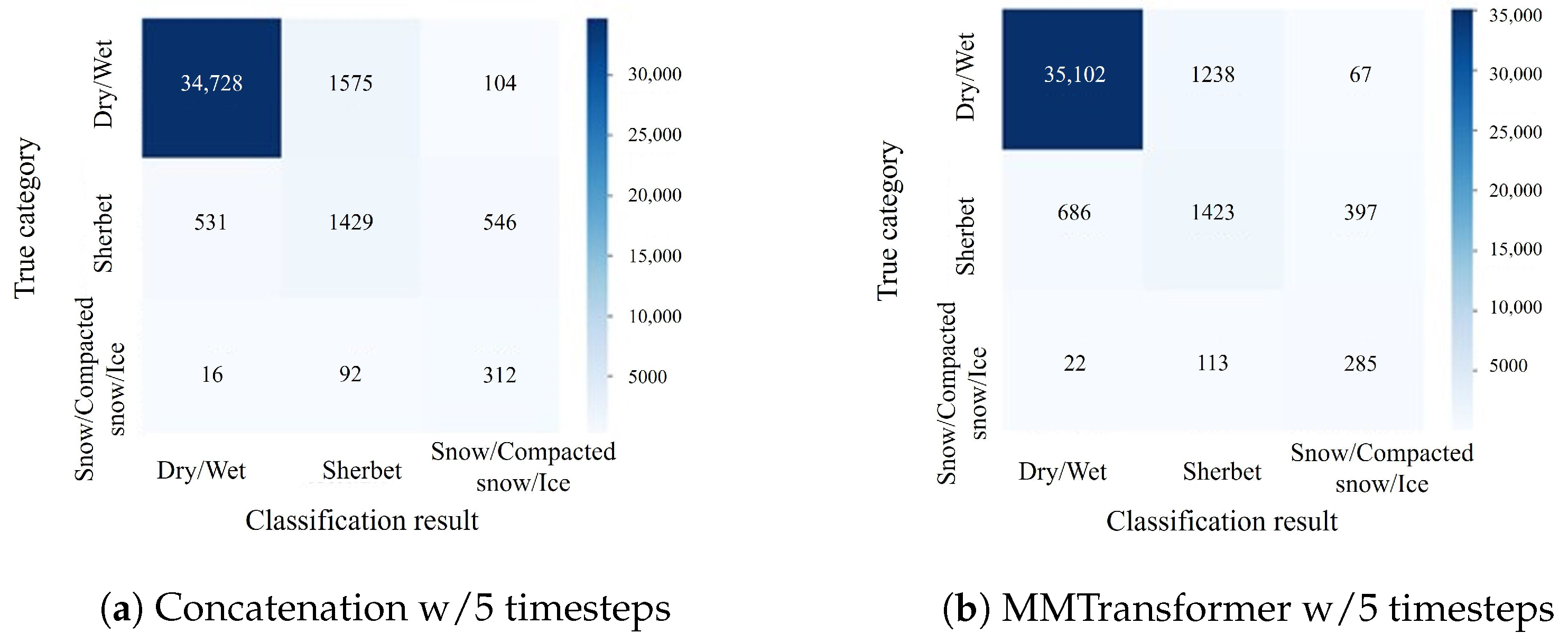
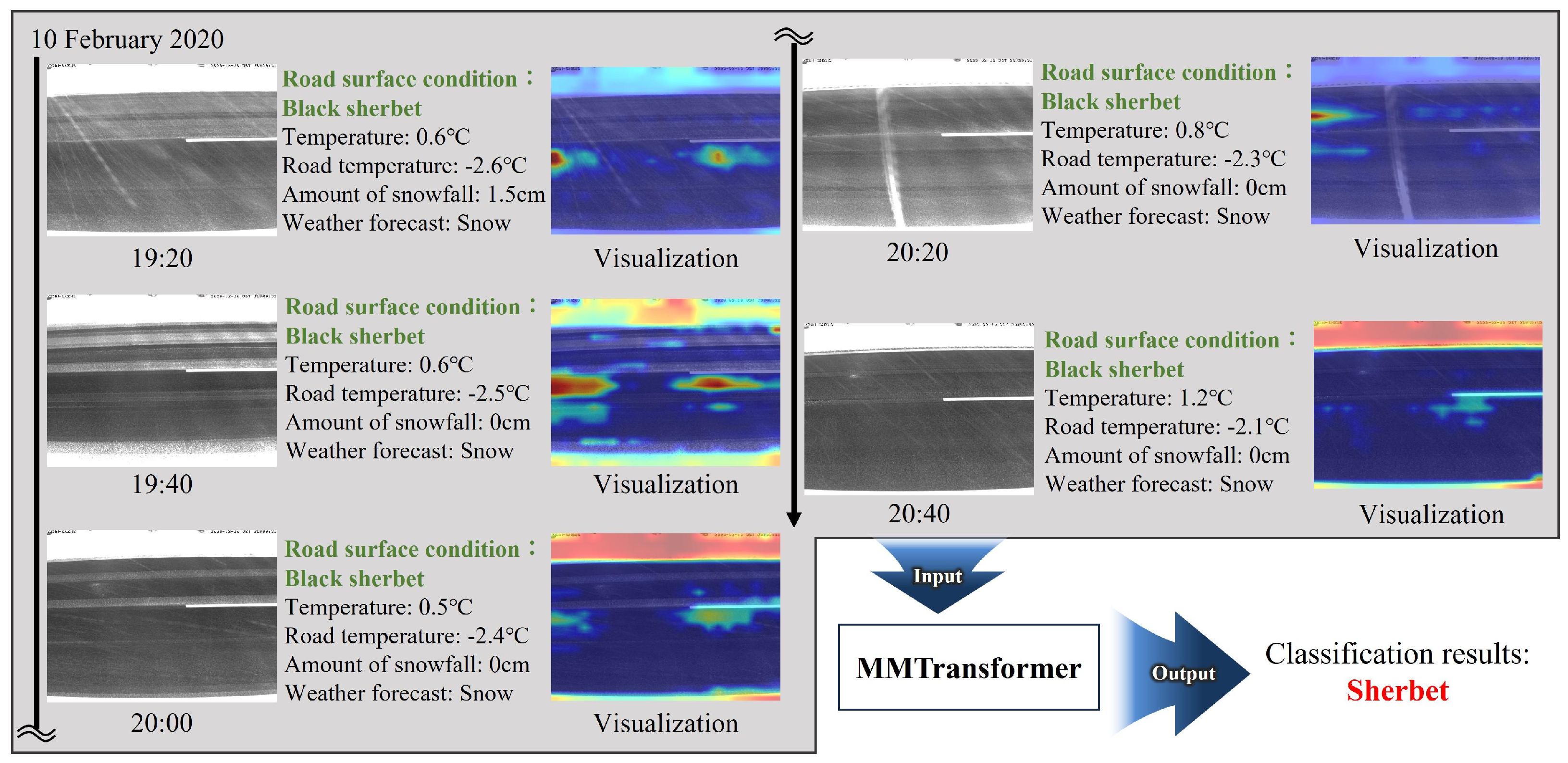
Experiments confirmed that the proposed MMTransformer method achieves high accuracy in classifying winter road surface conditions and is effective for both the detection and prediction tasks by varying the teacher labels. In addition, using attention rollout for visualization, we expected to provide additional insights into the relationship between road surface images and road surface conditions. In this way, as the experimental findings, it was implied that attention rollout works well for the multimodal classification model of winter road surface conditions. The visualization in the image encoder can be utilized to enhance the classification model when detecting and predicting road surface conditions, and the experimental findings discussed in this paper have demonstrated the potential of this technique.
On the other hand, confusion matrices indicate that performance improvement was slight for the data belonging to sherbet or snow/compacted snow/ice categories since the road surface images belonging to sherbet or snow/compacted snow/ice categories were visually similar to those of each other category. Such limitations caused by visual similarity can be solved by effectively leveraging non-visual information, including auxiliary data, which remains in future works.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}