
Device-Free Wireless Sensing for Gesture Recognition Based on Complementary CSI Amplitude and Phase

 ,
,
Abstract
1. Introduction
- A WiFi-based gesture recognition system in which the complementary CSI amplitude and phase are jointly exploited for the classification fusion estimation.
- An improved Fisher method for feature selection which incorporates the distances among category centers to calculate the Fisher score, effectively avoiding misunderstandings caused by the overlap between different categories.
- A classification fusion estimation approach based on a stacking algorithm which in which the CSI amplitude and phase models are trained separately, then a meta-model is constructed to exploit the complementary characteristics of the phase and amplitude.
- Our experiments show that the average accuracy of the proposed HGR system is 98.3%.
2. Related Works
2.1. WiFi-Based Wireless Sensing
2.2. Gesture Recognition
2.2.1. Wearable Sensor-Based Methods
2.2.2. Vision-Based Methods
2.2.3. WiFi-Based Wireless Sensing Methods
3. Human Gesture Recognition System Based on Wireless Sensing
3.1. Framework Overview
3.2. Data Collection
3.3. Data Processing
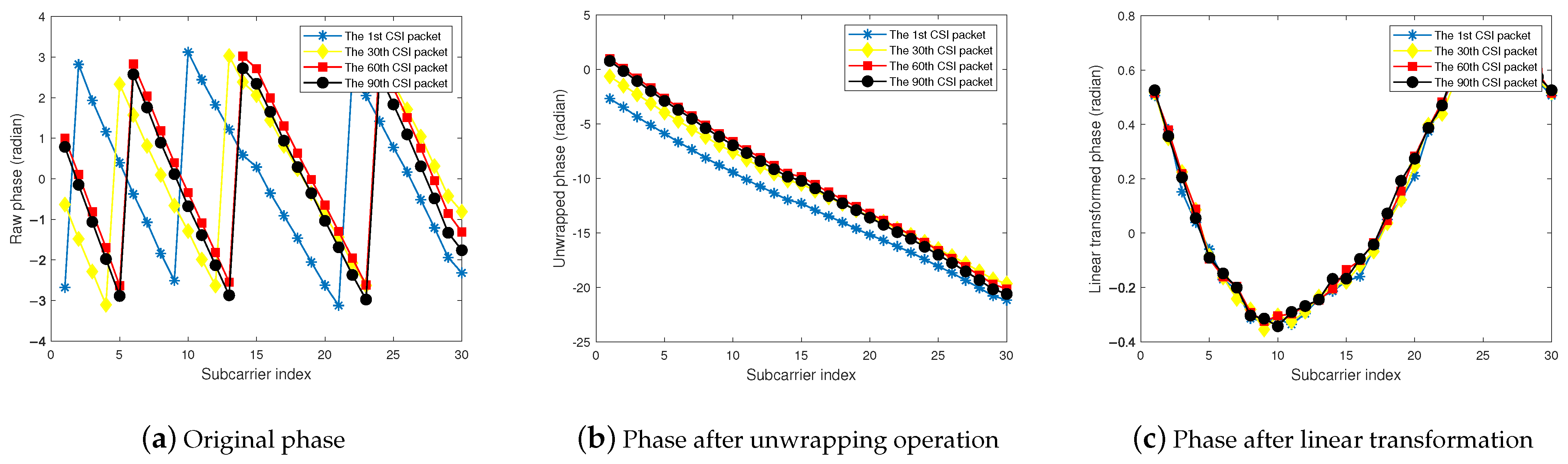
3.3.1. Eliminating Phase Deviation
3.3.2. Replacing Abnormal Data
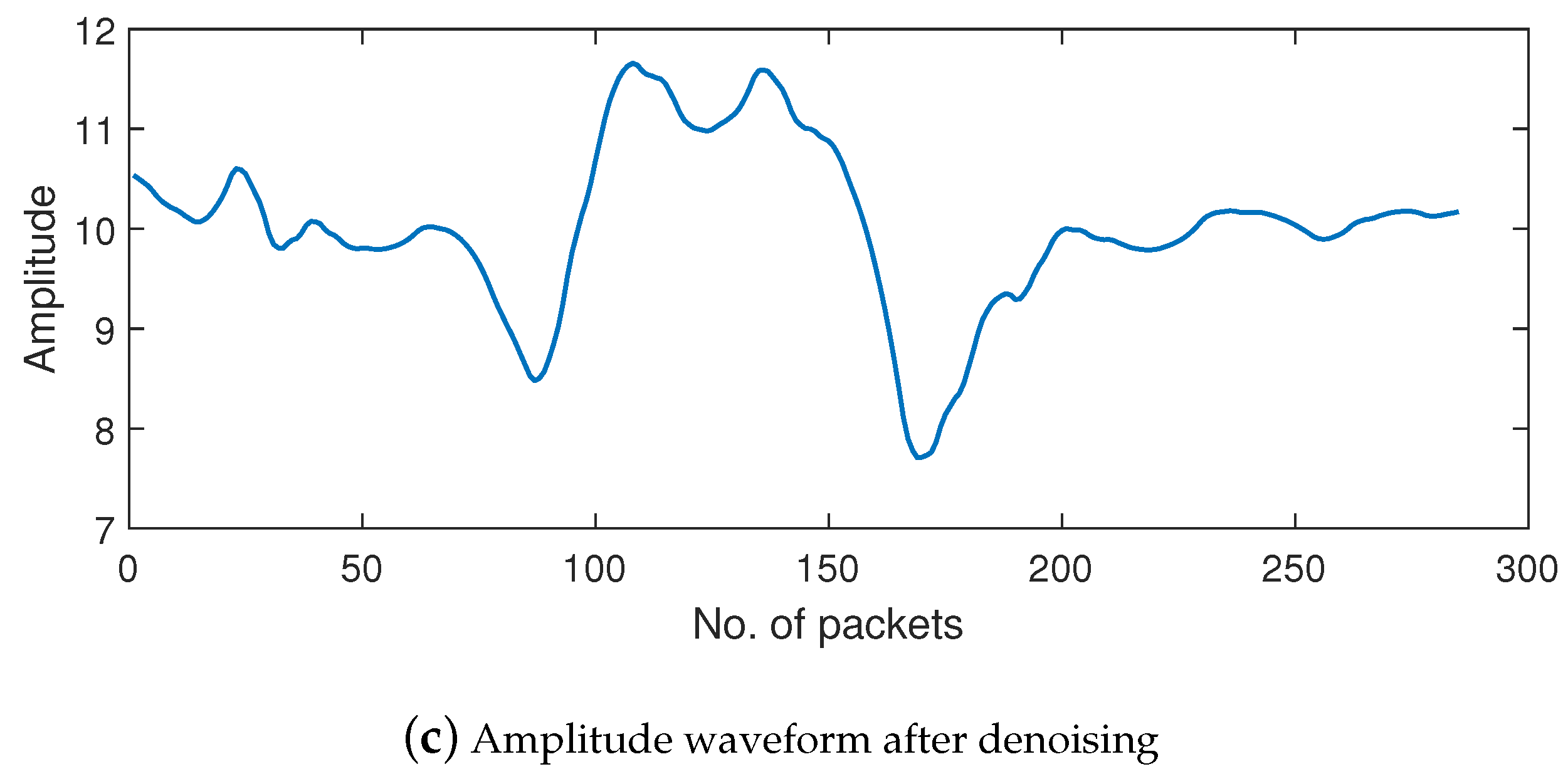
3.3.3. Denoising
3.4. Feature Extraction and Selection
- Step 1: Calculate the covariance matrix. The covariance of the features selected based on the improved Fisher score is calculated and a covariance matrix with dimension is constructed, where is the number of selected features.
- Step 2: Calculate the eigenvalues and eigenvectors. The eigenvalues e and eigenvectors q of the covariance matrix are calculated, then the contribution scores are obtained based on the eigenvalues. The contribution scores are ranked, and all of the eigenvalues and eigenvectors with contribution scores up to 0.95 are selected.
- Step 3: Calculate the principal components. Using the eigenvalues and eigenvectors selected in Step 2, the linearly uncorrelated principal components can be obtained by decomposing them with (where F is the dataset of features after feature selection) for use as the training set in the next step of model training.
3.5. Training and Gesture Recognition
- First, as there are m primary learners, the training dataset is randomly divided into m folds.
- Second, in the first round of training, for the i-th () primary learner, we select the corresponding i-th fold as the validation fold and the remaining m-1 folds as the training folds. Subsequently, we train the i-th primary learner, resulting in a total of m primary learners.
- Third, each primary learner makes primary predictions on the corresponding validation fold. These primary predictions are reconstructed to form a new training set for the secondary learner, which is then obtained through a second round of training.
- Fourth, the test set is fed to the m primary learners, resulting in m sets of primary predictions. These primary prediction sets are then averaged to form a new test set for the secondary learner.
- Finally, the secondary learner is used to make predictions on the new test set and obtain the final output.
| Algorithm 1: SVM-Stacking algorithm for gesture classification |
 |
4. Performance Evaluation
4.1. Experimental Setting
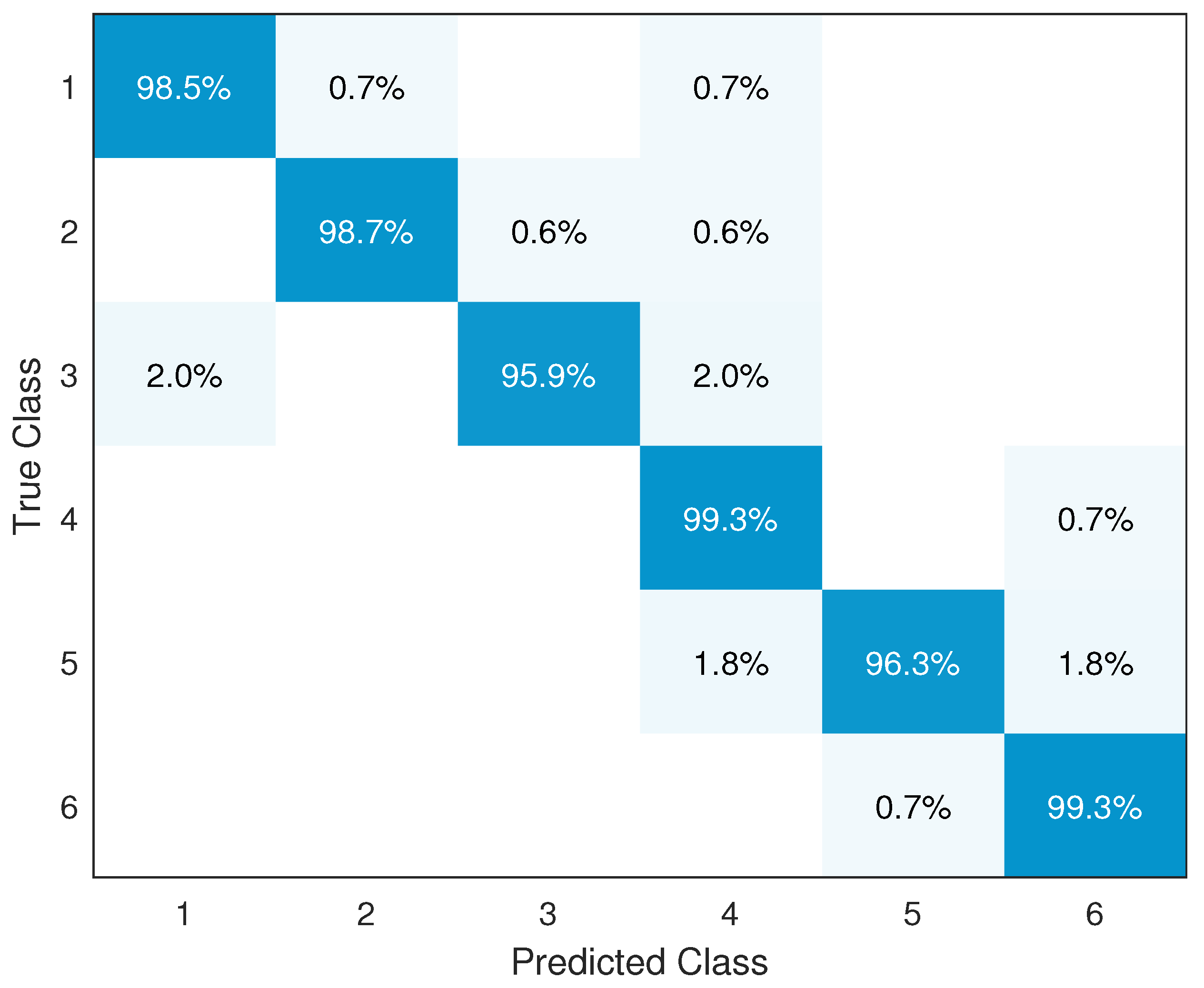
4.2. Recognition Accuracy Performance
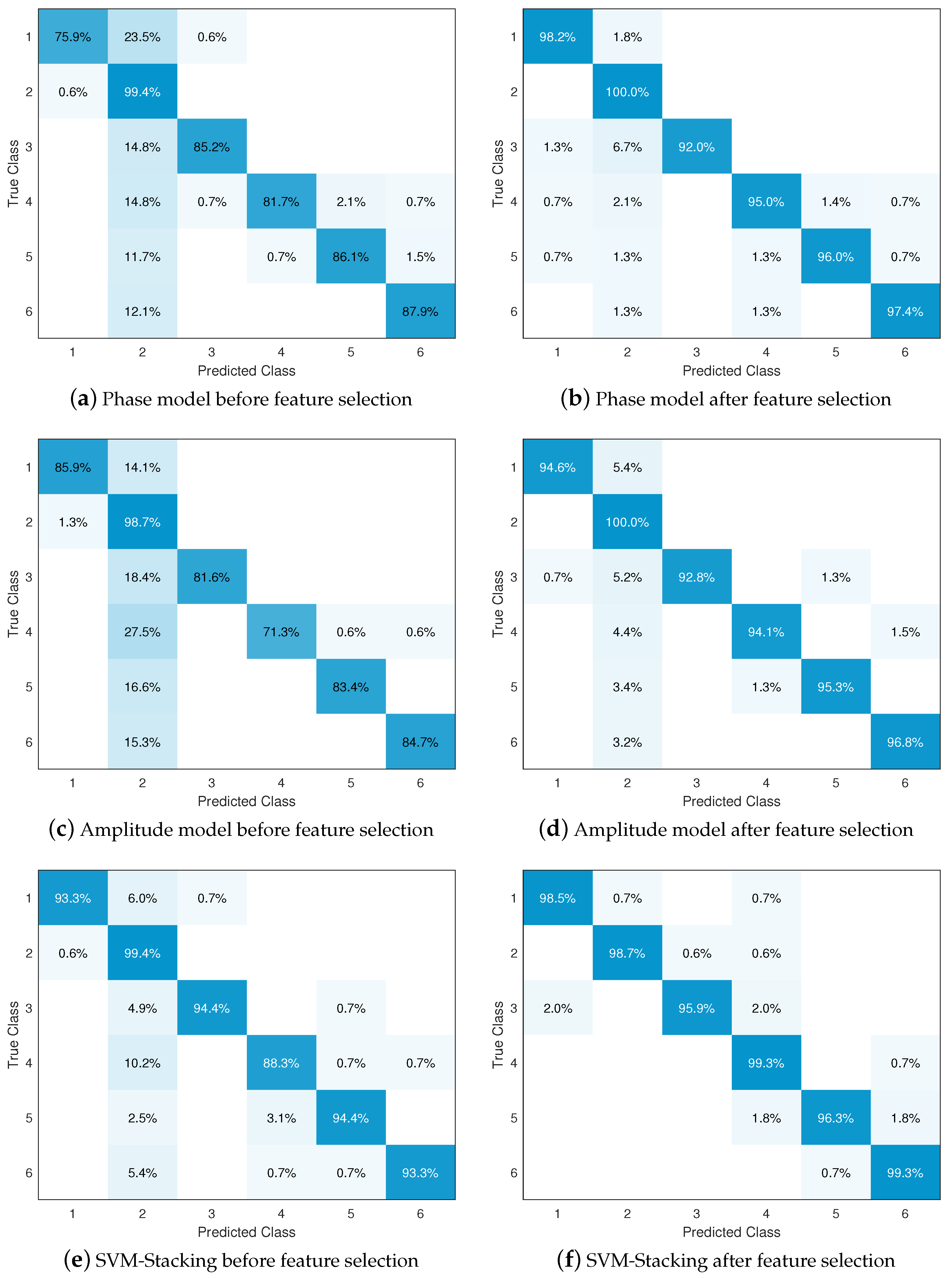
4.3. Impact of Feature Selection and Classification Methods
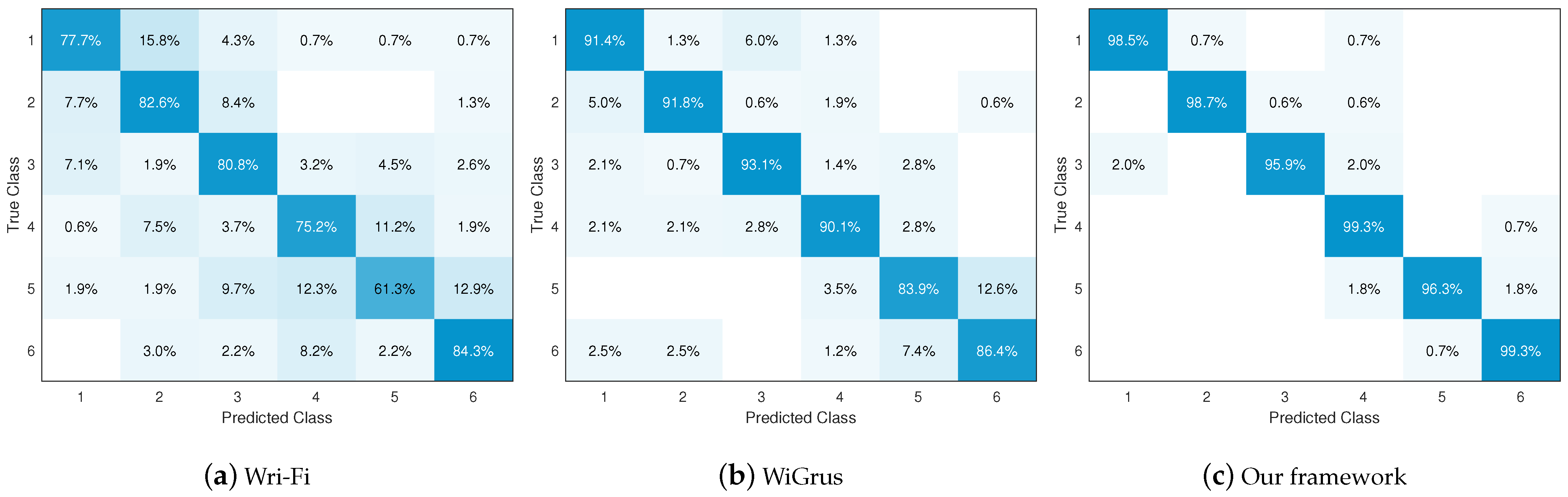
4.4. Performance Comparison
5. Discussion and Conclusions
5.1. Discussion
- 1.
- Robustness and generality issues for real-world applications. The research work in this paper, as well as most of the existing research work, collects CSI data on different gestures in a relatively ideal environment, and subsequent processing steps are conducted based on machine learning or deep learning. However, the practical environment usually changes over time, for instance, changes in the external scene of the gesture action or the speed and angle of human movements, and the CSI is highly sensitive to the above factors. Thus, how to improve robustness in practical application scenarios remains one of most significant research challenges in the field of wireless sensing technology. In general, large-scale and high-quality datasets containing the CSI of samples taken from diverse and dynamic environments are necessary in order to address the robustness issue.
- 2.
- Practical wireless sensing applications within the edge computing paradigm. In order to truly apply WiFi-based gesture recognition technology to real life, it is necessary to consider the load of the central server along with data transmission delay and other issues. Recent developments in edge computing technology allow part of the data processing and analysis tasks of edge devices to be offloaded to the edge server, which can reduce the load on the central server and reduce data transmission delays [70]. Therefore, integrating wireless sensing technology into the edge computing paradigm represents a critical way to deploy WiFi-based gesture recognition technology into daily life.
- 3.
- Issues with recognizing multiple gestures in complex environments. When multiple peoples perform gestures in a complex environment, channel variations and interference caused by their bodies may be superimposed, leading to complex signal aliasing. In addition, multiple gestures made by multiple peoples may lead to cross-interference, where the gesture of one individual may affect the signal of another. This makes it challenging to extract effective gesture features, leading to a decrease in gesture recognition performance.
5.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Intelligent Human-Computer Interaction Based on Surface EMG Gesture Recognition. IEEE Access 2019, 7, 61378–61387. [Google Scholar] [CrossRef]
- Weichert, F.; Bachmann, D.; Rudak, B.; Fisseler, D. Analysis of the Accuracy and Robustness of the Leap Motion Controller. Sensors 2013, 13, 6380–6393. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Schlömer, T.; Poppinga, B.; Henze, N.; Boll, S. Gesture Recognition with a Wii Controller. In Proceedings of the 2nd International Conference on Tangible and Embedded Interaction, Bonn, Germany, 18–20 February 2008; pp. 11–14. [Google Scholar]
- Cao, Y.; Ohtsuki, T.; Maghsudi, S.; Quek, T.Q.S. Deep Learning and Image Super-Resolution-Guided Beam and Power Allocation for mmWave Networks. IEEE Trans. Veh. Technol. 2023, 72, 15080–15085. [Google Scholar] [CrossRef]
- Echigo, H.; Cao, Y.; Bouazizi, M.; Ohtsuki, T. A Deep Learning-Based Low Overhead Beam Selection in mmWave Communications. IEEE Trans. Veh. Technol. 2021, 70, 682–691. [Google Scholar] [CrossRef]
- Zhang, R.; Jing, X.; Wu, S.; Jiang, C.; Mu, J.; Yu, F.R. Device-Free Wireless Sensing for Human Detection: The Deep Learning Perspective. IEEE Internet Things J. 2021, 8, 2517–2539. [Google Scholar] [CrossRef]
- Cheng, X.; Huang, B. CSI-Based Human Continuous Activity Recognition Using GMM–HMM. IEEE Sens. J. 2022, 22, 18709–18717. [Google Scholar] [CrossRef]
- Zhao, Y.; Gao, R.; Liu, S.; Xie, L.; Wu, J.; Tu, H.; Chen, B. Device-Free Secure Interaction with Hand Gestures in WiFi-Enabled IoT Environment. IEEE Internet Things J. 2021, 8, 5619–5631. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Youssef, M.; Harras, K.A. WiGest: A ubiquitous WiFi-based gesture recognition system. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 1472–1480. [Google Scholar]
- Al-qaness, M.A.A.; Li, F. WiGeR: WiFi-Based Gesture Recognition System. ISPRS Int. J.-Geo-Inf. 2016, 5, 92. [Google Scholar] [CrossRef]
- Fu, Z.; Xu, J.; Zhu, Z.; Liu, A.X.; Sun, X. Writing in the Air with WiFi Signals for Virtual Reality Devices. IEEE Trans. Mob. Comput. 2019, 18, 473–484. [Google Scholar] [CrossRef]
- Man, D.; Yang, W.; Wang, X.; Lv, J.; Du, X.; Yu, M. PWiG: A Phase-based Wireless Gesture Recognition System. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 837–842. [Google Scholar]
- Zou, H.; Yang, J.; Zhou, Y.; Xie, L.; Spanos, C.J. Robust WiFi-Enabled Device-Free Gesture Recognition via Unsupervised Adversarial Domain Adaptation. In Proceedings of the 2018 27th International Conference on Computer Communication and Networks (ICCCN), Hangzhou, China, 30 July–2 August 2018; pp. 1–8. [Google Scholar]
- Fard Moshiri, P.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-Based Human Activity Recognition Using Deep Learning. Sensors 2021, 21, 7225. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI Based Passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2019, 18, 2714–2724. [Google Scholar] [CrossRef]
- Zhang, T.; Song, T.; Chen, D.; Zhang, T.; Zhuang, J. WiGrus: A Wifi-Based Gesture Recognition System Using Software-Defined Radio. IEEE Access 2019, 7, 131102–131113. [Google Scholar] [CrossRef]
- Zeng, Y.; Wu, D.; Gao, R.; Gu, T.; Zhang, D. FullBreathe: Full Human Respiration Detection Exploiting Complementarity of CSI Phase and Amplitude of WiFi Signals. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–19. [Google Scholar] [CrossRef]
- Yu, Y.; Yu, D.; Cheng, J. A roller bearing fault diagnosis method based on EMD energy entropy and ANN. J. Sound Vib. 2006, 294, 269–277. [Google Scholar] [CrossRef]
- Zhang, A.; Yang, B.; Huang, L. Feature Extraction of EEG Signals Using Power Spectral Entropy. In Proceedings of the 2008 International Conference on BioMedical Engineering and Informatics, Sanya, China, 27–30 May 2008; Volume 2, pp. 435–439. [Google Scholar]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; de Schaetzen, V.; Duque, R.; Bersini, H.; Nowe, A. A Survey on Filter Techniques for Feature Selection in Gene Expression Microarray Analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef] [PubMed]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the Proceedings IEEE INFOCOM 2000, Conference on Computer Communications, Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No. 00CH37064), Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar]
- Kotaru, M.; Joshi, K.; Bharadia, D.; Katti, S. SpotFi: Decimeter Level Localization Using WiFi. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 269–282. [Google Scholar]
- Wang, Y.; Yang, J.; Chen, Y.; Liu, H.; Gruteser, M.; Martin, R.P. Tracking human queues using single-point signal monitoring. In Proceedings of the 12th Annual International Conference on Mobile Systems, Applications, and Services, Bretton Woods, NH, USA, 16–19 June 2014; pp. 42–54. [Google Scholar]
- Liu, Z.; Yuan, R.; Yuan, Y.; Yang, Y.; Guan, X. A Sensor-Free Crowd Counting Framework for Indoor Environments Based on Channel State Information. IEEE Sens. J. 2022, 22, 6062–6071. [Google Scholar] [CrossRef]
- Zeng, Y.; Pathak, P.H.; Mohapatra, P. WiWho: WiFi-Based Person Identification in SMart Spaces. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar]
- Wang, W.; Liu, A.X.; Shahzad, M. Gait recognition using wifi signals. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 363–373. [Google Scholar]
- Zhou, Z.; Yang, Z.; Wu, C.; Shangguan, L.; Liu, Y. Towards omnidirectional passive human detection. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 3057–3065. [Google Scholar]
- Wang, G.; Zou, Y.; Zhou, Z.; Wu, K.; Ni, L.M. We Can Hear You with Wi-Fi! In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 593–604. [Google Scholar]
- Wang, Y.; Wu, K.; Ni, L.M. WiFall: Device-Free Fall Detection by Wireless Networks. IEEE Trans. Mob. Comput. 2017, 16, 581–594. [Google Scholar] [CrossRef]
- Chetty, K.; Smith, G.E.; Woodbridge, K. Through-the-Wall Sensing of Personnel Using Passive Bistatic WiFi Radar at Standoff Distances. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1218–1226. [Google Scholar] [CrossRef]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool Release: Gathering 802.11n Traces with Channel State Information. SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Ali, K.; Liu, A.X.; Wang, W.; Shahzad, M. Keystroke Recognition Using WiFi Signals. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015; pp. 90–102. [Google Scholar]
- Fang, B.; Sun, F.; Liu, H.; Liu, C. 3D human gesture capturing and recognition by the IMMU-based data glove. Neurocomputing 2018, 277, 198–207. [Google Scholar] [CrossRef]
- Kim, M.; Cho, J.; Lee, S.; Jung, Y. IMU Sensor-Based Hand Gesture Recognition for Human-Machine Interfaces. Sensors 2019, 19, 3827. [Google Scholar] [CrossRef]
- Geng, K.; Yin, G. Using Deep Learning in Infrared Images to Enable Human Gesture Recognition for Autonomous Vehicles. IEEE Access 2020, 8, 88227–88240. [Google Scholar] [CrossRef]
- Ren, Z.; Meng, J.; Yuan, J. Depth camera based hand gesture recognition and its applications in Human-Computer-Interaction. In Proceedings of the 2011 8th International Conference on Information, Communications & Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Ma, X.; Zhao, Y.; Zhang, L.; Gao, Q.; Pan, M.; Wang, J. Practical Device-Free Gesture Recognition Using WiFi Signals Based on Metalearning. IEEE Trans. Ind. Inform. 2020, 16, 228–237. [Google Scholar] [CrossRef]
- Tang, Z.; Liu, Q.; Wu, M.; Chen, W.; Huang, J. WiFi CSI gesture recognition based on parallel LSTM-FCN deep space-time neural network. China Commun. 2021, 18, 205–215. [Google Scholar] [CrossRef]
- Lu, Y.; Lv, S.; Wang, X. Towards Location Independent Gesture Recognition with Commodity WiFi Devices. Electronics 2019, 8, 1069. [Google Scholar] [CrossRef]
- Palaniappan, A.; Bhargavi, R.; Vaidehi, V. Abnormal human activity recognition using SVM based approach. In Proceedings of the 2012 International Conference on Recent Trends in Information Technology, Chennai, India, 19–21 April 2012; pp. 97–102. [Google Scholar]
- Chu, H.C.; Huang, S.C.; Liaw, J.J. An Acceleration Feature-Based Gesture Recognition System. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3807–3812. [Google Scholar]
- Tubaiz, N.; Shanableh, T.; Assaleh, K. Glove-Based Continuous Arabic Sign Language Recognition in User-Dependent Mode. IEEE Trans.-Hum.-Mach. Syst. 2015, 45, 526–533. [Google Scholar] [CrossRef]
- Abualola, H.; Ghothani, H.A.; Eddin, A.N.; Almoosa, N.; Poon, K. Flexible gesture recognition using wearable inertial sensors. In Proceedings of the 2016 IEEE 59th International Midwest Symposium on Circuits and Systems (MWSCAS), Abu Dhabi, United Arab Emirates, 16–19 October 2016; pp. 1–4. [Google Scholar]
- Saif, R.; Ahmad, M.; Naqvi, S.Z.H.; Aziz, S.; Khan, M.U.; Faraz, M. Multi-Channel EMG Signal analysis for Italian Sign Language Interpretation. In Proceedings of the 2022 International Conference on Emerging Trends in SMart Technologies (ICETST), Karachi, Pakistan, 23–24 September 2022; pp. 1–5. [Google Scholar]
- Pan, T.Y.; Tsai, W.L.; Chang, C.Y.; Yeh, C.W.; Hu, M.C. A Hierarchical Hand Gesture Recognition Framework for Sports Referee Training-Based EMG and Accelerometer Sensors. IEEE Trans. Cybern. 2022, 52, 3172–3183. [Google Scholar] [CrossRef]
- Nguyen, V.S.; Kim, H.; Suh, D. Attention Mechanism-Based Bidirectional Long Short-Term Memory for Cycling Activity Recognition Using Smartphones. IEEE Access 2023, 11, 136206–136218. [Google Scholar] [CrossRef]
- Rehg, J.M.; Kanade, T. Visual tracking of high DOF articulated structures: An application to human hand tracking. In Proceedings of the Computer Vision—ECCV’94; Springer: Berlin/Heidelberg, Germany, 1994; pp. 35–46. [Google Scholar]
- Starner, T.; Pentland, A. Real-time American Sign Language recognition from video using Markov models. In Proceedings of the Proceedings of International Symposium on Computer Vision—ISCV, Coral Gables, FL, USA, 21–23 November 1995; pp. 265–270. [Google Scholar]
- Vinh, T.Q.; Tri, N.T. Hand gesture recognition based on depth image using kinect sensor. In Proceedings of the 2015 2nd National Foundation for Science and Technology Development Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 16–18 September 2015; pp. 34–39. [Google Scholar]
- Lamberti, L.; Camastra, F. Real-Time Hand Gesture Recognition Using a Color Glove. In Proceedings of the Image Analysis and Processing—ICIAP 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 365–373. [Google Scholar]
- Jiang, D.; Li, M.; Xu, C. WiGAN: A WiFi Based Gesture Recognition System with GANs. Sensors 2020, 20, 4757. [Google Scholar] [CrossRef]
- Bu, Q.; Yang, G.; Ming, X.; Zhang, T.; Feng, J.; Zhang, J. Deep transfer learning for gesture recognition with WiFi signals. Pers. Ubiquitous Comput. 2022, 26, 543–554. [Google Scholar] [CrossRef]
- Meng, W.; Chen, X.; Cui, W.; Guo, J. WiHGR: A Robust WiFi-Based Human Gesture Recognition System via Sparse Recovery and Modified Attention-Based BGRU. IEEE Internet Things J. 2022, 9, 10272–10282. [Google Scholar] [CrossRef]
- Hu, P.; Tang, C.; Yin, K.; Zhang, X. WiGR: A Practical Wi-Fi-Based Gesture Recognition System with a Lightweight Few-Shot Network. Appl. Sci. 2021, 11, 3329. [Google Scholar] [CrossRef]
- Farhana Thariq Ahmed, H.; Ahmad, H.; Phang, S.K.; Vaithilingam, C.A.; Harkat, H.; Narasingamurthi, K. Higher Order Feature Extraction and Selection for Robust Human Gesture Recognition using CSI of COTS Wi-Fi Devices. Sensors 2019, 19, 2959. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Xing, J.; Li, J.; Yang, Q. A Device-Free Number Gesture Recognition Approach Based on Deep Learning. In Proceedings of the 2016 12th International Conference on Computational Intelligence and Security (CIS), Wuxi, China, 16–19 December 2016; pp. 57–63. [Google Scholar]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless Fine-Grained Gesture Recognition Uses Channel State Information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef]
- Akhtar, Z.U.A.; Wang, H. WiFi-Based Gesture Recognition for Vehicular Infotainment System—An Integrated Approach. Appl. Sci. 2019, 9, 5268. [Google Scholar] [CrossRef]
- He, W.; Wu, K.; Zou, Y.; Ming, Z. WiG: WiFi-Based Gesture Recognition System. In Proceedings of the 2015 24th International Conference on Computer Communication and Networks (ICCCN), Las Vegas, NV, USA, 3–6 August 2015; pp. 1–7. [Google Scholar]
- Alsaify, B.A.; Almazari, M.M.; Alazrai, R.; Alouneh, S.; Daoud, M.I. A CSI-Based Multi-Environment Human Activity Recognition Framework. Appl. Sci. 2022, 12, 930. [Google Scholar] [CrossRef]
- Dang, X.; Tang, X.; Hao, Z.; Liu, Y. A Device-Free Indoor Localization Method Using CSI with Wi-Fi Signals. Sensors 2019, 19, 3233. [Google Scholar] [CrossRef]
- Anutam, R.; Rajni, F. Performance analysis of image denoising with wavelet thresholding methods for different levels of decomposition. Int. J. Multimed. Its Appl. 2014, 6, 35–46. [Google Scholar] [CrossRef]
- Wu, D.; Guo, S. An improved Fisher Score feature selection method and its application. J. Liaoning Tech. Univ. (Nat. Sci.) 2019, 38, 472–479. [Google Scholar]
- Sun, L.; Wang, T.; Ding, W.; Xu, J.; Lin, Y. Feature selection using Fisher score and multilabel neighborhood rough sets for multilabel classification. Inf. Sci. 2021, 578, 887–912. [Google Scholar] [CrossRef]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24–24 October 2016; pp. 18–20. [Google Scholar]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the myopia of inductive learning algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Q.; Ma, X.; Yu, F.R. Computation Offloading for Edge Intelligence in Two-Tier Heterogeneous Networks. IEEE Trans. Netw. Sci. Eng. 2024, 11, 1872–1884. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition | Symbol | Definition |
|---|---|---|---|
| The CSI at time t | The CSI of the i-th transceiver antenna pair in the f-th subcarrier at time t | ||
| The transmitted and received frequency signals of the i-th transceiver antenna pair in the f-th subcarrier at time t | The amplitude and phase of | ||
| The measured CSI phase of the i-th transceiver antenna pair in the f-th subcarrier at time t | The subcarrier index varying from −28 to 28 in IEEE 802.11n | ||
| N | The number of (FFT) window points | The time offset between the transmitter and receiver at time t | |
| The unknown phase offset at time t | The noise introduced by the measurement procedure at time t | ||
| The two variables introduced to realize the linear transformation of the i-th transceiver antenna pair at time t | n | The total number of subcarriers | |
| The calibrated CSI phase of the i-th transceiver antenna pair in the f-th subcarrier at time t | The mean and variance of the i-th transceiver antenna pair in the f-th subcarrier at time t under the window | ||
| The CSI phase or CSI amplitude of the i-th transceiver antenna pair in the f-th subcarrier at time t | W | The time series window size | |
| The length of CSI data samples | The threshold value | ||
| The original wavelet coefficients and processed wavelet coefficients | The i-th IMFs | ||
| E | The total energy of all IMFs | The energy and energy percentage of | |
| The FFT on or | The frequency point at time t | ||
| The number of frequency points of the FFT | The PSD | ||
| The PSD distribution function | The inter-class scatter of i-th feature | ||
| The intra-class scatter of k-th class of gesture samples under i-th feature | The Fisher score of the whole feature dataset at the i-th feature | ||
| The number of instances of all gesture samples | c | The number of gesture types | |
| The mean of all samples under the i-th feature | The variance of the k-th class of samples under the i-th feature | ||
| The value of the j-th sample in the k-th class of samples taken under the i-th feature | The inter-class scatter of i-th feature after correction | ||
| The means of the samples of k-th and -th class under the i-th feature | The number of gesture samples of k-th and -th class | ||
| The number of k-th and -th class of gesture samples that takes the same value under the i-th feature | The cross coefficient under the i-th feature | ||
| The improved Fisher score at the i-th feature | F | The data set of features after feature selection | |
| The number of selected features | The eigenvalues and eigenvectors of the covariance matrix | ||
| m | The number of folds in stacking algorithm | Dataset of CSI phase and amplitude | |
| Amplitude feature vector and gesture label | Phase feature vector and gesture label | ||
| Primary phase learner parameter | Primary amplitude learner parameter | ||
| Secondary learner parameter | SVM-Stacking classification model | ||
| Training dataset of CSI phase and amplitude | Validation dataset of CSI phase and amplitude | ||
| The number of validation dataset | The primary phase model and the primary amplitude model | ||
| The secondary model training set | The phase model and amplitude model probability estimation vector |
| Value | Class of Gesture | |||||
|---|---|---|---|---|---|---|
| Class1 | Class2 | Class3 | Class4 | Class5 | Class6 | |
| Recall | 98.5% | 98.7% | 95.9% | 99.3% | 96.3% | 99.3% |
| Precision | 97.3% | 99.4% | 99.3% | 94.7% | 99.4% | 97.4% |
| Method | Accuracy | Computing Time | Phase Iter | Amplitude Iter | Meta Iter | Phase nSV | Amplitude nSV | Meta nSV | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class1 | Class2 | Class3 | Class4 | Class5 | Class6 | Overall | |||||||||
| Before feature selection | Phase model | 75.9% | 99.4% | 85.2% | 81.7% | 86.1% | 87.9% | 86.1% | 405.06 s | 1060 | — | — | 1818 | — | — |
| Amplitude model | 85.9% | 98.7% | 81.6% | 71.3% | 83.4% | 84.7% | 84.1% | 384.29 s | — | 1092 | — | — | 2066 | — | |
| SVM-Stacking classifier | 93.3% | 99.4% | 94.4% | 88.3% | 94.4% | 93.3% | 94.0% | 323.66 s | 740 | 855 | 72 | 1351 | 1457 | 83 | |
| After feature selection | Phase model | 98.2% | 100% | 92.0% | 95.0% | 96.0% | 97.4% | 96.4% | 47.87 s | 840 | — | — | 1434 | — | — |
| Amplitude model | 94.6% | 100% | 92.8% | 94.1% | 95.3% | 96.8% | 95.6% | 27.99 s | — | 959 | — | — | 1500 | — | |
| SVM-Stacking classifier | 98.5% | 98.7% | 95.9% | 99.3% | 96.3% | 99.3% | 98.3% | 39.44 s | 614 | 675 | 43 | 1140 | 1144 | 65 | |
| Method | Overall Accuracy | Computing Time | Phase Iter | Amplitude Iter | Meta Iter | Phase nSV | Amplitude nSV | Meta nSV |
|---|---|---|---|---|---|---|---|---|
| ReliefF | 97.7% | 245.36s | 790 | 836 | 50 | 1230 | 1313 | 88 |
| Lasso | 96.8% | 225.43s | 753 | 790 | 31 | 1329 | 1447 | 59 |
| NewFisher | 98.1% | 217.50s | 697 | 739 | 48 | 1239 | 1243 | 80 |
| NewFisher + PCA | 98.3% | 39.44s | 614 | 675 | 43 | 1140 | 1144 | 65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Z.; Li, Z.; Chen, Z.; Zhuo, H.; Zheng, L.; Wu, X.; Liu, Y. Device-Free Wireless Sensing for Gesture Recognition Based on Complementary CSI Amplitude and Phase. Sensors 2024, 24, 3414. https://doi.org/10.3390/s24113414
Cai Z, Li Z, Chen Z, Zhuo H, Zheng L, Wu X, Liu Y. Device-Free Wireless Sensing for Gesture Recognition Based on Complementary CSI Amplitude and Phase. Sensors. 2024; 24(11):3414. https://doi.org/10.3390/s24113414
Chicago/Turabian StyleCai, Zhijia, Zehao Li, Zikai Chen, Hongyang Zhuo, Lei Zheng, Xianda Wu, and Yong Liu. 2024. "Device-Free Wireless Sensing for Gesture Recognition Based on Complementary CSI Amplitude and Phase" Sensors 24, no. 11: 3414. https://doi.org/10.3390/s24113414
APA StyleCai, Z., Li, Z., Chen, Z., Zhuo, H., Zheng, L., Wu, X., & Liu, Y. (2024). Device-Free Wireless Sensing for Gesture Recognition Based on Complementary CSI Amplitude and Phase. Sensors, 24(11), 3414. https://doi.org/10.3390/s24113414