
A Novel Method of UAV-Assisted Trajectory Localization for Forestry Environments

Abstract
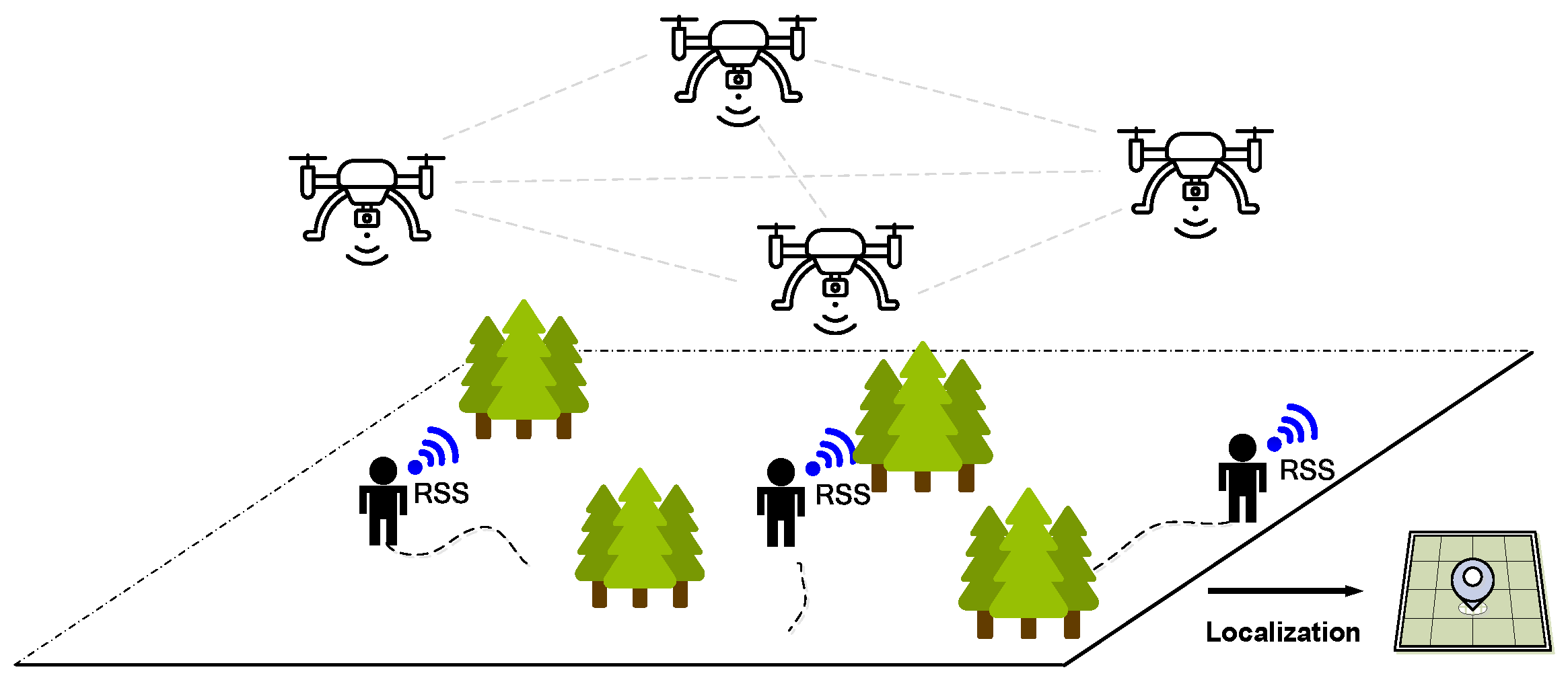
1. Introduction
- For different existing localization systems [2,3,13,14,15,16,17], the proposed multi-agent DRL-based trajectory localization framework employs easy-deployed UAVs as the signal anchors and eliminates the requirements for several pre-deployed anchors with fixed locations, which is more feasible for the complicated and changeable forestry environments, especially in the emergency rescue process.
- To cope with the environmental uncertainty and heterogeneity among agents, which severely degrade the localization performance, the proposed trajectory localization method utilizes the multi-agent DRL technique to automatically navigate the UAVs to form an optimal topology in real-time, allowing higher-accuracy localization for the targets.
- Moreover, by developing a shared replay memory for multi-agent interactions, the complementary information among agents can be utilized to enhance learning efficiency and performance, which contributes to superior and robust localization performance.
2. Preliminaries and Problem Formulation
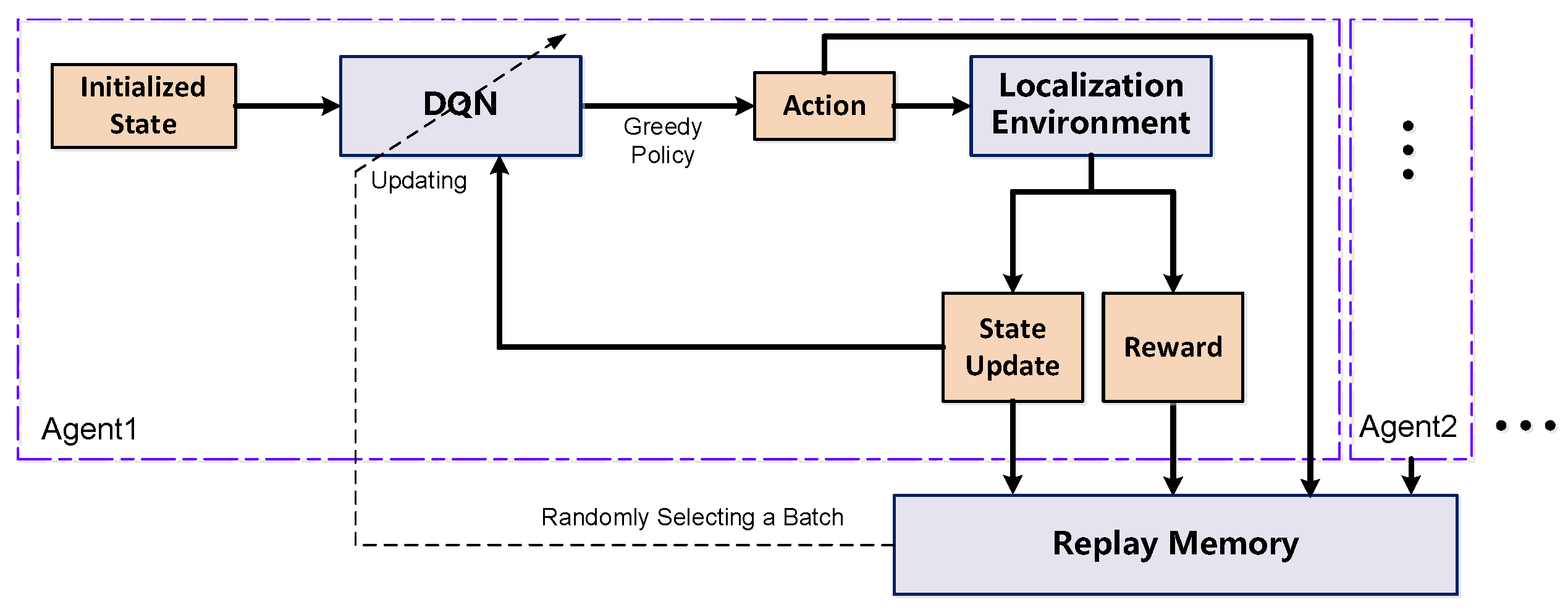
3. Proposed Multi-Agent DQN-Based Method
| Algorithm 1. Training process for the UAV-assisted trajectory localization framework |
| Input: The RSS sequence, the trajectory of the UAVs, and the trajectory for the target. Output: DQN parameters. 1: Initialize the model parameters, environment, space, and experience replay memory. 2: for episode in 1 to M do: 3: for each trajectory do: 4: Utilizing the LLS/WLLS scheme to estimate the initial location for the target 5: for t in 1 to Tmax do: 6: for agent in 1 to do: 7: Select an action using epsilon-greedy policy 8: Execute the action and obtain reward r, next state s′ 9: Navigate the UAV itself to next placement 10: Estimate the location for the target in time t using LLS/WLLS 11: Store the experience into the replay memory 12: Randomly select a batch from the replay memory 13: Using Equations (12) and (13) to update DQN 14: end for 15: end for 16: end for 17: end for |
4. Simulation Results and Analyses
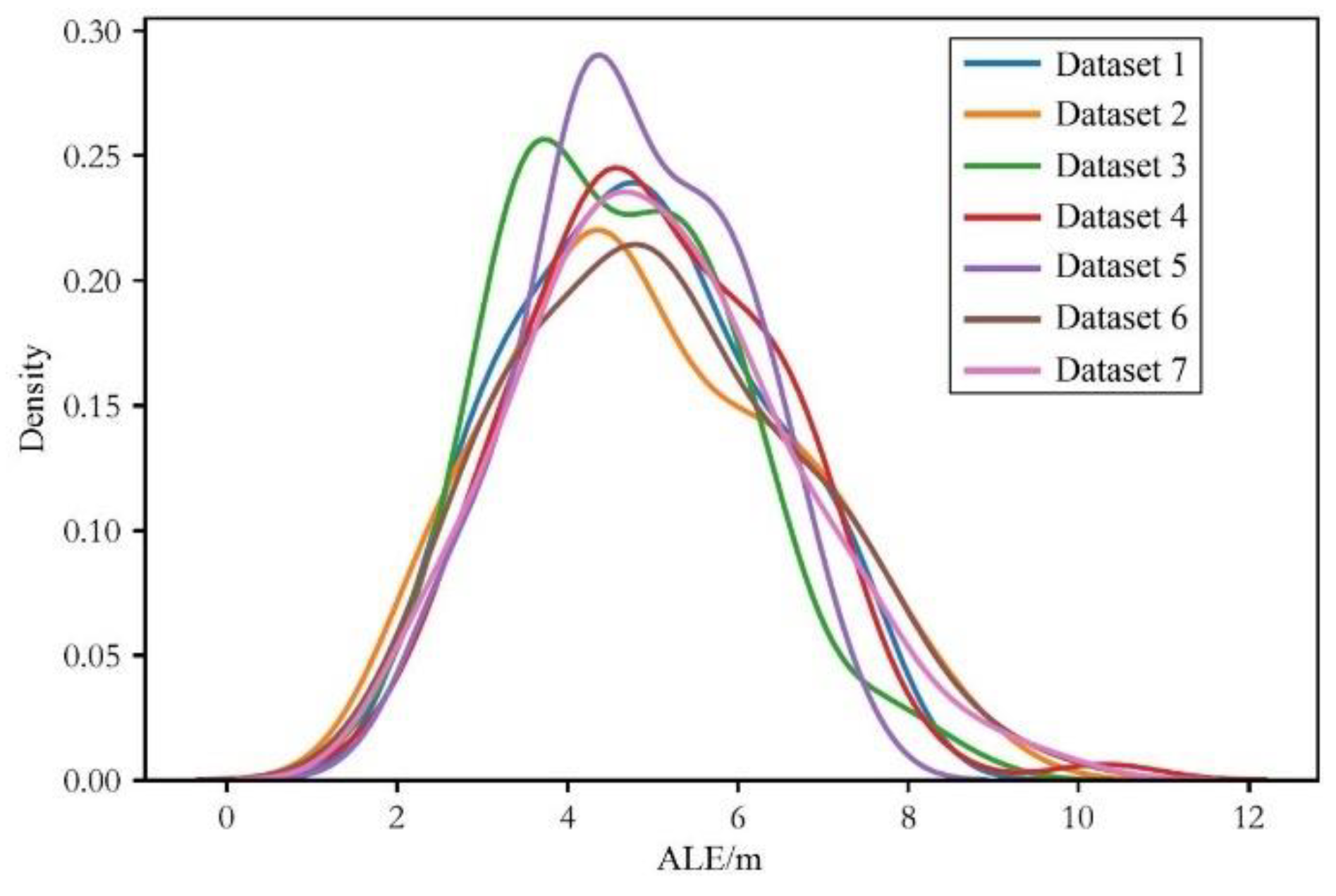
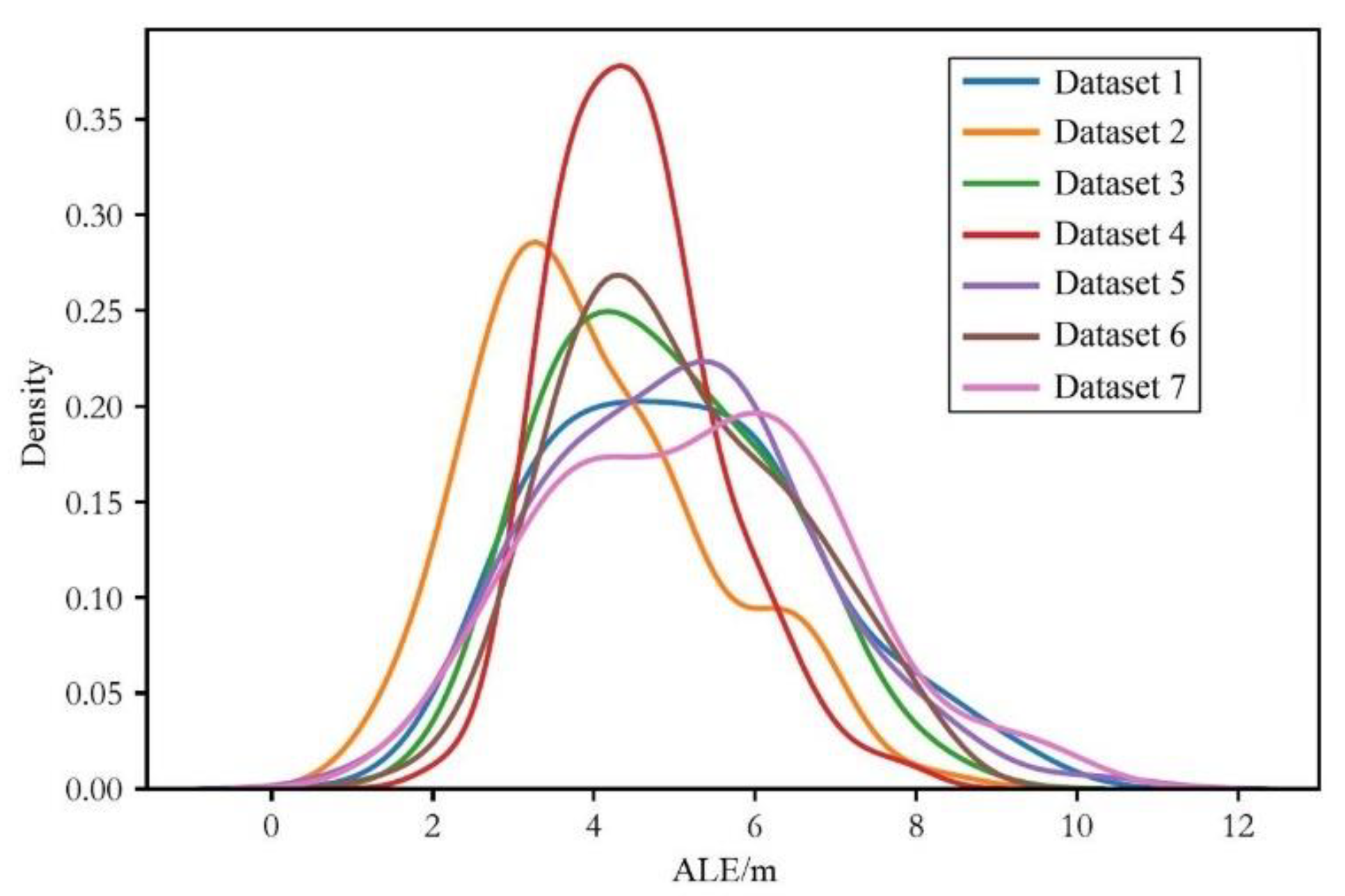
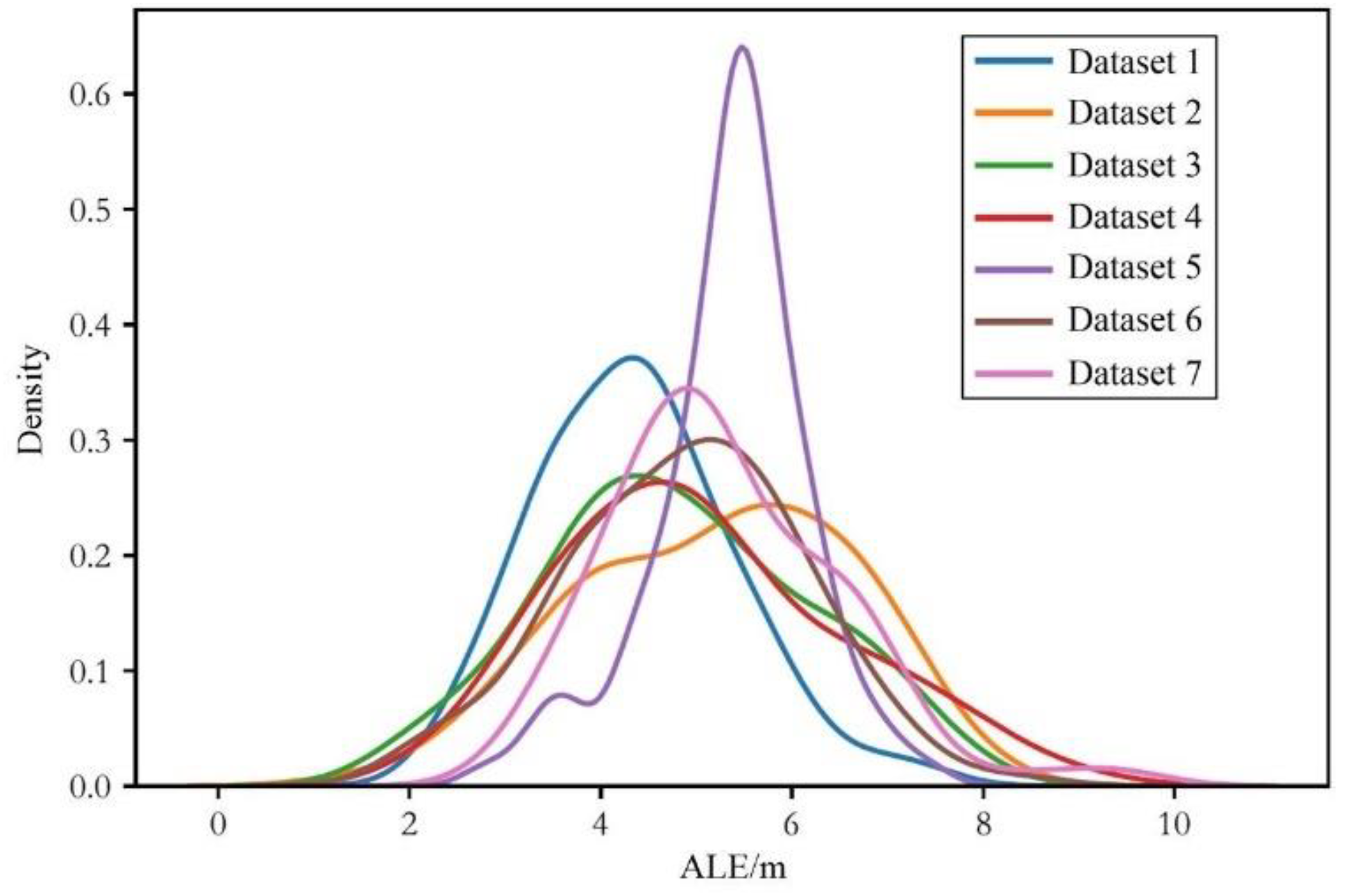
4.1. Dataset Description
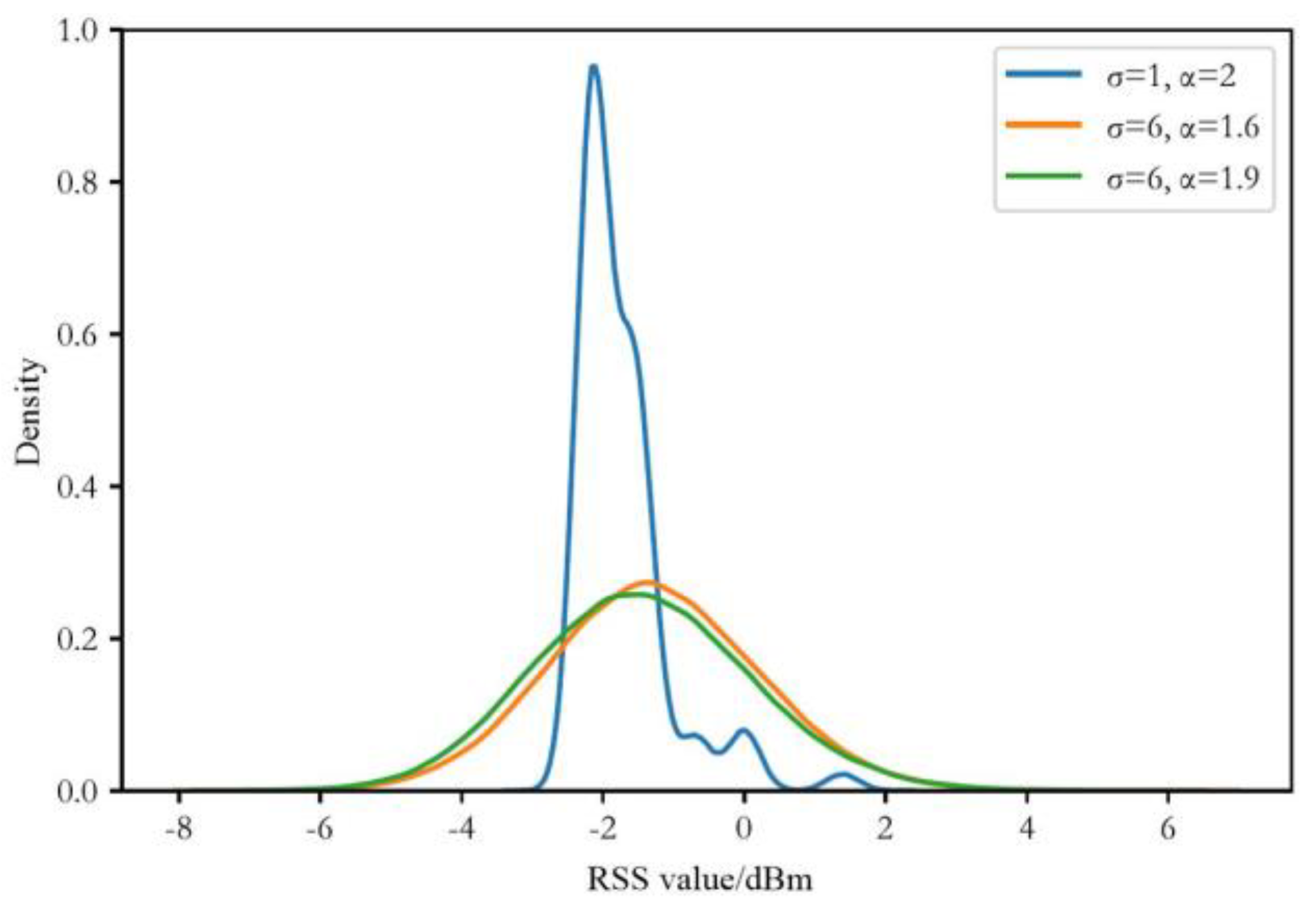
4.2. Environmental Setting
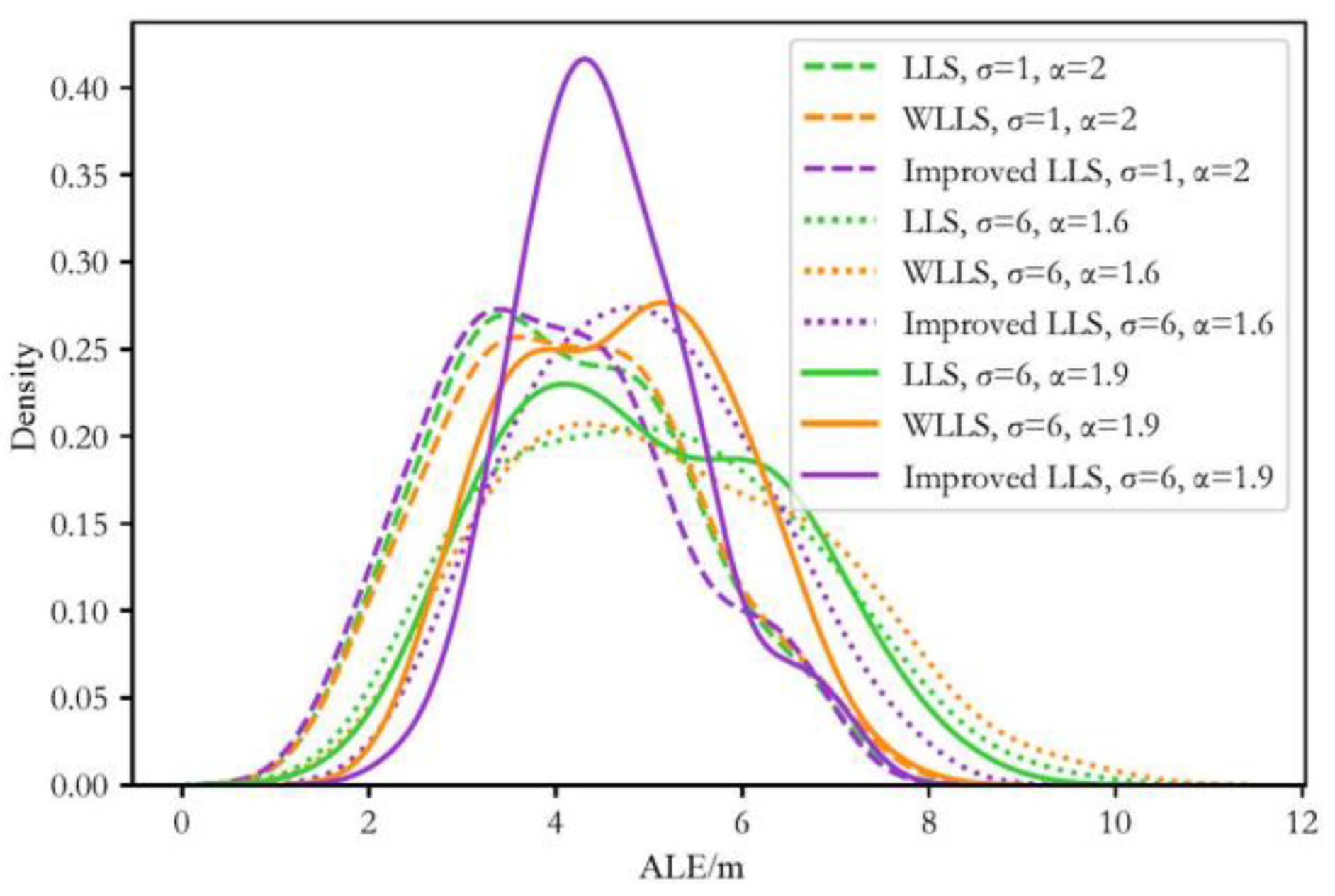
4.3. Evaluation of Localization Performance
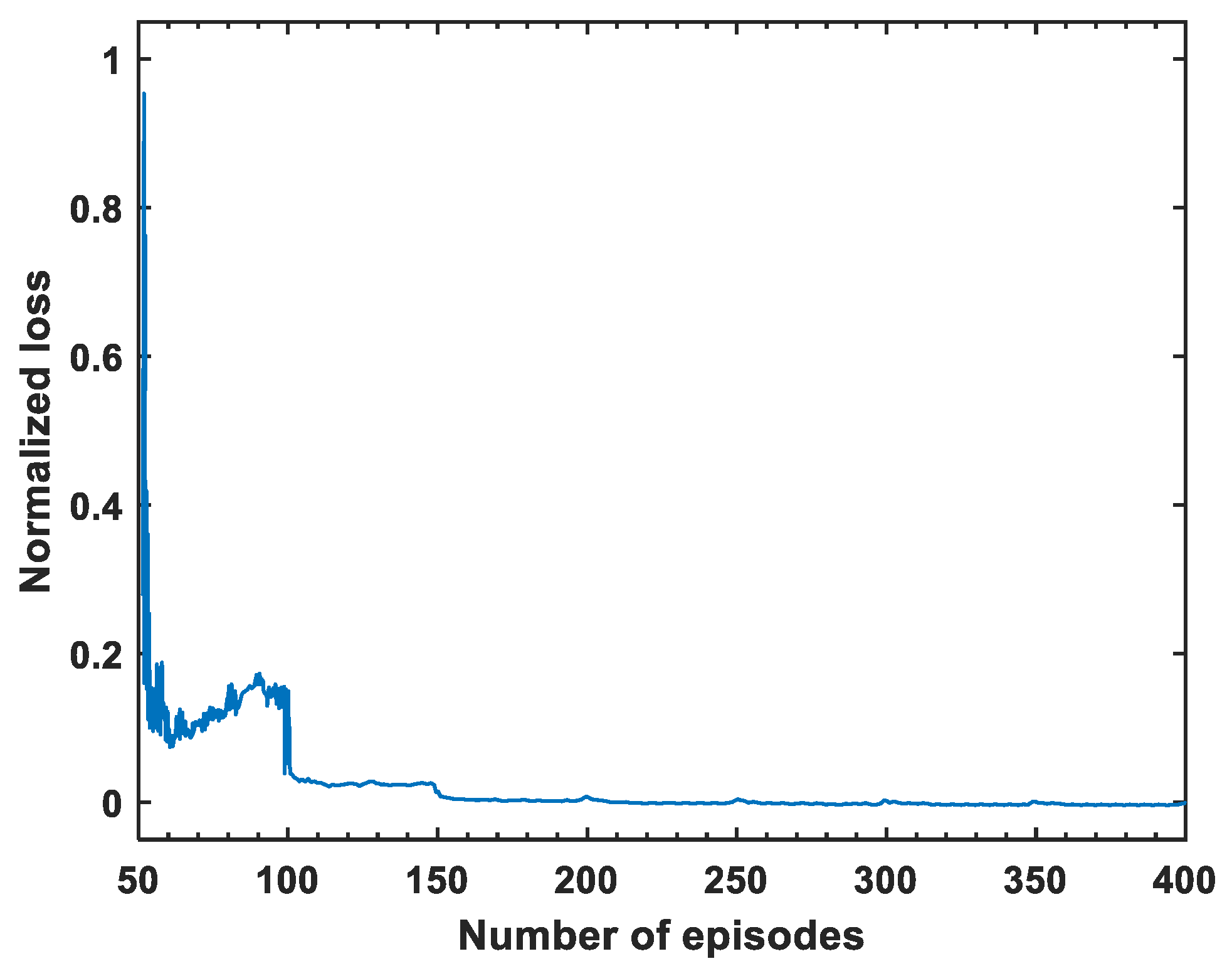
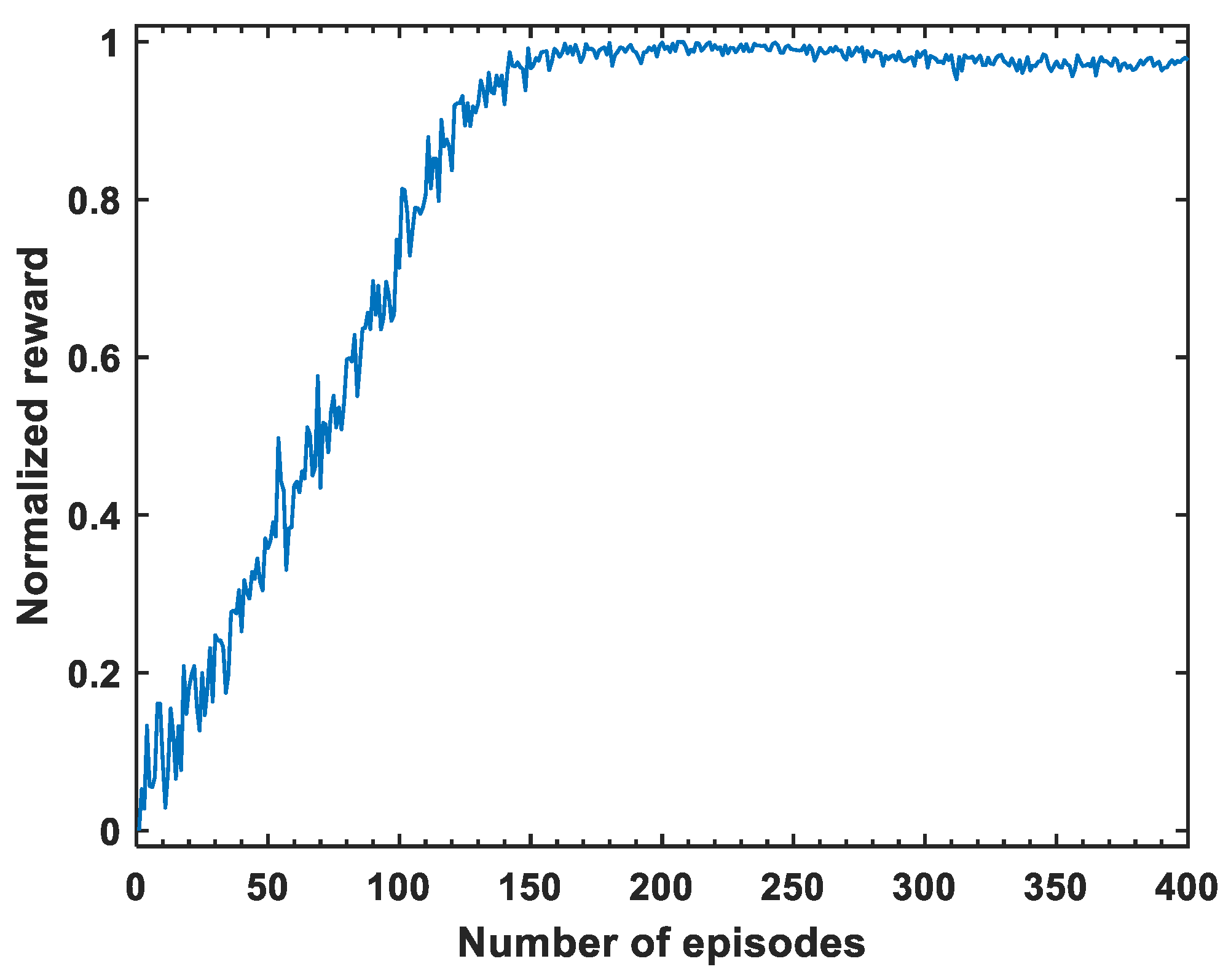
4.3.1. Training Process
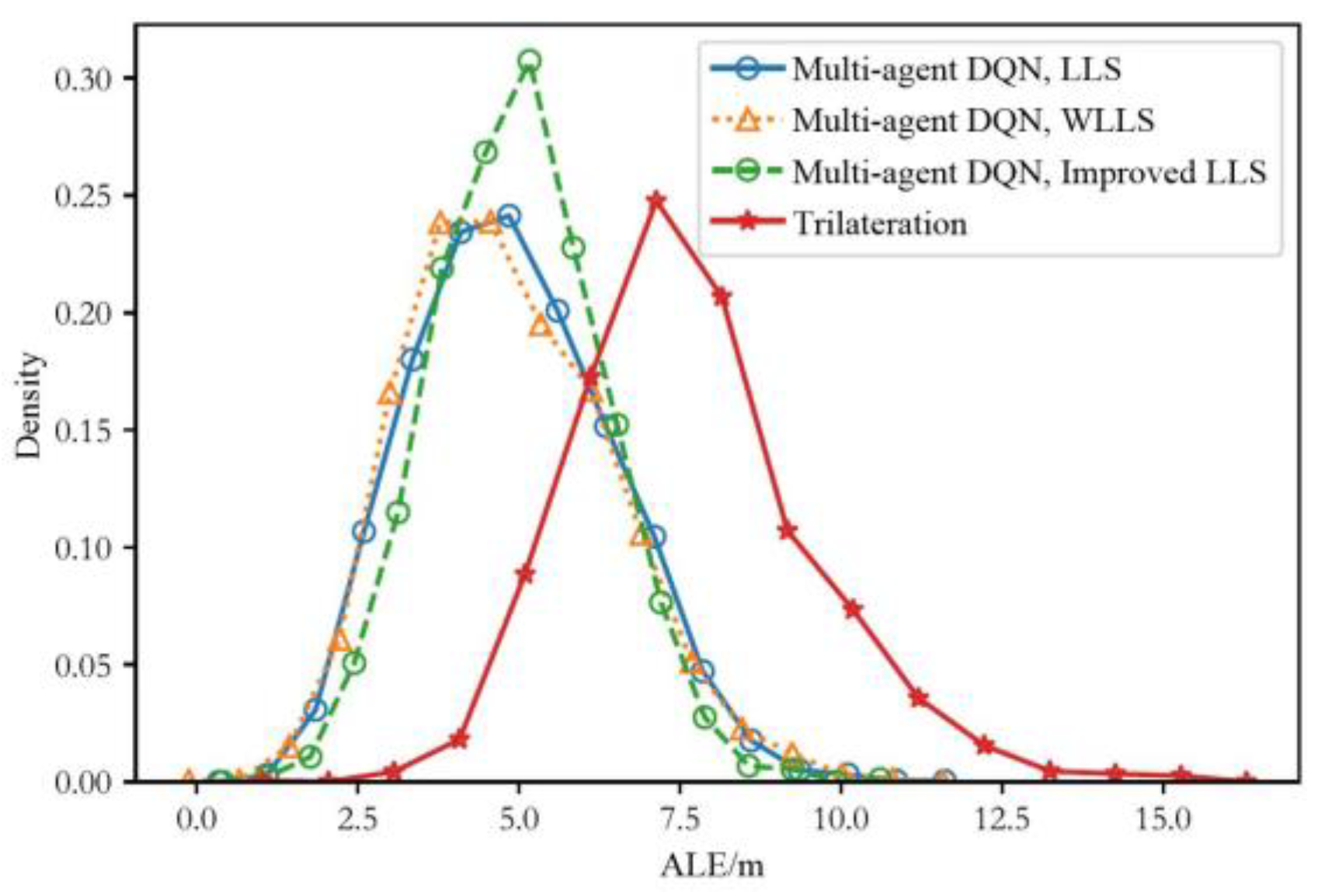
4.3.2. Testing Process
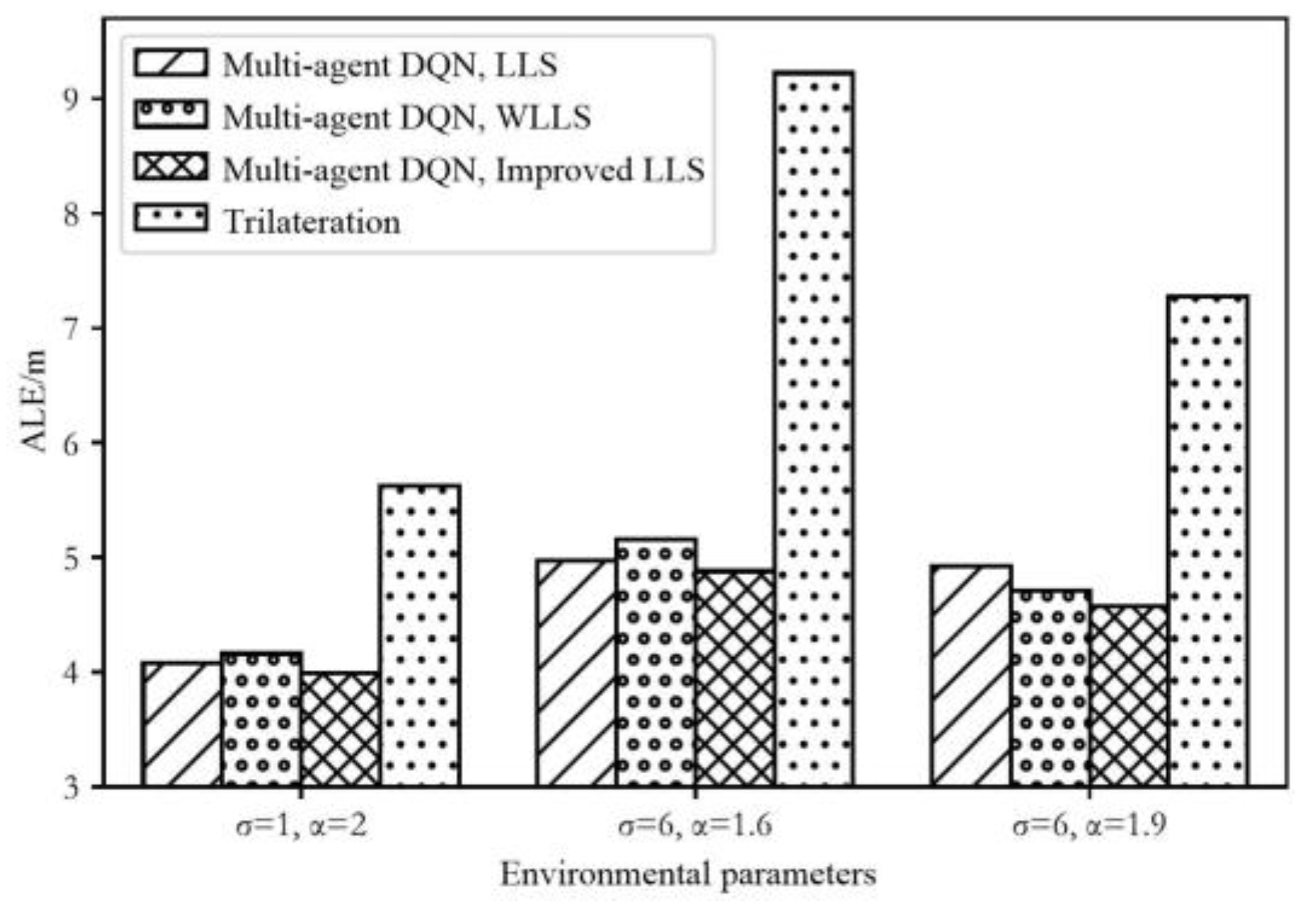
4.3.3. Performance Comparison between the Proposed Scheme and the Traditional Trilateration Scheme
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, X.; Nirwan, A.; Hu, F.; Shao, Y.; Elikplim, N.R.; Li, L. A survey on fusion-based indoor positioning. IEEE Commun. Surv. Tuts. 2019, 22, 566–594. [Google Scholar] [CrossRef]
- Szrek, J.; Trybała, P.; Góralczyk, M.; Michalak, A.; Ziętek, B.; Zimroz, R. Accuracy evaluation of selected mobile inspection robot localization techniques in a GNSS-denied environment. Sensors 2020, 21, 141. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Guo, Z.; Wang, Y.; Yao, D.; Li, B.; Li, L. A survey of trajectory planning methods for autonomous driving—Part I: Unstructured scenarios. IEEE Trans. Intell. Veh. 2023, 1–29. [Google Scholar] [CrossRef]
- Zhao, C.; Chu, D.; Deng, Z.; Lu, L. Human-like decision making for autonomous driving with social skills. IEEE Trans. Intell. Transp. Syst. 2024, 1–16. [Google Scholar] [CrossRef]
- Dou, F.; Lu, J.; Wang, Z.; Xiao, X.; Bi, J.; Huang, C.-H. Top-down indoor localization with Wi-fi fingerprints using deep Q-network. In Proceedings of the 2018 IEEE 15th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Chengdu, China, 9–12 October 2018; pp. 166–174. [Google Scholar]
- Dou, F.; Lu, J.; Zhu, T.; Bi, J. On-device indoor positioning: A federated reinforcement learning approach with heterogeneous devices. IEEE Internet Things J. 2023, 11, 3909–3926. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Guizani, M.; Oh, J.-S. Semisupervised deep reinforcement learning in support of IoT and smart city services. IEEE Internet Things J. 2017, 5, 624–635. [Google Scholar] [CrossRef]
- Li, Y.; Hu, X.; Zhuang, Y.; Gao, Z.; Zhang, P.; El-Sheimy, N. Deep reinforcement learning (DRL): Another perspective for unsupervised wireless localization. IEEE Internet Things J. 2019, 7, 6279–6287. [Google Scholar] [CrossRef]
- Testi, E.; Favarelli, E.; Giorgetti, A. Reinforcement Learning for Connected Autonomous Vehicle Localization via UAVs. In Proceedings of the 2020 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento, Italy, 4–6 November 2020; pp. 13–17. [Google Scholar]
- Afifi, G.; Gadallah, Y. Autonomous 3-D UAV Localization Using Cellular Networks: Deep Supervised Learning Versus Reinforcement Learning Approaches. IEEE Access 2021, 9, 155234–155248. [Google Scholar] [CrossRef]
- So, H.C.; Lin, L. Linear least squares approach for accurate received signal strength based source localization. IEEE Trans. Signal Process. 2011, 59, 4035–4040. [Google Scholar] [CrossRef]
- Guo, X.; Li, L.; Xu, F.; Ansari, N. Expectation maximization indoor localization utilizing supporting set for Internet of Things. IEEE Internet Things J. 2018, 6, 2573–2582. [Google Scholar] [CrossRef]
- Si, H.; Guo, X.; Ansari, N. Multi-agent interactive localization: A positive transfer learning perspective. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 553–566. [Google Scholar] [CrossRef]
- Miao, Q.; Huang, B.; Jia, B. Estimating distances via received signal strength and connectivity in wireless sensor networks. Wirel. Netw. 2020, 26, 971–982. [Google Scholar] [CrossRef]
- Tarrio, P.; Bernardos, A.M.; Besada, J.A.; Casar, J.R. A new positioning technique for RSS-based localization based on a weighted least squares estimator. In Proceedings of the 2008 IEEE International Symposium on Wireless Communication Systems, Reykjavik, Iceland, 21–24 October 2008; pp. 633–637. [Google Scholar]
- Chitte, S.D.; Dasgupta, S.; Ding, Z. Source localization from received signal strength under log-normal shadowing: Bias and variance. In Proceedings of the 2009 2nd International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 1–5. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Patwari, N.; Hero, A.O.; Perkins, M.; NCorreal, S. Relative location estimation in wireless sensor networks. IEEE Trans. Signal Process. 2003, 51, 2137–2148. [Google Scholar] [CrossRef]
- Chiu, W.Y.; Chen, B.S.; Yang, C.Y. Robust relative location estimation in wireless sensor networks with inexact position problems. IEEE Trans. Mob. Comput. 2012, 11, 935–946. [Google Scholar] [CrossRef]
- Zanca, G.; Zorzi, F.; Zanella, A.; Zorzi, M. Experimental comparison of RSSI-based localization algorithms for indoor wireless sensor networks. In Proceedings of the Workshop on Real-world Wireless Sensor Networks, Glasgow, UK, 1 April 2008; pp. 1–5. [Google Scholar]
- Deng, Z.; Chu, D.; Wu, C.; Liu, S.; Sun, C.; Liu, T.; Cao, D. A probabilistic model for driving-style-recognition-enabled driver steering behaviors. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1838–1851. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values | ||
|---|---|---|---|
| Environmental parameters | Number of grid lines | 10 | |
| Number of grid volumes | 10 | ||
| Grid size | 1 m × 1 m | ||
| Number of actions | 9 | ||
| Number of agents | 3 | ||
| Number of training traces | 1000 | ||
| Number of testing traces | 100 | ||
| Number of steps in each trace | 100 | ||
| Algorithm parameters | LS algorithm | Path loss exponent | 2/1.6/1.9 |
| Stand deviation | 1/6 | ||
| multi-agent DRL algorithm | Size of replay memory | 20,000 | |
| Initial size of replay memory | 2000 | ||
| Batch size for gradient decent | 200 | ||
| Update frequency of the network | 100 | ||
| Discount factor | 0.99 | ||
| Learning rate | 0.001 | ||
| Initial exploration rate | 1 | ||
| Discount factor of exploration rate | 0.002 | ||
| Final exploration rate | 0.1 | ||
| ALE (m) | RMSE (m) | MLE (m) | ||
|---|---|---|---|---|
| LLS | 4.081 | 3.439 | 1.952 | |
| WLLS | 4.161 | 3.503 | 1.952 | |
| Improved LLS | 3.991 | 3.410 | 1.837 | |
| Trilateration | 5.623 | 4.419 | 1.495 | |
| LLS | 4.971 | 3.990 | 2.039 | |
| WLLS | 5.159 | 4.135 | 2.375 | |
| Improved LLS | 4.879 | 3.938 | 2.235 | |
| Trilateration | 9.225 | 16.384 | 5.918 | |
| LLS | 4.925 | 3.982 | 2.014 | |
| WLLS | 4.710 | 3.855 | 2.571 | |
| Improved LLS | 4.571 | 3.697 | 2.323 | |
| Trilateration | 7.274 | 8.919 | 4.860 |
| APE (m) | RMSE (m) | LPE (m) | ||
|---|---|---|---|---|
| , , , | LLS | 4.840 | 3.889 | 2.191 |
| WLLS | 5.084 | 4.070 | 1.870 | |
| Improved LLS | 4.343 | 3.535 | 2.326 | |
| Trilateration | 6.724 | 7.270 | 2.459 | |
| , , , | LLS | 4.944 | 4.012 | 2.024 |
| WLLS | 3.990 | 3.429 | 1.215 | |
| Improved LLS | 5.198 | 4.207 | 1.480 | |
| Trilateration | 6.262 | 6.282 | 2.388 | |
| , , , | LLS | 4.611 | 3.816 | 1.790 |
| WLLS | 4.846 | 3.985 | 2.034 | |
| Improved LLS | 4.793 | 3.949 | 1.848 | |
| Trilateration | 8.303 | 13.165 | 4.999 | |
| , , , | LLS | 4.991 | 4.014 | 1.638 |
| WLLS | 4.518 | 3.746 | 2.147 | |
| Improved LLS | 5.045 | 4.086 | 2.183 | |
| Trilateration | 7.852 | 11.743 | 4.847 | |
| , , , | LLS | 4.775 | 3.869 | 1.887 |
| WLLS | 5.027 | 4.074 | 1.202 | |
| Improved LLS | 5.352 | 4.285 | 2.806 | |
| Trilateration | 7.045 | 9.625 | 4.395 | |
| , , , | LLS | 5.041 | 4.082 | 1.788 |
| WLLS | 5.017 | 4.068 | 1.730 | |
| Improved LLS | 4.885 | 3.928 | 2.090 | |
| Trilateration | 8.582 | 12.960 | 5.198 | |
| , , , | LLS | 5.038 | 4.084 | 2.023 |
| WLLS | 5.274 | 4.268 | 1.754 | |
| Improved LLS | 5.291 | 4.244 | 2.975 | |
| Trilateration | 8.766 | 11.586 | 5.024 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Guo, X. A Novel Method of UAV-Assisted Trajectory Localization for Forestry Environments. Sensors 2024, 24, 3398. https://doi.org/10.3390/s24113398
Huang J, Guo X. A Novel Method of UAV-Assisted Trajectory Localization for Forestry Environments. Sensors. 2024; 24(11):3398. https://doi.org/10.3390/s24113398
Chicago/Turabian StyleHuang, Jian, and Xiansheng Guo. 2024. "A Novel Method of UAV-Assisted Trajectory Localization for Forestry Environments" Sensors 24, no. 11: 3398. https://doi.org/10.3390/s24113398
APA StyleHuang, J., & Guo, X. (2024). A Novel Method of UAV-Assisted Trajectory Localization for Forestry Environments. Sensors, 24(11), 3398. https://doi.org/10.3390/s24113398