
DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning



Abstract
1. Introduction
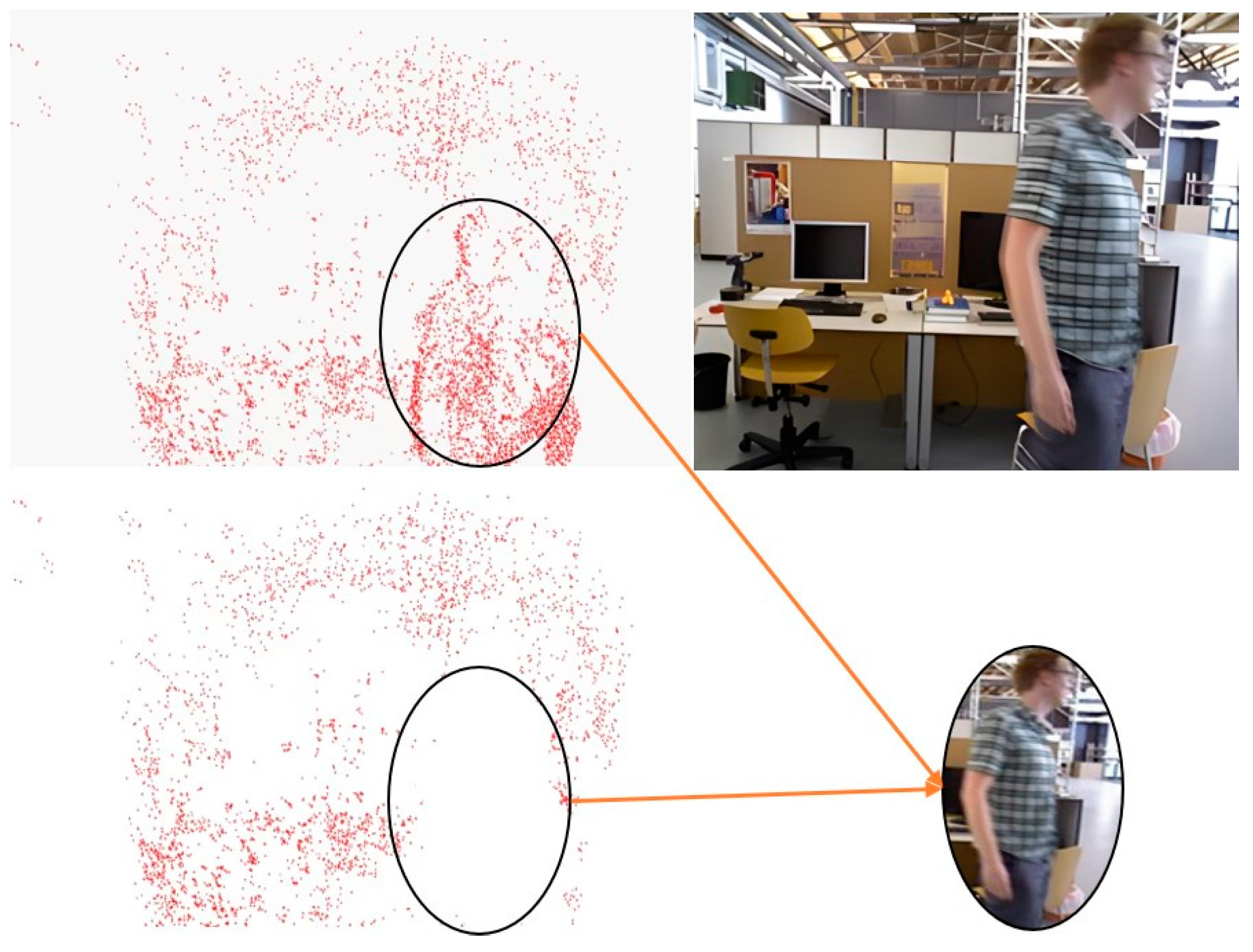
- We refine the region segmentation approach within the DSO algorithm, accelerating the motion recognition speed of the algorithm through dynamic region segmentation and the direct selection of optical flow points.
- We propose a method that utilizes inter-frame semantic information to identify and remove dynamic objects. This approach effectively reduces the interference caused by noise introduced by dynamic objects, enhancing the system’s robustness in dynamic environments. Furthermore, we also improve the matching accuracy of pixel intensities points by adding semantic probability, so that our algorithm can make full use of semantic information.
- We synergize video inpainting algorithms with the map-building thread of the DSO algorithm, compensating for static background gaps caused by the removal of moving objects, thereby optimizing the map construction performance of the DSO algorithm in dynamic environments.
- We integrate a loop closure detection module, thus rendering the DSO algorithm framework more comprehensive. Moreover, by associating loop closure detection with video inpainting algorithms, we enhance the efficiency of this module in identifying loop closures within dynamic environments.
2. Related Works
2.1. Eliminating Dynamic Objects
2.2. Constructing Dynamic Objects
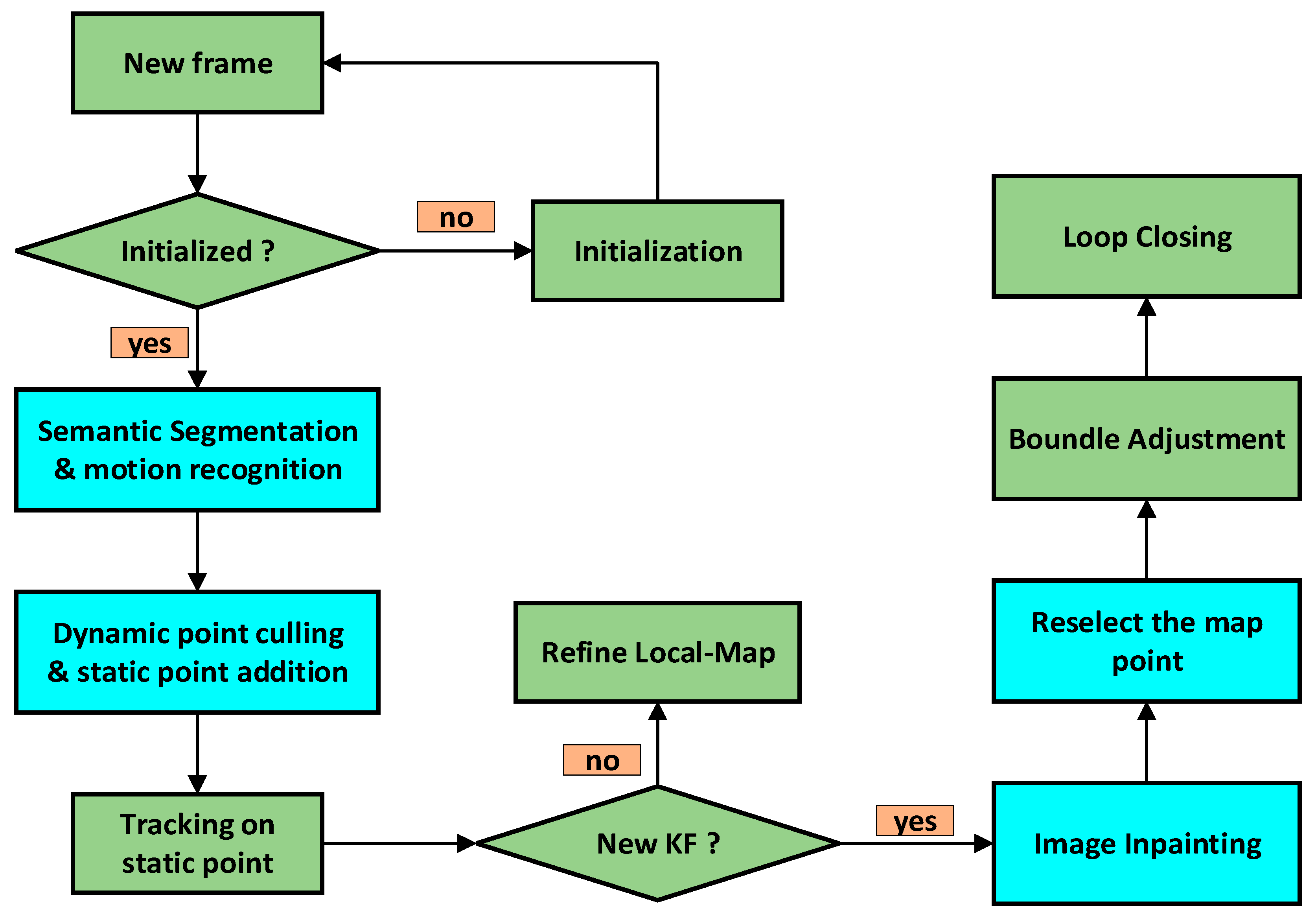
3. Algorithm Design
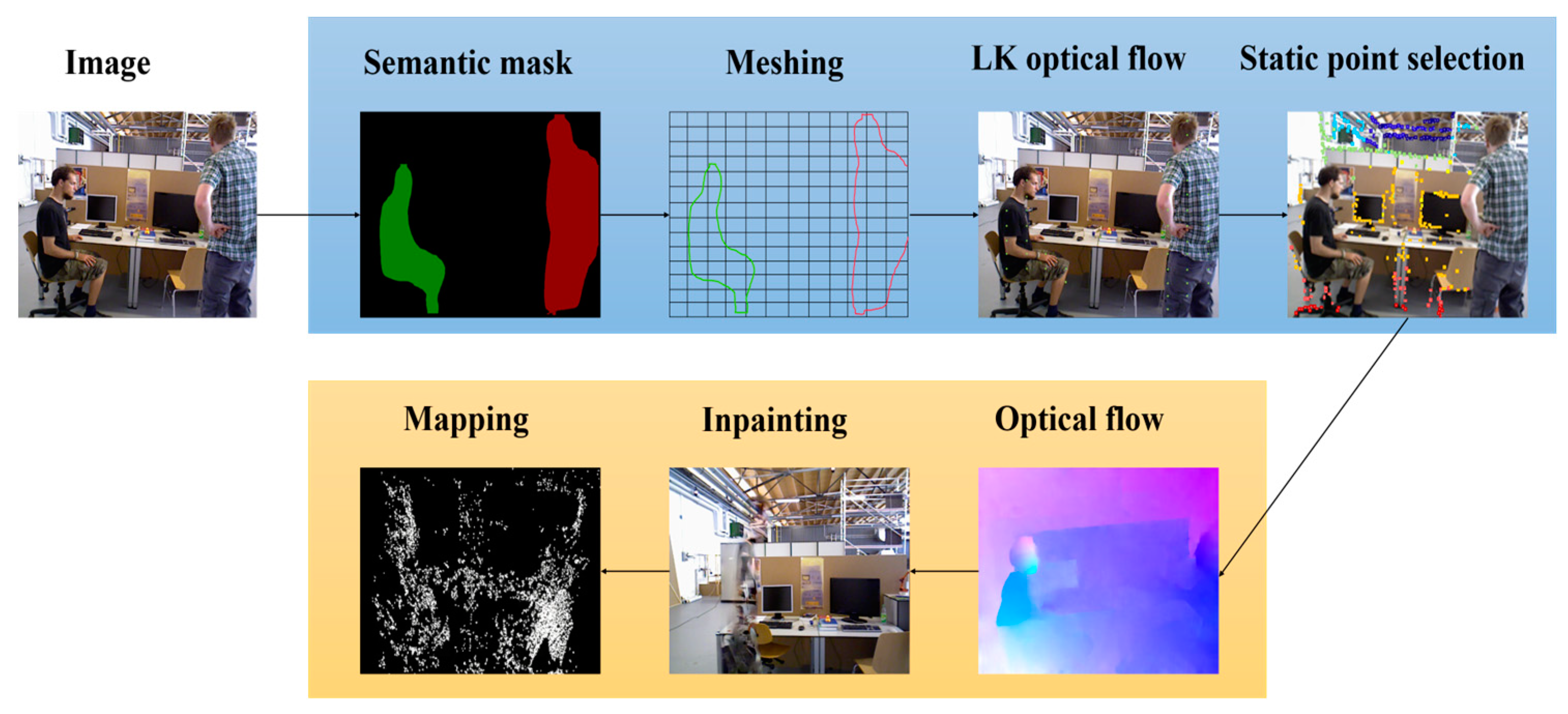
3.1. Segmentation of Potential Dynamic Objects
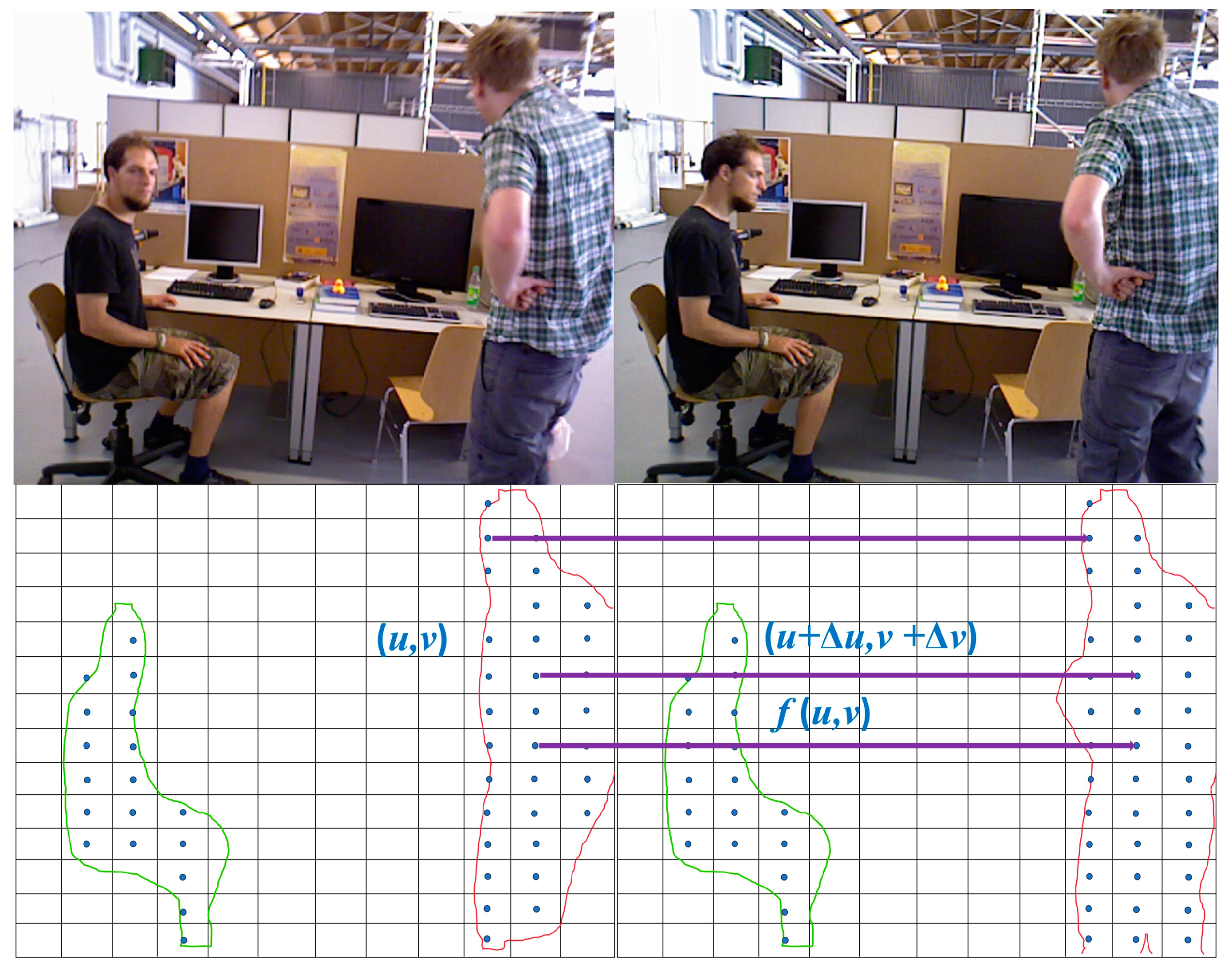
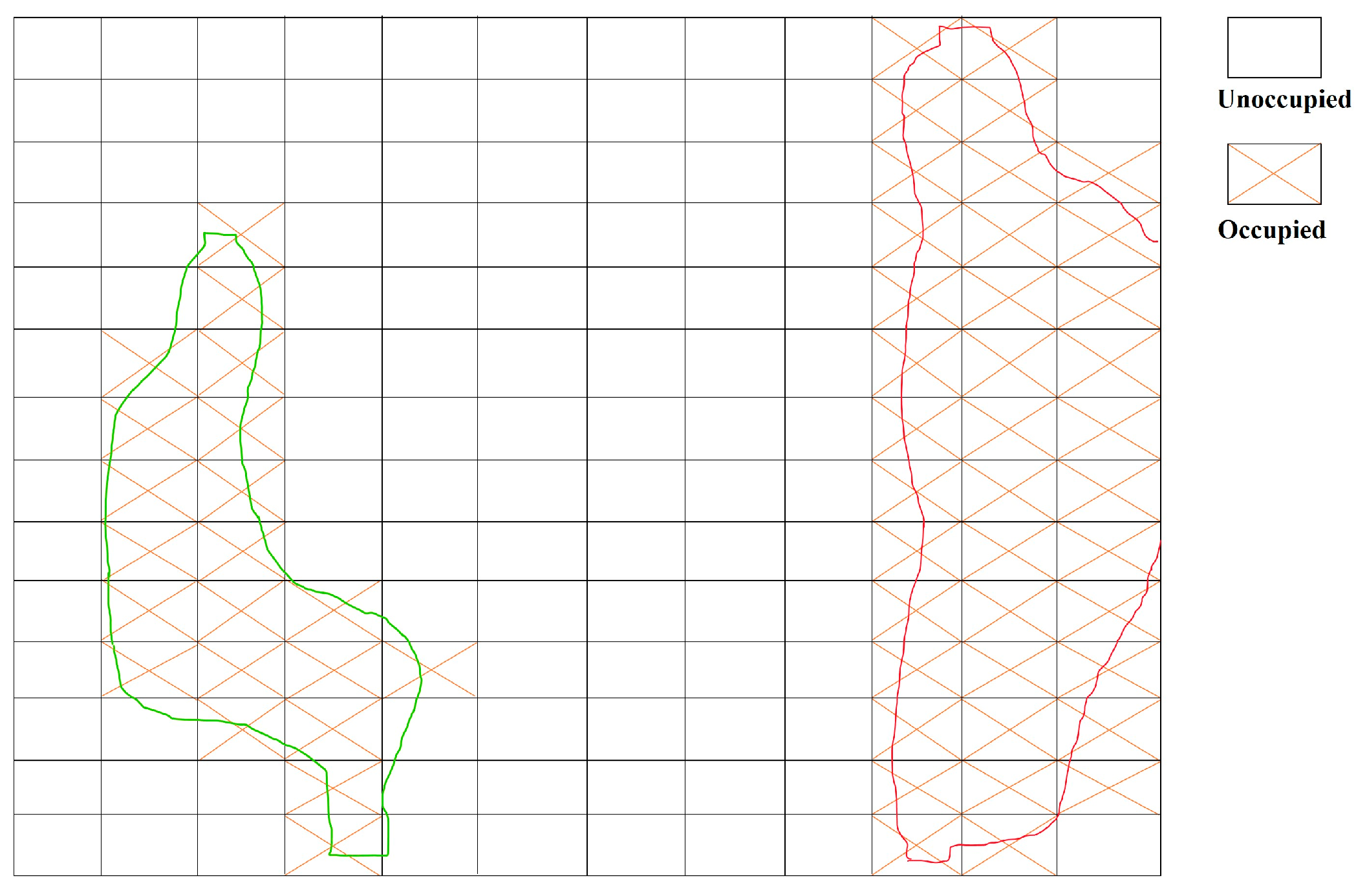
3.2. Region Segmentation and Data Association
3.3. Dynamic Object Recognition and Determination of Dynamic Regions
3.4. Completion of Static Background in Keyframes and Loop Closure
4. Simulation Testing
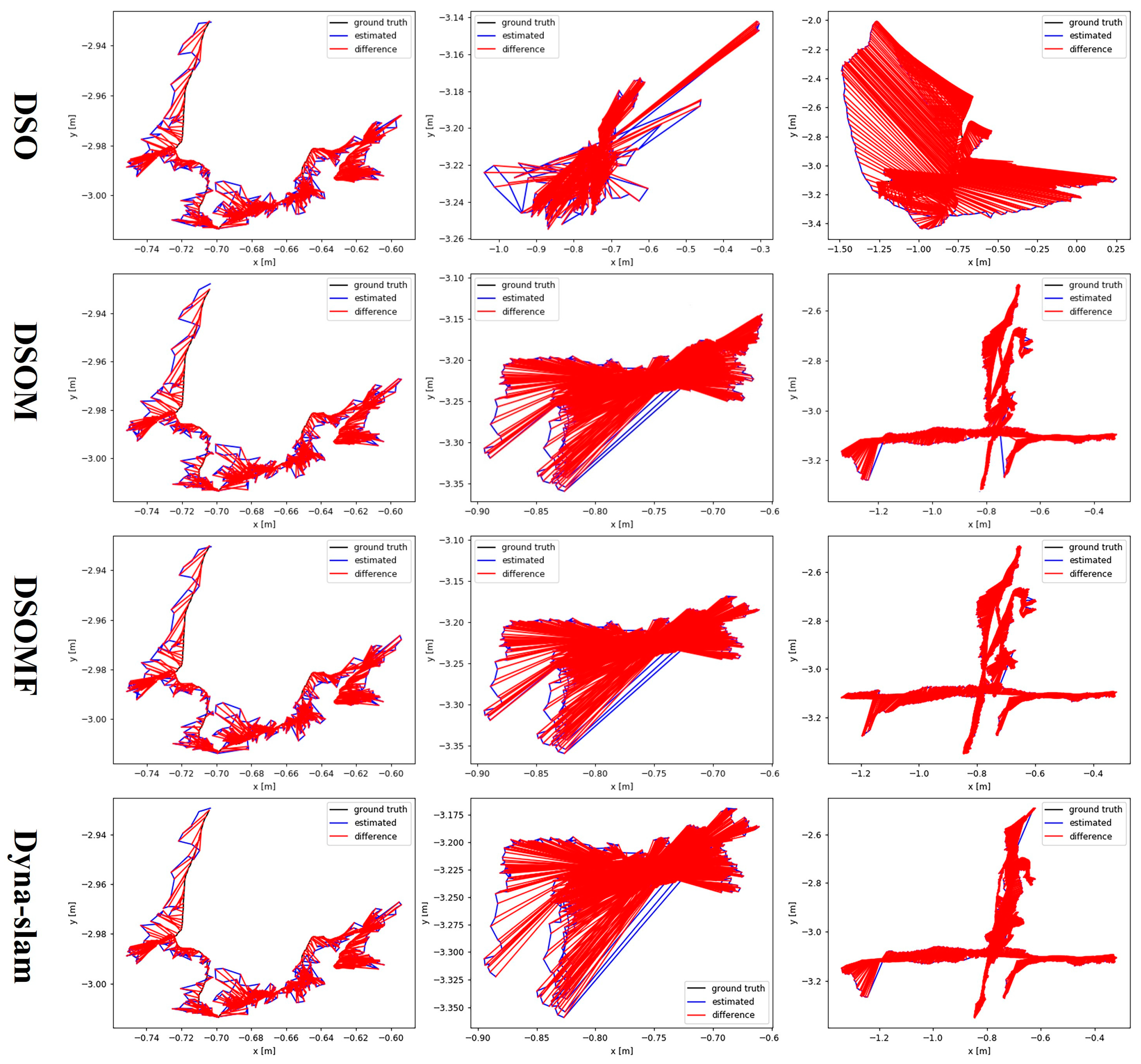
4.1. Simulation Testing on TUM Dataset
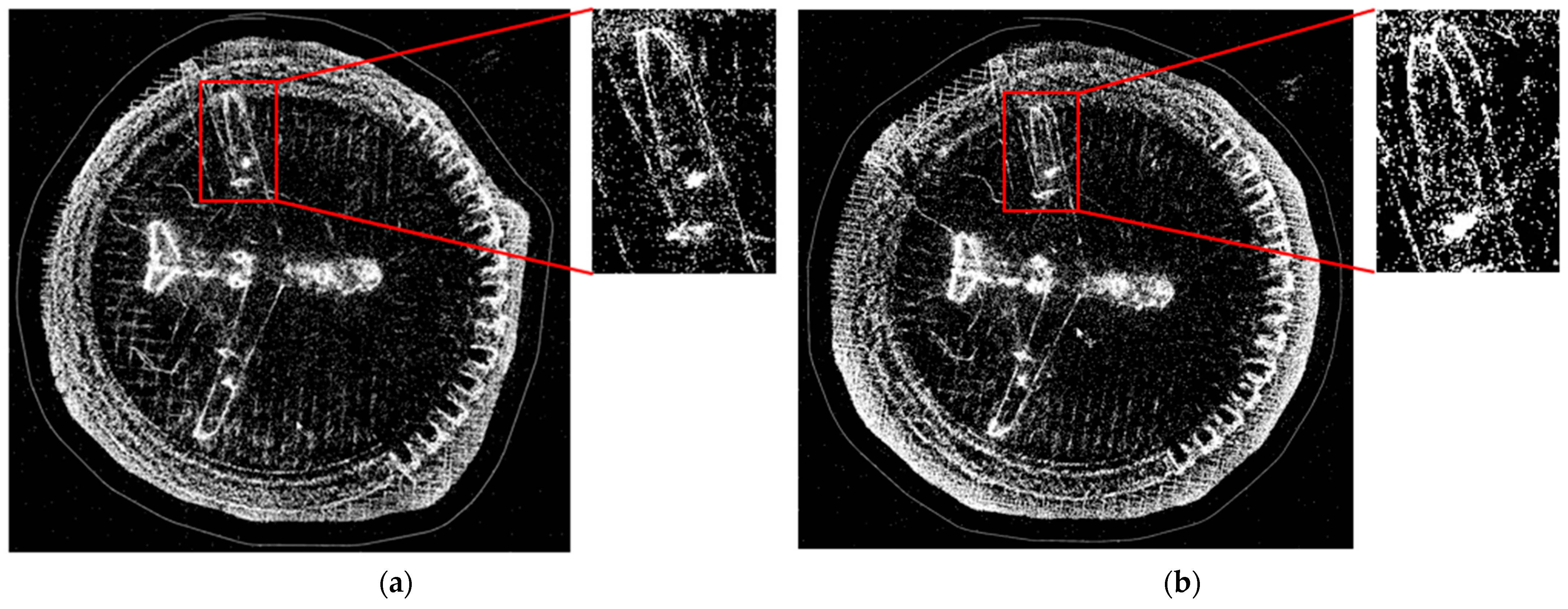
4.2. Simulation Testing on KITTI Dataset
5. Unmanned Platform Experiment
5.1. Drone Experiment
5.2. Driverless Car Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tourani, A.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H. Visual SLAM: What Are the Current Trends and What to Expect? Sensors 2022, 22, 9297. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12776–12786. [Google Scholar]
- Wang, H.; Wang, J.; Agapito, L. Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13293–13302. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- El Ghazouali, S.; Mhirit, Y.; Oukhrid, A.; Michelucci, U.; Nouira, H. FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything. Sensors 2024, 24, 2889. [Google Scholar] [CrossRef]
- Yugay, V.; Li, Y.; Gevers, T.; Oswald, M.R. Gaussian-SLAM: Photo-Realistic Dense SLAM with Gaussian Splatting. arXiv 2023, arXiv:2312.10070. [Google Scholar] [CrossRef]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS Int. J. Geo-Inf. 2020, 9, 202. [Google Scholar] [CrossRef]
- Zhong, F.; Wang, S.; Zhang, Z.; Chen, C.; Wang, Y. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Sun, Y.; Liu, M.; Meng, M.Q.-H. Improving RGB-D SLAM in Dynamic Environments: A Motion Removal Approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Li, S.; Lee, D. RGB-D SLAM in Dynamic Environments Using Static Point Weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, S. Towards Dense Moving Object Segmentation Based Robust Dense RGB-D SLAM in Dynamic Scenarios. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 1841–1846. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Tan, W.; Dong, Z.; Zhang, G.; Bao, H. Robust Monocular SLAM in Dynamic Environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Ferrera, M.; Moras, J.; Trouvé-Peloux, P.; Creuze, V. Real-Time Monocular Visual Odometry for Turbid and Dynamic Underwater Environments. arXiv 2018, arXiv:1806.05842. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Liu, Y.; Miura, J. RDS-SLAM: Real-Time Dynamic SLAM Using Semantic Segmentation Methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Yebes, J.J.; Almazan, J.; Bergasa, L.M. On Combining Visual SLAM and Dense Scene Flow to Increase the Robustness of Localization and Mapping in Dynamic Environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 1290–1297. [Google Scholar]
- Wang, C.-C.; Thorpe, C.; Thrun, S.; Hebert, M.; Durrant-Whyte, H. Simultaneous Localization, Mapping and Moving Object Tracking. Int. J. Robot. Res. 2007, 26, 889–916. [Google Scholar] [CrossRef]
- Reddy, N.D.; Singhal, P.; Chari, V.; Krishna, K.M. Dynamic Body VSLAM with Semantic Constraints. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 1897–1904. [Google Scholar]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.J.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Tateno, K.; Tombari, F.; Navab, N. When 2.5D Is Not Enough: Simultaneous Reconstruction, Segmentation and Recognition on Dense SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2295–2302. [Google Scholar]
- Sucar, E.; Wada, K.; Davison, A. NodeSLAM: Neural Object Descriptors for Multi-View Shape Reconstruction. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 949–958. [Google Scholar]
- Hosseinzadeh, M.; Li, K.; Latif, Y.; Reid, I. Real-Time Monocular Object-Model Aware Sparse SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7123–7129. [Google Scholar]
- Nicholson, L.; Milford, M.; Sunderhauf, N. QuadricSLAM: Dual Quadrics From Object Detections as Landmarks in Object-Oriented SLAM. IEEE Robot. Autom. Lett. 2019, 4, 1–8. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. arXiv 2020, arXiv:2010.07820. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kluger, F.; Rosenhahn, B. PARSAC: Accelerating Robust Multi-Model Fitting with Parallel Sample Consensus. Proc. AAAI Conf. Artif. Intell. 2024, 38, 2804–2812. [Google Scholar] [CrossRef]
- Gao, C.; Saraf, A.; Huang, J.-B.; Kopf, J. Flow-Edge Guided Video Completion. arXiv 2020, arXiv:2009.01835. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Runz, M.; Buffier, M.; Agapito, L. MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Pan, X.; Liu, H.; Fang, M.; Wang, Z.; Zhang, Y.; Zhang, G. Dynamic 3D Scenario-Oriented Monocular SLAM Based on Semantic Probability Prediction. J. Image Graph. 2023, 28, 2151–2166. [Google Scholar] [CrossRef]
- Xu, R.; Li, X.; Zhou, B.; Loy, C.C. Deep Flow-Guided Video Inpainting. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3718–3727. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identifier | DSO | Dyna-SLAM | DSOM | DSOMF | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | STD | RMSE | STD | RMSE | STD | RMSE | STD | |
| sitting_static | 0.009 | 0.004 | 0.006 | 0.003 | 0.006 | 0.003 | 0.006 | 0.003 |
| walking_static | 0.307 | 0.113 | 0.037 | 0.043 | 0.035 | 0.039 | 0.029 | 0.032 |
| walking_xyz | 0.889 | 0.419 | 0.091 | 0.057 | 0.081 | 0.047 | 0.072 | 0.043 |
| Algorithm Name | Time (ms/Frame) | GPU Memory Usage/GB |
|---|---|---|
| DSO | 19 | - |
| DSOM | 240 | 5.2 |
| DSOMF | 312 | 6.5 |
| Dyna-SLAM | 300 | 5.7 |
| Algorithm Name | Time (ms/Frame) |
|---|---|
| Semantic Segmentation | 70 |
| Tracking | 10 |
| Data Association | 5 |
| Image Completion | 55 |
| Sequence | DSO | DSOMF | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Max | Min | RMSE | Mean | Max | Min | |
| 01 | 9.478 | 7.969 | 16.756 | 4.125 | 5.987 | 6.028 | 11.763 | 1.485 |
| 02 | 6.561 | 5.212 | 15.608 | 0.199 | 5.626 | 3.697 | 10.438 | 0.286 |
| 04 | 1.131 | 1.759 | 1.745 | 0.541 | 1.067 | 1.172 | 2.251 | 0.318 |
| 06 | 0.886 | 0.739 | 1.241 | 0.433 | 0.568 | 0.786 | 1.081 | 0.306 |
| Sequence | Dyna-SLAM | DSOM | DSOMF |
|---|---|---|---|
| 00 | 3.505 | 2.937 | 2.521 |
| 01 | 9.003 | 7.607 | 6.420 |
| 02 | 5.219 | 4.213 | 4.238 |
| 03 | 1.299 | 1.054 | 0.966 |
| 04 | 1.591 | 1.256 | 1.214 |
| 05 | 1.779 | 1.289 | 1.372 |
| 06 | 0.824 | 0.672 | 0.604 |
| 07 | 2.489 | 2.036 | 1.880 |
| 08 | 3.291 | 2.778 | 2.473 |
| 09 | 2.564 | 2.101 | 1.966 |
| 10 | 2.743 | 2.259 | 2.375 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, S.; Wang, Z.; Zhang, X. DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning. Sensors 2024, 24, 3063. https://doi.org/10.3390/s24103063
Yue S, Wang Z, Zhang X. DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning. Sensors. 2024; 24(10):3063. https://doi.org/10.3390/s24103063
Chicago/Turabian StyleYue, Shengzhe, Zhengjie Wang, and Xiaoning Zhang. 2024. "DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning" Sensors 24, no. 10: 3063. https://doi.org/10.3390/s24103063
APA StyleYue, S., Wang, Z., & Zhang, X. (2024). DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning. Sensors, 24(10), 3063. https://doi.org/10.3390/s24103063