
Multi-Scale-Denoising Residual Convolutional Network for Retinal Disease Classification Using OCT

Abstract
:1. Introduction
- The soft-denoising block is designed to effectively remove noise-related features by employing soft thresholding.
- The multi-scale context block (MCB) aims to express multi-scale features and enhance feature extraction by increasing the receptive field for each subnet.
- The feature fusion block (FFB) is designed to combine low-resolution and high-resolution features, enabling more accurate identification of retinopathy at various scales in OCT images.
- Anti-noise experiments proved that the proposed method exhibits superior robustness against various intensities of speckle noise and Gaussian noise.
2. Materials and Methods
2.1. OCT Datasets
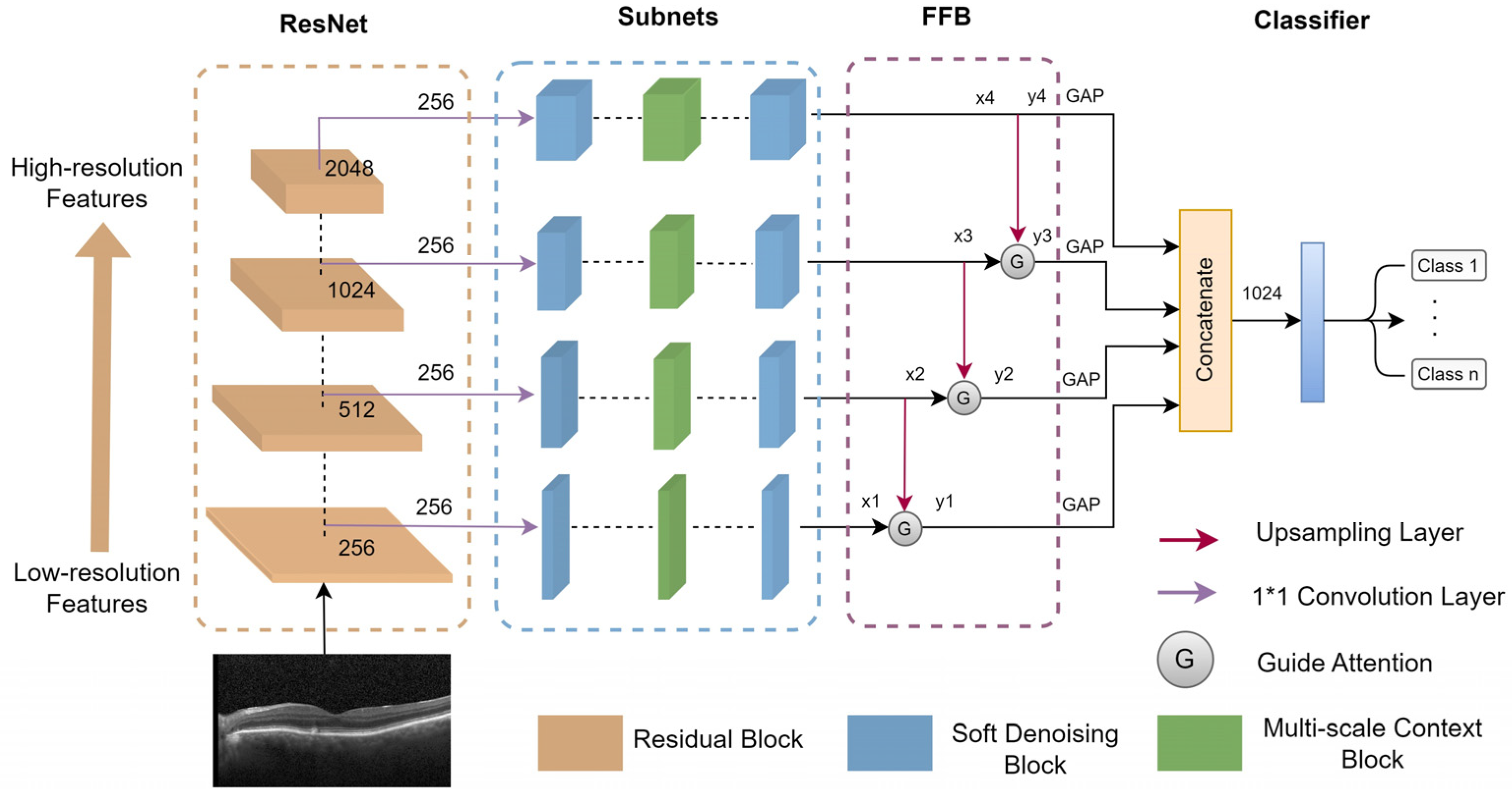
2.2. Proposed MS-DRCN Method
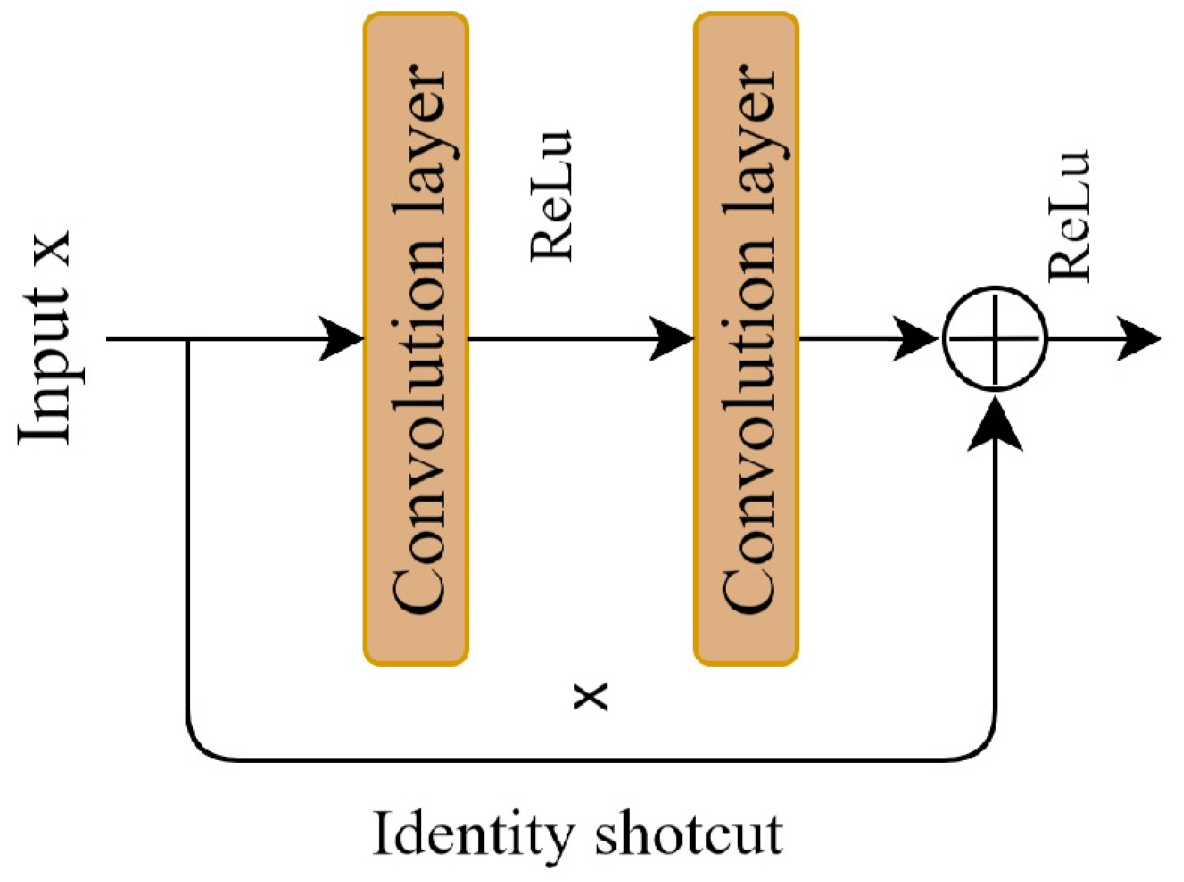
2.2.1. Residual Learning
2.2.2. Soft-Denoising Block
2.2.3. Multi-Scale Context Block
2.2.4. Feature Fusion Block
2.3. Experimental Settings
2.4. Evaluation Criteria
3. Results and Discussion
3.1. Comparisons on OCT2017 Dataset
3.2. Comparisons on OCT-C4 Datasets
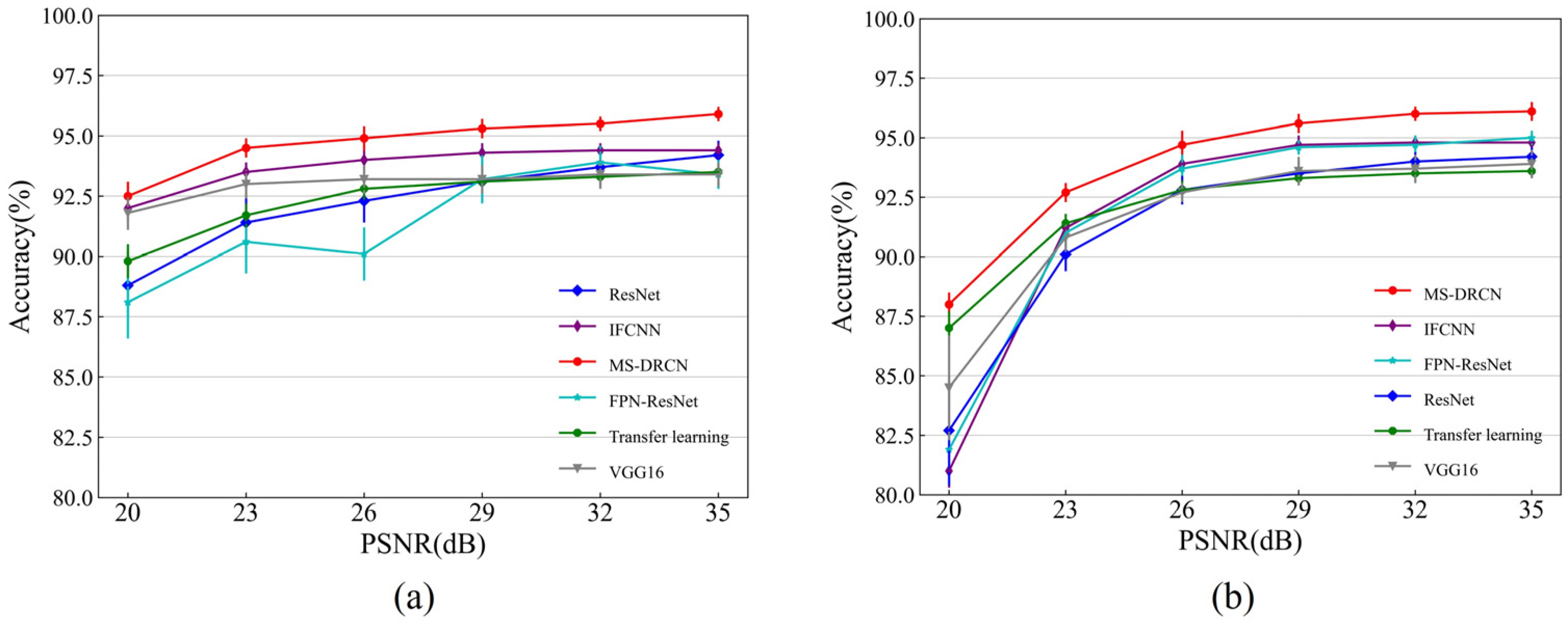
3.3. Robustness of Our Method to Noise
3.4. Ablation Experiments
3.5. Visualization
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gale, R.; Scanlon, P.H.; Evans, M.; Ghanchi, F.; Yang, Y.; Silvestri, G.; Freeman, M.; Maisey, A.; Napier, J. Action on diabetic macular oedema: Achieving optimal patient management in treating visual impairment due to diabetic eye disease. Eye 2017, 31, S1–S20. [Google Scholar] [CrossRef] [PubMed]
- Wong, W.L.; Su, X.; Li, X.; Cheung, C.M.; Klein, R.; Cheng, C.Y.; Wong, T.Y. Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: A systematic review and meta-analysis. Lancet Glob. Health 2014, 2, e106–e116. [Google Scholar] [CrossRef] [PubMed]
- Puliafito, C.A.; Hee, M.R.; Lin, C.P.; Reichel, E.; Schuman, J.S.; Duker, J.S.; Izatt, J.A.; Swanson, E.A.; Fujimoto, J.G. Imaging of macular diseases with optical coherence tomography. Ophthalmology 1995, 102, 217–229. [Google Scholar] [CrossRef] [PubMed]
- Drexler, W.; Fujimoto, J.G. State-of-the-art retinal optical coherence tomography. Prog. Retin. Eye Res. 2008, 27, 45–88. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed]
- van Velthoven, M.E.J.; Faber, D.J.; Verbraak, F.D.; van Leeuwen, T.G.; de Smet, M.D. Recent developments in optical coherence tomography for imaging the retina. Prog. Retin. Eye Res. 2007, 26, 57–77. [Google Scholar] [CrossRef] [PubMed]
- Rong, Y.; Xiang, D.; Zhu, W.; Yu, K.; Shi, F.; Fan, Z.; Chen, X. Surrogate-Assisted Retinal OCT Image Classification Based on Convolutional Neural Networks. IEEE J. Biomed. Health Inform. 2019, 23, 253–263. [Google Scholar] [CrossRef]
- Rasti, R.; Mehridehnavi, A.; Rabbani, H.; Hajizadeh, F. Convolutional Mixture of Experts Model: A Comparative Study on Automatic Macular Diagnosis in Retinal Optical Coherence Tomography Imaging. J. Med. Signals Sens. 2019, 9, 1–14. [Google Scholar] [CrossRef]
- Altan, G. DeepOCT: An explainable deep learning architecture to analyze macular edema on OCT images. Eng. Sci. Technol. Int. J. 2022, 34, 101091. [Google Scholar] [CrossRef]
- Wen, H.; Zhao, J.; Xiang, S.; Lin, L.; Liu, C.; Wang, T.; An, L.; Liang, L.; Huang, B. Towards more efficient ophthalmic disease classification and lesion location via convolution transformer. Comput. Methods Programs Biomed. 2022, 220, 106832. [Google Scholar] [CrossRef]
- Das, V.; Dandapat, S.; Bora, P.K. Multi-scale deep feature fusion for automated classification of macular pathologies from OCT images. Biomed. Signal Process. Control 2019, 54, 101605. [Google Scholar] [CrossRef]
- Albarrak, A.; Coenen, F.; Zheng, Y. Age-related Macular Degeneration Identification In Volumetric Optical Coherence Tomography Using Decomposition and Local Feature Extraction. In Proceedings of the 17th Medical Image, Understanding and Analysis Conference, Aberdeen, UK, 19–21 July 2023; pp. 59–64. [Google Scholar]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Li, S.; Sun, Z. Fully automated macular pathology detection in retina optical coherence tomography images using sparse coding and dictionary learning. J. Biomed. Opt. 2017, 22, 16012. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Serener, A.; Serte, S. Dry and wet age-related macular degeneration classification using oct images and deep learning. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; IEEE: Nicosia, Cyprus, 2019; pp. 1–4. [Google Scholar]
- Kaymak, S.; Serener, A. Automated age-related macular degeneration and diabetic macular edema detection on oct images using deep learning. In Proceedings of the 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 6–8 September 2018; IEEE: Nicosia, Cyprus, 2018; pp. 265–269. [Google Scholar]
- Saleh, N.; Abdel Wahed, M.; Salaheldin, A.M. Transfer learning-based platform for detecting multi-classification retinal disorders using optical coherence tomography images. Int. J. Imaging Syst. Technol. 2021, 32, 740–752. [Google Scholar] [CrossRef]
- Karri, S.P.; Chakraborty, D.; Chatterjee, J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express 2017, 8, 579–592. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e1129. [Google Scholar] [CrossRef]
- Huang, L.; He, X.; Fang, L.; Rabbani, H.; Chen, X. Automatic Classification of Retinal Optical Coherence Tomography Images with Layer Guided Convolutional Neural Network. IEEE Signal Process. Lett. 2019, 26, 1026–1030. [Google Scholar] [CrossRef]
- Fang, L.; Jin, Y.; Huang, L.; Guo, S.; Zhao, G.; Chen, X. Iterative fusion convolutional neural networks for classification of optical coherence tomography images. J. Vis. Commun. Image Represent. 2019, 59, 327–333. [Google Scholar] [CrossRef]
- Fang, L.; Wang, C.; Li, S.; Rabbani, H.; Chen, X.; Liu, Z. Attention to Lesion: Lesion-Aware Convolutional Neural Network for Retinal Optical Coherence Tomography Image Classification. IEEE Trans. Med. Imaging 2019, 38, 1959–1970. [Google Scholar] [CrossRef]
- Sotoudeh-Paima, S.; Jodeiri, A.; Hajizadeh, F.; Soltanian-Zadeh, H. Multi-scale convolutional neural network for automated AMD classification using retinal OCT images. Comput. Biol. Med. 2022, 144, 105368. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2018; pp. 2117–2125. [Google Scholar]
- Ma, Z.; Xie, Q.; Xie, P.; Fan, F.; Gao, X.; Zhu, J. HCTNet: A Hybrid ConvNet-Transformer Network for Retinal Optical Coherence Tomography Image Classification. Biosensors 2022, 12, 542. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Deng, G.; Li, W.; Chen, Y.; Gao, F.; Liu, H.; He, Y.; Shi, G. Deep learning for quality assessment of retinal OCT images. Biomed. Opt. Express 2019, 10, 6057–6072. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Chen, H.; Liu, Z.; Zhang, X.D.; Jiang, M.S.; Wu, Z.Z.; Zhou, K.Q. Deep learning-based automated detection of retinal diseases using optical coherence tomography images. Biomed. Opt. Express 2019, 10, 6204–6226. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Deng, Y.; Fang, L.; Peng, Q. Multi-Modal Retinal Image Classification with Modality-Specific Attention Network. IEEE Trans. Med. Imaging 2021, 40, 1591–1602. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xu, Z.; Yu, W.; Zhao, J.; Yang, J.; He, F.; Yang, Z.; Chen, D.; Ding, D.; Chen, Y. Two-stream CNN with loose pair training for multi-modal AMD categorization. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings, Part I 22, 2019. Springer: Berlin/Heidelberg, Germany, 2019; pp. 156–164. [Google Scholar]
- Karthik, K.; Mahadevappa, M. Convolution neural networks for optical coherence tomography (OCT) image classification. Biomed. Signal Process. Control. 2023, 79, 104176. [Google Scholar] [CrossRef]
- Ozcan, A.; Bilenca, A.; Desjardins, A.E.; Bouma, B.E.; Tearney, G.J. Speckle reduction in optical coherence tomography images using digital filtering. Int. J. Comput. Vis. 2007, 8, 123–139. [Google Scholar] [CrossRef]
- Ruan, F.; Dang, L.; Ge, Q.; Zhang, Q.; Qiao, B.; Zuo, X. Dual-Path Residual “Shrinkage” Network for Side-Scan Sonar Image Classification. Comput. Intell. Neurosci. 2022, 2022, 6962838. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep Residual Shrinkage Networks for Fault Diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Isogawa, K.; Ida, T.; Shiodera, T.; Takeguchi, T. Deep Shrinkage Convolutional Neural Network for Adaptive Noise Reduction. IEEE Signal Process. Lett. 2018, 25, 224–228. [Google Scholar] [CrossRef]
- Thomas, A.; Harikrishnan, P.M.; Krishna, K.A.; Palanisamy, P.; Gopi, V.P. A novel multiscale convolutional neural network based age-related macular degeneration detection using OCT images. Biomed. Signal Process. Control. 2021, 67, 102538. [Google Scholar] [CrossRef]
- Thomas, A.; Harikrishnan, P.M.; Ramachandran, R.; Ramachandran, S.; Manoj, R.; Palanisamy, P.; Gopi, V.P. A novel multiscale and multipath convolutional neural network based age-related macular degeneration detection using OCT images. Comput. Methods Programs Biomed 2021, 209, 106294. [Google Scholar] [CrossRef] [PubMed]
- Rasti, R.; Rabbani, H.; Mehridehnavi, A.; Hajizadeh, F. Macular OCT Classification Using a Multi-Scale Convolutional Neural Network Ensemble. IEEE Trans. Med. Imaging 2018, 37, 1024–1034. [Google Scholar] [CrossRef] [PubMed]
- Naren, O.S. Retinal OCT-C8. Available online: https://www.kaggle.com/datasets/obulisainaren/retinal-oct-c8 (accessed on 4 August 2022).
- Sergey, I.; Christian, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Cluj-Napoca, Romania, 6–8 September 2018; pp. 7132–7141. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Forouzanfar, M.; Moghaddam, H.A. A Directional Multiscale Approach for Speckle Reduction in Optical Coherence Tomography Images. In Proceedings of the 2007 International Conference Eletrical Engineering, London, UK, 2–4 July 2007; pp. 1–6. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. IEEE Int. Conf. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmentation Type | Value |
|---|---|
| Rotation range | ±15 degrees |
| Scale range | ±20% |
| Brightness range | ±20% |
| Horizontal flip | True |
| Method | Class | Accuracy (%) | Precision (%) | Sensitivity (%) | OA (%) | OP (%) |
|---|---|---|---|---|---|---|
| Vgg16 [43] | CNV | 94.6 ± 0.4 | 82.5 ± 0.6 | 99.1 ± 0.2 | 93.4 ± 0.5 | 94.3 ± 0.5 |
| DME | 98.9 ± 0.3 | 96.6 ± 1.6 | 98.3 ± 0.3 | |||
| Drusen | 94.6 ± 0.5 | 99.3 ± 0.2 | 78.6 ± 1.2 | |||
| Normal | 98.9 ± 0.2 | 98.5 ± 0.2 | 97.0 ± 1.0 | |||
| ResNet [44] | CNV | 95.0 ± 0.5 | 85.0 ± 1.4 | 97.2 ± 1.2 | 94.0 ± 0.6 | 94.5 ± 0.5 |
| DME | 98.7 ± 0.4 | 95.5 ± 1.5 | 99.5 ± 0.2 | |||
| Drusen | 95.1 ± 0.6 | 99.3 ± 0.2 | 81.0 ± 2.7 | |||
| Normal | 98.9 ± 0.2 | 98.2 ± 0.6 | 98.1 ± 1.0 | |||
| Transfer learning [20] | CNV | 95.0 ± 0.7 | 85.4 ± 2.1 | 98.9 ± 0.5 | 94.3 ± 0.8 | 94.8 ± 0.6 |
| DME | 99.1 ± 0.4 | 98.4 ± 1.3 | 97.8 ± 0.6 | |||
| Drusen | 95.2 ± 0.6 | 97.9 ± 0.2 | 82.6 ± 2.4 | |||
| Normal | 98.8 ± 0.2 | 97.3 ± 0.4 | 98.0 ± 0.9 | |||
| IFCNN [22] | CNV | 95.4 ± 0.3 | 84.8 ± 0.7 | 99.0 ± 0.5 | 94.7 ± 0.2 | 95.2 ± 0.3 |
| DME | 98.8 ± 0.4 | 98.4 ± 0.2 | 95.5 ± 0.3 | |||
| Drusen | 96.0 ± 0.4 | 98.0 ± 0.4 | 85.1 ± 0.8 | |||
| Normal | 98.7 ± 0.3 | 98.4 ± 0.3 | 98.5 ± 0.4 | |||
| FPN-ResNet [24] | CNV | 95.9 ± 0.3 | 87.2 ± 0.6 | 98.2 ± 0.5 | 94.6 ± 0.2 | 94.9 ± 0.2 |
| DME | 98.8 ± 0.1 | 96.1 ± 0.4 | 99.2 ± 0.2 | |||
| Drusen | 95.7 ± 0.2 | 98.8 ± 0.2 | 83.4 ± 0.8 | |||
| Normal | 98.9 ± 0.2 | 97.8 ± 0.2 | 97.3 ± 0.4 | |||
| MS-DRCN | CNV | 97.4 ± 0.3 | 91.1 ± 1.0 | 99.2 ± 0.2 | 96.4 ± 0.2 | 96.6 ± 0.2 |
| DME | 99.3 ± 0.3 | 98.5 ± 1.0 | 98.8 ± 0.1 | |||
| Drusen | 97.1 ± 0.2 | 97.9 ± 0.2 | 90.1 ± 0.7 | |||
| Normal | 99.0 ± 0.2 | 98.7 ± 0.2 | 97.5 ± 0.4 |
| Method | Class | Accuracy (%) | Precision (%) | Sensitivity (%) | OA (%) | OP (%) |
|---|---|---|---|---|---|---|
| Vgg16 [43] | CNV | 97.5 ± 0.5 | 97.5 ± 1.1 | 91.4 ± 1.4 | 93.5 ± 0.6 | 94.3 ± 0.3 |
| DME | 99.2 ± 0.2 | 96.2 ± 0.3 | 97.6 ± 0.5 | |||
| Drusen | 94.5 ± 0.5 | 91.8 ± 2.1 | 87.5 ± 0.8 | |||
| Normal | 95.8 ± 0.3 | 91.7 ± 1.2 | 97.7 ± 0.5 | |||
| ResNet [44] | CNV | 98.1 ± 0.2 | 97.2 ± 0.6 | 94.1 ± 1.2 | 94.0 ± 0.4 | 95.2 ± 0.4 |
| DME | 99.3 ± 0.2 | 98.4 ± 0.5 | 97.0 ± 0.4 | |||
| Drusen | 95.0 ± 0.5 | 94.0 ± 0.7 | 87.0 ± 1.1 | |||
| Normal | 96.0 ± 0.5 | 91.4 ± 1.4 | 98.5 ± 0.6 | |||
| Transfer learning [20] | CNV | 98.0 ± 0.2 | 96.7 ± 0.3 | 94.1 ± 0.6 | 93.7 ± 0.3 | 94.6 ± 0.2 |
| DME | 99.3 ± 0.3 | 97.3 ± 1.3 | 97.9 ± 0.6 | |||
| Drusen | 94.4 ± 0.3 | 94.4 ± 0.5 | 84.2 ± 1.1 | |||
| Normal | 95.6 ± 0.3 | 90.4 ± 0.9 | 98.6 ± 0.4 | |||
| IFCNN [23] | CNV | 98.1 ± 0.2 | 97.3 ± 0.2 | 94.5 ± 0.5 | 94.9 ± 0.3 | 95.5 ± 0.3 |
| DME | 99.2 ± 0.2 | 97.0 ± 0.5 | 97.4 ± 0.4 | |||
| Drusen | 95.7 ± 0.2 | 94.1 ± 0.2 | 89.7 ± 0.5 | |||
| Normal | 96.7 ± 0.2 | 93.4 ± 0.3 | 98.0 ± 0.2 | |||
| FPN-ResNet [24] | CNV | 98.4 ± 0.2 | 97.0 ± 0.4 | 95.8 ± 0.7 | 94.9 ± 0.4 | 95.3 ± 0.5 |
| DME | 99.2 ± 0.2 | 96.0 ± 1.9 | 98.5 ± 0.3 | |||
| Drusen | 95.7 ± 0.3 | 95.1 ± 0.7 | 88.7 ± 0.8 | |||
| Normal | 96.5 ± 0.3 | 93.2 ± 0.2 | 97.6 ± 0.8 | |||
| MS-DRCN | CNV | 98.7 ± 0.2 | 97.4 ± 0.3 | 96.8 ± 0.4 | 96.5 ± 0.3 | 96.9 ± 0.4 |
| DME | 99.6 ± 0.1 | 98.4 ± 0.2 | 98.7 ± 0.3 | |||
| Drusen | 96.9 ± 0.2 | 96.4 ± 0.6 | 91.9 ± 0.6 | |||
| Normal | 97.0 ± 0.2 | 95.3 ± 0.3 | 98.7 ± 0.3 |
| Method | OA (%) | OP (%) | F1 (%) | Parameter |
|---|---|---|---|---|
| ResNet | 94.0 ± 0.6 | 94.5 ± 0.5 | 94.2 ± 0.2 | 24.5 M |
| ResNet + FFB | 94.9 ± 0.4 | 95.2 ± 0.3 | 95.1 ± 0.4 | 26.7 M |
| ResNet + FFB + MCB | 95.7 ± 0.2 | 95.9 ± 0.2 | 95.8 ± 0.2 | 26.7 M |
| MS-DRCN | 96.4 ± 0.2 | 96.6 ± 0.2 | 96.5 ± 0.2 | 27.3 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Lu, J.; Zhuo, J.; Li, P. Multi-Scale-Denoising Residual Convolutional Network for Retinal Disease Classification Using OCT. Sensors 2024, 24, 150. https://doi.org/10.3390/s24010150
Peng J, Lu J, Zhuo J, Li P. Multi-Scale-Denoising Residual Convolutional Network for Retinal Disease Classification Using OCT. Sensors. 2024; 24(1):150. https://doi.org/10.3390/s24010150
Chicago/Turabian StylePeng, Jinbo, Jinling Lu, Junjie Zhuo, and Pengcheng Li. 2024. "Multi-Scale-Denoising Residual Convolutional Network for Retinal Disease Classification Using OCT" Sensors 24, no. 1: 150. https://doi.org/10.3390/s24010150
APA StylePeng, J., Lu, J., Zhuo, J., & Li, P. (2024). Multi-Scale-Denoising Residual Convolutional Network for Retinal Disease Classification Using OCT. Sensors, 24(1), 150. https://doi.org/10.3390/s24010150