1. Introduction
With the advancement of drone-related technologies, Unmanned Aerial Vehicles (UAVs), distinguished by their lightweight and swift characteristics, have found extensive applications across diverse domains. Object detection, serving as a pivotal component in the execution of UAV missions, is assuming an increasingly significant role, bearing profound implications for research.
Traditional object detection algorithms primarily rely on classical algorithms in machine learning and computer vision, such as feature-based approaches [
1,
2], template matching [
3], and cascade classifiers [
4,
5]. These techniques often depend on manually designed features and traditional machine learning algorithms to identify and locate targets. Traditional object detection algorithms typically enhance detection performance through feature fusion and ensemble learning methods. Consequently, traditional approaches to object detection in UAVs generally utilize algorithms predicated on handcrafted features. Shao [
6] integrated the Histogram of Oriented Gradients (HOGs) with Support Vector Machine (SVM) for object detection in UAVs. However, in practical applications, traditional object detection algorithms based on handcrafted features exhibit lower stability and demand higher requirements for the detection environment. When changes in lighting conditions or object posture occur, the precision of detection markedly diminishes.
As the realm of deep learning continues to rapidly evolve, object detection algorithms based on deep learning have become a research hotspot in UAV applications. Compared with object detection algorithms based on handcrafted features, those predicated on deep learning boast a wider range of applications, more convenient design, and simpler dataset creation, among other advantages. Object detection methodologies based on deep learning can principally be divided into two categories: the first encompasses two-stage object detection algorithms, exemplified by Fast R-CNN [
7] and Faster R-CNN [
8], which initially generate candidate regions and subsequently classify and locate objects. These methodologies are characterized by their high detection precision and low omission rates, but they face challenges related to slower detection speeds and demanding computational requirements, rendering them unsuitable for real-time detection. The second category is represented by single-stage object detection algorithms, such as You Only Look Once (YOLO) [
9] and Single Shot Multibox Detector (SSD) [
10]. These algorithms directly execute the location and category of the target, offering advantages such as swift detection and reduced computational load, albeit at the expense of a relatively lower accuracy. However, in natural scenarios, the substantial distance during drone aerial photography makes it susceptible to environmental factors such as illumination, leading to reduced measurement precision and increased omission rates for small targets. There are two common definitions for small targets. One is common, as defined in the COCO dataset [
11], where small targets have a resolution smaller than 32 pixels × 32 pixels. The other definition, based on relative scale, is determined by the target’s proportion to the image, specifically when the target occupies less than 0.01 of the original image ratio. In this paper, objects with a resolution smaller than 32 × 32 pixels or occupying less than 0.01 of the original image ratio are categorized as small target objects. Therefore, the aforementioned mainstream detection algorithms cannot be directly applied to object detection tasks in drone aerial photography scenes.
At present, numerous scholars have embarked on extensive research in the realm of object detection within drone aerial photography scenarios. Liu et al. [
12] optimized the darknet Resblock in YOLOv3, while incorporating convolutions in the early layers to increase spatial information. However, as time has passed, the darknet framework appears somewhat antiquated. Luo et al. [
13] enhanced detection performance by improving the feature extraction module within the YOLOv5 backbone network and validated the module’s practicality using a substantial dataset. However, their approach exhibited suboptimal results in detecting small objects. Zhou et al. [
14], from a data augmentation perspective, devised two data augmentation strategies, namely background replacement and noise addition, to increase the background diversity of the dataset. Although data augmentation improved the detection of small objects to some extent, it merely increased the proportion of small objects in the data, lacking the integration and utilization of semantic information. Wang et al. [
15] introduced the Ultra-lightweight Subspace Attention Module (ULSAM) into the network structure, with an emphasis on target features and the attenuation of background features. However, this module primarily incorporated spatial information, neglecting channel information, and resulting in suboptimal small object detection performance, especially in densely occluded scenes. Considering the significant scale discrepancies of objects in drone aerial photography images, Liu et al. [
16] proposed a multi-branch parallel feature pyramid network designed to enhance the network’s multi-scale feature extraction capability. However, due to significant disparities in spatial and semantic information among feature maps at different levels, the fusion process easily introduced redundant information and noise, potentially leading to the loss of small object details in different levels. To address the problem of semantic disparities in feature maps at different levels, Wu et al. [
17], based on the use of a multi-branch parallel pyramid network, introduced a feature concatenation fusion module. Nevertheless, this method introduced a significant number of additional parameters, which consequently reduced detection speed.
In summary, although existing drone aerial object detection algorithms have improved detection performance to some extent, there are still some shortcomings:
Inaccurate Localization of Small Objects: The accurate localization of small objects remains a challenge, primarily due to their reduced presence in images in comparison to larger objects. This scarcity poses difficulties in precisely pinpointing their locations.
Loss of Small Object Feature Information: The downsampling operations commonly applied in detection algorithms can lead to the loss of critical feature information associated with small objects. Recovering these details during the subsequent upsampling stages proves to be a complex endeavor.
Susceptibility to Confusion Among Small Object Categories: Small objects are particularly susceptible to occlusion and may share similar categories with other objects in their immediate environment. This similarity can result in confusion and misclassification, further complicating the detection process.
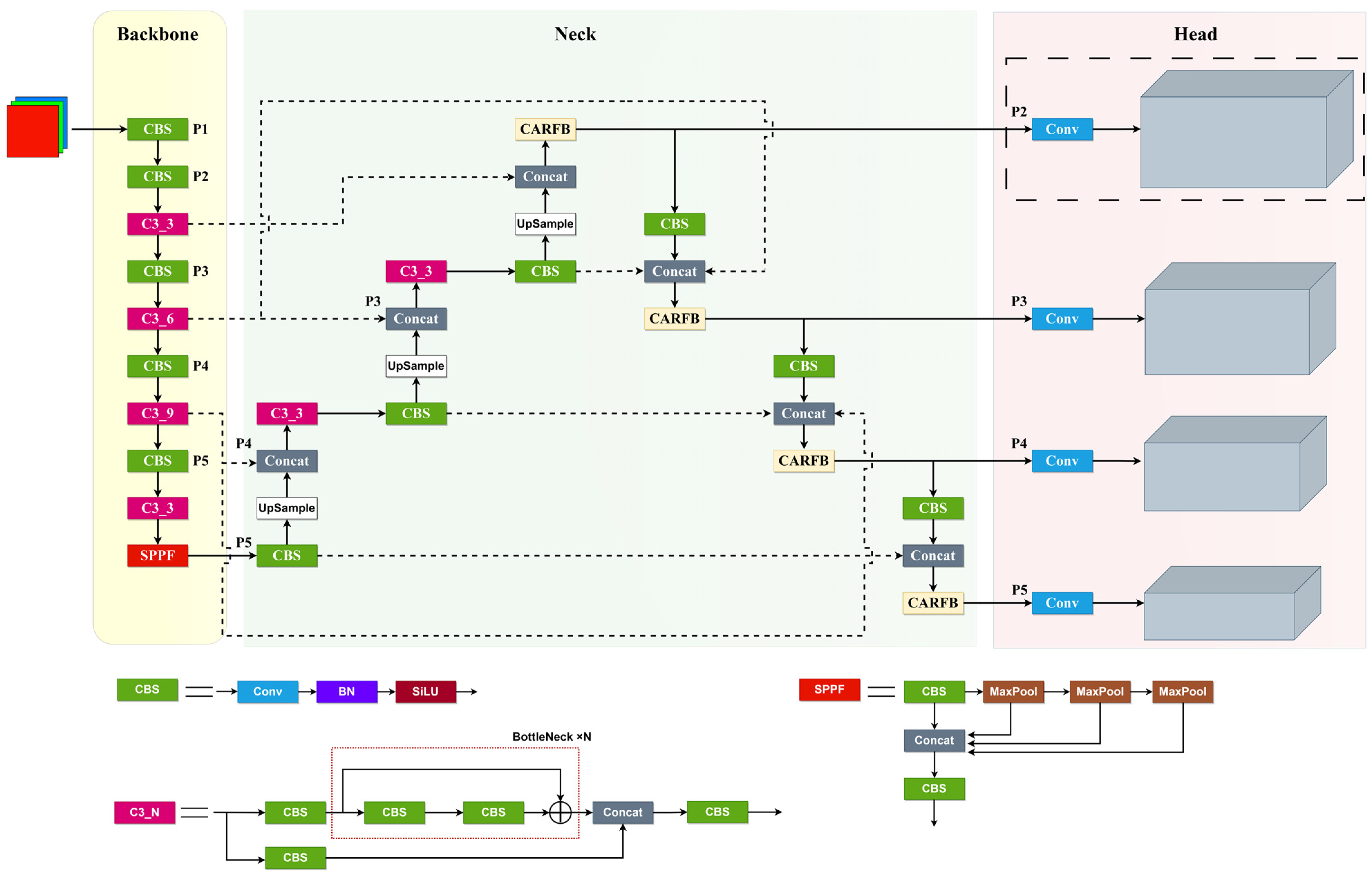
Therefore, to address the challenge of detecting small objects in drone scenarios using existing object detection algorithms, this paper endeavors to redesign the network architecture. This redesign involves the integration of multi-scale features, the introduction of attention mechanisms, and the proposal of an enhanced algorithm called SMT-YOLOv5. The primary contributions of this paper’s algorithm are outlined as follows:
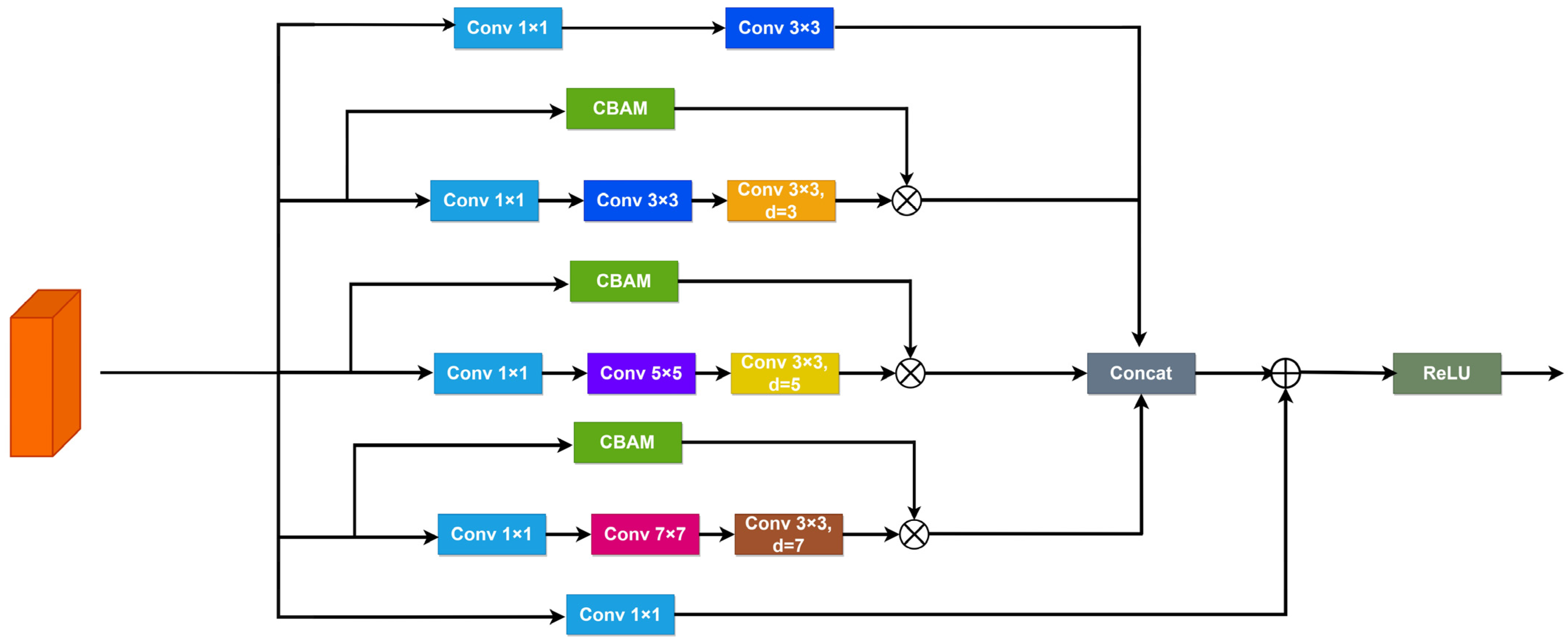
Attention-Based Receptive Field Feature Extraction Module: We introduce an Attention-based receptive field feature extraction module that can be seamlessly integrated into various models. This module efficiently leverages feature information across different scales, capturing a wealth of global contextual cues. Furthermore, it combines spatial and channel attention mechanisms, enhancing the model’s ability to represent crucial information for small objects effectively.
Detection Layer with Enhanced Small Target Feature Map: We introduce a detection layer featuring a small target feature map sampled at a 4× scale, significantly enhancing our detection capabilities for small objects. Additionally, we incorporate a multi-level feature pyramid structure that facilitates the comprehensive fusion of both local and global information. This fusion markedly improves the accuracy of target detection across various scales. The effective combination of deep and shallow information provides valuable assistance to the network in detecting small objects.
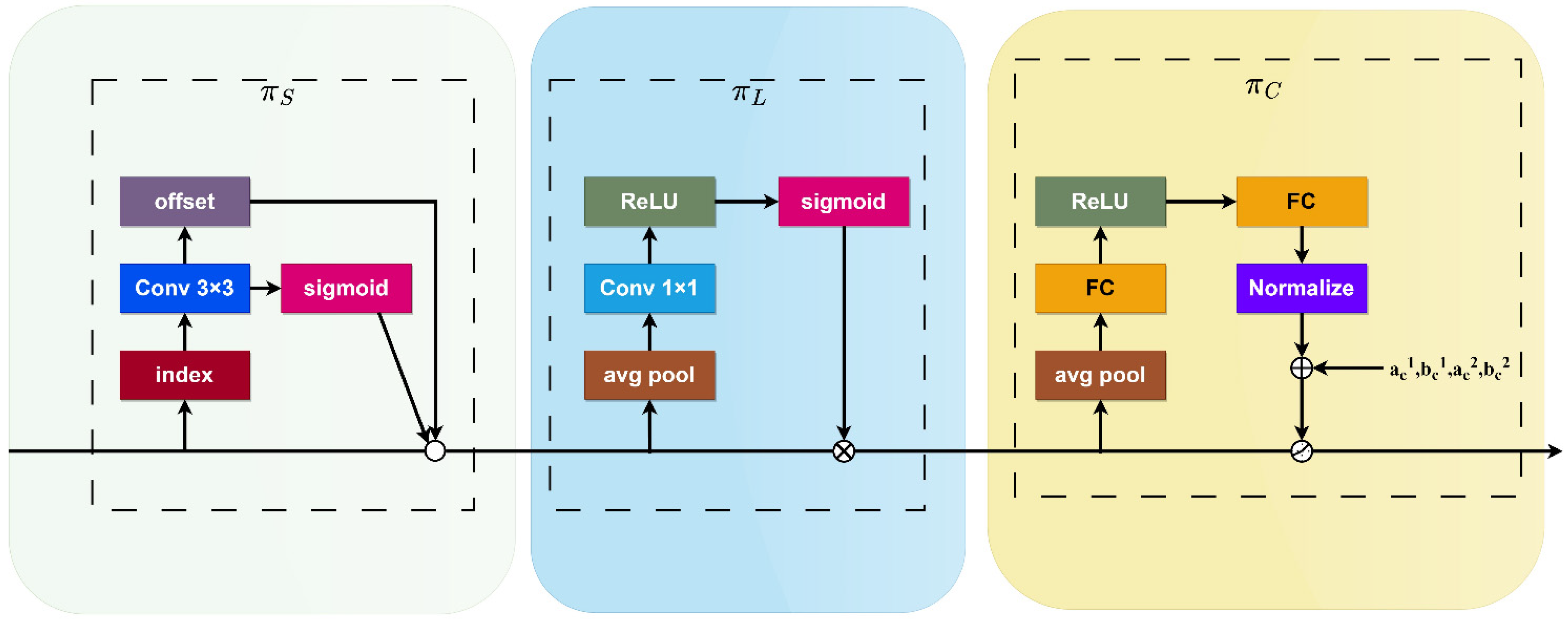
Dynamic Head: We introduce the DyHead, which cohesively integrates various self-attention mechanisms within the output channels dedicated to scale awareness, spatial awareness, and task awareness. This integration is aimed at enhancing the network’s ability to detect small targets and, consequently, improving the precision of target detection.
The remainder of this paper is structured as follows:
Section 2. describes the improved method used in this paper,
Section 3. demonstrates the effectiveness of the method in detail through experiments, and
Section 4. concludes the paper.
4. Conclusions
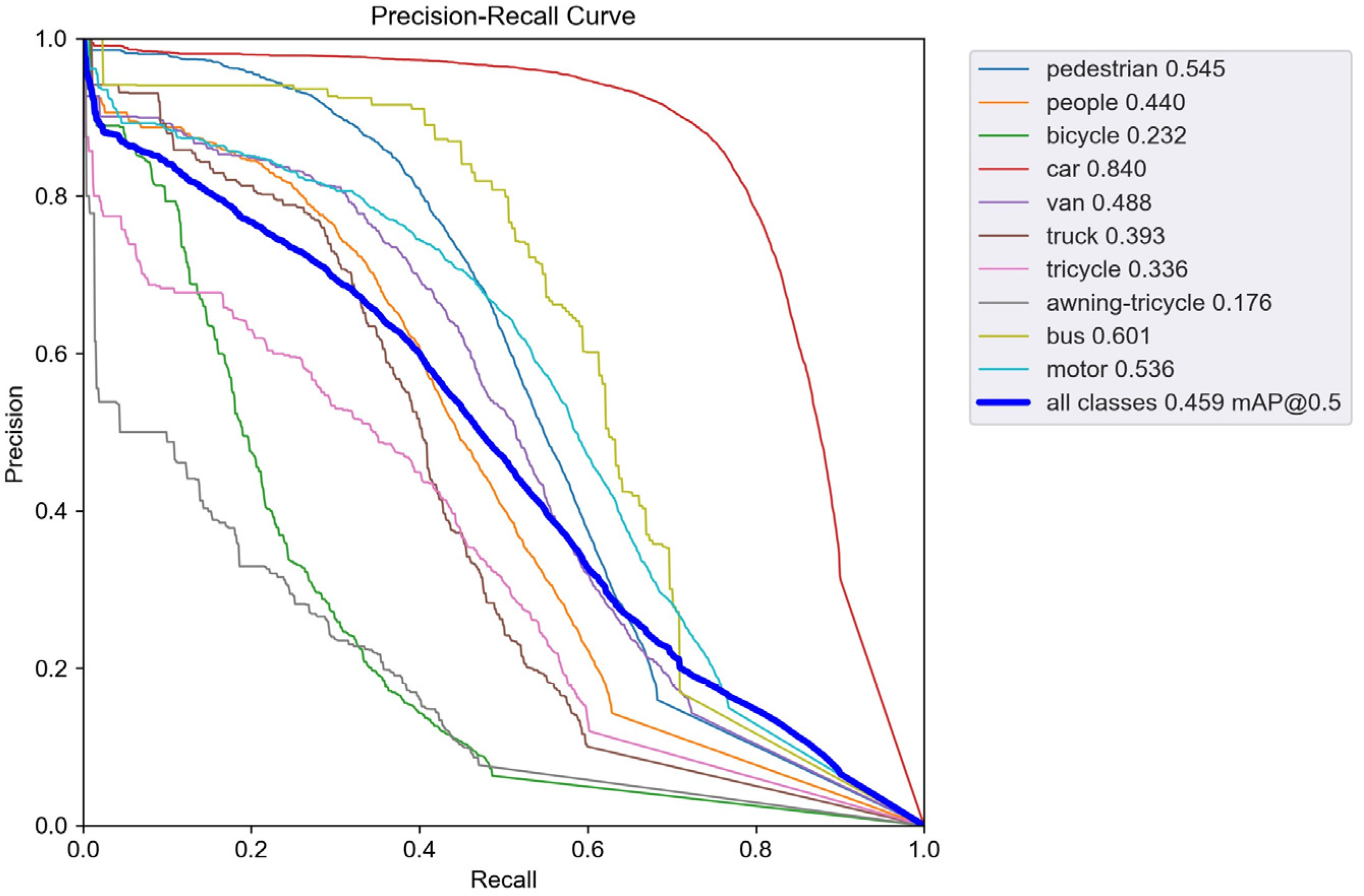
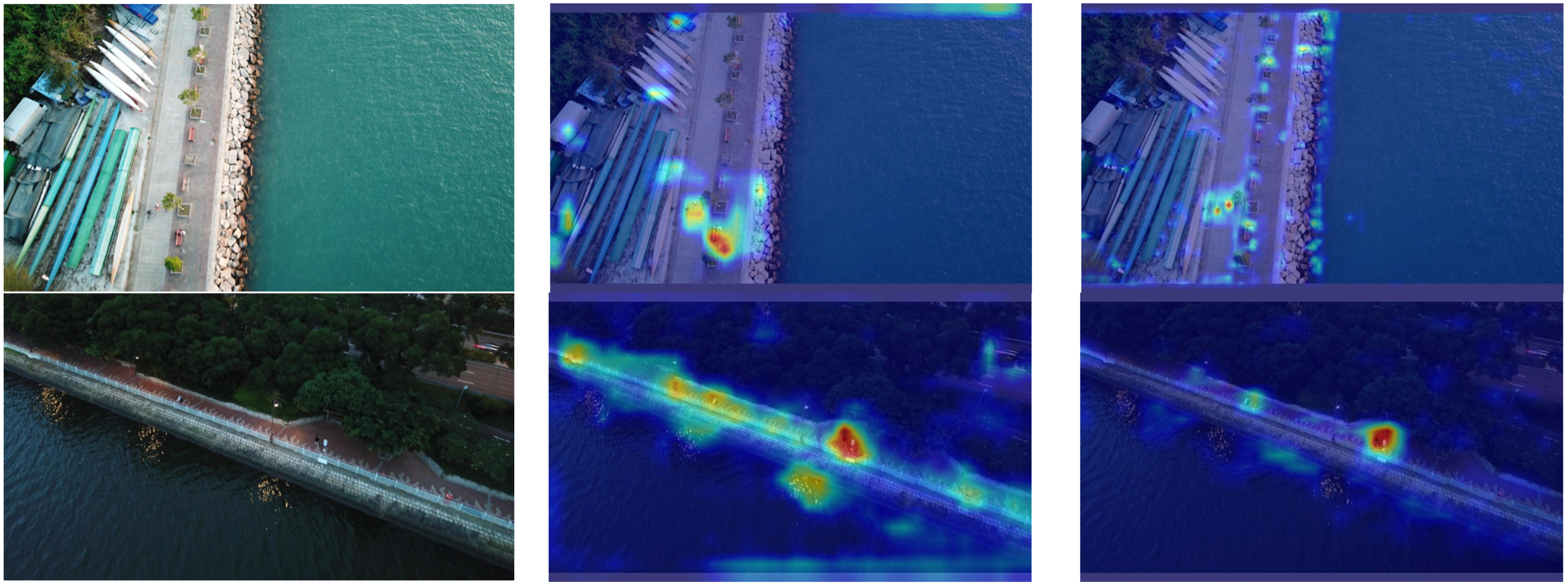
Addressing the deficiencies of existing object detectors in small object detection, such as false detection and omission, this study proposes an enhanced detection model, SMT-YOLOv5, predicated on YOLOv5. Firstly, to address the difficulty of detecting small objects in drone imagery, we add a detection layer in the feature fusion network to enhance the ability to capture small objects, while employing a weighted bi-directional feature pyramid network capable of effectively integrating information from different receptive fields. This approach resolves the lack of sufficient high-level semantic information and effective fusion between multi-scale receptive fields, thereby improving the detection accuracy of small objects. Subsequently, a receptive field feature extraction module, CARFB, based on the attention mechanism, is introduced to expand the receptive field of the feature map and reduce feature information loss. Building upon this, a dynamic object detection head, DyHead, is incorporated to enhance perception in three dimensions, space, scale, and task, addressing the issue of objects presenting drastically different shapes and positions under different natural viewing angles, and improving the detection accuracy of occluded high-density small objects. Finally, experimental validation on the VisDrone2021 dataset attests to the remarkable enhancement achieved by SMT-YOLOv5 in the realm of target detection accuracy. Each refinement strategy augments mean precision. Ultimately, relative to the original methodology, SMT-YOLOv5s exhibits an elevation of 12.4 percentage points in mean precision. Furthermore, in the detection of large, medium, and small targets, improvements of 6.9%, 9.5%, and 7.7%, respectively, are observed compared to the original approach. Similarly, the application of identical enhancement strategies to the computationally less intricate YOLOv8n yields SMT-YOLOv8n, presenting a complexity akin to that of SMT-YOLOv5s. The results manifest that, in comparison to SMT-YOLOv8n, SMT-YOLOv5s demonstrates a 2.5 percentage point increase in mean precision. Additionally, in comparative experiments with alternative enhancement methodologies such as KPE-YOLOv5s, UN-YOLOv5s, and FE-YOLOv5s, our proposed approach showcases increments of 6.7 percentage points, 5.4 percentage points, and 8.9 percentage points in mAP@0.5, respectively, affirming the efficacy of our refinement strategies. Naturally, what brings us delight is that the same approach yields commendable results on YOLOv8n, providing a guiding direction for our subsequent enhancements.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}