
Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning



Abstract
1. Introduction
- It requires a single image and a single network. A single network is proposed to transform a single image into four phase-shifted fringe images and an unwrapped coarse phase map;
- It preserves the accuracy advantage of the classic FPP-based method while eliminating the disadvantage of slow speed originated from capturing multiple phase-shifted fringe patterns;
- It uses a concise network. Only a single network is used for phase determination instead of multiple sub-networks;
- It takes a simple image. A single grayscale image is utilized for the training network rather than using a color composite image or an additional reference image;
- It yields higher accuracy than the image-to-depth approaches.
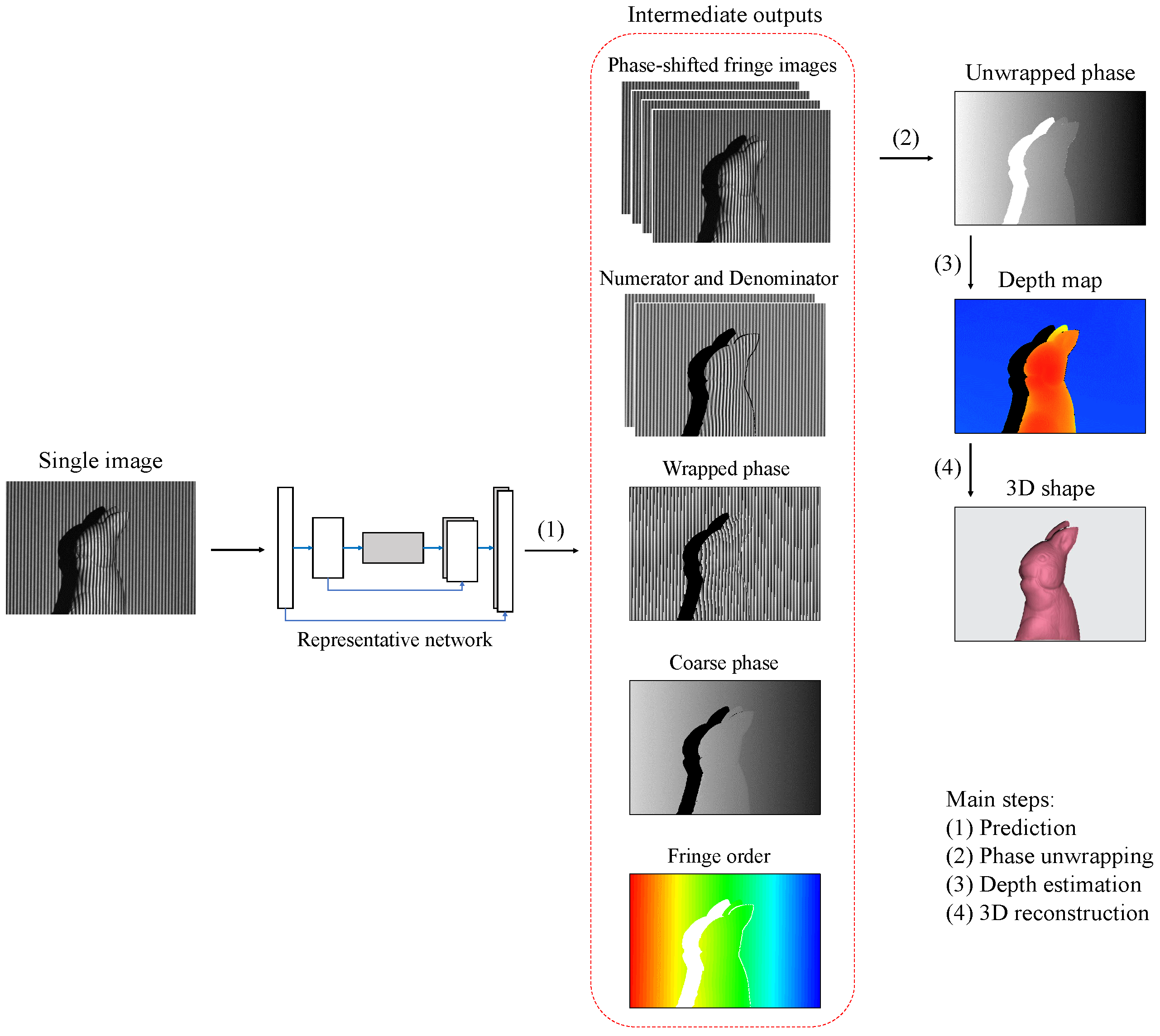
2. Methodology
2.1. Fringe Projection Profilometry Technique for 3D Shape Reconstruction
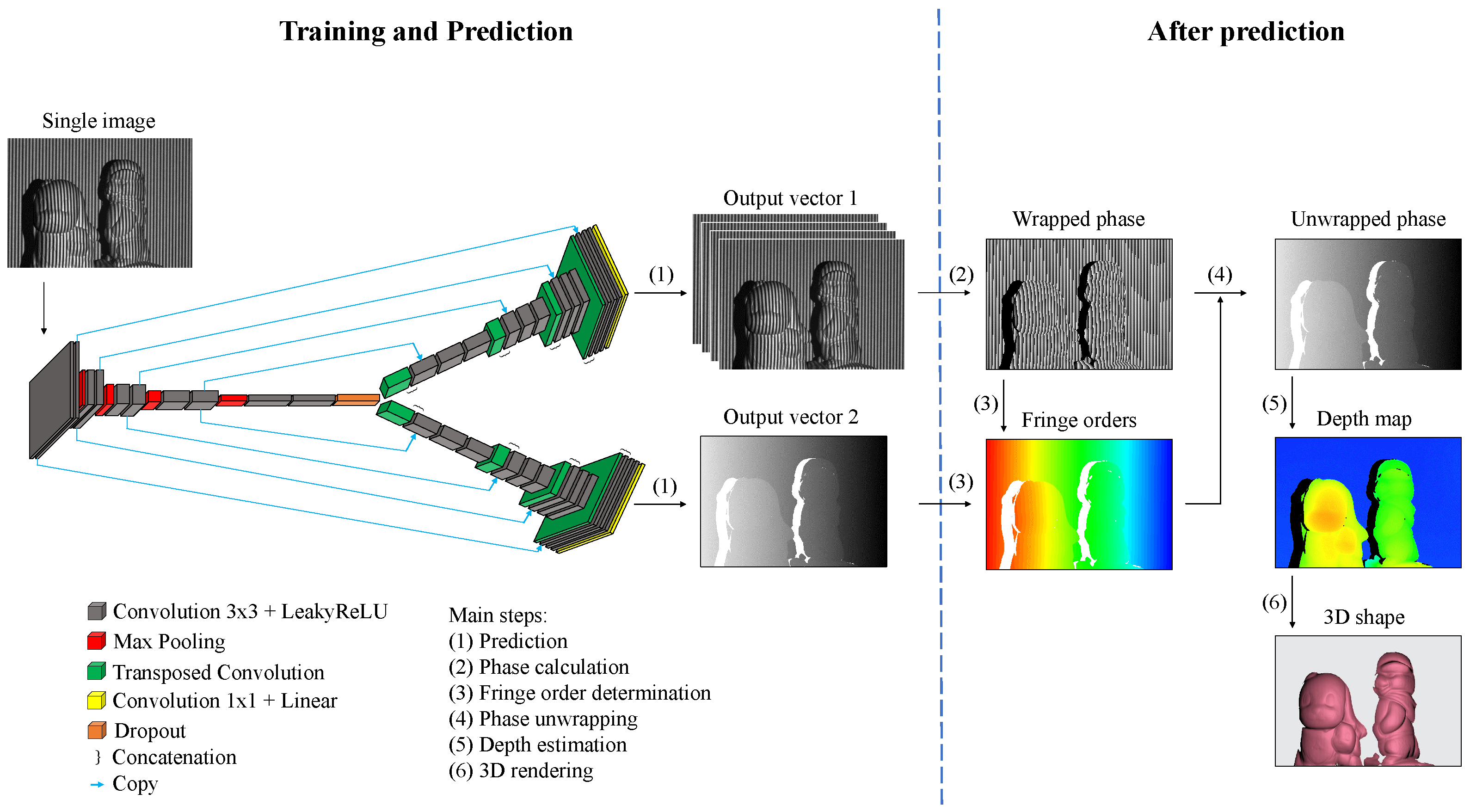
2.2. Single-Input Dual-Output Network for Fringe Image Transformation and Phase Retrieval
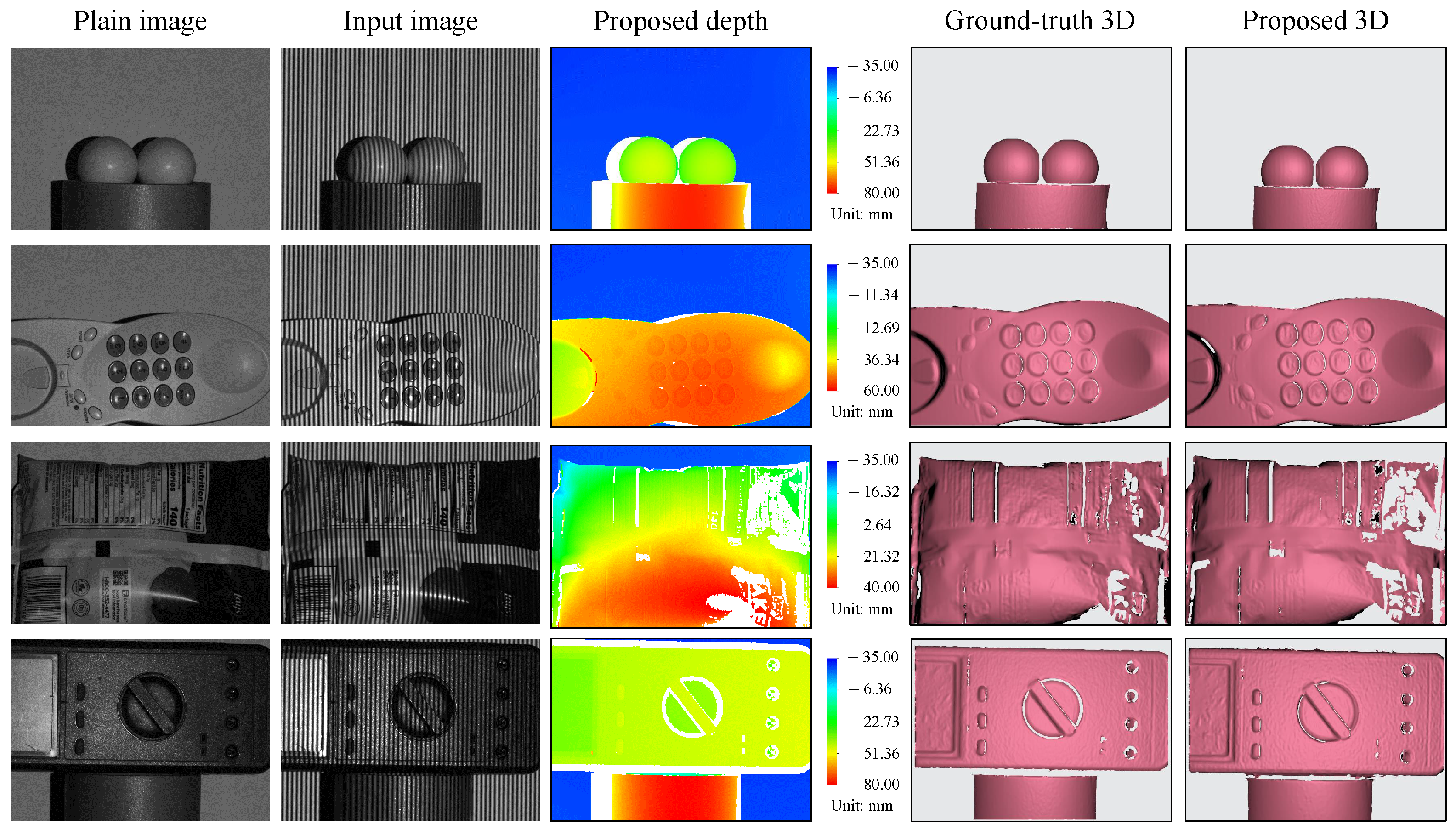
3. Experiments and Assessments
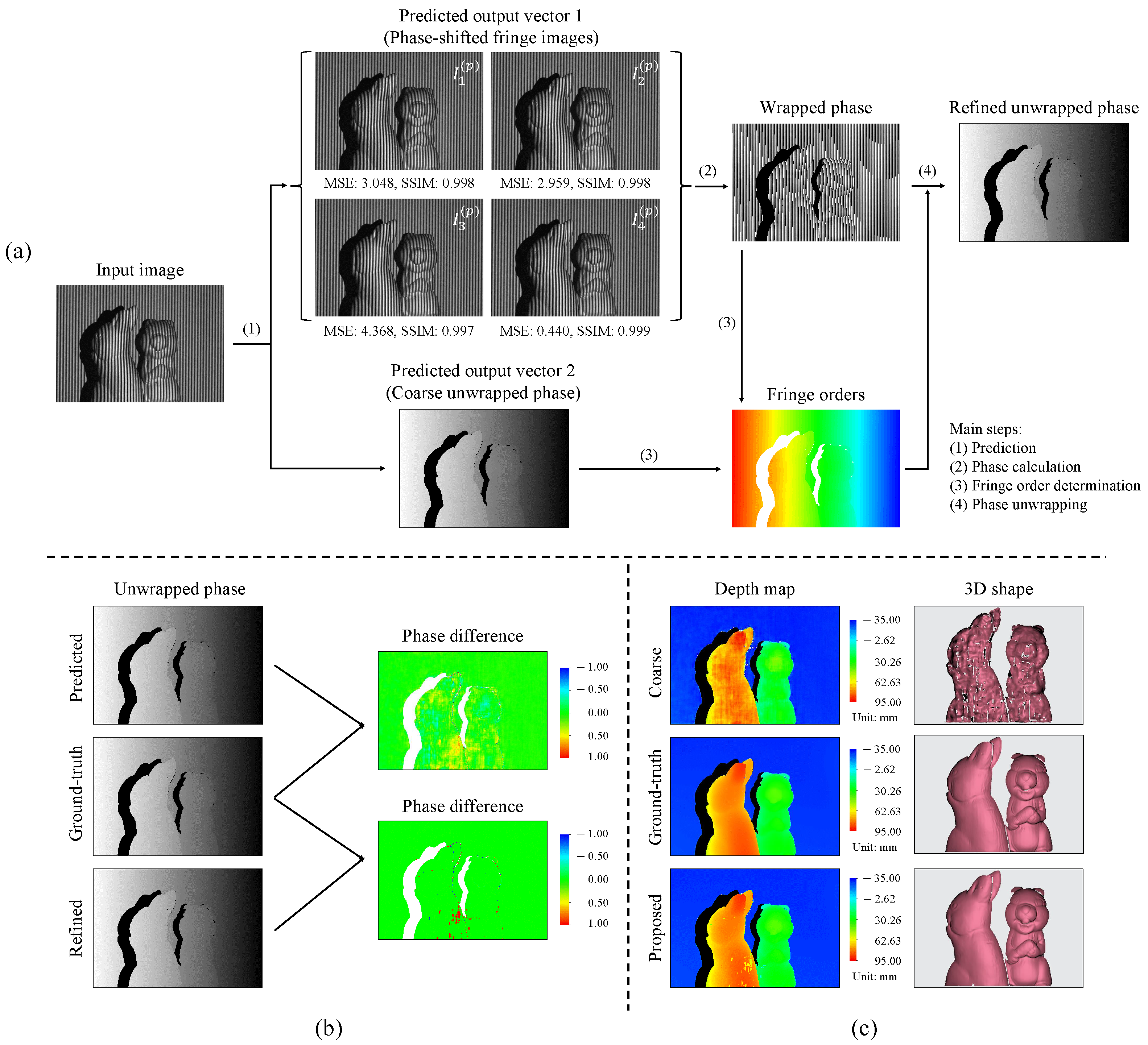
3.1. Can the Predicted Unwrapped Phase Map Be Used Directly for 3D Reconstruction?
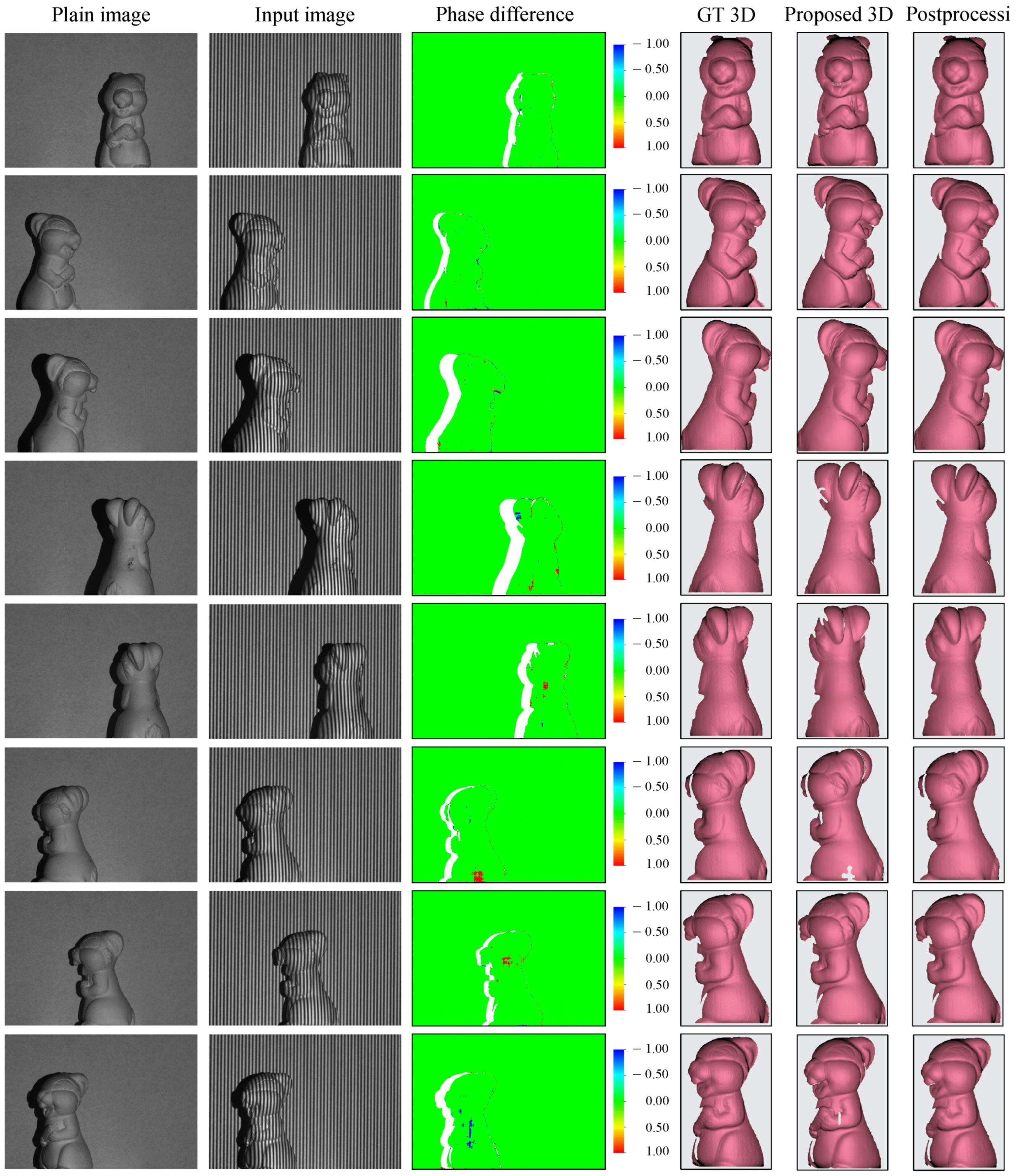
3.2. Full-Surface 360 3D Reconstruction of a Single Object
3.3. Three-Dimensional Reconstruction of Multiple Objects
3.4. Three-Dimensional Reconstruction of Objects with Varied Colors
3.5. Accuracy Comparison of the Proposed 3D Reconstruction Technique with Other Fringe-to-Phase and Fringe-to-Depth Methods
- Absolute relative error (rel): ;
- Root-mean-square error (rms): ;
- Average error (log): ;
- Root-mean-square log error (rms log):;
- Threshold accuracy:.
4. Discussions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Su, X.; Zhang, Q. Dynamic 3-D shape measurement method: A review. Opt. Lasers Eng. 2010, 48, 191–204. [Google Scholar] [CrossRef]
- Bruno, F.; Bruno, S.; Sensi, G.; Luchi, M.; Mancuso, S.; Muzzupappa, M. From 3D reconstruction to virtual reality: A complete methodology for digital archaeological exhibition. J. Cult. Herit. 2010, 11, 42–49. [Google Scholar] [CrossRef]
- Huang, S.; Xu, K.; Li, M.; Wu, M. Improved Visual Inspection through 3D Image Reconstruction of Defects Based on the Photometric Stereo Technique. Sensors 2019, 19, 4970. [Google Scholar] [CrossRef] [PubMed]
- Bennani, H.; McCane, B.; Corwall, J. Three-dimensional reconstruction of In Vivo human lumbar spine from biplanar radiographs. Comput. Med. Imaging Graph. 2022, 96, 102011. [Google Scholar] [CrossRef] [PubMed]
- Do, P.; Nguyen, Q. A Review of Stereo-Photogrammetry Method for 3-D Reconstruction in Computer Vision. In Proceedings of the 19th International Symposium on Communications and Information Technologies, Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 138–143. [Google Scholar] [CrossRef]
- Blais, F. Review of 20 years of range sensor development. J. Electron. Imaging 2004, 13, 231–243. [Google Scholar] [CrossRef]
- Chen, F.; Brown, G.; Song, M. Overview of threedimensional shape measurement using optical methods. Opt. Eng. 2000, 39, 10–22. [Google Scholar] [CrossRef]
- Bianco, G.; Gallo, A.; Bruno, F.; Muzzuppa, M. A Comparative Analysis between Active and Passive Techniques for Underwater 3D Reconstruction of Close-Range Objects. Sensors 2013, 13, 11007–11031. [Google Scholar] [CrossRef]
- Khilar, R.; Chitrakala, S.; Selvamparvathy, S. 3D image reconstruction: Techniques, applications and challenges. In Proceedings of the 2013 International Conference on Optical Imaging Sensor and Security, Coimbatore, India, 2–3 July 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, S. High-speed 3D shape measurement with structured light methods: A review. Opt. Lasers Eng. 2018, 106, 119–131. [Google Scholar] [CrossRef]
- Nguyen, H.; Ly, K.; Nguyen, T.; Wang, Y.; Wang, Z. MIMONet: Structured-light 3D shape reconstruction by a multi-input multi-output network. Appl. Opt. 2021, 60, 5134–5144. [Google Scholar] [CrossRef]
- Prusak, A.; Melnychuk, O.; Roth, H.; Schiller, I.; Koch, R. Pose estimation and map building with a Time-Of-Flight-camera for robot navigation. Int. J. Intell. Syst. Technol. Appl. 2008, 5, 355–364. [Google Scholar] [CrossRef]
- Kolb, A.; Barth, E.; Koch, R.; Larsen, R. Time-of-Flight Sensors in Computer Graphics. In Proceedings of the Eurographics 2009—State of the Art Reports, Munich, Germany, 30 March–3 April 2009. [Google Scholar] [CrossRef]
- Kahn, S.; Wuest, H.; Fellner, D. Time-of-flight based Scene Reconstruction with a Mesh Processing Tool for Model based Camera Tracking. In Proceedings of the International Conference on Computer Vision Theory and Applications—Volume 1: VISAPP, Angers, France, 17–21 May 2010; pp. 302–309. [Google Scholar] [CrossRef]
- Kim, D.; Lee, S. Advances in 3D Camera: Time-of-Flight vs. Active Triangulation. In Proceedings of the Intelligent Autonomous Systems 12. Advances in Intelligent Systems and Computing, Jeju Island, Republic of Korea, 26–29 June 2012; Volume 193, pp. 301–309. [Google Scholar] [CrossRef]
- Geng, J. Structured-light 3D surface imaging: A tutorial. Adv. Opt. Photonics 2011, 3, 128–160. [Google Scholar] [CrossRef]
- Jeught, S.; Dirckx, J. Real-time structured light profilometry: A review. Sensors 2016, 87, 18–31. [Google Scholar] [CrossRef]
- Fernandez, S.; Salvi, J.; Pribanic, T. Absolute phase mapping for one-shot dense pattern projection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 128–144. [Google Scholar] [CrossRef]
- Moreno, D.; Taubin, G. Simple, Accurate, and Robust Projector-Camera Calibration. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 464–471. [Google Scholar] [CrossRef]
- Jensen, J.; Hannemose, M.; Bærentzen, A.; Wilm, J.; Frisvad, J.; Dahl, A. Surface Reconstruction from Structured Light Images Using Differentiable Rendering. Sensors 2021, 21, 1068. [Google Scholar] [CrossRef] [PubMed]
- Tran, V.; Lin, H.Y. A Structured Light RGB-D Camera System for Accurate Depth Measurement. Int. J. Opt. 2018, 2018, 8659847. [Google Scholar] [CrossRef]
- Diba, A.; Sharma, V.; Pazandeh, A.; Pirsiavash, H.; Gool, L. Weakly Supervised Cascaded Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5131–5139. [Google Scholar] [CrossRef]
- Doulamis, N. Adaptable deep learning structures for object labeling/tracking under dynamic visual environments. Multimed. Tools. Appl. 2018, 77, 9651–9689. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar] [CrossRef]
- Lin, L.; Wang, K.; Zuo, W.; Wang, M.; Luo, J.; Zhang, L. A Deep Structured Model with Radius–Margin Bound for 3D Human Activity Recognition. Int. J. Comput. Vis. 2016, 118, 256–273. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 13. [Google Scholar] [CrossRef]
- Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Velasco-Hernandez, G.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the 2019 Computer Vision Conference (CVC), Las Vegas, NV, USA, 2–3 May 2019; pp. 128–144. [Google Scholar] [CrossRef]
- Han, X.F.; Laga, H.; Bennamoun, M. Image-Based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1578–1604. [Google Scholar] [CrossRef]
- Fu, K.; Peng, J.; He, Q.; Zhang, H. Single image 3D object reconstruction based on deep learning: A review. Multimed. Tools Appl. 2020, 80, 463–498. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Z.; Liu, T.; Peng, B.; Li, X. RealPoint3D: An Efficient Generation Network for 3D Object Reconstruction From a Single Image. IEEE Access 2019, 7, 57539–75749. [Google Scholar] [CrossRef]
- Jeught, S.; Dirckx, J. Deep neural networks for single shot structured light profilometry. Opt. Express 2019, 27, 17091–17101. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Wang, Y. Three-dimensional measurement of precise shaft parts based on line structured light and deep learning. Measurement 2022, 191, 110837. [Google Scholar] [CrossRef]
- Guan, J.; Li, J.; Yang, X.; Chen, X.; Xi, J. Defect detection method for specular surfaces based on deflectometry and deep learning. Opt. Eng. 2022, 61, 061407. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Q.; Zhong, L.; Lu, X. Hybrid-net: A two-to-one deep learning framework for three-wavelength phase-shifting interferometry. Opt. Express 2021, 29, 34656–34670. [Google Scholar] [CrossRef]
- Yan, K.; Yu, Y.; Huang, C.; Sui, L.; Qian, K.; Asundi, A. Fringe pattern denoising based on deep learning. Opt. Commun. 2019, 437, 148–152. [Google Scholar] [CrossRef]
- Nguyen, H.; Tran, T.; Wang, Y.; Wang, Z. Three-dimensional Shape Reconstruction from Single-shot Speckle Image Using Deep Convolutional Neural Networks. Opt. Lasers Eng. 2021, 143, 106639. [Google Scholar] [CrossRef]
- Zhu, X.; Han, Z.; Song, L.; Wang, H.; Wu, Z. Wavelet based deep learning for depth estimation from single fringe pattern of fringe projection profilometry. Optoelectron. Lett. 2022, 18, 699–704. [Google Scholar] [CrossRef]
- Wang, F.; Wang, C.; Guan, Q. Single-shot fringe projection profilometry based on deep learning and computer graphics. Opt. Express 2021, 29, 8024–8040. [Google Scholar] [CrossRef]
- Jia, T.; Liu, Y.; Yuan, X.; Li, W.; Chen, D.; Zhang, Y. Depth measurement based on a convolutional neural network and structured light. Meas. Sci. Technol. 2022, 33, 025202. [Google Scholar] [CrossRef]
- Machineni, R.; Spoorthi, G.; Vengala, K.; Gorthi, S.; Gorthi, R. End-to-end deep learning-based fringe projection framework for 3D profiling of objects. Comput. Vis. Image Underst. 2020, 199, 103023. [Google Scholar] [CrossRef]
- Fan, S.; Liu, S.; Zhang, X.; Huang, H.; Liu, W.; Jin, P. Unsupervised deep learning for 3D reconstruction with dual-frequency fringe projection profilometry. Opt. Express 2021, 29, 32547–32567. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lu, D.; Qiu, R.; Tao, J. 3D reconstruction from structured-light profilometry with dual-path hybrid network. EURASIP J. Adv. Signal Process. 2022, 2022, 14. [Google Scholar] [CrossRef]
- Nguyen, A.; Sun, B.; Li, C.; Wang, Z. Different structured-light patterns in single-shot 2D-to-3D image conversion using deep learning. Appl. Opt. 2022, 61, 10105–10115. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Wang, Y.; Wang, Z. Single-Shot 3D Shape Reconstruction Using Structured Light and Deep Convolutional Neural Networks. Sensors 2020, 20, 3718. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar] [CrossRef]
- Wang, L.; Lu, D.; Tao, J.; Qiu, R. Single-shot structured light projection profilometry with SwinConvUNet. Opt. Eng. 2022, 61, 114101. [Google Scholar] [CrossRef]
- Nguyen, H.; Nicole, D.; Li, H.; Wang, Y.; Wang, Z. Real-time 3D shape measurement using 3LCD projection and deep machine learning. Apt. Opt. 2019, 58, 7100–7109. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Chen, X.; Huang, R.; Bai, L.; Zheng, D.; Han, J. Untrained deep learning-based phase retrieval for fringe projection profilometry. Opt. Lasers Eng. 2023, 164, 107483. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Ji, Y.; Qian, J.; Che, Y.; Zuo, C.; Chen, Q.; Feng, S. Deep Learning-Based 3D Measurements with Near-Infrared Fringe Projection. Sensors 2022, 22, 6469. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, Y.; Wang, N.; Luo, L.; Peng, J. Single-shot 3D shape reconstruction for complex surface objects with colour texture based on deep learning. J. Mod. Opt. 2022, 69, 941–956. [Google Scholar] [CrossRef]
- Yu, H.; Chen, X.; Zhang, Z.; Zuo, C.; Zhang, Y.; Zheng, D.; Han, J. Dynamic 3-D measurement based on fringe-to-fringe transformation using deep learning. Opt. Express 2020, 28, 9405–9418. [Google Scholar] [CrossRef]
- Yang, Y.; Hou, Q.; Li, Y.; Cai, Z.; Liu, X.; Xi, J.; Peng, X. Phase error compensation based on Tree-Net using deep learning. Opt. Lasers Eng. 2021, 143, 106628. [Google Scholar] [CrossRef]
- Nguyen, H.; Wang, Z. Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network. Photonics 2021, 8, 459. [Google Scholar] [CrossRef]
- Nguyen, A.; Ly, K.; Li, C.; Wang, Z. Single-shot 3D shape acquisition using a learning-based structured-light technique. Appl. Opt. 2022, 61, 8589–8599. [Google Scholar] [CrossRef]
- Feng, S.; Chen, Q.; Gu, G.; Tao, T.; Zhang, L.; Hu, Y.; Yin, W.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photonics 2019, 1, 025001. [Google Scholar] [CrossRef]
- Li, Y.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Composite fringe projection deep learning profilometry for single-shot absolute 3D shape measurement. Opt. Express 2022, 30, 3424–3442. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Lin, S.; Lin, J.; Jiang, K. Single-shot high-precision 3D reconstruction with color fringe projection profilometry based BP neural network. Opt. Commun. 2022, 517, 128323. [Google Scholar] [CrossRef]
- Nguyen, H.; Novak, E.; Wang, Z. Accurate 3D reconstruction via fringe-to-phase network. Measurement 2022, 190, 110663. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, J.; Shao, J.; Song, B.; Yao, B.; Liang, R. Deep Convolutional Neural Network Phase Unwrapping for Fringe Projection 3D Imaging. Sensors 2020, 20, 3691. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Zhu, X.; Wang, H.; Song, L.; Guo, Q. Label enhanced and patch based deep learning for phase retrieval from single frame fringe pattern in fringe projection 3D measurement. Opt. Express 2019, 27, 28929–28943. [Google Scholar] [CrossRef]
- Yin, W.; Chen, Q.; Feng, S.; Tao, T.; Huang, L.; Trusiak, M.; Asundi, A.; Zuo, C. Temporal phase unwrapping using deep learning. Sci. Rep. 2019, 9, 20175. [Google Scholar] [CrossRef]
- Qian, J.; Feng, S.; Tao, T.; Han, J.; Chen, Q.; Zuo, C. Single-shot absolute 3D shape measurement with deep-learning-based color fringe projection profilometry. Opt. Lett. 2020, 45, 1842–1845. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Han, B.; Bai, L.; Zheng, D.; Han, J. Untrained deep learning-based fringe projection profilometry. APL Photonics 2022, 7, 016102. [Google Scholar] [CrossRef]
- Yao, P.; Gai, S.; Chen, Y.; Chen, W.; Da, F. A multi-code 3D measurement technique based on deep learning. Opt. Lasers Eng. 2021, 143, 106623. [Google Scholar] [CrossRef]
- Li, W.; Yu, J.; Gai, S.; Da, F. Absolute phase retrieval for a single-shot fringe projection profilometry based on deep learning. Opt. Eng. 2021, 60, 064104. [Google Scholar] [CrossRef]
- Nguyen, A.; Rees, O.; Wang, Z. Learning-based 3D imaging from single structured-light image. Graph. Models 2023, 126, 101171. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, D.; Wang, Z.; Kieu, H.; Le, M. Real-time, high-accuracy 3D imaging and shape measurement. Appl. Opt. 2015, 54, A9–A17. [Google Scholar] [CrossRef]
- Nguyen, H.; Liang, J.; Wang, Y.; Wang, Z. Accuracy assessment of fringe projection profilometry and digital image correlation techniques for three-dimensional shape measurements. J. Phys. Photonics 2021, 3, 014004. [Google Scholar] [CrossRef]
- Le, H.; Nguyen, H.; Wang, Z.; Opfermann, J.; Leonard, S.; Krieger, A.; Kang, J. Demonstration of a laparoscopic structured-illumination three-dimensional imaging system for guiding reconstructive bowel anastomosis. J. Biomed. Opt. 2018, 23, 056009. [Google Scholar] [CrossRef]
- Du, H.; Wang, Z. Three-dimensional shape measurement with an arbitrarily arranged fringe projection profilometry system. Opt. Lett. 2007, 32, 2438–2440. [Google Scholar] [CrossRef]
- Vo, M.; Wang, Z.; Pan, B.; Pan, T. Hyper-accurate flexible calibration technique for fringe-projection-based three-dimensional imaging. Opt. Express 2012, 20, 16926–16941. [Google Scholar] [CrossRef]
- Single-Input Dual-Output 3D Shape Reconstruction. Available online: https://figshare.com/s/c09f17ba357d040331e4 (accessed on 13 April 2023).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Keras. ExponentialDecay. Available online: https://keras.io/api/optimizers/learning_rate_schedules/ (accessed on 13 April 2023).
- Nguyen, H.; Ly, K.L.; Tran, T.; Wang, Y.; Wang, Z. hNet: Single-shot 3D shape reconstruction using structured light and h-shaped global guidance network. Results Opt. 2021, 4, 100104. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Error (Lower Is Better) | Accuracy (Higher Is Better) | ||||||
|---|---|---|---|---|---|---|---|---|
| rel | rms | log | rms log | |||||
| Proposed method | 0.004 | 0.385 | 0.003 | 0.050 | 99.5% | 99.8% | 99.9% | |
| Fringe-to-ND | 0.005 | 0.392 | 0.003 | 0.049 | 99.5% | 99.8% | 99.9% | |
| Fringe-to-WP | 0.007 | 0.610 | 0.004 | 0.061 | 99.2% | 99.7% | 99.8% | |
| Fringe-to-depth | 0.023 | 0.916 | 0.015 | 0.119 | 97.7% | 99.1% | 99.5% | |
| Speckle-to-depth | 0.027 | 0.923 | 0.016 | 0.120 | 98.0% | 99.2% | 99.6% | |
| Plain-to-depth | 0.031 | 1.104 | 0.020 | 0.134 | 96.8% | 98.9% | 99.4% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, A.-H.; Ly, K.L.; Lam, V.K.; Wang, Z. Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning. Sensors 2023, 23, 4209. https://doi.org/10.3390/s23094209
Nguyen A-H, Ly KL, Lam VK, Wang Z. Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning. Sensors. 2023; 23(9):4209. https://doi.org/10.3390/s23094209
Chicago/Turabian StyleNguyen, Andrew-Hieu, Khanh L. Ly, Van Khanh Lam, and Zhaoyang Wang. 2023. "Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning" Sensors 23, no. 9: 4209. https://doi.org/10.3390/s23094209
APA StyleNguyen, A.-H., Ly, K. L., Lam, V. K., & Wang, Z. (2023). Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning. Sensors, 23(9), 4209. https://doi.org/10.3390/s23094209