
Regularization for Unsupervised Learning of Optical Flow


Abstract
1. Introduction
- We propose a novel and effective teacher–student unsupervised learning strategy for optical flow and scene flow estimation, where the teacher and student networks share the same weights but differ in the use of a content-aware regularization module.
- We experimentally show that a PWC-Net model trained with our unsupervised framework outperforms all other unsupervised PWC-Net variants on standard benchmarks. The multi-frame version surpasses supervised PWC-Net with lower computational costs and using a smaller model.
- A PWC-Net model trained with our method shows superior cross-dataset generalization compared to supervised PWC-Net and unsupervised ARFlow.
2. Related Work
2.1. Supervised Optical Flow Methods
2.2. Unsupervised Optical Flow Methods
2.3. Regularization in CNNs
2.4. Teaching Strategy
3. Methods
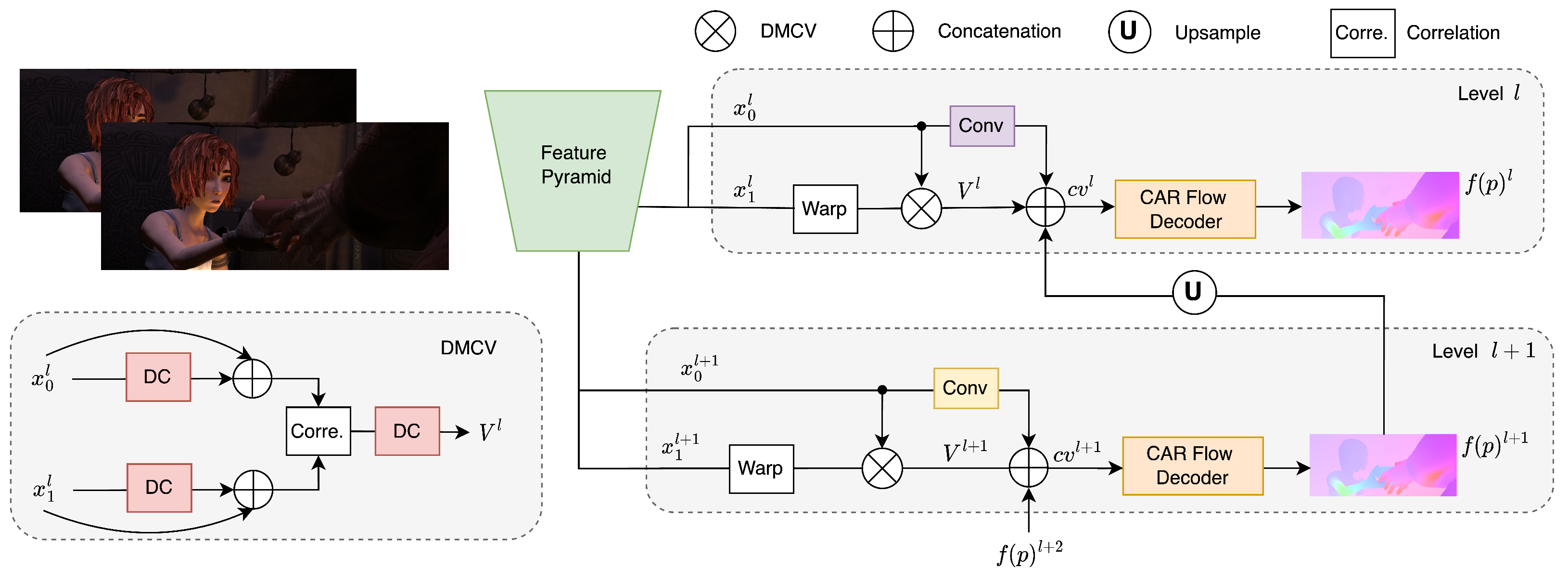
3.1. Network Structure
3.2. Content-Aware Regularization Module
3.3. Shared-Weight Teacher–Student Strategy
3.4. Regularization and Unsupervised Loss
3.4.1. Content-Aware Regularization
3.4.2. Level Dropout as Regularization
3.4.3. Overall Unsupervised Loss
4. Experiments
4.1. Implementation Details and the Use of Datasets
4.2. Regularization Analysis
4.3. Comparison to the State-of-the-Art
4.4. Ablation Study
4.5. Cross-Dataset Generalization
4.6. CAR in Unsupervised Scene Flow Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Comparison of the Regularization Rate

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rate | Sintel Clean | Sintel Final | KITTI-12 | KITTI-15 | |
|---|---|---|---|---|---|
| CAR | 0.2 | 2.31 | 3.24 | 1.24 | 2.42 |
| 0.5 | 2.23 | 3.09 | 1.17 | 2.24 | |
| 0.7 | 2.25 | 3.04 | 1.16 | 2.28 | |
| 0.9 | 2.29 | 3.13 | 1.21 | 2.37 | |
| LDR | 0.2 | 2.33 | 3.17 | 1.26 | 2.32 |
| 0.5 | 2.21 | 3.07 | 1.17 | 2.21 | |
| 0.8 | 2.19 | 3.01 | 1.13 | 2.18 | |
| 0.9 | 2.19 | 2.98 | 1.12 | 2.16 |
Appendix A.2. CAR Module Structure

Appendix A.3. Additional Results


References
- Jiang, H.; Sun, D.; Jampani, V.; Yang, M.H.; Learned-Miller, E.; Kautz, J. Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9000–9008. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar] [CrossRef]
- Xu, R.; Li, X.; Zhou, B.; Loy, C.C. Deep Flow-Guided Video Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3718–3727. [Google Scholar] [CrossRef]
- Yang, Y.; Loquercio, A.; Scaramuzza, D.; Soatto, S. Unsupervised Moving Object Detection via Contextual Information Separation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 879–888. [Google Scholar] [CrossRef]
- Cheng, J.; Tsai, Y.H.; Wang, S.; Yang, M.H. SegFlow: Joint Learning for Video Object Segmentation and Optical Flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 686–695. [Google Scholar] [CrossRef]
- Behl, A.; Jafari, O.H.; Mustikovela, S.K.; Alhaija, H.A.; Rother, C.; Geiger, A. Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios? In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2593–2602. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Models Matter, So Does Training: An Empirical Study of CNNs for Optical Flow Estimation. IEEE Trans. Pattern Recognit. Mach. Intell. 2020, 42, 1408–1423. [Google Scholar] [CrossRef] [PubMed]
- Ranjan, A.; Black, M.J. Optical Flow Estimation Using a Spatial Pyramid Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2720–2729. [Google Scholar] [CrossRef]
- Hui, T.W.; Loy, X.T.C.C. LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8981–8989. [Google Scholar] [CrossRef]
- Wulff, J.; Sevilla-Lara, L.; Black, M.J. Optical Flow in Mostly Rigid Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6911–6920. [Google Scholar] [CrossRef]
- Revaud, J.; Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. EpicFlow: Edge-preserving interpolation of correspondences for optical flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1164–1172. [Google Scholar] [CrossRef]
- Sun, D.; Roth, S.; Black, M.J. Secrets of optical flow estimation and their principles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2432–2439. [Google Scholar] [CrossRef]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High accuracy optical flow estimation based on a theory for warping. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision (ECCV), Prague, Czech Republic, 11–14 May 2004; Springer: Prague, Czech Republic, 2004; Volume 3024, pp. 25–36. [Google Scholar] [CrossRef]
- Li, J.; Zhao, J.; Song, S.; Feng, T. Occlusion aware unsupervised learning of optical flow from video. In Proceedings of the Thirteenth International Conference on Machine Vision; International Society for Optics and Photonics; SPIE: Rome, Italy, 2021; Volume 11605, pp. 224–231. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Z. Optical Flow Estimation with Occlusion Detection. Algorithms 2019, 12, 92. [Google Scholar] [CrossRef]
- Ren, Z.; Yan, J.; Ni, B.; Liu, B.; Yang, X.; Zha, H. Unsupervised Deep Learning for Optical Flow Estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar] [CrossRef]
- Luo, K.; Wang, C.; Liu, S.; Fan, H.; Wang, J.; Sun, J. Upflow: Upsampling pyramid for unsupervised optical flow learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1045–1054. [Google Scholar] [CrossRef]
- Ranjan, A.; Jampani, V.; Balles, L.; Sun, D.; Kim, K.; Wulff, J.; Black, M.J. Competitive Collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12232–12241. [Google Scholar] [CrossRef]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar] [CrossRef]
- Liu, L.; Zhai, G.; Ye, W.; Liu, Y. Unsupervised Learning of Scene Flow Estimation Fusing with Local Rigidity. In Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI, Macao, China, 10–16 August 2019; pp. 876–882. [Google Scholar] [CrossRef]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 8527–8537. [Google Scholar] [CrossRef]
- Wang, H.; Fan, R.; Liu, M. CoT-AMFlow: Adaptive modulation network with co-teaching strategy for unsupervised optical flow estimation. In Proceedings of the International Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 143–155. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. DropBlock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31, 10750–10760. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; He, R.; Liu, Y.; Wang, Y.; Tai, Y.; Luo, D.; Wang, C.; Li, J.; Huang, F. Learning by Analogy: Reliable Supervision from Transformations for Unsupervised Optical Flow Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6488–6497. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Häusser, P.; Hazırbaş, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef]
- Truong, P.; Danelljan, M.; Timofte, R. GLU-Net: Global-Local Universal Network for dense flow and correspondences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3262–3272. [Google Scholar] [CrossRef]
- Hur, J.; Roth, S. Iterative Residual Refinement for Joint Optical Flow and Occlusion Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4761–4770. [Google Scholar] [CrossRef]
- Ren, Z.; Gallo, O.; Sun, D.; Yang, M.H.; Sudderth, E.B.; Kautz, J. A Fusion Approach for Multi-Frame Optical Flow Estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1683–1692. [Google Scholar] [CrossRef]
- Zhao, S.; Sheng, Y.; Dong, Y.; Chang, E.I.C.; Xu, Y. MaskFlownet: Asymmetric Feature Matching with Learnable Occlusion Mask. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6277–6286. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, Y.; Dai, Y.; Zhang, K.; Ji, P.; Li, H. Displacement-invariant matching cost learning for accurate optical flow estimation. Adv. Neural Inf. Process. Syst. 2020, 33, 15220–15231. [Google Scholar]
- Yang, G.; Ramanan, D. Volumetric correspondence networks for optical flow. Adv. Neural Inf. Process. Syst. 2019, 32, 794–805. [Google Scholar]
- Teed, Z.; Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 402–419. [Google Scholar] [CrossRef]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Ranjan, A.; Black, M.J.; Geiger, A. Unsupervised Learning of Multi-Frame Optical Flow with Occlusions. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switerland; Munich, Germany, 2018; Volume 11220, pp. 713–731. [Google Scholar] [CrossRef]
- Liu, P.; King, I.; Lyu, M.R.; Xu, J. DDFlow: Learning Optical Flow with Unlabeled Data Distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8571–8578. [Google Scholar] [CrossRef]
- Liu, P.; Lyu, M.; King, I.; Xu, J. SelFlow: Self-Supervised Learning of Optical Flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6707–6716. [Google Scholar] [CrossRef]
- Ren, Z.; Luo, W.; Yan, J.; Liao, W.; Yang, X.; Yuille, A.; Zha, H. STFlow: Self-Taught Optical Flow Estimation Using Pseudo Labels. IEEE Trans. Image Process. 2020, 29, 9113–9124. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Ji, P.; Wang, J.; Dai, Y.; Li, H. Unsupervised Deep Epipolar Flow for Stationary or Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12069–12078. [Google Scholar] [CrossRef]
- Zou, Y.; Luo, Z.; Huang, J.B. DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 38–55. [Google Scholar] [CrossRef]
- Jonschkowski, R.; Stone, A.; Barron, J.T.; Gordon, A.; Konolige, K.; Angelova, A. What Matters in Unsupervised Optical Flow. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 557–572. [Google Scholar] [CrossRef]
- Kong, L.; Yang, J. MDFlow: Unsupervised Optical Flow Learning by Reliable Mutual Knowledge Distillation. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 677–688. [Google Scholar] [CrossRef]
- Marsal, R.; Chabot, F.; Loesch, A.; Sahbi, H. BrightFlow: Brightness-Change-Aware Unsupervised Learning of Optical Flow. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 2060–2069. [Google Scholar] [CrossRef]
- Stone, A.; Maurer, D.; Ayvaci, A.; Angelova, A.; Jonschkowski, R. SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3887–3896. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar] [CrossRef]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep Networks with Stochastic Depth. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 646–661. [Google Scholar] [CrossRef]
- Chen, L.; Gautier, P.; Aydore, S. DropCluster: A structured dropout for convolutional networks. arXiv 2020. [Google Scholar] [CrossRef]
- Ratner, A.J.; Ehrenberg, H.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to Compose Domain-Specific Transformations for Data Augmentation. Adv. Neural Inf. Process. Syst. 2017, 30, 3236–3246. [Google Scholar]
- Xiao, C.; Zhu, J.Y.; Li, B.; He, W.; Liu, M.; Song, D. Spatially Transformed Adversarial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar] [CrossRef]
- Bar-Haim, A.; Wolf, L. ScopeFlow: Dynamic Scene Scoping for Optical Flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7995–8004. [Google Scholar] [CrossRef]
- Zheng, Z.; Peng, X. Self-Guidance: Improve Deep Neural Network Generalization via Knowledge Distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 351–360. [Google Scholar] [CrossRef]
- Lu, Y.; Valmadre, J.; Wang, H.; Kannala, J.; Harandi, M.; Torr, P.H.S. Devon: Deformable Volume Network for Learning Optical Flow. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2694–2702. [Google Scholar] [CrossRef]
- Xie, S.; Lai, P.K.; Laganiere, R.; Lang, J. Effective Convolutional Neural Network Layers in Flow Estimation for Omni-Directional Images. In Proceedings of the International Conference on 3D Vision, Quebec City, QC, Canada, 16–19 September 2019; pp. 671–680. [Google Scholar] [CrossRef]
- Haiyun, Z.; Xuezhi, X.; Rongfang, Z.; Mingliang, Z.; Ali, S.M. Learning Optical Flow via Deformable Convolution and Feature Pyramid Networks. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 26–30. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video Enhancement with Task-Oriented Flow. Int. J. Comput. Vis. (IJCV) 2019, 127, 1106–1125. [Google Scholar] [CrossRef]
- Yu, J.J.; Harley, A.W.; Derpanis, K.G. Back to Basics: Unsupervised Learning of Optical Flow via Brightness Constancy and Motion Smoothness. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 11–14 October 2016; pp. 3–10. [Google Scholar]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conf. on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 611–625. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization 3rd Int. In Proceedings of the Conf. for Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Meister, S.; Hur, J.; Roth, S. UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7255–7263. [Google Scholar] [CrossRef]
- Hur, J.; Roth, S. Self-Supervised Monocular Scene Flow Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7394–7403. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R. Every Pixel Counts: Unsupervised Geometry Learning with Holistic 3D Motion Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 691–709. [Google Scholar]
- Luo, C.; Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R.; Yuille, A.L. Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding. IEEE Trans. Pattern Recognit. Mach. Intell. 2020, 42, 2624–2641. [Google Scholar] [CrossRef] [PubMed]







| Experiment | Sintel Clean | Sintel Final |
|---|---|---|
| None | 2.79 | 3.72 |
| Dropout | 2.83 | 3.77 |
| DropBlock, bs = 1 | 2.81 | 3.73 |
| DropBlock, bs = 3 | 2.77 | 3.75 |
| DropBlock, bs = 7 | 2.76 | 3.72 |
| SpatialDropout | 2.74 | 3.69 |
| CAR | 2.70 | 3.63 |
| Method | Sintel Clean | Sintel Final | KITTI-12 | KITTI-15 | ||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| PWC-Net [26] | (1.70) | 3.86 | (2.21) | 5.13 | (1.45) | 1.7 | (2.16) | 9.60% |
| IRR-PWC [30] | (1.92) | 3.84 | (2.51) | 4.58 | – | – | (1.63) | 7.65% |
| ScopeFlow [56] | - | 3.59 | - | 4.10 | – | - | - | 6.82% |
| VCN [34] | (1.66) | 2.81 | (2.24) | 4.40 | – | - | (4.1) | 6.30% |
| DICL [33] | (1.11) | 2.12 | (1.60) | 3.44 | – | - | (3.6) | 6.31% |
| MaskFlownet [32] | (2.25) | 2.52 | (3.61) | 4.17 | (2.94) | 1.1 | - | 6.11% |
| UnFlow-CSS [67] | – | – | (7.91) | 10.22 | 3.29 | – | 8.10 | 23.30% |
| OccAwareFlow [15] | (4.03) | 7.95 | (5.95) | 9.15 | 3.55 | 4.2 | 8.88 | 31.2% |
| UnFlow [67] | – | 9.38 | (7.91) | 10.22 | 3.29 | – | 8.10 | 23.3% |
| DDFlow [38] | (2.92) | 6.18 | (3.98) | 7.40 | 2.35 | 3.0 | 5.72 | 14.29% |
| EpiFlow [41] | (3.54) | 7.00 | (4.99) | 8.51 | (2.51) | 3.4 | (5.55) | 16.95% |
| SelFlow [39] | (2.88) | 6.56 | (3.87) | 6.57 | 1.69 | 2.2 | 4.84 | 14.19% |
| ARFlow [27] | (2.79) | 4.78 | (3.87) | 5.89 | 1.44 | 1.8 | 2.85 | 11.80% |
| ARFlow-MV [27] | (2.73) | 4.49 | (3.69) | 5.67 | 1.26 | 1.5 | 3.46 | 11.79% |
| UFlow [43] | (2.50) | 5.21 | (3.39) | 6.50 | 1.68 | 1.9 | 2.71 | 11.13% |
| MDFlow [44] | (2.17) | 4.16 | (3.14) | 5.46 | - | - | 2.45 | 8.91% |
| UPFlow [18] | (2.33) | 4.68 | (2.67) | 5.32 | 1.27 | 1.4 | 2.45 | 9.38% |
| CAR-Flow (our) | (2.36) | 3.69 | (3.28) | 5.21 | 1.16 | 1.3 | 2.34 | 9.09% |
| CAR-Flow-MV (our) | (2.25) | 3.46 | (3.23) | 4.95 | 1.02 | 1.2 | 2.11 | 8.40% |
| Method | # FLOPs | # Params | Inference | Sintel | KITTI | ||
|---|---|---|---|---|---|---|---|
| Time | Clean | Final | 2012 | 2015 | |||
| UPFlow [18] | 198.27 G | 3.49 M | 271 ms | 4.68 | 5.32 | 1.4 | 9.38% |
| SMURF [46] | 810.14 G | 5.26 M | 413 ms | 3.15 | 4.18 | - | 6.38% |
| CAR-Flow | 50.49 G | 2.74 M | 34 ms | 3.69 | 5.21 | 1.3 | 9.09% |
| CAR-Flow-MV | 108.08 G | 2.97 M | 59 ms | 3.46 | 4.95 | 1.2 | 8.40% |
| DMCV | LDR | ARL | CAR | Sintel Clean | Sintel Final | ||||
|---|---|---|---|---|---|---|---|---|---|
| ALL | NOC | OCC | ALL | NOC | OCC | ||||
| 2.92 | 1.53 | 22.14 | 3.87 | 2.46 | 26.24 | ||||
| ✔ | 2.74 | 1.32 | 20.92 | 3.75 | 2.31 | 23.90 | |||
| ✔ | ✔ | 2.58 | 1.17 | 18.64 | 3.43 | 2.14 | 22.52 | ||
| ✔ | ✔ | 2.53 | 1.15 | 18.46 | 3.51 | 2.03 | 22.43 | ||
| ✔ | ✔ | 2.57 | 1.21 | 18.72 | 3.47 | 1.91 | 22.16 | ||
| ✔ | ✔ | ✔ | 2.36 | 1.04 | 18.14 | 3.24 | 1.77 | 21.22 | |
| ✔ | ✔ | ✔ | 2.42 | 1.16 | 17.54 | 3.31 | 1.84 | 20.83 | |
| ✔ | ✔ | ✔ | 2.33 | 1.11 | 17.31 | 3.26 | 1.81 | 21.36 | |
| ✔ | ✔ | ✔ | ✔ | 2.25 | 1.01 | 16.27 | 3.07 | 1.62 | 20.12 |
| ✔ | ✔ | ✔ | ✔ | 2.13 | 0.99 | 16.12 | 2.83 | 1.55 | 19.70 |
| Method | Sintel Clean | Sintel Final | KITTI 2012 | KITTI 2015 |
|---|---|---|---|---|
| PWC-Net | (1.86) | (2.31) | 3.68 | 10.52% |
| ARFlow | (2.79) | (3.73) | 3.06 | 9.04% |
| CAR-Flow | (2.81) | (3.73) | 2.65 | 7.06% |
| CAR-Flow-MV | (2.22) | (3.26) | 2.23 | 5.97% |
| Method | D1-all | D2-all | F1-all | SF1-all |
|---|---|---|---|---|
| GeoNet [20] | 49.54 | 58.17 | 37.83 | 71.32 |
| EPC [69] | 26.81 | 60.97 | 25.74 | (>60.97) |
| EPC++ [70] | 23.84 | 60.32 | 19.64 | (>60.32) |
| Self-Mono-SF [68] | 31.25 | 34.86 | 23.49 | 47.0 |
| Self-Mono-SF-CAR (our) | 29.24 | 32.49 | 21.34 | 43.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, L.; Lang, J. Regularization for Unsupervised Learning of Optical Flow. Sensors 2023, 23, 4080. https://doi.org/10.3390/s23084080
Long L, Lang J. Regularization for Unsupervised Learning of Optical Flow. Sensors. 2023; 23(8):4080. https://doi.org/10.3390/s23084080
Chicago/Turabian StyleLong, Libo, and Jochen Lang. 2023. "Regularization for Unsupervised Learning of Optical Flow" Sensors 23, no. 8: 4080. https://doi.org/10.3390/s23084080
APA StyleLong, L., & Lang, J. (2023). Regularization for Unsupervised Learning of Optical Flow. Sensors, 23(8), 4080. https://doi.org/10.3390/s23084080