
Overcoming Challenges Associated with Developing Industrial Prognostics and Health Management Solutions

 ,
,  , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
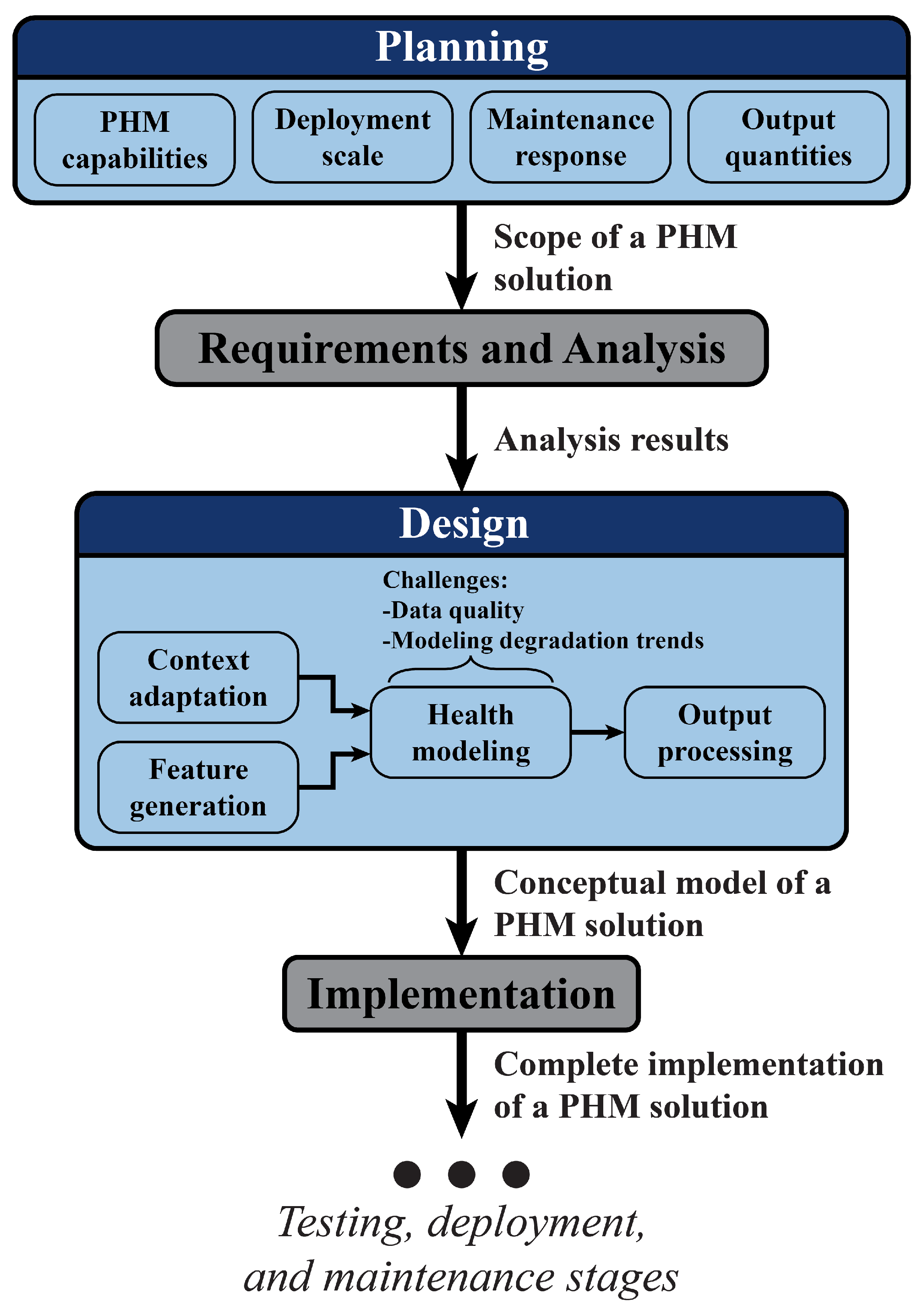
2. Development of Industrial PHM Solutions
3. Planning Stage
3.1. Subject Matter Expertise Classifications
- Business expertise: Knowledge of the financial aspects of a manufacturing operation. Business experts have an understanding of the production demands that apply to a manufacturing operation and the financial impacts of disruptions. An understanding of the costs (absolute or relative) of false negatives and false positives from a prospective PHM solution is also necessary.
- Reliability expertise: Knowledge of a manufacturing operation’s current reliability strategy. Reliability experts are aware of the initiatives that are currently in place to ensure that a manufacturing operation remains online, including scheduled preventative maintenance procedures and protocols for administering reactive maintenance.
- Equipment expertise: Knowledge of the machine(s) that a prospective PHM solution will monitor. Equipment experts have an understanding of the mechanical and electrical components that make up the machine and an awareness of its potential faults and failure modes.
- Data expertise: Knowledge of a manufacturing operation’s data collection capabilities. Data experts are aware of the signals that are available to be used in a PHM solution and understand how system health problems can manifest themselves in these signals. They are also familiar with the data reporting and storage infrastructure that will be used to implement the PHM solution and can provide insight into how data collection and processing can be improved to better support PHM solutions.
3.2. Planning Methodology
4. Design Stage
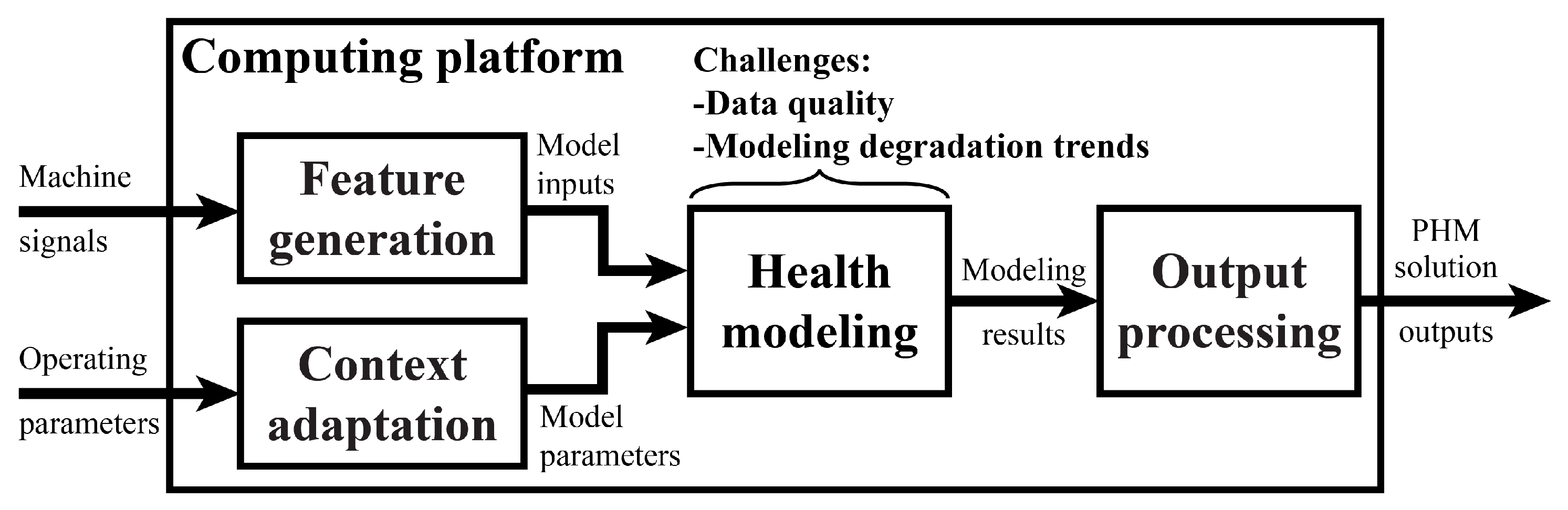
4.1. PHM Solution Architecture
4.2. Data Quality
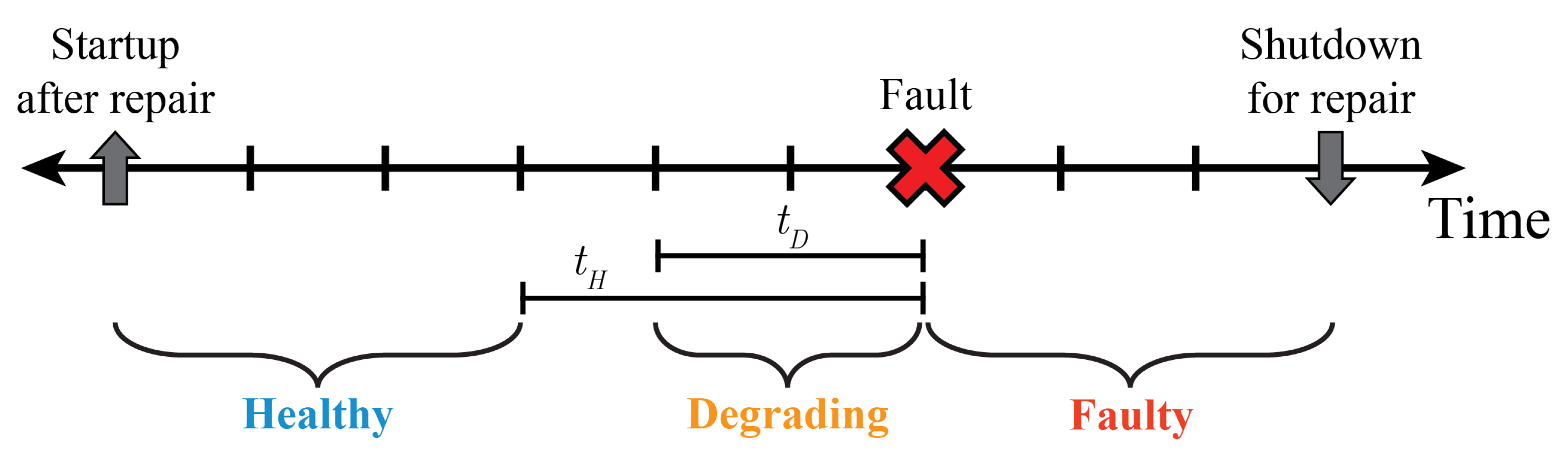
4.2.1. Pre-Processing Historical Data
: An occurrence associated with an unwanted situation within an manufacturing system that must be resolved through maintenance
: Transition of a system from an online state to an offline state for the purpose of conducting a repair procedure
: Transition of a system from an offline state to online state after a repair procedure has been completed
4.2.2. Combined Training Datasets
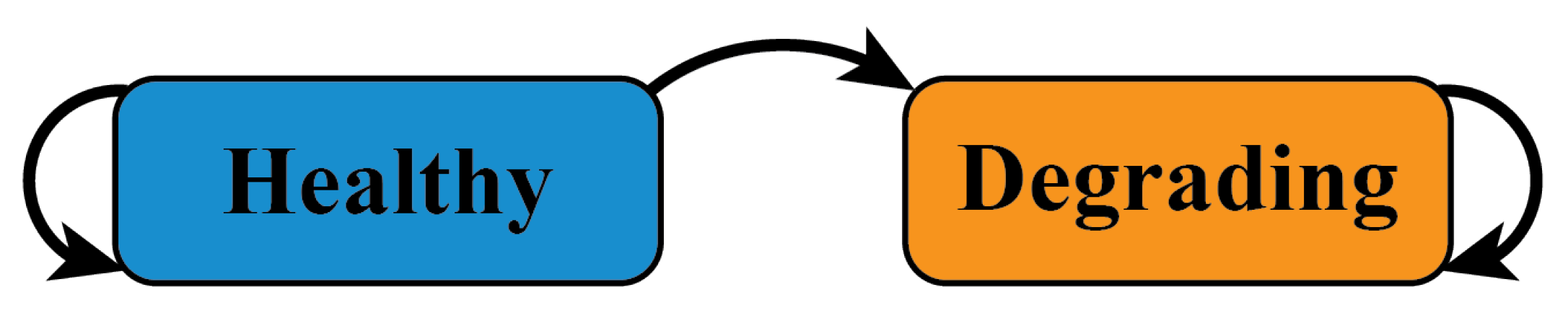
4.3. Modeling Time-Series Degradation Trends
5. Case Study PHM Solution Development
5.1. Planning
5.2. Requirements and Analysis
5.3. Design
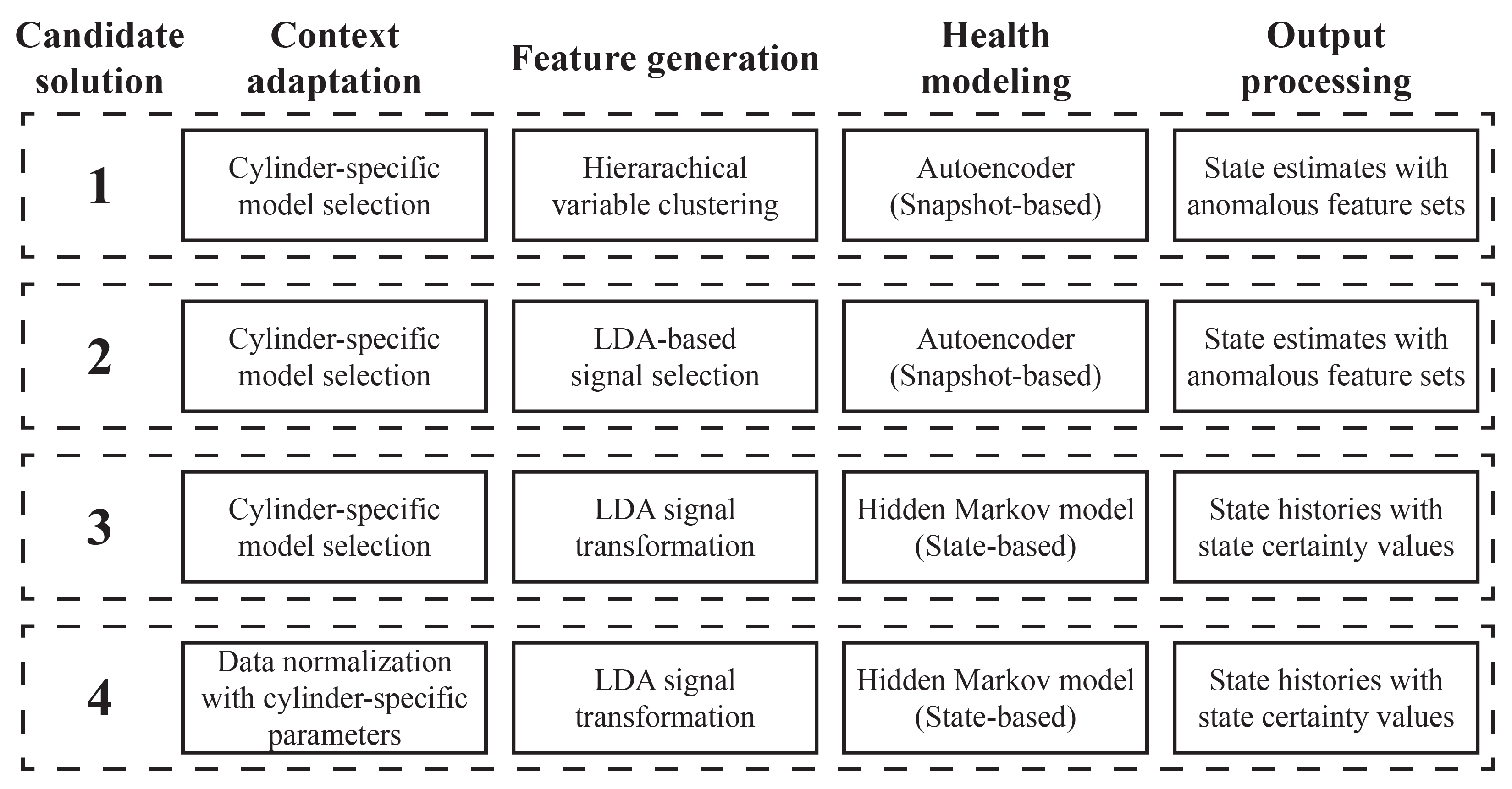
5.3.1. Context Adaptation
5.3.2. Feature Generation
5.3.3. Health Modeling
5.3.4. Output Processing
6. Case Study Insights
6.1. Planning
6.2. Design
6.3. Data Quality
6.4. Modeling Time-Series Degradation Trends
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems Reviews, methodology, and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-Driven Methods for Predictive Maintenance of Industrial Equipment: A Survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Hu, Y.; Miao, X.; Si, Y.; Pan, E.; Zio, E. Prognostics and health management: A review from the perspectives of design, development and decision. Reliab. Eng. Syst. Saf. 2022, 217, 108063. [Google Scholar] [CrossRef]
- Li, R.; Verhagen, W.J.; Curran, R. Stakeholder-oriented systematic design methodology for prognostic and health management system: Stakeholder expectation definition. Adv. Eng. Inform. 2020, 43, 101041. [Google Scholar] [CrossRef]
- Zonta, T.; Da Costa, C.A.; da Rosa, R.R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Moyne, J.; Qamsane, Y.; Balta, E.C.; Kovalenko, I.; Faris, J.; Barton, K.; Tilbury, D.M. A requirements driven digital twin framework: Specification and opportunities. IEEE Access 2020, 8, 107781–107801. [Google Scholar] [CrossRef]
- Li, R.; Verhagen, W.J.; Curran, R. A systematic methodology for Prognostic and Health Management system architecture definition. Reliab. Eng. Syst. Saf. 2020, 193, 106598. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Ruparelia, N.B. Software development lifecycle models. ACM SIGSOFT Softw. Eng. Notes 2010, 35, 8–13. [Google Scholar] [CrossRef]
- Royce, W.W. Managing the development of large software systems: Concepts and techniques. In Proceedings of the 9th International Conference on Software Engineering, Monterey, CA, USA, 30 March–2 April 1987; pp. 328–338. [Google Scholar]
- Bhuvaneswari, T.; Prabaharan, S. A survey on software development life cycle models. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 262–267. [Google Scholar]
- Qamsane, Y.; Moyne, J.; Toothman, M.; Kovalenko, I.; Balta, E.C.; Faris, J.; Tilbury, D.M.; Barton, K. A Methodology to Develop and Implement Digital Twin Solutions for Manufacturing Systems. IEEE Access 2021, 9, 44247–44265. [Google Scholar] [CrossRef]
- ISO 24765:2017; Systems and Software Engineering—Vocabulary. International Organization for Standardization: Geneva, Switzerland, 2017.
- Forsberg, K.; Mooz, H. The relationship of systems engineering to the project cycle. Eng. Manag. J. 1992, 4, 36–43. [Google Scholar] [CrossRef]
- Birrell, N.D.; Ould, M.A. A Practical Handbook for Software Development; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Boehm, B.W. A spiral model of software development and enhancement. Computer 1988, 21, 61–72. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Abid, A.; Khan, M.T.; Iqbal, J. A review on fault detection and diagnosis techniques: Basics and beyond. Artif. Intell. Rev. 2021, 54, 3639–3664. [Google Scholar] [CrossRef]
- Zhao, Y.; Toothman, M.; Moyne, J.; Barton, K. An Adaptive Modeling Framework for Bearing Failure Prediction. Electronics 2022, 11, 257. [Google Scholar] [CrossRef]
- Toothman, M.; Braun, B.; Bury, S.J.; Dessauer, M.; Henderson, K.; Phillips, S.; Ye, Y.; Tilbury, D.M.; Moyne, J.; Barton, K. A Digital Twin Framework for Mechanical System Health State Estimation. In Proceedings of the Modeling, Estimation, and Control Conference, Austin, TX, USA, 24–27 October 2021; pp. 1–7. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yan, R.; Shen, F.; Sun, C.; Chen, X. Knowledge transfer for rotary machine fault diagnosis. IEEE Sens. J. 2019, 20, 8374–8393. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–280. [Google Scholar]
- Elwany, A.; Gebraeel, N. Real-Time Estimation of Mean Remaining Life Using Sensor-Based Degradation Models. J. Manuf. Sci. Eng. 2009, 131, 051005. [Google Scholar] [CrossRef]
- Gebraeel, N.Z.; Lawley, M.A.; Li, R.; Ryan, J.K. Residual-life distributions from component degradation signals: A Bayesian approach. IiE Trans. 2005, 37, 543–557. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, P.X.; Gao, J. Model-based fault diagnosis methods for systems with stochastic process—A survey. Neurocomputing 2022, 513, 137–152. [Google Scholar] [CrossRef]
- Doraiswami, R.; Diduch, C.P.; Tang, J. A new diagnostic model for identifying parametric faults. IEEE Trans. Control Syst. Technol. 2009, 18, 533–544. [Google Scholar] [CrossRef]
- Bachir, S.; Tnani, S.; Trigeassou, J.C.; Champenois, G. Diagnosis by parameter estimation of stator and rotor faults occurring in induction machines. IEEE Trans. Ind. Electron. 2006, 53, 963–973. [Google Scholar] [CrossRef]
- Tafazoli, S.; Sun, X. Hybrid system state tracking and fault detection using particle filters. IEEE Trans. Control Syst. Technol. 2006, 14, 1078–1087. [Google Scholar] [CrossRef]
- Yin, S.; Zhu, X. Intelligent particle filter and its application to fault detection of nonlinear system. IEEE Trans. Ind. Electron. 2015, 62, 3852–3861. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Zhang, D.; Andrew, D.B.; Djurdjanovic, D. Bayesian Identification of Hidden Markov Models and Their Use for Condition-Based Monitoring. IEEE Trans. Reliab. 2016, 65, 1471–1482. [Google Scholar] [CrossRef]
- Toothman, M.; Braun, B.; Bury, S.J.; Dessauer, M.; Henderson, K.; Ray Wright, D.M.T.; Moyne, J.; Barton, K. Trend-based repair quality assessment for industrial rotating equipment. IEEE Control Syst. Lett. 2020, 5, 1675–1680. [Google Scholar] [CrossRef]
- Yu, S.Z. Hidden semi-Markov models. Artif. Intell. 2010, 174, 215–243. [Google Scholar] [CrossRef]
- Dong, M.; He, D. A segmental hidden semi-Markov model (HSMM)-based diagnostics and prognostics framework and methodology. Mech. Syst. Signal Process. 2007, 21, 2248–2266. [Google Scholar] [CrossRef]
- Peng, Y.; Dong, M. A prognosis method using age-dependent hidden semi-Markov model for equipment health prediction. Mech. Syst. Signal Process. 2011, 25, 237–252. [Google Scholar] [CrossRef]
- SAS/STAT 15.2 User’s Guide: The VARCLUS Procedure, 2020. Available online: https://go.documentation.sas.com/api/docsets/statug/15.2/content/varclus.pdf (accessed on 4 October 2022).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toothman, M.; Braun, B.; Bury, S.J.; Moyne, J.; Tilbury, D.M.; Ye, Y.; Barton, K. Overcoming Challenges Associated with Developing Industrial Prognostics and Health Management Solutions. Sensors 2023, 23, 4009. https://doi.org/10.3390/s23084009
Toothman M, Braun B, Bury SJ, Moyne J, Tilbury DM, Ye Y, Barton K. Overcoming Challenges Associated with Developing Industrial Prognostics and Health Management Solutions. Sensors. 2023; 23(8):4009. https://doi.org/10.3390/s23084009
Chicago/Turabian StyleToothman, Maxwell, Birgit Braun, Scott J. Bury, James Moyne, Dawn M. Tilbury, Yixin Ye, and Kira Barton. 2023. "Overcoming Challenges Associated with Developing Industrial Prognostics and Health Management Solutions" Sensors 23, no. 8: 4009. https://doi.org/10.3390/s23084009
APA StyleToothman, M., Braun, B., Bury, S. J., Moyne, J., Tilbury, D. M., Ye, Y., & Barton, K. (2023). Overcoming Challenges Associated with Developing Industrial Prognostics and Health Management Solutions. Sensors, 23(8), 4009. https://doi.org/10.3390/s23084009