
Machine Learning-Assisted Improved Anomaly Detection for Structural Health Monitoring


Abstract
1. Introduction
2. Background
2.1. Anomalies in Time Series
2.2. Synthetic Minority Oversampling Technique (SMOTE)
- #1
- n-dimensional vector space corresponding to n features of an ML model is defined where all the training data can be represented by feature vectors.
- #2
- Depending upon the amount of over-sampling required, k nearest neighbors (in terms of Euclidean distance) are randomly chosen.
- #3
- The difference between the feature vector (arbitrarily chosen from the set of k nearest neighbors) and its nearest neighbor is calculated.
- #4
- This difference is multiplied by a random number between 0 and 1, and a new feature vector is created at the corresponding location.
2.3. Minimum Redundancy and Maximum Relevance (MRMR) Algorithm
3. Data Analysis
3.1. Description of the Data and Adopted Performance Metrics
3.2. Feature Engineering and Application of MRMR
4. Simplified Anomaly Detection Approach
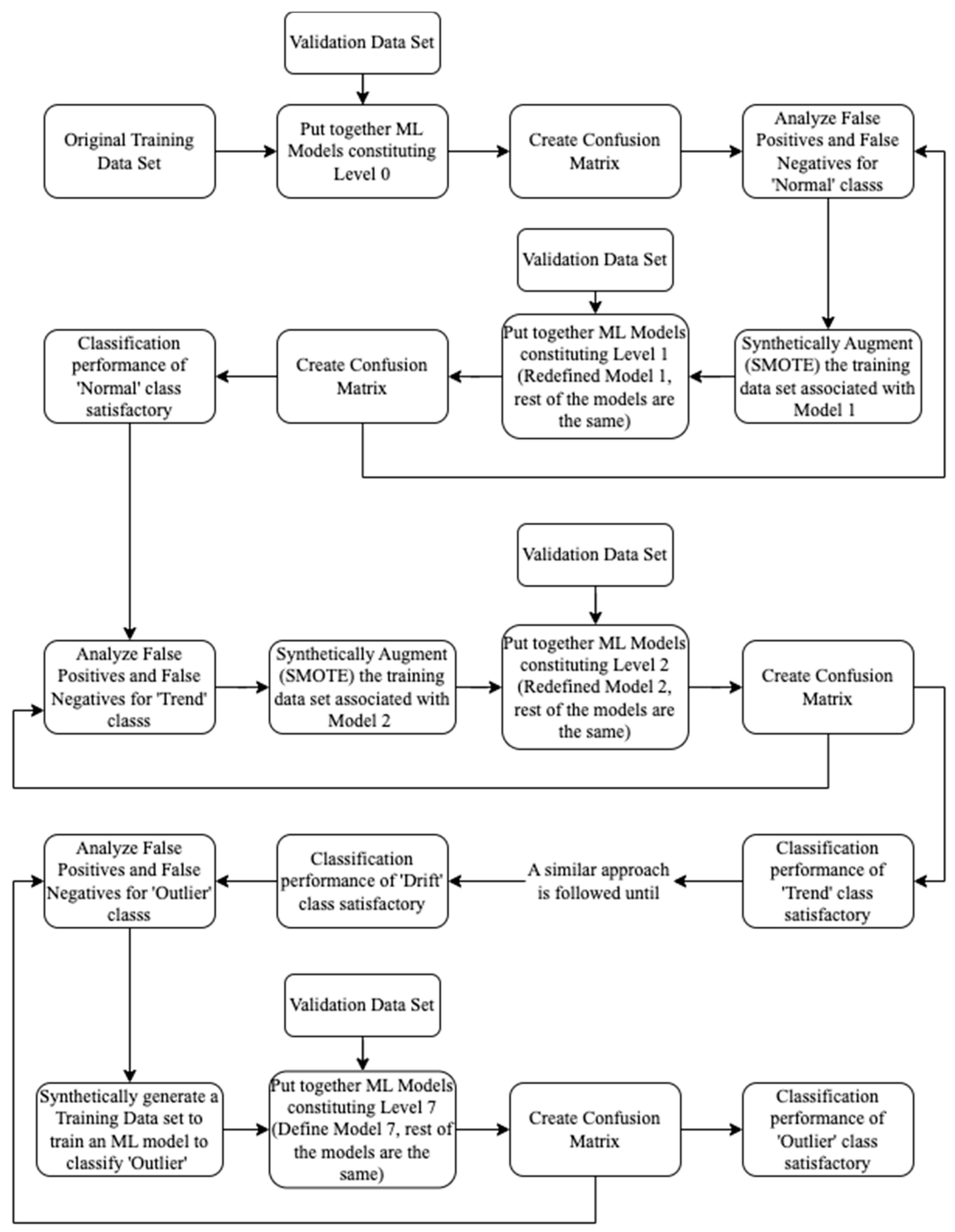
5. The Proposed ML-Based Recursive Binary Decision Tree for Anomaly Detection
- #1
- Calculated a set of 30 characteristic features to represent each one-hour-long time series (see Section 3.2 and Table 3);
- #2
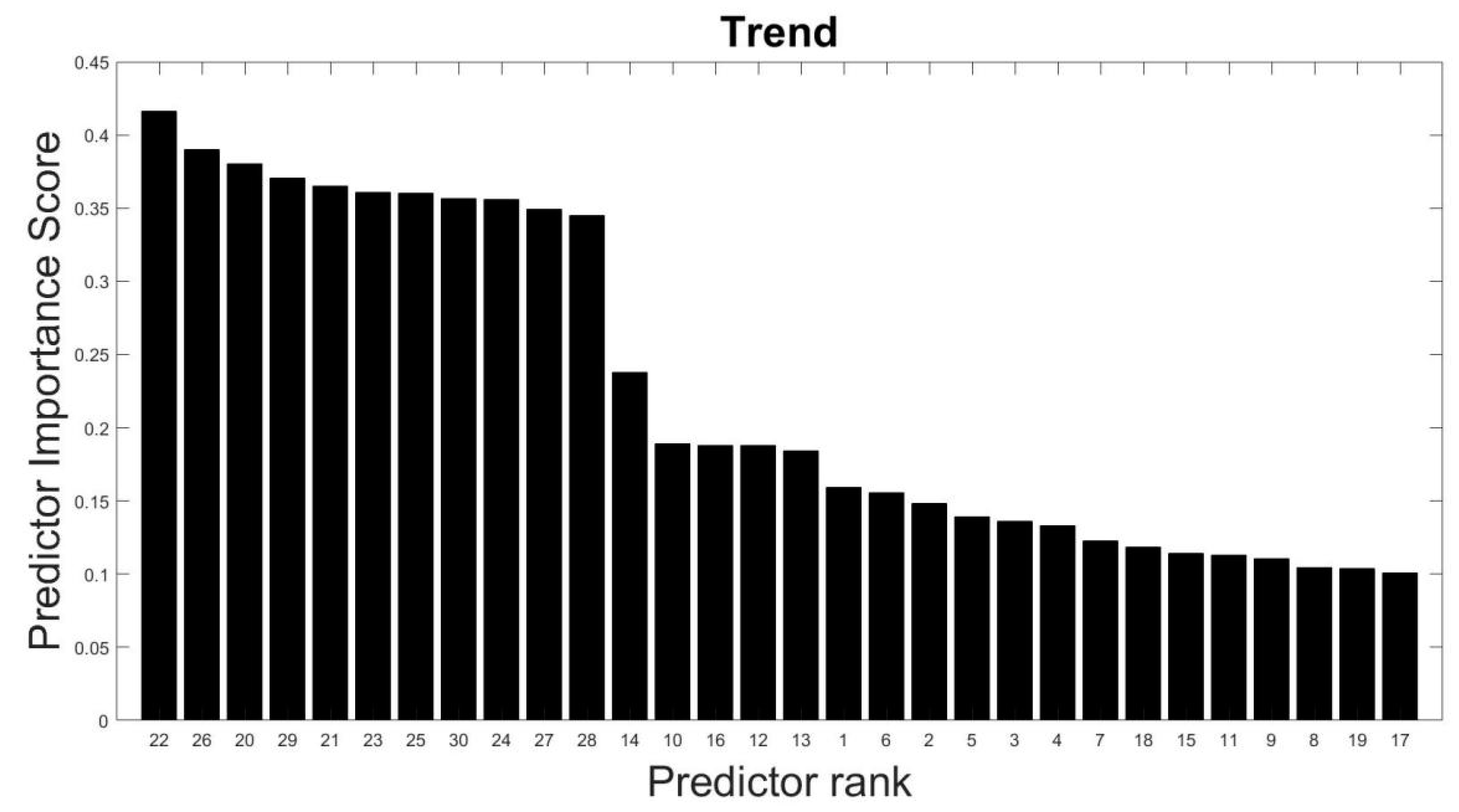
- Performed predictor importance or information value calculations to test the suitability of defined characteristic features toward the prediction of the target variable (anomalous class) using the MRMR algorithm (see Section 3.2, Figure 3 and Figure 4);
- #3
- #4
- #5
6. Results
6.1. Anomaly Detection Using Traditional Unsupervised ML
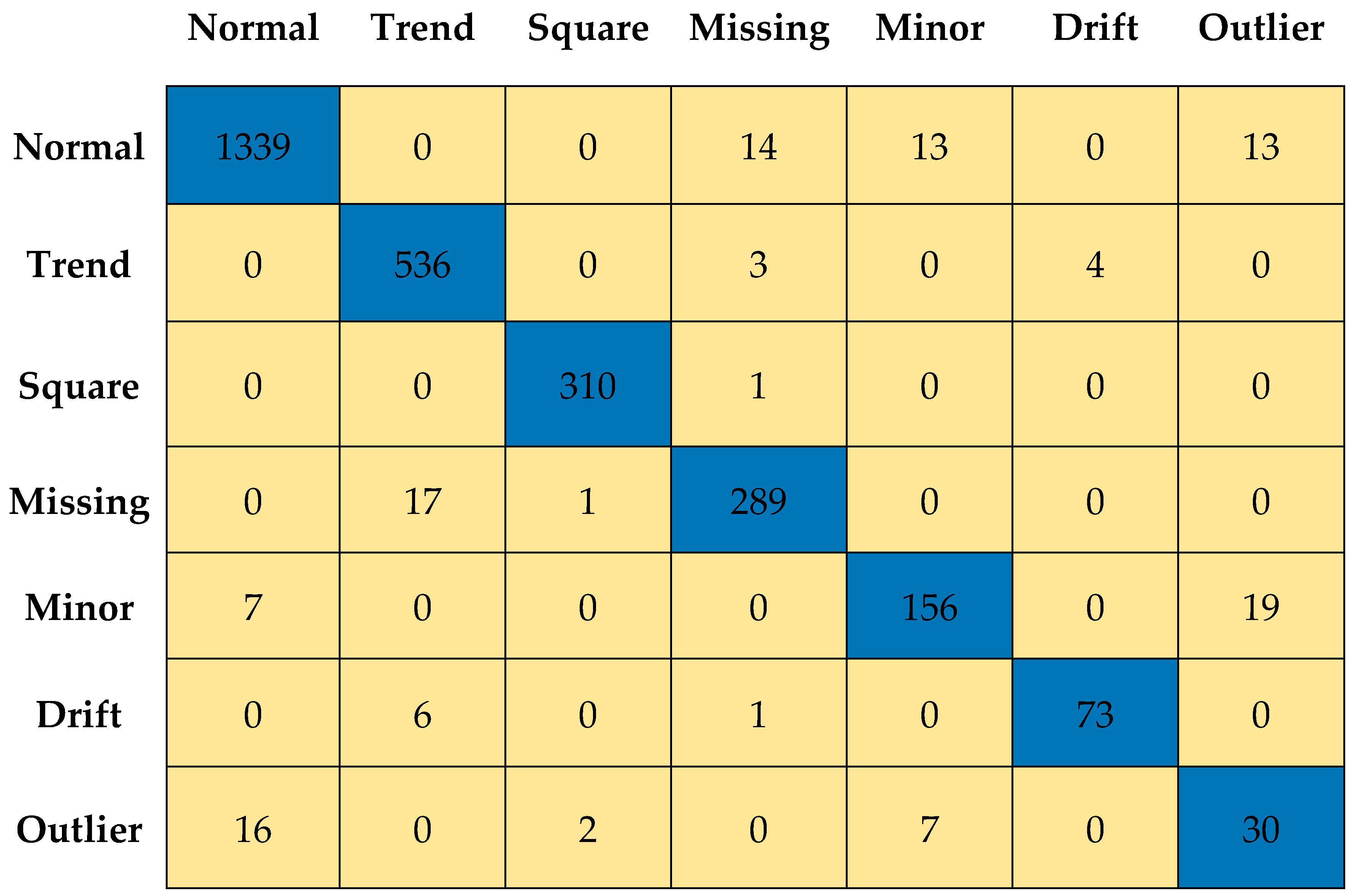
6.2. Anomaly Detection Using the Proposed Methodology
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, X.; Ren, Y.; Huang, Q.; Fan, Z.Y.; Tong, Z.J.; Chang, W.J.; Liu, B. Anomaly detection for large span bridges during operational phase using structural health monitoring data. Smart Mater. Struct. 2020, 29, 045029. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Wang, H.; Wan, H.P.; Mao, J.X.; Xu, Y.C. Anomaly detection of structural health monitoring data using the maximum likelihood estimation-based Bayesian dynamic linear model. Struct. Health Monit. 2021, 20, 2936–2952. [Google Scholar] [CrossRef]
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Sun, L.; Shang, Z.; Xia, Y.; Bhowmick, S.; Nagarajaiah, S. Review of bridge structural health monitoring aided by big data and artificial intelligence: From condition assessment to damage detection. J. Struct. Eng. 2020, 146, 04020073. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. An Introduction to Structural Health Monitoring. Philos. Trans. R. Soc. 2007, 365, 303–315. [Google Scholar] [CrossRef]
- Brownjohn, J.M.; De Stefano, A.; Xu, Y.L.; Wenzel, H.; Aktan, A.E. Vibration-based monitoring of civil infrastructure: Challenges and successes. J. Civ. Struct. Health Monit. 2011, 1, 79–95. [Google Scholar] [CrossRef]
- Nagarajaiah, S.; Erazo, K. Structural monitoring and identification of civil infrastructure in the United States. Struct. Monit. Maint. 2016, 3, 51–69. [Google Scholar] [CrossRef]
- Li, S.; Li, H.; Liu, Y.; Lan, C.; Zhou, W.; Ou, J. SMC structural health monitoring benchmark problem using monitored data from an actual cable-stayed bridge. Struct. Control Health Monit. 2014, 21, 156–172. [Google Scholar] [CrossRef]
- Li, H.; Ou, J.; Zhang, X.; Pei, M.; Li, N. Research and practice of health monitoring for long-span bridges in the mainland of China. Smart Struct. Syst. 2015, 15, 555–576. [Google Scholar] [CrossRef]
- Ni, F.; Zhang, J.; Noori, M.N. Deep learning for data anomaly detection and data compression of a long-span suspension bridge. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 685–700. [Google Scholar] [CrossRef]
- Tang, Z.; Chen, Z.; Bao, Y.; Li, H. Convolutional neural network-based data anomaly detection method using multiple information for structural health monitoring. Struct. Control Health Monit. 2019, 26, e2296. [Google Scholar] [CrossRef]
- Mao, J.; Wang, H.; Spencer, B.F., Jr. Toward data anomaly detection for automated structural health monitoring: Exploiting generative adversarial nets and autoencoders. Struct. Health Monit. 2021, 20, 1609–1626. [Google Scholar] [CrossRef]
- Abdelghani, M.; Friswell, M.I. Sensor validation for structural systems with multiplicative sensor faults. Mech. Syst. Signal Process. 2007, 21, 270–279. [Google Scholar] [CrossRef]
- Feng, Z.; Wang, Q.; Shida, K. A review of self-validating sensor technology. Sensor 2007, 27, 48–56. [Google Scholar]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Arul, M.; Kareem, A. Data Anomaly Detection for Structural Health Monitoring of Bridges using Shapelet Transform. arXiv 2020, arXiv:2009.00470. [Google Scholar]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Sarmadi, H.; Karamodin, A. A novel anomaly detection method based on adaptive Mahalanobis-squared distance and one-class kNN rule for structural health monitoring under environmental effects. Mech. Syst. Signal Process. 2020, 140, 106495. [Google Scholar] [CrossRef]
- Flah, M.; Nunez, I.; Ben Chaabene, W.; Nehdi, M.L. Machine learning algorithms in civil structural health monitoring: A systematic review. Arch. Comput. Methods Eng. 2021, 28, 2621–2643. [Google Scholar] [CrossRef]
- Bigoni, C.; Hesthaven, J.S. Simulation-based anomaly detection and damage localization: An application to structural health monitoring. Comput. Methods Appl. Mech. Eng. 2020, 363, 112896. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, Z.; Yang, R. Data anomaly detection for structural health monitoring by multi-view representation based on local binary patterns. Measurement 2022, 202, 111804. [Google Scholar] [CrossRef]
- Bao, Y.; Li, J.; Nagayama, T.; Xu, Y.; Spencer, B.F., Jr.; Li, H. The 1st international project competition for structural health monitoring (IPC-SHM, 2020): A summary and benchmark problem. Struct. Health Monit. 2021, 20, 2229–2239. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Weiss, G.M. Imbalanced Learning: Foundations, Algorithms, and Applications: Foundations of Imbalanced Learning; Wiley: Hoboken, NJ, USA, 2012; pp. 13–41. [Google Scholar]
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef] [PubMed]
- Darbellay, G.A.; Vajda, I. Estimation of the information by an adaptive partitioning of the observation space. IEEE Trans. Inf. Theory 1999, 45, 1315–1321. [Google Scholar] [CrossRef]
- Zhao, Z.; Anand, R.; Wang, M. Maximum relevance and minimum redundancy feature selection methods for a marketing machine learning platform. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 442–452. [Google Scholar]
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural network toolbox. User’s Guide MathWorks 2010, 2, 77–81. [Google Scholar]
- Kohonen, T. Essentials of the self-organizing map. Neural Netw. 2013, 37, 52–65. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Description |
|---|---|
| Normal | Time-domain response is symmetrical, whereas frequency-domain response has several resonance peaks. |
| Trend | An evident trend can be found in the time-domain response, whereas a distinctive peak value can be found in the frequency-domain response. |
| Square | The time-domain response resembles a square wave. |
| Missing | Most or all of the time-domain response is missing. |
| Minor | Relative to normal class data, the amplitude is very small in the time-domain response. |
| Drift | The time-domain response is non-stationary with random drift or time-domain response diverges with time. |
| Outlier | One or more outliers (i.e., high spikes) appear in the time-domain response. |
| Anomaly | Quantity |
|---|---|
| Normal | 13,575 |
| Trend | 5778 |
| Square | 2996 |
| Missing | 2942 |
| Minor | 1775 |
| Drift | 679 |
| Outlier | 527 |
| Feature # | Feature Description | Feature # | Feature Description | Feature # | Feature Description |
|---|---|---|---|---|---|
| 1 | (μ2 − μ1)/μ₁ | 11 | S₁ | 21 | K₁ |
| 2 | (μ3 − μ2)/μ₂ | 12 | S₂ | 22 | K₂ |
| 3 | (μ4 − μ3)/μ₃ | 13 | S₃ | 23 | K₃ |
| 4 | (μ5 − μ4)/μ₄ | 14 | S₄ | 24 | K₄ |
| 5 | (μ6 − μ5)/μ₅ | 15 | S₅ | 25 | K₅ |
| 6 | (μ7 − μ6)/μ₆ | 16 | S₆ | 26 | K₆ |
| 7 | (μ8 − μ7)/μ₇ | 17 | S₇ | 27 | K₇ |
| 8 | (μ9 − μ8)/μ₈ | 18 | S₈ | 28 | K₈ |
| 9 | (μ10 − μ9)/μ₉ | 19 | S₉ | 29 | K₉ |
| 10 | (max − min)/μ | 20 | S10 | 30 | K10 |
| Class | Training | Validation | Testing |
|---|---|---|---|
| Normal | 9365 | 2830 | 1380 |
| Trend | 4056 | 1160 | 562 |
| Square | 2079 | 600 | 317 |
| Missing | 2041 | 588 | 313 |
| Minor | 1231 | 368 | 176 |
| Drift | 475 | 126 | 78 |
| Outlier | 353 | 110 | 64 |
| Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 | Level 6 | Level 7 |
|---|---|---|---|---|---|---|---|
| Model 1 | Redefined Model 1 | Redefined Model 1 | Redefined Model 1 | Redefined Model 1 | Redefined Model 1 | Redefined Model 1 | Redefined Model 1 |
| Model 2 | Model 2 | Redefined Model 2 | Redefined Model 2 | Redefined Model 2 | Redefined Model 2 | Redefined Model 2 | Redefined Model 2 |
| Model 3 | Model 3 | Model 3 | Redefined Model 3 | Redefined Model 3 | Redefined Model 3 | Redefined Model 3 | Redefined Model 3 |
| Model 4 | Model 4 | Model 4 | Model 4 | Redefined Model 4 | Redefined Model 4 | Redefined Model 4 | Redefined Model 4 |
| Model 5 | Model 5 | Model 5 | Model 5 | Model 5 | Redefined Model 5 | Redefined Model 5 | Redefined Model 5 |
| Model 6 | Model 6 | Model 6 | Model 6 | Model 6 | Model 6 | Redefined Model 6 | Redefined Model 6 |
| Model 7 |
| Identifying Normal | Identifying Trend | ||||
|---|---|---|---|---|---|
| Class | Model 1 | Class | Model 2 | ||
| Training Set | Training Set | ||||
| Type-1 Normal | Normal | 9365 | Type-1 Trend | Trend | 4056 |
| Type-2 Not Normal | Trend | 4056 | Type-2 Not Trend | Normal | 0 |
| Square | 2079 | Square | 2079 | ||
| Missing | 2041 | Missing | 2041 | ||
| Minor | 1231 | Minor | 1231 | ||
| Drift | 475 | Drift | 475 | ||
| Outlier | 353 | Outlier | 353 | ||
| Identifying Square | Identifying Missing | ||||
|---|---|---|---|---|---|
| Class | Model 3 | Class | Model 4 | ||
| Training Set | Training Set | ||||
| Type-1 Square | Square | 2079 | Type-1 Missing | Missing | 2041 |
| Type-2 Not Square | Normal | 0 | Type-2 Not Missing | Normal | 0 |
| Trend | 0 | Trend | 0 | ||
| Missing | 2041 | Square | 0 | ||
| Minor | 1231 | Minor | 1231 | ||
| Drift | 475 | Drift | 475 | ||
| Outlier | 353 | Outlier | 353 | ||
| Identifying Minor | Identifying Drift | ||||
|---|---|---|---|---|---|
| Class | Model 5 | Class | Model 6 | ||
| Training Set | Training Set | ||||
| Type-1 Minor | Minor | 1231 | Type-1 Drift | Drift | 475 |
| Type-2 Not Minor | Normal | 0 | Type-2 Not Drift | Normal | 0 |
| Trend | 0 | Trend | 0 | ||
| Square | 0 | Square | 0 | ||
| Missing | 0 | Missing | 0 | ||
| Drift | 475 | Minor | 0 | ||
| Outlier | 353 | Outlier | 353 | ||
| Identifying Normal | Identifying Trend | ||||||
|---|---|---|---|---|---|---|---|
| Class | Model 1 | Redefined Model 1 | Class | Model 2 | Redefined Model 2 | ||
| Original Training Set | After Synthetic Augmentation | Original Training Set | After Synthetic Augmentation | ||||
| Type-1 Normal | Normal | 9365 | 13,111 | Type-1 Trend | Trend | 4056 | 4056 |
| ↑ 40% | ↑ 0% | ||||||
| Type-2 Not Normal | Trend | 4056 | 4056 | Type-2 Not Trend | Normal | 0 | 0 |
| ↑ 0% | ↑ 0% | ||||||
| Square | 2079 | 2079 | Square | 2079 | 2079 | ||
| ↑ 0% | ↑ 0% | ||||||
| Missing | 2041 | 5103 | Missing | 2041 | 2041 | ||
| ↑ 150% | ↑ 0% | ||||||
| Minor | 1231 | 3078 | Minor | 1231 | 1231 | ||
| ↑ 150% | ↑ 0% | ||||||
| Drift | 475 | 475 | Drift | 475 | 475 | ||
| ↑ 0% | ↑ 0% | ||||||
| Outlier | 353 | 1765 | Outlier | 353 | 353 | ||
| ↑ 400% | ↑ 0% | ||||||
| Identifying Square | Identifying Missing | ||||||
|---|---|---|---|---|---|---|---|
| Class | Model 3 | Redefined Model 3 | Class | Model 4 | Redefined Model 4 | ||
| Original Training Set | After Synthetic Augmentation | Original Training Set | After Synthetic Augmentation | ||||
| Type-1 Square | Square | 2079 | 2079 | Type-1 Missing | Missing | 2041 | 2041 |
| ↑ 0% | ↑ 0% | ||||||
| Type-2 Not Square | Normal | 0 | 0 | Type-2 Not Missing | Normal | 0 | 2000 |
| ↑ 0% | ↑ 21.4% | ||||||
| Trend | 0 | 0 | Trend | 0 | 2000 | ||
| ↑ 0% | ↑ 49.3% | ||||||
| Missing | 2041 | 2041 | Square | 0 | 0 | ||
| ↑ 0% | ↑ 0% | ||||||
| Minor | 1231 | 1231 | Minor | 1231 | 1231 | ||
| ↑ 0% | ↑ 0% | ||||||
| Drift | 475 | 475 | Drift | 475 | 475 | ||
| ↑ 0% | ↑ 0% | ||||||
| Outlier | 353 | 353 | Outlier | 353 | 1412 | ||
| ↑ 0% | ↑ 300% | ||||||
| Identifying Minor | Identifying Drift | ||||||
|---|---|---|---|---|---|---|---|
| Class | Model 5 | Redefined Model 5 | Class | Model 6 | Redefined Model 6 | ||
| Original Training Set | After Synthetic Augmentation | Original Training Set | After Synthetic Augmentation | ||||
| Type-1 Minor | Minor | 1231 | 4924 | Type-1 Drift | Drift | 475 | 2375 |
| ↑ 300% | ↑ 400% | ||||||
| Type-2 Not Minor | Normal | 0 | 2500 | Type-2 Not Drift | Normal | 0 | 0 |
| ↑ 26.7% | ↑ 0% | ||||||
| Trend | 0 | 0 | Trend | 0 | 2000 | ||
| ↑ 0% | ↑ 49.3% | ||||||
| Square | 0 | 0 | Square | 0 | 0 | ||
| ↑ 0% | ↑ 0% | ||||||
| Missing | 0 | 0 | Missing | 0 | 0 | ||
| ↑ 0% | ↑ 0% | ||||||
| Drift | 475 | 475 | Minor | 0 | 0 | ||
| ↑ 0% | ↑ 0% | ||||||
| Outlier | 353 | 1765 | Outlier | 353 | 1765 | ||
| ↑ 400% | ↑ 400% | ||||||
| Identifying Outlier | |||
|---|---|---|---|
| Class | Model 7 | ||
| No Model | After Synthetic Augmentation | ||
| Type-1 Outlier | Outlier | 353 | 1765 |
| ↑ 400% | |||
| Type-2 Not Outlier | Normal | 0 | 300 |
| ↑ 3.2% | |||
| Trend | 0 | 100 | |
| ↑ 2.5% | |||
| Square | 0 | 100 | |
| ↑ 4.8% | |||
| Missing | 0 | 50 | |
| ↑ 2.4% | |||
| Minor | 0 | 150 | |
| ↑ 12.2% | |||
| Drift | 0 | 50 | |
| ↑ 10.5% | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samudra, S.; Barbosh, M.; Sadhu, A. Machine Learning-Assisted Improved Anomaly Detection for Structural Health Monitoring. Sensors 2023, 23, 3365. https://doi.org/10.3390/s23073365
Samudra S, Barbosh M, Sadhu A. Machine Learning-Assisted Improved Anomaly Detection for Structural Health Monitoring. Sensors. 2023; 23(7):3365. https://doi.org/10.3390/s23073365
Chicago/Turabian StyleSamudra, Shreyas, Mohamed Barbosh, and Ayan Sadhu. 2023. "Machine Learning-Assisted Improved Anomaly Detection for Structural Health Monitoring" Sensors 23, no. 7: 3365. https://doi.org/10.3390/s23073365
APA StyleSamudra, S., Barbosh, M., & Sadhu, A. (2023). Machine Learning-Assisted Improved Anomaly Detection for Structural Health Monitoring. Sensors, 23(7), 3365. https://doi.org/10.3390/s23073365